Was ist ein Amazon-Web-Scraper
Ein Amazon-Web-Scraper ist ein praktisches Tool oder eine Software, die automatisch Daten von extrahiert. Dazu gehören etwa Produktdetails, Preise, Bewertungen, Lagerbestand und mehr. Das Hauptziel eines Amazon-Web-Scrapers ist es, große Datenmengen für Marktforschung, Preisvergleiche oder Wettbewerbsanalysen zu sammeln. Außerdem können Sie Nutzerbewertungen für die Keyword-Recherche erfassen, um die Vor- und Nachteile von Produkten besser zu verstehen.
Wichtige Funktionen eines Amazon-Web-Scrapers
- Automatisierte Datenerfassung: Verabschieden Sie sich von der mühsamen Aufgabe, Informationen manuell zu kopieren und einzufügen. Ein Web-Scraper kann die benötigten Daten automatisch von Webseiten holen.
- Anpassbares Scraping: Sie können den Scraper so anpassen, dass er bestimmte Datenfelder nach Bedarf extrahiert und gezielt analysierbar macht.
- Datenexport: Exportieren Sie die gesammelten Daten ganz einfach in gängige Formate wie Excel, CSV oder JSON, um sie mit verschiedenen Daten-Tools weiterzuverarbeiten.
- Regelmäßige Aktualisierungen: Legen Sie feste Intervalle für das Scraping fest, um Ihre Amazon-Produktdatenbank aktuell zu halten und immer mit frischen Daten zu arbeiten.
- Bewertungs-Scraping: Häufig müssen die Vor- und Nachteile aus den Bewertungen für eine Wettbewerbsanalyse herausgefiltert werden.

Warum einen Amazon-Web-Scraper verwenden
Amazon ist ein wichtiger Akteur im globalen E-Commerce und bekannt für seine riesige Produktauswahl, wettbewerbsfähige Preise und ein reibungsloses Einkaufserlebnis. Die Plattform ermöglicht es Unternehmen, potenzielle Kundinnen und Kunden weltweit zu erreichen und ihre Marktreichweite zu vergrößern. Verbraucher vertrauen Amazon als wichtigem Online-Einkaufsziel und bieten Händlern damit ein verlässliches Verkaufsumfeld. Außerdem ermöglicht Amazons Logistiknetzwerk Unternehmen, schnelle und effiziente Lieferdienste zu nutzen, was die Kundenzufriedenheit steigert. Amazon stellt darüber hinaus verschiedene Marketing-Tools bereit, um die Sichtbarkeit und den Absatz von Produkten zu erhöhen, etwa Sponsored-Product-Anzeigen und Markenaktionen.
Für E-Commerce-Unternehmen ist die Analyse von Verkaufsdaten auf Amazon entscheidend. Mit einem Amazon-Web-Scraper können Unternehmen Daten sammeln, um Einblicke in Markttrends und Kundenverhalten zu gewinnen sowie Produktstrategien und Bestandsmanagement zu optimieren. So lassen sich Unternehmen auf der Amazon-Plattform besser skalieren, der Umsatz steigern und die Markenbekanntheit für nachhaltiges Wachstum ausbauen. So können Sie einen Amazon-Web-Scraper für Analysen einsetzen:
Marktforschung
-
SKU-Auswahl
Die Wahl der richtigen SKU (Stock Keeping Unit) ist entscheidend für den Erfolg im E-Commerce und wirkt sich auf Produktsortiment, Effizienz der Lieferkette und Bestandsmanagement aus. Mit einem Amazon-Web-Scraper können Sie präzise Daten aus Millionen von Produkten extrahieren, um Verkaufsentwicklungen und Kundenpräferenzen zu analysieren. Wenn Sie etwa Amazons Produktdetailseiten scrapen, erhalten Sie schnell wichtige Informationen wie Produktpreise, Anzahl der Bewertungen und Händlerbewertungen für eine fundierte Marktanalyse. Diese Daten helfen zu bestimmen, ob eine SKU Marktpotenzial hat, und zeigen, welche Produkte am besten performen. Durch den Vergleich von Produkten innerhalb derselben Kategorie können Unternehmen ihre Produktauswahl optimieren, den Bestand für beliebte SKUs erhöhen und Lagerbestände langsamer verkaufter Artikel reduzieren, was die Lagerumschlagshäufigkeit verbessert.
-
Kundentrends identifizieren
Durch das Scrapen großer Mengen an Produktbewertungen, Sternebewertungen und Kundenfeedback kann ein Web-Scraper Ihnen helfen, Veränderungen in der Nachfrage schnell zu erkennen. Wenn Sie beispielsweise Bewertungsdaten analysieren, können Sie herausfinden, welche Merkmale Verbraucher an einem Produkt am meisten schätzen, etwa „günstiger Preis“ oder „Langlebigkeit“. Diese Informationen sind entscheidend für Produktentwicklung, Preisstrategie und Marketingstrategie. Darüber hinaus können Sie durch das Scrapen von Daten zu Kaufhäufigkeit und Verkaufsentwicklungen im Zeitverlauf saisonale Schwankungen vorhersagen und Bestands- sowie Marketingmaßnahmen im Voraus planen.

Wettbewerbsanalyse
-
Preisüberwachung
In einem wettbewerbsintensiven Umfeld ist die Preisüberwachung für E-Commerce-Unternehmen unverzichtbar. Ein Amazon-Web-Scraper hilft Ihnen dabei, Produktdaten in Echtzeit zu scrapen und Preisänderungen der Konkurrenz nachzuverfolgen, damit Ihre Preise wettbewerbsfähig bleiben. Diese Funktion ist besonders wertvoll für dynamische Preisstrategien. Durch das Sammeln von Preisinformationen zu ähnlichen Produkten können Unternehmen flexible Preismodelle entwickeln, die Preise automatisch an Marktnachfrage, Lagerbestände und Konkurrenzpreise anpassen, um den Gewinn zu maximieren.
-
Bewertungen scrapen
beeinflussen nicht nur den Produktabsatz, sondern spiegeln auch Veränderungen der Marktnachfrage wider. Ein Amazon-Web-Scraper hilft Unternehmen dabei, große Mengen an Kundenfeedback zu sammeln. KI-basierte Web-Scraper können beim Zusammenfassen und bei der Stimmungsanalyse unterstützen, um Einblicke in die Meinungen der Nutzer zu Ihren Produkten und denen der Konkurrenz zu gewinnen, sodass Sie Produktdesign oder Marketingstrategie rechtzeitig anpassen können.
Kostenvergleich
Mit einem Amazon-Web-Scraper können Unternehmen Daten zu Preisen, Versandkosten und Aktionen ähnlicher Produkte sammeln, um umfassende Kostenvergleiche durchzuführen. Die Analyse dieser Daten hilft Unternehmen, ihre Kostenstruktur zu optimieren, unnötige Ausgaben zu vermeiden und die Gewinnmargen zu erhöhen. Für Unternehmen, die auf Amazon nach Lieferanten suchen, bietet dies zudem Einblicke in unterschiedliche Versandgebühren und Verkaufspreise, senkt Kosten und sorgt für wettbewerbsfähige Preise am Markt, was letztlich die Bruttomarge verbessert.
KI für Web-Scraping ausprobieren
Probieren Sie es aus! Sie können klicken, erkunden und den Workflow ausführen, während Sie zusehen.
Warum KI zum Scrapen von Amazon-Produktdaten verwenden
Mit der rasanten Entwicklung von KI führen KI-gestützte Amazon-Web-Scraper eine neue Ära der Datenerfassung an und bieten gegenüber herkömmlichen Web-Scraping-Prozessen zahlreiche Vorteile. KI macht die Datenerfassung nicht nur effizienter und genauer, sondern senkt auch die technische Einstiegshürde deutlich und eröffnet E-Commerce-Unternehmen innovativere Möglichkeiten.
Benutzerfreundlich für Nicht-Techniker
Für Nutzer ohne technischen Hintergrund bieten KI-gestützte Amazon-Web-Scraper große Vorteile. Anders als herkömmliche Scraper, die manuelles Programmieren und API-Aufrufe erfordern, geben Nutzer einfach ihre Scraping-Anforderungen an und wählen die gewünschten Spaltennamen aus. KI erstellt automatisch passende Scraping-Pläne und Vorschläge, wodurch Programmieraufwand und komplexe Einstellungen entfallen. Diese benutzerfreundliche Funktion hilft E-Commerce-Teams, Daten effizient und ohne Fachpersonal zu gewinnen, steigert die Produktivität und ermöglicht es auch nicht-technischen Mitarbeitenden, fortschrittliche Datenerfassungstools problemlos zu nutzen.
Schnell und effizient
automatisieren den Datenerfassungsprozess und erhöhen Geschwindigkeit und Effizienz des Scrapings deutlich. Sie können komplexe Website-Strukturen und dynamische Inhalte schnell verarbeiten, Ziel-Daten präzise erfassen, manuelle Eingriffe reduzieren und die gesamte Genauigkeit des Scrapings verbessern. Außerdem können die Betriebskosten erheblich senken und Workflows optimieren, sodass Unternehmen hochwertige Daten zu geringeren Kosten erhalten und so Entscheidungen besser unterstützen können.
Intelligente Analyse und Vorschläge
Im Vergleich zu herkömmlichen Web-Scrapern bieten den Vorteil einer intelligenten Workflow-Automatisierung. KI-Tools können Daten automatisch kategorisieren, zusammenfassen und Erkenntnisse daraus ableiten. Unternehmen können KI beispielsweise nutzen, um verschiedene Produkte automatisch in vordefinierte Kategorien einzuordnen oder große Mengen an Bewertungsdaten zu analysieren, um Schlüsselwörter und Stimmungs-Trends zu extrahieren. So verstehen Unternehmen Kundenfeedback besser und können Produkte gezielter optimieren. KI kann auch maßgeschneiderte Berichte auf Basis der gesammelten Daten erstellen und automatisch Marktanalysen generieren, damit Unternehmen beliebte Produkteigenschaften und potenzielle Marktchancen schneller erkennen.
Intelligente Ausgabe- und Exportoptionen
Mit einem KI-basierten Amazon-Web-Scraper lassen sich Daten intelligenter ausgeben. Herkömmliche Programmiermethoden liefern meist nur CSV-Dateien, während KI-Tools neben CSV auch das automatische Exportieren der gescrapten Daten an Kollaborationsplattformen wie Google Sheets und Notion unterstützen, was die Datenanalyse und den Austausch deutlich erleichtert. Sie können die Daten beispielsweise direkt in Google Sheets für eine Echtzeitanalyse importieren oder in Team-Tools einbinden, sodass Informationen nahtlos zwischen Abteilungen fließen. Diese intelligente Exportmethode ermöglicht schnellere Entscheidungen und verbessert die Flexibilität und Reaktionsfähigkeit des Unternehmens insgesamt.
Scrapen mit : Der
ist ein neu eingeführtes, leistungsstarkes und umfassendes , das entwickelt wurde, um Ihre Datenanforderungen zu erfüllen. Mit Thunderbit können Nutzer mühelos Daten von Amazon erfassen, egal ob Produktdetails, Preisentwicklung oder Kundenbewertungen, und sie schnell in wertvolle Geschäftseinblicke umwandeln. So kann Thunderbit E-Commerce-Unternehmen helfen, ihre Wettbewerbsfähigkeit zu stärken.
Besuchen Sie zunächst die und fügen Sie die Thunderbit- in Ihrem Chrome-Browser hinzu. Melden Sie sich mit Ihrem Google-Konto oder einer anderen E-Mail-Adresse an.
 Als Nächstes können Sie den integrierten vorgefertigten Web-Scraper oder den von Thunderbit verwenden, um . So geht’s:
Als Nächstes können Sie den integrierten vorgefertigten Web-Scraper oder den von Thunderbit verwenden, um . So geht’s:
Option 1: Den vorgefertigten Web-Scraper von Thunderbit verwenden
hat verschiedene vorgefertigte Web-Scraper-Tools auf Basis der Nutzerbedürfnisse entwickelt und optimiert, darunter ein spezielles Scraper-Modul für Amazon. Diese Tools verfügen über vorab definierte Vorlagen für die komplexe Datenstruktur von Amazon und haben bereits große Datenmengen erfasst. So entfällt die Notwendigkeit, die Scraping-Logik selbst zu entwerfen, und der gesamte Prozess wird für eine schnellere und effizientere Datenerfassung beschleunigt.
