
Letzte Woche habe ich 40 Minuten damit verbracht, ein eigentlich sauberes Python-Skript zu debuggen, das auf drei Testseiten einwandfrei lief – nur um dann festzustellen, dass die vierte Seite hinter Cloudflare lag. Der Scraper hing ewig auf einer Seite mit „Checking your browser…“ fest und lieferte nur Challenge-HTML zurück. Kommt dir das bekannt vor?
Wenn du schon einmal genau an diesem Punkt festgesteckt hast, bist du nicht allein. nutzen inzwischen Cloudflare, darunter im Internet. Damit ist Cloudflare die häufigste Hürde für alle, die Webdaten sammeln wollen – egal ob für Lead-Generierung, Preisüberwachung, Immobilienrecherche oder Wettbewerbsanalysen.
Das Problem: Die meisten Anleitungen werfen einfach jede Umgehungsmethode in eine lose Liste, ohne zu erklären, womit du in deiner Situation zuerst anfangen solltest. Dieser Leitfaden geht anders vor: mit einer priorisierten Entscheidungsstruktur, ehrlichen Einschätzungen zur Zuverlässigkeit und einem No-Code-Pfad, den die meisten Artikel komplett übersehen.
- Schwierigkeit: Einsteiger bis Fortgeschrittene (je nach Methode)
- Benötigte Zeit: ca. 10–30 Minuten für den No-Code-Pfad; bei Code-Methoden unterschiedlich
- Was du brauchst: Chrome-Browser (für den No-Code-Pfad), optional Python 3.9+ (für Code-Methoden) und eine Ziel-URL
Was ist Cloudflare-Schutz überhaupt – und warum blockiert er deinen Scraper?
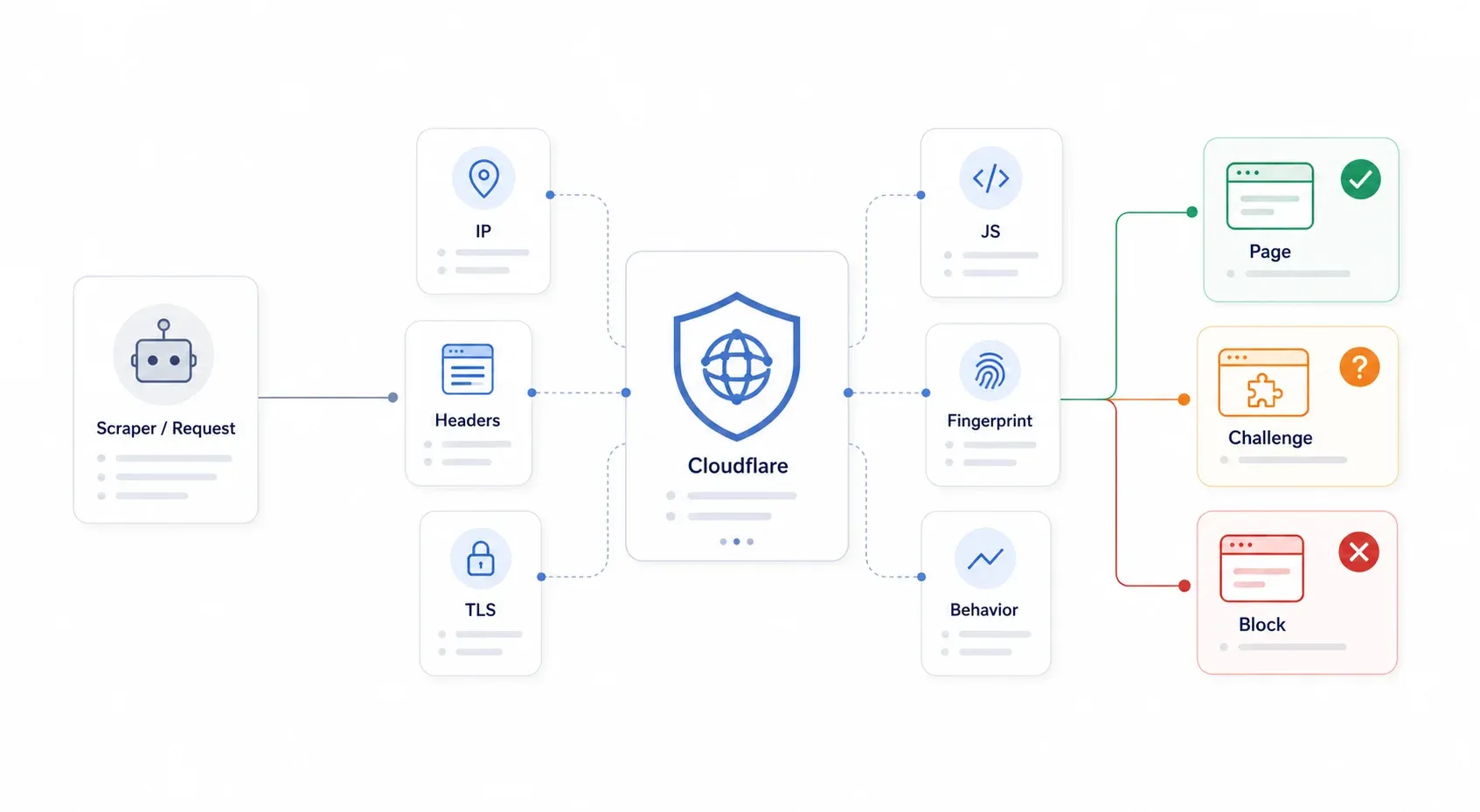
Cloudflare ist ein Reverse Proxy, der zwischen Besuchern und dem Origin-Server der Website sitzt. Jede Anfrage läuft zuerst über Cloudflare, und Cloudflare entscheidet dann, ob die Seite ausgeliefert, ein Challenge-Schritt angezeigt oder direkt blockiert wird. Wichtig ist: Cloudflare muss nicht wissen, dass dein Scraper bösartig ist. Es reicht, wenn deine Anfrage als ausreichend automatisiert oder verdächtig eingestuft wird.
Das von Cloudflare arbeitet mehrschichtig – also nicht mit einem einzigen Schloss, sondern eher wie an einer ganzen Sicherheitskontrolle. Geprüft werden IP-Reputation, HTTP-Header, TLS-Fingerprints, JavaScript-Ausführung, Browser-Fingerprinting und Verhaltensmuster. Wenn deine Python-requests-Bibliothek per GET eine Cloudflare-geschützte Seite anfragt, scheitert sie an mehreren Ebenen auf einmal: falscher TLS-Handshake, keine JavaScript-Ausführung, keine Cookies, kein Browser-Fingerprint. Deshalb funktioniert simples Header-Spoofing schon seit Jahren nicht mehr.
Typische Symptome sind: 403 Forbidden, 503 mit „Checking your browser…“, 1020 Access Denied, endlose Challenge-Schleifen, Turnstile-Widgets, die nie aufgelöst werden, und HTML-Challenge-Seiten dort, wo du eigentlich JSON erwartet hättest.
