

Das Web platzt aus allen Nähten vor Daten, und 2026 ist der Wettlauf, dieses Chaos in echten Geschäftswert zu verwandeln, härter denn je. Ich habe miterlebt, wie Vertriebs-, E-Commerce- und Operations-Teams ihre Abläufe umgekrempelt haben, indem sie automatisierten, was früher stundenlanges, einschläferndes Copy-and-Paste war. Wer 2026 keine Software für Web-Daten-Scraping einsetzt, fällt nicht nur zurück – wer dort feststeckt, sitzt vermutlich noch im Tabellenkalkulations-Limbo, während die Konkurrenz schon beim zweiten Kaffee ist.
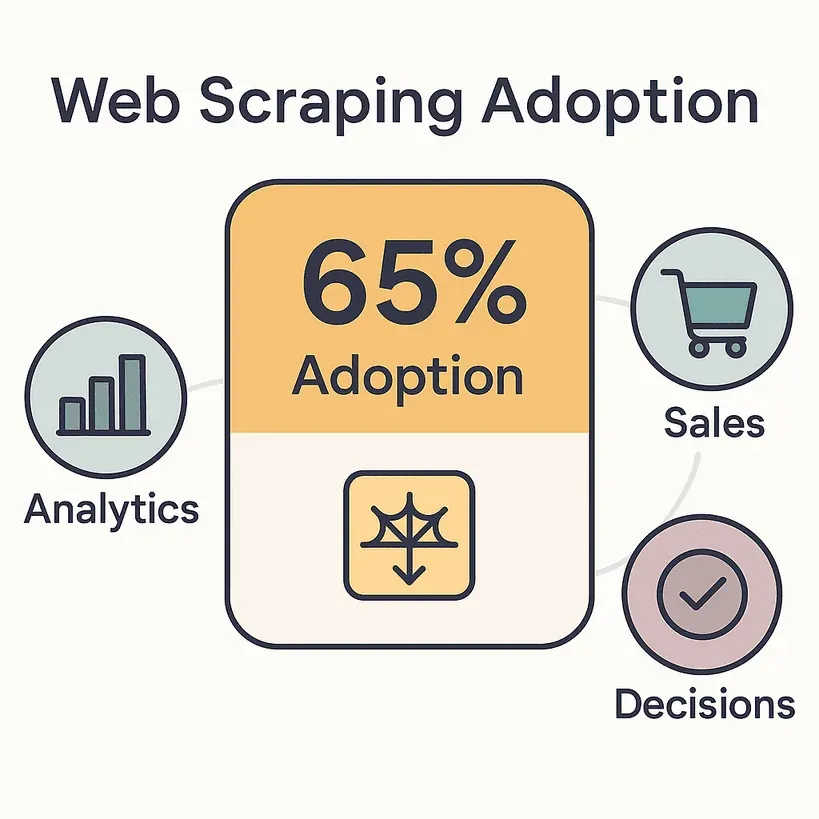
Die Zahlen sprechen für sich: 65 % der Unternehmen setzen inzwischen Web-Scraper ein, um Analytics, Vertrieb und Entscheidungen mit Daten zu versorgen. Der weltweite Markt für Web-Datenextraktion ist bereits über 1 Milliarde US-Dollar schwer und soll sich bis 2030 verdoppeln. Vertriebsmitarbeitende verbringen bis zu 70 % ihrer Zeit mit Tätigkeiten, die nichts mit Verkaufen zu tun haben – Dateneingabe und Recherche. Eine Menge Zeit, die man auch ins tatsächliche Abschließen von Deals stecken könnte – oder zumindest in eine Mittagspause.

Was ist also 2026 die beste Software für Web-Daten-Scraping? Ich habe mir die fünf besten Tools gründlich vorgenommen, die für Teams jeder Größe und mit ganz unterschiedlichem technischem Hintergrund den Unterschied machen. Ob Sie als Nicht-Coder einfach klicken und loslegen wollen oder als Entwickler maximale Flexibilität suchen – hier ist für jeden etwas dabei.
