
2015 bedeutete Scraping noch, einen Entwickler um ein Python-Skript anzuflehen oder ein Wochenende damit zu verbringen, XPath zu lernen. 2026 tippst du „alle Produktnamen und Preise abrufen“ ein – und eine KI erledigt den Rest.
Dieser Wandel ging schnell. Über setzen inzwischen auf Web-Scraping. Der Markt überschritt und dürfte sich bis 2030 verdoppeln.
Der größte Treiber? KI-Web-Crawler. Sie passen sich an Layout-Änderungen an. Sie verstehen den Seiteninhalt, nicht nur HTML-Tags. Und sie funktionieren für Menschen, die noch nie eine Zeile Code geschrieben haben.
Ich habe monatelang 15 davon getestet. Hier ist, was ich herausgefunden habe – einschließlich, warum Thunderbit (ja, das Unternehmen, das ich mitgegründet habe) den Spitzenplatz belegt hat.
Warum KI das Scraping von Webseiten verändert: Die neue Ära der Web-Scraper-Tools
Seien wir ehrlich: Traditionelles Web-Scraping war nie für den durchschnittlichen Business-User gedacht. Es drehte sich alles um Code, Selektoren und die Hoffnung, dass das Skript nicht beim nächsten Layout-Wechsel einer Website kaputtgeht. Aber KI und LLMs haben das Spiel komplett gedreht.
So funktioniert es:
- Anweisungen in natürlicher Sprache: Statt mit Code zu kämpfen, sagst du der KI einfach, was du willst. Tools wie verstehen deine klaren Anweisungen auf Englisch und richten die Extraktion für dich ein ().
- Adaptive Lernfähigkeit: KI-Scraper können sich an auf Websites anpassen und so den Wartungsaufwand senken.
- Umgang mit dynamischen Inhalten: Moderne Websites lieben JavaScript und Endlos-Scrolling. KI-gestützte Tools interagieren mit diesen Elementen und erfassen Daten, die alte Scraper verpassen würden.
- Strukturierte Ausgabe durch KI-Parsing: LLM-basierte Scraper tatsächlich und geben saubere, strukturierte Daten aus.
- Automatische Umgehung von Bot-Schutz: KI-Scraper können und Proxys/Headless-Browser nutzen, um IP-Sperren zu vermeiden.
- Integrierte Daten-Workflows: Die besten Tools ziehen nicht nur Daten ab – sie liefern sie dorthin, wo du sie brauchst, mit Ein-Klick-Exporten nach Google Sheets, Airtable, Notion und mehr ().
Das Ergebnis? Web-Scraping ist heute ein Point-and-Click-Erlebnis – oder sogar eine chatähnliche Erfahrung – und öffnet nicht nur Entwicklern, sondern auch Sales-, Marketing- und Operations-Teams den direkten Zugang zu Webdaten.
15 KI-Web-Crawler, die 2026 deine Aufmerksamkeit verdienen
Schauen wir uns die Top 15 KI-Web-Crawler an, beginnend mit Thunderbit. Ich gebe dir zu jedem Tool einen Überblick über die Kernfunktionen, die Zielgruppe, die Preise und das, was es besonders macht. Und ja: Ich sage auch ehrlich, wo jedes Tool glänzt – und wo vielleicht nicht.
1. Thunderbit: Der KI-Web-Scraper für alle
Ich bin hier natürlich etwas voreingenommen, aber Thunderbit ist der KI-Web-Scraper, den ich mir vor Jahren gewünscht hätte. Deshalb steht er auf Platz 1 dieser Liste:
- Extraktion in natürlicher Sprache: Du „chattest“ mit Thunderbit. Beschreibe einfach die Daten, die du willst – „scrape alle Produktnamen und Preise von dieser Seite“ – und die KI erledigt den Rest (). Kein Code, keine Selektoren, keine Kopfschmerzen.
- Crawling über Unterseiten und mehrere Ebenen: Thunderbit kann . Zum Beispiel kannst du eine Produktliste scrapen und dann jedes Produkt für Details anklicken – alles in einem Durchlauf.
