

Amazon zählt fast 2 Millionen Verkaufspartner und hunderte Millionen Artikel im Katalog. Wer schon einmal versucht hat, Produkttitel, Preise, Bewertungen und ASINs von Hand in eine Tabelle zu kopieren, kennt die Mühe und weiß, wie schnell das Ganze ausufert.
Ich arbeite bei Thunderbit an einem KI-Web-Scraper und denke deshalb viel darüber nach, wie Menschen Daten von Websites holen. Für diesen Artikel wollte ich aber etwas tun, das andere Übersichten kaum konsequent durchziehen: sieben echte Chrome-Erweiterungen direkt nebeneinanderstellen, die Sie auf Amazon installieren und ausführen können, sie auf denselben Seiten testen und klar sagen, was funktioniert, was nicht und wofür sich welches Tool eignet. Jede Erweiterung habe ich an acht Kriterien gemessen, die direkt zu den Problemen passen, die mir in Foren und bei unseren eigenen Nutzern begegnen – KI-Felderkennung, Unterseiten-Scraping, Sperrrisiko, kostenlose Tarife und Exportoptionen. Ob Amazon-Verkäufer, Marketer oder einfach jemand, der vom Kopieren genug hat: Dieser Leitfaden ist für Sie.
Thunderbit für Amazon-Scraping ausprobieren
Warum überhaupt Amazon-Produktdaten scrapen?
Wer scrapt Amazon eigentlich – und warum?
Praktisch jeder, der online Produkte verkauft, vermarktet oder analysiert. Amazon zufolge stammen mehr als 60 % des Umsatzes im Store von unabhängigen Verkäufern, und die beobachten sich ständig gegenseitig. Die häufigsten Anwendungsfälle, die mir begegnen:
| Anwendungsfall | Wer es nutzt | Was sie erhalten |
|---|---|---|
| Konkurrenz-Preisbeobachtung | Verkäufer, Pricing-Teams, Agenturen | Preis- und Verfügbarkeitsdaten in Echtzeit für Konkurrenzprodukte |
| Produktrecherche & Trend-Tracking | Amazon-Verkäufer, Marktforscher | Wachsende Kategorien, neue Marktteilnehmer und Nachfrageverschiebungen erkennen |
| Analyse der Bewertungsstimmung | Private-Label-Verkäufer, Brand-Teams | Wiederkehrende Beschwerden, Funktionslücken und Chancen |
| Lead-Generierung (Verkäuferkontakte) | Großhandelsteams, Agenturen | Verkäufernamen, Shops und Kontaktdaten |
| Katalog- & Bestandsüberwachung | E-Commerce-Operations, Markenschutz | Lagerbestände, Listing-Änderungen und unautorisierte Verkäufer verfolgen |
| Keyword- & Listing-Optimierung | Markeninhaber, Marktplatzbetreiber | Suchbegriffsdaten, Listing-Text und Konkurrenz-Keywords |
Der ROI ist greifbar. Amazons eigene Fallstudien zeigen, dass die vierteljährlichen Verkäufe von thefitguy um über 40 % stiegen, nachdem mit strukturierten Daten für die wichtigsten Suchbegriffe optimiert wurde. Und eine Parseur-Umfrage ergab, dass Beschäftigte über 9 Stunden pro Woche mit repetitiver Dateneingabe zubringen. Wer auch nur einen Teil davon automatisiert, gewinnt enorm viel Zeit für die eigentlichen Entscheidungen.
Was eine gute Amazon-Scraper-Chrome-Erweiterung ausmacht (meine Testkriterien)
Chrome-Erweiterungen sind nicht alle gleich – und die meisten Vergleiche werfen APIs, Desktop-Apps und Browser-Erweiterungen in einen Topf, als wären sie austauschbar. Sind sie nicht. Das ist mein Bewertungsraster, samt Begründung für jedes Kriterium:
- Einfachheit der Einrichtung – Erzielt ein nicht-technischer Nutzer in unter 5 Minuten Ergebnisse? (Foren bestätigen: ein zentrales Thema.)
- KI-gestützte Felderkennung – Erkennt das Tool Produktfelder automatisch, oder müssen Sie Selektoren von Hand konfigurieren? (Kein anderer Artikel behandelt das als eigene Kategorie.)
- Unterseiten- / Detailseiten-Scraping – Lassen sich Listing-Daten in einem Arbeitsgang mit Informationen von Produktdetailseiten anreichern?
- Anti-Bot- / Sperrrisiko-Handling – Wie geht das Tool mit Amazons aggressiver Bot-Erkennung um? (Die größte Schwachstelle in Nutzerforen.)
- Paginierungsunterstützung – Scrapt es automatisch über mehrere Ergebnisseiten hinweg?
- Kostenloser Tarif / Preisgestaltung – Was bekommt man tatsächlich ohne Bezahlung? (Nutzer fragen ausdrücklich nach Gratisoptionen, und kaum ein Wettbewerber antwortet praktisch.)
- Exportoptionen – CSV, Excel, Google Sheets, Airtable, Notion?
- Planung & Automatisierung – Lässt es sich regelmäßig ausführen?
Getestet habe ich jede Erweiterung auf Amazon-US-Suchergebnisseiten und Produktdetailseiten – gleiche Suchanfragen, gleiche Bedingungen.

KI-gestütztes vs. selektorbasiertes Scraping: Warum das für Amazon wichtig ist
Es gibt einen Unterschied, den kaum eine andere Amazon-Scraper-Übersicht klar benennt – und er entscheidet maßgeblich, wie viel Wartung Ihr Scraper braucht.
Die meisten Chrome-Erweiterungen ordnen CSS-Selektoren den Datenfeldern zu. Sie (oder die Vorlage des Tools) zeigen auf das HTML-Element für „Preis“ oder „Titel“, und der Scraper holt, was dort steht. Das Problem: Amazon ändert sein zugrunde liegendes HTML und CSS praktisch täglich, um Scraper auszubremsen. Nutzer in Foren nennen gehashte oder wechselnde Klassennamen als häufigen Fehlerfall.
So stehen die drei wichtigsten Ansätze zueinander:
| Ansatz | So funktioniert es | Wenn Amazon das Layout ändert |
|---|---|---|
| Selektorbasiert (klassisch) | Nutzer ordnet CSS-Selektoren manuell Feldern zu | Funktioniert nicht mehr – der Nutzer muss neu konfigurieren |
| Vorlagenbasiert | Vorgefertigte Rezepte für Amazon-Seiten | Funktioniert nicht, bis der Entwickler die Vorlage aktualisiert |
| KI-gestützt (z. B. Thunderbit) | KI liest Seiteninhalt und erkennt Felder automatisch | Passt sich automatisch an – keine Wartung nötig |
Nur eine der sieben getesteten Erweiterungen, Thunderbit, setzt KI-Felderkennung als Standardweg ein. Die übrigen arbeiten mit Selektoren oder Vorlagen, was bei Amazons unvermeidlichen Layout-Änderungen mehr Pflege bedeutet. Wer diesen Unterschied versteht, erspart sich später viel Frust.
1. Thunderbit – die KI-gestützte Amazon-Scraper-Chrome-Erweiterung
Thunderbit ist das Tool, das wir in unserem Unternehmen entwickeln – das sage ich offen. Aber ich bin ehrlich überzeugt, dass es die beste Wahl für nicht-technische Nutzer ist, die schnell präzise Amazon-Daten wollen, ohne sich mit Selektoren oder Code herumzuschlagen.
