Wenn du schon einmal versucht hast, eine Preisliste von Wettbewerbern aufzubauen, neue Immobilienangebote im Blick zu behalten oder einfach einen riesigen E-Commerce-Katalog zu sortieren, kennst du das Problem: stundenlanges Kopieren, Einfügen und Bereinigen chaotischer Daten – nur um am Ende festzustellen, dass vieles schon wieder veraltet ist. Im Jahr 2025, in dem das Web jedes Jahr um Milliarden neuer Seiten wächst, kommt man mit manueller Datenerfassung schlicht nicht mehr hinterher. Unternehmen erkennen immer deutlicher: Strukturierte Webdaten sind kein „Nice-to-have“ mehr – sie sind das Rückgrat smarter Entscheidungen, von Vertrieb und Marketing bis hin zu Operations und Produktstrategie.
Genau hier kommen Listing-Crawler und automatisierte Listing-Extraktion ins Spiel. Ich habe aus erster Hand erlebt, wie Teams mit KI-gestützten Tools wie mühsame, fehleranfällige Recherche in einen schnellen, skalierbaren und sogar ein bisschen angenehmen Prozess verwandeln. Schauen wir uns an, was Listing-Crawling wirklich bedeutet, wie die neuesten KI-gestützten Lösungen funktionieren und wie du sie nutzen kannst, um deinem Unternehmen einen echten Vorsprung zu verschaffen – ganz ohne eine einzige Zeile Code zu schreiben (oder den Verstand zu verlieren).
Was ist ein Listing-Crawler? Die Grundlagen der automatisierten Listing-Extraktion
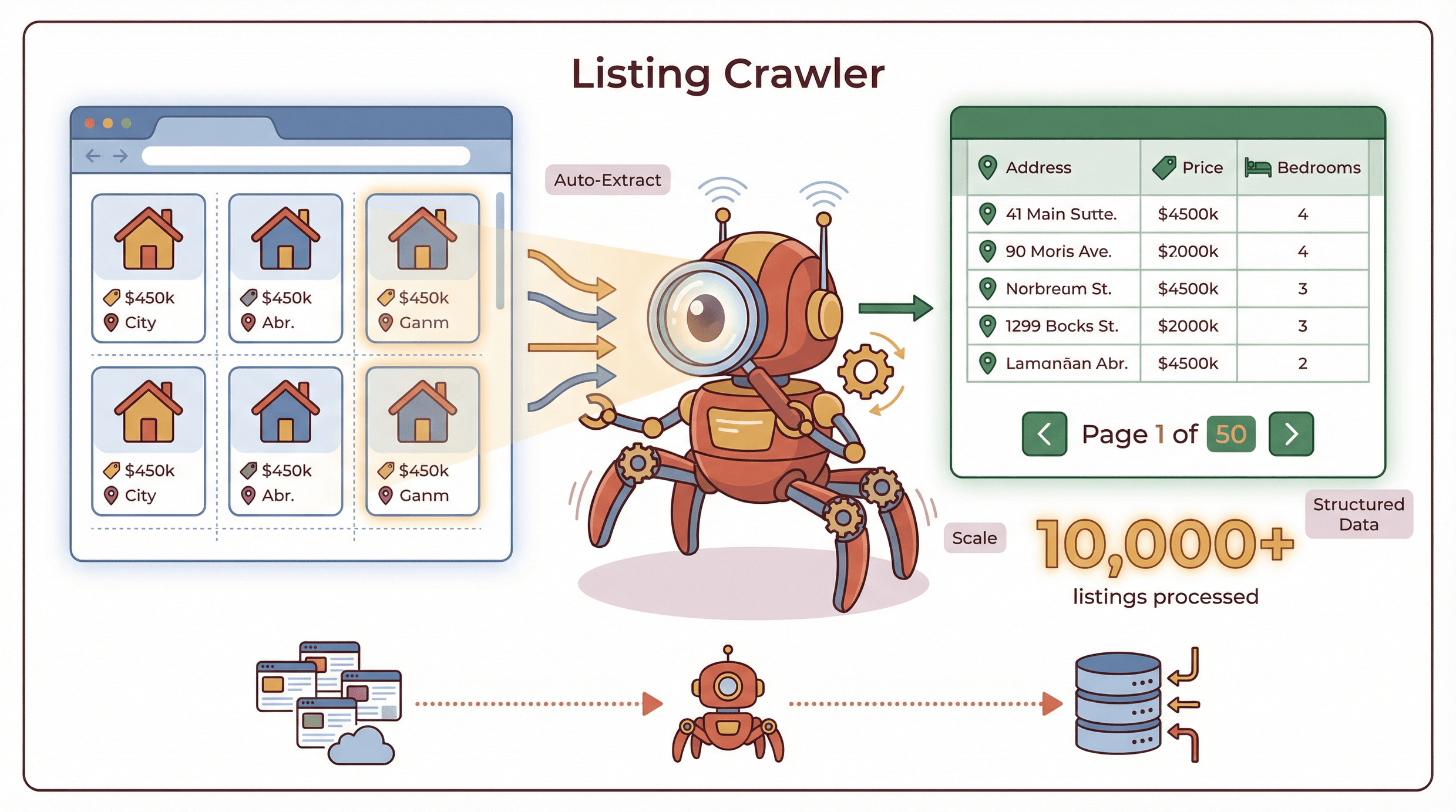 Ein Listing-Crawler ist ein spezialisiertes Tool, das strukturierte Daten aus Webseiten extrahiert, auf denen mehrere Einträge in einem einheitlichen Format dargestellt werden – etwa Produktkataloge, Immobilienanzeigen, Jobbörsen oder