- Sofort strukturierte Ausgabe: Die KI , schlägt relevante Felder vor, vereinheitlicht Formate und fasst Texte sogar zusammen oder kategorisiert sie.
- Breite Quellenunterstützung: Thunderbit ist nicht nur für HTML gedacht – es kann mit integrierter OCR und Vision-KI auch aus PDFs und Bildern extrahieren ().
- Business-Integrationen: Ein-Klick-Export nach Google Sheets, Airtable, Notion oder Excel (). Plane Scrapes ein und leite Daten direkt in den Workflow deines Teams.
- Vorlagen: Für Seiten wie Amazon, LinkedIn, Zillow usw. bietet Thunderbit für die Datenerfassung mit einem Klick.
- Benutzerfreundlich und zugänglich: Die Oberfläche ist Point-and-Click-basiert und hat einen intuitiven Assistenten. Nutzer berichten, dass sie in wenigen Minuten startklar sind.

Thunderbit wird von vertraut, darunter Teams bei Accenture, Grammarly und Puma. Vertriebsteams nutzen es, um , Makler sammeln Immobilienangebote, und Marketing-Teams beobachten Wettbewerber – alles ohne eine einzige Zeile Code.
Preisgestaltung: Es gibt eine (bis zu 100 Schritte pro Monat), bezahlte Tarife beginnen bei 14,99 $/Monat. Selbst die Pro-Pläne sind für Einzelpersonen und kleine Teams erschwinglich.
Thunderbit ist das Näheste, was ich je daran gesehen habe, „das Web in eine Datenbank zu verwandeln“ – und es ist für alle gebaut, nicht nur für Ingenieure.
2. Crawl4AI
Für wen es ist: Entwickler und technische Teams, die eigene Pipelines bauen.
Crawl4AI ist ein Open-Source-Framework auf Python-Basis, optimiert für Geschwindigkeit und groß angelegtes Crawling, mit . Es ist rasend schnell, unterstützt Headless-Browser für dynamische Inhalte und kann Scraped Daten so strukturieren, dass sie leicht in KI-Workflows einfließen.
- Am besten für: Entwickler, die eine leistungsstarke, anpassbare Crawling-Engine brauchen.
- Preis: Kostenlos (MIT-Lizenz). Du musst es selbst hosten und betreiben.
3. ScrapeGraphAI
Für wen es ist: Entwickler und Analysten, die KI-Agenten oder komplexe Datenpipelines bauen.
ScrapeGraphAI ist eine promptgesteuerte Open-Source-Python-Bibliothek, die Websites mit LLMs in strukturierte Daten-„Graphs“ verwandelt. Du kannst Prompts schreiben wie „Extrahiere alle Produktnamen, Preise und Bewertungen von den ersten 5 Seiten“, und das Tool baut dir einen Scraping-Workflow ().
- Am besten für: technisch versierte Nutzer, die flexibles, promptbasiertes Scraping wollen.
- Preis: Die Open-Source-Bibliothek ist kostenlos; die Cloud-API startet bei 20 $/Monat.
4. Firecrawl
Für wen es ist: Entwickler, die KI-Agenten oder Datenpipelines im großen Stil bauen.
Firecrawl ist eine KI-orientierte Crawling-Plattform und API, die ganze Websites in „LLM-fähige“ Daten verwandelt (). Sie gibt Markdown oder JSON aus, verarbeitet dynamische Inhalte und integriert sich mit Frameworks wie LangChain und LlamaIndex.
- Am besten für: Entwickler, die Live-Webdaten in KI-Modelle einspeisen wollen.
- Preis: Der Open-Source-Kern ist kostenlos; Cloud-Tarife starten bei 19 $/Monat.
5. Browse AI
Für wen es ist: Business-User, Growth Hacker und Analysten.
Browse AI ist eine No-Code-Plattform mit einer . Du „trainierst“ einen Bot, indem du auf die gewünschten Daten klickst, und die KI verallgemeinert das Muster für zukünftige Scrapes. Sie kommt mit Logins, Endlos-Scrollen klar und kann Websites auf Änderungen überwachen.
