
Letzte Woche habe ich einen ganzen Nachmittag darauf verwendet, einer KI-Agentin beizubringen, ein Lieferantenformular in einem passwortgeschützten Portal auszufüllen. Nach drei Stunden starrte ich auf die Fehlermeldung „Connection Refused“, der Speicher meines VPS war erschöpft, und ich war ernsthaft drauf und dran, die Sache einfach wieder von Hand zu erledigen.
Genau so fühlt sich der Einstieg in die OpenClaw-Browserautomatisierung oft an. Das Tool navigiert durch Seiten, scrapt Daten, füllt Formulare aus und arbeitet komplexe Workflows nach Anweisungen in ganz normaler Sprache ab — wirklich beeindruckend. Doch zwischen „klingt großartig“ und „läuft tatsächlich auf meinem Rechner“ bleiben die meisten stecken.
Ich kenne beide Seiten dieser Lücke nur zu gut — aus der Entwicklung von Automatisierungstools bei Thunderbit ebenso wie aus dem Testen dessen, was das Open-Source-Ökosystem hergibt. Dieser Leitfaden ist genau der, den ich mir damals gewünscht hätte: eine echte Schritt-für-Schritt-Einrichtung, die Browser-Modus-Entscheidung, an der alle stolpern, ein Windows-nativer Weg (weil WSL keine Voraussetzung sein sollte), ein Überlebensleitfaden gegen Bot-Schutz, echte Ausgabe-Beispiele, typische Fehler mitsamt konkreten Fixes und eine ehrliche Einschätzung, wann OpenClaw die richtige Wahl ist — und wann es schlicht zu viel des Guten ist.
Thunderbit für müheloses Web-Scraping testen
Daten von jeder Website mit KI scrapen Get Started Free
Was ist OpenClaw Browser Automation?
OpenClaw ist eine kostenlose, quelloffene KI-Agenten-Plattform (MIT-Lizenz), die in Ihrem Auftrag einen Browser steuert. Statt Selenium-Skripte oder Puppeteer-Code zu schreiben, beschreiben Sie einfach in normaler Sprache, was passieren soll — „Öffne diese Seite und extrahiere alle Produktnamen und Preise“ — und die KI übernimmt den Rest. Dabei stützt sich OpenClaw auf ein nummeriertes Snapshot-System: Der Agent erkennt Seitenelemente, vergibt Referenznummern und arbeitet sie Schritt für Schritt ab.
Die Architektur ruht auf drei Bausteinen — deshalb ist die Einrichtung mehr als nur ein simples Browser-Plugin:
- Gateway (VPS/Server): das „Gehirn“, das Ihre Anweisungen verarbeitet und mit den LLMs verbunden ist. Standardmäßig läuft es auf Port 18789.
- Node Host (lokaler Rechner): ein Relay, über das das Gateway Browser-Befehle an Ihr lokales Chrome schickt. Angebunden über einen sicheren Tunnel wie Tailscale.
- Chrome-Erweiterung (Browser-Relay): gibt dem Agenten die direkte Kontrolle über Browser-Tabs in Ihrem echten Browser.
Weitere Ports sind Control Service (18791), CDP Relay (18792) sowie Managed-Browser-CDP (18800–18899, unterstützt bis zu 100 parallele Profile).
Ja, das sind viele bewegliche Teile. Aber sobald Sie verstehen, wofür jede Komponente gut ist, ergibt das Setup Sinn. Denken Sie an ein ferngesteuertes Auto: Das Gateway ist die Fernsteuerung, der Node Host das Funksignal und die Chrome-Erweiterung das Auto selbst.

Warum OpenClaw Browser Automation für Business-Teams wichtig ist
Wissensarbeiter verbringen laut Studien bis zu 60 % ihrer Zeit mit Routineverwaltung statt mit wertschöpfender Arbeit — darunter 1,8 Stunden täglich allein mit dem Suchen und Zusammentragen von Informationen. Smartsheet fand heraus, dass mehr als 40 % der Beschäftigten mindestens ein Viertel ihrer Wochenarbeitszeit für manuelle, sich wiederholende Aufgaben verbrauchen. Allein die manuelle Dateneingabe kostet US-Unternehmen schätzungsweise 8.500 US-Dollar (ca. 7.850 Euro) pro Mitarbeiter und Jahr.
Genau dieses Problem will OpenClaw Browser Automation lösen. In der Praxis lässt sich das auf konkrete Geschäftsprozesse herunterbrechen:
| Anwendungsfall | Was OpenClaw macht | Geschäftlicher Nutzen |
|---|---|---|
| Lead-Generierung | Extrahiert Kontaktdaten aus Verzeichnissen und Unternehmensseiten | Der Sales-Funnel füllt sich schneller |
| Wettbewerbs-Preisbeobachtung | Ruft täglich Produktseiten auf und extrahiert Preise | Wettbewerbsinformationen in Echtzeit |
| Formularausfüllung / Dateneingabe | Füllt wiederkehrende Webformulare aus (CRM, Portale, Anträge) | Stundenersparnis pro Woche |
| Content-Monitoring | Prüft Wettbewerbsblogs, Jobbörsen und Pressemitteilungen | Frühe Marktsignale |
| QA / Testing | Führt Web-Abläufe aus, um ihre Funktion zu prüfen | Weniger fehlerhafte Nutzererlebnisse |
Der Markt für KI-Agenten erreichte 2025 ein Volumen von 7,38 Milliarden US-Dollar (ca. 6,8 Milliarden Euro) und hat sich damit gegenüber 3,7 Milliarden US-Dollar im Jahr 2023 nahezu verdoppelt. Hinzu kommt, dass inzwischen 88 % der Unternehmen in mindestens einem Bereich KI-Automatisierung einsetzen. Das ist längst keine Nische mehr.
Sandbox Chromium vs. Browser Relay vs. Chrome Remote Debugging: Den richtigen Modus wählen
Den falschen Browser-Modus zu erwischen, ist nach meiner Erfahrung die größte Frustquelle für neue OpenClaw-Nutzer. Ich habe erlebt, wie Leute stundenlang Verbindungsprobleme debuggt haben, die sich mit der richtigen Moduswahl von Anfang an erübrigt hätten. OpenClaw bietet drei Verbindungswege — und jeder hat seine ganz realen Vor- und Nachteile:
- Sandbox Chromium (Managed Profile): OpenClaw startet seinen eigenen Headless-Browser auf dem Server. Keine Login-Sitzungen, schnell, wenig Setup — dafür für Bot-Schutzsysteme leichter zu erkennen.
