
上週我花了 40 分鐘除錯一支明明在三個測試網站都運作正常的 Python 腳本,最後才發現第四個網站架了 Cloudflare。爬蟲一直卡在「Checking your browser…」頁面,回傳的只有挑戰頁 HTML。是不是很熟悉?
如果你也卡過這道牆,你不是一個人。 現在都在使用 Cloudflare,約占網路上。這也讓 Cloudflare 成為任何想蒐集網頁資料的人最常遇到的阻礙之一——不管是做開發名單、價格監控、不動產研究,還是競品分析。
問題在於,大多數教學都把各種繞過方式平鋪直敘地列出來,卻沒告訴你「在你的情境下,應該先試哪一個」。這篇指南採用不同的方式:先做分級判斷、提供誠實的成功率估計,還有大多數文章都完全忽略的無程式碼路線。
- 難度: 初階到中階(取決於你選用的方法)
- 所需時間: 無程式碼方案約 10–30 分鐘;程式碼方案則視情況而定
- 你需要準備: Chrome 瀏覽器(無程式碼方案適用),可選 Python 3.9+(程式碼方案適用),以及目標網址
什麼是 Cloudflare 保護?為什麼它會擋住你的爬蟲?
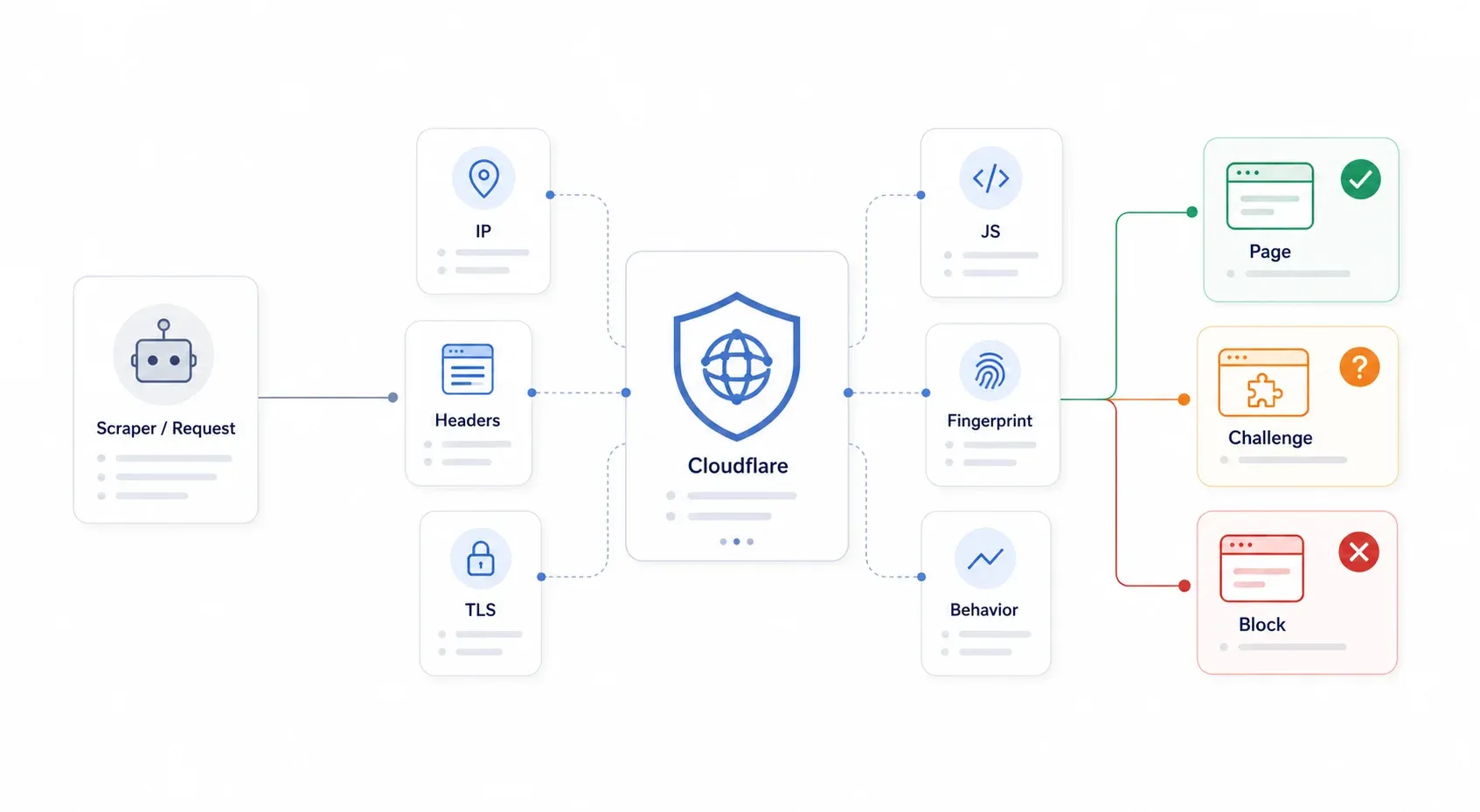
Cloudflare 本質上是一個反向代理,介於訪客與網站原始伺服器之間。每個請求都會先經過 Cloudflare 的邊緣節點,接著由 Cloudflare 判斷是要直接回傳頁面、發出挑戰,還是直接封鎖。最重要的是:Cloudflare 不一定需要「知道」你的爬蟲是惡意的,它只需要把你的請求判定為自動化程度過高或可疑即可。
Cloudflare 的 採用的是分層式偵測——不是單一門鎖,而是一整套安檢關卡。它會檢查 IP 信譽、HTTP 標頭、TLS 指紋、JavaScript 執行能力、瀏覽器指紋,以及行為模式。當你的 Python requests 對受 Cloudflare 保護的頁面發出 GET 請求時,通常會同時在多層被攔下:TLS 握手不對、沒有執行 JavaScript、沒有 Cookie、沒有瀏覽器指紋。這就是為什麼單純偽裝標頭,很多年前就已經不夠用了。
你最常看到的症狀包括:403 Forbidden、503 並顯示「Checking your browser…」、1020 Access Denied、無限挑戰循環、Turnstile 小工具一直無法通過,以及你以為應該拿到 JSON,結果卻看到挑戰頁 HTML。
被動偵測:頁面還沒載入前,Cloudflare 就已經在檢查什麼
在你看到任何頁面之前,Cloudflare 的被動檢測層就已經先為你的請求打分了:
- IP 信譽: 資料中心 IP、雲端主機網段,以及已知的代理出口,通常都會被標記。住宅 IP 和行動網路 IP 。2026 年的社群回報也一再指出:本機住宅環境通常能通過,但 Docker 或 VPS 環境常常被擋。
- HTTP 標頭分析: Cloudflare 會比對你的 User-Agent、Accept-Language、標頭順序與 HTTP 版本。只要有不一致——例如你自稱是 Chrome 136,但 TLS 握手卻明顯像 Python——就很容易露餡。
- TLS 指紋(JA3/JA4): 在 TLS 握手過程中,客戶端會暴露支援的加密套件、擴充功能與協定偏好組合。 會把這些資訊壓縮成一個識別值。真實的 Chrome 和 Python
requests腳本,留下來的「形狀」差很多。 - HTTP/2 指紋: 瀏覽器與 HTTP 函式庫在 HTTP/2 的 SETTINGS frames、pseudo-header 順序、優先順序行為上都有差異。Cloudflare 的 做法已經不只看單次請求的身份,而是追蹤請求之間的長期模式。