- Am besten für: nicht-technische Nutzer, die Datenerfassung und Monitoring automatisieren wollen.
- Preis: Kostenloser Plan (50 Credits/Monat); bezahlte Pläne starten bei 19 $/Monat.
6. LLM Scraper
Für wen es ist: Entwickler, die die KI das Parsen übernehmen lassen wollen.
LLM Scraper ist eine Open-Source-JavaScript/TypeScript-Bibliothek, mit der du und ein LLM diese Daten von jeder Webseite extrahieren lassen kannst. Sie basiert auf Playwright, unterstützt mehrere LLM-Anbieter und kann sogar wiederverwendbaren Code generieren.
- Am besten für: Entwickler, die mit LLMs jede Webseite in strukturierte Daten verwandeln wollen.
- Preis: Kostenlos (MIT-Lizenz).
7. Reader (Jina Reader)
Für wen es ist: Entwickler, die LLM-Anwendungen, Chatbots oder Zusammenfassungs-Tools bauen.
Jina Reader ist eine API, die extrahiert und LLM-fähiges Markdown oder JSON zurückgibt. Sie wird von einem eigenen KI-Modell angetrieben und kann sogar Bilder beschriften.
- Am besten für: saubere, lesbare Inhalte für LLMs oder Q&A-Systeme abrufen.
- Preis: Kostenlose API (für die Grundnutzung kein Schlüssel erforderlich).
8. Bright Data
Für wen es ist: Unternehmen und professionelle Nutzer, die Skalierbarkeit, Compliance und Zuverlässigkeit brauchen.
Bright Data ist ein Schwergewicht in der Webdaten-Branche, mit einem riesigen Proxy-Netzwerk und . Es bietet fertige Scraper, eine allgemeine Web Scraper API und „LLM-fähige“ Datenfeeds.
- Am besten für: Organisationen, die verlässliche Webdaten in großem Umfang brauchen.
- Preis: Nutzungsbasiert, Premium. Kostenlose Testphasen verfügbar.
9. Octoparse
Für wen es ist: Nicht-technische bis halbtechnische Nutzer.
Octoparse ist ein etabliertes No-Code-Tool mit einem und KI-gestützter Auto-Erkennung. Es kommt mit Logins, Endlos-Scrollen klar und kann Daten in verschiedenen Formaten exportieren.
- Am besten für: Analysten, Kleinunternehmer oder Forscher.
- Preis: Kostenlose Stufe verfügbar; bezahlte Pläne starten bei 119 $/Monat.
10. Apify
Für wen es ist: Entwickler und Tech-Teams mit Bedarf an maßgeschneidertem Scraping/Automation.
Apify ist eine Cloud-Plattform zum Ausführen von Scraping-Skripten („Actors“) und bietet einen . Sie ist skalierbar, lässt sich mit KI integrieren und unterstützt Proxy-Verwaltung.
- Am besten für: Entwickler, die eigene Skripte in der Cloud ausführen wollen.
- Preis: Kostenlose Stufe; nutzungsbasierte bezahlte Pläne starten bei 49 $/Monat.
11. Zyte (Scrapy Cloud)
Für wen es ist: Entwickler und Unternehmen, die Scraping auf Enterprise-Niveau brauchen.
Zyte ist das Unternehmen hinter Scrapy und bietet eine Cloud-Plattform sowie . Es übernimmt Scheduling, Proxys und große Projekte.
- Am besten für: Dev-Teams mit langfristigen Scraping-Projekten.
- Preis: Von kostenlosen Testphasen bis zu individuellen Enterprise-Tarifen.
12. Webscraper.io
Für wen es ist: Einsteiger, Journalisten und Forscher.
ist eine für die Datenerfassung per Point-and-Click. Sie ist einfach, für die lokale Nutzung kostenlos und bietet einen Cloud-Dienst für größere Aufgaben.
- Am besten für: schnelle, einmalige Scraping-Aufgaben.
