

Amazon 的商品目錄裡有將近 200 萬個賣家合作夥伴與數億件商品。只要你手動把商品標題、價格、評分、ASIN 一筆筆貼進試算表過,就懂那種折磨;量一大只會更糟。
我的本業在Thunderbit做人工智慧網頁爬蟲,所以「怎麼把資料從網站裡弄出來」占了我日常思考的一大塊。這篇我想避開多數總整理文的老套路:拎出 7 款貨真價實、裝得起來也跑得動的 Amazon Chrome 擴充功能,全擺到同一頁上實測,直白講清楚誰能打、誰只是花架子、各自對得上哪種需求。評分我拉了 8 條標準,全是在論壇、在自家使用者口中反覆聽到的痛處——AI 欄位偵測、子頁面抓取、封鎖風險、免費方案、匯出選項。不管你是 Amazon 賣家、跑行銷的,還是被複製貼上磨到沒耐性,往下讀都不吃虧。
為什麼要先抓取 Amazon 商品資料?
先釐清:需求到底來自哪些人?
範圍比想像中廣。凡是要在網路上賣貨、跑行銷、研究市場的角色,遲早都會撞上這需求。根據 Amazon 數據,店內銷售有超過 60% 出自獨立賣家,彼此的觀望與較勁又從沒停過。下面幾種是我碰過最多的場景:
| 使用情境 | 執行者 | 取得的資料 |
|---|---|---|
| 競爭對手價格監控 | 賣家、定價團隊、代理商 | 競品即時價格與供貨狀態資料 |
| 商品研究與趨勢追蹤 | Amazon 賣家、市場研究員 | 找出成長中的類別、新進者與需求變化 |
| 評論情緒分析 | 自有品牌賣家、品牌團隊 | 反覆出現的抱怨、功能缺口與商機 |
| 開發潛在客戶(賣家聯絡資料) | 批發團隊、代理商 | 賣家名稱、店面與聯絡資訊 |
| 目錄與庫存監控 | 電商營運、品牌保護 | 追蹤庫存量、商品頁變更與未授權賣家 |
| 關鍵字與商品頁優化 | 品牌主、平台營運者 | 搜尋字詞資料、商品文案與競品關鍵字 |
這些工夫換回來的東西並不抽象。拿 Amazon 官方案例來說,thefitguy 靠結構化資料把熱門搜尋詞調整到位,單季銷售就跳升逾 40%。另一頭,Parseur 的調查也算過一筆帳:光是重複性資料輸入,員工一週就耗掉 9 小時以上。這塊哪怕只自動化一半,多出來的時間都能挪去做要緊的判斷。
什麼樣的 Amazon 爬蟲 Chrome 擴充功能才算好?(我的測試標準)
別把 Chrome 擴充功能全當成同一種東西。多數比較文最愛犯的毛病,就是把 API、桌面應用程式跟瀏覽器擴充功能攪在一塊講,彷彿三者換來換去都無所謂——但它們根本不是一回事。我評分用的這套框架,連同各項標準的份量,列在下面:
- 上手容易度-非技術使用者能不能在 5 分鐘內拿到結果?(論壇也印證這是大家最在意的一點。)
- AI 欄位偵測-工具會自動辨識商品欄位,還是得手動設定 selector?(幾乎沒有競品把它當成獨立類別來談。)
- 子頁面/詳情頁抓取-能不能在同一個流程裡,把列表頁資料再補上詳情頁資訊?
- 反機器人/封鎖風險處理-它怎麼應付 Amazon 那套積極的機器人偵測?(這是使用者論壇上的第一大痛點。)
- 分頁支援-能不能自動跨多個結果頁抓取?
- 免費方案/定價-不付費,實際能拿到什麼?(使用者會直接問免費選項,但競品很少給實用答案。)
- 匯出選項-CSV、Excel、Google 試算表、Airtable、Notion?
- 排程與自動化-能不能設定定期執行?
測試環境我固定在 Amazon 美國站,搜尋結果頁跟商品詳情頁各跑一遍,查詢字串與條件對每一款都一模一樣。

AI 驅動 vs. Selector 基礎抓取:為什麼這對 Amazon 很重要?