Passive Erkennung: Was Cloudflare prüft, bevor die Seite überhaupt lädt
Noch bevor du die Seite siehst, hat die passive Schutzschicht von Cloudflare deine Anfrage bereits bewertet:
- IP-Reputation: Rechenzentrums-IPs, Cloud-Hosts und bekannte Proxy-Ausgänge werden markiert. Residential- und Mobilfunk-IPs sind . Erfahrungsberichte aus 2026 zeigen durchgehend: Lokales Browsing über eine Residential-Umgebung funktioniert, während Docker- oder VPS-Setups blockiert werden.
- HTTP-Header-Analyse: Cloudflare vergleicht User-Agent, Accept-Language, Header-Reihenfolge und HTTP-Version. Ein Widerspruch – etwa Chrome 136 vorzugeben, während der TLS-Handshake eindeutig nach „Python“ aussieht – ist ein sofortiger Verräter.
- TLS-Fingerprinting (JA3/JA4): Beim TLS-Handshake offenbart dein Client Muster aus unterstützten Cipher Suites, Erweiterungen und Protokollpräferenzen. verdichtet das zu einer Kennung. Echtes Chrome und ein Python-
requests-Skript hinterlassen sehr unterschiedliche „Formen“. - HTTP/2-Fingerprinting: Browser und HTTP-Libraries unterscheiden sich bei HTTP/2-SETTINGS-Frames, der Reihenfolge von Pseudo-Headern und dem Priorisierungsverhalten. Cloudflares gehen über die Identität einzelner Requests hinaus und verfolgen Muster über mehrere Anfragen hinweg.
- AI Labyrinth: Das ist Cloudflares neuere Falle. Statt verdächtige Crawler direkt zu blockieren, um, die plausibel aussehen, aber Crawler-Ressourcen verschwenden. Dein Scraper merkt womöglich nicht einmal, dass er hineingetappt ist.
Aktive Erkennung: Challenges, die im Browser laufen
Wenn passive Checks nicht eindeutig sind, schaltet Cloudflare auf aktive Herausforderungen um:
- JavaScript-Challenges: Die klassische „Checking your browser…“-Zwischenseite. Cloudflares führen unsichtbare Skripte aus, um automatisierte Anfragen zu erkennen.
- Turnstile: Cloudflares CAPTCHA-Alternative. Zu den gehören Managed, Non-Interactive und Invisible. Dabei werden Mausbewegungen, Browser-Umgebung, TLS-Fingerprint und mehr ausgewertet – ohne dass zwingend ein sichtbares Rätsel erscheint.
- Canvas- und WebGL-Fingerprinting: Diese Prüfungen entlarven Headless-Browser, deren Rendering sich von echten Browsern unterscheidet.
- Verhaltenssignale: Anfrage-Timing, Scroll-Muster, Klickfolgen. Ein Scraper, der 50 Seiten in 3 Sekunden ohne Mausbewegung abruft, wirkt eben nicht wie ein Mensch.
Die praktische Konsequenz: Wenn Cloudflare auf eine aktive Challenge hochgestuft hat, schaffen reine HTTP-Clients wie requests, httpx oder selbst curl_cffi das nicht mehr. Dann brauchst du eine echte Browser-Umgebung.
Cloudflare-Schutzstufen: Warum dasselbe Skript auf einer Seite klappt und auf der anderen scheitert
Genau das übersehen die meisten Umgehungs-Guides komplett. Cloudflares Schutz ist nicht überall gleich. Eine Website auf dem kostenlosen Plan mit „Security Level: Medium“ ist eine ganz andere Aufgabe als eine Enterprise-Seite mit Bot Management und aktiviertem Turnstile. Dasselbe Skript, das auf der einen Seite problemlos durchläuft, prallt auf der anderen gegen eine Wand.