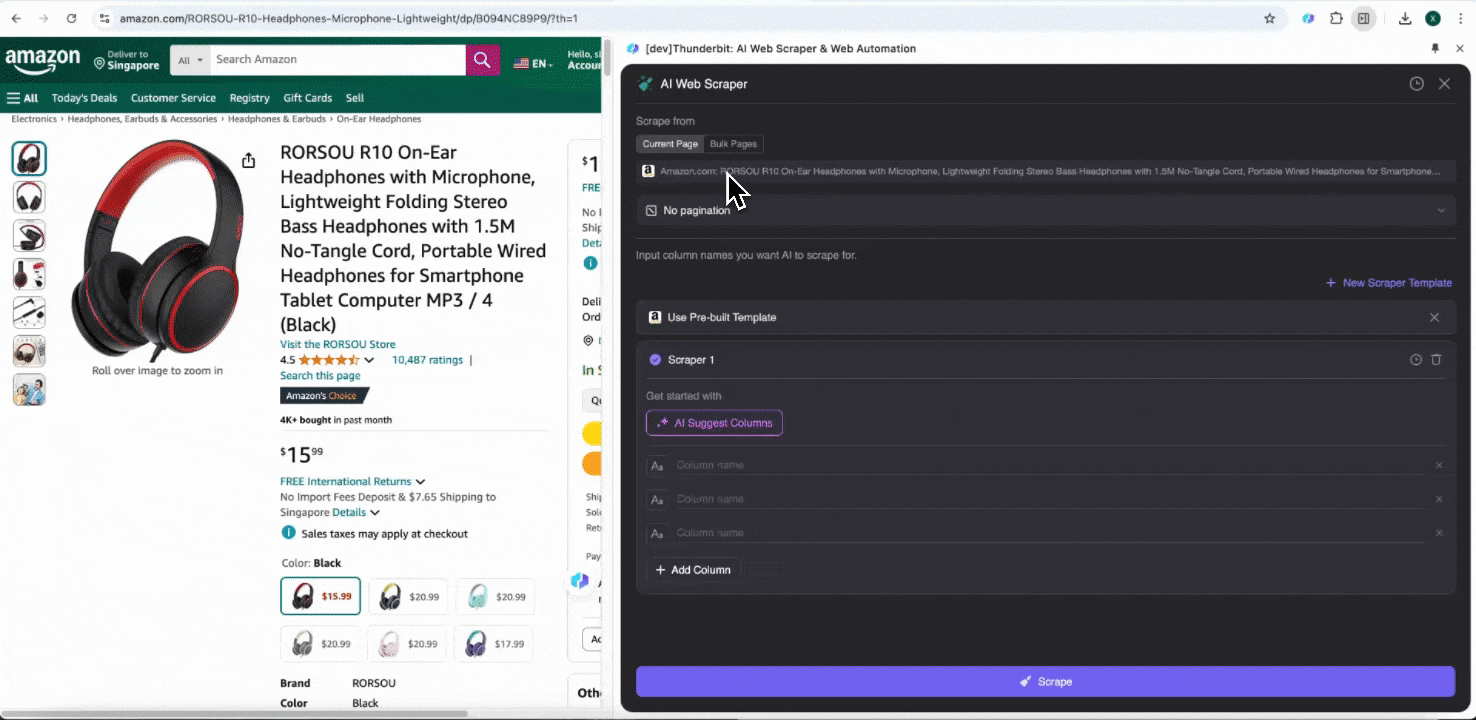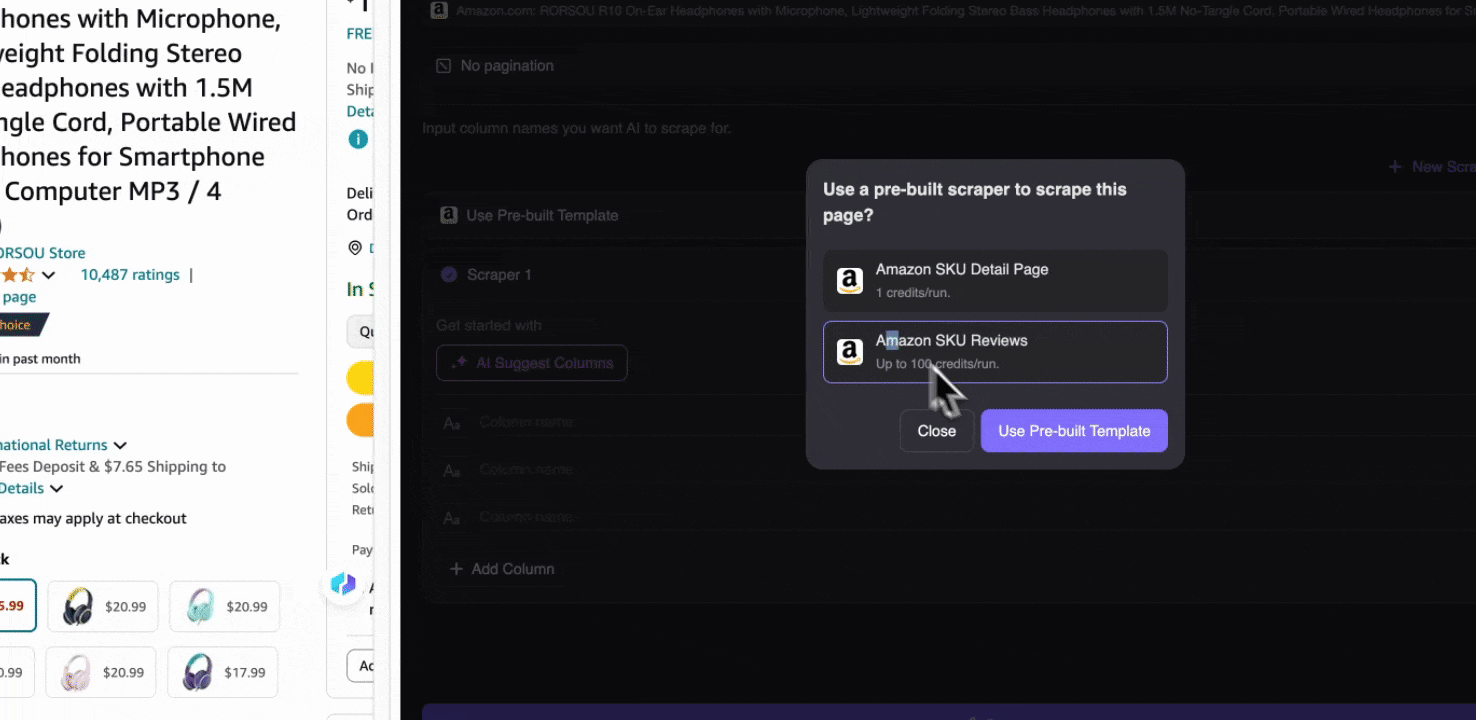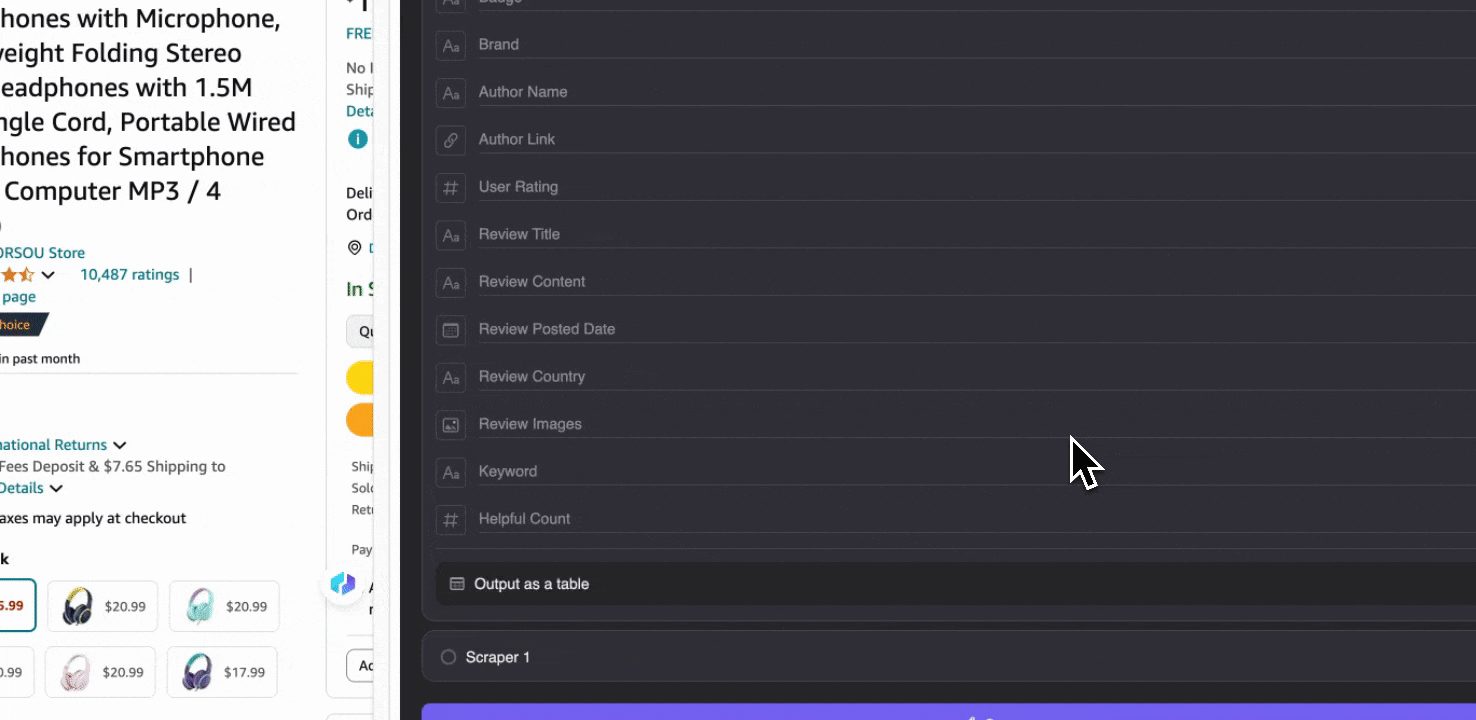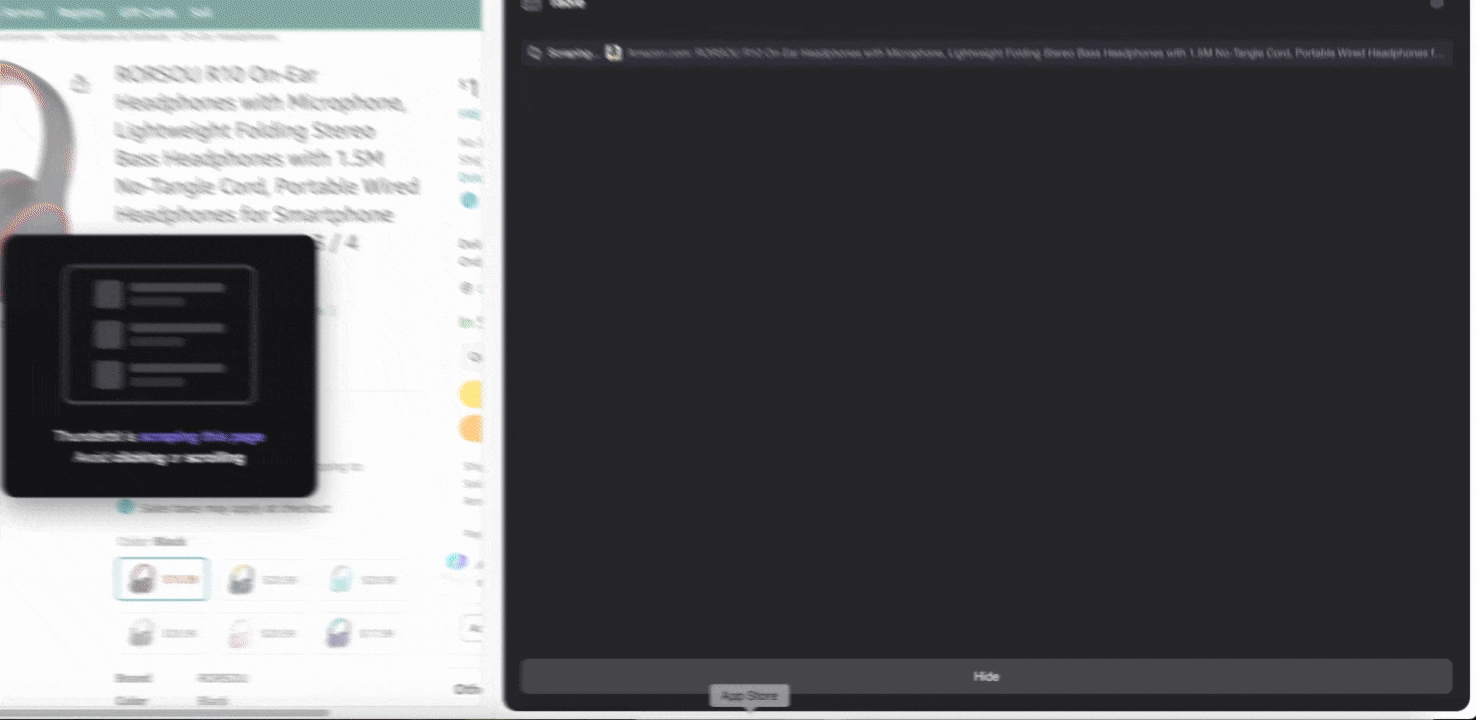
Wenn Sie eine beliebige Seite auf Amazon öffnen, öffnen Sie den Web-Scraper der Thunderbit-Erweiterung. Sie sehen zwei vorgefertigte Scraper mit umfangreichen Spaltennamen. Wählen Sie einfach die Spaltennamen aus, die Sie extrahieren möchten, und Thunderbit übernimmt den Rest.