- Browser Relay (Existing-Session): Ein Node Host auf Ihrem lokalen Rechner reicht Anweisungen vom VPS an Ihren echten Chrome-Browser weiter. Unterstützt Logins und Cookies und übernimmt den Fingerprint Ihres realen Browsers.
- Chrome Remote Debugging (Remote CDP): verbindet sich über eine WebSocket-URL mit Remote-Browsern. Voller Sitzungszugriff, aber die höchste Einrichtungs-Komplexität. Funktioniert mit Cloud-Anbietern wie Browserless oder Browserbase.
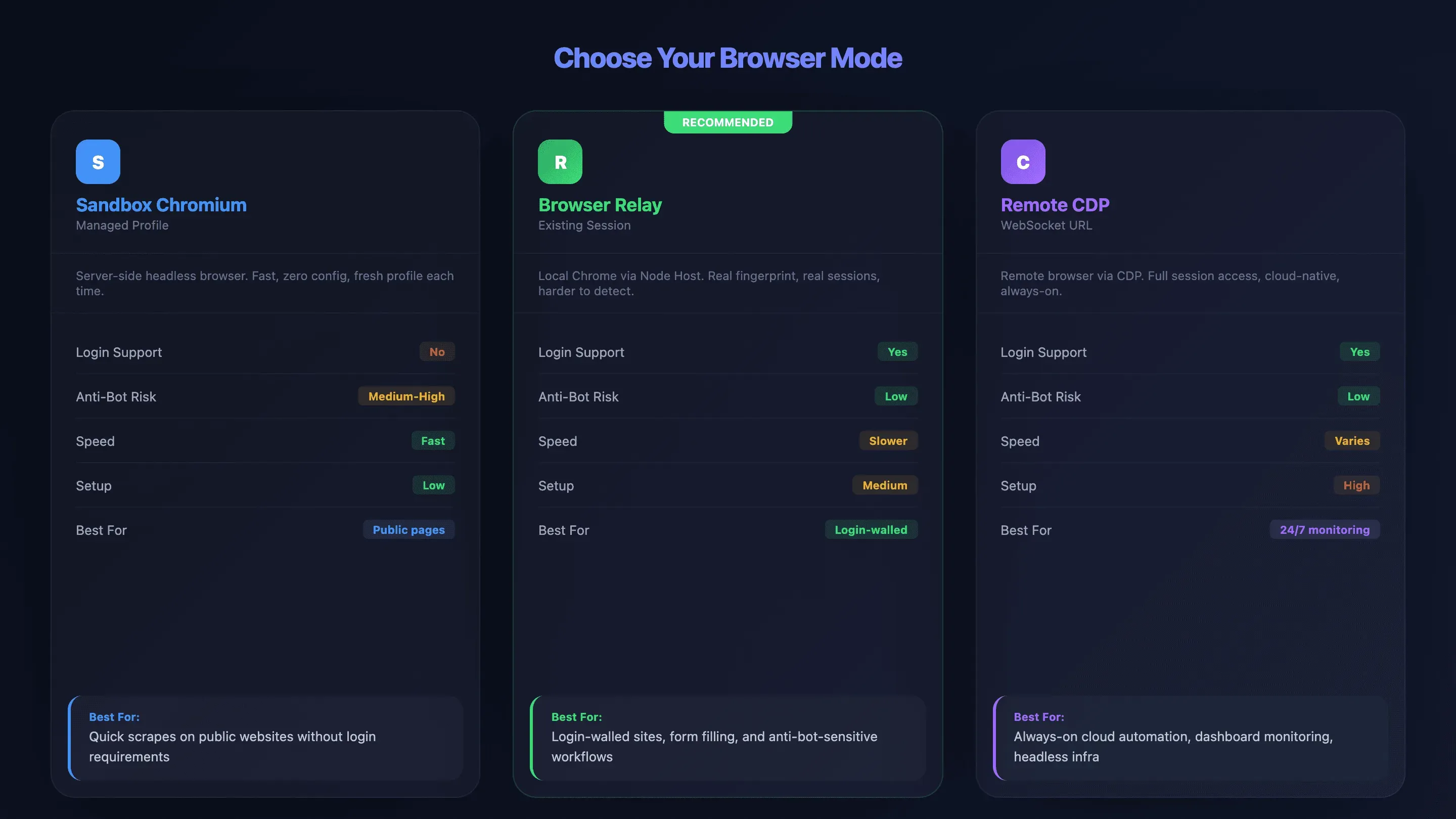
Vergleichstabelle: Alle drei Browser-Modi
| Faktor | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| Login-Unterstützung | ❌ Nein (frisches Profil) | ✅ Ja (echte Sitzungen) | ✅ Ja (vorab authentifiziert) |
| Bot-Schutz-Risiko | ⚠️ Mittel-hoch | ✅ Niedrig (realer Fingerprint) | ✅ Niedrig (provider-verwaltet) |
| Geschwindigkeit | ✅ Schnell | ⚠️ Langsamer (Netzwerk-Relay) | ⚠️ Variiert |
| Setup-Komplexität | Niedrig | Mittel | Hoch |
| Vollständige Funktionsunterstützung | ✅ Ja (alle Funktionen) | ⚠️ Eingeschränkt (kein Batch, kein Download-Intercept) | Abhängig vom Anbieter |
| Am besten für | Öffentliche Seiten, schnelle Scrapes | Login-geschützte Seiten, Formularausfüllung | Cloud-Infrastruktur, dauerhaftes Monitoring |
Entscheidungsbaum: Welchen Modus sollten Sie wählen?
Arbeiten Sie diese Fragen der Reihe nach durch:
- „Müssen Sie eingeloggt sein?“ — Nein → Sandbox Chromium. Ja → nächste Frage.
- „Hat die Seite starken Bot-Schutz?“ — Ja → Browser Relay (Ihr echter Browser-Fingerprint senkt die Erkennungsrate). Nein → Browser Relay oder Remote CDP.
- „Brauchen Sie eine dauerhafte, ständig aktive Sitzung (z. B. ein Dashboard rund um die Uhr überwachen)?“ — Ja → Remote CDP mit einem Cloud-Anbieter. Nein → Browser Relay.