有個關鍵分野幾乎沒人在 Amazon 爬蟲的總整理文裡點出來,偏偏它才是拉高或壓低後續維護成本的頭號變數。
大多數 Chrome 擴充功能型爬蟲的底層邏輯,是拿 CSS selector 去綁資料欄位。「價格」「標題」由你自己(或工具內建範本)指到對應的 HTML 元素,爬蟲再照位置撈值。麻煩就在這:Amazon 動不動就天天改底層 HTML 與 CSS,專門把爬蟲弄壞。那種被雜湊過、名字一天一個樣的 class,在論壇上被列為最典型的翻車情況。
三種主要做法的比較如下:
| 方式 | 運作原理 | Amazon 版面變動時 |
|---|---|---|
| 基於 selector(傳統) | 使用者手動把 CSS selector 對應到欄位 | 會失效-使用者必須重新設定 |
| 基於範本 | 預先建立好的 Amazon 頁面規則 | 會失效,直到開發者更新範本 |
| AI 驅動(例如 Thunderbit) | AI 讀取頁面內容並自動辨識欄位 | 自動適應-不需維護 |
這回上場的 7 款裡,把 AI 欄位偵測寫進預設設定流程的就 Thunderbit 一家。剩下的不是靠 selector 就是靠範本,講白了,Amazon 改版一次,維護帳單就漲一次。先把這層落差看明白,日後能免掉不少來回折騰。
1. Thunderbit-AI 驅動的 Amazon 爬蟲 Chrome 擴充功能
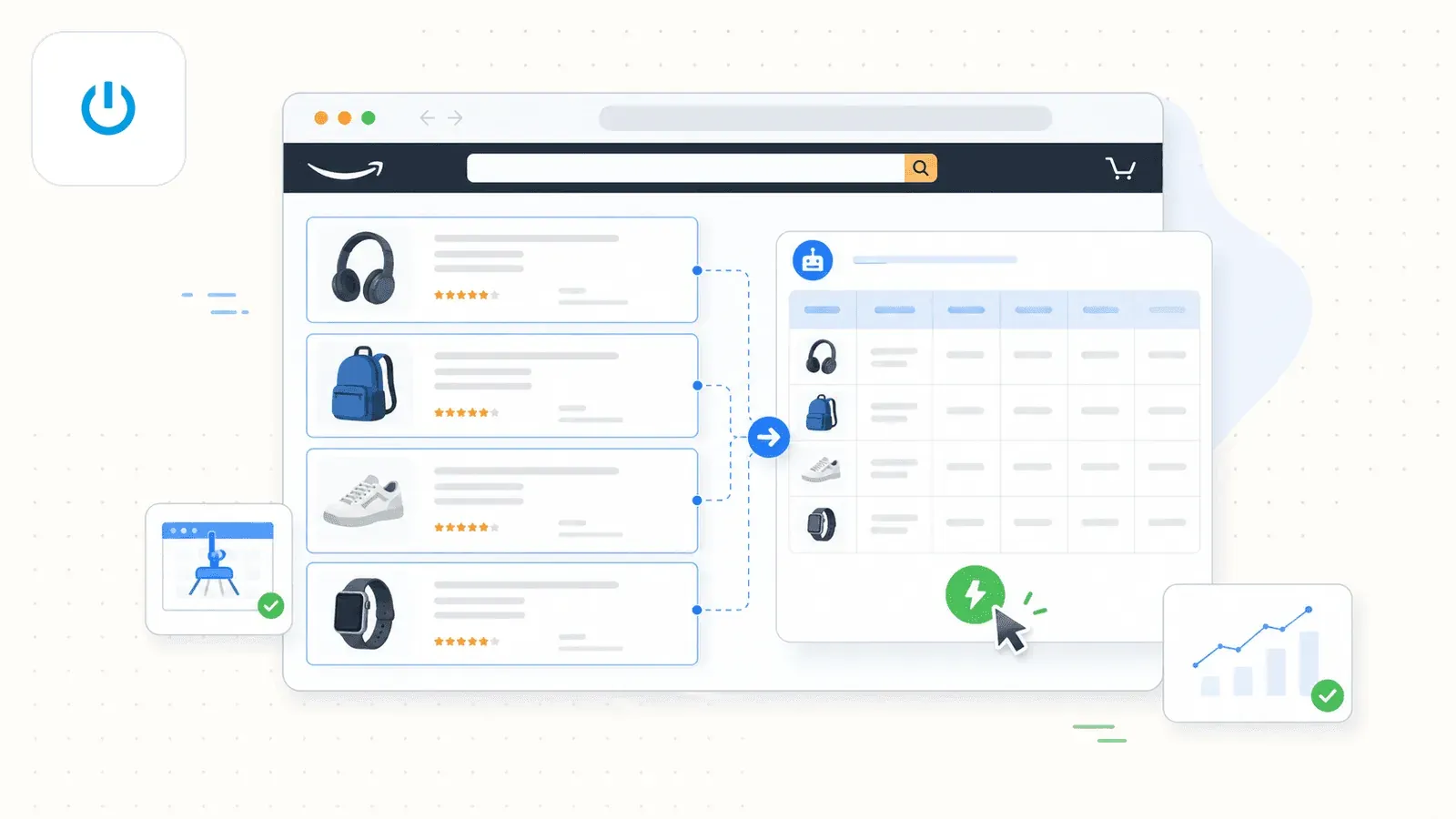
Thunderbit 是我們公司做的工具,這點先講清楚。但我也真心覺得,對不想碰 selector 或程式碼、又想快速又準確拿到 Amazon 資料的非技術使用者來說,它是最合適的一款。
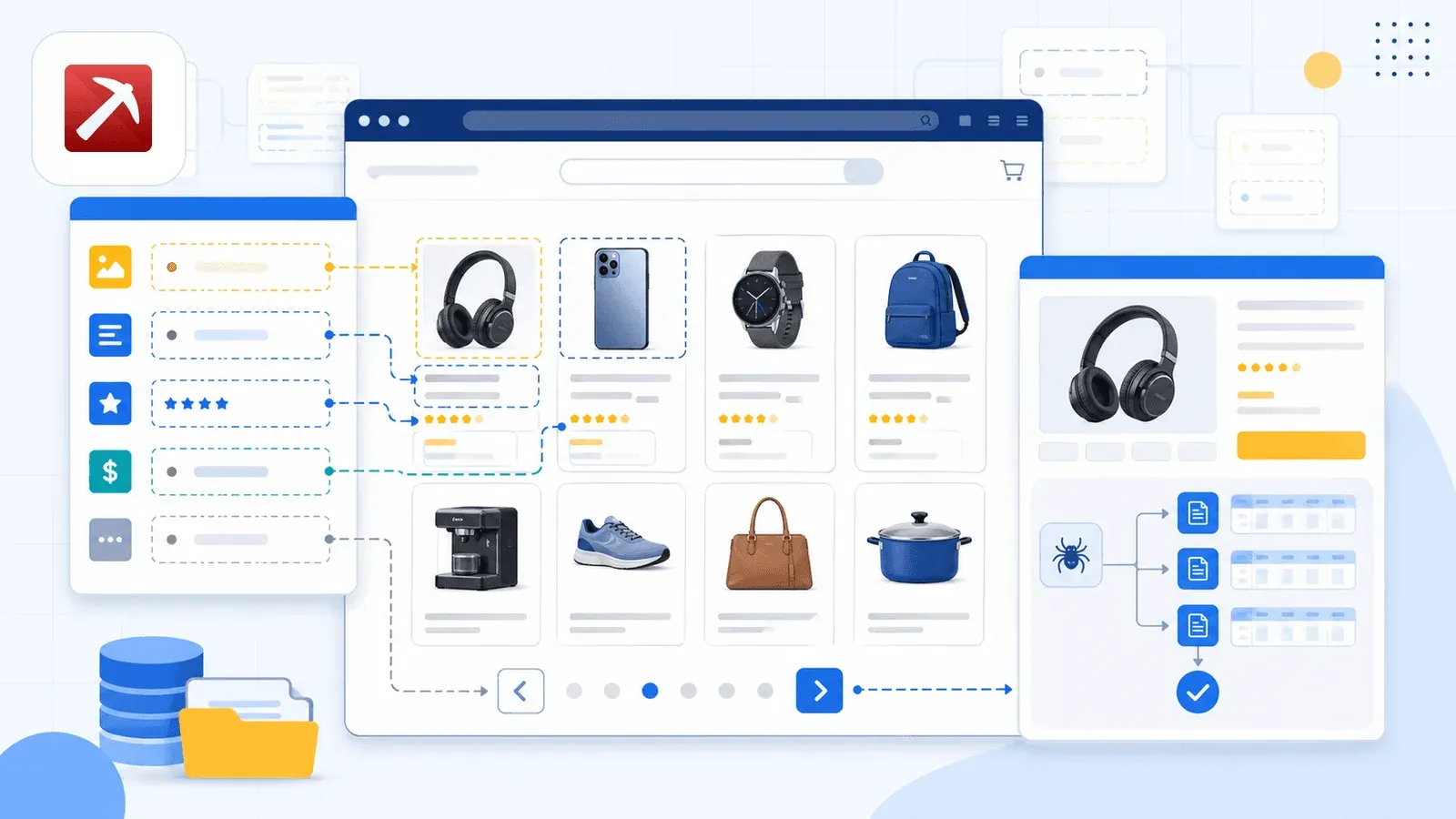
真正拉開差距的招式是 AI Suggest Fields。在 Amazon 搜尋結果頁按下那顆按鈕,Thunderbit 的 AI 便通讀整頁,把它認得的欄位一條條擺出來-標題、價格、評分、ASIN、評論數、商品 URL 全在內。你這端一個設定都不必碰;頁面上有什麼資訊、該歸成哪種資料類型,AI 自己盤點、自己建議。

一般的 Amazon 抓取流程長這樣:
- 安裝 Thunderbit Chrome 擴充功能,打開 Amazon 搜尋結果頁。
- 點 AI Suggest Fields-AI 會自動偵測並列出欄位。
- 點 Scrape-資料立刻填進表格。
- 遇到熱門的 Amazon 頁面,也可以直接用預先建立好的 Amazon Scraper Template,真的做到一鍵抓取。
若真要挑最出彩的環節,那是 子頁面抓取。列表頁一抓完,按下 Scrape Subpages,Thunderbit 就挨個點進每條商品 URL,把詳情層欄位-完整描述、條列重點、賣家資訊、圖片 URL-接回同一張表。這功能在競品擴充功能裡多半缺席。
雲端與瀏覽器的切換也值得一提。走雲端,單次最多吃下 50 個公開列表頁;走瀏覽器,靠的是你手上這個 Chrome 工作階段-登入 Seller Central、或想把動作壓低調些的時候特別合用。
排程則是你用大白話把時間間隔講出來,換算的活兒交給 AI。