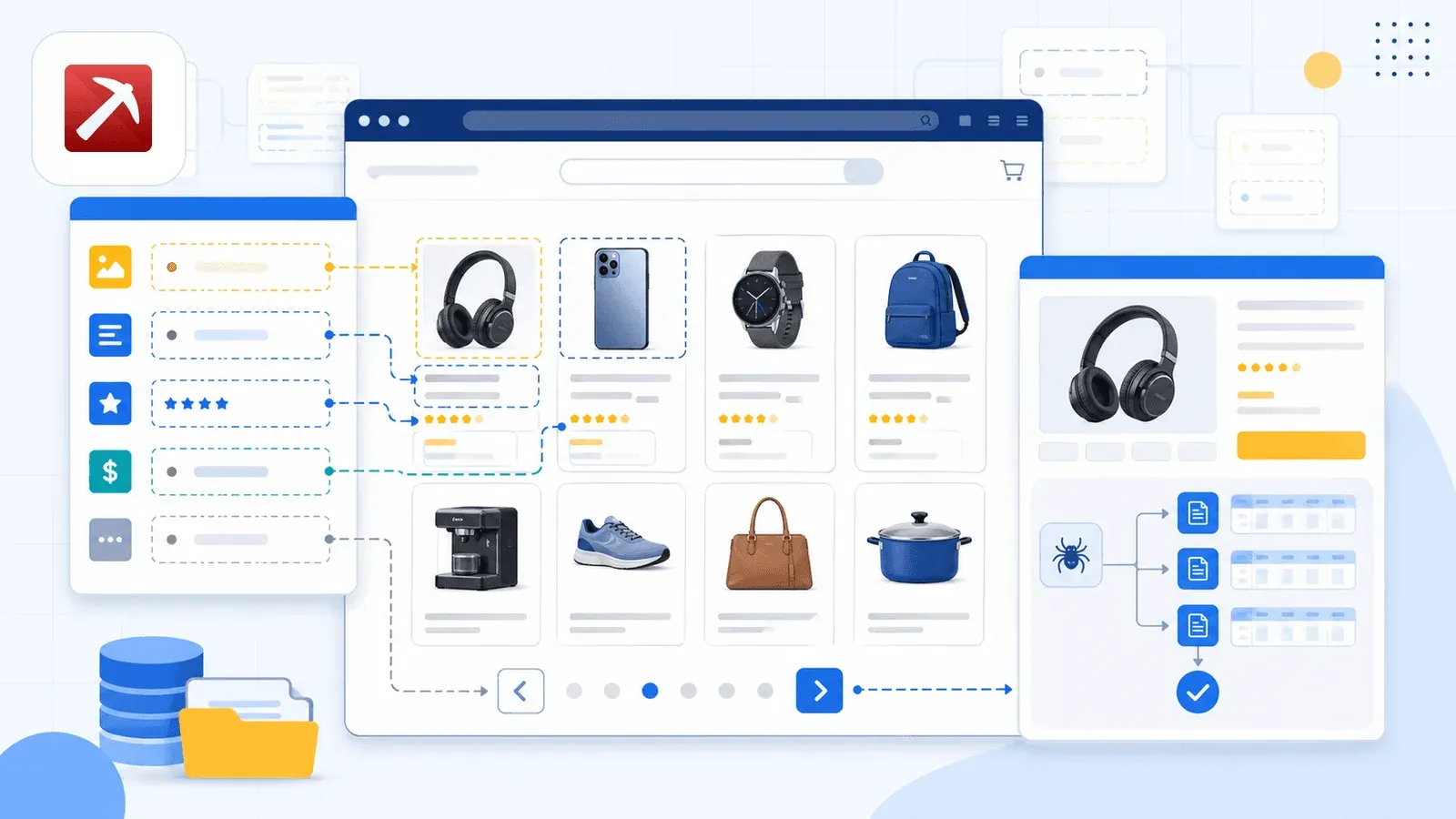
Der entscheidende Unterschied heißt KI-Felder vorschlagen. Öffnen Sie eine Amazon-Suchergebnisseite und klicken Sie auf den Button, liest die KI von Thunderbit die Seite aus und schlägt Spaltennamen vor – Titel, Preis, Bewertung, ASIN, Anzahl der Rezensionen, Produkt-URL und mehr. Konfigurieren müssen Sie nichts. Die KI erkennt, was auf der Seite steht, und schlägt die passenden Felder und Datentypen vor.

So sieht eine typische Amazon-Scraping-Sitzung aus:
- Installieren Sie die Thunderbit Chrome Extension und öffnen Sie eine Amazon-Suchergebnisseite.
- Klicken Sie auf KI-Felder vorschlagen – die KI erkennt die Spalten und schlägt sie vor.
- Klicken Sie auf Scrape – die Daten werden sofort eingefügt.
- Für gefragte Amazon-Seiten nutzen Sie auch die fertige Amazon-Scraper-Vorlage für ein echtes 1-Klick-Erlebnis.
Was Thunderbit wirklich abhebt, ist das Unterseiten-Scraping. Nach dem Scrapen der Listing-Seite klicken Sie auf Unterseiten scrapen – Thunderbit besucht jede Produkt-URL und ergänzt Detailfelder wie vollständige Beschreibungen, Stichpunkte, Verkäuferinformationen und Bild-URLs in derselben Tabelle. Die meisten Konkurrenz-Erweiterungen können das schlicht nicht.
Dazu kommt ein Umschalter zwischen Cloud und Browser. Der Cloud-Modus scrapt bis zu 50 Seiten gleichzeitig für öffentliche Listings. Der Browser-Modus nutzt Ihre eigene Chrome-Sitzung. Das ist ideal, wenn Sie in Seller Central eingeloggt sind oder möglichst unauffällig arbeiten wollen.
Die Planung läuft in normalem Deutsch: Beschreiben Sie das Zeitintervall, und die KI macht daraus einen Zeitplan.
Exportiert wird nach Excel, Google Sheets, Airtable, Notion, CSV und JSON – alles im kostenlosen Tarif enthalten.
Vor- und Nachteile von Thunderbit
Vorteile:
- KI erkennt Felder automatisch – keine Selektor-Einrichtung, keine Wartung bei Amazons Layout-Änderungen
- Anreicherung von Unterseiten mit einem Klick
- Umschalter zwischen Cloud und Browser für Flexibilität und geringeres Sperrrisiko
- Größte Auswahl an Exportoptionen (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Planung in natürlicher Sprache
- Amazon-Vorlagen für sofortige Ergebnisse
Nachteile:
- Das kreditbasierte System bedeutet: Vielnutzer brauchen einen kostenpflichtigen Plan
- Die KI-Felderkennung braucht einen kurzen Verarbeitungsschritt (ein paar Sekunden)
- Jüngeres Tool, daher weniger Community-Dokumentation als bei älteren Optionen
Thunderbit-Preise
- Kostenloser Tarif: 6 Seiten (10 mit Test-Boost), inklusive KI-Funktionen und allen Exportformaten
- Kostenpflichtige Pläne: ab ca. 9 $/Monat (jährlich, ca. 8 €/Monat) für 500 Credits; 1 Credit = 1 Ausgabereihe
- Die aktuellsten Details unter Thunderbit-Preise
Amazon-Seiten mit KI scrapen Get Started Free
2. Instant Data Scraper – die kostenlose, schnörkellose Option
Instant Data Scraper ist eine Chrome-Erweiterung, die tabellarische Daten auf Webseiten mit heuristischen Algorithmen automatisch erkennt. Es gibt sie seit Jahren, und sie gehört nach wie vor zu den meistgeladenen kostenlosen Scraper-Tools im Chrome Web Store.
Auf Amazon aktivieren Sie die Erweiterung auf einer Suchergebnisseite, und sie versucht, die Datentabelle automatisch zu erkennen. Manchmal müssen Sie auf „try another table“ klicken, falls die erste Erkennung danebenliegt. Für einfache, einmalige Scrapes klappt das ordentlich.
