什麼是 Amazon 網頁爬蟲
Amazon 網頁爬蟲是一種很實用的工具或軟體,可以自動從 擷取資料。這些資料可能包括商品詳情、價格、評論、庫存狀態等。使用 Amazon 網頁爬蟲的主要目的,是蒐集大量資料,用於市場研究、價格比較或競品分析。您也可以收集使用者評論來做關鍵字研究,更清楚掌握產品的優缺點。
Amazon 網頁爬蟲的主要功能
- 自動化資料擷取:告別手動複製貼上的繁瑣工作。網頁爬蟲可以自動抓取您需要的網頁資料。
- 可自訂的爬取方式:您可以依需求調整爬蟲,只擷取特定資料欄位,方便進行精準分析。
- 資料匯出:輕鬆將爬取到的資料匯出成 Excel、CSV 或 JSON 等常見格式,方便進一步透過各種資料工具分析。
- 定期更新:可設定爬取間隔,讓您的 Amazon 商品資料庫隨時保持最新,確保資料不過時。
- 評論爬取:多半也需要從評論區擷取優缺點,作為競品分析的一部分。

為什麼要使用 Amazon 網頁爬蟲
Amazon 是全球電商領域的重要平台,以商品種類豐富、價格具競爭力,以及順暢的購物體驗聞名。它讓企業能接觸到全球潛在客戶,擴大市場觸及範圍。消費者也信任 Amazon,將其視為主要的線上購物目的地,為賣家提供可靠的銷售環境。此外,Amazon 的物流網路也讓企業能善用快速且高效率的配送服務,提升顧客滿意度。Amazon 也提供多種行銷工具,協助提升商品曝光與銷售,例如贊助商品廣告與品牌推廣活動。