- AI Labyrinth: 這是 Cloudflare 比較新的陷阱。它不直接封鎖可疑爬蟲,而是把它們,看起來合理,卻只會浪費爬蟲資源。你的爬蟲甚至可能都沒發現自己已經中招。
主動偵測:在瀏覽器裡執行的挑戰
當被動檢查還無法下定論時,Cloudflare 就會升級成主動挑戰:
- JavaScript 挑戰: 經典的「Checking your browser…」中介頁。Cloudflare 的 會執行隱藏腳本來辨識自動化請求。
- Turnstile: Cloudflare 的 CAPTCHA 替代方案。 包括 Managed、Non-Interactive 與 Invisible。它會分析滑鼠移動、瀏覽器環境、TLS 指紋等資訊,未必會真的顯示出可見題目。
- Canvas 與 WebGL 指紋: 這些檢查會抓出 headless 瀏覽器與真實瀏覽器之間的渲染差異。
- 行為訊號: 請求時間間隔、捲動模式、點擊順序。若某個爬蟲在 3 秒內抓了 50 頁,而且完全沒有滑鼠移動,根本不像真人。
實務上的結論是:如果 Cloudflare 已經升級到主動挑戰階段,單純的 HTTP 用戶端如 requests、httpx,甚至 curl_cffi,都過不了。你需要的是能執行真正瀏覽器環境的方案。
Cloudflare 保護等級:為什麼同一支腳本在一個網站有效,到了另一個網站卻失敗
這正是大多數繞過教學完全沒講清楚的地方。Cloudflare 的保護並不是一致的。使用 Cloudflare 免費方案、且安全等級是「Medium」的網站,和啟用 Bot Management 與 Turnstile 的 Enterprise 網站,難度完全不同。同一支腳本在前者可能一路順風,到了後者就會直接撞牆。
| Cloudflare 等級 | 常見防護 | 繞過難度 | 通常有效的方法 |
|---|---|---|---|
| 免費方案(低安全性) | Bot Fight Mode、基礎 WAF 規則、IP 信譽 | ⭐ 低 | 內部 API 探查、帶正確標頭的 curl_cffi、真實瀏覽器工作階段 |
| Pro 方案(中等) | Super Bot Fight Mode、Managed Challenge、JavaScript 偵測 | ⭐⭐ 中 | 真實瀏覽器工作階段、隱匿式瀏覽器自動化、住宅代理 |
| Business | 更強的 WAF、Bot Analytics、對關鍵路徑採用更嚴格的挑戰 | ⭐⭐⭐ 中高 | 瀏覽器工作階段擷取、工作階段持久化、住宅/行動代理、付費爬蟲 API |
| Enterprise / Bot Management | Bot 分數、JA3/JA4 欄位、依端點規則、Turnstile、AI Labyrinth | ⭐⭐⭐⭐ 高 | 內部 API(若可取得)、真實使用者工作階段工具、等級更高的爬蟲 API 供應商 |
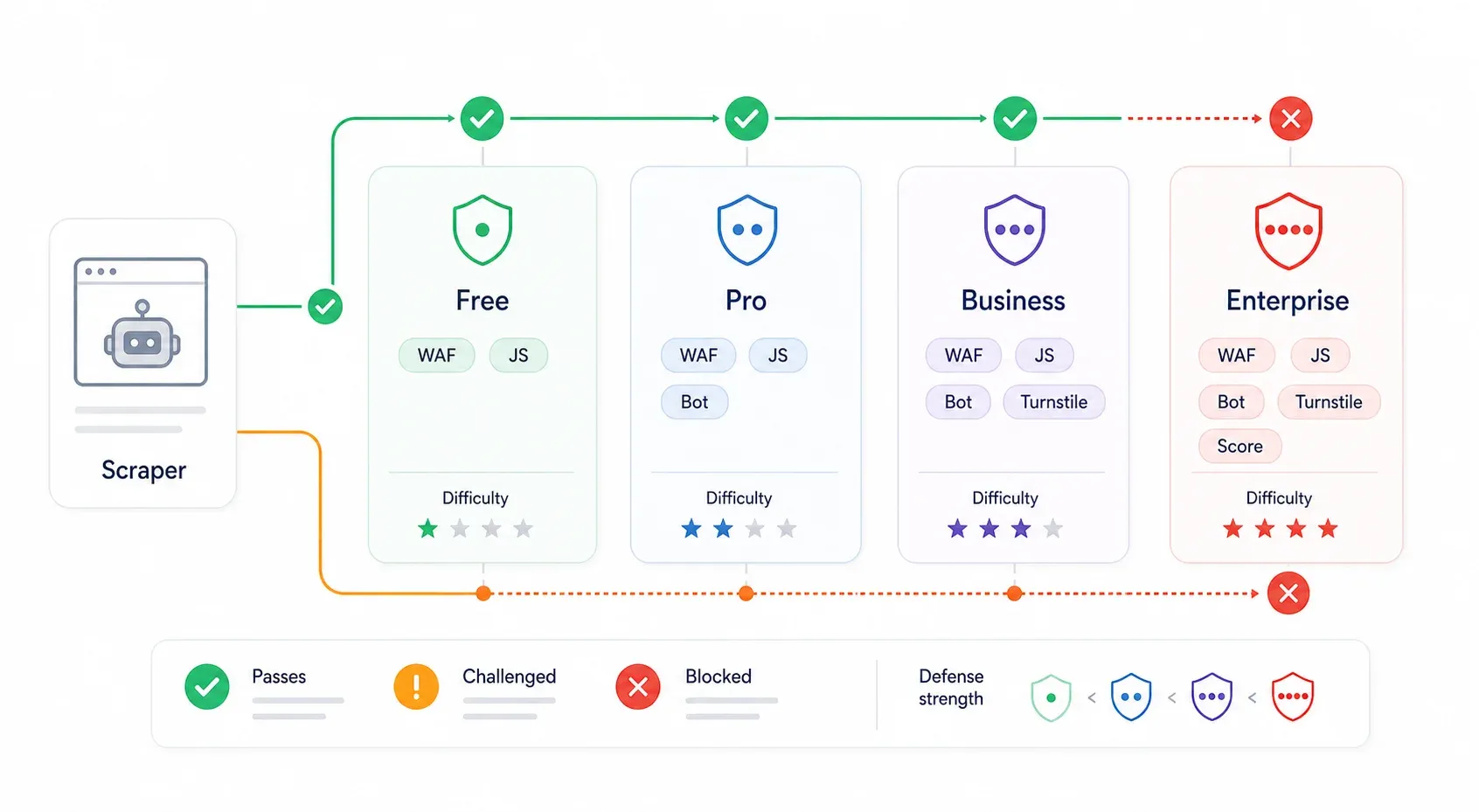
顯示 Free 為 $0、Pro 為 $20/月、Business 為 $200/月,Enterprise 則採客製化報價。 是免費方案中的基本開關; 則為 Pro/Business 提供更多控制;Enterprise Bot Management 則加入更細緻的 bot 分數與端點專屬規則。
