Firecrawl 已經成為 AI 開發者圈最受矚目的網頁爬取 API 之一——、Y Combinator 投資,以及客戶名單中包含 Shopify、Zapier 和 Apple。不過,仔細看過定價文件、使用者抱怨、第三方基準測試與真實成本模型之後,你會發現宣傳故事和實際體驗之間,其實差距不小。
這篇 Firecrawl 評測不是另一份功能清單。如果你已經註冊、跑過幾次測試擷取,現在正想知道「放大到實際規模後,這到底會花我多少錢?」——或者你只是想先確認 Firecrawl 到底適不適合你的團隊——那你來對地方了。我會帶你看真實成本(包括多數評測都略過的雙重計費陷阱)、Firecrawl 真正擅長的地方、它最容易失手的情境(尤其是有防機器人保護的網站)、以及什麼時候應該直接換成完全不同的工具——包括像 這類免程式碼方案。我的目標很簡單:幫你避開下一張意外的信用卡帳單。
Firecrawl 是什麼?適合誰用?
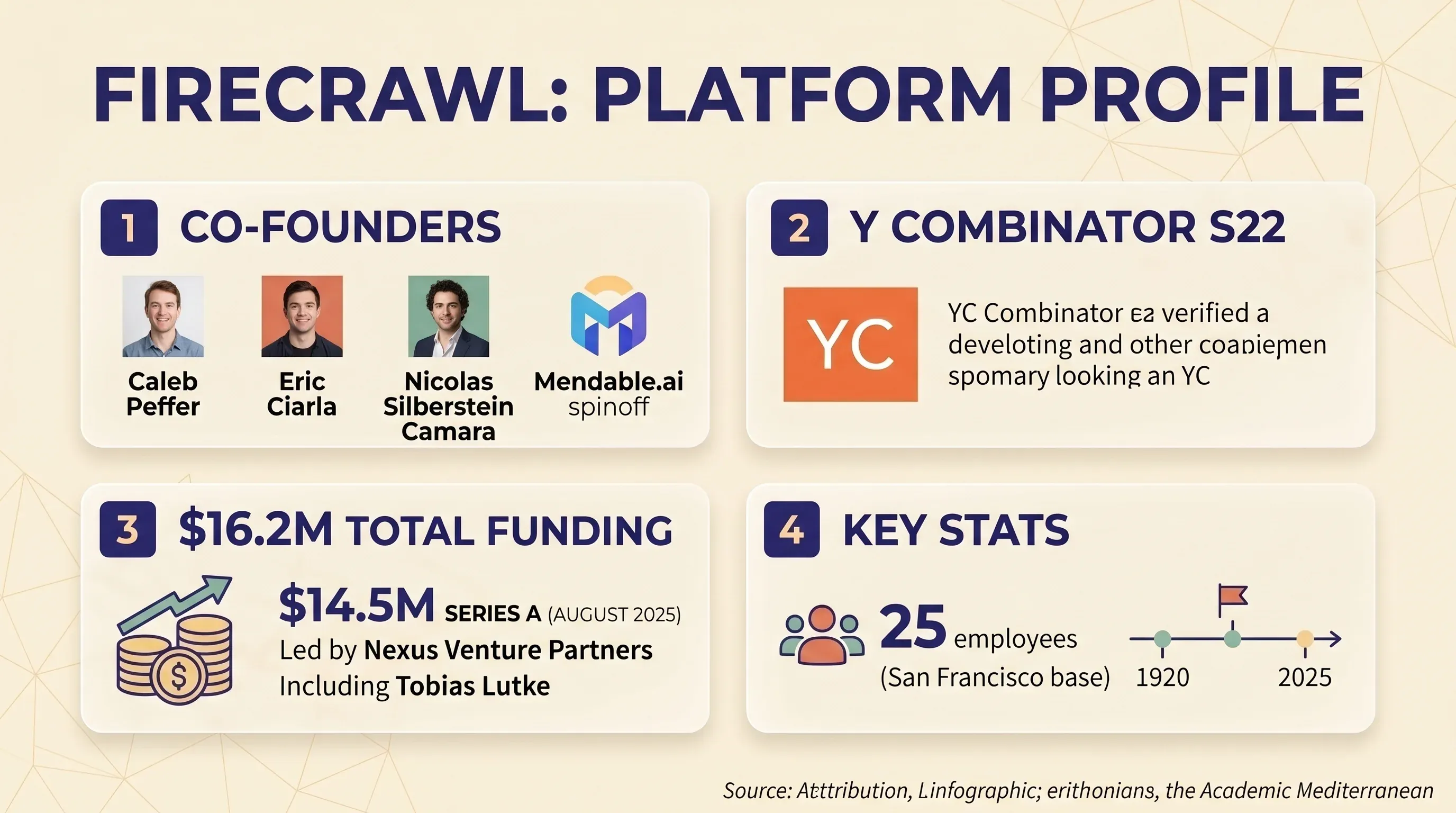
Firecrawl 是一個以 API 為核心的網頁爬取與抓取平台,能把網站轉成乾淨的 markdown 或結構化 JSON。它主要是為正在打造 AI 與 LLM 應用的開發者而設計,例如 RAG 流程、聊天機器人知識庫,以及 AI agent 工作流程。這家公司由 Caleb Peffer、Eric Ciarla 和 Nicolas Silberstein Camara 創立,原本是 Mendable.ai 的衍生專案。他們經過 ,並在 2025 年 8 月完成由 Nexus Venture Partners 領投的 ,Shopify 執行長 Tobias Lutke 也有參與。總募資金額為 1,620 萬美元。團隊共 25 人,總部位於舊金山。
Firecrawl 提供四種核心模式,外加兩個較新的功能:
| 模式 | 功能說明 |
|---|---|
| Scrape | 將單一 URL 轉成 markdown、JSON 或截圖 |
| Crawl | 抓取一個 URL 及其所有子頁面 |
| Map | 在幾秒內找出網站上的所有 URL(最多 10 萬個 URL) |
| Search | 進行網頁搜尋,並擷取完整頁面內容 |
| Extract | 透過提示詞或 schema 進行 AI 驅動的結構化擷取 |
| Agent(研究預覽) | 不需指定 URL,即可自動進行網頁研究 |
先說清楚:Firecrawl 是開發者工具。它需要 API 呼叫、程式能力和技術設定。如果你是業務使用者,想在不寫程式的情況下從網站抓資料,Firecrawl 不是為你而生的(後面會談替代方案)。但對正在打造 AI 應用的開發團隊來說,它的賣點很吸引人——乾淨、可直接餵給 LLM 的網頁資料,而且基礎設施負擔很低。
Firecrawl 評測:價格方案一眼看懂
表面上看,Firecrawl 的定價相當直觀。以下是 上列出的內容:
| 方案 | 月費 | 每月點數 | 併發數 | 年費 |
|---|---|---|---|---|
| Free | $0 | 500(一次性,不是每月) | 2 | — |
| Hobby | $19/月 | 3,000 | 10 | 年繳 $16/月 |
| Standard | $99/月 | 100,000 | 50 | 年繳 $83/月 |
| Growth | $399/月 | 500,000 | 100 | 年繳 $333/月 |
| Scale | $749/月 | 1,000,000 | 1,000 | 年繳 $599/月 |