Für 2026 gibt es allerdings einen wichtigen Haken: Die offizielle Landingpage weist inzwischen darauf hin, dass Instant Data Scraper nicht mehr Web Robots gehört, von ihnen entwickelt oder unterstützt wird. Das heißt: keine Updates, keine Fehlerbehebungen, keine neuen Funktionen. In einem Reddit-Thread berichtete ein Nutzer, die Erweiterung habe Übersichtsseiten verarbeitet, sich aber bei Klicks auf Detailseiten aufgehängt.
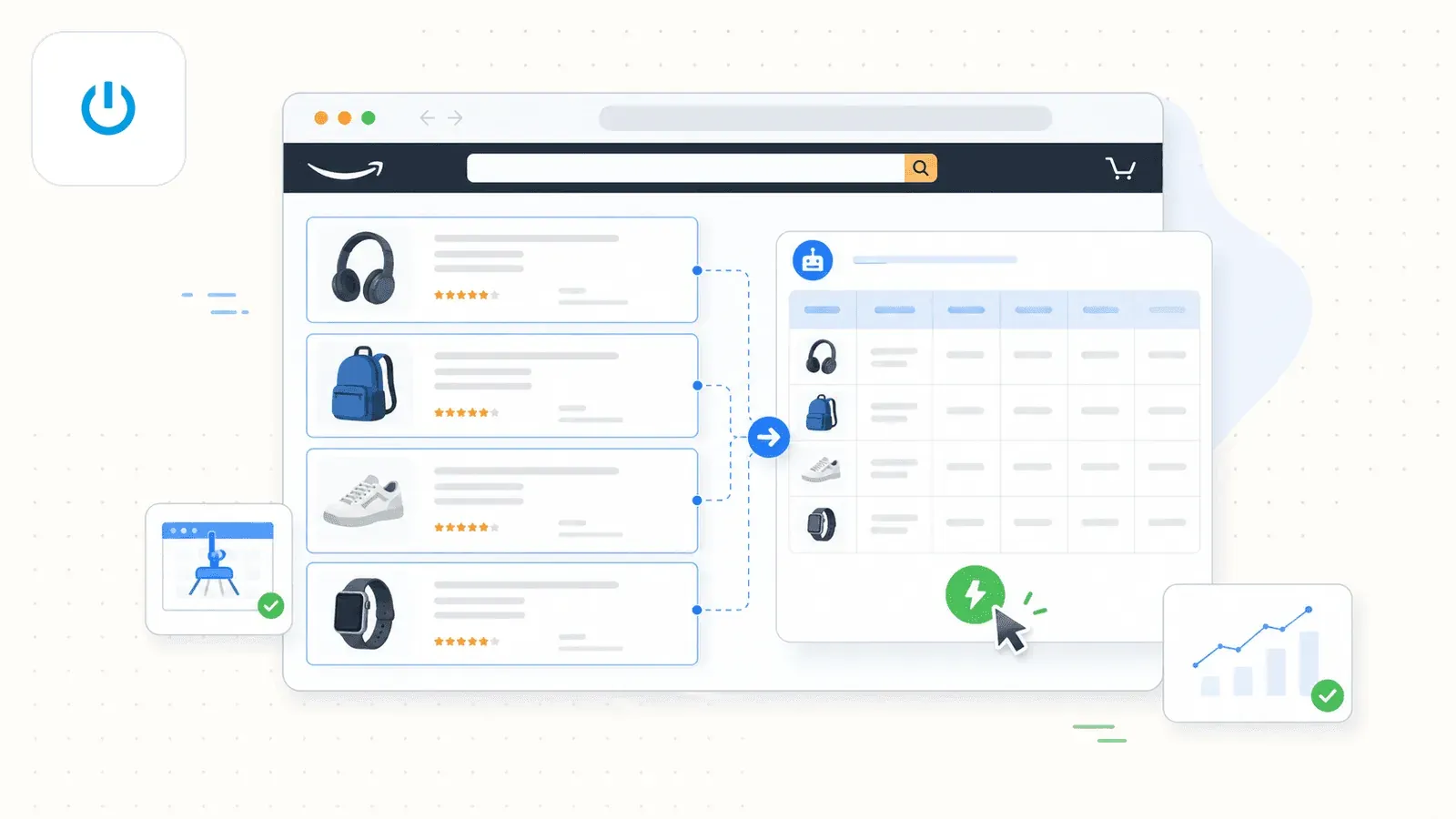
Vor- und Nachteile von Instant Data Scraper
Vorteile:
- 100 % kostenlos, kein Konto nötig
- Leichtgewichtig und schnell bei einfachen Tabellen
- Unterstützt einfache Paginierung („Next“-Button klicken)
Nachteile:
- Keine KI-Felderkennung (setzt auf Mustererkennung, die Amazons komplexes Layout falsch lesen kann)
- Kein Unterseiten-Scraping
- Nur CSV-/Excel-Export
- Keine Planung, keine Cloud-Option
- Nicht mehr gepflegt – bricht bei Amazons Layout-Änderungen, und niemand repariert es
3. Web Scraper – der Veteran für manuelle Konfiguration
Web Scraper ist einer der etabliertesten Chrome-Erweiterungs-Scraper, aufgebaut um einen visuellen Sitemap-Builder. Sie öffnen die DevTools, erstellen per Klick eine „Sitemap“ mit Selektoren, konfigurieren die Paginierung und folgen Links zu Produktdetailseiten.
Web Scraper bietet außerdem eine Marktplatz-Vorlage „Amazon Products Listings Scraper“, die Navigation, Paginierung und das Extrahieren von Produktseiten übernimmt. Die Schritt-für-Schritt-Anleitung führt durch acht Stufen – Installation, Selektoren erzeugen, Paginierung konfigurieren, Produktlinks folgen, lokal oder in der Cloud ausführen.
Die Cloud-Version ergänzt Planung, API-Zugriff, Proxy-Rotation, CAPTCHA-Umgehung und eine Google-Sheets-Integration.