如何大致判斷你遇到的是哪個等級: 如果你看到的是 Cloudflare 品牌的封鎖頁,而且沒有挑戰腳本,通常代表是 WAF 或指紋拒絕。若頁面出現 cf-turnstile 的 div,或載入了 challenges.cloudflare.com/turnstile/v0/api.js,那就是 Turnstile。若你看到「Checking your browser」中介頁,則通常是 Managed Challenge。首頁能成功打開,但特定路徑失敗,往往表示那條路徑套用了更嚴格的 WAF 或 Bot Management 規則。
在選擇方法前先確認防護等級,真的可以省下好幾個小時的除錯時間。
「先試這個」的 Cloudflare 繞過決策樹
與其亂試各種方法,不如照著優先順序走。從最簡單、最穩定的方式開始,必要時再逐步升級:
| 步驟 | 先試這個 | 原因 | 失敗後 → |
|---|---|---|---|
| 1 | 檢查是否有內部/未公開 API | 完全繞開 Cloudflare;最快也最穩定 | 步驟 2 |
| 2 | 使用內建瀏覽器渲染的無程式碼工具(例如 Thunderbit) | 不需設定,會自動處理 JS 挑戰 | 步驟 3 |
| 3 | TLS 指紋偽裝(curl_cffi) | 快、輕量、不需要瀏覽器 | 步驟 4 |
| 4 | 隱匿式瀏覽器自動化(SeleniumBase UC / Puppeteer stealth) | 能處理 JS 挑戰與指紋偵測 | 步驟 5 |
| 5 | FlareSolverr + Docker | 開源、適合伺服器部署 | 步驟 6 |
| 6 | 付費爬蟲 API(ScrapingBee、ZenRows、Scrapfly 等) | 直接把這場攻防戰交給供應商 | — |
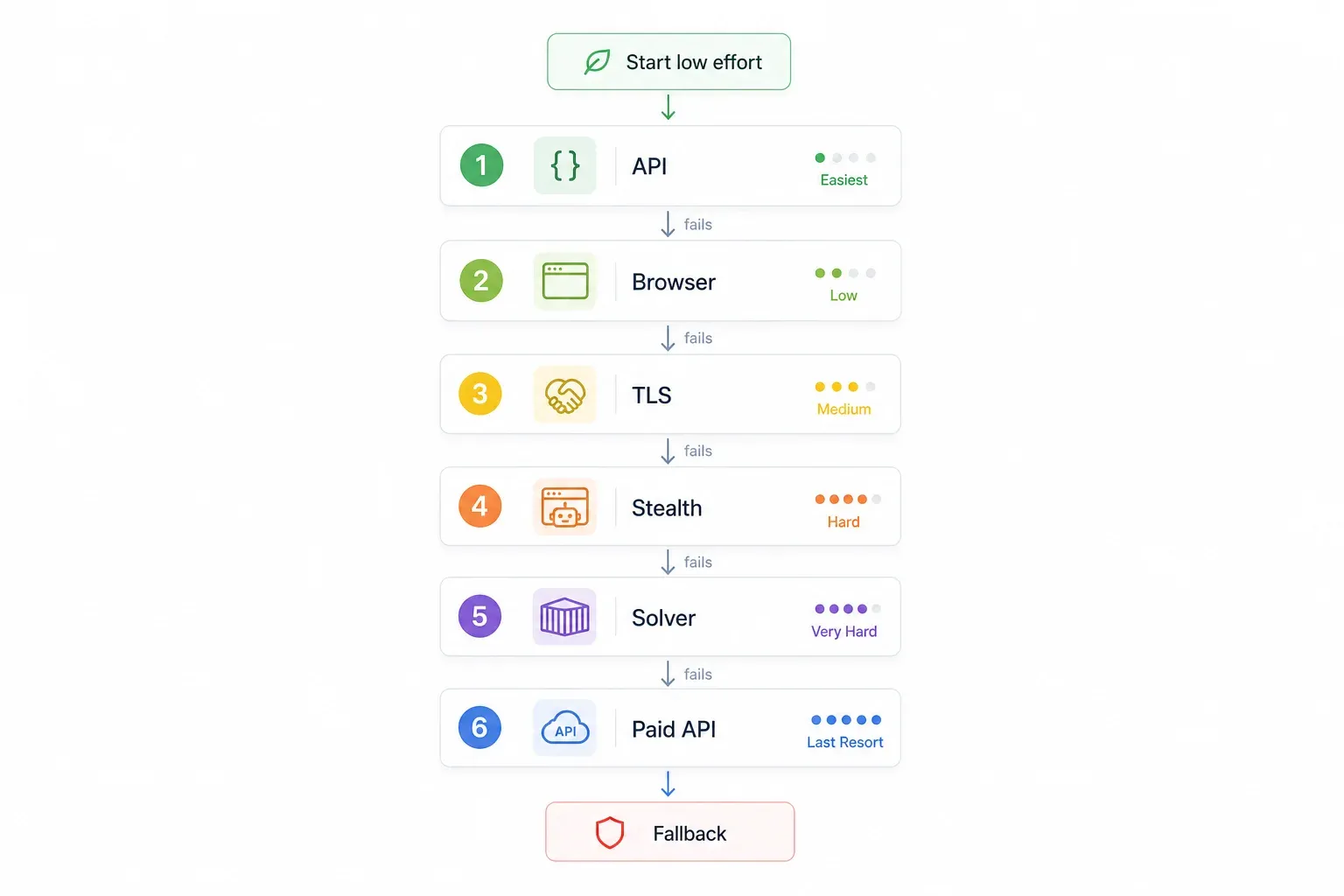
邏輯很簡單:先從免費、低成本的方法開始,最後才考慮寫程式或付費。直接跳到最符合你情況的步驟即可。
聲稱,curl_cffi 在 20 個測試網域中通過了 16 個(80%),FlareSolverr 約可涵蓋 55–70%,而付費代理整合服務平均成功率約 97%——但同一串討論也提醒,這些數字會隨 Cloudflare 更新而變動。所有成功率都只能當作方向參考,不能視為保證。
第 1 步:先別硬碰硬——找出 Cloudflare 背後的內部 API
我看到的四個不同論壇討論都建議,與其正面對抗 Cloudflare,不如先找網站的內部 API。老實說,這也是最聰明的第一步。如果網站有內部 API,你就能完全繞開 Cloudflare——不需要技巧、不需要偽裝指紋,也不需要 stealth 外掛。
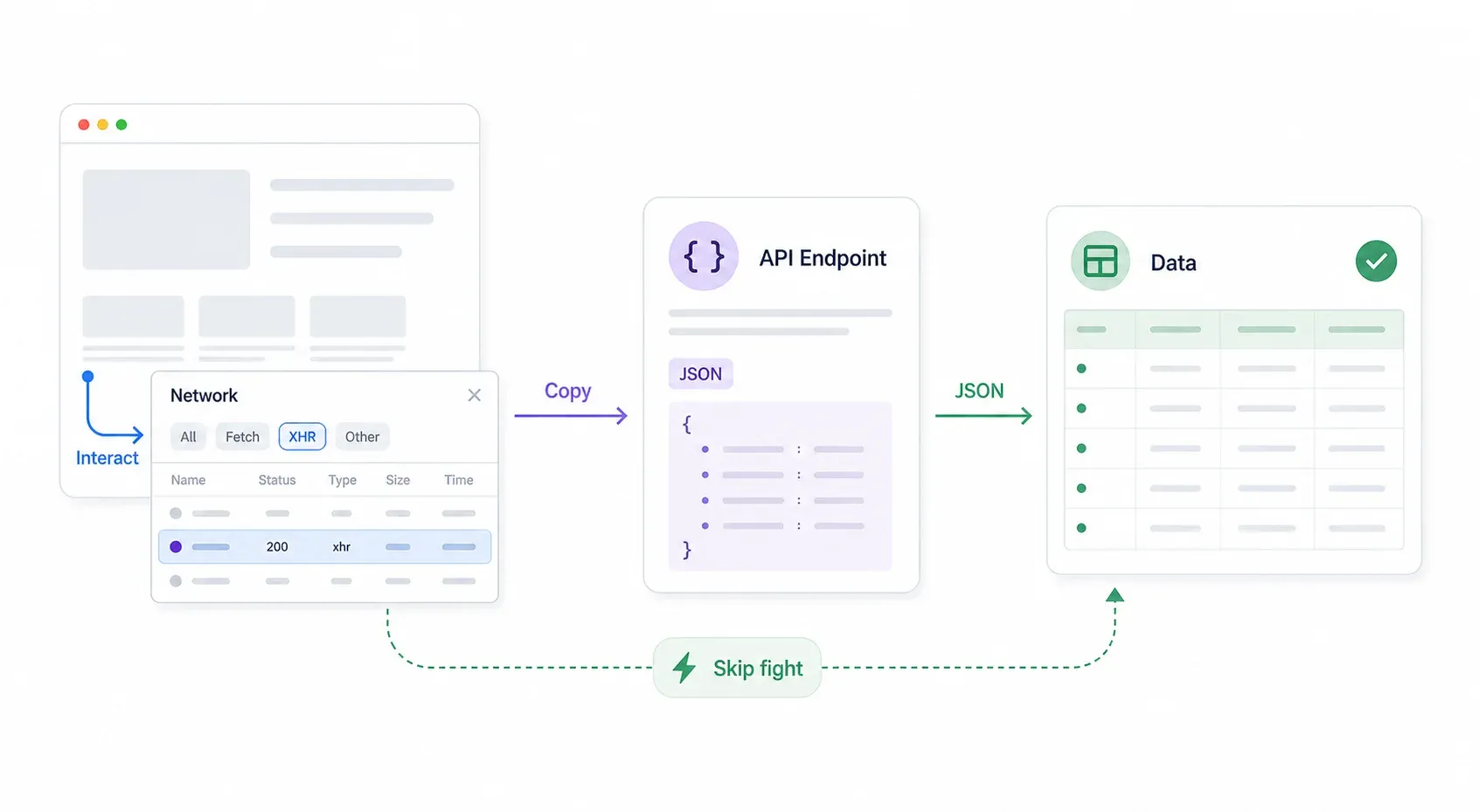
系統化的做法如下:
- 打開 Chrome DevTools → 前往 Network 分頁 → 篩選 XHR/Fetch。
- 與頁面互動:搜尋、篩選、翻頁、捲動。注意 Network 分頁中是否出現 JSON 回應。
- 檢查請求 URL 和標頭。 很多時候 API 端點沒有 Cloudflare 防護,或防護比前端頁面更弱。
- 在請求上按右鍵 → Copy → Copy as cURL。 把它貼到終端機或 Postman 中測試。
- 在 Python 中重現請求(使用
requests或curl_cffi),並沿用相同的標頭、Cookie 與查詢參數。
如果 API 回傳的是結構化 JSON,那你可能根本不需要傳統爬蟲。就描述了這種情況:某位使用者即使使用 curl_cffi 還是被 Cloudflare 擋下,最後唯一可行的方法是直接攔截 API 回應。
實用技巧: 當 cURL 複製後可以運作,再開始刪掉不必要的標頭。像 sec-ch-ua、cookies、CSRF tokens、referer 這些可能是必要的;但瀏覽器快取控制相關標頭通常不是。若你是從瀏覽器 cURL 轉成程式碼,請確保 TLS 指紋與 User-Agent 保持一致。