匯出這頭很齊:Excel、Google 試算表、Airtable、Notion、CSV、JSON 一應俱全,而且不必升級,免費方案裡就全開放。
Thunderbit 的優缺點
優點:
- AI 自動偵測欄位,不用設定 selector,也不必擔心 Amazon 改版後要重做
- 一鍵補抓子頁面資料
- 可切換雲端/瀏覽器模式,彈性高、封鎖風險較低
- 匯出選項最完整(Sheets、Airtable、Notion、Excel、CSV、JSON)
- 可用自然語言設定排程
- 內建 Amazon 範本,開箱即用
缺點:
- 採點數制,重度使用者最後還是得走付費方案
- AI 欄位偵測會多一個短暫的處理步驟(幾秒)
- 工具較新,社群文件比老牌方案少
Thunderbit 定價
- 免費方案: 6 頁(試用加碼後可到 10 頁),含 AI 功能與所有匯出格式
- 付費方案: 年繳約每月 9 美元起,含 500 點;1 點 = 1 筆輸出資料列
- 最新資訊請見 Thunderbit 定價
用 AI 抓取 Amazon 頁面 Get Started Free
2. Instant Data Scraper-免費、簡潔、沒什麼花俏功能的選項
這款 Chrome 擴充功能的路數,是用啟發式演算法嗅出網頁上的表格式資料。它上架已久,時至今日仍穩坐 Chrome Web Store 免費爬蟲下載榜前段。
擺到 Amazon 上,就在搜尋結果頁把它開起來,它便自行框出資料表;第一次抓歪的話,補按「try another table」通常能救回來。應付單次、結構單純的抓取,成績還過得去。
只是 2026 年這時間點有件事非提不可:官方登陸頁如今白紙黑字寫著,Instant Data Scraper 已不再歸 Web Robots 擁有、開發或支援。翻成人話-沒更新、沒修 bug、別指望新功能。某則Reddit 討論串裡就有使用者回報,總覽頁它扛得住,可一旦要往詳情層鑽就卡住動不了。
Instant Data Scraper 的優缺點
優點:
- 完全免費,不需要帳號
- 輕量、快速,適合簡單表格
- 支援基本分頁(點擊「Next」按鈕)
缺點:
- 沒有 AI 欄位偵測(靠模式比對,容易在 Amazon 複雜版面上看錯)
- 不支援子頁面抓取
- 只能匯出 CSV/Excel
- 沒有排程、沒有雲端模式
- 已停止維護,Amazon 一改版就可能失效,且沒人修
3. Web Scraper-老牌、適合手動設定的擴充功能
論資歷,Web Scraper 稱得上 Chrome 擴充功能型爬蟲裡的老將,靈魂是那套視覺化 sitemap 建立器。流程大致是:開 DevTools,用點選搭出一份「sitemap」,把 selector 一個個定下來、把分頁配好,甚至順著連結一路走進商品詳情頁。
它的市集裡也備了一個 Amazon Products Listings Scraper 範本,導覽、分頁、商品頁擷取都涵蓋。官方逐步教學會領你走完 8 個步驟-裝好、生 selector、配分頁、跟商品連結、擇本機或雲端跑起來。
雲端那版還加碼排程、API 存取、代理輪換、CAPTCHA 繞過,以及 Google 試算表整合。
Web Scraper 的優缺點
優點:
- 成熟、文件完整,且有社群支援