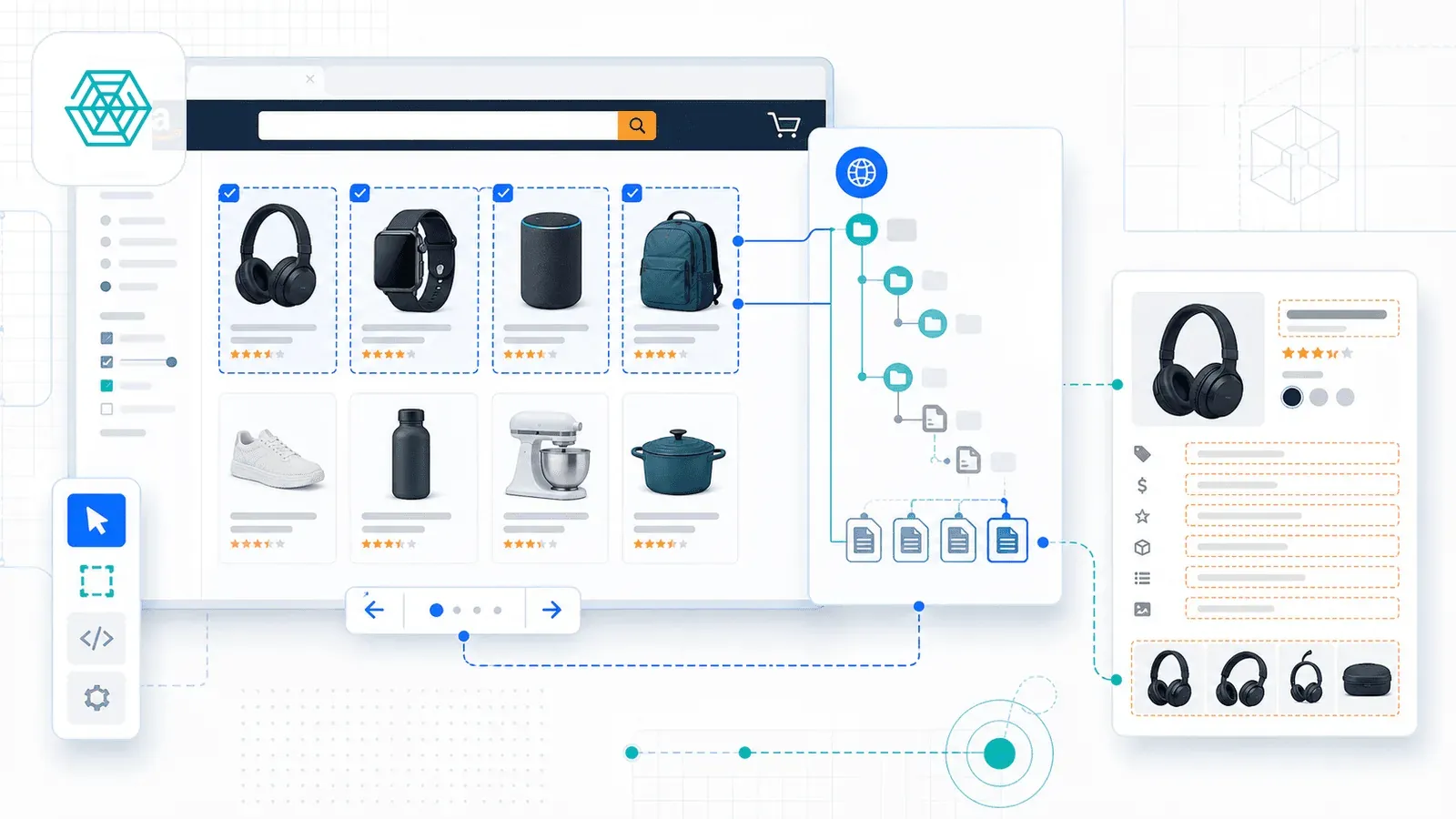
Vor- und Nachteile von Web Scraper
Vorteile:
- Ausgereift, gut dokumentiert und von der Community getragen
- Kostenlose Browser-Erweiterung (unbegrenzte lokale Nutzung)
- Marktplatz-Vorlagen für Amazon
- Cloud-Option zum Skalieren (Planung, IP-Rotation, Integrationen)
- Folgt Links zu Produktdetailseiten (teilweise Unterseiten-Anreicherung)
Nachteile:
- Erfordert manuelle Selektor-Einrichtung – steilere Lernkurve für nicht-technische Nutzer
- Keine automatische KI-Feldverknüpfung
- Vorlagen können bei Amazons Layout-Änderungen brechen
- Erweiterte Funktionen hinter kostenpflichtigen Cloud-Plänen
Web-Scraper-Preise
- Kostenlos: Chrome-Erweiterung, unbegrenztes lokales Scraping
- Cloud-Pläne: ab 50 $/Monat (Project), 100 $/Monat (Professional), ab 200 $/Monat (Scale) – ca. 46 / 92 / 184 €/Monat
4. Octoparse – die funktionsreiche Plattform mit Chrome-Erweiterungs-Haken
Octoparse ist eine starke No-Code-Scraping-Plattform mit fertigen Amazon-Vorlagen für Produktdetails, Keyword-Suche und Bewertungen. Sie unterstützt Cloud-Scraping, Planung und mehrstufige Workflows.
Ein wichtiger Punkt aber: Die Chrome-Web-Store-Erweiterung von Octoparse heißt derzeit Octoparse AI Web Automation, und dort steht ausdrücklich, dass sie nur zusammen mit Octoparse AI Bot unter Windows läuft. Das eigentliche Scraping ist also eher plattform- als erweiterungszentriert. Wer einen reinen „installieren und in Chrome scrapen“-Workflow sucht, bekommt mit Octoparse eher eine Desktop-App mit Browser-Helfer.
Die Vorlagen sind dafür hervorragend. Sie geben eine Such-URL ein, Octoparse extrahiert die Produktdaten automatisch, und Sie können eigene Workflows mit Point-and-Click-Selektoren, Paginierung und Link-Folgen für Detailseiten aufbauen.
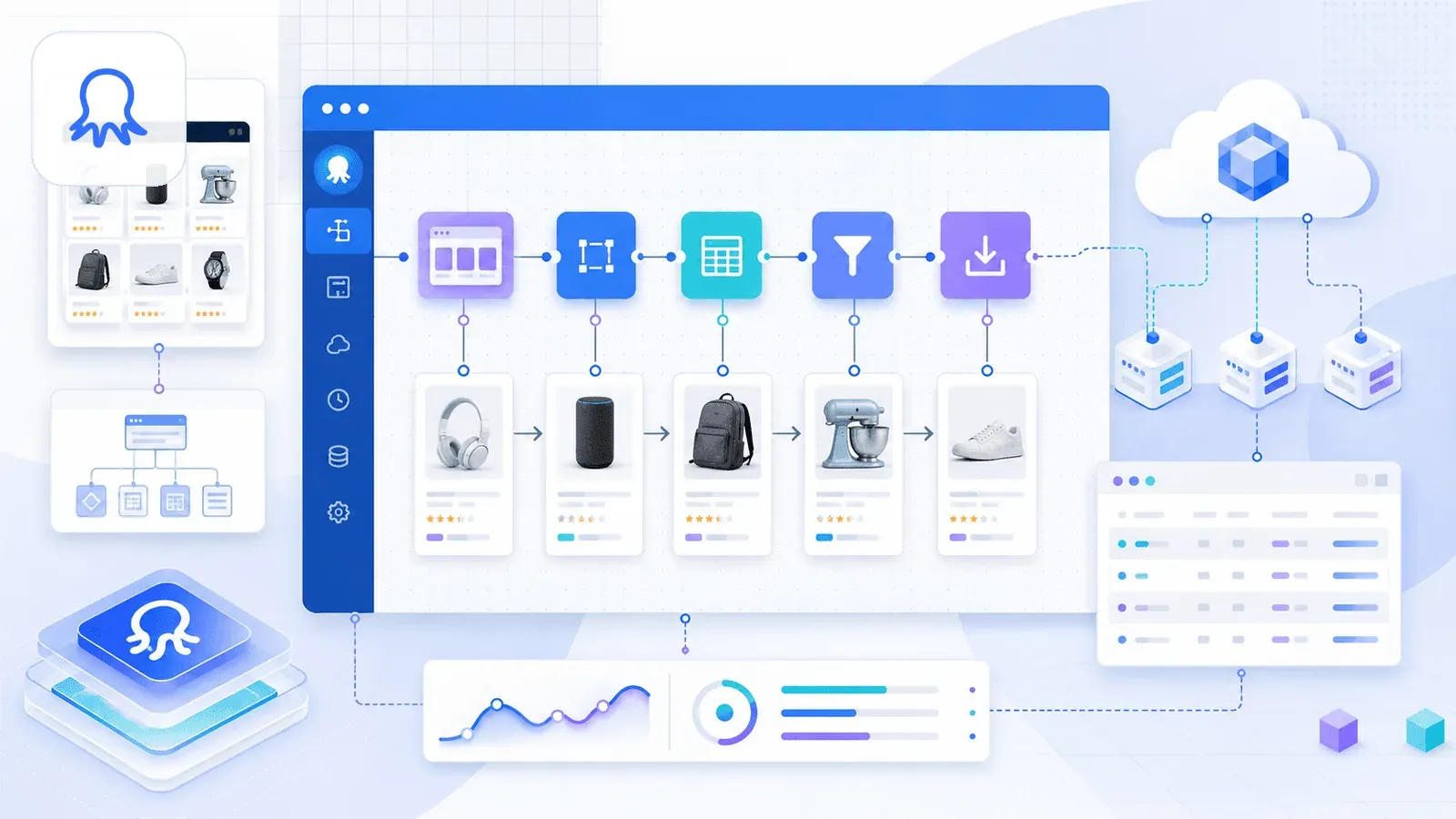
Vor- und Nachteile von Octoparse
Vorteile:
- Starkes Funktionspaket mit Amazon-Vorlagen
- Cloud-Nodes für Tempo, Planung und Unterseiten-Extraktion über Workflows
- Gute Paginierungsunterstützung
- Geeignet für komplexe, mehrstufige Scraping-Pipelines
Nachteile:
- Volle Leistung nur mit der Desktop-App – kein reines Chrome-Erweiterungs-Erlebnis
- Keine KI-Autovorschläge für Felder (es gibt ein separates Produkt namens Chat4Data, aber das ist eine andere Erweiterung)
- Kostenloser Plan begrenzt auf ca. 50.000 Datenexporte/Monat, 10.000 Zeilen pro Export
- Die Oberfläche kann für Einsteiger komplex wirken
Octoparse-Preise
- Kostenlos: eingeschränkt (lokale Extraktion, 50.000 Export-Limit)
- Standard: ca. 75–83 $/Monat (ca. 69–76 €/Monat)
- Professional: ca. 208–249 $/Monat (ca. 191–229 €/Monat)
- Add-ons: IP-Rotation für 3 $/GB, CAPTCHA-Lösung für 2–2,50 $ pro 1.000 (ca. 2,80 € bzw. 1,80–2,30 €)
5. Axiom.ai – der No-Code-Bot-Builder
Axiom.ai ist eine Chrome-Erweiterung zum Bauen von Browser-Automatisierungs-Bots per visuellem No-Code-Builder. Es ist eher ein allgemeines Automatisierungstool als ein dedizierter Scraper, bietet aber Amazon-Scraping-Vorlagen und Anleitungen zur ASIN-Extraktion.