限制: 不是每個網站都有可存取的 API。有些 API 需要驗證、CSRF token、簽名參數,或依賴 session 的 Cookie。但只要成功,這幾乎就是接近 99% 成功率、而且幾乎不用維護的方法。
第 2 步:無程式碼路線——用瀏覽器擴充功能繞過 Cloudflare(Thunderbit)
大多數競品文章都預設讀者會寫 Python 或 JavaScript。但這個關鍵字其實也吸引了業務團隊在建立開發名單、電商營運在監控競品價格、以及房地產分析師在抓取物件資料。這些人通常不想自己架 Docker 容器。
像 這樣的 Chrome 擴充功能,天生就能處理許多 Cloudflare 檢查,因為它是在你的真實瀏覽器工作階段裡執行。它會繼承 Chrome 真實的 TLS 指紋、你的 Cookie、登入狀態,以及行為訊號——這些正是 Cloudflare 最信任的資訊。沒有 stealth 外掛、沒有 xvfb-run、也不用敲終端機指令。
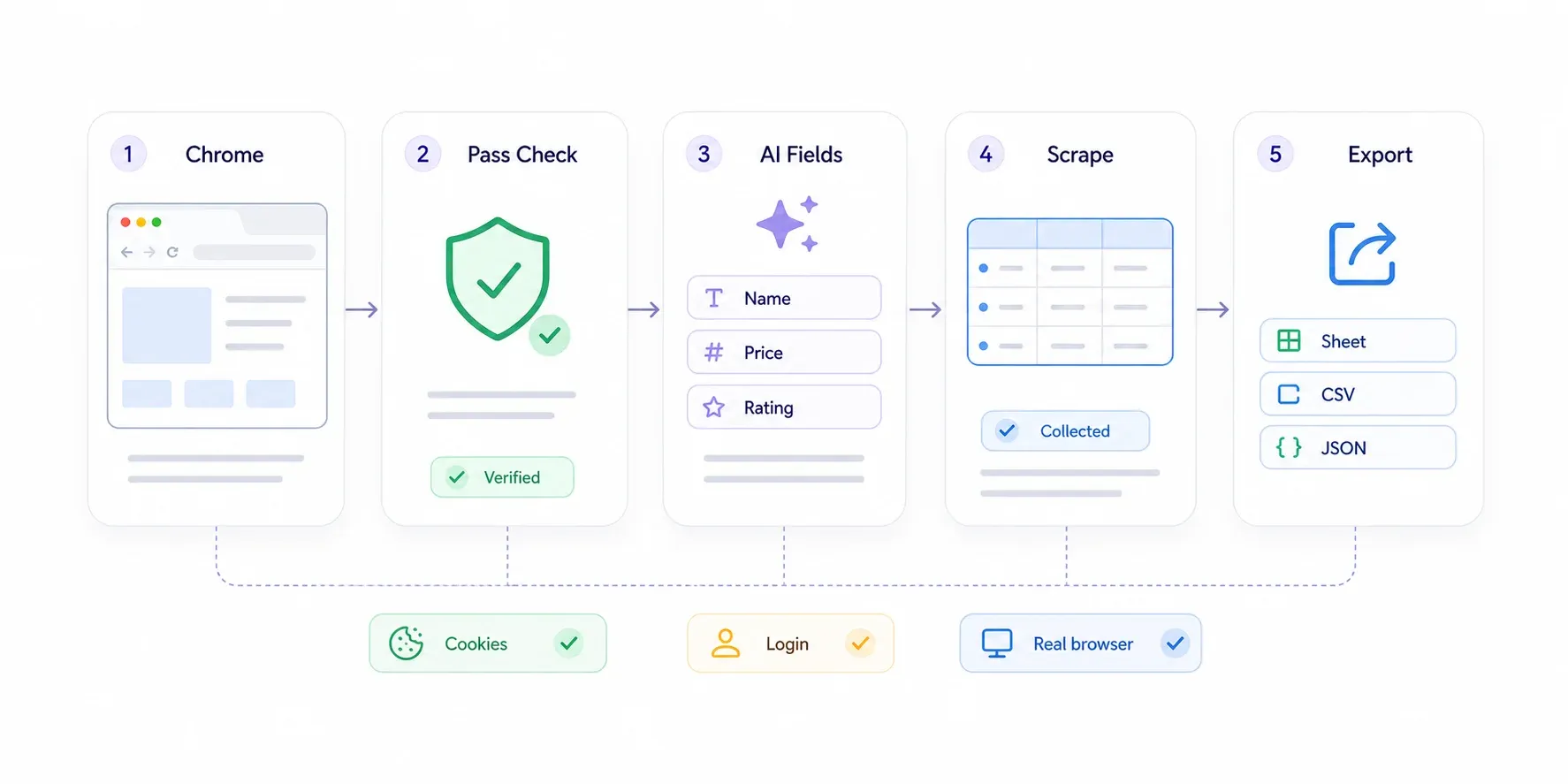
操作步驟
- 從 Chrome 線上應用程式商店安裝 。
- 在 Chrome 中打開受 Cloudflare 保護的頁面。若 Cloudflare 要你驗證,就像一般使用者一樣通過:點 Turnstile 勾選框、等待「Checking your browser」頁面消失。你是用真實瀏覽器操作的真實使用者,Cloudflare 會放行。
- 在 Thunderbit 側邊欄點選 「AI Suggest Fields」。AI 會掃描頁面並自動建議欄位,例如「產品名稱」、「價格」、「評分」,或任何與你需求相關的欄位。
- 檢查建議欄位。刪掉不需要的,並用自然語言描述你想要的內容,新增自訂欄位。
- 點選 「Scrape」。Thunderbit 就會開始擷取當前頁面的資料。
- 匯出到 Google Sheets、Excel、Airtable、Notion、CSV 或 JSON。
對於有分頁的網站,Thunderbit 同時支援點擊式分頁與無限捲動。若是詳細頁面(例如你已經有一串商品連結,想抓每個商品頁的規格),可以使用 ——Thunderbit 會逐一造訪每個連結頁面並補充你的表格資料。
依我經驗,對一般 50–100 筆資料的任務來說,從安裝到匯出試算表通常只要 5–10 分鐘。
什麼時候瀏覽器式抓取最好用?什麼時候不適合?
我也要誠實說明限制。瀏覽器式抓取的速度受限於你的工作階段。它很適合中等規模任務——幾百到幾千頁。如果你需要排程式地抓取上百萬頁,那你會更需要程式碼方案或 API 方案。
Thunderbit 的 Cloud Scraping 功能可以加快速度,對公開可存取網站一次最多可抓 50 頁。若是開發者流程或更大規模需求,Thunderbit 的 則可處理 JavaScript 渲染、反機器人防護與代理輪換,並支援每次批次最多 。
但如果你是要抓名單、價格資料或房源清單,而且規模合理?這通常就是你唯一需要的方法。免寫程式、免代理、免維護。
第 3 步:使用 curl_cffi 做 TLS 指紋偽裝(輕量級程式方案)
如果你會寫 Python,而且無程式碼方案不符合你的工作流程, 是最輕量的程式選項。它是建立在 libcurl 上的 Python 綁定,可以模擬真實瀏覽器的 TLS 指紋。和 requests 或 httpx 不同,你的 TLS 握手看起來就像來自 Chrome 或 Safari。