有幾件事一眼就很關鍵。免費方案的 500 點數是一次性,不是每月——很多使用者往往要等點數用完,才發現這件事。而且這些方案看起來雖然簡單,但實際成本高度取決於你用了哪些功能。頁面上看到的價格,其實只是起點。真正的帳單?那才是下一節要談的。
Firecrawl 的真實成本:依你的使用情境計算點數
定價是 Firecrawl 真實使用者最常抱怨的痛點——「貴得要命」、「照我的使用量,我得升到 99 美元/月的方案」、「貴得離譜」這些都是 Hacker News 和 Reddit 討論串裡的真實原話。原因在於:Firecrawl 有一套雙重計費系統,幾乎所有評測都完全忽略了。
陷阱就在這裡:Firecrawl 的點數方案涵蓋 Scrape、Crawl、Map 和 Search。但 Extract——這個 AI 驅動的結構化擷取,也是 Firecrawl 的主打功能之一——採用的是完全獨立的 token 訂閱制。
| Extract 方案 | 月費 | 每年 Tokens | 每月 Tokens(約) |
|---|---|---|---|
| Starter | $89/月 | 1,800 萬 | ~150 萬 |
| Standard | $189/月 | 4,800 萬 | ~400 萬 |
| Growth | $389/月 | 1.08 億 | ~900 萬 |
| Pro | $719/月 | 1.92 億 | ~1,600 萬 |
所以,一家使用 Standard 點數方案($99/月)但同時需要擷取功能的新創公司,最低就得付 $99 + $89 = $188/月——這還沒算任何點數倍增。這就是讓人措手不及的雙重計費陷阱。
多數使用者會忽略的隱藏點數倍率
「每頁 1 點數」這句話其實很容易誤導。實際功能成本如下:
| 功能 | 點數成本 | 實際倍率 |
|---|---|---|
| 基本 Scrape/Crawl | 每頁 1 點數 | 1x |
| Search | 10 筆結果 2 點數 | 每組結果 2x |
| JSON 擷取(透過 Scrape) | 每頁 +4 點數 | 總計 5x |
| Enhanced Mode | 每頁 +4 點數 | 總計 5x |
| JSON + Enhanced Mode | 每頁 +8 點數 | 總計 9x |
| 瀏覽器互動 | 每分鐘 2 點數 | 變動 |
| Agent 模式(spark-1-mini) | 動態計費,約 100–500/query | 100–500x |
| Agent 模式(spark-1-pro) | 動態計費,約 200–1,500+/query | 200–1,500x |
還有幾個很重要的細節:點數不會跨月累積。失敗的請求仍然會扣點數(使用者回報在不穩定網站上會浪費 20–30%)。Agent 模式沒有執行前成本估算器——你只能設定 maxCredits 參數,但本質上就是在猜。免費方案的 500 點數若啟用擷取,大約只能跑 56 頁左右。這不算試用,頂多只是嚐個味道。
依使用者輪廓估算的每月成本表
| 使用者輪廓 | 每月頁數 | 使用功能 | 估計點數消耗 | 估計每月成本 |
|---|---|---|---|---|
| 業餘 / 副業專案 | 500 | 基本 scrape + crawl | ~500 點數 | $19/月(Hobby 方案) |
| 業餘 + JSON 擷取 | 500 | Scrape + Extract | ~2,500 點數 + $89 Extract | $108/月 |