Sie bauen einen Bot (oder nehmen eine Vorlage), der Produkt-URLs in einem Google Sheet durchläuft, jede Seite besucht, Daten per Point-and-Click-Selektoren extrahiert und die Ergebnisse zurück ins Sheet schreibt. Planung gibt es in kostenpflichtigen Plänen, und Cloud-Ausführungen sind inzwischen ab 1 Cloud-Bot in Starter und Pro verfügbar, bis zu 20 gleichzeitige Cloud-Bots im Ultimate-Tarif.
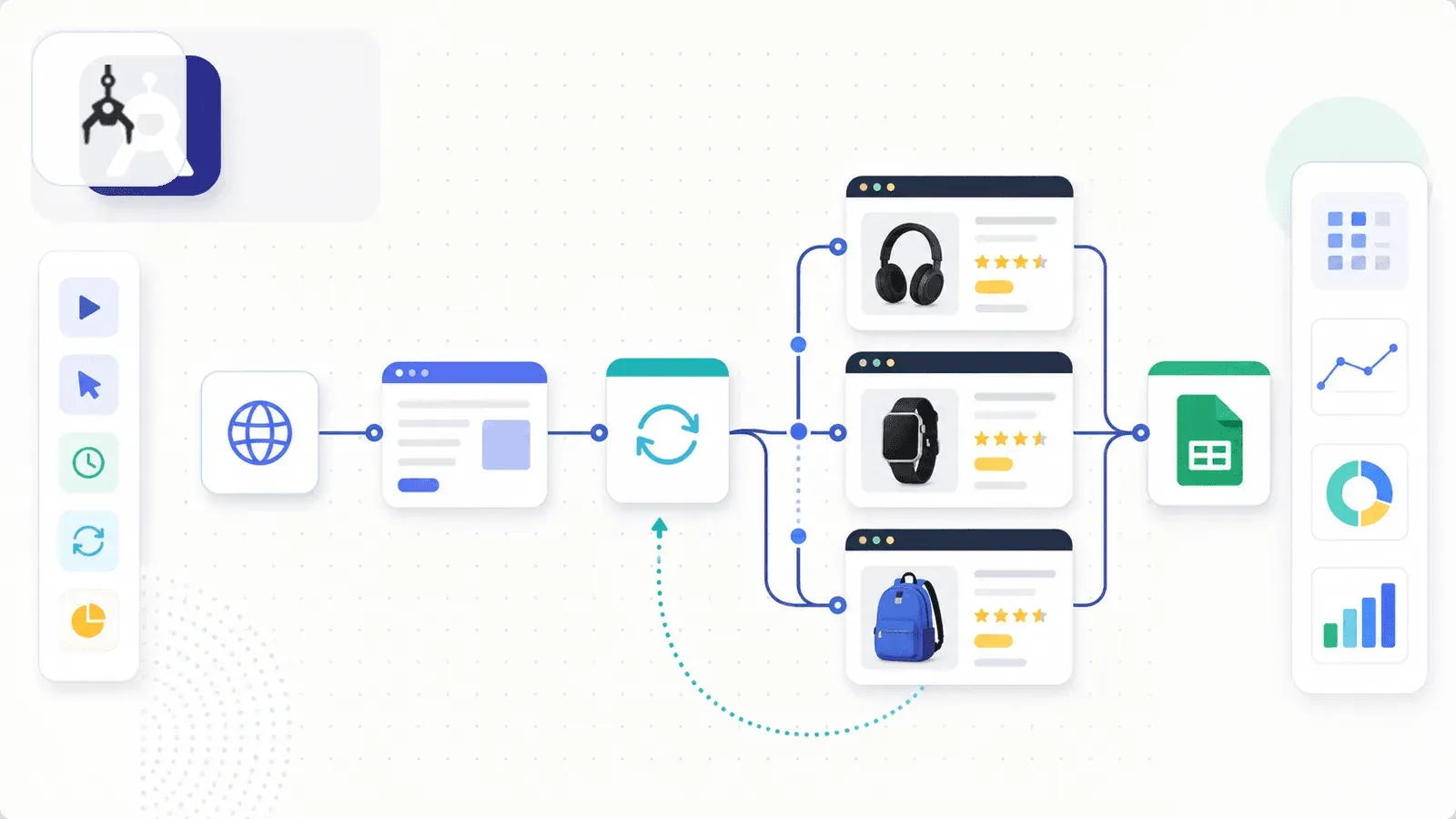
Vor- und Nachteile von Axiom.ai
Vorteile:
- Vielseitige No-Code-Automatisierung (nicht nur Scraping)
- Native Google-Sheets-Integration
- Planung und Cloud-Ausführungen in kostenpflichtigen Plänen
- Amazon-Vorlagen
- Gut für mehrstufige Workflows über die reine Datenerfassung hinaus
Nachteile:
- Mehr Aufwand bei einem simplen Scrape (Bot-Design, Google-Sheet-Konfiguration, Loop-Tests nötig)
- Keine KI-Felderkennung
- Keine Unterseiten-Anreicherung mit einem Klick (ein separater Bot-Schritt ist nötig)
- Export nur nach Google Sheets oder CSV
Axiom.ai-Preise
- Kostenlos: 2 Stunden Laufzeit
- Starter: 15 $/Monat (ca. 14 €/Monat)
- Pro: 50 $/Monat (ca. 46 €/Monat)
- Pro Max: 150 $/Monat (ca. 138 €/Monat)
- Ultimate: 250 $/Monat (ca. 230 €/Monat)
6. Data Miner – die rezeptbasierte Erweiterung
Data Miner ist eine Chrome-Erweiterung, die Daten über „Rezepte“ extrahiert – vordefinierte oder selbst gebaute Scraping-Vorlagen. Sie suchen in der öffentlichen Bibliothek ein vorhandenes Amazon-Rezept oder erstellen selbst eines, indem Sie Seitenelemente auswählen.