| Cloudflare-Stufe | Typische Schutzmechanismen | Schwierigkeitsgrad der Umgehung | Was meist funktioniert |
|---|---|---|---|
| Free-Plan (niedrige Sicherheit) | Bot Fight Mode, einfache WAF-Regeln, IP-Reputation | ⭐ Niedrig | Interne API finden, curl_cffi mit korrekten Headern, echte Browser-Session |
| Pro-Plan (mittel) | Super Bot Fight Mode, Managed Challenge, JavaScript-Erkennung | ⭐⭐ Mittel | Echte Browser-Session, Stealth-Browser-Automatisierung, Residential Proxies |
| Business | Stärkere WAF, Bot Analytics, strengere Challenges auf kritischen Pfaden | ⭐⭐⭐ Mittel–hoch | Extraktion über Browser-Session, Session-Persistenz, Residential-/Mobile-Proxies, kostenpflichtige Scraping-APIs |
| Enterprise / Bot Management | Bot Scores, JA3/JA4-Felder, Regeln pro Endpunkt, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Hoch | Interne API (wenn verfügbar), Tools für echte Nutzer-Sessions, Scraping-APIs auf Provider-Niveau |
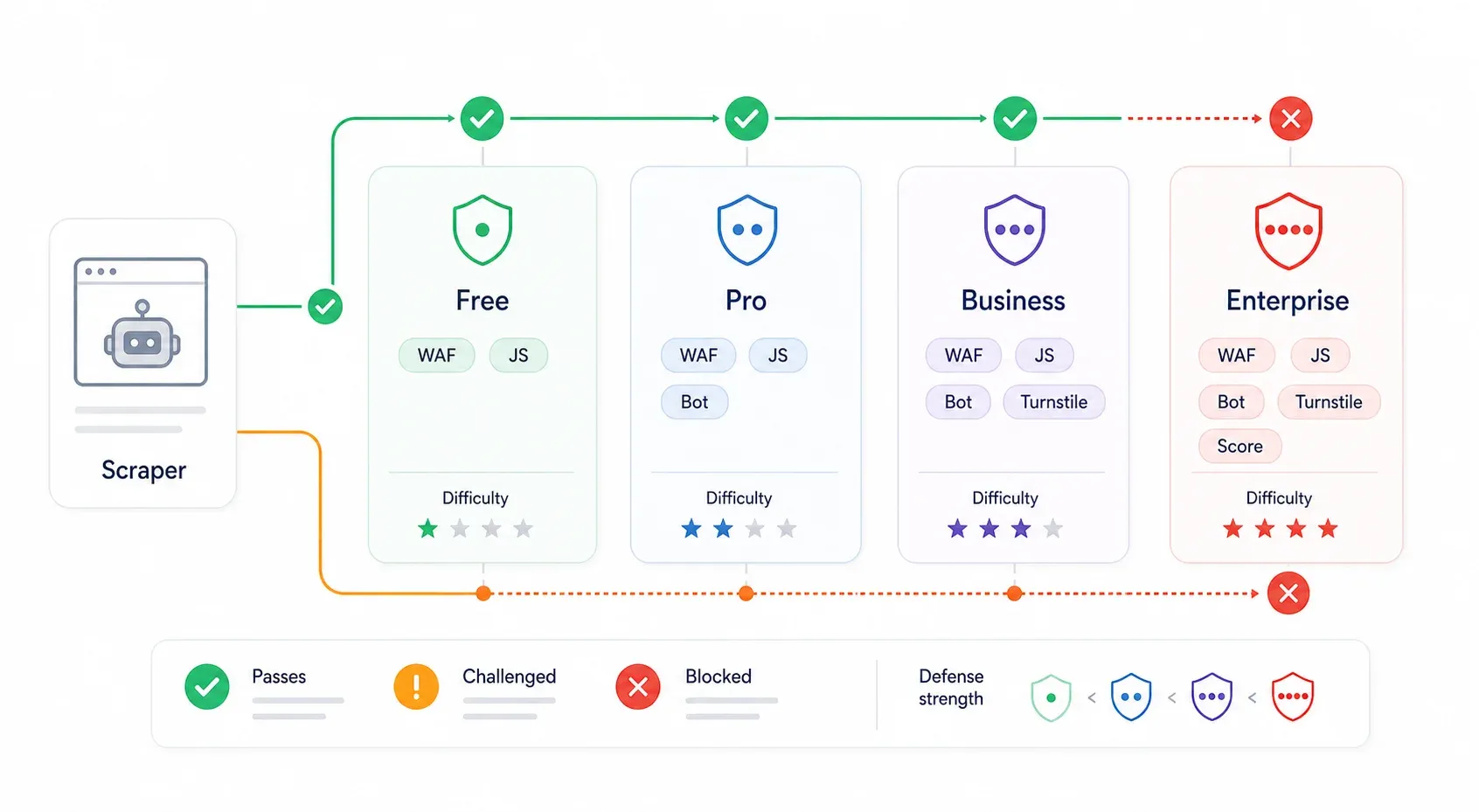
Auf der steht Free bei 0 $, Pro bei 20 $/Monat, Business bei 200 $/Monat und Enterprise mit individueller Preisgestaltung. ist der einfache Schalter im Free-Plan; bringt zusätzliche Kontrollen für Pro/Business; Enterprise Bot Management ergänzt fein granulierte Bot Scores und Regeln pro Endpunkt.
So erkennst du grob die Stufe, mit der du es zu tun hast: Ein 403 mit Cloudflare-Branding und ohne Challenge-Skript deutet oft auf WAF- oder Fingerprint-Ablehnung hin. Ein cf-turnstile-Div oder das Skript challenges.cloudflare.com/turnstile/v0/api.js spricht für Turnstile. Eine „Checking your browser“-Zwischenseite weist auf eine Managed Challenge hin. Pfadspezifische Fehler nach erfolgreich geladener Startseite deuten häufig auf WAF- oder Bot-Management-Regeln für bestimmte Endpunkte hin.
Bestimme die Schutzstufe bevor du deine Methode auswählst. Das spart Stunden an Debugging.
Die Entscheidungsstruktur „Das zuerst probieren“ für Cloudflare-Umgehung
Statt wahllos Methoden auszuprobieren, geh strukturiert vor. Starte mit der einfachsten und zuverlässigsten Option und eskaliere nur bei Bedarf:
| Schritt | Das zuerst probieren | Warum | Wenn es scheitert → |
|---|---|---|---|
| 1 | Nach einer internen/nicht dokumentierten API suchen | Umgeht Cloudflare vollständig; am schnellsten und zuverlässigsten | Schritt 2 |
| 2 | No-Code-Tool mit eingebautem Browser-Rendering nutzen (z. B. Thunderbit) | Keine Einrichtung, verarbeitet JavaScript-Challenges automatisch | Schritt 3 |
| 3 | TLS-Fingerprint-Imitation (curl_cffi) | Schnell, leichtgewichtig, kein Browser nötig | Schritt 4 |
| 4 | Stealth-Browser-Automatisierung (SeleniumBase UC / Puppeteer stealth) | Beherrscht JavaScript-Challenges und Fingerprinting | Schritt 5 |
| 5 | FlareSolverr + Docker | Open Source, gut auf Servern einsetzbar | Schritt 6 |
| 6 | Kostenpflichtige Scraping-API (ScrapingBee, ZenRows, Scrapfly usw.) | Lagert das Wettrüsten vollständig aus | — |
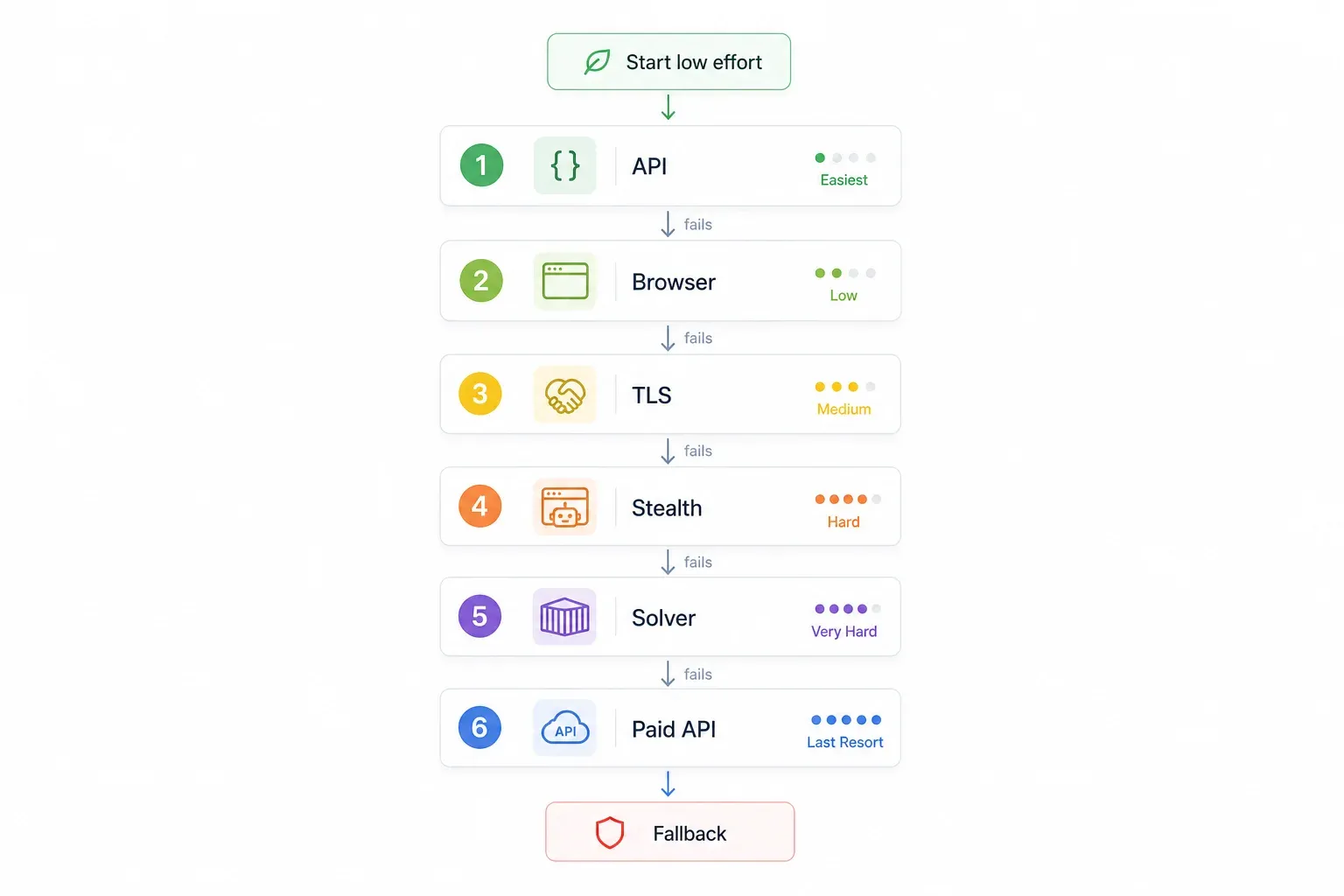
Die Logik ist einfach: erst kostenlos und mit wenig Aufwand, Code-lastiges und kostenpflichtiges ganz zum Schluss. Springe direkt zu dem Schritt, der zu deiner Situation passt.