Unternehmensverzeichnisse. Anders als allgemeine Web-Scraper, die Daten von beliebigen Seiten ziehen können (strukturiert oder nicht), konzentriert sich ein Listing-Crawler auf wiederkehrende, strukturierte Inhalte und kann problemlos über mehrere Seiten hinweg skalieren, inklusive Funktionen wie Pagination und Unterseiten ().
Ein Listing-Crawler ist ein spezialisiertes Tool, das strukturierte Daten aus Webseiten extrahiert, auf denen mehrere Einträge in einem einheitlichen Format dargestellt werden – etwa Produktkataloge, Immobilienanzeigen, Jobbörsen oder Unternehmensverzeichnisse. Anders als allgemeine Web-Scraper, die Daten von beliebigen Seiten ziehen können (strukturiert oder nicht), konzentriert sich ein Listing-Crawler auf wiederkehrende, strukturierte Inhalte und kann problemlos über mehrere Seiten hinweg skalieren, inklusive Funktionen wie Pagination und Unterseiten ().
Wie funktioniert das? Stell dir vor, du schaust dir eine Immobilienseite mit 50 Objekten pro Seite an. Ein Listing-Crawler kann automatisch die Details jedes Hauses erkennen (Adresse, Preis, Schlafzimmer usw.), sie in eine saubere Tabelle übertragen und dann zur nächsten Seite „klicken“, um weiterzumachen – ganz ohne manuelles Kopieren. Fortgeschrittene Crawler können sogar Links zu Detailseiten (Unterseiten) verfolgen, um zusätzliche Informationen wie Kontaktdaten des Maklers oder Objektbeschreibungen abzurufen.
Der wichtigste Unterschied: Listing-Crawler sind für Skalierung und Struktur gebaut. Sie sind wie ein Roboter-Praktikant, der nie müde wird, nie Tippfehler macht und in Minuten Tausende von Einträgen verarbeiten kann.