Praxisbeispiele:
- Öffentliche Amazon-Listings scrapen → Sandbox Chromium
- CRM-Formular hinter Login ausfüllen → Browser Relay
- Internes Analytics-Dashboard rund um die Uhr überwachen → Remote CDP mit Browserless/Browserbase
Wenn Sie diese eine Entscheidung richtig treffen, ersparen Sie sich Stunden an Fehlersuche. Wirklich.
Bevor Sie starten
- Schwierigkeit: Mittelstufe (CLI-Kenntnisse erforderlich)
- Benötigte Zeit: 45–75 Minuten für das komplette Setup; 10–15 Minuten pro Schritt
- Was Sie brauchen: einen VPS (mindestens 2 GB RAM, 4 GB empfohlen), Node.js v22.12.0+, ein Tailscale-Konto (kostenlos), Chrome und etwas Geduld
Schritt 1: OpenClaw auf einem VPS starten (oder lokal)
Auf dem VPS läuft das „Gehirn“ von OpenClaw. Es gibt zwei Wege, es ans Laufen zu bringen:
Option A: VPS-Hosting mit Ein-Klick-Setup
Mehrere Anbieter halten vorgefertigte OpenClaw-Images bereit:
| Anbieter | Startpreis | Hinweise |
|---|---|---|
| Hostinger | ab 6,99 $/Monat | Vorgekonfiguriertes Image |
| Tencent Cloud Lighthouse | ab ca. 0,08 $/Jahr (Promo) | 2 Kerne / 4 GB empfohlen |
| Hetzner | ab 4,09 $/Monat (CX22) | Bestes Preis-Leistungs-Verhältnis; manuelle Installation |
| DigitalOcean | ab 4 $/Monat | Manuelle Installation |
| Vultr | ab 3,50 $/Monat | Manuelle Installation |
Option B: Manuelle CLI-Installation
# Installation über npm (erfordert Node.js v22.12.0+)
npm install -g openclaw
# Onboarding-Assistent starten
openclaw onboard
# Gateway-Token erzeugen (unbedingt speichern — den brauchen Sie später für den Node Host)
openclaw doctor --generate-gateway-token
# Konfiguration prüfen
openclaw doctor --fix
Mindestanforderungen: 2 GB RAM (bei 1 GB kommt es zu Abstürzen), 4 GB empfohlen. Jede Headless-Browser-Instanz schluckt im Leerlauf 400–800 MB. Wenn Sie Docker verwenden, setzen Sie shm_size: '2gb' — das ist für die Stabilität entscheidend.
Nach diesem Schritt sollte OpenClaw laufen und ein Gateway-Token sicher verstaut sein. (Ich bewahre meinen im Passwortmanager auf. Verlieren Sie ihn nicht.)
Schritt 2: Tailscale einrichten, um VPS und lokalen Rechner zu verbinden
Tailscale spannt einen privaten, verschlüsselten Tunnel zwischen Ihrem VPS und Ihrem lokalen Gerät, damit Browser-Anweisungen nicht über das offene Internet laufen. Angesichts der Tatsache, dass OpenClaw Anfang 2026 512 von Kaspersky gemeldete Schwachstellen aufwies, sollten Sie diesen Schritt besser nicht überspringen.
# Auf dem VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Merken Sie sich die Tailscale-IP des VPS (100.x.x.x)
# Gateway so konfigurieren, dass es auf dem Tailscale-Netzwerk lauscht
openclaw config set gateway.listen "100.x.x.x:18789"
Installieren Sie Tailscale auf Ihrem lokalen Rechner über tailscale.com/download. Beide Geräte müssen dasselbe Tailscale-Konto nutzen.
Alternativen, falls Tailscale nichts für Sie ist:
| Faktor | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Einrichtungszeit | 5 Min. | 10–15 Min. | 20–30 Min. |
| Kosten | Kostenlos (privat) | Kostenlos | Kostenlos |
| NAT-Traversal | Automatisch | Automatisch | Manuell |
Jetzt sollten Sie von Ihrem lokalen Rechner aus die Tailscale-IP Ihres VPS anpingen können. Klappt das nicht, prüfen Sie, ob beide Geräte im selben Tailscale-Konto angemeldet sind.
Schritt 3: Node Host auf Ihrem lokalen Gerät installieren
Der Node Host reicht Browser-Anweisungen vom VPS-Gateway an Ihr lokales Chrome weiter — der Übersetzer zwischen Server und Browser.
# Node-Host-Paket installieren
npm install -g @openclaw/node-host
# Gateway-Token aus Schritt 1 setzen
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Node Host starten und auf die Tailscale-IP Ihres VPS zeigen
openclaw node install --host 100.x.x.x --port 18789
# Verbindung von der VPS-Seite aus freigeben
openclaw node approve <node-id>
Sie sollten eine Bestätigung sehen, dass der Node verbunden und freigegeben ist. Bleibt der Freigabeschritt hängen, starten Sie den Gateway-Prozess auf dem VPS neu.
Schritt 4: OpenClaw Chrome-Erweiterung installieren
Die Erweiterung gibt dem Agenten die direkte Kontrolle über Browser-Tabs. Sie finden sie auch im Chrome Web Store, wenn Sie nach „OpenClaw Browser Relay“ suchen.
# Erweiterungsdateien installieren
openclaw browser extension install
# Oder manuell:
# 1. chrome://extensions öffnen
# 2. "Entwicklermodus" aktivieren (Schalter oben rechts)
# 3. Auf "Entpackte Erweiterung laden" klicken → Erweiterungsordner auswählen
# 4. An die Symbolleiste anheften
# 5. Prüfen, ob das Badge "ON" anzeigt
Zeigt das Badge „ON“, läuft alles. Bleibt es bei „OFF“, springen Sie direkt zum Troubleshooting-Abschnitt weiter unten.
Schritt 5: Ihre erste OpenClaw-Browserautomatisierungsaufgabe ausführen
Öffnen Sie einen Ziel-Tab und probieren Sie dann im OpenClaw-Chat etwas Schlichtes:
Gehe zu https://books.toscrape.com und extrahiere Titel und Preis jedes Buchs auf der Seite
Erwarteter Ablauf: Anweisung gesendet → Agent nimmt einen Snapshot auf (erkennt Seitenelemente mit nummerierten Referenzen) → Agent extrahiert die Daten → strukturierte Ausgabe kommt als JSON oder CSV zurück.
Ein Tipp aus der Praxis: Starten Sie mit sehr einfachen Prompts. Zu viele Details können die KI tatsächlich verwirren — ergänzen Sie nur dann mehr, wenn der Agent Ihre erste Anweisung falsch deutet.