- Preis: Kostenlose Erweiterung; Cloud-Tarife starten bei etwa 50 $/Monat.
13. ParseHub
Für wen es ist: Nicht-technische Nutzer, die mehr Leistung als Basistools brauchen.
ParseHub ist eine Desktop-App mit visuellem Workflow für das Scrapen dynamischer Inhalte, einschließlich Karten und Formulare. Projekte können in der Cloud ausgeführt werden, und es gibt eine API.
- Am besten für: Digital Marketer, Analysten und Journalisten.
- Preis: Kostenlose Stufe (200 Seiten pro Lauf); bezahlte Pläne starten bei 189 $/Monat.
14. Diffbot
Für wen es ist: Unternehmen und KI-Firmen, die strukturierte Webdaten im großen Maßstab brauchen.
Diffbot nutzt Computer Vision und NLP, um von jeder Webseite zu extrahieren, und bietet APIs für Artikel, Produkte und einen riesigen Knowledge Graph.
- Am besten für: Market Intelligence, Finance und Trainingsdaten für KI.
- Preis: Premium, ab etwa 299 $/Monat.
15. DataMiner
Für wen es ist: Nicht-technische Nutzer, besonders in Vertrieb, Marketing und Journalismus.
DataMiner ist eine für schnelle Webdaten-Extraktion per Point-and-Click. Sie hat eine Bibliothek mit vorgefertigten „Rezepten“ und kann direkt nach Google Sheets exportieren.
- Am besten für: schnelle Aufgaben wie das Exportieren von Tabellen oder Listen in Tabellenkalkulationen.
- Preis: Kostenlose Stufe (500 Seiten/Tag); Pro startet bei etwa 19 $/Monat.
Die Top-KI-Web-Scraper-Tools im Vergleich: Welches passt zu dir?
Hier ist ein grober Vergleich, der dir bei der Auswahl hilft:
| Tool | KI/LLM-Nutzung | Benutzerfreundlichkeit | Ausgabe/Integration | Ideal für | Preisgestaltung |
|---|---|---|---|---|---|
| Thunderbit | Natürliche Sprachoberfläche; KI schlägt Felder vor | Am einfachsten (No-Code-Chat) | Exporte nach Sheets, Airtable, Notion | Nicht-technische Teams | Kostenlose Stufe; Pro ca. 30 $/Monat |
| Crawl4AI | KI-fähiges Crawling; LLMs integrierbar | Schwer (Python-Code) | Bibliothek/CLI; Integration per Code | Entwickler, die schnelle KI-Datenpipelines brauchen | Kostenlos |
| ScrapeGraphAI | LLM-Prompt-Pipelines fürs Scraping | Mittel (etwas Code oder API) | API/SDK; JSON-Ausgabe | Entwickler/Analysten, die KI-Agenten bauen | Kostenlos OSS; API ab 20 $/Monat |
| Firecrawl | Crawling zu LLM-fähigem Markdown/JSON | Mittel (API/SDK-Nutzung) | SDKs (Py, Node usw.); LangChain-Integration | Entwickler, die Live-Webdaten in KI einspeisen | Kostenlos + bezahlte Cloud |
| Browse AI | KI-gestütztes Point-and-Click | Einfach (No-Code) | Über 7000 App-Integrationen (Zapier) | Nicht-technische Nutzer für Web-Monitoring | Kostenlos 50 Läufe; bezahlt ab 19 $/Monat |
| LLM Scraper | Nutzt LLMs, um Seiten in ein Schema zu parsen | Schwer (TS/JS-Code) | Code-Bibliothek; JSON-Ausgabe | Entwickler, die die Analyse der KI überlassen wollen | Kostenlos (eigene LLM-API nutzen) |
| Reader (Jina) | KI-Modell extrahiert Text/JSON | Einfach (einfacher API-Aufruf) | REST-API gibt Markdown/JSON zurück | Entwickler, die Websuche/Inhalte in LLMs einspeisen | Kostenlose API |
| Bright Data | KI-verbesserte Scraping-APIs; großes Proxy-Netzwerk | Schwer (API, technisch) | APIs/SDKs; Datenströme oder Datensätze | Enterprise-Skalierung | Nutzungsbasiert |