- 免費瀏覽器擴充功能(本機使用不限量)
- 有 Amazon 市集範本
- 有雲端方案可擴充(排程、IP 輪換、整合)
- 支援跟隨連結到商品詳情頁(部分子頁面補充)
缺點:
- 需要手動設定 selector,非技術使用者學習曲線較陡
- 沒有 AI 自動偵測欄位
- 範本可能在 Amazon 改版後失效
- 進階功能需付費雲端方案
Web Scraper 定價
- 免費: Chrome 擴充功能、本機抓取不限量
- 雲端方案: Project 每月 50 美元起、Professional 每月 100 美元起、Scale 每月 200 美元起
4. Octoparse-功能豐富的平台,但 Chrome 擴充功能有個前提
Octoparse 骨子裡是套火力十足的無程式碼抓取平台,Amazon 商品詳情、關鍵字搜尋、評論等預設範本都內建現成,雲端抓取、排程、多步驟工作流程一樣不缺。
不過有個細節得先講清楚:它掛在 Chrome Web Store 上的擴充功能,現在叫 Octoparse AI Web Automation,說明裡也寫死了-它只認 Windows 上的 Octoparse AI Bot,得配著跑。也就是說,抓取的重頭戲落在平台端,擴充功能只是配角。你若要的是「裝進 Chrome 就能開抓」的乾脆體驗,Octoparse 更像桌面應用程式外掛一個瀏覽器小助手。
但持平說,它那批範本是真有東西。搜尋 URL 一貼進去,Octoparse 就能自動撈出商品資料;想更進一步,也能靠點選拼出自訂工作流程,分頁跟追蹤連結進詳情頁都含在內。
Octoparse 的優缺點
優點:
- 功能完整,內建 Amazon 範本
- 雲端節點可加速、排程,並透過工作流程做子頁面擷取
- 分頁處理得不錯
- 適合複雜、多步驟的抓取流程
缺點:
- 想發揮完整功能需要桌面應用程式,不是純 Chrome 擴充功能體驗
- 沒有 AI 自動建議欄位(雖然另有 Chat4Data 產品,但那是不同擴充功能)
- 免費方案每月匯出資料上限約 5 萬筆,且每次匯出上限 10,000 列
- 對新手來說介面可能偏複雜
Octoparse 定價
- 免費: 功能有限(本機擷取、5 萬筆匯出上限)
- Standard: 每月約 75–83 美元
- Professional: 每月約 208–249 美元
- 加購:IP 輪換每 GB 3 美元,CAPTCHA 解決每 1,000 次 2–2.50 美元
5. Axiom.ai-無程式碼 Bot 建立器
Axiom.ai 這款 Chrome 擴充功能,主打用無程式碼視覺化建構器組瀏覽器自動化 bot。它的定位偏向什麼都能自動化的通用型工具,而非鎖定抓取的專才,不過 Amazon 抓取範本、ASIN 擷取教學也一併附上。
玩法是這樣:自己搭一個 bot,或拿現成範本,讓它把 Google 試算表裡的商品 URL 一輪輪跑過去,逐頁點開、用 selector 取值,再把成果回填進試算表。排程屬於付費方案的待遇;雲端執行方面,Starter 與 Pro 起步就配 1 個雲端 bot,到 Ultimate 則能一口氣並行 20 個。
Axiom.ai 的優缺點
優點:
- 彈性的無程式碼自動化,不只限於抓取
- 原生整合 Google 試算表