Bei 20 Büchern auf der ersten Seite sollten Sie mit rund 30–60 Sekunden rechnen. Strukturierte Daten zurück? Dann steht Ihr OpenClaw-Browser-Automatisierungs-Setup.
OpenClaw Browser Automation unter Windows: Der native Setup-Pfad
Die meisten OpenClaw-Anleitungen gehen von macOS oder Linux aus. Wenn Sie unter Windows arbeiten, ist Ihnen das sicher längst aufgefallen. Ein Foren-Nutzer brachte es treffend auf den Punkt: „Viele Lösungen klangen konzeptionell gut, aber keine war für natives Windows gedacht.“
Hier kommt, was tatsächlich funktioniert.
Option A: Chrome Remote Debugging unter Windows (empfohlener nativer Weg)
Der zuverlässigste Windows-native Ansatz. Öffnen Sie PowerShell und starten Sie Chrome mit aktivem Remote-Debugging:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Liegt Chrome dort nicht, probieren Sie:
# Alternative Speicherorte prüfen
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# Oder AppData prüfen
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Konfigurieren Sie anschließend OpenClaw für die Verbindung per Remote CDP, indem Sie in Ihrer openclaw.json-Konfiguration cdpUrl auf ws://localhost:9222 setzen.
Option B: Docker Desktop als Windows-Fallback
Macht der native Weg Probleme, kann Docker Desktop unter Windows einen Headless-Chromium-Container betreiben:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# OpenClaw darauf zeigen lassen: cdpUrl: "ws://localhost:9222"
Das bringt zwar eine zusätzliche Komplexitätsebene mit, läuft bei manchen Nutzern aber stabiler. Funktioniert, ist nur nicht besonders elegant.
Windows-spezifischer Fehlerkatalog
| Fehler | Ursache | Fix (PowerShell) |
|---|---|---|
| Port 9222 bereits belegt | Eine andere DevTools-Sitzung ist offen | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| Chrome-Binary nicht gefunden | Falscher Pfad | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale: Verbindung abgelehnt | Windows-Firewall blockiert | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm-Berechtigungsfehler | PowerShell nicht als Administrator ausgeführt | PowerShell als Administrator starten oder nvm-windows verwenden |
Alle Befehle oben sind PowerShell, nicht bash. Einfach kopieren und einfügen.
Überlebensleitfaden gegen Bot-Schutz für OpenClaw Browser Automation
Bot-Erkennung ist das größte Ärgernis für Nutzer der OpenClaw-Browserautomatisierung. Das Standard-Chromium von OpenClaw hat keine eingebauten Stealth-Maßnahmen — Websites erkennen es am WebDriver-Flag, an Bildschirmgrößen, am Font-Fingerprinting und an der IP-Reputation. Ich habe erlebt, wie Agenten auf manchen Seiten binnen Sekunden blockiert wurden.
Es hilft aber, sich gestaffelt vorzuarbeiten. Beginnen Sie mit der einfachsten Lösung und gehen Sie nur dann eine Stufe weiter, wenn es nötig ist.
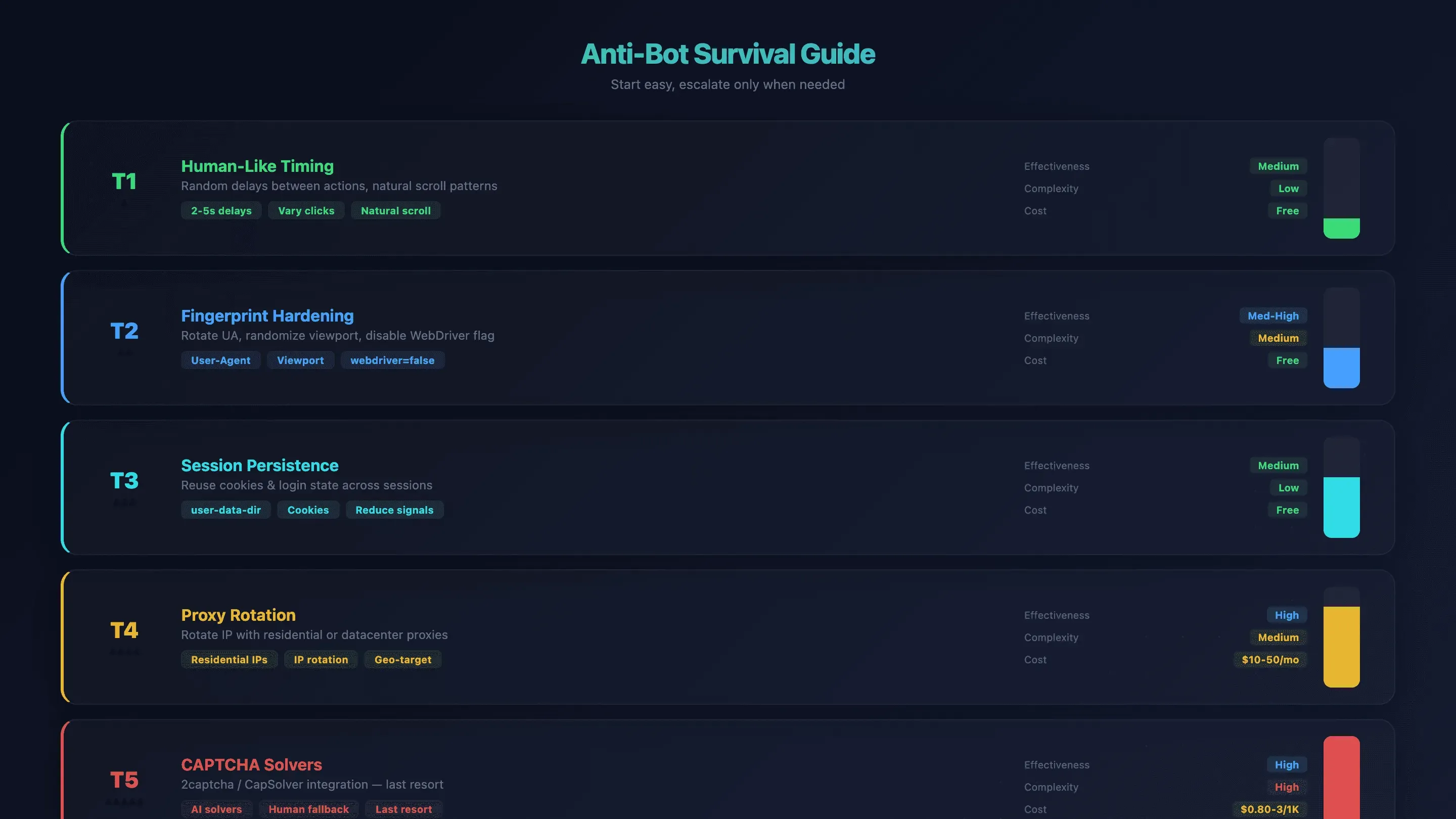
Stufe 1: Menschliches Timing und Verhalten
Bauen Sie in Ihre Prompts zufällige Verzögerungen zwischen den Aktionen ein. Statt Klicks mit Maschinentempo abzufeuern, weisen Sie den Agenten an: „warte zwischen jedem Klick 2–5 Sekunden“. Die KI variiert das Timing ohnehin ein Stück weit, aber klare Anweisungen helfen.