Ein behauptete, dass curl_cffi 16 von 20 getesteten Domains passierte (80 %), FlareSolverr etwa 55–70 % abdeckte und kostenpflichtige Proxy-Aggregatoren im Schnitt rund 97 % Erfolg erreichten – derselbe Thread warnt aber auch, dass diese Werte mit Cloudflare-Updates schwanken. Behandle Erfolgsquoten daher als Richtwerte, nicht als Garantie.
Schritt 1: Den Kampf umgehen – die interne API hinter Cloudflare finden
Vier verschiedene Foren-Threads, auf die ich gestoßen bin, empfehlen, die interne API der Website zu finden, statt Cloudflare frontal anzugreifen. Und ehrlich gesagt: Das ist der klügste erste Schritt. Wenn die Seite eine interne API hat, umgehst du Cloudflare komplett – keine Tricks, kein Fingerprint-Spoofing, keine Stealth-Plugins.
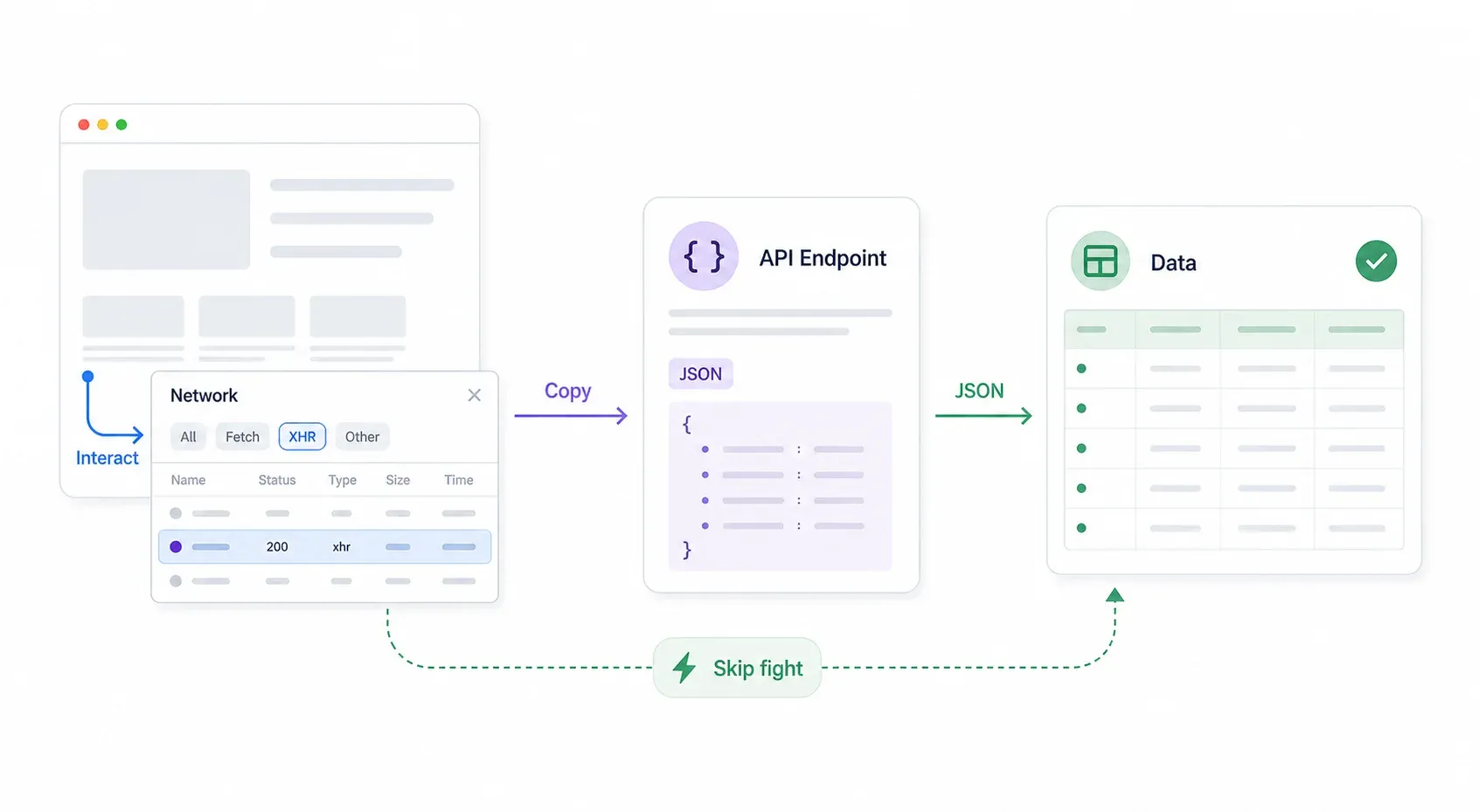
So gehst du systematisch vor:
- Chrome DevTools öffnen → zum Reiter Network wechseln → nach XHR/Fetch filtern.
- Mit der Seite interagieren: suchen, filtern, blättern, scrollen. Achte darauf, ob im Network-Tab JSON-Antworten auftauchen.
- Request-URL und Header prüfen. Oft ist der API-Endpunkt gar nicht oder deutlich schwächer durch Cloudflare geschützt als die Frontend-Seite.
- Rechtsklick auf den Request → Copy → Copy as cURL. Füge ihn in dein Terminal oder in Postman ein und teste ihn.
- Die Anfrage in Python nachbauen (mit
requestsodercurl_cffi) – mit denselben Headern, Cookies und Query-Parametern.