Warum automatisierte Listing-Extraktion für Unternehmen wichtig ist
Mal ganz praktisch: Warum kümmern sich so viele Teams – von Vertrieb über Produkt bis Operations – um automatisierte Listing-Extraktion? Hier sind einige der größten Anwendungsfälle und der geschäftliche Nutzen, den sie bringen:
| Anwendungsfall | Geschäftsbereich | Nutzen |
|---|---|---|
| Lead-Generierung (Verzeichnisse scrapen) | Vertrieb / Business Dev | In Minuten statt Wochen frische, qualifizierte Leads ins CRM einpflegen |
| Wettbewerber-Preisüberwachung (Kataloge scrapen) | Marketing / Produkt | Preisintelligenz in Echtzeit, schnellere Strategiewechsel, Umsatzsteigerung |
| Bestands- & Lieferantenüberwachung | Operations / Supply Chain | Aktuelle Bestandsdaten, Engpässe vermeiden, Lieferänderungen sofort erkennen |
| Marktforschung (Einträge/Bewertungen aggregieren) | Strategie / Analytics | Trendanalysen in großem Maßstab, bessere Produktentscheidungen, vollständiger Marktüberblick |
| Immobilien-Tracking | Immobilien / Investment | Rechtzeitige Hinweise auf neue Chancen, Preisänderungen und Vergleichsobjekte – schnellerer Dealflow |
Der ROI ist real: Unternehmen, die automatisierte Listing-Crawler einsetzen, berichten von 30–40 % Zeitersparnis bei der Datenerfassung () und von Datengenauigkeit von bis zu 99 % – im Vergleich zu einer um das 8-Fache höheren Fehlerquote bei manueller Eingabe (). Was früher eine Woche gedauert hat, dauert heute Minuten – und die Daten sind direkt für Analysen bereit, statt nur in einer Tabelle herumzuliegen.
Traditionelle vs. KI-gestützte Listing-Crawler: Was ist der Unterschied?
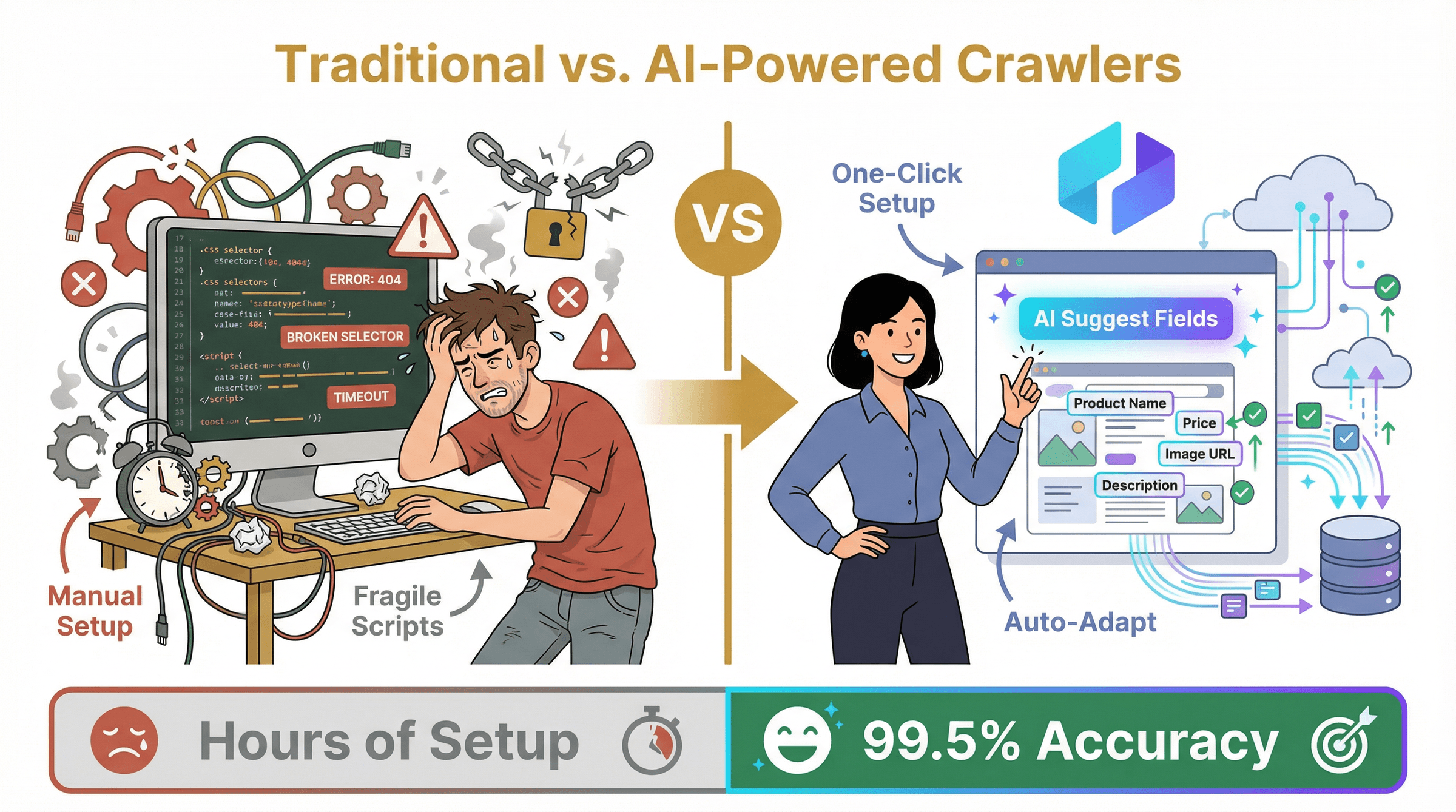 Seien wir ehrlich: Traditionelle Listing-Crawler (denk an Scrapy, BeautifulSoup oder sogar einige „No-Code“-Tools) können die Aufgabe erledigen, bringen aber einige Nachteile mit:
Seien wir ehrlich: Traditionelle Listing-Crawler (denk an Scrapy, BeautifulSoup oder sogar einige „No-Code“-Tools) können die Aufgabe erledigen, bringen aber einige Nachteile mit:
- Manuelle Einrichtung: Du musst CSS-Selektoren definieren, Skripte schreiben oder Vorlagen für jedes Feld erstellen, das du extrahieren willst.
- Anfällige Workflows: Ändert die Website ihr Layout oder ihre Klassennamen, bricht dein Scraper – und du fängst wieder bei null an.