Wirksamkeit: Mittel | Komplexität: Niedrig | Kosten: Kostenlos
Stufe 2: Fingerprint-Härtung
Rotieren Sie User-Agent-Strings, variieren Sie die Viewport-Größe und lassen Sie OpenClaw den navigator.webdriver-Flag automatisch abschalten (über --disable-blink-features=AutomationControlled).
# Eigene Header setzen
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Viewport randomisieren
openclaw browser set viewport 1366 768
# Zeitzone und Locale setzen
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Für eine stärkere Tarnung empfiehlt die Community Camoufox (ein Firefox-basierter Anti-Detect-Browser mit Fingerprint-Spoofing direkt auf C++-Engine-Ebene).
Wirksamkeit: Mittel bis hoch | Komplexität: Mittel | Kosten: Kostenlos
Stufe 3: Sitzungs-Persistenz
Nutzen Sie user-data-dir, um Cookies und Login-Status über Sitzungen hinweg zu erhalten. So reduzieren Sie die Signale eines „frischen Browsers“, auf die Bot-Systeme anspringen.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Wirksamkeit: Mittel | Komplexität: Niedrig | Kosten: Kostenlos
Stufe 4: Proxy-Rotation
Reichen Timing und Fingerprint-Tuning nicht aus, rotieren Sie Ihre IP-Adresse. Residential Proxies sind schwerer zu enttarnen; Datacenter-Proxies sind schneller und günstiger.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Hinweis: Die Proxy-Konfiguration auf Browserebene ist derzeit noch ein Feature-Wunsch (GitHub Issue #8079). Aktuell müssen Proxys auf OS- oder Umgebungs-Ebene gesetzt werden.
| Anbieter | Residential | Datacenter | Am besten für |
|---|---|---|---|
| Bright Data | 4–8,40 $/GB | 0,43–0,60 $/GB | Enterprise, höchste Qualität |
| Oxylabs | 6–8 $/GB | 0,48–5 $/GB | Scraping im großen Stil |
| Decodo (Smartproxy) | 4–5,50 $/GB | 0,70–5 $/GB | Mittleres Budget |
| IPRoyal | 5–7 $/GB | -- | Preisbewusst |
| DataImpulse | 1 $/GB | -- | Niedrigste Kosten |
Wirksamkeit: Hoch | Komplexität: Mittel | Kosten: 10–50 $/Monat
Stufe 5: CAPTCHA-Löser
Nur als letztes Mittel. Binden Sie Dienste wie 2captcha oder CapSolver ein.
| Dienst | reCAPTCHA v2 | Cloudflare Turnstile | Latenz |
|---|---|---|---|
| 2Captcha | 2,99 $/1K | 2,99 $/1K | 15–45 Sek. (menschliche Löser) |
| CapSolver | 0,80–1,50 $/1K | 0,80 $/1K | 0,5–10 Sek. (KI) |
FlareSolverr (Open-Source-Umgehung für Cloudflare) gilt 2025–2026 als unzuverlässig, weil Cloudflares Schutzmechanismen immer weiter verschärft wurden.
Wirksamkeit: Hoch | Komplexität: Hoch | Kosten: 0,80–3 $/1K Lösungen
Zusammenfassung der Anti-Bot-Strategien
| Technik | Wirksamkeit | Komplexität | Kosten |
|---|---|---|---|
| Menschliches Timing | Mittel | Niedrig | Kostenlos |
| Fingerprint-Härtung | Mittel bis hoch | Mittel | Kostenlos |
| Sitzungs-Persistenz | Mittel | Niedrig | Kostenlos |
| Proxy-Rotation | Hoch | Mittel | 10–50 $/Monat |
| CAPTCHA-Löser | Hoch | Hoch | 0,80–3 $/1K Lösungen |
Für alle, die immer wieder am Bot-Schutz scheitern und einfach nur an die Daten kommen wollen: Das Cloud-Scraping von Thunderbit kommt bei öffentlichen Websites mit Bot-Schutz direkt zurecht — ohne Proxy-Konfiguration und ohne Fingerprint-Tuning. Das ist ein grundlegend anderer Ansatz (die KI liest die Seite jedes Mal über verwaltete Cloud-Infrastruktur) und umgeht bei typischen Extraktionsaufgaben die komplette Anti-Bot-Aufrüstung.
Echte Ausgabe: Was OpenClaw Browser Automation tatsächlich produziert
Bevor Sie 45–75 Minuten in die Einrichtung stecken, wollen Sie vermutlich sehen, wie das Ergebnis aussieht. Verständlich — hier sind drei Workflow-Beispiele mit echter Ausgabe.
Beispiel 1: Web-Scraping — Produktdaten extrahieren
Prompt: „Gehe zu https://books.toscrape.com und extrahiere den Titel und Preis jedes Buchs auf der Seite“
Ausgabe (erste 5 Zeilen):
| Titel | Preis |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Benötigte Zeit: ca. 45 Sekunden für 20 Zeilen (eine Seite). Für die Paginierung war eine Folgeanweisung nötig: „Klicke auf Next und wiederhole das für 5 Seiten.“ Insgesamt: rund 100 Zeilen in etwa 3 Minuten.
Beispiel 2: Formularautomatisierung — Ein mehrfeldriges Webformular ausfüllen
Szenario: ein Lieferantenanfrageformular mit Firmennamen, Kontaktdaten und Produktinteresse ausfüllen.