-
Amazon SKU-Bewertungen erfassen
Dieses Tool bietet vorgefertigte Spaltennamen wie Produktname, Produkt-URL, Gesamtbewertung des Produkts, detaillierte Bewertungsaufschlüsselung, Anzahl der Produktbewertungen, Bewertungstitel, Autorenname, Bewertungstext, Bewertungsland und Schlüsselwörter. Sie können die Kästchen neben den Spaltennamen auswählen, die Sie extrahieren möchten, auf Scrapen klicken und erhalten schnell die benötigten SKU-Bewertungsdaten für die Produktanalyse.
-
Amazon SKU-Details erfassen
Dieses Tool bietet vorgefertigte Spaltennamen wie Produktname, Produkt-URL, Marke, Hersteller, Anfangspreis, Endpreis, Beschreibung, Bewertung, Kategorien, Lieferoptionen und Händler-URL. Wählen Sie die gewünschten Spalten aus, klicken Sie auf Scrapen und erhalten Sie schnell die benötigten SKU-Detaildaten. Ob Sie Händler, Hersteller und Lieferoptionen vergleichen, Marktforschung betreiben, die Preiswettbewerbsfähigkeit Ihrer SKU bewerten oder die neuesten Verkaufstrends verstehen möchten – diese SKU-Detaildaten unterstützen Ihre Analyse.
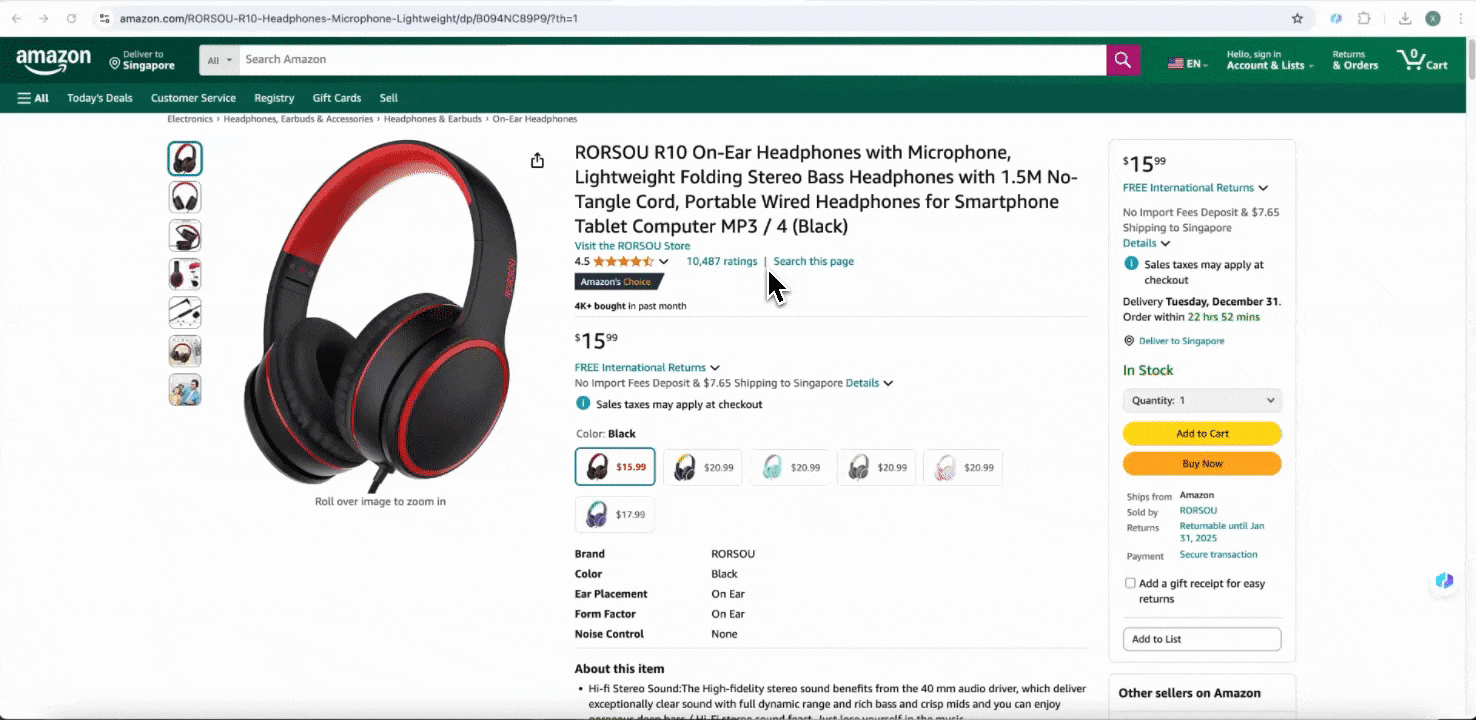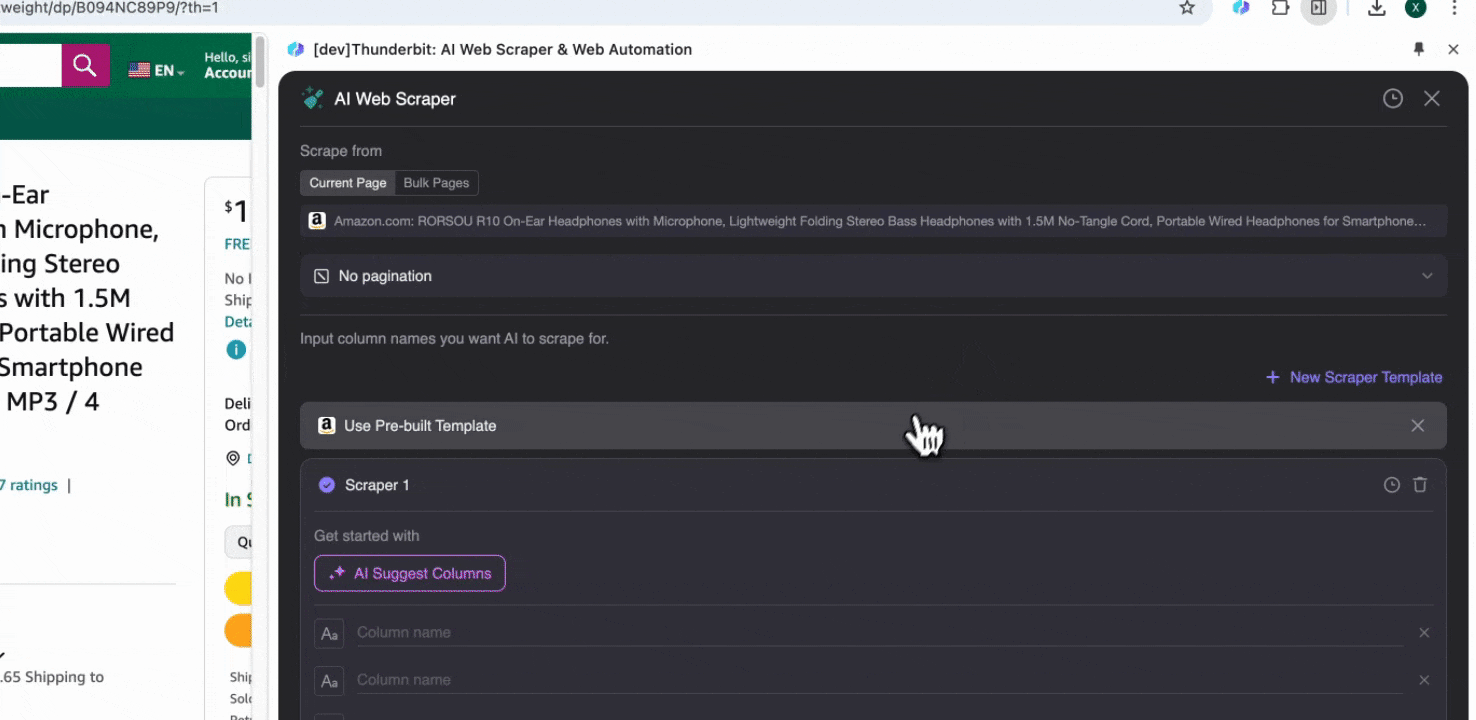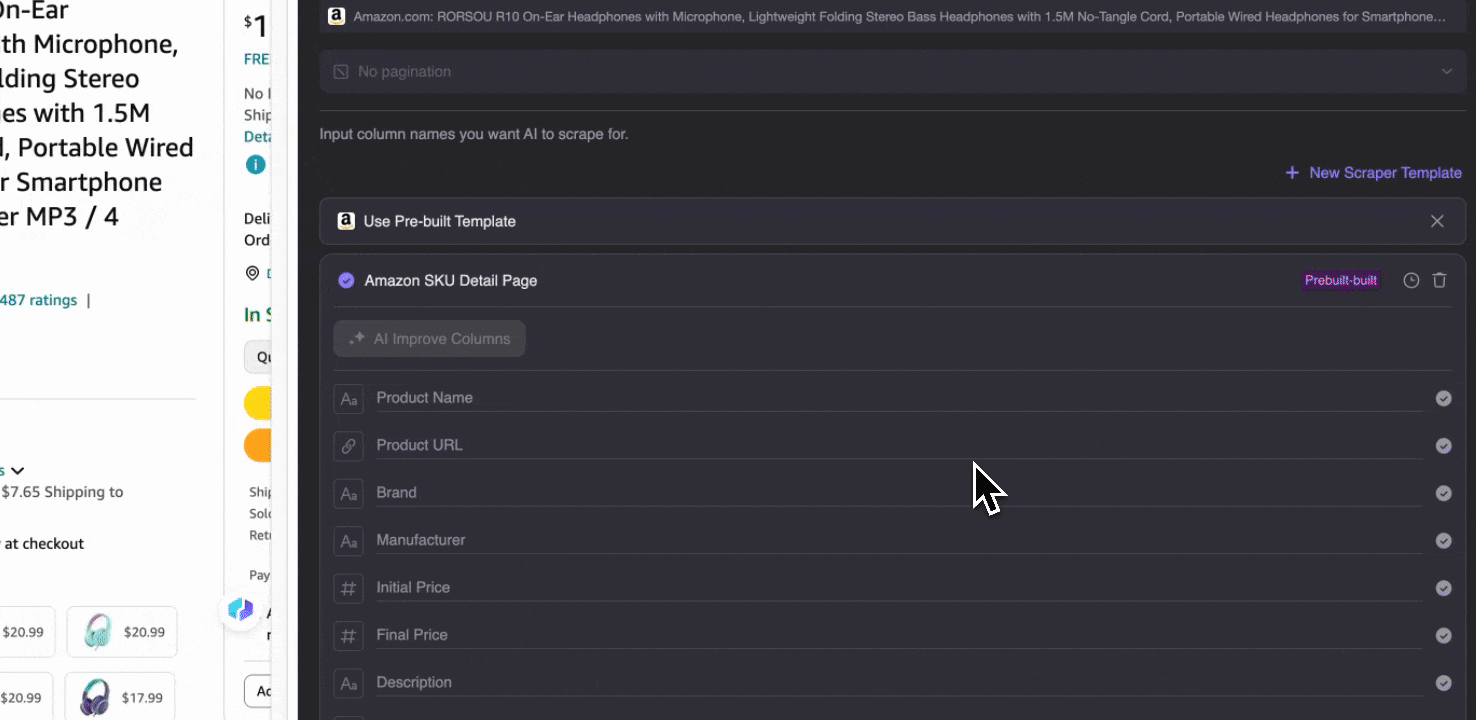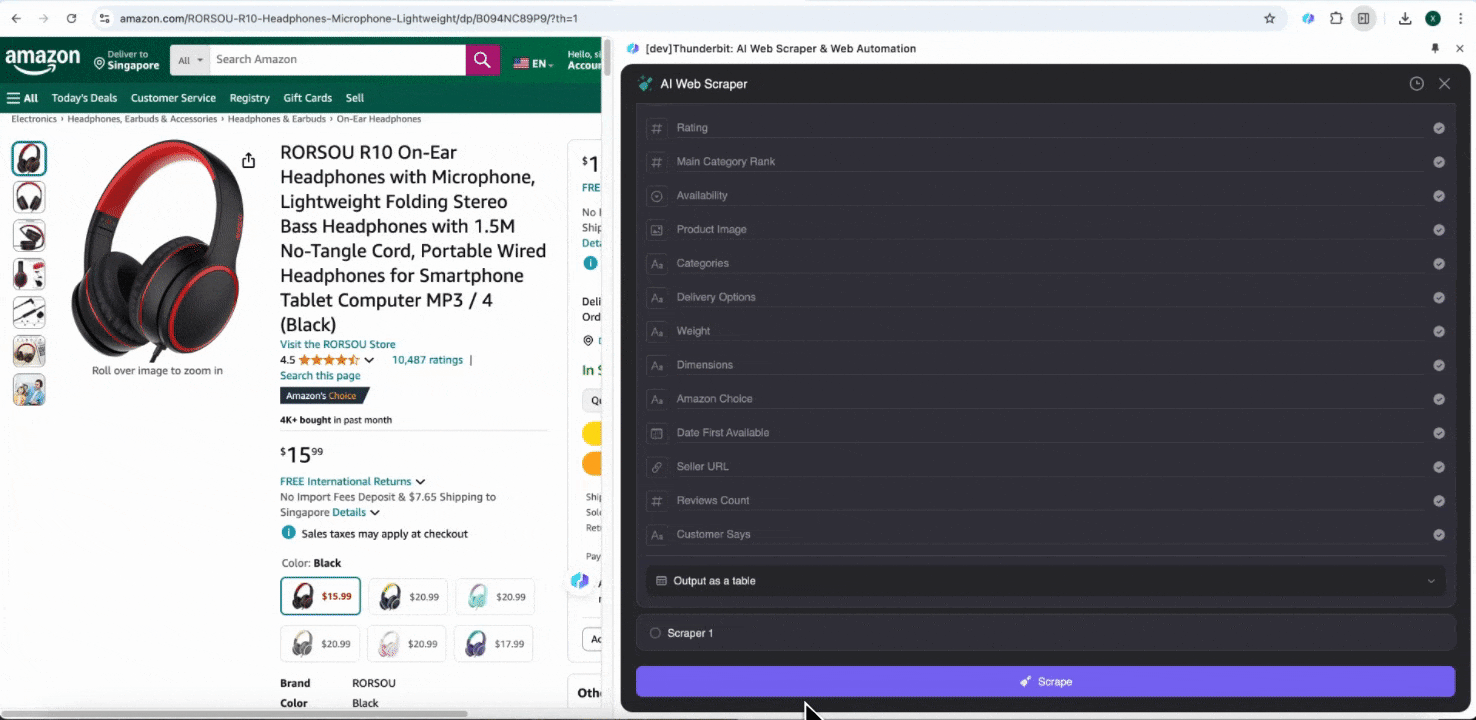