截至 2026 年,包括 chrome136、safari184,以及許多歷史版本設定。這個函式庫在 ,代表它還在積極維護中。
適合使用的情境: 主要依賴被動指紋偵測的免費版或 Pro 級 Cloudflare 保護網站——沒有主動式 JavaScript 挑戰,也沒有 Turnstile。
基本範例:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])最容易踩坑的一點: User-Agent 要和模擬目標一致。如果你要偽裝成 Chrome 136,就不要送出 Chrome 120 的 User-Agent。這種不一致本身就是訊號。
限制: curl_cffi 不會執行 JavaScript。如果網站回傳的是「Checking your browser」挑戰頁或 Turnstile 小工具,這種方法就會失敗。對於需要瀏覽器挑戰後才能取得 cookie 狀態的網站,它也派不上用場。把它想成是對只做被動防護網站的快速、便宜第一試。
同類替代方案: tls-client 與 curl-impersonate 也提供類似的 TLS 模擬能力。
第 4 步:隱匿式瀏覽器自動化(Puppeteer Stealth 與 SeleniumBase UC)
當網站需要執行 JavaScript、主動挑戰,或 Turnstile 時,TLS 偽裝就不夠了。這時你需要完整的瀏覽器。主要有兩種選擇:
- SeleniumBase UC Mode(Python): 可以讓自動化看起來更像真人,並避開反機器人服務。它還附有處理 Cloudflare Turnstile 的範例。
- 搭配
puppeteer-extra-plugin-stealth的 Puppeteer(Node.js):這套工具仍然常見,但在 。社群回報指出,它會因 CDP(Chrome DevTools Protocol)偵測標記和瀏覽器設定檔不一致而失敗。
這兩種工具都會啟動真實的 Chromium 瀏覽器,但會修補可被偵測的自動化訊號:navigator.webdriver、WebGL 中繼資料、外掛清單等等。
真正重要的設定建議:
- 使用有介面模式(不是 headless)。SeleniumBase 的文件明確提醒,UC Mode 在 headless 模式下更容易被偵測。在 Linux 伺服器上,請搭配虛擬顯示器使用。
- 隨機化視窗尺寸與 User-Agent,但兩者之間,以及與代理地理位置之間,都要一致。
- 在動作之間加入合理延遲。 例如頁面載入間隔只有 200 毫秒,幾乎就是在告訴對方「我是機器人」。
- 通過初始挑戰後,保留 Cookie 與瀏覽器設定檔。 不要每次請求都重新解題。
- 搭配住宅代理,以提升 IP 信譽。
這種方法最大的風險是維護成本。當 Chrome 更新、Cloudflare 加入新訊號、stealth 外掛跟不上,或者目標網站改成針對特定路徑使用 Turnstile,整個自動化堆疊就可能壞掉。發現,很多 stealth 瀏覽器組合會因為「franken-fingerprint」的混搭而在指紋測試中失敗——例如時區、語言與代理地理位置互相矛盾。
這方法很強,但運營成本也高。請預留持續修補的時間。
代理輪換:為什麼 IP 跟指紋一樣重要
就算瀏覽器隱匿得再好,從同一個 IP 發送太多請求,還是會觸發速率限制。Cloudflare 對住宅 IP 和行動 IP 的信任度,遠高於資料中心 IP。
- 住宅代理: 2026 年入門量級約 。更容易被信任,但也更貴。
- 資料中心代理: 雖然便宜,但在 。
- 輪換策略: 以工作階段輪換,不要以每個請求輪換。每次請求就換 IP 會破壞 session cookie 和