- 付費方案可排程與雲端執行
- 有 Amazon 範本
- 適合超出單純資料擷取的多步驟流程
缺點:
- 若只是單次抓取,設定較重(要設計 bot、設定 Google 試算表、測試迴圈)
- 沒有 AI 欄位偵測
- 沒有一鍵子頁面補充功能(必須另外建立 bot 步驟)
- 匯出僅限 Google 試算表或 CSV
Axiom.ai 定價
- 免費: 2 小時執行時間
- Starter: 每月 15 美元
- Pro: 每月 50 美元
- Pro Max: 每月 150 美元
- Ultimate: 每月 250 美元
6. Data Miner-以 Recipe 為核心的擴充功能
Data Miner 這款 Chrome 擴充功能的整套邏輯都圍著「recipes」轉-也就是預先定義或自己客製的抓取範本。你可以到公開資料庫翻找現成的 Amazon recipe,也可以自己在頁面上圈選元素、從頭做一份。
分頁交給 Next Page Automation 處理;另有一條 Crawl Scrape 工作流程,能點進詳情 URL 再套上第二份 recipe。所以嚴格講,它並非「不能抓子頁面」-只是這條路手動、分好幾步走完,跟一鍵補齊是兩碼子事。
它卡得最緊的地方在免費方案:一個月封頂 500 頁,而且免費版下某些網域還會被額外設限。recipe 綁死某個網站,Data Miner 自家文件也早早打了預防針-只要網站改版、當初參照的那段 HTML 程式碼變了樣,這份 recipe 就會罷工。
Data Miner 的優缺點
優點:
- 既有 recipe 容易直接執行
- 社群 recipe 資料庫
- 支援分頁與詳情頁爬取(需手動設定)
- 介面簡單
缺點:
- 免費方案限制為每月 500 頁
- 沒有 AI 欄位偵測
- Amazon 改版時 recipe 容易失效
- 沒有雲端抓取,公開文件也不支援排程
- 匯出:CSV、Excel、剪貼簿;付費方案可匯出到 Google 試算表
Data Miner 定價
- 免費: 每月 500 頁
- 付費: 每月 19.99、49、99、200 美元,限制與功能逐步提升
7. Helium 10-專為 Amazon 賣家設計的情報工具套件
Helium 10 更像一整組打包好的 Amazon 賣家工具,而非拿來到處抓的通用型網頁爬蟲。它的 Chrome 擴充功能(Xray)會把資料直接疊在 Amazon 搜尋結果之上,銷量預估、營收、評論趨勢、BSR 一眼就看得到。設計初衷是服務做商品研究的 Amazon 賣家,而非替你把頁面原始資料一筆筆搬走。
2026 年的 Helium 10 是有免費方案沒錯,只是免費版能動用的 Chrome 擴充功能權限被砍了一截。這支擴充功能能把結果導成 CSV 或 Excel,剪貼簿流程也支援。

Helium 10 的優缺點
優點:
- 深度的 Amazon 專屬洞察(銷量預估、關鍵字資料、BSR 趨勢)
- 受專業賣家信任
- 有雲端支援的資料與排程,可做關鍵字/排名追蹤
- 有免費方案(但有限制)
缺點:
- 不是通用爬蟲,無法從任意頁面擷取自訂欄位
- 相較於專注抓取的工具,價格偏高
- 匯出格式有限(CSV、Excel)
- 沒有 AI 欄位偵測,也沒有抓取意義上的子頁面補充