Der Agent nimmt einen Snapshot des Formulars auf, identifiziert jedes Feld über eine Referenznummer und füllt sie nacheinander aus. Vorher: leere Formularfelder. Nachher: alle Felder ausgefüllt, Bestätigungsnachricht angezeigt. Dropdown-Menüs oder Checkboxen verarbeitet das Snapshot-System gleich mit — der Agent „sieht“ die Optionen und wählt die richtige aus.
Benötigte Zeit: ca. 30 Sekunden für ein Formular mit 6 Feldern.
Beispiel 3: Paginierung — Scraping über mehrere Seiten hinweg
Ergebnis zu Beginn: 20 Zeilen von Seite 1. Nach der Anweisung „Klicke auf Next und wiederhole das für alle Seiten“: 1.000 Zeilen über 50 Seiten auf books.toscrape.com. Der Agent erkennt den „Next“-Button per Snapshot und klickt ihn in einer Schleife.
Benötigte Zeit: ca. 12 Minuten für den vollständigen Datensatz mit 1.000 Zeilen.
Direktvergleich: Dieselbe Scraping-Aufgabe in Thunderbit
Für dasselbe books.toscrape.com-Beispiel sieht der Ablauf in Thunderbit so aus:
- Installieren Sie die Thunderbit Chrome-Erweiterung (~30 Sekunden)
- Öffnen Sie die Seite
- Klicken Sie auf „KI-Felder vorschlagen“ → die KI erkennt Titel, Preis, Verfügbarkeit und Bewertung
- Klicken Sie auf „Scrapen“ → 20 Zeilen werden extrahiert
- Nutzen Sie die Paginierungsfunktionen → alle Seiten werden gescrapt
- Export nach Google Sheets (kostenlos)
Gesamtzeit: ca. 3 Minuten von null bis zu exportierten Daten — ohne VPS, ohne CLI, ohne Konfiguration.
Es geht nicht darum, dass ein Tool „besser“ wäre. Das richtige Tool richtet sich danach, was Sie tatsächlich erreichen wollen.
Thunderbit Chrome-Erweiterung testen
Wann OpenClaw Browser Automation überdimensioniert ist (und was Sie stattdessen nutzen sollten)
OpenClaw spielt seine Stärken bei komplexen, mehrstufigen, agentischen Automatisierungen aus — Login-geschützte Workflows, die Browser-Aktionen mit Shell-Befehlen verzahnen und 24/7 auf einem VPS laufen. Lautet das Ziel hingegen nur „Produktdaten aus einer Listing-Seite holen“ oder „E-Mails aus einem Verzeichnis ziehen“, ist der komplette Stack aus VPS + Tailscale + Node Host wahrscheinlich unnötig schwerfällig.
Ich habe erlebt, wie Menschen über 60 Minuten in ein Setup gesteckt haben, um eine Aufgabe zu lösen, die mit einem schlankeren Tool in 2 Minuten erledigt gewesen wäre. Kein guter Tausch.
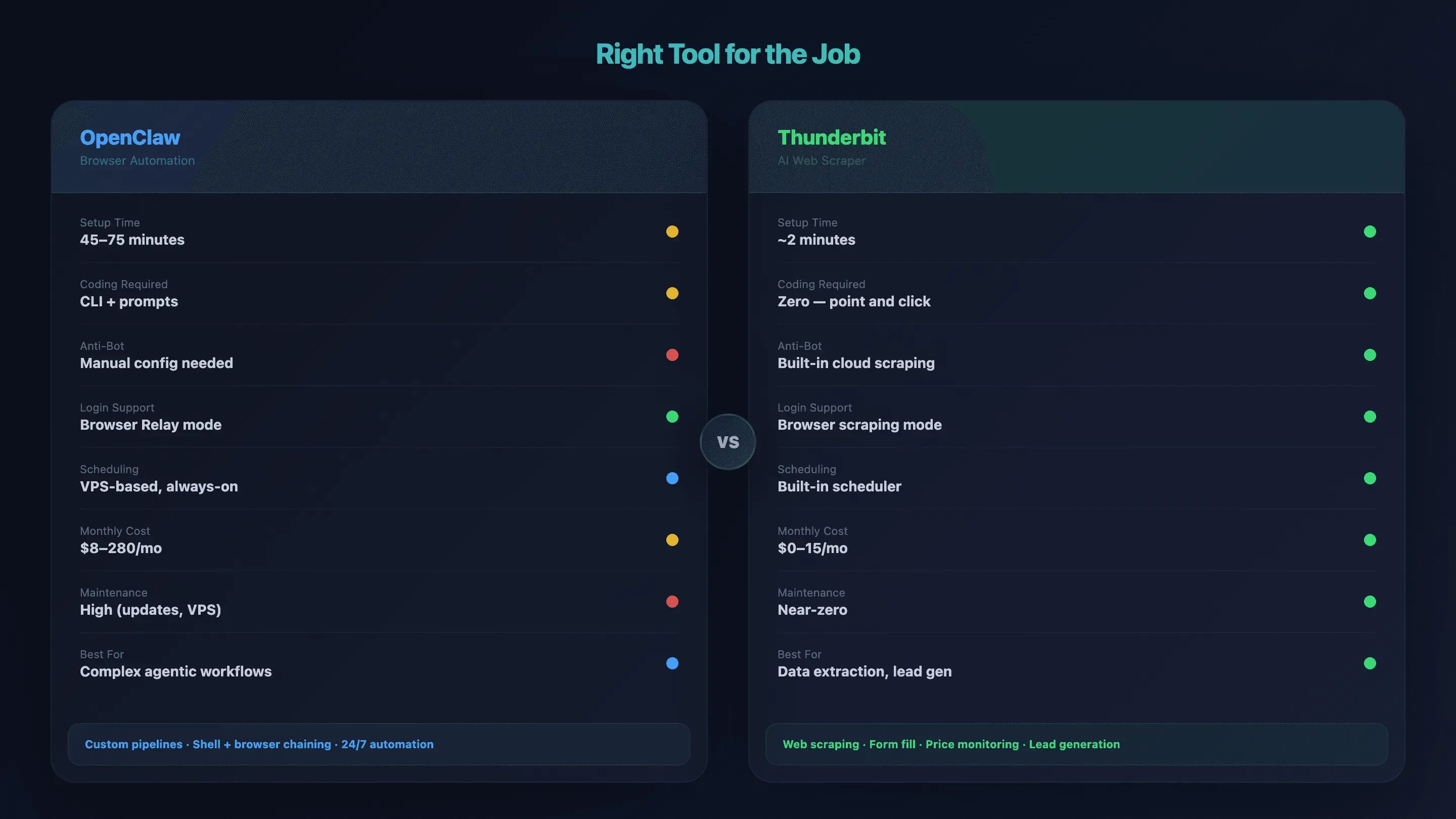
Das richtige Werkzeug für den Job: Vergleichstabelle
| Faktor | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| Einrichtungszeit | 45–75 Min. (VPS + Tailscale + Node Host) | ca. 2 Min. (Chrome-Erweiterung installieren) |
| Programmierung nötig | CLI + Prompts in natürlicher Sprache | Keine — einfach „KI-Felder vorschlagen“ → „Scrapen“ klicken |
| Bot-Schutz | Manuell (Proxy, Fingerprint-Konfiguration) | Integriertes Cloud-Scraping |
| Navigation durch Login-Walls | ✅ Browser Relay / Remote Debug | ✅ Browser-Scraping-Modus |
| Subpage-Anreicherung | Für jeden Workflow eigenes Skripting | Subpage-Scraping mit einem Klick |
| Geplante / 24×7 Läufe | VPS-basiert, immer aktiv | Integrierter Scheduled Scraper |
| Monatliche Kosten | 8–14 $ (Hobby) bis 110–280 $ (intensiv) | 0 $ (kostenlose Stufe) bis 15 $/Monat |
| Wartungsaufwand | Hoch (Updates, VPS, Debugging) | Nahe null — KI passt sich Layout-Änderungen an |
| Am besten für | Komplexe agentische Workflows, Custom Pipelines | Datenauswertung, Formulare, Lead-Generierung, Preisbeobachtung |
Einsatzempfehlung
- Sie brauchen mehrstufige agentische Workflows, die Browseraktionen mit Shell-Befehlen, Messaging-Apps und Datenbanken verknüpfen → OpenClaw ist die richtige Wahl.