對電商企業來說,分析 Amazon 上的銷售資料非常重要。透過 Amazon 網頁爬蟲,企業可以蒐集資料,洞察市場趨勢與消費者行為,進而優化產品策略與庫存管理。這有助於企業在 Amazon 平台上有效擴張,提升銷售與品牌知名度,實現長期成長。以下是您可以用 Amazon 網頁爬蟲進行分析的方式:
市場研究
-
SKU 選擇
挑對 **SKU(庫存單位)**是電商成功的關鍵,會影響商品組合、供應鏈效率與庫存管理。透過 Amazon 網頁爬蟲,您可以從數百萬件商品中擷取精準資料,分析銷售趨勢與顧客偏好。舉例來說,若爬取 Amazon 的商品詳細頁,您就能輕鬆取得商品價格、評論數與賣家評分等關鍵資訊,進行深入市場分析。這些資料有助於判斷某個 SKU 是否具備市場潛力,也能看出哪些商品表現最好。透過比較同一類別中的商品,企業可以優化選品、增加熱門 SKU 的庫存,並減少滯銷品,提升庫存周轉率。
-
找出顧客趨勢
透過爬取大量商品評論、評分與顧客回饋,網頁爬蟲可以幫助您快速掌握消費需求的變化。例如,分析評論資料時,您可以找出消費者最重視的產品特性,例如「價格實惠」或「耐用性」。這些資訊對產品開發、定價策略與行銷策略都非常關鍵。此外,爬取歷史購買頻率與銷售趨勢資料,也能幫助您預測季節性銷售波動,提前規劃庫存與行銷活動。

競品分析
-
價格監控