Helium 10 定價
- 免費: 有限權限,包含 Chrome 擴充功能
- Starter: 每月 49 美元
- Platinum: 每月 229 美元
- Diamond: 每月 359 美元
Amazon 爬蟲 Chrome 擴充功能大比較
下面這張比較表,我沒往好看的方向修飾。跑完實測、又對 2026 年現況逐項核對後,先前草稿裡幾個想當然耳的假設也一併改掉了:
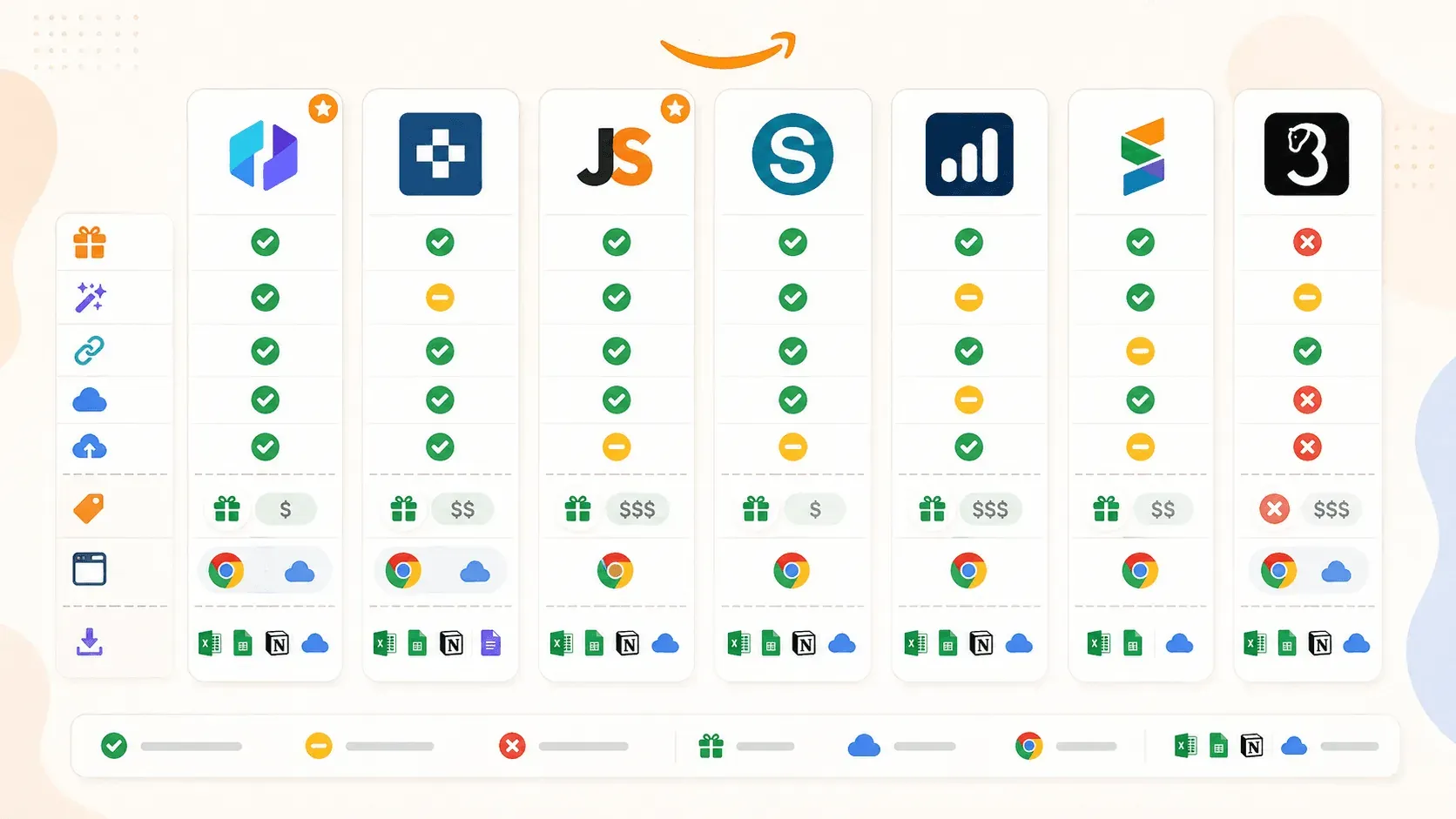
| 功能 | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| 主要類型 | AI 爬蟲擴充功能 | 免費啟發式爬蟲 | selector/範本型爬蟲 | 無程式碼抓取平台 | 瀏覽器自動化 bot 建立器 | 以 recipe 為基礎的爬蟲擴充功能 | 賣家研究疊加工具 |
| AI 自動建議欄位 | 有 | 無 | 無 | 無(另有 Chat4Data) | 無 | 無 | 無 |
| 子頁面補充 | 有(1 鍵) | 無 | 有(手動 sitemap) | 有(工作流程) | 有(手動 bot 步驟) | 有(手動 crawl) | 不適用 |
| 雲端抓取 | 有 | 無 | 有(付費) | 有(付費) | 有(付費) | 無 | 雲端支援分析 |
| 排程 | 有 | 無 | 有(付費) | 有(付費) | 有(付費) | 無 | 有(關鍵字/排名追蹤) |
| 免費方案 | 有(6–10 頁) | 有(完全免費) | 有(僅瀏覽器) | 有(有限) | 有(2 小時執行) | 有(每月 500 頁) | 有(有限) |
| Amazon 預建範本 | 有 | 無 | 有 | 有 | 有(教學) | Recipe 資料庫 | 不適用 |
| 匯出到 Sheets/Airtable/Notion | 有(全部) | 僅 CSV/Excel | CSV、Excel、JSON;Sheets 需雲端 | CSV、Excel、JSON 等更多格式 | Google 試算表、CSV | CSV、Excel;付費版可用 Sheets | CSV、Excel |
幾條結論一目了然。AI 欄位偵測這欄,全場只有 Thunderbit 打勾,免費方案還順帶給了最齊全的匯出口子。要圖省事又不花錢,Instant Data Scraper 最直接,代價是沒人在維護。Web Scraper 跟 Octoparse 能耐都夠猛,前提是你肯花時間設定-而且兩者都稱不上「裝好即抓」的純擴充功能體驗。要跨出抓取、串多步驟自動化,Axiom.ai 最對味。Data Miner 拿現成 recipe 開跑很順手,可惜免費額度勒得緊。Helium 10 則是賣家的情報中樞,本來就不歸通用爬蟲那一類。
Amazon 的雲端 vs. 瀏覽器抓取:你該知道的封鎖風險
這一節才是整件事的要害。自動化抓取這種行為,Amazon 會主動盯上並攔下來。Reddit 上就有使用者反映,量壓得再低,CAPTCHA 照樣跳出來;而 Amazon 那份使用條款也把話說死了-它給的授權,不含「任何資料探勘、機器人或類似的資料蒐集與擷取工具」這一塊。
那瀏覽器抓取和雲端抓取,實際差在哪?