Data Miner unterstützt Paginierung über die Funktion Next Page Automation und bietet einen Crawl-Scrape-Workflow, um Detail-URLs zu besuchen und ein zweites Rezept anzuwenden. „Kein Unterseiten-Scraping“ stimmt also nicht – es ist aber ein manueller, mehrstufiger Prozess statt einer Anreicherung mit einem Klick.
Die große Einschränkung ist der kostenlose Tarif: 500 Seiten/Monat, dazu sind einige Domains in der Gratisversion gesperrt. Rezepte sind websitespezifisch, und Data Miners eigene Doku stellt klar, dass ein Rezept nicht mehr funktioniert, sobald sich die Website und damit der referenzierte HTML-Code ändert.
Vor- und Nachteile von Data Miner
Vorteile:
- Ein vorhandenes Rezept lässt sich leicht ausführen
- Community-Bibliothek mit Rezepten
- Unterstützt Paginierung und Crawlen von Detailseiten (manuelle Einrichtung)
- Einfache Oberfläche
Nachteile:
- Kostenloser Tarif auf 500 Seiten/Monat begrenzt
- Keine KI-Felderkennung
- Rezepte brechen, wenn Amazon das Layout ändert
- Kein Cloud-Scraping, keine Planung laut öffentlicher Doku
- Export: CSV, Excel, Zwischenablage; Google Sheets in kostenpflichtigen Plänen
Data-Miner-Preise
- Kostenlos: 500 Seiten/Monat
- Kostenpflichtig: 19,99 $, 49 $, 99 $, 200 $/Monat (ca. 18 / 45 / 91 / 184 €/Monat) mit steigenden Limits und Funktionen
7. Helium 10 – die Amazon-Seller-Intelligence-Suite
Helium 10 ist ein umfassendes Toolkit für Amazon-Verkäufer, kein allgemeiner Web-Scraper. Die Chrome-Erweiterung (Xray) blendet Daten direkt über die Amazon-Suchergebnisse ein – geschätzte Verkäufe, Umsatz, Bewertungs-Trends, BSR und mehr. Sie richtet sich an Amazon-Verkäufer in der Produktrecherche, nicht ans Extrahieren roher Seitendaten.
Helium 10 hat 2026 zwar einen kostenlosen Plan, doch der Zugriff auf die Chrome-Erweiterung ist darin eingeschränkt. Exportieren kann die Erweiterung als CSV oder Excel, und sie unterstützt Zwischenablage-Workflows.

Vor- und Nachteile von Helium 10
Vorteile:
- Tiefe Amazon-spezifische Einblicke (Verkaufsprognosen, Keyword-Daten, BSR-Trends)
- Bei professionellen Verkäufern geschätzt
- Cloud-gestützte Daten und Planung fürs Keyword-/Ranking-Tracking
- Kostenloser Plan verfügbar (eingeschränkt)
Nachteile:
- Kein allgemeiner Scraper – kann keine eigenen Datenfelder von beliebigen Seiten holen
- Teuer im Vergleich zu Scraping-fokussierten Tools
- Begrenzte Exportformate (CSV, Excel)
- Keine KI-Felderkennung, keine Unterseiten-Anreicherung im Scraping-Sinn
Helium-10-Preise
- Kostenlos: eingeschränkter Zugriff, inklusive Chrome-Erweiterung
- Starter: 49 $/Monat (ca. 45 €/Monat)
- Platinum: 229 $/Monat (ca. 211 €/Monat)
- Diamond: 359 $/Monat (ca. 330 €/Monat)
Amazon-Scraper-Chrome-Erweiterungen im Vergleich: der vollständige Side-by-Side-Vergleich
Hier die ehrliche Vergleichstabelle. Nach dem Hands-on-Test und der Verifizierung für 2026 habe ich einige Annahmen aus früheren Entwürfen korrigiert:
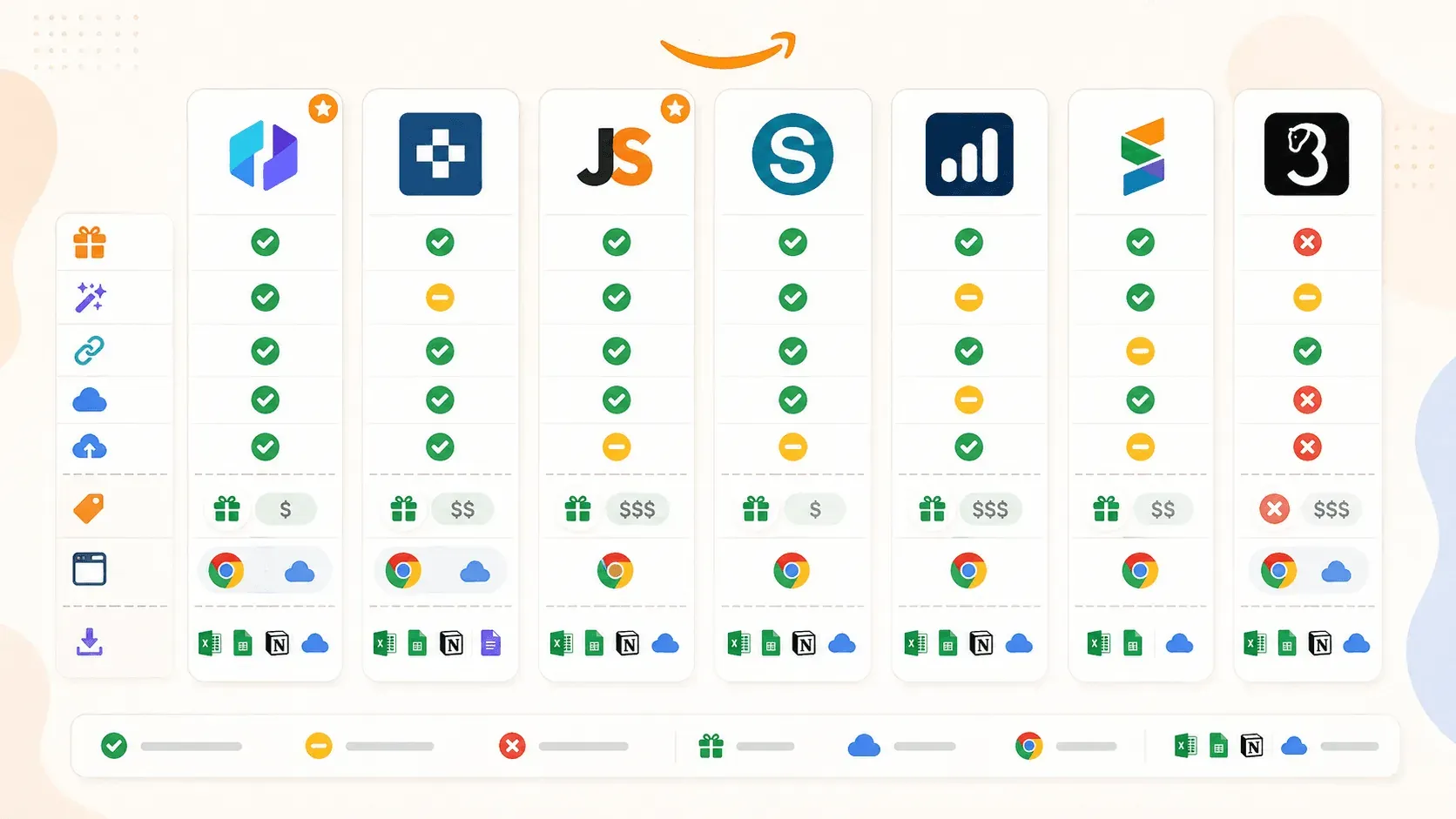
| Funktion | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Hauptkategorie | KI-Scraper-Erweiterung | Kostenloser heuristischer Scraper | Selektor-/Vorlagen-Scraper | No-Code-Scraping-Plattform | Browser-Automatisierungs-Bot-Builder | Rezeptbasierte Scraper-Erweiterung | Seller-Research-Overlay |
| KI-Autovorschläge für Felder | Ja | Nein | Nein | Nein (separates Chat4Data) | Nein | Nein | Nein |
| Anreicherung von Unterseiten | Ja (1 Klick) | Nein | Ja (manuelle Sitemap) | Ja (Workflow) | Ja (manueller Bot-Schritt) | Ja (manuelles Crawlen) | N/V |
| Cloud-Scraping | Ja | Nein | Ja (kostenpflichtig) | Ja (kostenpflichtig) | Ja (kostenpflichtig) | Nein | Cloud-gestützte Analysen |
| Planung | Ja | Nein | Ja (kostenpflichtig) | Ja (kostenpflichtig) | Ja (kostenpflichtig) | Nein | Ja (Keyword-/Ranking-Tracking) |
| Kostenloser Tarif | Ja (6–10 Seiten) | Ja (vollständig kostenlos) | Ja (nur Browser) | Ja (eingeschränkt) | Ja (2 Stunden Laufzeit) | Ja (500 Seiten/Monat) | Ja (eingeschränkt) |
| Vorgefertigte Amazon-Vorlage | Ja | Nein | Ja | Ja | Ja (Anleitungen) | Rezeptbibliothek | N/V |
| Export zu Sheets/Airtable/Notion | Ja (alle) | Nur CSV/Excel | CSV, Excel, JSON; Sheets über Cloud | CSV, Excel, JSON, mehr | Google Sheets, CSV | CSV, Excel; Sheets in kostenpflichtigen Plänen | CSV, Excel |