| 新創 / AI 應用 | 5,000 | Scrape + Extract + Search | ~30,000 點數 + $89 Extract | $188/月(Standard + Extract) |
| 企業 / 資料管線 | 50,000 | 完整功能 + Agent | ~250,000–450,000 點數 + $389 Extract | $788–$1,138/月 |
一位每月付 190 美元的 Hacker News 開發者把體驗形容為「很貴,而且感覺半成品」,最後改用 2,700 行自訂 Elixir 程式碼取代 Firecrawl。這是一個相當強烈的訊號。
自架 Firecrawl:哪些是真的免費,哪些只有雲端版才有
「我可以直接免費自架 Firecrawl 嗎?」這是我最常看到的問題之一。答案是:算是可以,但大概不是你以為的那種免費。
Firecrawl 有開源核心(AGPL-3.0 授權),但有幾個重要功能只提供雲端版。以下是完整拆解:
| 能力 | 自架(免費) | 雲端(付費) |
|---|---|---|
| 基本 Scrape/Crawl 轉 markdown | ✅ | ✅ |
| Map(URL 探索) | ✅ | ✅ |
| LLM 驅動 Extract | ⚠️(需自備 LLM keys) | ✅(代管) |
| Agent 模式 | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| 防機器人 / 代理輪轉(Fire-engine) | ❌(使用你的固定 IP) | ✅ |
| 批次處理 | ❌ | ✅ |
| 儀表板 / 分析 | ❌ | ✅ |
| 代管基礎設施 | ❌(需要 Docker + PostgreSQL + Redis) | ✅ |
Fire-engine 是 Firecrawl 專有的防機器人系統,。自架使用者完全沒有防機器人能力,必須自己提供代理伺服器。
什麼情況下自架仍然有意義
如果你是開發者,只想要一條基本的 crawl-to-markdown 管線,而且你熟悉管理包含 5 個以上服務的 Docker Compose,自架就有可能成立。最低需求包括:4GB RAM、2 顆 CPU 核心,以及用於擷取的 LLM API keys(每頁約 $0.01–$0.10),如果需要,還要加上代理服務。全部算下來,自架成本約 $90–$340/月——在中等量級下,往往和雲端方案差不多。
為什麼使用者對自架版本不滿
真實使用者回饋描繪出來的畫面並不樂觀。多個 Reddit 和 GitHub 討論串都提到,自架版本會隨著時間變得越來越弱,因為功能逐漸移到雲端版。某位使用者直接總結:這家公司「試圖把所有使用者都推去付費,讓自架版形同虛設。」社群甚至做出一個 firecrawl-simple 分支來解決這些痛點。如果你把自架當成長期免費方案,最好調整期待——它適合拿來試驗,但無法在大規模情境下取代付費雲端產品。
Firecrawl 防機器人表現:哪些能過,哪些過不了
如果你最在意的是:「Firecrawl 到底能不能在我需要抓的網站上正常運作?」那這一節最重要。
簡短答案:完全取決於網站的防護強度。
基準測試數據
針對 15 個防機器人機制很重的網站,獨立測試了 10 家網頁爬取 API。Firecrawl 的結果如下:
| 供應商 | 成功率(2 req/s) | 成功率(10 req/s) |
|---|---|---|
| Zyte | 93.14% | 89.2% |