Was zeichnet die beste Software für Web-Daten-Scraping aus?
Was Data Scraping ist und wie man es 2025 macht Get Started Free
Ganz ehrlich: Nicht jeder Web-Scraper ist gleich gut. Die beste Software für Web-Daten-Scraping macht die Datenextraktion 2026 vor allem schnell, zuverlässig und für alle zugänglich – nicht nur für Leute, die in Python träumen.
Auf diese Kriterien achte ich (und sie sind für Business-Anwendende am wichtigsten):
- Einfache Bedienung: Bekommen nicht-technische Nutzer ein Scraping in Minuten eingerichtet? No-Code- und KI-gestützte Oberflächen sind für die meisten Teams Pflicht.
- Flexibilität bei den Datenquellen: Werden Webseiten, PDFs, Bilder und dynamische Inhalte wie endloses Scrollen oder AJAX unterstützt? Je mehr Quellen, desto besser.
- Automatisierung & Planung: Lassen sich wiederkehrende Scrapes planen, Paginierung verarbeiten und Unterseiten-Navigation automatisieren? Genau hier liegt der Unterschied zwischen „einmal einrichten und vergessen“ und „einmal einrichten und ständig babysitten“.
- Integration & Export: Lässt sich direkt nach Excel, Google Sheets, Notion, Airtable oder per API exportieren? Je weniger Handarbeit, desto entspannter das Team.
- Erforderliches technisches Know-how: Ist es wirklich No-Code, oder müssen Sie erst Ihr Regex auffrischen? Die besten Tools holen Nicht-Coder und Power-User gleichermaßen ab.
- Skalierbarkeit: Schafft das Tool Hunderte oder Tausende Seiten, ohne ins Schwitzen zu geraten?
- Support & Community: Gibt es gute Dokumentation, schnellen Support und eine aktive Nutzerschaft?
Diese Punkte sind keine netten Extras – sie trennen die Tools, die Ihnen Stunden sparen, von denen, die Sie Tage kosten. 2026, wo fast die Hälfte des gesamten Internetverkehrs von Bots stammt, ist der richtige Scraper ein klarer Wettbewerbsvorteil.
Werfen wir nun einen Blick auf die Top 5.
Die 5 besten Softwarelösungen für Web-Daten-Scraping im Jahr 2026
- Thunderbit für No-Code-, KI-gestütztes Scraping aus mehreren Quellen
- Import.io für Datenpipelines auf Enterprise-Niveau
- Scrapy für flexible Open-Source-Entwicklung
- Octoparse für visuelles No-Code-Scraping mit Planung
- ParseHub für benutzerfreundliche Datenerfassung per Klick
1. Thunderbit: Die einfachste KI-gestützte Software für Web-Daten-Scraping
Daten von jeder Website mit KI scrapen Get Started Free
Thunderbit ist meine erste Empfehlung für alle, die Web-Daten scrapen wollen, ohne auch nur eine Zeile Code zu schreiben. Und ja, ich bin ein bisschen befangen – ich habe beim Aufbau mitgewirkt. Aber hören Sie mir kurz zu: Thunderbit ist für Business-Anwendende gemacht, die Ergebnisse wollen, keine Kopfschmerzen.
Was Thunderbit besonders macht:
- KI-Felder vorschlagen lassen: Ein Klick auf „KI-Felder vorschlagen“ genügt, dann liest die KI von Thunderbit die Seite, empfiehlt, was extrahiert werden soll, und richtet den Scraper für Sie ein. Keine Selektoren, keine Vorlagen, kein Theater.
- Scraping aus mehreren Quellen: Nicht nur Webseiten, sondern auch PDFs und Bilder. Thunderbit holt Texte, Links, E-Mails, Telefonnummern und Bilder heraus – alles in zwei Klicks.
- Automatisierung für Unterseiten & Paginierung: Brauchen Sie Details von jeder Produkt- oder Profilseite? Das Unterseiten-Scraping von Thunderbit folgt den Links, zieht die Zusatzinfos und fügt sie in Ihre Tabelle ein. Endloses Scrollen und Paginierung meistert es ebenfalls mühelos.