Wenn die API strukturiertes JSON zurückgibt, brauchst du möglicherweise gar keinen klassischen Scraper. Ein beschrieb genau so einen Fall: Ein Nutzer war trotz curl_cffi an Cloudflare gescheitert und stellte fest, dass nur das direkte Abgreifen der API-Antwort funktionierte.
Praxis-Tipp: Wenn der kopierte cURL-Befehl funktioniert, kannst du nach und nach unnötige Header entfernen. Header wie sec-ch-ua, Cookies, CSRF-Tokens und referer können nötig sein; Browser-Cache-Control meist nicht. Achte darauf, dass der TLS-Fingerprint zum User-Agent passt, wenn du vom Browser-cURL in Code wechselst.
Einschränkungen: Nicht jede Website hat eine zugängliche API. Manche APIs verlangen Authentifizierung, CSRF-Tokens, signierte Parameter oder sessiongebundene Cookies. Aber wenn es funktioniert, ist das die Methode mit ungefähr 99 % Erfolgsquote und praktisch ohne Wartung.
Schritt 2: Der No-Code-Pfad – Cloudflare mit einer Browser-Erweiterung umgehen (Thunderbit)
Die meisten anderen Leitfäden setzen voraus, dass man Python oder JavaScript schreibt. Aber dieses Keyword zieht auch Vertriebsteams an, die Lead-Listen bauen, E-Commerce-Teams, die Konkurrenzpreise überwachen, und Immobilienanalysten, die Objektdaten ziehen. Diese Nutzer möchten keine Docker-Container aufsetzen.
Eine Chrome-Erweiterung wie kommt Cloudflare-Prüfungen oft sehr natürlich durch, weil sie in deiner echten Browser-Session läuft. Sie nutzt den echten Chrome-TLS-Fingerprint, deine Cookies, deinen Login-Status und deine Verhaltenssignale – genau das, was Cloudflare vertraut. Keine Stealth-Plugins, kein xvfb-run, keine Terminal-Befehle.
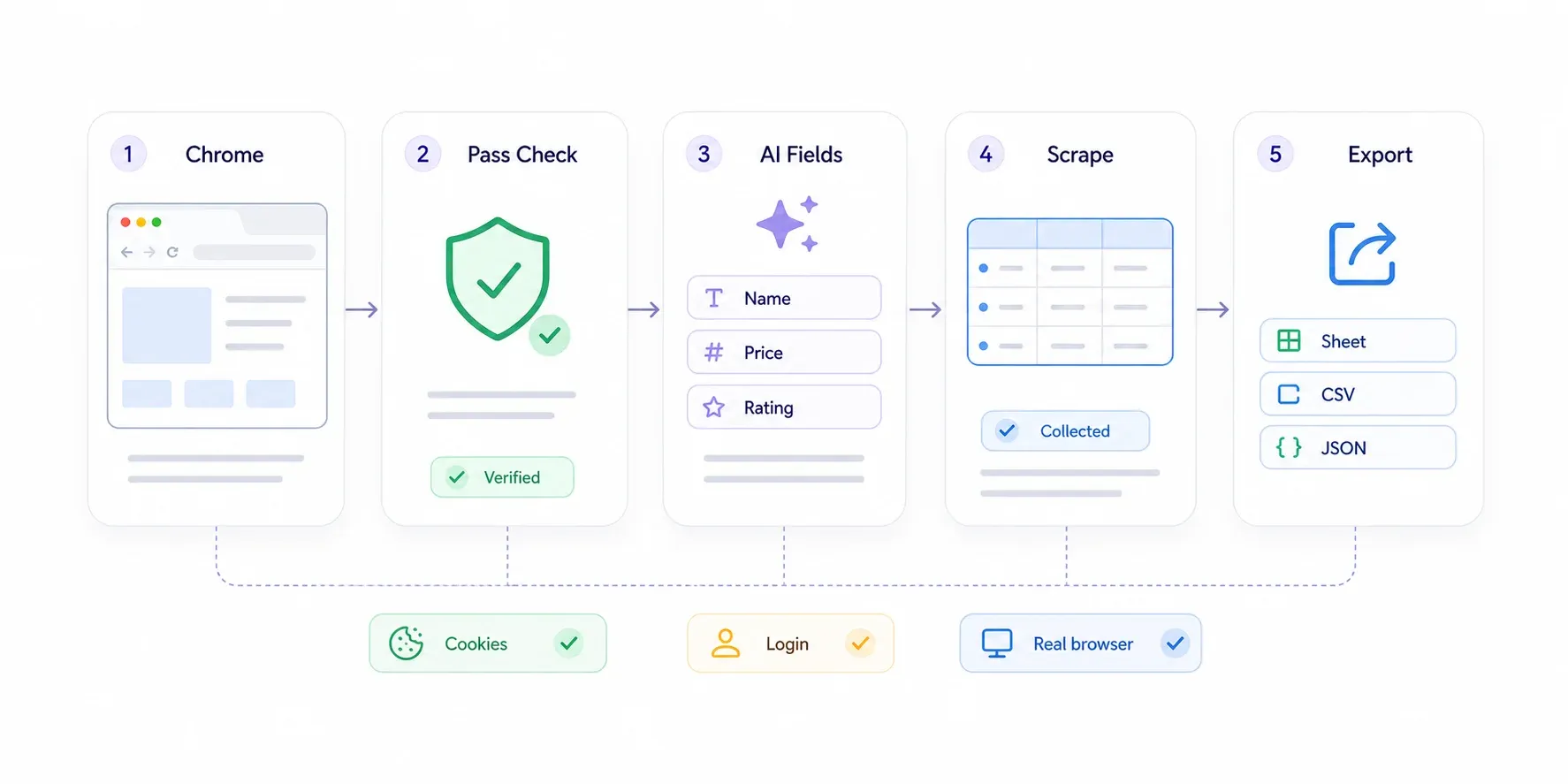
Schritt-für-Schritt-Anleitung
- Installiere die aus dem Chrome Web Store.
- Öffne die durch Cloudflare geschützte Seite in Chrome. Wenn Cloudflare dich mit einer Challenge begrüßt, löse sie wie ein normaler Nutzer: Turnstile anklicken, warten, bis die „Checking your browser“-Seite verschwindet. Du bist ein echter Mensch im echten Browser – Cloudflare lässt dich durch.
- Klicke in der Thunderbit-Seitenleiste auf „AI Suggest Fields“. Die KI analysiert die Seite und schlägt Datenfelder vor, etwa „Produktname“, „Preis“, „Bewertung“ oder was auch immer relevant ist.
- Prüfe die vorgeschlagenen Felder. Entferne alles, was du nicht brauchst, und füge eigene Felder hinzu, indem du in normalem Englisch beschreibst, was du möchtest.
- Klicke auf „Scrape“. Thunderbit extrahiert die Daten von der sichtbaren Seite.
- Exportiere nach Google Sheets, Excel, Airtable, Notion, CSV oder JSON.