| ScrapFly | 91.8% | 88.5% |
| Bright Data | 88.7% | 84.9% |
| Firecrawl | 33.69% | 26.69% |
Firecrawl 在受保護網站上於 10 家供應商中。它的快速回應時間(平均 7.92 秒)部分是因為採取了「快速失敗」策略——它會很快回傳失敗,而不是反覆重試。
更長期的綜合基準則顯示,Firecrawl 的整體成功率為 65.4%(高於 59.5% 的產業平均),在容易目標上表現不錯,但在受保護網站上就明顯下滑。
網站難度分級:容易、中等、困難
| 難度 | 示例網站 | Firecrawl 成功率 | 建議 |
|---|---|---|---|
| 容易 | 部落格、文件站、公開 SaaS 頁面 | 85–98% | 可放心使用 Firecrawl |
| 中等 | 商品目錄、只有基本防護的新聞站、Etsy、Realtor.com | 53–65% | 請仔細測試,並預期會失敗 |
| 困難 | Amazon、LinkedIn、Instagram、Cloudflare 防護很重的頁面 | 0–33% | 不要依賴 Firecrawl,改用專門的防機器人供應商 |
受 Cloudflare 保護的網站是最常被回報的失敗點。多個 GitHub issue 都記錄了這個問題:即使使用 IP 輪轉,Cloudflare 的指紋辨識仍會擋下 Firecrawl。自架使用者受影響最嚴重,因為他們沒有 Fire-engine 的代理基礎設施。
當 Firecrawl 不夠用時怎麼辦
遇到防護很強的網站時,使用者通常會轉向 ScrapFly 或 Bright Data 這類專門代理服務,或使用帶有自訂隱蔽設定的 headless browser 工具。如果你是業務使用者,不想處理代理輪轉或成功率公式,像 這類免程式碼工具會在背後處理防機器人問題——你只要點一下,就能拿到資料。
Firecrawl 優缺點:誠實總結
Firecrawl 做得好的地方
- 乾淨、可直接給 LLM 使用的 markdown 輸出——格式穩定,標題層級也很完整。這確實是 Firecrawl 最強的賣點。
- 雲端使用者幾乎零基礎設施負擔——不用設定瀏覽器、不用管代理,也不用配置 headless browser。
- 廣泛的框架整合——LangChain、LlamaIndex、CrewAI、AutoGPT、Dify、、Flowise(AI 流程整合超過 7 種)。
- Map 端點的 URL 探索速度很快——完整 sitemap 大約 2–3 秒。
- 開源核心與 ——透明度高,也有社群貢獻。
- MCP server 支援,並搭配 FIRE-1 模型,適合 AI agent 工作流程。
- ——對 JavaScript 很重的頁面(React、Vue、Angular SPA)表現不錯。
Firecrawl 不足的地方
- 雙重定價(點數 + 另外的 Extract token 方案)會帶來沒人預期的帳單驚喜。
- 點數倍率讓實際成本比標價高出 5–9 倍。
- 防機器人表現:在 Proxyway 基準測試中敬陪末座( 對上表現最佳者的 93.14%)。
- Agent 模式的點數消耗不可預測,且沒有執行前成本估算器。
- 失敗請求仍會扣點——在不穩定網站上會浪費 20–30%。
- 自架版本缺少 Agent、Browser Sandbox、Fire-engine 防機器人和儀表板。
- 沒有原生 CAPTCHA 破解——相較 Bright Data 和 Zyte 這是很大的缺口。