- Batch- & geplantes Scraping: Eine URL-Liste einfügen, wiederkehrende Jobs planen und Thunderbit die Schwerstarbeit überlassen – ob tägliches Preis-Monitoring oder wöchentliche Lead-Updates.
- Sofortiger Export: Direkt nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON. Schluss mit Copy-and-Paste-Marathons.
- Eigene KI-Prompts: Wollen Sie Daten schon beim Scrapen kategorisieren, übersetzen oder beschriften? Fügen Sie eine eigene Anweisung hinzu, den Rest erledigt die KI von Thunderbit.
- Cloud- oder Browser-Modus: Scrapes in der Cloud für mehr Tempo (50 Seiten gleichzeitig) oder lokal für Websites, die einen Login verlangen.
Thunderbit genießt das Vertrauen von über 30.000 Nutzern weltweit – von Vertriebsteams über Immobilienmakler bis zu Indie-E-Commerce-Shops. Der Gratis-Tarif erlaubt bis zu 6 Seiten (oder 10 mit einem Test-Boost), und Sie zahlen nur für das, was Sie nutzen – einen Kredit pro Ausgabereihe.
Warum ich es schätze: Thunderbit ist das einzige Tool, bei dem ich gesehen habe, wie ein nicht-technischer Nutzer in unter fünf Minuten von „Ich brauche diese Daten“ zu „Hier ist meine Tabelle“ kommt. Die Oberfläche ist wirklich angenehm gestaltet (daran haben wir uns geradezu festgebissen), und die KI passt sich Website-Änderungen an, sodass Sie nicht ständig kaputte Scraper flicken müssen.
Am besten für: Vertrieb, E-Commerce, Operations und alle, die No-Code-, KI-gestütztes Scraping ohne Wartungsaufwand wollen.
Thunderbit Chrome-Erweiterung ausprobieren
Weitere Anleitungen finden Sie im Thunderbit-Blog.
2. Import.io: Web-Daten-Scraping und Integration auf Enterprise-Niveau
Import.io ist der Schwergewichts-Champion für Unternehmen, die Webdaten im großen Stil brauchen – und sie direkt in ihre Geschäftssysteme einspeisen wollen.
Was Import.io auszeichnet:
- Enterprise-taugliche Pipelines: Import.io ist nicht bloß ein Scraper, sondern eine vollwertige Plattform zur Webdaten-Integration. Denken Sie an „Data as a Service“ mit kontinuierlichen, automatisierten Feeds.
- Selbstheilende KI: Ändert sich eine Website, versucht die KI von Import.io, die Felder automatisch neu zuzuordnen, damit Ihre Pipelines nicht über Nacht kaputtgehen.
- Robuste Automatisierung: Scrapes stündlich, täglich oder in eigenen Intervallen planen. Benachrichtigungen erhalten, wenn etwas hakt oder die Daten merkwürdig aussehen.
- Interaktive Workflows: Websites mit Logins, Formularen oder mehrstufiger Navigation verarbeiten. Import.io kann komplexe Abläufe aufzeichnen und wiedergeben.
- Compliance & Governance: Automatische Erkennung personenbezogener Daten, Maskierung und Audit-Protokolle – entscheidend für regulierte Branchen. Gerade im DACH-Raum hilft das, DSGVO-Anforderungen sauber abzubilden.
- API & Integration: Daten direkt in Google Sheets, Excel, Tableau, Power BI, Datenbanken oder eigene Apps per API streamen.
Import.io genießt das Vertrauen von Marken wie Unilever, Volvo und RedHat. Es ist die erste Wahl für Anwendungsfälle wie Preisüberwachung über Tausende E-Commerce-Seiten, Market Intelligence oder das Versorgen von KI-/ML-Modellen mit frischen Webdaten.
Preis: Import.io ist eine Premium-Lösung, die bei etwa 299 US-Dollar pro Monat (ca. 275 €/Monat) für Self-Service-Pläne startet. Eine kostenlose Testphase gibt es, einen dauerhaften Gratis-Tarif nicht. Sind Webdaten geschäftskritisch, rechnet sich das.