Ein paar Dinge stechen heraus. Thunderbit ist die einzige Erweiterung mit KI-Felderkennung und der breitesten Exportauswahl im kostenlosen Tarif. Instant Data Scraper ist die einfachste Gratisoption, wird aber nicht mehr gepflegt. Web Scraper und Octoparse sind leistungsstark für alle, die Zeit in die Einrichtung stecken, aber keines ist ein reines „installieren und loslegen“-Erlebnis. Axiom.ai passt am besten für mehrstufige Automatisierung jenseits des Scrapings. Data Miner ist einfach, wenn man vorhandene Rezepte ausführt, doch der kostenlose Tarif ist knapp. Helium 10 ist ein Intelligence-Tool für Verkäufer, kein allgemeiner Scraper.
Cloud- vs. Browser-Scraping für Amazon: Was Sie zum Sperrrisiko wissen müssen
Das ist das Thema, um das alle herumreden. Amazon erkennt und blockiert automatisiertes Scraping aktiv. Nutzer auf Reddit berichten, dass CAPTCHAs schon bei geringem Scraping-Volumen auftauchen, und Amazons eigene Nutzungsbedingungen sagen ausdrücklich, dass die Lizenz keine „Verwendung von Data-Mining-, Robotern oder ähnlichen Tools zur Datenerfassung und -extraktion“ umfasst.
Was ist also der praktische Unterschied zwischen Browser- und Cloud-Scraping?
- Browser-Scraping läuft in Ihrer eigenen Chrome-Sitzung – echte Cookies, eingeloggter Status, natürliches Surfverhalten. Es wirkt bei geringem Volumen menschlicher, blockiert aber Ihren Browser.
- Cloud-Scraping nutzt entfernte Server für Tempo (Thunderbit verarbeitet im Cloud-Modus 50 Seiten gleichzeitig), braucht aber Ratenbegrenzung und Proxy-Rotation, um nicht erkannt zu werden.
Die Entscheidungs-Matrix, die ich nutze:
| Szenario | Empfohlener Modus | Warum |
|---|---|---|
| 20 Produktseiten für Recherche scrapen | Browser | Geringes Volumen, natürliches Verhalten |
| 500 Konkurrenz-SKUs wöchentlich überwachen | Cloud | Geschwindigkeit zählt, öffentliche Daten |
| Beim Einloggen in Seller Central scrapen | Browser | Benötigt Ihre Login-Sitzung |
| Einmaliger Massenexport einer Kategorie | Cloud | Paralleles Scraping für mehr Tempo |
Unter den sieben Erweiterungen gibt es Cloud-Scraping bei Thunderbit, Web Scraper (kostenpflichtig), Octoparse (kostenpflichtig), Axiom.ai (kostenpflichtig) und Helium 10 (für seine Analysen). Instant Data Scraper und Data Miner laufen nur im Browser.
Praktische Tipps gegen das Sperrrisiko: Halten Sie vernünftige Abstände zwischen den Anfragen, scrapen Sie möglichst nicht zu Spitzenzeiten und rotieren Sie User Agents, sofern Ihr Tool das unterstützt. Und rechnen Sie nie mit „null Risiko“ – managen Sie es nur besser.
Von der Listing-Seite zur Produktdetailseite: So funktioniert Unterseiten-Scraping auf Amazon
Dieser Workflow wird unterschätzt – und kein konkurrierender Artikel zeigt ihn von Anfang bis Ende.
Beim Scrapen einer Amazon-Suchergebnisseite bekommen Sie zusammenfassende Daten: Produkttitel, Preise, Bewertungen, ASINs und Produkt-URLs. Oft brauchen Sie aber auch Daten von der Detailseite – vollständige Beschreibungen, Stichpunkte, Bild-URLs, Verkäuferinformationen, Aufschlüsselungen der Rezensionen. Genau dafür ist Unterseiten-Scraping da.
Mit Thunderbit läuft der Workflow so:
- Amazon-Suchergebnisseite scrapen -> Sie erhalten eine Produkttabelle (Titel, Preis, Bewertung, ASIN, Produkt-URL).
- Auf „Unterseiten scrapen“ klicken -> Thunderbit besucht jede Produkt-URL und ergänzt Detailfelder (Beschreibung, Anzahl der Rezensionen, Verkäufername, Bild-URLs usw.) in derselben Tabelle.
- Die angereicherte Tabelle exportieren nach Google Sheets, Airtable, Notion oder Excel.
Die KI erkennt die Struktur der Unterseite und reichert die Tabelle automatisch an – ganz ohne manuelle Konfiguration. Aus meiner Erfahrung spart das pro Batch mindestens eine Stunde gegenüber dem manuellen Öffnen jeder Produktseite und dem einzelnen Kopieren der Felder.
Andere Tools können das ebenfalls, aber mit mehr Aufwand:
- Web Scraper: Sie konfigurieren eine Sitemap, die Produktlinks folgt, und definieren Selektoren für jedes Detailfeld. Es funktioniert, ist aber manuell und mehrstufig.
- Octoparse: Sie bauen einen Workflow mit Link-Folge-Schritten. Leistungsfähig, aber nicht mit einem Klick.
- Axiom.ai: Sie gestalten eine Bot-Schleife, die jede URL besucht und Daten extrahiert. Flexibel, aber Bot-Building-Kenntnisse vorausgesetzt.
- Data Miner: Sie nutzen Crawl Scrape, um gespeicherte URLs zu besuchen und ein zweites Rezept anzuwenden. Manuell und rezeptabhängig.
- Instant Data Scraper und Helium 10: kein Workflow zur Unterseiten-Anreicherung.
Wer regelmäßig Daten sowohl auf Listing- als auch auf Detailseiten-Ebene braucht, sollte ein Tool wählen, das diesen Workflow einfach macht – nicht nur irgendwie ermöglicht.