在競爭激烈的環境中,價格監控對電商企業至關重要。Amazon 網頁爬蟲可以幫助您抓取即時商品資料,追蹤競爭對手的價格變化,確保您的定價維持競爭力。這項功能特別適合用來實施動態定價策略。透過蒐集相似商品的價格資訊,企業可以建立彈性的定價模型,依市場需求、庫存量與競爭對手價格自動調整售價,進而最大化利潤。
-
評論爬取
不只會影響商品銷售,也能反映市場需求的變化。Amazon 網頁爬蟲可以協助企業蒐集大量顧客回饋。基於 AI 的網頁爬蟲還能幫忙摘要與進行情緒分析,洞察使用者對您和競爭對手商品的看法,讓您能及時調整產品設計或行銷策略。
成本比較
使用 Amazon 網頁爬蟲,企業可以蒐集相似商品的價格、運費與促銷資訊,進行完整的成本比較。分析這些資料有助於優化成本結構、避免不必要的支出,並提升利潤率。對於在 Amazon 上尋找供應商的企業來說,這也能提供不同供應商的運費與售價洞察,降低成本並確保市場定價具競爭力,最終提升毛利率。
試試用 AI 做網頁爬取
試試看!您可以邊看邊點擊、探索並執行工作流程。
為什麼要用 AI 抓取 Amazon 商品資料
隨著 AI 快速進步,AI 驅動的 Amazon 網頁爬蟲工具正帶來新一波資料擷取方式,為傳統網頁爬取流程提供許多便利。AI 不只讓資料蒐集更有效率、更精準,也大幅降低技術門檻,為電商企業帶來更多創新機會。
對非技術人員也很友善