Am besten für: Unternehmen und datengetriebene Organisationen, die Zuverlässigkeit, Skalierung, Compliance und tiefe Integration brauchen.
3. Scrapy: Open-Source-Web-Scraping-Framework für Entwickler
Scrapy ist ein Open-Source-Kraftpaket für Entwickler, die maximale Flexibilität und Kontrolle wollen. Wer – ob allein oder im Team – in Python programmiert, findet in Scrapy das Allzweckwerkzeug fürs Web-Scraping.
Warum Entwickler Scrapy lieben:
- Volle Anpassbarkeit: Schreiben Sie Spiders (Skripte), um Daten genau so zu crawlen, zu parsen und zu verarbeiten, wie Sie es brauchen. Mehrseitige Abläufe, eigene Logik und komplexe Datenbereinigung lassen sich problemlos umsetzen.
- Asynchron und schnell: Scrapys Architektur ist auf Tempo und Skalierung ausgelegt – scrapen Sie Hunderte Seiten pro Minute oder Millionen mit verteilten Crawlern.
- Erweiterbar: Großes Ökosystem an Plugins und Middleware für Proxys, Headless-Browser (Splash/Playwright) und Integrationen.
- Kostenlos & Open Source: Keine Lizenzgebühren. Betreiben Sie es auf eigener Hardware oder in der Cloud und skalieren Sie so groß, wie Sie es brauchen.
- Community-Support: Über 55.000 GitHub-Sterne und eine riesige Nutzerschaft. Wo Sie hängen bleiben, hat es vermutlich schon jemand gelöst.
Nachteile: Scrapy verlangt Python-Kenntnisse und Sicherheit auf der Kommandozeile. Eine Klick-und-los-GUI gibt es nicht – hier gilt Code-first. Für maßgeschneiderte Projekte, Trainingsdaten für KI oder riesige Crawls gibt es allerdings kaum etwas Besseres.
Am besten für: Organisationen mit internen Entwicklern, maßgeschneiderten Datenpipelines oder großen, komplexen Scraping-Anforderungen.
4. Octoparse: Visuelles Web-Daten-Scraping ganz einfach
Octoparse ist ein Favorit unter Nicht-Codern, die leistungsstarkes Scraping mit einer visuellen, klickbasierten Oberfläche wollen.
Warum Octoparse beliebt ist:
- Visueller Workflow-Builder: Klicken Sie im integrierten Browser auf Elemente, und Octoparse erkennt Muster automatisch. Kein Code, einfach klicken und extrahieren.
- Unterstützt dynamische Inhalte: Scrapen Sie AJAX, endloses Scrollen und login-geschützte Websites. Klicks, Scrollen und Formulareingaben werden simuliert.
- Cloud-Scraping & Planung: Aufgaben in der Cloud ausführen (schneller, parallelisiert) und wiederkehrende Jobs für stets aktuelle Daten planen.
- Vorgefertigte Vorlagen: Hunderte Vorlagen für beliebte Websites (Amazon, Twitter, Zillow usw.) bringen Sie sofort an den Start.
- Export & API: Ergebnisse als CSV, Excel oder JSON herunterladen oder Daten per API abrufen. Integration mit Google Sheets oder Datenbanken.
Octoparse wird oft als „super einfach zu benutzen, selbst für Anfänger“ beschrieben. Der Gratis-Tarif ist eingeschränkt, aber kostenpflichtige Pläne (ab etwa 83 US-Dollar pro Monat, ca. 76 €/Monat) schalten Cloud-Runs, Planung und mehr Tempo frei.
Am besten für: Nicht-technische Nutzer, Marketer, Forschende und kleine Teams, die regelmäßig automatisiert Daten sammeln wollen, ohne zu programmieren.
5. ParseHub: Benutzerfreundliche Datenextraktion für den Alltag
ParseHub ist ein weiterer No-Code-Favorit, besonders für kleine Unternehmen und Freelancer, die alltägliche Datentasks automatisieren wollen.