- 瀏覽器抓取是在你自己的 Chrome 工作階段裡執行-真實 cookies、已登入狀態、自然的瀏覽行為。流量低時看起來比較像真人,但會占用你的瀏覽器。
- 雲端抓取則用遠端伺服器加速(Thunderbit 在雲端模式下一次可處理 50 頁),但要搭配速率限制與代理輪換,才能壓低被偵測的機率。
以下是我常用的決策矩陣:
| 情境 | 建議模式 | 原因 |
|---|---|---|
| 抓取 20 個商品頁做研究 | 瀏覽器 | 流量低、行為自然 |
| 每週監控 500 個競品 SKU | 雲端 | 速度重要,而且是公開資料 |
| 登入 Seller Central 時抓取 | 瀏覽器 | 需要您的登入工作階段 |
| 一次性大量匯出某個類別 | 雲端 | 平行抓取,速度更快 |
把雲端抓取這欄拉出來看,7 款當中站得住的是:Thunderbit、Web Scraper(付費)、Octoparse(付費)、Axiom.ai(付費),以及 Helium 10(限它的分析那一面)。剩下的 Instant Data Scraper 跟 Data Miner,就只能困在瀏覽器裡運作。
降低封鎖風險的實用做法: 請求間隔別催太快、避開尖峰時段、工具支援的話輪換 user agent。也別給自己打包票說「零風險」-把風險管理好就夠了。
從列表頁到商品詳情頁:Amazon 的子頁面抓取怎麼運作?
這流程常被低估-而且沒有一篇競品文章能完整示範端到端的做法。
在 Amazon 搜尋結果頁抓,拿到的是一層摘要:商品標題、價格、評分、ASIN,加上商品 URL。可實務上你要的往往不止於此-完整描述、條列重點、圖片 URL、賣家資訊、評論細分,這些都藏在詳情頁裡。補這一層,正是子頁面抓取的職責。
用 Thunderbit 的流程如下:
- 抓取 Amazon 搜尋結果頁 → 取得商品表格(標題、價格、評分、ASIN、商品 URL)。
- 點擊「Scrape Subpages」 → Thunderbit 逐一拜訪每個商品 URL,並把詳情欄位(描述、評論數、賣家名稱、圖片 URL 等)附加到同一張表裡。
- 匯出補強後的表格 到 Google 試算表、Airtable、Notion 或 Excel。
整個過程你不必動手設定,子頁面長什麼結構、表格怎麼補,AI 自己認、自己填。就我實跑下來,比起每個商品頁一個個點開、一欄一欄手工搬,這招最少替我擠出一小時。
其他工具也做得到,只是要多費點工夫:
- Web Scraper: 你得設定 sitemap 來跟隨商品連結,並為每個詳情欄位定義 selector。可以做,但屬於多步驟的手動流程。
- Octoparse: 你要建立含追蹤連結步驟的工作流程。很強,但不是一鍵。
- Axiom.ai: 你要設計一個 bot 迴圈,逐一造訪每個 URL 並擷取資料。彈性高,但需要 bot 建置能力。
- Data Miner: 你要用 Crawl Scrape 功能造訪已儲存的 URL,並套用第二個 recipe。這是手動、且依賴 recipe 的做法。
- Instant Data Scraper 和 Helium 10: 沒有子頁面補充流程。
如果你經常同時要列表層級與詳情層級的 Amazon 資料,那你挑的工具就該讓這流程變輕鬆,而不只是「勉強可行」。
誠實的免費方案拆解:不付費時,你實際能拿到什麼?