- Sie wollen Daten von Websites scrapen, Formulare ausfüllen oder Preise überwachen, ohne ein Terminal anzufassen → Thunderbit bringt Sie schneller ans Ziel. Für schnelle Demos werfen Sie auch einen Blick auf den Thunderbit YouTube Channel.
- Sie brauchen ein leichtgewichtiges Skript für nur einen bestimmten API-Endpunkt → Ein einfaches Python-Skript mit Requests kann schon reichen.
Genau dieses Raster ziehe ich heran, wenn mich jemand im Team fragt: „Welches Tool soll ich dafür nehmen?“
Häufige OpenClaw Browser-Automatisierungsfehler und wie man sie behebt
Setzen Sie für diesen Abschnitt ein Lesezeichen. Er ist nach Symptomen geordnet, damit Sie mit Strg+F direkt zur Lösung springen können.
„Connection Refused“ oder der Node Host verbindet sich nicht
Wahrscheinliche Ursachen (in dieser Reihenfolge prüfen):
- Tailscale läuft nicht auf beiden Geräten →
tailscale statusauf beiden ausführen - Gateway lauscht nicht auf dem Tailscale-Netzwerk (hängt noch auf localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - Falsche IP-Adresse → mit
tailscale ip -4gegenprüfen - Firewall blockiert Port 18789 →
sudo ufw allow 18789/tcp(Linux) oder Windows-Firewall-Regel hinzufügen
Erweiterungs-Badge bleibt auf „OFF“ oder Tab wird nicht erkannt
- Erweiterung nicht im Entwicklermodus geladen →
chrome://extensions→ Entwicklermodus aktivieren → neu laden - Node Host läuft nicht → mit
openclaw node startneu starten - Chrome-Instanz-Konflikt → alle Chrome-Instanzen schließen, neu starten und die Erweiterung neu laden
Agent liefert leere oder falsche Daten
- Seite noch nicht vollständig geladen: Weisen Sie den Agenten an, „nach dem Aufruf 3 Sekunden zu warten, bevor extrahiert wird“. Viele SPAs brauchen Zeit zum Rendern.
- Bot-Schutz greift: Prüfen Sie, ob statt echter Inhalte eine CAPTCHA-Seite auftaucht. Wechseln Sie von Sandbox Chromium zu Browser Relay.
- Veralteter Snapshot: Bitten Sie den Agenten, „einen neuen Snapshot aufzunehmen“ — Referenznummern werden nach einer Navigation schnell ungültig.
„Port 9222 Already in Use“
Kommt häufig vor, wenn Chrome DevTools oder ein anderes Automatisierungstool den Port bereits belegt.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS läuft wegen zu wenig Speicher voll
Jede Headless-Browser-Instanz schluckt 400–800 MB RAM. Laufen mehrere parallel, kann ein kleiner VPS abstürzen.
Lösungen:
- Bilder/CSS/Schriften deaktivieren:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Die Zahl paralleler Instanzen an den verfügbaren RAM anpassen
shm_size: '2gb'in Docker-Konfigurationen setzen- Sitzungshibernation aktivieren:
OPENCLAW_HIBERNATE_AFTER=300 - VPS auf 4 GB+ RAM aufrüsten, wenn Sie mehr Puffer brauchen
Tipps, damit OpenClaw Browser Automation stabil läuft
Ein paar Best Practices, die ich mir mit der Zeit beim Betrieb solcher Setups angeeignet habe:
- Bilder, Stylesheets und Schriften deaktivieren, wenn Sie nur Daten scrapen. Das senkt den Ressourcenverbrauch deutlich und macht alles flotter.
- Browser-Instanzen wiederverwenden, statt für jede Aufgabe eine neue zu starten. Frische Instanzen kosten viel RAM und lösen häufiger Bot-Signale aus.
- Mit einfachen Prompts beginnen. Ergänzen Sie Details nur, wenn der Agent Sie missversteht. Zu viele Informationen verwirren die KI eher, als dass sie helfen.
- VPS-Ressourcen überwachen (CPU, RAM) und rechtzeitig hochskalieren, bevor Sie an Limits stoßen. Ein abgestürzter VPS um 2 Uhr morgens ist kein Vergnügen.
- OpenClaw und die Chrome-Erweiterung aktuell halten — Updates aber zuerst in einer Staging-Umgebung testen. OpenClaw bringt etwa 13 Releases pro Monat heraus, und nicht alle laufen reibungslos.
- Für laufende, wiederkehrende Aufgaben (tägliche Preischecks, wöchentliche Lead-Exporte) lässt sich bei Thunderbit der Scheduled Scraper in normaler Sprache terminieren — ganz ohne VPS-Wartung.