Option 2: Den KI-Web-Scraper von Thunderbit verwenden
Schritt 1: Öffnen Sie und klicken Sie in der Seitenleiste auf „“
Öffnen Sie die in Ihrem Chrome-Browser, suchen Sie oder navigieren Sie zu der Seite, von der Sie Daten extrahieren möchten, und klicken Sie dann auf das Thunderbit-Symbol oben rechts in Ihrem Chrome-Browser, um die Thunderbit-Erweiterung zu öffnen, und klicken Sie auf „“.
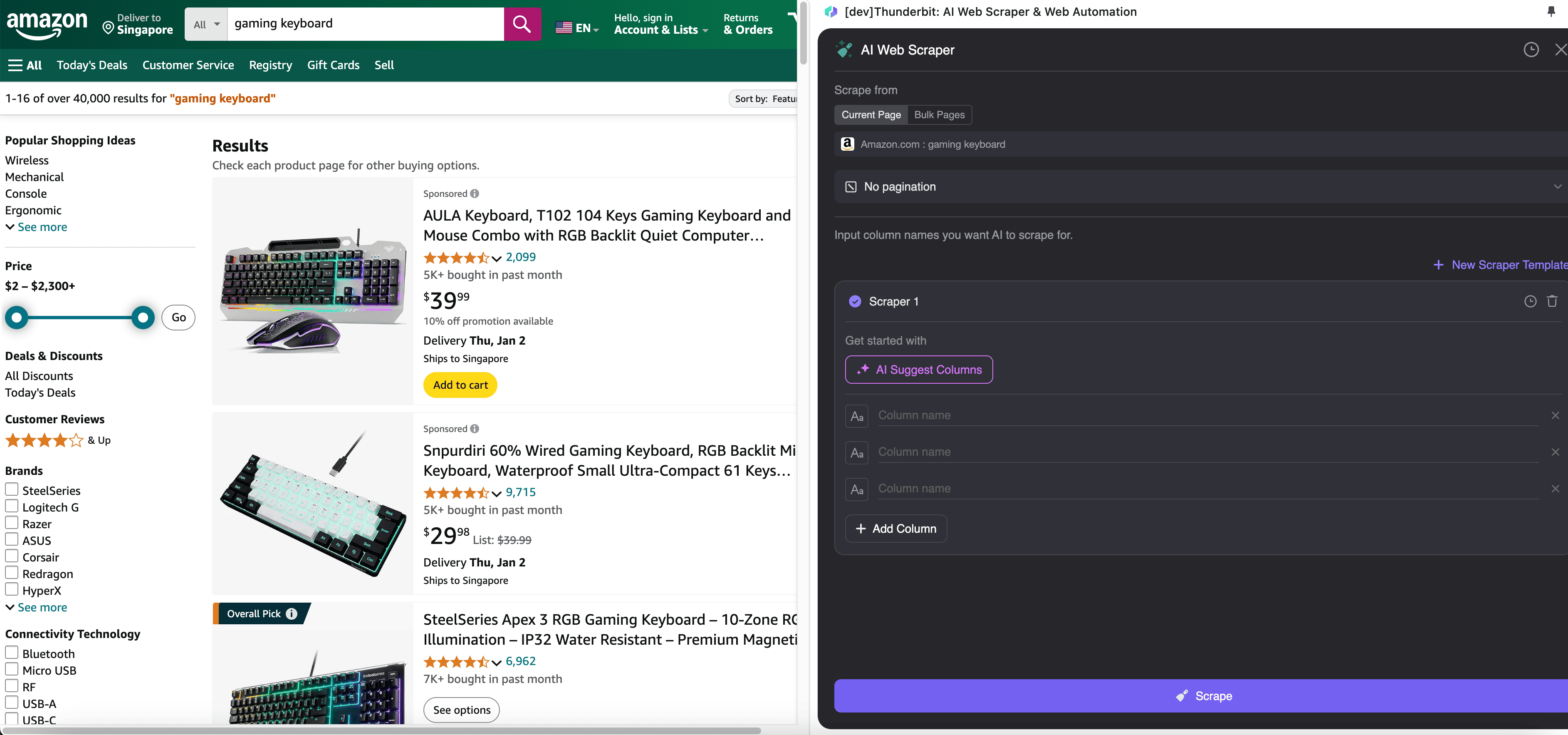
Schritt 2: Passen Sie die gewünschten Datenfelder an
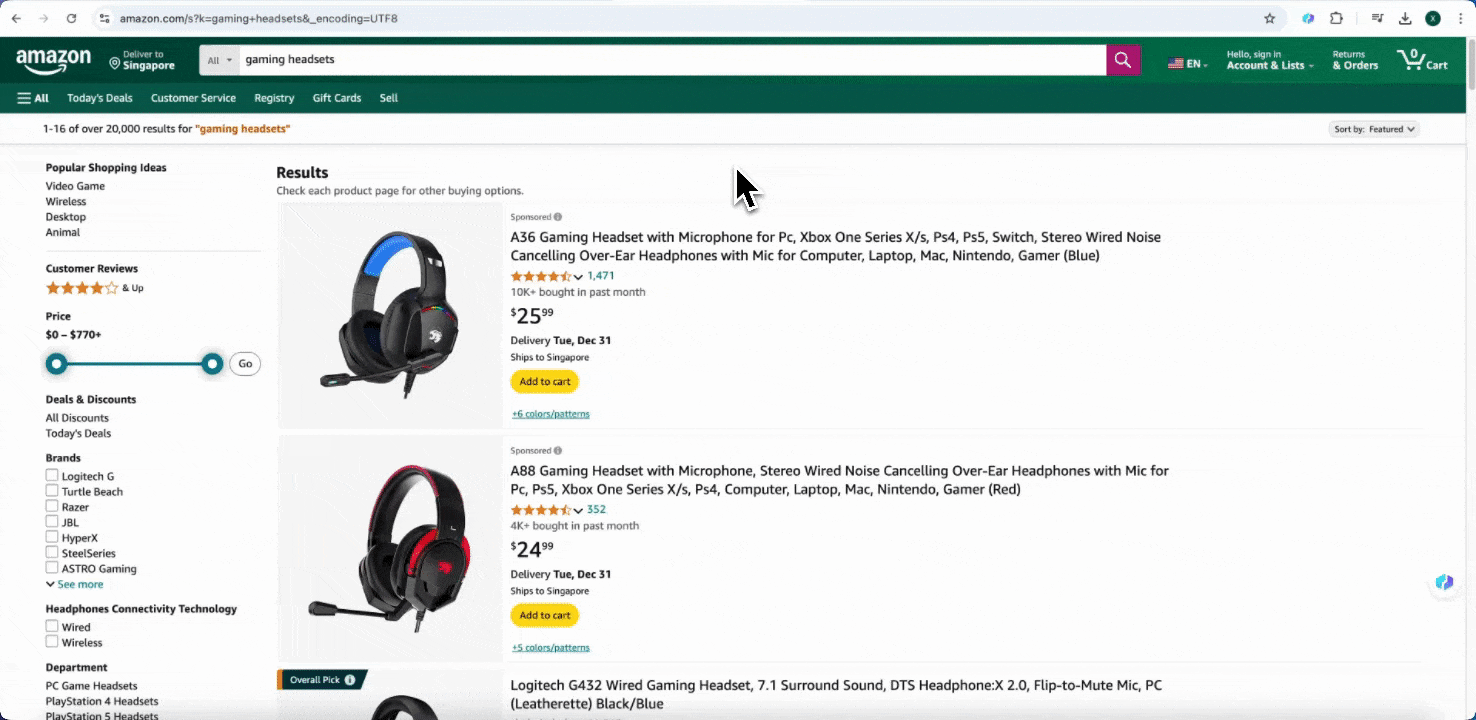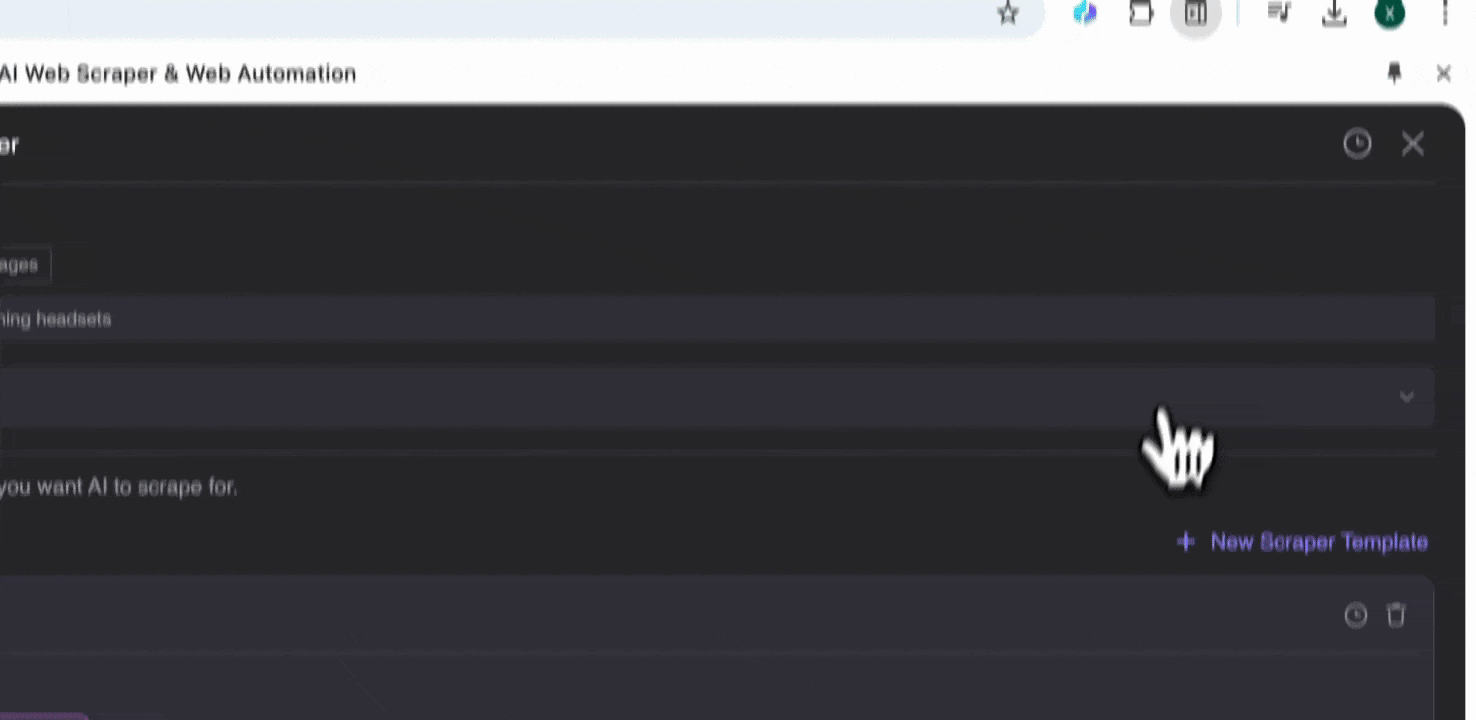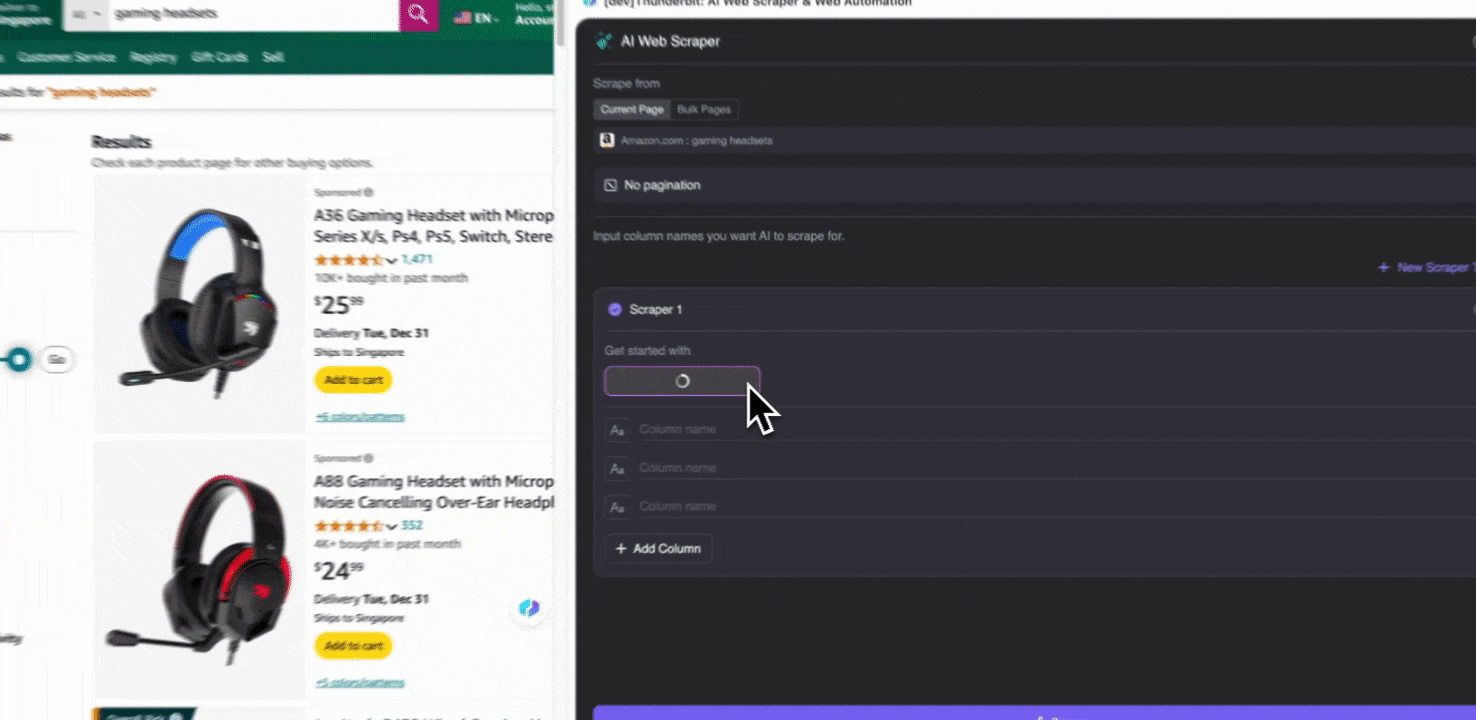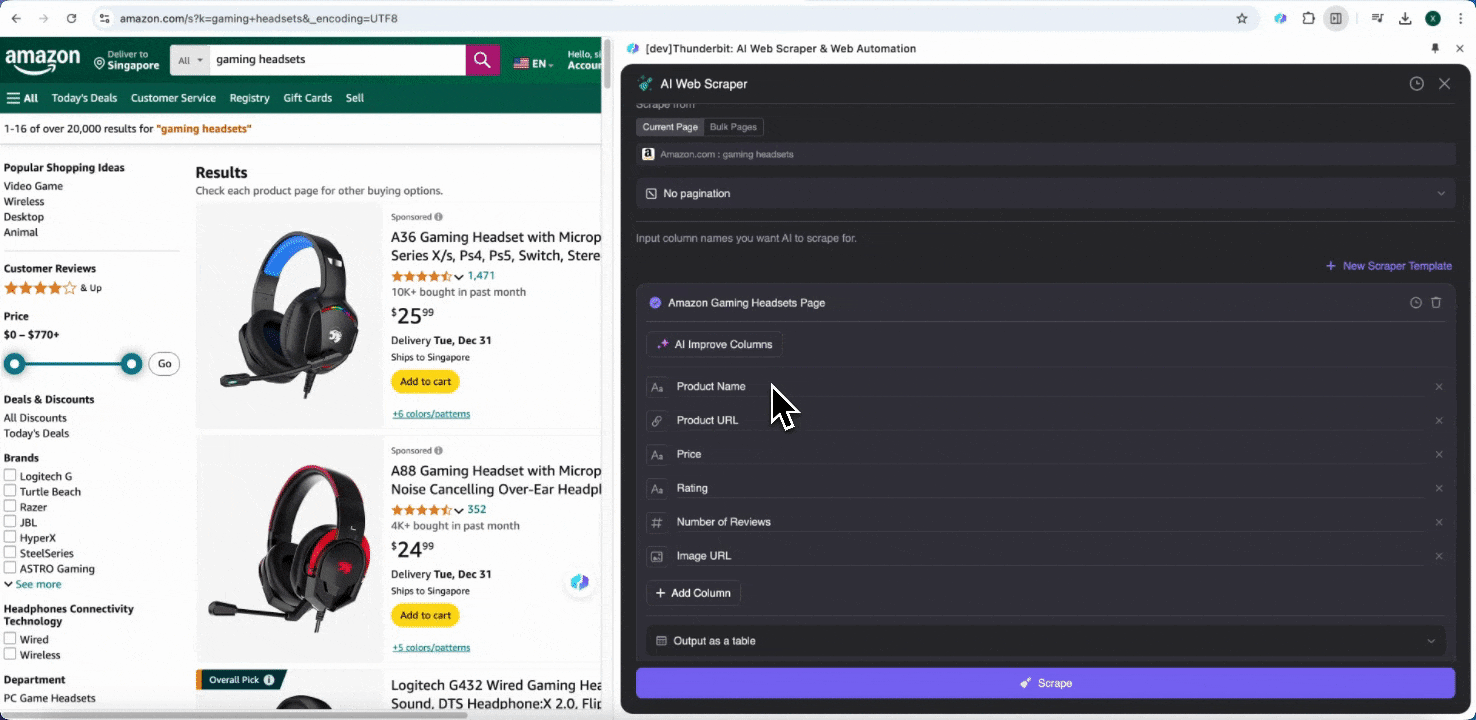