Bei Seiten mit Paginierung verarbeitet Thunderbit sowohl klickbasierte Pagination als auch unendliches Scrollen. Für Detailseiten – also wenn du eine Liste von Produktlinks hast und aus jeder einzelnen Seite Spezifikationen ziehen willst – nutze : Thunderbit besucht jede verlinkte Detailseite und reichert deine Tabelle an.
Aus meiner Erfahrung dauert dieser Workflow vom Installieren bis zur exportierten Tabelle bei einem typischen Datensatz mit 50–100 Zeilen etwa 5–10 Minuten.
Wann browserbasiertes Scraping am besten funktioniert – und wann nicht
Ich möchte die Grenzen ehrlich benennen. Browserbasiertes Scraping ist an die Geschwindigkeit deiner Sitzung gebunden. Ideal ist es für mittelgroße Aufgaben – von Hunderten bis niedrigen Tausenden Seiten. Wenn du Millionen von Seiten nach Zeitplan crawlen musst, sind Code- oder API-Methoden besser geeignet.
Die Cloud-Scraping-Option von Thunderbit kann die Geschwindigkeit erhöhen, indem sie auf öffentlich zugänglichen Seiten bis zu 50 Seiten gleichzeitig verarbeitet. Und für Entwickler-Workflows oder größere Umfänge übernimmt Thunderbits JavaScript-Rendering, Anti-Bot-Schutz und Proxy-Rotation mit Batch-Verarbeitung von bis zu .
Für Business-Nutzer, die Leads, Preisdaten oder Immobilienangebote in vernünftigem Umfang scrapen? Oft ist das die einzige Methode, die du brauchst. Kein Code, keine Proxies, keine Wartung.
Schritt 3: TLS-Fingerprint-Spoofing mit curl_cffi (leichter Code-Ansatz)
Wenn du dich mit Python wohlfühlst und der No-Code-Pfad nicht zu deinem Workflow passt, ist die leichtgewichtigste Code-Option. Es ist ein Python-Binding um libcurl, das echte Browser-TLS-Fingerprints imitieren kann. Anders als requests oder httpx sieht dein TLS-Handshake dann so aus, als käme er von Chrome oder Safari.
Stand 2026 gehören zu den unter anderem chrome136, safari184 und viele historische Profile. Die Bibliothek hatte , ist also aktiv gepflegt.
Wann einsetzen: Bei Websites mit Cloudflare-Schutz auf Free- oder Pro-Niveau, die vor allem auf passivem Fingerprinting basieren – ohne aktive JavaScript-Challenge und ohne Turnstile.
Einfaches Beispiel:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Worauf viele hereinfalle: Halte deinen User-Agent konsistent mit dem Imitationsziel. Wenn du Chrome 136 imitierst, solltest du nicht einen User-Agent für Chrome 120 senden. Diese Abweichung ist ein Signal.
Einschränkungen: curl_cffi führt kein JavaScript aus. Wenn die Seite eine „Checking your browser“-Challenge oder ein Turnstile-Widget ausliefert, scheitert diese Methode. Sie hilft auch nicht bei Seiten, die Cookie-basierten Session-Status aus einer Browser-Challenge benötigen. Sie ist also eher ein schneller, günstiger Erstversuch für rein passive Schutzmechanismen.
Alternativen in derselben Familie: tls-client und curl-impersonate bieten ähnliche TLS-Imitationsfunktionen.
Schritt 4: Stealth-Browser-Automatisierung (Puppeteer Stealth und SeleniumBase UC)
TLS-Spoofing reicht nicht aus, wenn die Website JavaScript-Ausführung, aktive Challenges oder Turnstile verlangt. Dann brauchst du einen vollständigen Browser. Die zwei Hauptoptionen:
- SeleniumBase UC Mode (Python): Die als Möglichkeit, Automatisierung menschlicher wirken zu lassen und Anti-Bot-Dienste zu umgehen. Dort gibt es auch Beispiele für den Umgang mit Cloudflare Turnstile.
- Puppeteer mit
puppeteer-extra-plugin-stealth(Node.js): Wird weiterhin viel genutzt, ist 2026 aber . Community-Berichte nennen Fehlschläge durch CDP-Erkennung (Chrome DevTools Protocol) und unpassende Browser-Profile.
Beide Tools starten einen echten Chromium-Browser, patchen aber erkennbare Automatisierungssignale: navigator.webdriver, WebGL-Metadaten, Plugin-Listen und mehr.
Konfigurationstipps, die wirklich wichtig sind:
- Headed Mode verwenden (nicht Headless). SeleniumBase weist in der Doku darauf hin, dass UC Mode im Headless-Modus erkennbar ist. Auf Linux-Servern solltest du ein virtuelles Display nutzen.
- Viewport-Größe und User-Agent zufällig variieren, aber aufeinander und auf die Geolokation deines Proxys abstimmen.
- Realistische Pausen zwischen Aktionen einbauen. 200 ms zwischen Seitenaufrufen schreit geradezu nach „Bot“.
- Cookies und Browser-Profile speichern, nachdem die erste Challenge bestanden ist. Nicht bei jedem Request die Challenge erneut lösen.
- Mit Residential Proxies kombinieren, um eine bessere IP-Reputation zu bekommen.
Das Risiko bei diesem Ansatz ist der Wartungsaufwand. Browser-Automation-Stacks brechen, wenn Chrome aktualisiert wird, Cloudflare ein neues Signal einführt, ein Stealth-Plugin hinterherhinkt oder eine Zielseite pfadspezifisches Turnstile hinzufügt. Ein fand heraus, dass viele Stealth-Browser-Setups bei Fingerprint-Tests durch sogenannte „Franken-Fingerprints“ scheitern – also unpassenden Kombinationen aus Zeitzone, Sprache und Proxy-Geografie.
Diese Methode ist stark, aber operativ teuer. Plane Zeit für laufende Korrekturen ein.
Proxy-Rotation: Warum die IP genauso wichtig ist wie der Fingerprint
Selbst mit perfektem Browser-Stealth lösen zu viele Anfragen von einer einzigen IP Rate Limits aus. Cloudflare vertraut Residential- und Mobile-IPs deutlich stärker als Rechenzentrums-IPs.
- Residential Proxies: 2026 je nach Volumen im Einstieg. Vertrauenswürdiger, aber teurer.
- Datacenter Proxies: Günstiger, aber .
- Rotationsstrategie: Pro Session rotieren, nicht pro Request. Eine Rotation pro Request zerstört sessiongebundene Cookies und
cf_clearance. Halte IP, Cookies und Fingerprint innerhalb einer Session konsistent.
Es gibt keine magische „Mindestgröße“ für einen Proxy-Pool. Ein Scrape mit geringem Volumen für Leads funktioniert vielleicht mit einigen wenigen Sticky-Residential-Sessions; ein Preismonitor mit hohem Volumen braucht möglicherweise Hunderte von Ausgängen plus Retry-Logik.