- 不適合非技術使用者——需要寫程式和懂 API。
- 免費方案的 500 點數是終身制,不是每月補充——不足以做有意義的測試。
不只看開發者工具:Firecrawl 評測很少提到的免程式碼替代方案
我看過的每一篇 Firecrawl 評測,幾乎都只拿它去和其他開發者工具比較——Crawl4AI、Scrapy、Playwright、Apify。若你是開發者,這樣比很合理。但搜尋網頁爬取方案的人中,有很大一部分其實不是開發者:像是建立潛在客戶名單的業務團隊、監控競品價格的電商營運、蒐集內容資料的行銷人員、追蹤房源的房仲。
這裡其實有一個很值得補上的落差。
Firecrawl 替代方案比較表
| 工具 | 最適合 | 需要程式嗎? | 可直接給 LLM 使用的輸出 | 起始價格 |
|---|---|---|---|---|
| Firecrawl | 建 AI 應用的開發者 | 需要(API) | ✅ Markdown/JSON | $19/月 |
| Crawl4AI | 想要免費 / 開源的開發者 | 需要(Python) | ✅ Markdown | 免費 |
| Apify | 需要規模與市集的開發者 | 需要(SDK) | ⚠️ 需設定 | $39/月 |
| Thunderbit | 業務使用者(免程式碼) | 不需要(Chrome 擴充功能) | ✅ 結構化資料 | 有免費方案 |
| ScrapingBee | 需要代理的開發者 | 需要(API) | ❌ 原始 HTML | $49/月 |
| Bright Data | 企業資料團隊 | 需要(API/SDK) | ⚠️ 需設定 | $500+/月 |
為什麼 Thunderbit 是非技術團隊的首選
我在 Thunderbit 團隊工作,所以我先把立場講清楚。Thunderbit 會出現在這份比較裡,是因為它解的是和 Firecrawl 不同的問題、面向不同的受眾,而且完全不需要寫程式。
Thunderbit 的流程只要兩步:打開 ,點「AI 建議欄位」,再點「擷取」。AI 會讀取頁面、建議合適的欄位,並把結構化資料抓成表格。沒有 API keys,沒有 selector,也不需要寫程式。你可以免費匯出到 Excel、Google Sheets、Airtable 或 Notion。
對業務使用者來說,Thunderbit 的關鍵差異包括:
- 子頁面補強——點進詳情頁,自動抓取更多欄位
- 能因應版面變動的 AI——網站改版也不用手動維護
- 內建資料標註與翻譯——適合多語言資料集
- 熱門網站的即用範本——如 Amazon、Zillow、LinkedIn 等
如果你是偏開發者、想找 API 替代方案,Thunderbit 也提供 ,而且定價比 Firecrawl 的雙重點數 / token 制度更簡單。它不會取代 Firecrawl 在 LLM 流程開發上的位置。但對銷售、電商、行銷和營運團隊來說,如果你需要的是結構化資料而不是寫程式,那它會是更快也更便宜的路徑。
自建 vs 購買:Firecrawl 什麼時候划算,什麼時候不划算
「我想過自己寫一個網頁爬蟲……雖然比 Firecrawl 簡單,但至少比較便宜。」這是多位使用者提過的觀點。與其主觀討論,不如用一個結構化決策框架來看。
決策框架表
| 因素 | 自建(Scrapy/Playwright) | 購買 Firecrawl Cloud | 使用 Thunderbit(免程式碼) |
|---|---|---|---|
| 設定時間 | 10–40+ 小時 | 約 30 分鐘 | 約 5 分鐘 |