| Octoparse | KI erkennt Listen automatisch | Mittel (No-Code-App) | CSV/Excel, API für Ergebnisse | Halbtechnische Nutzer | Kostenlos eingeschränkt; 59–166 $/Monat |
| Apify | Einige KI-Funktionen (Actors, KI-Tutorials) | Schwer (Code-Skripte) | Umfangreiche API; Integration mit LangChain | Entwickler, die benutzerdefiniertes Scraping in der Cloud brauchen | Kostenlose Stufe; Pay-as-you-go |
| Zyte (Scrapy) | ML-basierte Auto-Extraktion; Scrapy-Framework | Schwer (Python-Code) | API, Scrapy-Cloud-UI; JSON/CSV | Dev-Teams, Langzeitprojekte | Individuelle Preise |
| Webscraper.io | Keine KI (manuelle Vorlagen) | Einfach (Browser-Erweiterung) | CSV-Download, Cloud-API | Einsteiger, schnelle Einmal-Scrapes | Kostenlose Erweiterung; Cloud ca. 50 $/Monat |
| ParseHub | Kein explizites LLM; visueller Builder | Mittel (No-Code-App) | JSON/CSV; API für Cloud-Läufe | Nicht-Entwickler, die komplexe Websites scrapen | Kostenlos 200 Seiten; bezahlt ab 189 $/Monat |
| Diffbot | KI-Vision/NLP für jede Seite; Knowledge Graph | Einfach (nur API-Aufrufe) | APIs (Article/Prod/...) + Knowledge-Graph-Abfrage | Enterprise, strukturierte Webdaten | Ab ca. 299 $/Monat |
| DataMiner | Kein LLM; Community-Rezepte | Am einfachsten (Browser-Oberfläche) | Excel/CSV-Export; Google Sheets | Nicht-technische Nutzer, die in Tabellen exportieren | Kostenlos eingeschränkt; Pro ca. 19 $/Monat |
Tool-Kategorien: Von Entwickler-Schwergewichten bis zu businessfreundlichen Web-Scrapern
Um diese Liste einzuordnen, lassen sich die Tools in ein paar Kategorien aufteilen:
1. Powerhouses für Entwickler und Open Source
- Beispiele: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Stärken: Hohe Flexibilität, Skalierbarkeit und Anpassbarkeit. Ideal für eigene Pipelines oder die Integration mit KI-Modellen.
- Nachteile: Erfordern Programmierkenntnisse und mehr Konfiguration.
- Anwendungsfälle: Eine eigene Datenpipeline bauen, komplexe Websites scrapen oder in interne Systeme integrieren.
2. KI-integrierte Scraping-Agenten
- Beispiele: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Stärken: Überbrücken die Lücke zwischen Scraping und Datenverständnis. Natürliche Sprachoberflächen machen sie zugänglich.
- Nachteile: Einige entwickeln sich noch weiter; möglicherweise fehlt feingranulare Kontrolle.
- Anwendungsfälle: Schnelle Antworten oder Datensätze, autonome Agenten bauen oder Live-Daten an LLMs liefern.
3. No-Code-/Low-Code-Scraper für Business-Teams
- Beispiele: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Stärken: Benutzerfreundlich, kaum oder kein Coding nötig, gut für regelmäßige Business-Aufgaben.
- Nachteile: Können bei sehr komplexen Websites oder extremem Umfang an Grenzen stoßen.
- Anwendungsfälle: Lead-Generierung, Wettbewerbsbeobachtung, Rechercheprojekte und einmalige Datenabzüge.
4. Enterprise-Datenplattformen und Services
- Beispiele: Bright Data, Diffbot, Zyte
- Stärken: Komplettlösungen, Managed Services, Compliance und Zuverlässigkeit im großen Maßstab.
- Nachteile: Höhere Kosten, mehr Onboarding erforderlich.
- Anwendungsfälle: Dauerhafte Datenpipelines in großem Umfang, Market Intelligence und Trainingsdaten für KI.