cf_clearance。在同一個 session 裡,IP、Cookie 和指紋都要保持一致。
並沒有什麼神奇的「最小代理池大小」。低流量的名單抓取可能只需要幾個固定的住宅 session;高流量的價格監控可能就需要數百個出口節點與重試邏輯。
第 5 步:FlareSolverr —— 開源的 Cloudflare 繞過伺服器
是一個開源代理伺服器,它在 Docker 容器中使用 Chromium 與 undetected-chromedriver 來解決 Cloudflare 挑戰,並回傳可重複使用的 cookies/headers。它在 ,代表目前仍在維護。
適合使用的情境: 伺服器端的爬取流程,需要一個持續存在的挑戰解決服務——例如每天夜間執行的自動任務,需要新的 cf_clearance Cookie。
運作方式: 你的爬蟲把網址送給 FlareSolverr 的 API。FlareSolverr 會在瀏覽器中打開頁面、嘗試通過挑戰,然後回傳 HTML 與 Cookie。之後你就可以在一般 HTTP 用戶端中重用這些 Cookie。
設定概覽: 用 Docker Compose 啟動容器,然後對本機 API 端點送出 POST 請求。。
我想先說清楚的限制:
- 無法穩定通過互動式 Turnstile 挑戰或 Enterprise Bot Management。
- 和 顯示它的行為不穩定:挑戰偵測漏抓、Turnstile 逾時、頁面當掉。
- 需要 Docker 基礎設施與持續維護。
- 資源消耗高——每次解題都會啟動一個瀏覽器 context。
預估可靠度:中等防護目標約 60–80%。Enterprise 級別會更低,簡單的挑戰頁則更高。如果 FlareSolverr 不夠用,那就該考慮付費 API 了。
第 6 步:讓 Cloudflare 幫你處理掉的付費爬蟲 API
有時候算一算就知道:自己維護隱匿基礎設施的人力成本,往往比訂閱費還高。付費爬蟲 API 會把整場攻防戰交給專業供應商——你只要送出 URL,對方負責指紋偵測、代理、挑戰解題與重試。
怎麼比較這些服務:
| 供應商 | Cloudflare 支援 | JS 渲染 | 住宅代理 | 結構化輸出 | 計價方式 |
|---|---|---|---|---|---|
| ScrapingBee | 有 | 有 | 有 | 只有 HTML | 依請求扣點 |
| ZenRows | 有(宣稱成功率 >99%) | 有 | 有(高階方案) | HTML、部分解析 | CPM 搭配倍率 |
| Scrapfly | 有(列出 CF、Akamai、DataDome) | 有 | 有 | HTML、部分解析 | 依點數計費 |
| Browserless | 有 | 有(headless Chrome) | 有(內建) | HTML、截圖 | 依單位計費 |
| Thunderbit API | 有 | 有 | 有 | 透過 AI 結構輸出 JSON/CSV | 免費額度 + 付費方案 |
什麼時候值得用: 高流量爬取、需要企業級穩定性,或者你的團隊不想自己維護爬蟲基礎設施。費用大約落在每月 $30–$500+,小到中等用量適合,企業級流量則會更高。
Thunderbit API 值得另外提一下,因為它輸出的是結構化資料,而不只是原始 HTML。它的 每次最多可批次處理 50 個 URL,並根據 AI 驅動的 schema 回傳 JSON/CSV——如果你需要的是可直接分析的乾淨資料,而不是還要自己解析 HTML,這就很實用。
誠實可靠度排行榜:哪些真的有效,哪些會壞掉