- Begrenzter Umgang mit dynamischen Inhalten: Endloses Scrollen, AJAX-Inhalte oder interaktive Elemente? Dann stehen erst einmal einige späte Debugging-Nächte an.
KI-gestützte Listing-Crawler (wie Thunderbit) drehen den Spieß um. Statt dem Tool zu sagen, wie es Daten extrahieren soll, zeigst du ihm einfach die Seite (oder beschreibst dein Ziel), und die KI erledigt den Rest. Sie erkennt Muster, passt sich an Layout-Änderungen an und kann sogar dynamische Inhalte und Unterseiten verarbeiten – und das mit minimaler Einrichtung.
Die wichtigsten Vorteile der KI-gestützten automatisierten Listing-Extraktion
- Schnellere Einrichtung: Ein Klick auf „KI-Felder vorschlagen“ und das Tool schlägt alle relevanten Spalten vor – ganz ohne Selektoren oder Code.
- Höhere Genauigkeit: KI-Modelle erkennen Daten im Kontext, bereinigen und deduplizieren sie während des Prozesses. Genauigkeitsraten von 99,5 % sind selbst bei chaotischen Seiten möglich ().
- Robust gegenüber Änderungen: Wenn eine Website ihr HTML anpasst, passt sich die KI an – keine kaputten Skripte oder endlose Wartung mehr ().
- Beherrscht dynamische Inhalte: Endloses Scrollen, Pop-ups oder AJAX? KI-Crawler können wie ein Mensch mit der Seite interagieren und stellen sicher, dass nichts übersehen wird.
- Skalierbarkeit: Cloud-basierte KI-Crawler können Tausende von Seiten parallel verarbeiten – mit integrierter Planung und Automatisierung.
Thunderbit Listing Crawler: Der Schnellstart für deine automatisierte Listing-Extraktion
Ja, ich bin da vielleicht etwas voreingenommen – aber aus gutem Grund. wurde entwickelt, um Listing-Crawling so einfach zu machen wie das Bestellen von Essen. So funktioniert es:
- Installiere die : Die Installation dauert nur zwei Klicks, dann kannst du loslegen.
- Öffne eine Listing-Seite: Egal ob E-Commerce, Immobilien, Verzeichnis – was auch immer du brauchst.
- Klicke auf „KI-Felder vorschlagen“: Thunderbits KI scannt die Seite und schlägt die besten Spalten zur Extraktion vor (z. B. Produktname, Preis, Bild, URL).
- Passe die Spalten an, wenn du möchtest: Felder umbenennen, hinzufügen oder entfernen. Für fortgeschrittene Anforderungen kannst du eigene KI-Prompts für erweitertes Labeling oder Formatieren hinzufügen.