Was ParseHub stark macht:
- Einfache Bedienung per Klick: Wählen Sie Daten aus, indem Sie in einer Browseransicht auf Elemente klicken. Workflows visuell aufbauen – ganz ohne Programmieren.
- Verarbeitet JS- und dynamische Seiten: JavaScript-lastige Seiten, endloses Scrollen und mehrstufige Navigation scrapen.
- Cloud- und lokale Läufe: Scrapes auf dem Desktop oder in der Cloud ausführen. Wiederkehrende Jobs planen und Ergebnisse über API abrufen (in höheren Plänen).
- Export-Optionen: Daten als CSV, Excel oder JSON herunterladen. API-Zugriff für Automatisierung.
- Plattformübergreifend: Verfügbar für Windows, Mac und Linux.
Der kostenlose Plan von ParseHub ist begrenzt (200 Seiten pro Lauf), aber kostenpflichtige Pläne (ab etwa 189 US-Dollar pro Monat, ca. 174 €/Monat) schalten mehr Leistung, Tempo und API-Zugriff frei.
Am besten für: Kleine Unternehmen, Freelancer und Teams mit überschaubaren Scraping-Anforderungen, die ein zuverlässiges visuelles Tool wollen.
Vergleichstabelle: Die besten Softwarelösungen für Web-Daten-Scraping auf einen Blick
| Tool | Benutzerfreundlichkeit | Datenquellen | Automatisierung & Planung | Integration & Export | Technisches Know-how | Preisgestaltung |
|---|---|---|---|---|---|---|
| Thunderbit | No-Code, KI-gesteuert | Web, PDF, Bilder | Unterseiten, Paginierung, geplant, Batch | Excel, Sheets, Notion, Airtable, CSV, JSON | Keines | Freemium (Bezahlung pro Zeile) |
| Import.io | Klickbare Oberfläche | Web (statisch/dynamisch, Login) | Selbstheilend, geplant, Warnmeldungen | API, BI-Tools, Sheets, Excel, DB | Niedrig–Mittel | 299+ US-Dollar/Monat |
| Scrapy | Code erforderlich | Web, APIs, (JS über Add-ons) | Vollautomatisierung per Code | Alles (per Code) | Python-Entwickler | Kostenlos (Open Source) |
| Octoparse | Visuell, No-Code | Web (dynamisch, Login) | Cloud-Planung, Vorlagen | CSV, Excel, JSON, API | Keines | 83+ US-Dollar/Monat |
| ParseHub | Visuell, No-Code | Web (JS, dynamisch) | Cloud/lokal, geplant | CSV, Excel, JSON, API | Keines | 189+ US-Dollar/Monat |
So wählen Sie die beste Software für Web-Daten-Scraping für Ihr Unternehmen aus
Unsicher, welches Tool zu Ihnen passt? Hier mein Spickzettel:
- Nicht-technische Nutzer, schnelle Ergebnisse: Greifen Sie zu Thunderbit oder Octoparse. Thunderbit ist unschlagbar für sofortiges, KI-gestütztes Scraping und die Unterstützung mehrerer Quellen (Web, PDF, Bilder). Octoparse ist ideal für visuelle, geplante Scrapes.
- Enterprise-Integration, Compliance und Skalierung: Import.io ist die beste Wahl. Es ist für kontinuierliche, zuverlässige Datenpipelines und tiefe Integration gebaut.
- Entwickler, maßgeschneiderte Projekte oder riesige Crawls: Scrapy ist der richtige Weg. Sie brauchen Python-Know-how, bekommen dafür aber grenzenlose Flexibilität.
- Kleine Unternehmen, Freelancer oder alltägliche Aufgaben: ParseHub ist eine solide, benutzerfreundliche Wahl für Scraping per Klick und moderate Automatisierung.
Tipps zur Tool-Auswahl:
- Stimmen Sie das Tool auf die technischen Fähigkeiten Ihres Teams und Ihren Datenbedarf ab.