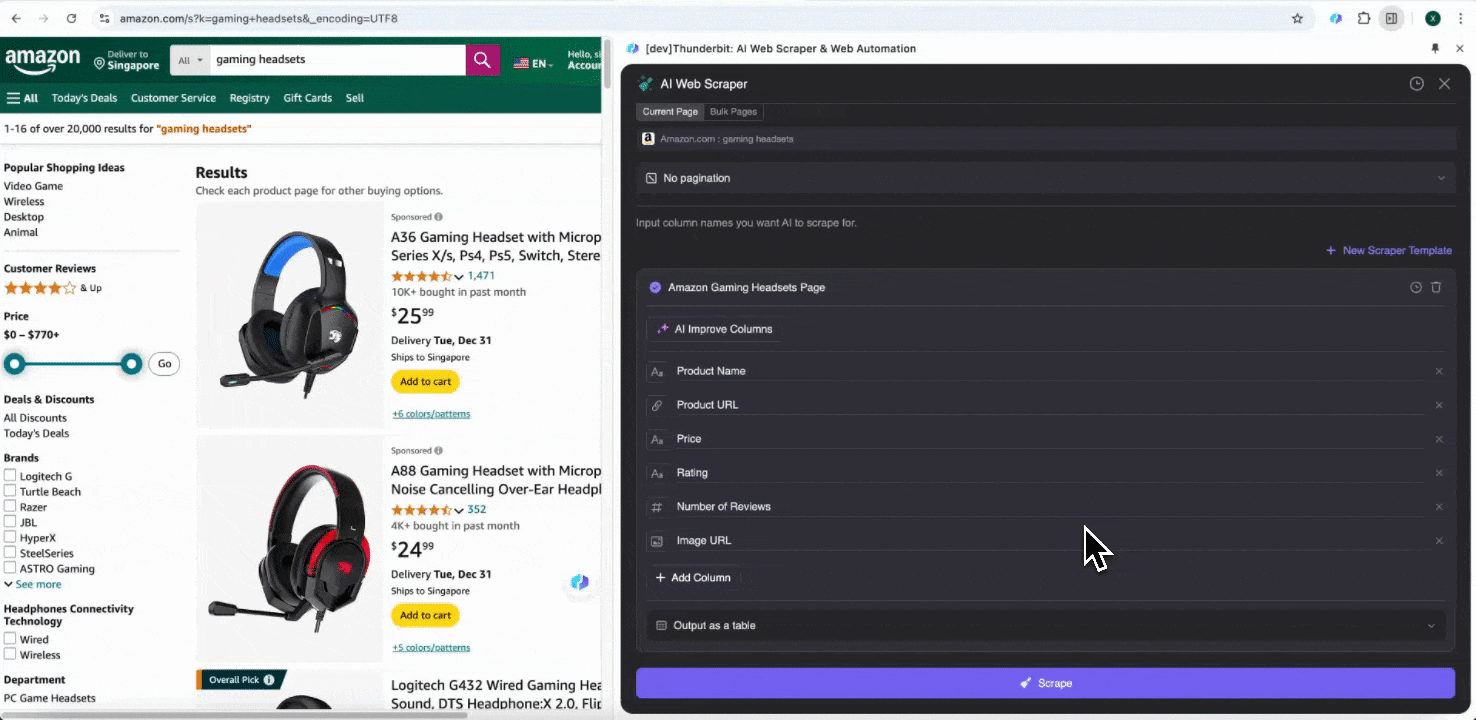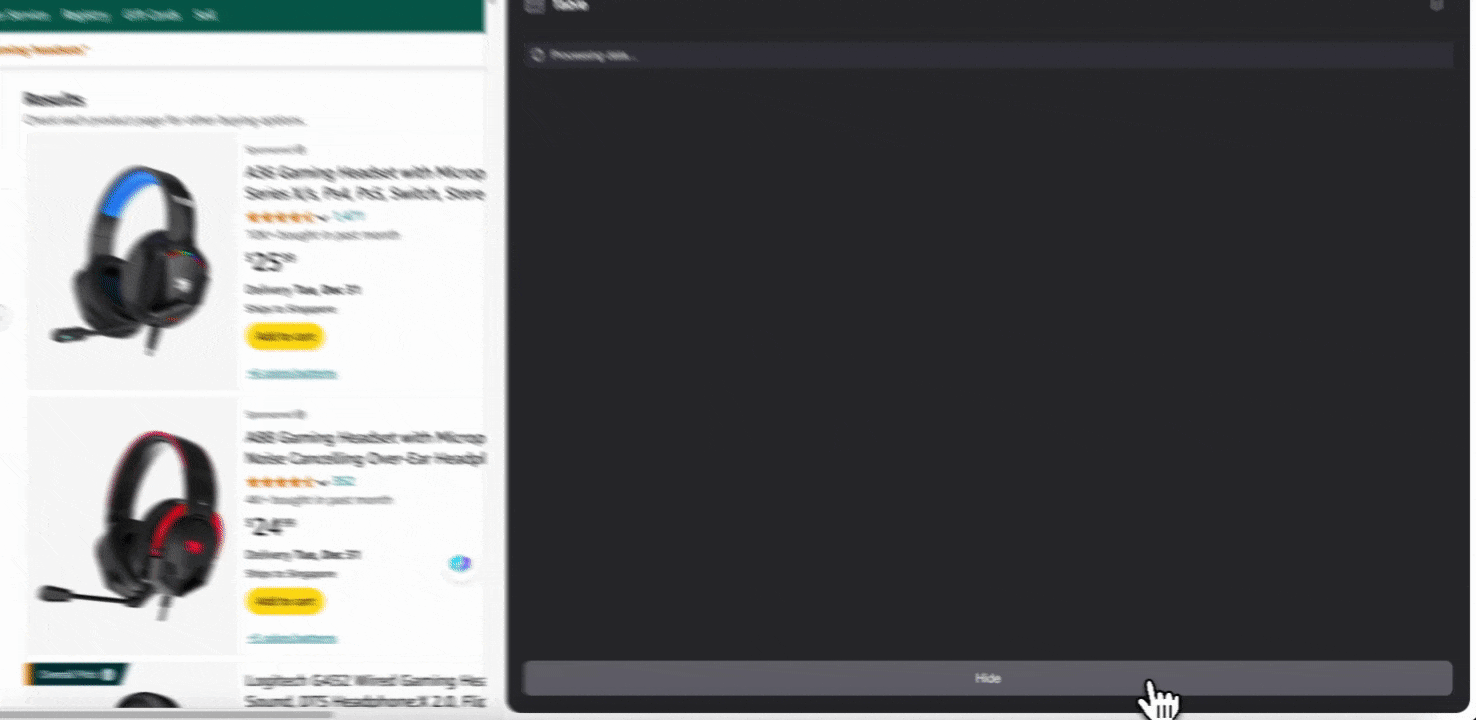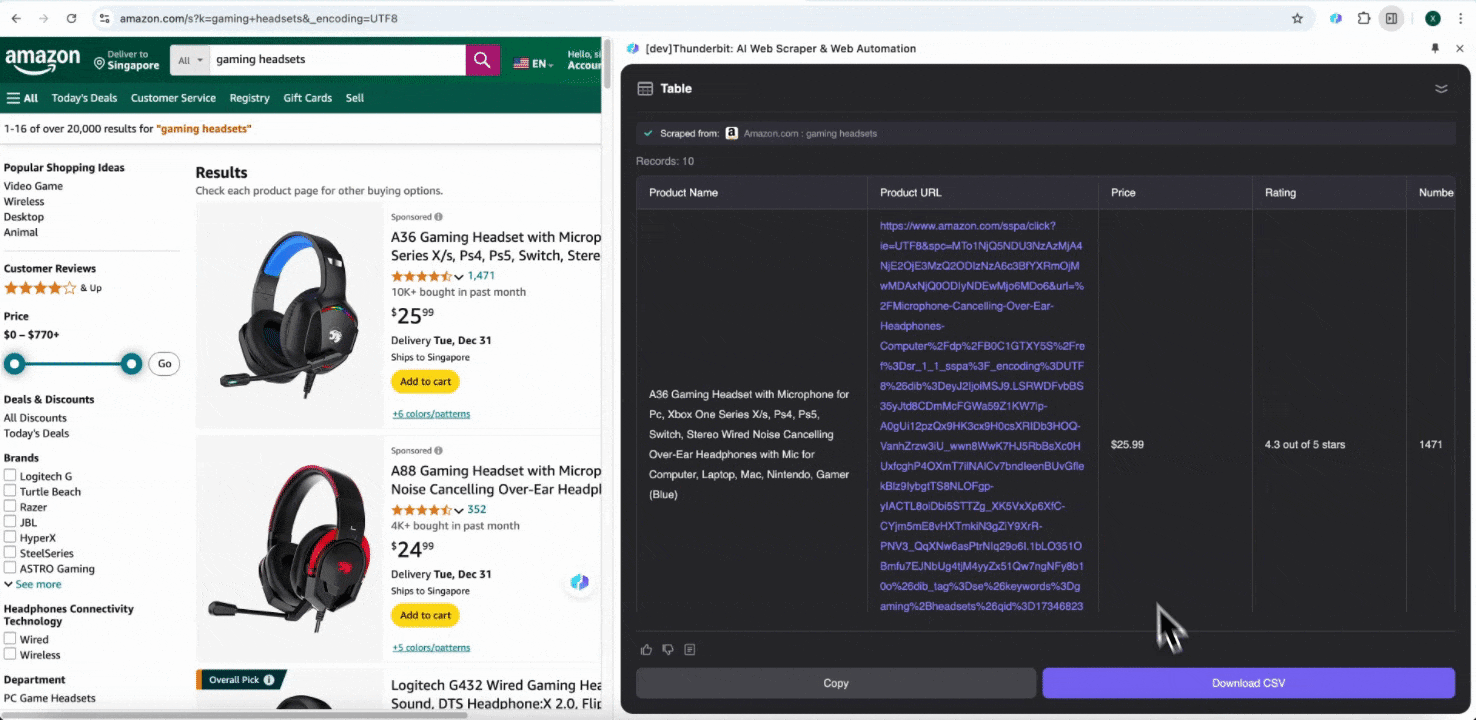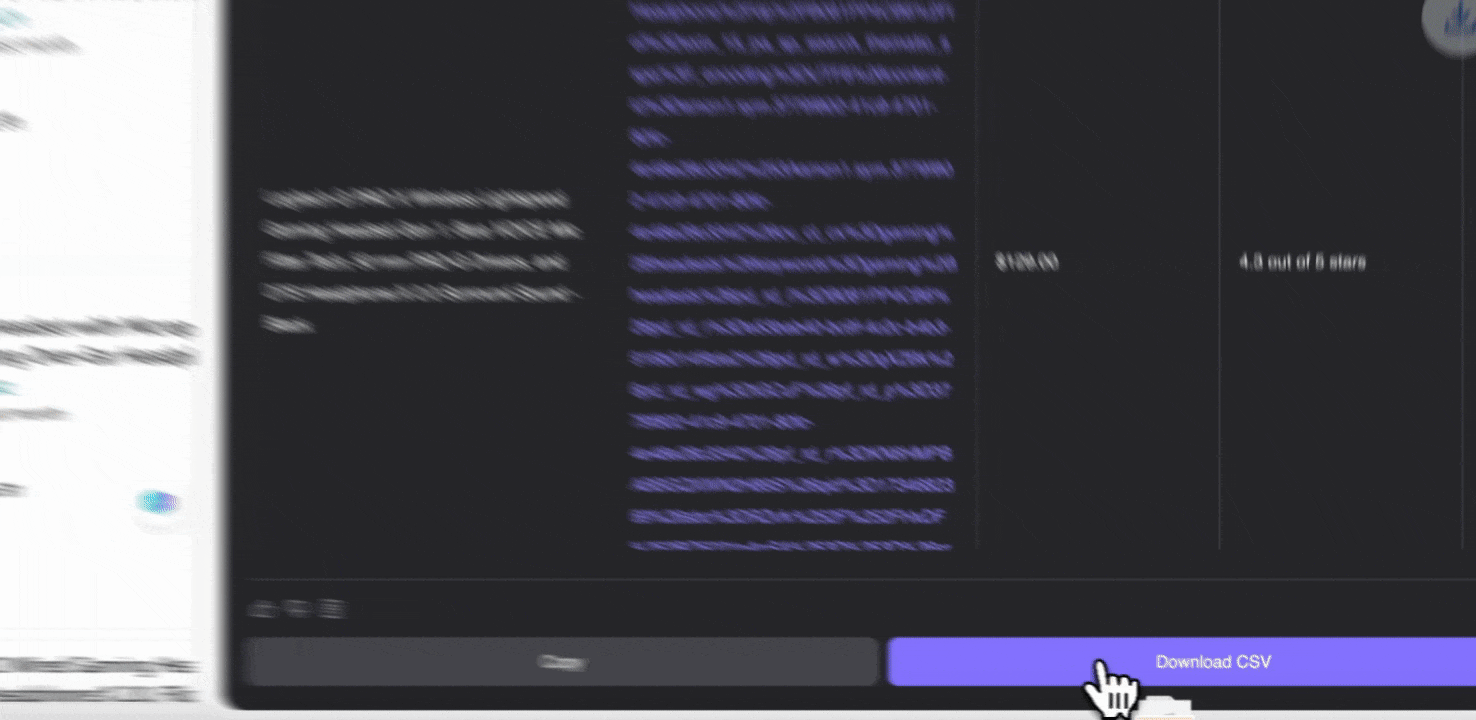
Wenn Sie sich bei den gewünschten Datenfeldern unsicher sind, klicken Sie auf Spalten per KI vorschlagen, damit Thunderbits KI automatisch zuverlässige Spaltennamen erstellt. Sie können die gewünschten Datenfelder auch in natürlicher Sprache beschreiben und in das Spaltennamenfeld eintragen. Wählen Sie Symbole aus, um den gewünschten Datentyp umzuschalten – etwa Bild, URL, Text, Zahl oder andere Datentypen – und scrapen Sie die entsprechenden Daten.