So wählst du den richtigen KI-Web-Crawler für dein Web-Scraping aus
Das richtige Tool auszuwählen kann überwältigend wirken, deshalb hier mein Schritt-für-Schritt-Leitfaden:
- Ziele und Datenanforderungen klar definieren: Welche Websites und Daten brauchst du? Wie oft? Wie viel? Was willst du damit machen?
- Technische Fähigkeiten einschätzen: Kein Coding? Versuch es mit Thunderbit, Browse AI oder Octoparse. Etwas Scripting? LLM Scraper oder DataMiner. Starke Dev-Skills? Crawl4AI, Apify oder Zyte.
- Frequenz und Umfang berücksichtigen: Einmalig? Nutze kostenlose Tools. Wiederkehrend? Achte auf Scheduling-Funktionen. Groß angelegt? Enterprise-Tools oder Open Source in Skalierung.
- Budget und Preismodell: Kostenlose Pläne eignen sich gut zum Testen. Abo oder nutzungsbasiert hängt von deinen Anforderungen ab.
- Test und Proof of Concept: Teste ein paar Tools mit deinen echten Daten. Die meisten haben kostenlose Stufen.
- Wartung und Support: Wer behebt Probleme, wenn sich eine Website ändert? No-Code-Tools mit KI können kleinere Änderungen automatisch anpassen; bei Open Source bist du oder die Community gefragt.
- Tools nach Szenarien zuordnen: Vertriebsteam scrapt Leads? Thunderbit oder Browse AI. Forscher sammelt Tweets? DataMiner oder . KI-Modell braucht Nachrichtenartikel? Jina Reader oder Zyte. Du baust eine Vergleichsseite? Apify oder Zyte.
- Einen Backup-Plan haben: Manchmal funktioniert ein Tool für eine bestimmte Website nicht. Dann brauchst du eine Alternative.
Das „richtige“ Tool ist das, mit dem du die benötigten Daten mit möglichst wenig Reibung und innerhalb deines Budgets bekommst. Manchmal ist es eine Kombination.
Thunderbit vs. traditionelle Web-Scraper-Tools: Was macht es besonders?
Schauen wir uns genauer an, warum Thunderbit anders ist:
- Oberfläche in natürlicher Sprache: Kein Code, kein Point-and-Click-Akrobatik. Beschreib einfach, was du willst ().
- Null Konfiguration & Vorlagenvorschläge: Thunderbit erkennt Pagination und Unterseiten automatisch und schlägt sogar Vorlagen für gängige Websites vor ().
- KI-gestützte Datenbereinigung und Anreicherung: Zusammenfassen, kategorisieren, übersetzen und Daten anreichern, während du scrapest ().
- Weniger Wartungsaufwand: Thunderbits KI ist robust gegenüber kleineren Website-Änderungen, wodurch weniger Brüche entstehen.
- Integration mit Business-Tools: Direktexport nach Google Sheets, Airtable, Notion – kein CSV-Gefummel mehr ().
- Schneller Mehrwert: Von der Idee zu den Daten in Minuten statt Tagen.
- Lernkurve: Wenn du im Web navigieren und beschreiben kannst, was du brauchst, kannst du Thunderbit nutzen.
- Anpassungsfähigkeit: Websites, PDFs, Bilder und mehr scrapen – alles mit demselben Tool.
Thunderbit ist nicht nur ein Scraper – es ist ein Datenassistent, der sich in deinen Workflow einfügt, egal ob du im Vertrieb, Marketing, E-Commerce oder Immobilienbereich arbeitest.
Best Practices für Web-Scraping mit KI-Web-Scraper-Tools
Damit du das Beste aus KI-Web-Scrapern herausholst, hier meine wichtigsten Tipps:
- Datenanforderungen klar definieren: Weißt genau, welche Felder du willst, wie viele Seiten und welches Format du brauchst.
- KI-Vorschläge nutzen: Nutze die Felderkennung und KI-Vorschläge der Tools, um wichtige Daten zu erfassen, die du sonst vielleicht übersiehst ().