我在 2025–2026 年間持續追蹤社群回報、GitHub issues 與各家廠商宣稱。下面這份比較是坦白版的結論,都是方向性估計,不是實驗室測試:
| 方法 | 估計成功率 | 維護負擔 | 何時會失效 | 成本範圍 |
|---|---|---|---|---|
| 內部 API(若存在) | 約 90–99% | 低 | API 改版、加入驗證、token 變成簽名式 | 免費 |
| 瀏覽器擴充功能(Thunderbit) | 約 85–95%(真實 session) | 低(AI 會適應版面變化) | 網站需要特殊驗證流程、每個動作都嚴格檢查 Turnstile | 有免費方案 |
curl_cffi / TLS 偽裝 | 約 70–85% | 中(需更新指紋) | Cloudflare 變更 JA3 檢查、需要主動 JS 挑戰 | 免費 |
| Puppeteer + stealth 外掛 | 約 70–90% | 高(外掛更新常落後) | CDP 偵測、新指紋訊號、headless 偵測 | 免費 + 代理成本 |
| FlareSolverr | 約 60–80% | 高(Docker、相依項漂移) | Enterprise 級防護、Turnstile 互動 | 免費 + 基礎設施成本 |
| 付費爬蟲 API | 約 85–95% | 低(由供應商維護) | 供應商未更新、預算用完 | 約 $30–500+/月 |
最重要的不是成功率那欄,而是「何時會失效」。每種方法都有失敗模式。最好的策略是挑選對你的目標而言成本最低、又能實際運作的方法,並準備好備用方案。
沒有永久解法。Cloudflare 會持續更新。這場軍備競賽是真實存在的。
不管用哪種方法,都能幫你降低被 Cloudflare 注意到的機率的小技巧
無論你選哪一種方法,下面這些習慣都能讓你更久不被 Cloudflare 盯上:
- 尊重速率限制。 請在請求之間加入合理延遲——模擬真人瀏覽時,至少保留 2–5 秒。用機器速度狂掃網站,是最快被封鎖的方法。
- 保持指紋一致。 User-Agent、TLS 指紋、瀏覽器版本、時區、語系與 IP 地理位置都應該講同一個故事。來自德國 IP、語系是
en-US、TLS 握手卻像 Python 的 Chrome 136 User-Agent,就是明顯矛盾。 - 通過挑戰後重用 Cookie 與 session。 不要每次請求都重新解題。
- 不要在 session 中途切換 IP。 Cloudflare 會追蹤 session 的連續性。
- 當用途與預算允許時,使用住宅或行動 IP。
- 留意軟性封鎖: 原本應該回傳 JSON,卻變成挑戰 HTML;表格空白;登入重新導向;或頁面看起來很像 的誘餌頁。
- 避開流量高峰時段。 因為網站管理者可能會在這時調高 WAF 規則。
- 建立備援路徑: 先 API → 再瀏覽器 session → 最後付費供應商。
對 Thunderbit 使用者來說尤其如此:AI 會自動適應頁面版面變化,所以你花在維護 CSS selectors 上的時間會少很多,能把時間花在真正使用資料上。
關於法律與倫理的一點提醒
這不是本文主軸,但太重要,不能不提。
在某些情境下,針對公開可存取資料的抓取在美國有——hiQ v. LinkedIn 的 CFAA 理由在最高法院發回重審後仍存續,但雙方於 2022 年和解,整體情況仍相當複雜。更近期,,指控其抓取使用者留言;同一年稍晚,。
在歐盟,只要涉及個人資料,GDPR 就適用; 也對 加入了特定義務。
幾個實務上的基本原則:
- 一定要先查看網站的服務條款。
- Cloudflare 保護本身就是一個訊號,代表網站擁有者希望控制自動化存取——請尊重這個意圖。