Schritt 5: FlareSolverr – der Open-Source-Server für Cloudflare-Umgehung
ist ein Open-Source-Proxy-Server, der Chromium mit undetected-chromedriver in einem Docker-Container nutzt, um Cloudflare-Challenges zu lösen und Cookies/Header für die Wiederverwendung zurückzugeben. Im , also wird das Projekt weiterhin gepflegt.
Wann verwenden: Für serverseitige Scraping-Pipelines, in denen du einen dauerhaften Challenge-Lösedienst brauchst – zum Beispiel für einen nächtlichen Job, der frische cf_clearance-Cookies benötigt.
So funktioniert es: Dein Scraper sendet eine URL an die API von FlareSolverr. FlareSolverr öffnet die Seite im Browser, versucht die Challenge zu lösen und gibt HTML plus Cookies zurück. Diese Cookies kannst du anschließend in deinem normalen HTTP-Client weiterverwenden.
Kurzüberblick zur Einrichtung: Docker Compose, Container starten, POST-Anfragen an den lokalen API-Endpunkt senden. .
Offene Grenzen:
- Interaktive Turnstile-Challenges oder Enterprise Bot Management lassen sich nicht zuverlässig lösen.
- und zeigen inkonsistentes Verhalten: verpasste Challenge-Erkennung, Turnstile-Timeouts, Seitenabstürze.
- Erfordert Docker-Infrastruktur und laufende Wartung.
- Ressourcenintensiv – jeder Challenge-Lösungsversuch startet einen Browser-Kontext.
Geschätzte Zuverlässigkeit: 60–80 % bei Zielen mit mittlerem Schutz. Niedriger bei Enterprise, höher bei einfacheren Challenge-Seiten. Wenn FlareSolverr nicht reicht, solltest du kostenpflichtige APIs in Betracht ziehen.
Schritt 6: Kostenpflichtige Scraping-APIs, die Cloudflare für dich übernehmen
Manchmal ist die Rechnung simpel: Die Pflege deiner eigenen Stealth-Infrastruktur kostet in Arbeitsstunden mehr als ein Abo. Kostenpflichtige Scraping-APIs lagern das gesamte Wettrüsten an einen spezialisierten Anbieter aus – du sendest eine URL, der Anbieter übernimmt Fingerprinting, Proxies, Challenge-Lösung und Retries.
So vergleichst du sie:
| Anbieter | Cloudflare-Unterstützung | JS-Rendering | Residential Proxies | Strukturierte Ausgabe | Preismodell |
|---|---|---|---|---|---|
| ScrapingBee | Ja | Ja | Ja | Nur HTML | Guthaben pro Anfrage |
| ZenRows | Ja (behauptet >99 % Erfolg) | Ja | Ja (Premium) | HTML, teils Parsing | CPM mit Multiplikatoren |
| Scrapfly | Ja (führt CF, Akamai, DataDome auf) | Ja | Ja | HTML, teils Parsing | Credit-basiert |
| Browserless | Ja | Ja (headless Chrome) | Ja (integriert) | HTML, Screenshots | Einheitenbasiert |
| Thunderbit API | Ja | Ja | Ja | Strukturierte JSON/CSV-Ausgabe mit KI-Schema | Kostenloser Tarif + kostenpflichtige Pläne |
Wann das sinnvoll ist: Scraping mit hohem Volumen, Anforderungen an Enterprise-Zuverlässigkeit oder wenn dein Team keine Scraping-Infrastruktur warten will. Kostenrahmen: grob 30–500+ $/Monat für kleine bis mittlere Nutzung, mit höherem Niveau für Enterprise-Volumen.
Die Thunderbit API ist separat erwähnenswert, weil sie strukturierte Daten ausgibt – nicht nur rohes HTML. Der kann bis zu 50 URLs pro Anfrage im Batch verarbeiten und JSON/CSV auf Basis eines KI-gestützten Schemas zurückgeben – praktisch, wenn du saubere, direkt analysierbare Daten statt HTML zum Selberparsen brauchst.
Ehrliche Zuverlässigkeitsübersicht: Was wirklich funktioniert – und was scheitert
Ich habe 2025–2026 Community-Berichte, GitHub-Issues und Anbieterangaben beobachtet. Was folgt, ist ein ehrlicher Vergleich. Das sind Richtwerte, keine Labormessungen:
| Methode | Geschätzte Erfolgsrate | Wartungsaufwand | Bricht, wenn… | Kostenrahmen |
|---|---|---|---|---|
| Interne API (falls vorhanden) | ~90–99 % | Niedrig | sich die API ändert, Authentifizierung hinzukommt, Tokens signiert werden | Kostenlos |
| Browser-Erweiterung (Thunderbit) | ~85–95 % (echte Session) | Niedrig (KI passt sich an Layoutänderungen an) | spezielle Auth-Flows nötig sind, aggressives Turnstile pro Aktion | Kostenloser Tarif verfügbar |
curl_cffi / TLS-Spoofing | ~70–85 % | Mittel (Fingerprint-Updates) | Cloudflare JA3-Prüfungen dreht, aktive JS-Challenge nötig | Kostenlos |
| Puppeteer + Stealth-Plugin | ~70–90 % | Hoch (Plugin-Updates hinken hinterher) | CDP-Erkennung, neue Fingerprint-Signale, Headless-Erkennung | Kostenlos + Proxy-Kosten |
| FlareSolverr | ~60–80 % | Hoch (Docker, Abhängigkeitsdrift) | Schutz auf Enterprise-Niveau, Turnstile-Interaktion | Kostenlos + Infrastrukturkosten |
| Kostenpflichtige Scraping-API | ~85–95 % | Niedrig (vom Anbieter gewartet) | Anbieter nicht aktualisiert, Budget überschritten | ca. 30–500+ $/Monat |
Die wichtigste Spalte ist nicht die Erfolgsrate, sondern „Bricht, wenn…“. Jede Methode hat einen Ausfallmodus. Die beste Strategie ist, die Methode mit dem geringsten Aufwand zu wählen, die für dein Ziel funktioniert, und einen Fallback-Plan zu haben.
Es gibt keine dauerhafte Lösung. Cloudflare wird ständig aktualisiert. Das Wettrüsten ist real.
Tipps, um unter Cloudflares Radar zu bleiben – egal welche Methode du nutzt
Unabhängig von der gewählten Methode helfen ein paar Gewohnheiten dabei, länger unauffällig zu bleiben:
- Rate Limits respektieren. Zwischen Requests realistische Pausen einbauen – mindestens 2–5 Sekunden für menschenähnliches Browsen. Eine Website mit Maschinen-Geschwindigkeit zu bearbeiten, ist der schnellste Weg zur Blockade.
- Den Fingerprint konsistent halten. User-Agent, TLS-Fingerprint, Browserversion, Zeitzone, Locale und IP-Geografie sollten dasselbe Bild ergeben. Ein Chrome-136-User-Agent von einer deutschen IP mit
en-US-Locale und Python-TLS-Handshake ist ein Widerspruch. - Cookies und Sessions wiederverwenden, nachdem eine Challenge bestanden wurde. Nicht bei jedem Request die Challenge neu lösen.