對於沒有技術背景的使用者來說,AI 支援的 Amazon 網頁爬蟲工具非常方便。不同於傳統爬蟲需要手動寫程式與呼叫 API,使用者只要提供爬取需求並選擇想要的欄位名稱即可。AI 會自動生成合適的爬取計畫與建議,省去程式撰寫與複雜設定的麻煩。這種友善的功能讓電商團隊不用專業技術人員也能高效率取得資料,提升團隊生產力,讓非技術人員也能輕鬆使用進階資料蒐集工具。
快速又高效
可自動化資料擷取流程,大幅提升爬取速度與效率。它能快速處理複雜網站結構與動態內容,精準抓取目標資料,減少人工介入,並提高整體爬取準確度。此外,也能大幅降低營運成本並優化工作流程,讓企業以更低成本取得高品質資料,為決策提供更精準的支持。
智慧分析與建議
相較於傳統網頁爬蟲,更具智慧化工作流程自動化的優勢。AI 工具可以自動分類資料、摘要資料,並提供資料洞察。例如,企業可以用 AI 自動將不同商品分類到預先定義的類別,或分析大量評論資料,萃取關鍵字與情緒趨勢,幫助企業更了解消費者回饋並優化產品。AI 也能根據爬取的資料生成客製化報告,自動產出市場分析,幫助企業快速辨識熱門商品特性與潛在市場機會。
智慧輸出與匯出選項
使用基於 AI 的 Amazon 網頁爬蟲,可以更智慧地輸出資料。傳統程式寫法通常只能輸出 CSV 檔,而 AI 工具除了支援 CSV 格式,還能自動將爬取資料匯出到 Google Sheets、Notion 等協作平台,讓資料分析與分享更方便。舉例來說,您可以直接把資料匯入 Google Sheets 即時分析,或整合到團隊協作工具中,確保部門之間資訊流通順暢。這種智慧化的資料匯出方式能讓團隊更快做出決策,提升整體業務彈性與反應速度。