- 不要在沒有合法依據的情況下收集個人資料。
- 若是商業用途或高流量工作流程,若有官方 API、授權資料或書面許可,優先使用。
- 若不確定,請針對你的具體情境與司法管轄區諮詢法律顧問。
Thunderbit 的設計目標是合法的商業用途——例如開發名單、價格監控、市場研究——並使用公開可存取的資料。
結語:先試什麼,下一步再試什麼
這整篇文章真正幫你省時間的,不是某個工具或程式碼片段,而是「在開始前先辨識防護等級」。光是這一步,就能避免你花好幾個小時去除錯一個本來就不可能成功的方法。
建議從這裡開始:
- 先檢查是否有內部 API(免費、快速,而且常被忽略)。
- 如果你是不用寫程式的商務使用者,試試 ——你的真實瀏覽器 session 是對抗 Cloudflare 最好的資產。
- 如果你是開發者,而且目標只用了被動式指紋偵測,試試
curl_cffi。 - 只有在更簡單的方法失敗時,才再升級到 stealth 瀏覽器、FlareSolverr 或付費 API。
沒有任何單一方法是永久有效的。把適合你規模的工具與備援方案結合起來,你就不會老是盯著 403 頁面發呆。
如果你想再深入一點,我們在 Thunderbit 部落格也寫了、,以及。如果你想直接看擴充功能實際運作,歡迎到 看操作教學影片。
常見問題
1. 能完全繞過 Cloudflare 保護嗎?
沒有任何單一方法能保證 100% 成功,尤其是面對 Enterprise 等級的 Bot Management、Turnstile、JA4 指紋與 AI Labyrinth。最可靠的方式,通常是把真實瀏覽器指紋與良好的 IP 信譽結合起來。找到內部 API 是最接近「完全繞過」的做法,因為它根本不需要碰 Cloudflare——但不是每個網站都有這種 API。
2. 抓取時繞過 Cloudflare 合法嗎?
這要看你的司法管轄區、網站的服務條款,以及你要抓取的資料內容。在某些情境下,抓取公開資料在美國有較有利的判例(hiQ v. LinkedIn),但若是繞過技術性存取控制、違反 ToS,或在沒有合法依據下收集個資,就可能產生法律風險。商業用途建議優先使用官方 API 或授權資料;若不確定,請諮詢法律顧問。
3. 不寫程式的話,最簡單的 Cloudflare 繞過方式是什麼?
像 這種在你真實 Chrome session 內執行的瀏覽器擴充功能,能自動處理 Cloudflare 挑戰——你像一般使用者一樣與網站互動,接著讓擴充功能擷取並匯出資料。不需要 Python、Docker,也不用設定代理。
4. 為什麼我的爬蟲能在某些 Cloudflare 網站上運作,到了其他網站卻不行?
Cloudflare 的防護等級會因方案(Free、Pro、Business、Enterprise)與設定而有巨大差異。能通過 Free 方案網站上基本 JS 挑戰的方法,可能在 Enterprise 網站的 Turnstile 或完整 Bot Management 面前完全失效。請先確認你遇到的是哪一種防護——簡單 JS 檢查、Managed Challenge,還是 Turnstile 小工具——再決定繞過方式。
5. Cloudflare 繞過方法多久會失效一次?
像 stealth 外掛與 TLS 偽裝這類程式方法,會隨 Cloudflare 更新偵測機制,可能在幾週到幾個月內逐漸失效。付費 API 與真實瀏覽器 session 工具通常更有韌性,因為它們是在基礎設施層或使用者 session 層進行適應。內部 API 通常不太會壞,除非網站重構後端或更改驗證模型。長期來看,最安全的做法是準備多個備援方法,而不是只依賴單一路線。
延伸閱讀