| 持續維護 | 高(selector 常壞) | 幾乎沒有(代管) | 零(AI 會自適應) |
| 防機器人處理 | 手動(代理、標頭、重試) | 內建(部分,但在受保護網站較弱) | 內建(瀏覽器 + 雲端模式) |
| 每月 1K 頁成本 | $50–150(伺服器 + 代理) | $19–$108(依功能而定) | $0–$15 |
| 每月 50K 頁成本 | $500–$1,500(基礎設施) | $399–$1,138 | $39–$249 |
| 可直接給 LLM 使用的輸出 | 需要自寫程式 | 內建(markdown/JSON) | 結構化表格(可匯出) |
| 最適合 | 完全控制、利基網站、DevOps 團隊 | AI/LLM 開發者、RAG 流程 | 業務、電商、行銷、營運 |
對多數組織來說,自建在三年內的成本會比 API 高出 。真正會出現自建更便宜的交叉點,大約是每月 1,000 萬頁以上——這是很少團隊真的會達到的規模。
誠實結論:哪條路最適合你?
Firecrawl 會划算的情況:
- 你的團隊已經在用 Python/JS 開發,而且需要乾淨的 markdown 供 LLM/RAG 流程使用
- 你的目標網站大多沒有強防護,或只有輕度防護
- 你想要代管基礎設施,但不想承擔 DevOps 負擔
- 你的量級維持在每月約 50K 頁以下
Firecrawl 不划算的情況:
- 你是沒有開發團隊的業務使用者,要做資料擷取 → Thunderbit 更簡單也更快
- 你的目標是高度防護網站(Amazon、LinkedIn、Cloudflare 很重的網站)→ Bright Data 或 Zyte
- 你需要大規模且可預測的帳單 → 點數倍率讓成本難以預期
- 你想要完整功能的自架版本 → Agent、Browser Sandbox、Fire-engine 都只在雲端版
只有在以下情況下,自建才有意義:
- 你的團隊有專職 DevOps 能力
- 你已經在超大規模運作(每月 1,000 萬頁以上)
- 你需要對利基或怪異網站的處理方式有完全控制權
- 你能接受持續維護 selector
Firecrawl 評測:並排比較表
以下把所有資訊放在一起看:
| 工具 | 類型 | 最適合 | 需要程式嗎 | 防機器人處理 | 可直接給 LLM 使用的輸出 | 可自架 | 起始價格 |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | AI/LLM 開發者 | 需要 | 對受保護網站較弱 | ✅ Markdown/JSON | ✅(有限) | $19/月 |
| Crawl4AI | Python 函式庫 | 開源優先的開發者 | 需要 | 無(自行處理) | ✅ Markdown | ✅ | 免費 |
| Apify | 雲端平台 | 需要規模 + 市集的團隊 | 需要 | 中等 | ⚠️ 需設定 | ✅ | $39/月 |
| Thunderbit | Chrome 擴充功能 + API | 業務使用者、免程式碼 | 不需要 | 內建 | ✅ 結構化資料 | ❌ | 免費方案 |
| ScrapingBee | API | 以代理為核心的開發者 | 需要 | 強 | ❌ 原始 HTML | ❌ | $49/月 |
| Bright Data | API + 代理網路 | 企業資料團隊 | 需要 | 最佳(約 99.9%) | ⚠️ 需設定 | ❌ | $500+/月 |
最終評語:Firecrawl 值得嗎?