Nachdem Sie die ersten Spaltennamen eingegeben haben, können Sie KI-Spalten verbessern auswählen, damit die KI Ihre Einträge weiter optimiert. Außerdem können Sie detaillierte Spaltenanweisungen hinzufügen, um Ihre Anforderungen genauer anzupassen. Sie können beispielsweise verlangen, dass die Produkttyp-Spalte Produkte in Herren-, Damen-, Kinder- und andere Kategorien einordnet. Thunderbit ordnet dann jeden Datensatz in dieser Spalte einer der vier von Ihnen definierten Kategorien zu. Sie können Thunderbit auch anweisen, alle Preise in der Preisspalte mithilfe des aktuellen Wechselkurses in die von Ihnen gewünschte Währung umzuwandeln, sodass Sie die gewünschten Werte problemlos für Analysen erhalten, ohne sich um Währungsinkonsistenzen sorgen zu müssen.
Schließlich können Sie die gewünschte Datenmenge individuell festlegen. Bei Amazon-Produktseiten können Sie die Paginierung per Klick auswählen und die Anzahl der Seiten bestimmen, die gescrapt werden sollen. Thunderbit blättert dann automatisch weiter und extrahiert alle Daten von jeder Seite.
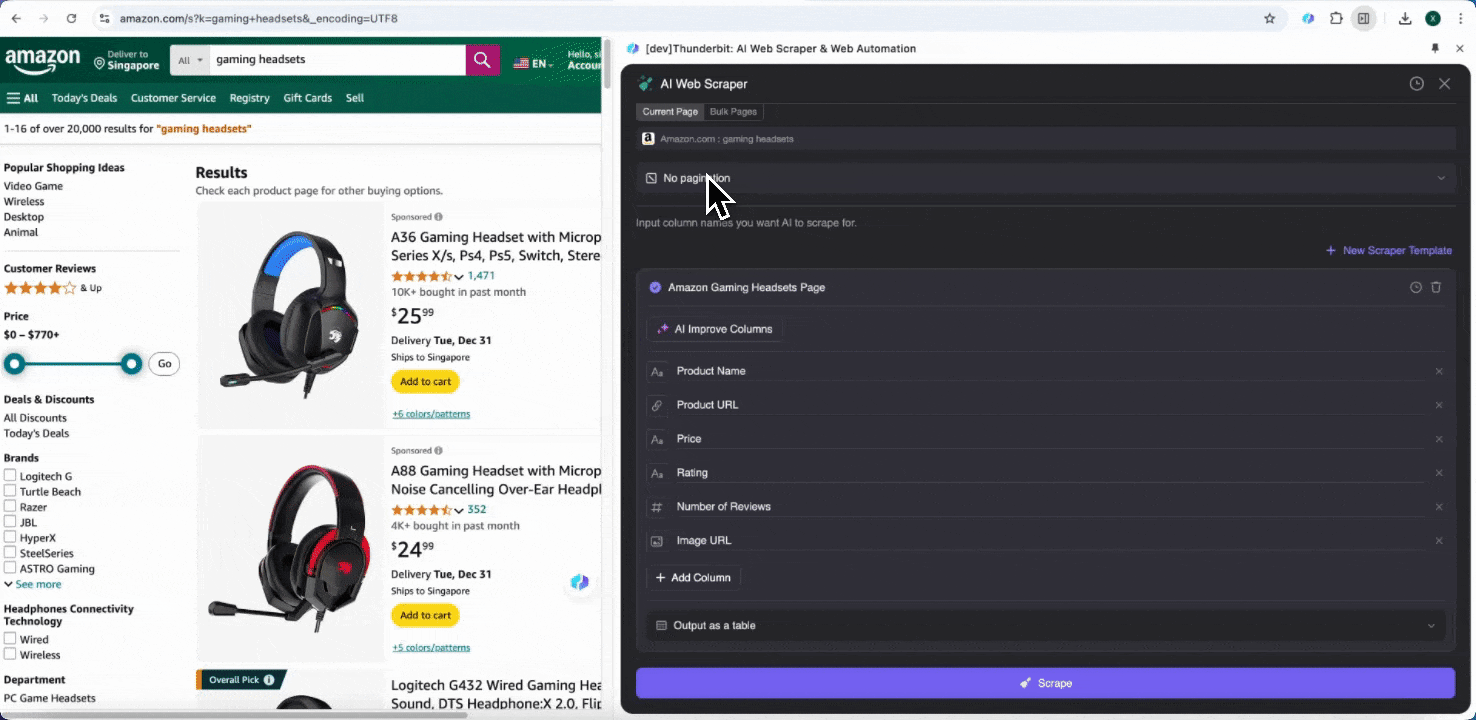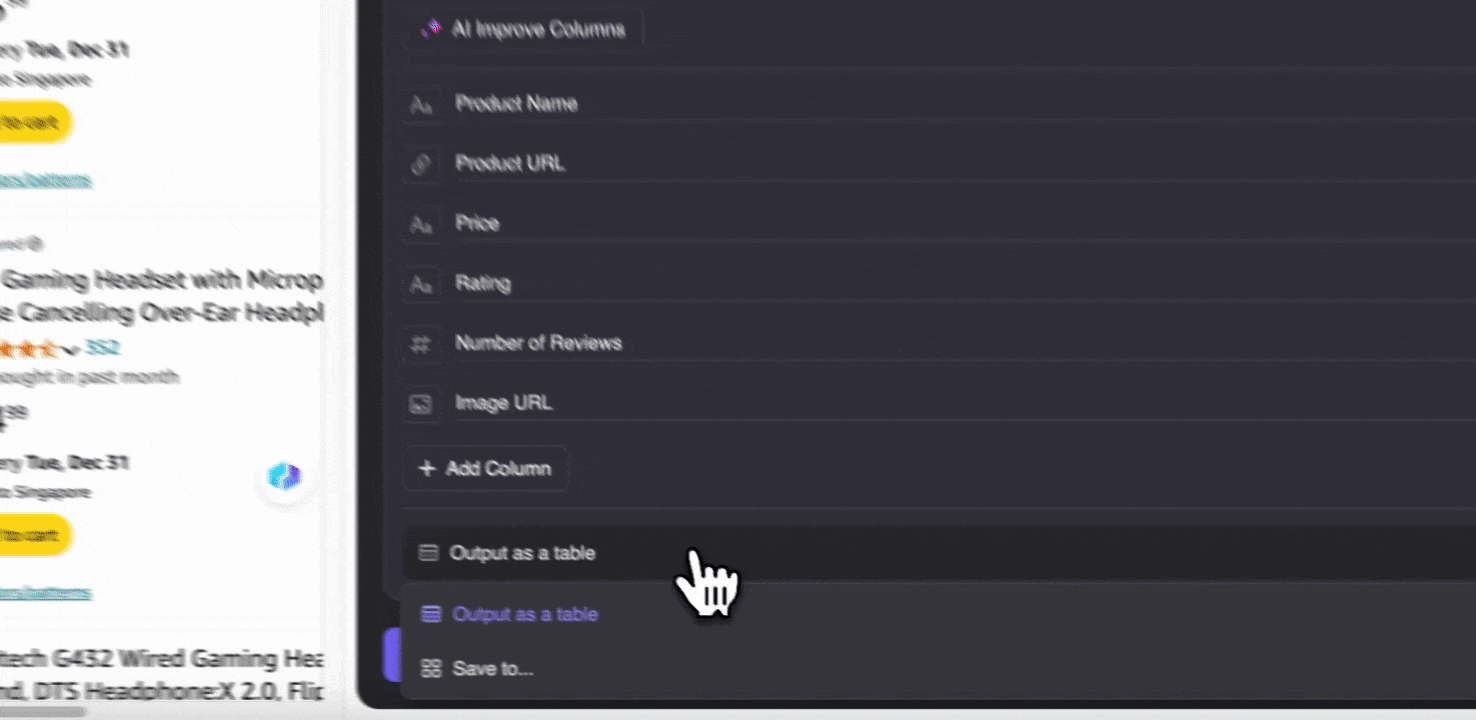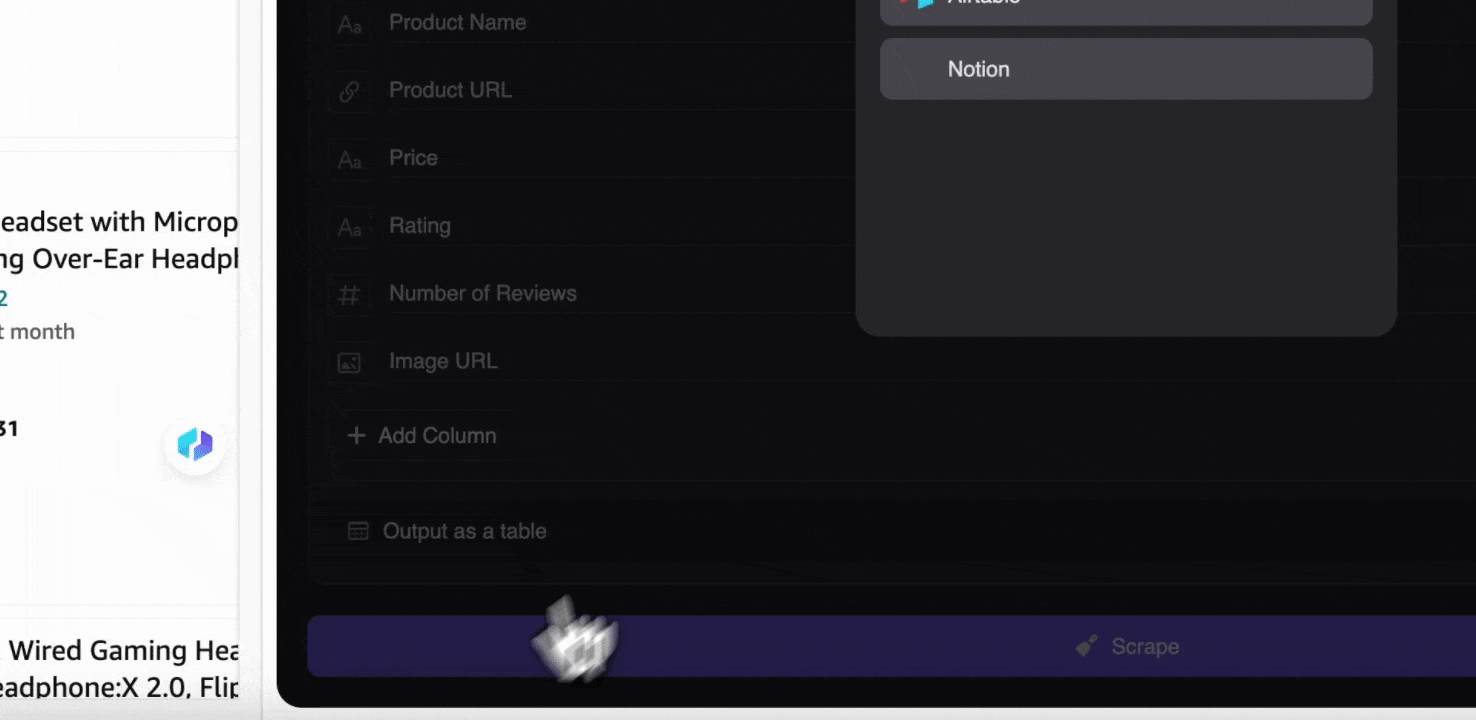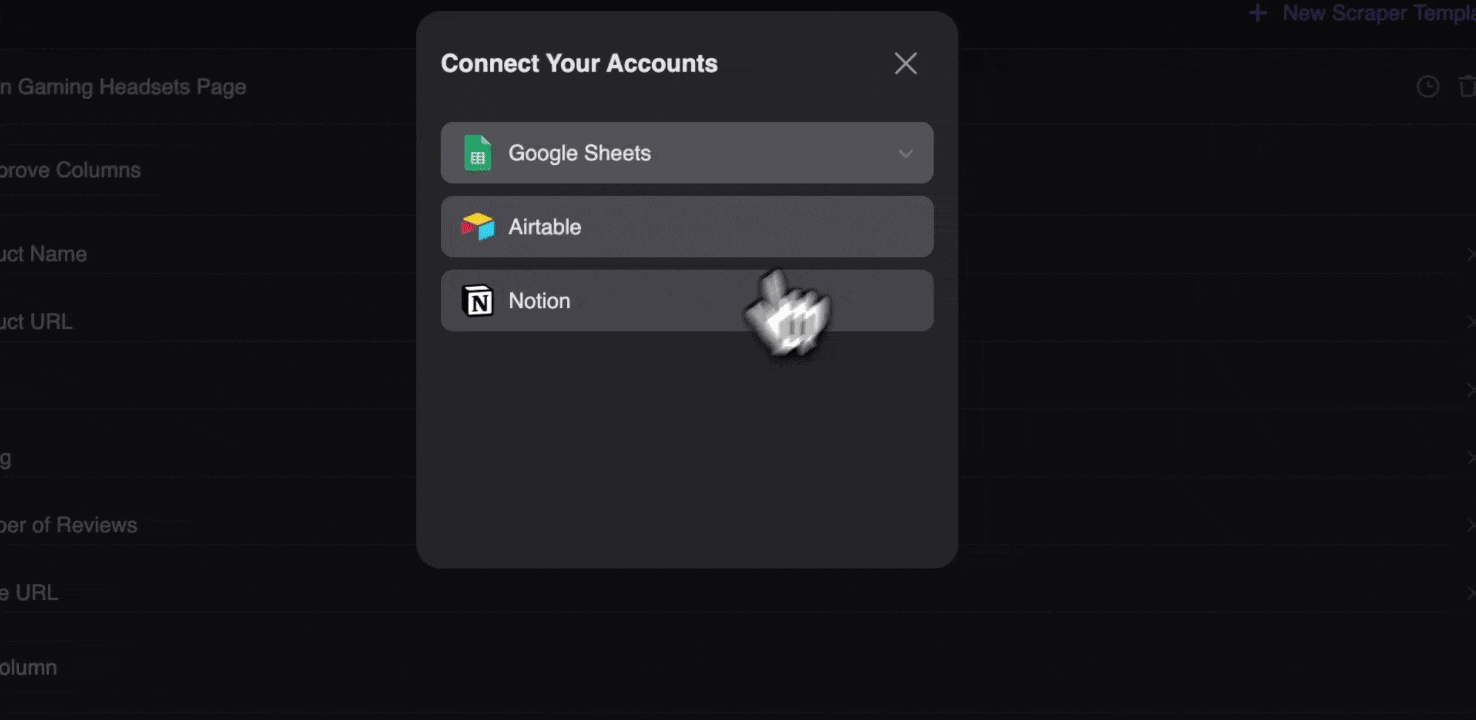
Schritt 3: Laden Sie die gescrapten Daten herunter oder exportieren Sie sie als Tabelle
Mit der Thunderbit-Web-Scraper-Erweiterung können Sie . Wählen Sie die Ausgabe als Tabelle, laden Sie dann die CSV-Datei lokal herunter, oder wählen Sie , Notion oder Airtable. Melden Sie sich in Ihrem Konto an und exportieren Sie direkt in diese Online-Kollaborations- und Dateiverwaltungsplattformen.
Scraping mit traditionellen Web-Scrapern
Neben den neuesten KI-Tools können Sie auch traditionelle Web-Scraper-Tools mit leichtem Code und APIs verwenden, um Amazon-Produktdaten zu scrapen.
: Amazon-Produktdaten im JSON-Format per API abrufen
ScraperAPI bietet eine effiziente API zur Datenerfassung auf Amazon, mit der Sie Produktdetails, Bewertungen, Suchergebnisse und Preisinformationen von Amazon scrapen und in einem strukturierten JSON-Format zurückerhalten können. So verwenden Sie die API zum Scrapen.
Schritt 1: Python-Umgebung einrichten
Stellen Sie zunächst sicher, dass Python 3.8 oder neuer installiert ist. Installieren Sie dann gängige Analysebibliotheken wie Pandas sowie Web-Scraping-Bibliotheken wie requests und BeautifulSoup. Diese Bibliotheken helfen Ihnen, Daten einfach aus Webseiten zu extrahieren.
Schritt 2: Ein ScraperAPI-Konto erstellen
Besuchen Sie die , um ein kostenloses Konto zu erstellen und Ihren API-Schlüssel zu erhalten. Sie können diesen Schlüssel in Ihrem Code verwenden, um auf ScraperAPI zuzugreifen.
Schritt 3: Den Code vorbereiten
Erstellen Sie lokal ein eigenes Verzeichnis und schreiben Sie ein Python-Skript für das Scraping. Hier ist ein grundlegender Ablauf:
- Amazon-Such-URL abrufen: Suchen Sie bei Amazon nach dem gewünschten Produkt und kopieren Sie die URL der Suchergebnisseite.
- Anfragen erstellen: ScraperAPI durchläuft automatisch die ersten fünf Seiten der Suchergebnisse. Die URL jeder Seite wird gebildet, indem &page= und die entsprechende Seitennummer an die Basis-URL angehängt werden.
- Anfragen senden und Daten parsen: Verwenden Sie die Methode get(), um Anfragen an ScraperAPI zu senden. Wenn die Anfrage erfolgreich ist (Statuscode 200), parsen Sie den Seiteninhalt, um die gewünschte ASIN (Amazon Standard Identification Number) zu extrahieren.
- Detaillierte Produktdaten abrufen: Über den Endpoint für strukturierte Daten können Sie für jede ASIN detaillierte Produktinformationen zur weiteren Analyse erhalten.
Schritt 4: Weitere Tutorials ansehen
Detailliertere Anleitungen finden Sie im .
: Blockierungen vermeiden und in großem Maßstab scrapen
Beim Scrapen von Amazon-Daten stellen Anti-Scraping-Techniken wie IP-Blockierungen, CAPTCHAs und dynamisches Nachladen von Inhalten für Scraper-Entwickler oft eine Herausforderung dar. ScrapFly stellt eine leistungsstarke API bereit, mit der diese Anti-Scraping-Mechanismen umgangen werden können, sodass die Datenerfassung reibungslos funktioniert.
Zu den Kernfunktionen von ScrapFly gehören:
- : IP-Adressen werden automatisch gewechselt, um IP-Blockierungen zu verhindern.
- : Dynamisch nachgeladene Inhalte verarbeiten und per JavaScript gerenderte Webseiten scrapen.