Ethische und rechtliche Aspekte
Kurz, aber wichtig. Halten Sie sich an robots.txt (als IETF-Standard in RFC 9309 formalisiert), drosseln Sie die Anfragerate, prüfen Sie die Nutzungsbedingungen der Zielseiten und behandeln Sie personenbezogene Daten gemäß DSGVO und den geltenden Datenschutzgesetzen. Der Präzedenzfall hiQ gegen LinkedIn (2022) stellte fest, dass das Scraping öffentlich zugänglicher Daten nicht gegen den CFAA verstößt — was aber nicht heißt, dass alles erlaubt ist. Verantwortungsvolle Automatisierung schützt Sie und Ihr Unternehmen. Mehr dazu lesen Sie in unserem Leitfaden zu den rechtlichen Implikationen von Web-Scraping.
Fazit
OpenClaw Browser Automation ist eine starke Lösung für komplexe, mehrstufige Web-Workflows, die sich per natürlicher Sprache steuern lassen. Das sind die wichtigsten Punkte:
- Wählen Sie den Browser-Modus von Anfang an richtig (Sandbox, Relay, Remote CDP) — allein diese Entscheidung erspart Ihnen Stunden an Fehlersuche.
- Windows-Nutzer haben einen gangbaren Weg, müssen aber Windows-spezifische Befehle verwenden und Firewall- sowie Pfadprobleme im Auge behalten.
- Bot-Schutz ist eine echte Hürde — starten Sie mit den einfachsten Maßnahmen (Timing, Fingerprinting) und eskalieren Sie nur bei Bedarf.
- Schauen Sie sich die Ausgabe an, bevor Sie sich festlegen. Brauchen Sie nur strukturierte Daten von einer Listing-Seite, bringt Sie ein No-Code-Tool wie Thunderbit in Minuten ans Ziel — ohne Wartungsaufwand.
- Planen Sie die Wartung mit ein. OpenClaw bringt rund 13 Releases pro Monat heraus, VPS-Kosten summieren sich, und Debugging gehört dazu.
Wenn Sie zuerst den einfachen Weg testen möchten, bietet Thunderbit eine kostenlose Stufe — installieren Sie die Erweiterung, scrapen Sie eine Seite und prüfen Sie, ob das Ihren Bedarf schon deckt, bevor Sie in ein komplettes VPS-Setup investieren. Entscheiden Sie sich doch für OpenClaw, setzen Sie ein Lesezeichen für diesen Leitfaden. Den Fehlerkatalog werden Sie früher oder später brauchen — und möge Ihren Browser-Instanzen nie der RAM ausgehen.
FAQs
Was ist der Unterschied zwischen OpenClaw Sandbox Chromium und Browser Relay?
Sandbox Chromium startet einen Headless-Browser auf dem Server — das ist schnell und mit wenig Setup verbunden, erzeugt aber jedes Mal ein frisches Profil (keine Login-Sitzungen) und ist für Bot-Schutzsysteme leichter zu erkennen. Browser Relay reicht Anweisungen an Ihren echten Chrome-Browser auf dem lokalen Rechner weiter, unterstützt also Logins, übernimmt den realen Browser-Fingerprint und ist als Automatisierung schwerer zu enttarnen. Der Haken: Browser Relay ist wegen des Netzwerk-Relays langsamer und bringt einige Funktionseinschränkungen mit (keine Batch-Aktionen, kein Download-Intercept).
Kann ich OpenClaw Browser Automation unter Windows ohne WSL ausführen?
Ja, aber mit Abstrichen. Der zuverlässigste Windows-native Weg ist Chrome Remote Debugging über PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop ist ein Fallback, falls das nicht stabil läuft. Die volle native Node-Host-Unterstützung unter Windows kann noch ihre Ecken und Kanten haben — werfen Sie einen Blick in die aktuelle Dokumentation und rechnen Sie mit Windows-spezifischen Hürden wie Firewall-Blockaden und abweichenden Binary-Pfaden. Alle Befehle im Windows-Abschnitt dieses Leitfadens sind PowerShell, nicht bash.
Wie gehe ich mit CAPTCHAs in OpenClaw Browser Automation um?
Senken Sie zuerst das Erkennungsrisiko: Bauen Sie menschlich wirkende Timing-Variationen ein, härten Sie den Browser-Fingerprint und nutzen Sie Sitzungs-Persistenz, damit der Browser nicht jedes Mal „frisch“ wirkt. Tauchen CAPTCHAs trotzdem auf, binden Sie einen Solver-Dienst wie 2captcha (2,99 $/1K Lösungen) oder CapSolver (0,80–1,50 $/1K, KI-gestützt) ein. Für öffentliche Websites, bei denen Sie nur Daten brauchen, übernimmt Thunderbit das Anti-Bot-Handling automatisch — ohne Proxy- oder CAPTCHA-Konfiguration.
Ist OpenClaw Browser Automation kostenlos?
OpenClaw selbst ist Open Source (MIT-Lizenz) und kostenlos. Sie brauchen allerdings Infrastruktur: einen VPS für 4–15 $/Monat sowie optionale Dienste wie Proxy-Rotation (10–50 $/Monat) oder CAPTCHA-Löser (Abrechnung pro Lösung). Die monatlichen Gesamtkosten liegen bei 8–14 $ für die Hobby-Nutzung bis 110–280 $ für intensive Automatisierungs-Workloads. Zum Vergleich: Die kostenlose Stufe von Thunderbit deckt grundlegendes Scraping ohne Infrastrukturkosten ab.
Was soll ich tun, wenn mein OpenClaw-Agent immer wieder leere Ergebnisse liefert?
Prüfen Sie drei Dinge in dieser Reihenfolge: Erstens könnte die Seite noch nicht vollständig geladen sein — sagen Sie dem Agenten, er soll „nach dem Aufruf 3 Sekunden warten, bevor er extrahiert“. Zweitens könnten Sie an einer Bot-Schutz-Mauer hängen — wenn der Agent statt echter Inhalte eine CAPTCHA-Seite „sieht“, wechseln Sie von Sandbox Chromium zu Browser Relay. Drittens könnten die Snapshot-Referenzen veraltet sein — bitten Sie den Agenten nach jeder Navigation um einen „neuen Snapshot“. Hilft nichts davon, prüfen Sie die RAM-Auslastung Ihres VPS — ein abgestürzter Browser-Prozess liefert oft stillschweigend leere Ergebnisse.
Thunderbit für schnellere Web-Datenextraktion testen Get Started Free