- IP nicht mitten in der Session wechseln. Cloudflare verfolgt die Sitzungs-Kontinuität.
- Residential oder Mobile IPs verwenden, wenn Anwendungsfall und Budget das rechtfertigen.
- Auf Soft Blocks achten: Challenge-HTML dort, wo du JSON erwartest, leere Tabellen, Login-Weiterleitungen oder Seiten, die verdächtig nach -Honeypots aussehen.
- Stoßzeiten meiden, wenn Website-Betreiber WAF-Regeln verschärfen könnten.
- Fallback-Pfade bauen: zuerst API → dann Browser-Session → dann kostenpflichtiger Anbieter.
Für Thunderbit-Nutzer ist besonders praktisch: Die KI passt sich automatisch an Layoutänderungen an, sodass du weniger Zeit mit der Pflege von CSS-Selektoren verbringst und mehr Zeit mit der eigentlichen Nutzung der Daten.
Kurzer Hinweis zu rechtlichen und ethischen Fragen
Nicht der Schwerpunkt dieses Artikels, aber zu wichtig, um es wegzulassen.
Das Scrapen öffentlich zugänglicher Daten hat in – die hiQ-v.-LinkedIn-CFAA-Argumentation überstand die Zurückverweisung durch den Supreme Court, auch wenn sich die Parteien 2022 einigten und die Lage insgesamt komplex bleibt. Später verklagte im Jahr 2025 wegen angeblichen Scrapings von Nutzerkommentaren, und .
In der EU gilt die DSGVO immer dann, wenn personenbezogene Daten betroffen sind, und der enthält spezifische Pflichten rund um .
Praktische Faustregeln:
- Prüfe immer die Nutzungsbedingungen der Website.
- Cloudflare-Schutz ist ein Signal dafür, dass der Betreiber automatisierten Zugriff kontrollieren will – respektiere diese Absicht.
- Erfasse keine personenbezogenen Daten ohne legitime Grundlage.
- Für kommerzielle oder hochvolumige Workflows sind offizielle APIs, lizenzierte Daten oder eine schriftliche Erlaubnis, wenn verfügbar, die bessere Wahl.
- Wenn du unsicher bist, hol für deinen konkreten Fall und deine Jurisdiktion rechtlichen Rat ein.
Thunderbit ist für legitime Business-Anwendungsfälle konzipiert – Lead-Generierung, Preisüberwachung, Marktforschung – auf Basis öffentlich zugänglicher Daten.
Fazit: Was du zuerst testen solltest und was danach
Der größte Zeitgewinn in diesem ganzen Artikel ist nicht ein Tool oder ein Code-Snippet – sondern die Schutzstufe zu erkennen, bevor du anfängst. Allein das verhindert stundenlanges Debugging einer Methode, die ohnehin nie funktioniert hätte.
Hier anfangen:
- Nach einer internen API suchen (kostenlos, schnell und oft übersehen).
- Wenn du als Business-Nutzer nicht programmierst, probiere – deine echte Browser-Session ist dein stärkster Vorteil gegen Cloudflare.
- Wenn du Entwickler bist und das Ziel nur passives Fingerprinting nutzt, teste
curl_cffi. - Steige erst dann auf Stealth-Browser, FlareSolverr oder kostenpflichtige APIs um, wenn die einfacheren Methoden scheitern.
Keine einzelne Methode ist dauerhaft. Kombiniere das passende Tool für deinen Umfang mit einem Fallback-Plan, und du wirst viel weniger Zeit vor 403-Seiten verbringen.
Wenn du tiefer einsteigen möchtest, haben wir im Thunderbit-Blog auch über , und geschrieben. Und wenn du die Erweiterung in Aktion sehen willst, schau dir den mit Walkthrough-Videos an.
FAQs
1. Kann man Cloudflare-Schutz vollständig umgehen?
Keine einzelne Methode garantiert 100 % Erfolg, besonders nicht gegen Enterprise Bot Management mit Turnstile, JA4-Fingerprinting und AI Labyrinth. Am zuverlässigsten sind Ansätze, die echte Browser-Fingerprints mit guter IP-Reputation kombinieren. Eine interne API ist dem „vollständigen“ Umgehen am nächsten, weil Cloudflare dabei gar nicht erst berührt wird – aber nicht jede Website hat so etwas.
2. Ist es legal, Cloudflare beim Scraping zu umgehen?
Das hängt von deiner Jurisdiktion, den Nutzungsbedingungen der Website und den erhobenen Daten ab. Das Scrapen öffentlich zugänglicher Daten ist in den USA in manchen Kontexten rechtlich günstig bewertet worden (hiQ v. LinkedIn), aber das Umgehen technischer Zugriffskontrollen, Verstöße gegen die Nutzungsbedingungen oder das Erfassen personenbezogener Daten ohne legitime Grundlage können rechtliche Risiken auslösen. Für kommerzielle Workflows solltest du nach Möglichkeit offizielle APIs oder lizenzierte Daten nutzen und bei Unsicherheit Rechtsberatung einholen.
3. Was ist die einfachste Methode, Cloudflare ohne Programmieren zu umgehen?
Browser-Erweiterungen wie , die in deiner echten Chrome-Session laufen, lösen Cloudflare-Challenges automatisch: Du interagierst mit der Seite wie ein normaler Nutzer und lässt dann die Erweiterung die Daten extrahieren und exportieren. Kein Python, kein Docker, keine Proxy-Konfiguration.
4. Warum funktioniert mein Scraper auf manchen Cloudflare-Seiten, auf anderen aber nicht?
Cloudflares Schutzstufe variiert stark je nach Plan (Free, Pro, Business, Enterprise) und Konfiguration. Eine Methode, die bei einer Free-Plan-Seite mit einfacher JS-Challenge funktioniert, kann an einer Enterprise-Seite mit Turnstile oder vollständigem Bot Management scheitern. Bestimme immer zuerst die Schutzstufe – also ob du nur einen einfachen JS-Check, eine Managed Challenge oder ein Turnstile-Widget siehst – und wähle dann deine Umgehungsmethode.
5. Wie oft brechen Cloudflare-Umgehungsmethoden?
Code-basierte Methoden wie Stealth-Plugins und TLS-Spoofing können bei schweren Zielen alle paar Wochen bis Monate an Wirksamkeit verlieren, wenn Cloudflare seine Erkennung aktualisiert. Kostenpflichtige APIs und Tools auf Basis echter Browser-Sessions sind meist robuster, weil sie sich auf Infrastruktur- oder Session-Ebene anpassen. Interne APIs brechen selten – außer die Website überarbeitet ihr Backend oder ändert ihr Authentifizierungsmodell. Die sicherste Langzeitstrategie ist daher, mehrere Fallback-Methoden zu haben, statt sich auf einen einzigen Ansatz zu verlassen.
Mehr erfahren