- Klicke auf „Scrape“: Thunderbit zieht alle Daten, verarbeitet die Pagination und kann sogar Unterseiten für zusätzliche Details besuchen.
- Sofort exportieren: Sende deine Daten nach Excel, Google Sheets, Notion oder Airtable – oder lade sie als CSV/JSON herunter, völlig kostenlos.
Thunderbit ist außerdem mit sofort einsatzbereiten Vorlagen für beliebte Websites ausgestattet (Amazon, Zillow, Shopify, Instagram und mehr), sodass du bei häufigen Anwendungsfällen die Einrichtung komplett überspringen kannst. Und wenn du PDFs oder Bilder scrapen musst, kann Thunderbits KI auch das erledigen.
Thunderbit im Vergleich zu anderen Listing-Crawlern: Direkt gegenübergestellt
So schlägt sich Thunderbit im Vergleich zu anderen beliebten Tools:
| Funktion | Thunderbit | Octoparse | Scrapy | Firecrawl | LinkUp |
|---|---|---|---|---|---|
| KI-Feldvorschläge | ✅ | ⚠️ (einfach) | ❌ | ✅ | ✅ |
| No-Code-Einrichtung | ✅ | ⚠️ | ❌ | ⚠️ | ⚠️ |
| Unterseiten-Scraping | ✅ | ⚠️ | ⚠️ | ✅ | ✅ |
| Vorgefertigte Vorlagen | ✅ | ✅ | ❌ | ❌ | ❌ |
| Export nach Sheets/Excel | ✅ | ✅ | ⚠️ | ⚠️ | ⚠️ |
| Kostenloser Datenexport | ✅ | ⚠️ | ✅ | ⚠️ | ⚠️ |
| Geplantes Scraping | ✅ | ✅ | ⚠️ | ✅ | ✅ |
| Erforderlicher Wartungsaufwand | Gering | Mittel | Hoch | Gering | Gering |
| Preis (Einsteiger) | 15 $/Monat | ca. 119 $/Monat | Kostenlos* | Variiert | Variiert |
*Scrapy ist kostenlos, erfordert aber Entwicklerzeit und Infrastruktur.
Thunderbits Stärke? Es ist für nicht-technische Business-Anwender gebaut, die schnell Ergebnisse wollen – keine steile Lernkurve, keine versteckten Exportgebühren und keine Kopfschmerzen, wenn Websites sich ändern.
Schritt-für-Schritt-Anleitung: Thunderbit für automatisierte Listing-Extraktion verwenden
Bereit, es selbst auszuprobieren? So nutzt du Thunderbit als deinen Listing-Crawler:
1. Thunderbit installieren
Gehe zum und füge Thunderbit hinzu. Registriere dich für ein kostenloses Konto (die Gratis-Version erlaubt dir, bis zu 6 Seiten zu scrapen, oder 10 mit einem Test-Boost).
2. Öffne deine Ziel-Listing-Seite
Navigiere zu der Website, die du scrapen möchtest – zum Beispiel eine Produktkategorie auf Amazon, eine Zillow-Suche oder ein Unternehmensverzeichnis. Wende alle Filter an, die du brauchst, direkt in der Oberfläche der Website.
3. Klicke auf „KI-Felder vorschlagen“
Klicke auf das Thunderbit-Symbol in deinem Browser. Wähle „KI-Felder vorschlagen“. Thunderbits KI liest die Seite und schlägt Spalten wie Produktname, Preis, URL, Bild usw. vor.
4. Spalten und Prompts anpassen
Überprüfe die vorgeschlagenen Felder. Benenne Spalten bei Bedarf um, füge welche hinzu oder entferne sie. Für fortgeschrittene Anforderungen kannst du einen Field AI Prompt hinzufügen (zum Beispiel „Preis nur als Zahl extrahieren“ oder „als ‚Luxus‘ markieren, wenn der Preis über 2.000 $ liegt“).
5. Pagination und Unterseiten verarbeiten
Wenn sich dein Listing über mehrere Seiten erstreckt, kann Thunderbit automatisch auf „Weiter“ klicken oder eine Liste von URLs akzeptieren. Für Detailseiten klicke auf „Unterseiten scrapen“, und Thunderbit besucht jeden Link und zieht zusätzliche Informationen heraus (etwa Spezifikationen oder Kontaktdaten).