- Klein anfangen und validieren: Teste mit einer kleinen Stichprobe, prüfe die Ausgabe und passe bei Bedarf an.
- Dynamische Inhalte behandeln: Stelle sicher, dass dein Tool dynamische Inhalte und Interaktionen unterstützt (Pagination, Endlos-Scrollen usw.).
- Website-Richtlinien respektieren: Prüfe robots.txt, vermeide das Scrapen sensibler Daten und halte dich an Rate Limits.
- Für Automatisierung integrieren: Nutze Exportfunktionen und Webhooks, um gescrapte Daten direkt in deinen Workflow einzuspeisen.
- Datenqualität sichern: Prüfe die Daten auf Plausibilität, nutze Nachbearbeitung und überwache Fehler.
- Prompts knapp halten: Bei KI-gestützten Tools liefern klare und spezifische Anweisungen bessere Ergebnisse.
- Von der Community lernen: Tritt Foren und Communities bei, um Tipps und Hilfe bei Problemen zu bekommen.
- Aktuell bleiben: KI-Tools entwickeln sich schnell – behalte neue Funktionen und Verbesserungen im Blick.
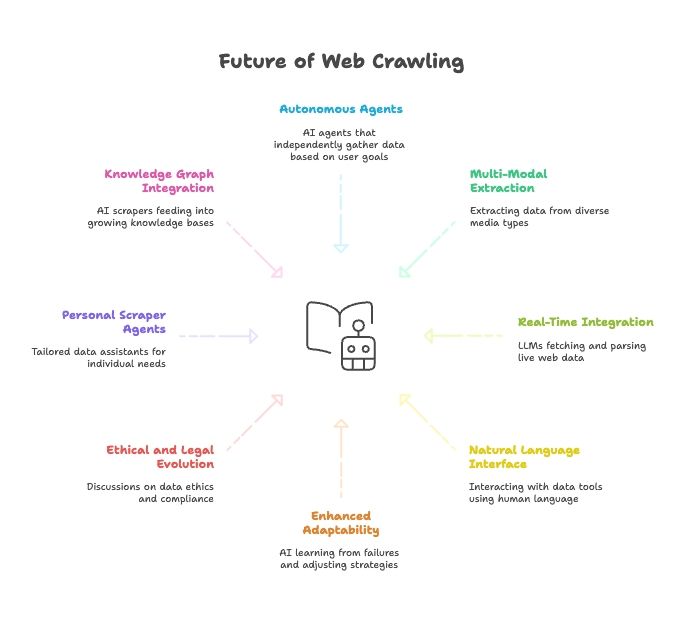
Die Zukunft des Web-Scrapings: KI, LLMs und der Aufstieg von Web-Scraper-Agenten in natürlicher Sprache
Wenn wir nach vorn schauen, beschleunigt sich das Zusammenwachsen von KI und Web-Scraping nur weiter:
- Vollständig autonome Scraper-Agenten: Bald sagst du einfach einem KI-Agenten dein Ziel, und er findet selbst heraus, wie er an die Daten kommt.
- Multimodale Datenerfassung: Scraper ziehen Daten aus Text, Bildern, PDFs und sogar Videos.
- Echtzeit-Integration mit KI-Modellen: LLMs werden eingebaute Module haben, um Live-Webdaten abzurufen und zu parsen.
- Alles in natürlicher Sprache: Wir werden mit unseren Datentools sprechen wie mit Menschen – und so Datenerfassung und Transformation für alle zugänglich machen.
- Mehr Anpassungsfähigkeit: KI-Scraper lernen aus Fehlern und passen Strategien automatisch an.
- Ethische und rechtliche Weiterentwicklung: Es wird noch mehr über Datenethik, Compliance und Fair Use gesprochen werden.
- Persönliche Scraper-Agenten: Stell dir einen persönlichen Datenassistenten vor, der Nachrichten, Stellenanzeigen und mehr passend zu deinen Bedürfnissen sammelt.