- : Browser steuern, um zu scrollen, Eingaben zu machen und auf Elemente zu klicken.
- : Als HTML, JSON, Text oder Markdown scrapen.
Mit nur wenigen Codezeilen können Sie ScrapFly zum Scrapen von Amazon-Daten verwenden. Hier ein einfaches Beispiel:
1import scrapfly_sdk
2# Client erstellen
3client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
4# Anfrage senden
5response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
6# Zurückgegebene Daten ausgeben
7print(response.json())Mit ScrapFly kann Ihr Scraper die verschiedenen Anti-Scraping-Mechanismen von Amazon besser bewältigen und die Erfolgsquote beim Scrapen erhöhen. Ob es um einfaches Produktdaten-Scraping oder komplexe Bewertungsanalysen geht, ScrapFly ist ein äußerst praktisches Tool. Weitere Anleitungen finden Sie im .
Scraping mit Python: Traditionelle Programmiermethoden
Für technisch versierte Personen, die mit Programmierung vertraut sind, können Sie auch Python-Code schreiben, um Amazon-Produktdaten zu scrapen. Hier ist ein einfaches Beispiel als Referenz.
Schritt 1: Voraussetzungen einrichten
Erstellen Sie zunächst einen eigenen Ordner für Ihr Projekt.
1mkdir amazonscraperInstallieren Sie dann die benötigten Bibliotheken in diesem Ordner.
1pip install beautifulsoup4
2pip install requestsErstellen Sie nun eine Python-Datei mit einem beliebigen Namen. Dies wird die Hauptdatei, in der unser Code gespeichert wird. Ich nenne sie amazon.py.
Schritt 2: Eine GET-Anfrage an die Zielseite senden
Lassen Sie uns mit der Bibliothek requests eine GET-Anfrage an unsere Zielseite senden.
1import requests
2from bs4 import BeautifulSoup
3target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
4headers = {
5 "accept-language": "en-US,en;q=0.9",
6 "accept-encoding": "gzip, deflate, br",
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
9}
10response = requests.get(target_url, headers=headers)Schritt 3: Amazon-Produktdaten scrapen
Nun müssen wir entscheiden, was wir von der extrahieren möchten.
1# Prüfen, ob die Anfrage erfolgreich war
2if response.status_code == 200:
3 # Seiteninhalt parsen
4 soup = BeautifulSoup(response.content, 'html.parser')
5 # Alle Produktauflistungen finden
6 products = soup.find_all('div', {'data-component-type': 's-search-result'})
7 # Über jedes Produkt iterieren und Details extrahieren
8 for product in products:
9 # Produkttitel extrahieren
10 title = product.h2.text.strip()
11 # Produktpreis extrahieren
12 price = product.find('span', 'a-price')
13 if price:
14 price = price.find('span', 'a-offscreen').text.strip()
15 else:
16 price = "Preis nicht verfügbar"
17 # Produktbewertung extrahieren
18 rating = product.find('span', 'a-icon-alt')
19 if rating:
20 rating = rating.text.strip()
21 else:
22 rating = "Bewertung nicht verfügbar"
23 # Produktdetails ausgeben
24 print(f"Titel: \{title\}")
25 print(f"Preis: \{price\}")
26 print(f"Bewertung: \{rating\}")
27 print("-" * 40)
28else:
29 print(f"Die Seite konnte nicht abgerufen werden. Statuscode: \{response.status_code\}")FAQs
1. Ist es legal, zu scrapen?
Ja, das Scrapen öffentlicher Daten von Amazon ist legal! Wie viele andere Websites stellt Amazon seine Produktlisten und andere öffentliche Informationen allen zur Verfügung, die sie ansehen möchten. Sie können diese frei verfügbaren Daten scrapen und sammeln, ohne gegen die Nutzungsbedingungen von Amazon zu verstoßen.
2. Kann ich Thunderbit kostenlos testen?
Ja, Thunderbit bietet kostenlose Funktionen für die Seitenerfassung und Datenerfassung. Einige erweiterte Funktionen können kostenpflichtig sein, die grundlegenden Datenerfassungsfunktionen sind jedoch .
3. Welche Daten kann ich von Amazon scrapen?
Sie können eine Vielzahl von Daten von Amazon scrapen, darunter Produkttitel, Preise, Beschreibungen, Bewertungen, Sternebewertungen und Verkäuferinformationen. Diese Daten sind wertvoll für Marktforschung, Preisüberwachung und Wettbewerbsanalysen.
4. Wie oft sollte ich Amazon-Daten scrapen?
Die Häufigkeit hängt von der Art der Daten ab, die Sie benötigen. Wenn Sie Preise oder Wettbewerbsaktivitäten überwachen, sollten Sie möglicherweise täglich oder wöchentlich scrapen. Für statischere Informationen wie Produktdetails kann ein monatliches Scraping ausreichen.
Mehr erfahren