6. Das Scraping ausführen
Klicke auf „Scrape“. Beobachte, wie Thunderbit deine Daten live in eine Tabelle füllt. Bei großen Aufgaben nutze Cloud Scraping für mehr Geschwindigkeit (bis zu 50 Seiten gleichzeitig).
7. Deine Daten exportieren
Wenn du fertig bist, exportiere direkt nach Excel, Google Sheets, Notion oder Airtable. Thunderbit lädt bei Bedarf sogar Bilder in Notion/Airtable hoch.
Profi-Tipp: Speichere deine Konfiguration als Vorlage für die nächste Verwendung oder plane sie so, dass sie automatisch ausgeführt wird (siehe unten).
Ausgabe anpassen: Filter und Ausgabeformate festlegen
Thunderbit gibt dir volle Kontrolle über deine Ausgabe:
- Bestimmte Felder auswählen: Behalte nur die Spalten, die du wirklich brauchst.
- Filter anwenden: Nutze vor dem Scraping die Filter der Website oder füge Logik in Field AI Prompts ein (z. B. „nur Einträge mit einem Preis unter 500.000 $ extrahieren“).
- Ausgabeformat wählen: Exportiere als Excel, CSV, JSON, Google Sheets, Notion oder Airtable.
- Erweiterte Transformation: Nutze Field AI Prompts für Formatierung, Aufteilen/Verbinden von Feldern, bedingte Extraktion, Kategorisierung oder sogar Übersetzung (Thunderbit unterstützt 34 Sprachen).
Wenn du etwa Einträge je nach Preis als „Günstig“ oder „Luxus“ kennzeichnen willst, füge einfach einen Prompt hinzu: „Als Luxus markieren, wenn der Preis über 2.000 $ liegt, sonst als Günstig.“ Thunderbit erledigt den Rest während des Scraping-Vorgangs.
Business-Upgrade: Automatisierte Listing-Extraktion für einen Wettbewerbsvorteil nutzen
Sobald du strukturierte Listing-Daten hast, sind die Möglichkeiten endlos:
- Wettbewerbsanalyse: Preise, neue Produkte und Bestände der Konkurrenz in Echtzeit verfolgen. Ein Einzelhändler steigerte seinen Umsatz um 4 % durch gescrapte Wettbewerberdaten ().
- Bestandsmanagement: Lieferantenseiten automatisch auf Lageränderungen, Preiserhöhungen oder neue SKUs überwachen.
- Lead-Generierung: Zielgerichtete Listen aus Verzeichnissen, LinkedIn oder Verbandsseiten erstellen und direkt ins CRM übernehmen.
- Marktforschung: Bewertungen, Produktmerkmale oder Immobiliendaten aggregieren, um Trends zu analysieren und klügere Produktentscheidungen zu treffen.
- Content-Aggregation: Vergleichsportale, Review-Aggregatoren oder SEO-Projekte mit immer frischen Daten versorgen.
Integriere deine exportierten Daten mit Analysetools (Tableau, PowerBI, Google Data Studio) für Dashboards, Trendanalysen oder prädiktive Modelle. Mit Thunderbit sammelst du nicht nur Daten – du baust ein Echtzeit-Radar für den Wettbewerb.
Dynamisches Monitoring: Planung und Echtzeit-Listing-Extraktion
Das Web schläft nie, und deine Daten sollten es auch nicht. Thunderbits Geplanter Scraper ermöglicht dir die Automatisierung laufender Überwachung:
- Zeitplan einrichten: Beschreibe ihn einfach in normalem Deutsch („jeden Tag um 7 Uhr“ oder „alle 4 Stunden“). Thunderbits KI übernimmt den Rest.
- URLs eingeben: Eine Seite oder eine ganze Liste scrapen – Thunderbit ruft sie nach Zeitplan ab.
- Nach Sheets/Airtable/Notion exportieren: Halte deine Daten live und morgens direkt für dein Team bereit.
Anwendungsfälle:
- E-Commerce: Preise und Bestände der Konkurrenz täglich verfolgen – und die eigene Preisgestaltung sofort anpassen.