Firecrawl 是一個很適合特定情境的紮實工具:如果你是要打造 LLM 應用、RAG 流程或 AI agents 的開發團隊,而且需要在中等規模下取得乾淨的網頁資料,又能接受 API 式工作流程,那它很值得考慮。markdown 輸出的品質確實是一流水準,而框架整合(LangChain、LlamaIndex、CrewAI)也相當成熟。如果你的團隊本來就主要使用 Python 或 JavaScript,而且目標網站沒有很強的防機器人保護,Firecrawl 可以幫你省下不少工程時間。
不過,缺點也很真實。雙重定價系統(點數 + 獨立的 Extract 訂閱)會讓帳單出現意料之外的驚喜。 的受保護網站成功率,代表你不能指望它穩定抓下 Amazon、LinkedIn 或 Cloudflare 很重的目標。自架版本少了太多功能,根本無法當成真正的免費替代方案。而且如果你不是技術使用者——例如銷售、電商或行銷人員——Firecrawl 完全不是為你設計的。
你可以先試用 Firecrawl 的 500 點免費額度,看看輸出品質是否符合你的流程。但在訂閱付費方案前,請先用上面的計算方式把真實每月成本算清楚。如果你只是想從網站取得結構化資料,而且不想寫程式,建議先從 開始——你會在幾分鐘內開始擷取資料,而不是幾小時。你現在就可以試試 ,或看看 了解哪個方案最適合你的團隊規模。若想看影片教學, 有逐步示範。
常見問題
Firecrawl 每抓取一頁要多少錢?
基本的 scrape 或 crawl 每頁 1 點數。JSON 擷取會額外加 4 點數/頁(總計 5 點)。Enhanced Mode 再加 4 點(最高總計 9 點)。Search 每 10 筆結果需 2 點數,而 Agent 模式每次查詢可能消耗 100–1,500+ 點數。此外,Extract 功能還需要獨立的 token 訂閱,起價 $89/月。請參考上方的成本計算區塊,依你的使用輪廓估算實際費用。
可以免費自架 Firecrawl 嗎?
可以,開源核心(AGPL-3.0)能免費自架。但你會失去 Agent 模式、Browser Sandbox、防機器人 / 代理輪轉(Fire-engine 是閉源的)、批次處理,以及管理儀表板。你需要自己提供 LLM keys 來做擷取,並自行管理 Docker、PostgreSQL 和 Redis。自架適合基本的 crawl-to-markdown 流程,但在正式生產規模下,不能取代雲端產品。
Firecrawl 適合抓 Amazon、LinkedIn 或其他受保護網站嗎?
顯示,Firecrawl 在高度防機器人保護的網站上成功率只有 33.69%,在 10 家測試供應商中排名最後。它在沒有防護的頁面上表現不錯(部落格、文件、SaaS 網站——成功率 85–98%),但對大型電商或社群平台並不可靠。這些目標建議改用 Bright Data 或 Zyte 這類專門防機器人供應商,或使用 Thunderbit 這類在背後處理防機器人的免程式碼工具。
非技術使用者最好的 Firecrawl 替代方案是什麼?
是最好的免程式碼替代方案。它是一個 Chrome 擴充功能,只要點「AI 建議欄位」再點「擷取」即可——不需要 API 呼叫、不需要寫程式,也不需要 selector。資料可免費匯出到 Excel、Google Sheets、Airtable 或 Notion。它就是為需要結構化網頁資料、但沒有開發者資源的銷售、電商、行銷和營運團隊而設計。
Firecrawl 有免費試用嗎?
Firecrawl 提供 ,而且不需要信用卡。這足以測試少數幾個頁面的基本 scrape/crawl 功能,但不足以用在正式生產——尤其是如果你啟用擷取功能(每頁會消耗 5 點)。免費方案的點數不會每月更新。
延伸閱讀