這是論壇使用者問得最勤、也是競品文章最不願透明回答的一題。
| 擴充功能 | 免費方案 | 免費可得內容 | 何時需要升級 |
|---|---|---|---|
| Thunderbit | 有(6 頁,試用可到 10 頁) | AI 欄位建議、所有匯出格式(Excel、Sheets、Airtable、Notion)、Email/電話擷取器 | 需要更多頁數或排程抓取 |
| Instant Data Scraper | 有(完全免費) | 基本表格偵測、CSV/Excel 匯出 | 不適用(沒有付費版,但也沒有更新) |
| Web Scraper | 有(僅瀏覽器) | 瀏覽器抓取、CSV 匯出 | 雲端抓取、排程、整合功能 |
| Octoparse | 有(有限) | 約 5 萬筆匯出/月、本機擷取 | 更多資料列、雲端節點 |
| Axiom.ai | 有(2 小時執行) | 基本自動化、Google 試算表 | 更多執行次數、排程、雲端 |
| Data Miner | 有(每月 500 頁) | Recipes、CSV/Excel、Next Page Automation | 更多頁數、Sheets、crawl 功能 |
| Helium 10 | 有(有限) | 有限的 Chrome 擴充功能存取 | 完整 Xray、關鍵字工具、排程 |
重點一句話:Thunderbit 把 AI 功能和全套匯出格式都塞進免費方案,同一批進階匯出或 AI,在多數競品那邊是鎖在付費牆後的。Instant Data Scraper 雖全免費,但 AI、子頁面、排程都沒有,加上早已停更。Helium 10 免費方案是有,可擴充功能權限被綁得死,而且它本來就不走通用爬蟲那條路。
依情境給的建議:
- 「只是想先試試看」→ Instant Data Scraper(完全免費)或 Thunderbit 免費方案
- 「需要規律、穩定的抓取」→ Thunderbit 或 Web Scraper 付費方案
- 「Amazon 賣家,需要市場情報」→ Helium 10
你該選哪一款 Amazon 爬蟲 Chrome 擴充功能?
7 款全測過之後,我的真心話結論是:
- 最適合想要快速、AI 驅動結果的非技術使用者: Thunderbit。AI 自動辨識欄位、一鍵補抓子頁面、匯出選項最完整,還能切換雲端/瀏覽器模式。想在兩分鐘內把 Amazon 頁面變成試算表,就選它。
- 最好的完全免費、適合一次性快速抓取的方案: Instant Data Scraper。零成本、免帳號,但功能有限,而且已不再維護。
- 最適合熟悉手動設定的使用者: Web Scraper。彈性的 sitemap 建立器、不錯的雲端方案、完整的文件。
- 最適合複雜、多步驟抓取流程: Octoparse(桌面版 + 擴充功能)或 Axiom.ai(瀏覽器 bot)。兩者都很強,但都不是純粹「裝好就開始」的 Chrome 擴充功能。
- 最適合簡單、以 recipe 為核心的擷取: Data Miner。很容易直接套用現成 recipe,但免費方案有限,而且沒有 AI。
- 最適合 Amazon 賣家情報,而非一般抓取: Helium 10。專為此打造、資料深度高,但價格不低,也不是通用爬蟲。
想親手摸一遍 AI 驅動的 Amazon 抓取是什麼手感,Thunderbit 的免費方案可以先拿去試。點沒幾下就做掉這麼多事,那落差多半會讓你有點意外。萬一它不是你最順手的那把,清單裡還有別款可挑-總之,別再耗在複製貼上上頭,換個更聰明的抓法正是時候。
想再多挖點 Amazon 抓取的門道,這幾篇指南可以接著看:如何抓取 Amazon 商品與評論、抓取 Amazon 價格、以及擷取並分析 Amazon 銷售資料。想看操作示範的話,Thunderbit YouTube 頻道也有教學。
用 Thunderbit 試試 AI Amazon 抓取 Get Started Free
常見問題
1. 抓取 Amazon 商品資料合法嗎?
公開可見的那些資料,抓取通常沒問題;但 Amazon 的使用條款講得明白-沒拿到書面同意,資料探勘與自動擷取一律不准。這裡不算法律意見,真要放大規模去抓之前,Amazon 那份條款請自己先讀過一遍。
2. Amazon 會偵測並封鎖 Chrome 擴充功能型爬蟲嗎?
會的。Amazon 那套反機器人機制一旦被踩到,CAPTCHA 會跳、請求頻率會被掐、IP 也可能直接被封。想壓低風險,訣竅不外乎:請求速率別催太快、量小用瀏覽器抓、量大改走有限速的雲端抓取。上面那節雲端 vs. 瀏覽器附了一張好用的決策矩陣,可以翻回去對照。
3. 用 Chrome 擴充功能可以從 Amazon 抓哪些資料?
最常抓的那幾欄大致是:商品標題、價格、評分、評論數、ASIN、賣家名稱、描述、圖片 URL,加上供貨狀態跟運送資訊。這些欄位,Thunderbit 這類 AI 工具能自己偵測、自己建議,你這頭一個手動設定都省了。
4. 使用 Amazon 爬蟲 Chrome 擴充功能需要寫程式嗎?
不必-這 7 款打從一開始就衝著非技術使用者做。差別只在設定輕重:Web Scraper、Octoparse、Axiom.ai 得多花點工,Thunderbit、Instant Data Scraper 幾乎不用配置。說到底,就是在彈性和易用之間各取所需。
5. 哪一款 Amazon 爬蟲 Chrome 擴充功能的免費方案最好?
論免費方案的含金量,Thunderbit 把 AI 欄位偵測連同全套匯出格式(Sheets、Airtable、Notion、Excel、CSV、JSON)都放了進去,而這些在多數競品那邊要付費才解鎖。Instant Data Scraper 雖全免費,卻沒有 AI、沒有子頁面、也沒有排程。Data Miner 每月給你 500 頁免費額度。Helium 10 的免費方案限制偏多,重心又擺在賣家研究,跟一般抓取不是同一件事。
延伸閱讀