- Vertrieb: Jede Woche eine frische Lead-Liste aus Verzeichnissen oder Jobbörsen erhalten.
- Immobilien: Neue Angebote oder Preisänderungen stündlich überwachen – und als Erster reagieren.
Geplantes Scraping bedeutet, dass du immer mit den neuesten Daten arbeitest – kein Herumstochern im Dunkeln und kein hektisches Aufholen mehr.
Zentrale Erkenntnisse: Deine Datenerfassung mit Listing-Crawlern skalieren
- Strukturierte Webdaten sind für moderne Unternehmen unverzichtbar. Unternehmen, die automatisierte Listing-Crawler nutzen, treffen schneller und intelligenter Entscheidungen und erzielen echten ROI ().
- KI-gestützte Tools wie Thunderbit machen Listing-Crawling für alle zugänglich. Kein Code, keine Vorlagen, keine Wartungsprobleme – nur Ergebnisse.
- Automatisierte Listing-Extraktion verschafft Wettbewerbsvorteile. Von Preisinformationen bis zur Lead-Generierung sind die Daten, die du brauchst, nur wenige Klicks entfernt.
- Kontinuierliches Monitoring ist der neue Standard. Mit geplantem Scraping ist dein Team immer auf dem neuesten Stand – bereit zu reagieren, zu analysieren und zu gewinnen.
- Der Einstieg ist einfach. Thunderbit bietet eine großzügige Gratis-Version und sofortige Exporte – du kannst es also risikofrei in deinem nächsten Datenprojekt ausprobieren.
Bereit, die manuelle Datenerfassung hinter dir zu lassen? und erlebe, wie einfach skalierbare, automatisierte Listing-Extraktion sein kann. Und wenn du tiefer einsteigen willst, schau im vorbei – dort findest du weitere Anleitungen, Tipps und Praxisbeispiele.
FAQs
1. Was ist der Unterschied zwischen einem Listing-Crawler und einem allgemeinen Web-Scraper?
Ein Listing-Crawler ist darauf spezialisiert, strukturierte, sich wiederholende Daten (wie Produkte oder Immobilienanzeigen) von Webseiten zu extrahieren und dabei Pagination und Unterseiten in großem Maßstab zu verarbeiten. Allgemeine Web-Scraper können zwar beliebige Daten extrahieren, erfordern aber oft mehr manuelle Einrichtung und sind nicht für große, strukturierte Listen optimiert.
2. Wie spart Thunderbits KI-gestützter Listing-Crawler im Vergleich zu manuellen Methoden Zeit?
Thunderbits KI erkennt Felder automatisch, verarbeitet Pagination und kann Unterseiten besuchen – so werden aus Stunden manuellen Kopierens und Einfügens Minuten automatisierter Extraktion. Außerdem passt sich das Tool an Website-Änderungen an, sodass du deinen Workflow nicht jedes Mal neu aufbauen musst, wenn eine Seite aktualisiert wird.
3. Kann ich Thunderbit nutzen, um Wettbewerberpreise oder Lagerbestände in Echtzeit zu überwachen?
Absolut. Mit Thunderbits geplantem Scraping kannst du tägliche oder stündliche Überwachung von Wettbewerber-Listings, Preisen oder Beständen einrichten. Die Daten lassen sich direkt in Google Sheets, Airtable oder Notion exportieren – für Live-Dashboards und Benachrichtigungen.
4. Welche Exportformate unterstützt Thunderbit?
Thunderbit ermöglicht den Export nach Excel, CSV, JSON, Google Sheets, Notion und Airtable. Bildfelder werden für eine korrekte Darstellung in Notion/Airtable hochgeladen, und alle Exporte sind kostenlos – sogar in der Gratis-Version.
5. Brauche ich technische Kenntnisse, um Thunderbit für automatisierte Listing-Extraktion zu nutzen?
Nein! Thunderbit ist für Business-Anwender konzipiert – einfach die Erweiterung installieren, auf „KI-Felder vorschlagen“ klicken, und schon kannst du Daten extrahieren. Kein Programmieren, keine Vorlagen und keine Wartung erforderlich.
Willst du Thunderbit in Aktion sehen? oder stöbere in weiteren Anleitungen auf dem . Viel Erfolg beim Crawlen!
Mehr erfahren