Die ehrliche Aufschlüsselung des kostenlosen Tarifs: Was Sie wirklich ohne Bezahlung bekommen
Danach fragen Nutzer in Foren häufiger als nach allem anderen, und kein Konkurrenzartikel antwortet transparent.
| Erweiterung | Kostenloser Tarif | Was Sie kostenlos bekommen | Wann ein Upgrade nötig ist |
|---|---|---|---|
| Thunderbit | Ja (6 Seiten, 10 mit Test) | KI-Feldvorschläge, alle Exportformate (Excel, Sheets, Airtable, Notion), E-Mail-/Telefon-Extraktor | Mehr Seiten oder geplantes Scraping erforderlich |
| Instant Data Scraper | Ja (vollständig kostenlos) | Einfache Tabellenerkennung, CSV-/Excel-Export | N/V (kein kostenpflichtiger Tarif, aber auch keine Updates) |
| Web Scraper | Ja (nur Browser) | Browser-Scraping, CSV-Export | Cloud-Scraping, Planung, Integrationen |
| Octoparse | Ja (eingeschränkt) | Ca. 50.000 Exporte/Monat, lokale Extraktion | Mehr Datensätze, Cloud-Nodes |
| Axiom.ai | Ja (2 Stunden Laufzeit) | Einfache Automatisierungen, Google Sheets | Mehr Läufe, Planung, Cloud |
| Data Miner | Ja (500 Seiten/Monat) | Rezepte, CSV/Excel, Next Page Automation | Mehr Seiten, Sheets, Crawl-Funktionen |
| Helium 10 | Ja (eingeschränkt) | Eingeschränkter Zugriff auf die Chrome-Erweiterung | Vollständiges Xray, Keyword-Tools, Planung |
Das Wichtigste: Der kostenlose Tarif von Thunderbit umfasst KI-Funktionen und alle Exportformate – die meisten Wettbewerber sperren erweiterte Exporte oder KI hinter Bezahlplänen. Instant Data Scraper ist komplett kostenlos, hat aber keine KI, keine Unterseiten und keine Planung (und wird nicht mehr gepflegt). Helium 10 hat zwar einen kostenlosen Plan, doch der Zugriff auf die Erweiterung ist limitiert und es ist kein allgemeiner Scraper.
Meine Empfehlung nach Szenario:
- „Ich will es einfach ausprobieren“ -> Instant Data Scraper (vollständig kostenlos) oder der kostenlose Tarif von Thunderbit
- „Ich brauche regelmäßiges, zuverlässiges Scraping“ -> Thunderbit oder die kostenpflichtigen Pläne von Web Scraper
- „Amazon-Verkäufer und Marktintelligenz nötig“ -> Helium 10
Welche Amazon-Scraper-Chrome-Erweiterung sollten Sie wählen?
Nach dem Test aller sieben lautet meine ehrliche Einschätzung:
- Am besten für nicht-technische Nutzer, die schnelle, KI-gestützte Ergebnisse wollen: Thunderbit. Die KI erkennt Felder automatisch, Unterseiten werden mit einem Klick angereichert, die Exportoptionen sind am breitesten, und es gibt den Cloud-/Browser-Umschalter. Wer von der Amazon-Seite in unter zwei Minuten zur Tabelle kommen will, liegt hier richtig.
- Beste komplett kostenlose Option für schnelle Einmal-Scrapes: Instant Data Scraper. Kein Preis, kein Konto, aber eingeschränkte Funktionen und keine Pflege mehr.
- Am besten für Nutzer, die manuelle Konfiguration gewohnt sind: Web Scraper. Flexibler Sitemap-Builder, gute Cloud-Option, gut dokumentiert.
- Am besten für komplexe, mehrstufige Scraping-Pipelines: Octoparse (Desktop + Erweiterung) oder Axiom.ai (Browser-Bots). Beide stark, aber keines eine reine „installieren und loslegen“-Chrome-Erweiterung.
- Am besten für einfache extraktionsbasierte Rezepte: Data Miner. Einfach mit bestehenden Rezepten, aber begrenzter kostenloser Tarif und keine KI.
- Am besten für Amazon-Seller-Intelligence, nicht für allgemeines Scraping: Helium 10. Speziell dafür gebaut, tiefe proprietäre Daten, aber teuer und kein allgemeiner Scraper.
Wenn Sie sehen wollen, wie KI-gestütztes Amazon-Scraping wirklich aussieht, testen Sie den kostenlosen Tarif von Thunderbit. Ich vermute, Sie werden überrascht sein, wie viel mit nur wenigen Klicks geht. Und passt Thunderbit nicht perfekt, probieren Sie ein paar andere aus dieser Liste. So oder so ersparen Sie sich das manuelle Kopieren.
Für weitere Tipps zum Amazon-Scraping sehen Sie sich unsere Anleitungen an: Amazon-Produkte und Bewertungen scrapen, Amazon-Preise scrapen und Amazon-Verkaufsdaten extrahieren und analysieren. Tutorials gibt es außerdem auf dem Thunderbit-YouTube-Kanal.
KI-gestütztes Amazon-Scraping mit Thunderbit ausprobieren Get Started Free
FAQs
1. Ist es legal, Amazon-Produktdaten zu scrapen?
Das Scrapen öffentlich sichtbarer Daten ist grundsätzlich zulässig, aber Amazons Nutzungsbedingungen verbieten Data Mining und automatisierte Extraktion ohne schriftliche Zustimmung ausdrücklich. Dieser Artikel ist keine Rechtsberatung – prüfen Sie Amazons Bedingungen stets, bevor Sie in großem Umfang scrapen.
2. Kann Amazon Chrome-Erweiterungs-Scraper erkennen und blockieren?
Ja. Amazon verfügt über Anti-Bot-Systeme, die CAPTCHAs auslösen, Anfragen drosseln oder IPs sperren können. Vernünftige Anfragelimits, browserbasiertes Scraping für kleine Jobs und Cloud-Scraping mit Ratenbegrenzung für größere Jobs senken das Risiko. Die praktische Entscheidungsmatrix finden Sie oben im Abschnitt zu Cloud vs. Browser.
3. Welche Daten kann man mit einer Chrome-Erweiterung von Amazon scrapen?
Zu den üblichen Feldern zählen Produkttitel, Preise, Bewertungen, Anzahl der Rezensionen, ASINs, Verkäufernamen, Beschreibungen, Bild-URLs, Verfügbarkeit und Versandinformationen. KI-gestützte Tools wie Thunderbit erkennen und schlagen diese Felder automatisch vor, ganz ohne manuelle Einrichtung.
4. Brauche ich Programmierkenntnisse, um eine Amazon-Scraper-Chrome-Erweiterung zu verwenden?
Nein – alle sieben getesteten Tools sind für nicht-technische Nutzer ausgelegt. Manche erfordern mehr Einrichtung (Web Scraper, Octoparse, Axiom.ai), andere kommen fast ohne Konfiguration aus (Thunderbit, Instant Data Scraper). Der Kompromiss heißt meist Flexibilität gegen Benutzerfreundlichkeit.
5. Welche Amazon-Scraper-Chrome-Erweiterung hat den besten kostenlosen Tarif?
Der kostenlose Tarif von Thunderbit umfasst KI-Felderkennung und alle Exportformate (Sheets, Airtable, Notion, Excel, CSV, JSON), die die meisten Wettbewerber hinter Bezahlplänen verstecken. Instant Data Scraper ist komplett kostenlos, hat aber keine KI, keine Unterseiten und keine Planung. Data Miner bietet 500 kostenlose Seiten pro Monat. Helium 10s kostenloser Plan ist eingeschränkt und auf Seller-Recherche fokussiert, nicht auf allgemeines Scraping.
Mehr erfahren