- Berücksichtigen Sie die Komplexität der Websites, die Sie scrapen müssen (dynamische Inhalte? Logins?).
- Überlegen Sie, wie Sie die Daten nutzen wollen – brauchen Sie einen direkten Export nach Sheets oder eine tiefe API-Integration?
- Starten Sie mit einer kostenlosen Testphase oder einem Freemium-Plan und testen Sie echte Aufgaben.
- Unterschätzen Sie nicht den Wert von gutem Support und guter Dokumentation.
Mit Thunderbit mit dem Scraping starten
Fazit: Business-Mehrwert mit der besten Software für Web-Daten-Scraping erschließen
Webdaten sind 2026 der Treibstoff für klügere Geschäftsentscheidungen. Die richtige Software für Web-Daten-Scraping kann Ihnen Stunden sparen, Fehler reduzieren und Ihrem Team einen echten Vorsprung verschaffen – ob Sie Lead-Listen aufbauen, Wettbewerber beobachten oder Ihre Analytics-Engine füttern.
Kurz zusammengefasst:
- Thunderbit ist der einfachste KI-gestützte No-Code-Scraper für Business-Anwendende.
- Import.io ist die Enterprise-Lösung für kontinuierliche, integrierte Datenpipelines.
- Scrapy ist das Open-Source-Toolkit für Entwickler, die volle Kontrolle wollen.
- Octoparse und ParseHub machen visuelles, No-Code-Scraping für alle zugänglich.
Die meisten dieser Tools bieten kostenlose Testphasen oder Freemium-Pläne – probieren Sie sie also einfach aus. Automatisieren Sie die langweiligen Aufgaben, gewinnen Sie neue Erkenntnisse und geben Sie Ihrem Team den Freiraum, sich auf das Wesentliche zu konzentrieren.
Viel Erfolg beim Scrapen – und mögen Ihre Daten stets frisch, strukturiert und einsatzbereit sein.
FAQs
1. Wofür wird Software für Web-Daten-Scraping verwendet?
Software für Web-Daten-Scraping automatisiert das Extrahieren von Informationen aus Websites, PDFs und Bildern. Sie kommt bei Lead-Generierung, Preisüberwachung, Marktforschung, Content-Aggregation und mehr zum Einsatz.
2. Ist Web-Daten-Scraping legal?
Web-Scraping ist legal, wenn öffentlich verfügbare Daten gesammelt und die Nutzungsbedingungen sowie Datenschutzgesetze der Website eingehalten werden. Im DACH-Raum gilt zusätzlich die DSGVO – prüfen Sie immer die Richtlinien der Seite und gehen Sie mit den Daten verantwortungsvoll um.
3. Muss ich programmieren können, um Software für Web-Daten-Scraping zu nutzen?
Nicht unbedingt! Tools wie Thunderbit, Octoparse und ParseHub sind für Nicht-Coder gemacht. Für komplexere oder maßgeschneiderte Projekte können Entwickler-Tools wie Scrapy nötig sein.
4. Wie exportiere ich gescrapte Daten nach Excel oder Google Sheets?
Die meisten modernen Scraper (Thunderbit, Octoparse, ParseHub) bieten einen Export per Klick nach Excel, Google Sheets, CSV oder sogar eine direkte Integration mit Notion und Airtable.
5. Können Softwarelösungen für Web-Daten-Scraping dynamische Seiten oder Logins verarbeiten?
Ja – Top-Tools wie Import.io, Octoparse und ParseHub kommen mit dynamischen Inhalten (AJAX, endloses Scrollen) und login-geschützten Websites zurecht. Thunderbit unterstützt ebenfalls das Scraping dynamischer Seiten und Unterseiten.
Möchten Sie sehen, wie modernes Web-Scraping aussieht? Laden Sie die Thunderbit-Chrome-Erweiterung herunter oder stöbern Sie im Thunderbit-Blog mit weiteren Tipps, Tutorials und tiefen Einblicken in die KI-gestützte Datenextraktion.
KI-Web-Scraper ausprobieren Get Started Free