- Integration mit Knowledge Graphs: KI-Scraper speisen kontinuierlich wachsende Wissensbasen und machen KI dadurch intelligenter.
Unterm Strich? Die Zukunft des Web-Scrapings ist untrennbar mit der Zukunft der KI verbunden. Die Tools werden jeden Tag intelligenter, autonomer und zugänglicher.
Fazit: Geschäftswert freisetzen mit dem richtigen KI-Web-Crawler
Web-Scraping hat sich dank KI von einer Nischen- und Technikfähigkeit zu einer zentralen Geschäftskompetenz entwickelt. Die 15 Tools, die ich hier vorgestellt habe, zeigen das Beste, was 2026 möglich ist – von Entwickler-Schwergewichten bis zu businessfreundlichen Assistenten.
Das eigentliche Geheimnis? Die Wahl des richtigen Tools kann den Wert, den du aus Webdaten ziehst, dramatisch erhöhen. Für nicht-technische Teams ist Thunderbit der einfachste Weg, das Web in eine strukturierte, analysefähige Datenbank zu verwandeln – kein Code, kein Stress, einfach Ergebnisse.
Egal also, ob du Leads sammelst, Wettbewerber beobachtest oder dein nächstes KI-Modell fütterst: Nimm dir die Zeit, deine Anforderungen zu prüfen, probiere ein paar Tools aus und finde heraus, was für dich funktioniert. Und wenn du die Zukunft des Web-Scrapings schon heute erleben willst, . Die Einblicke, die du brauchst, sind nur einen Prompt entfernt.
Neugierig auf mehr? Schau im vorbei für Deep Dives, Tutorials und das Neueste rund um KI-gestützte Datenerfassung.
Weiterführende Lektüre:
FAQs
1. Was ist ein KI-Web-Crawler und wie unterscheidet er sich von traditionellen Web-Scrapern?
Ein KI-Web-Crawler nutzt natürliche Sprachverarbeitung und maschinelles Lernen, um Webdaten zu verstehen, zu extrahieren und zu strukturieren. Im Gegensatz zu traditionellen Scrapern, die manuelles Coding und XPath-Selektoren erfordern, können KI-Tools dynamische Inhalte verarbeiten, sich an Layout-Änderungen anpassen und Nutzeranweisungen in einfachem Englisch interpretieren.
2. Wer sollte KI-Web-Scraping-Tools wie Thunderbit nutzen?
Thunderbit ist für nicht-technische und technische Nutzer gleichermaßen gebaut. Es ist ideal für Fachleute aus Vertrieb, Marketing, Operations, Research und E-Commerce, die strukturierte Daten aus Websites, PDFs oder Bildern extrahieren möchten – ohne Code zu schreiben.
3. Welche Funktionen machen Thunderbit im Vergleich zu anderen KI-Web-Crawlern besonders?
Thunderbit bietet eine Oberfläche in natürlicher Sprache, mehrstufiges Crawling, automatische Datenstrukturierung, OCR-Unterstützung und reibungslose Exporte zu Plattformen wie Google Sheets und Airtable. Außerdem gibt es KI-gestützte Feldvorschläge und vorgefertigte Vorlagen für beliebte Websites.
4. Gibt es 2026 kostenlose Optionen für KI-Web-Scraping?
Ja. Viele Tools wie Thunderbit, Browse AI und DataMiner bieten kostenlose Pläne mit begrenzter Nutzung. Für Entwickler bieten Open-Source-Optionen wie Crawl4AI und ScrapeGraphAI den vollen Funktionsumfang ohne Kosten, erfordern aber technische Einrichtung.
5. Wie wähle ich den richtigen KI-Web-Crawler für meine Anforderungen aus?
Beginne damit, deine Datenziele, technischen Fähigkeiten, dein Budget und deinen Skalierungsbedarf zu bestimmen. Wenn du eine No-Code-Lösung suchst, die einfach zu bedienen ist, sind Thunderbit oder Browse AI gute Optionen. Für groß angelegte oder individuelle Anforderungen eignen sich Tools wie Apify oder Bright Data besser.