用 進行爬取:這就是
是一款新推出、功能強大且完整的,專為滿足您的資料需求而設計。使用 Thunderbit,使用者可以輕鬆從 Amazon 蒐集資料,無論是商品詳情、價格變動,還是顧客評論,都能快速轉化為有價值的商業洞察。以下是 Thunderbit 如何幫助電商企業提升競爭力。
首先,前往 ,並將 Thunderbit 加到您的 Chrome 瀏覽器中。您可以使用 Google 帳戶或其他電子郵件登入。
 接著,您可以使用 Thunderbit 內建的預設網頁爬蟲,或 來。方法如下:
接著,您可以使用 Thunderbit 內建的預設網頁爬蟲,或 來。方法如下:
方案 1:使用 Thunderbit 內建網頁爬蟲
已依照使用者需求設計並優化了多種內建網頁爬蟲工具,其中也包含專為 Amazon 設計的爬蟲模組。這些工具針對 Amazon 複雜的資料結構預先建立好範本,並已整理大量資料,因此您不必自己設計爬取邏輯,就能加快爬取流程,更快、更有效率地蒐集資料。
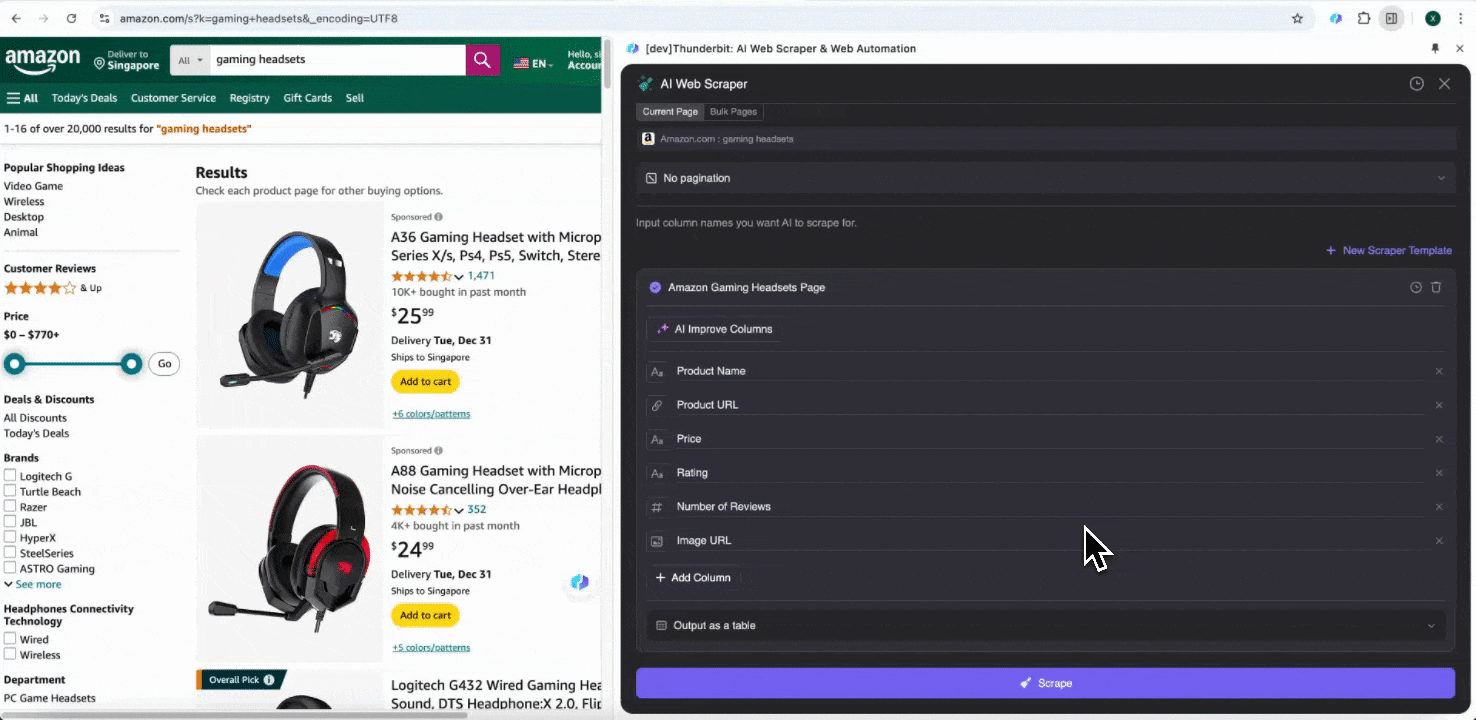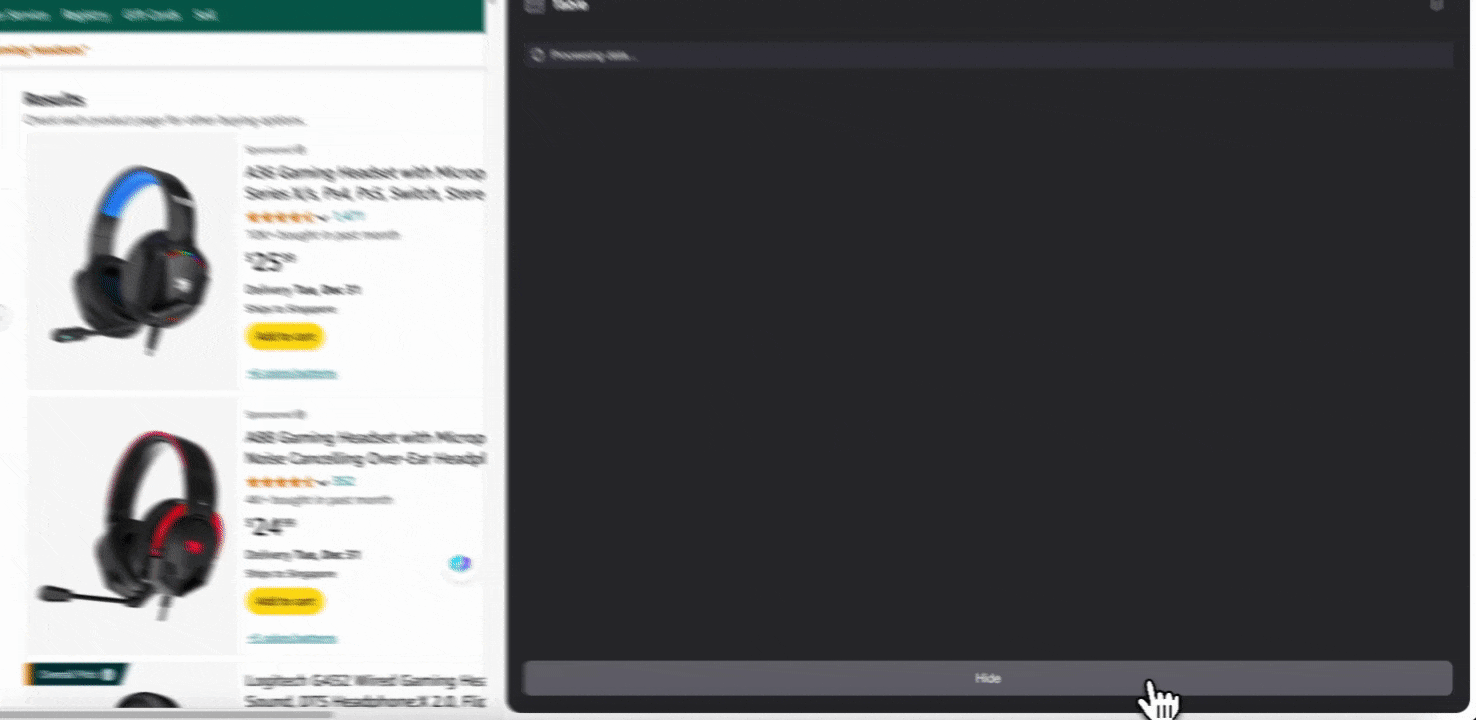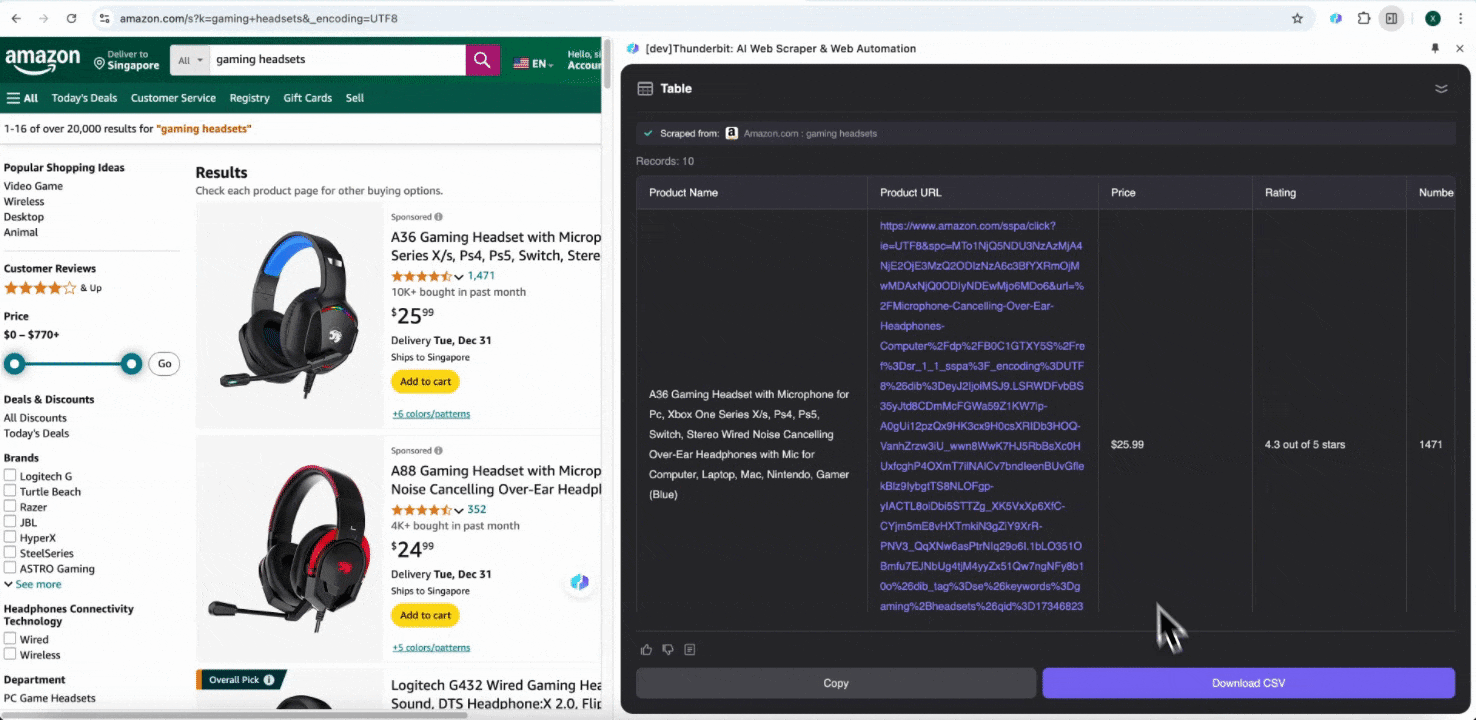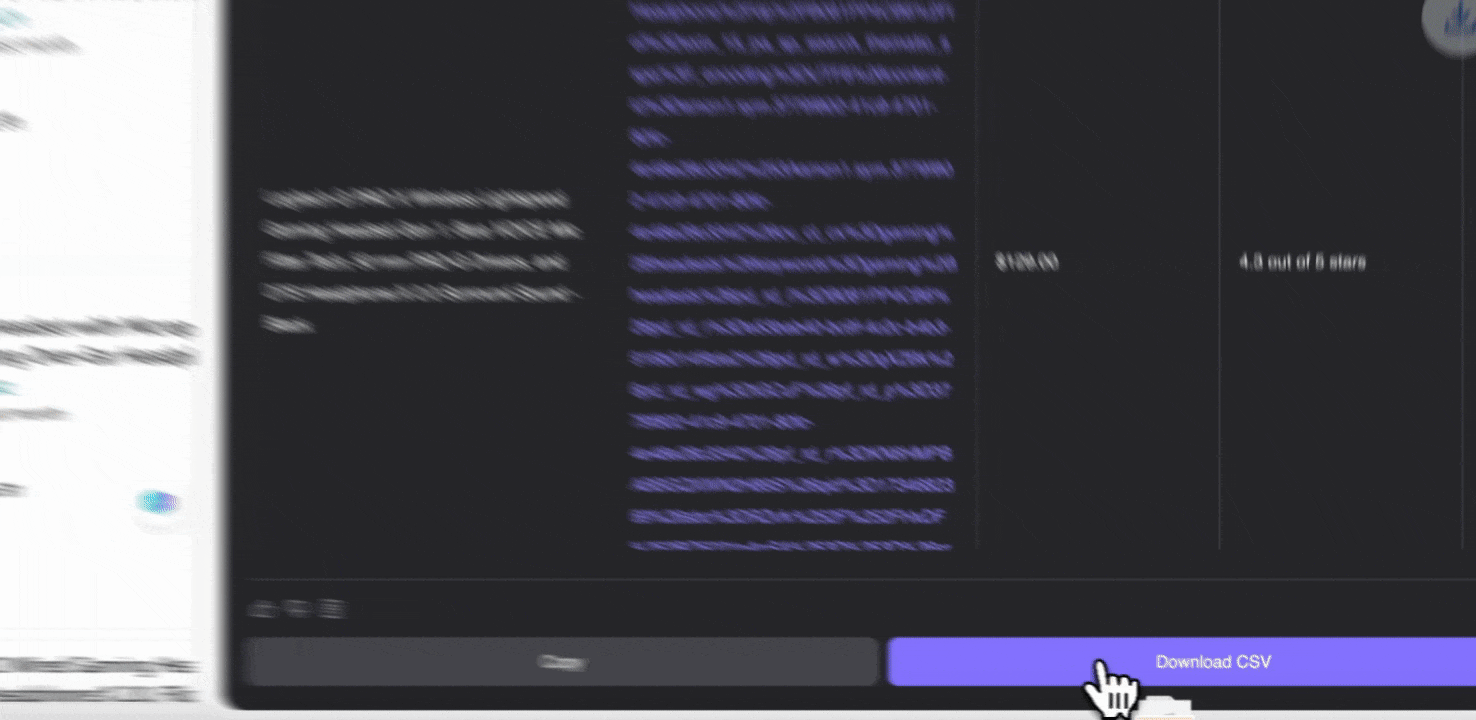
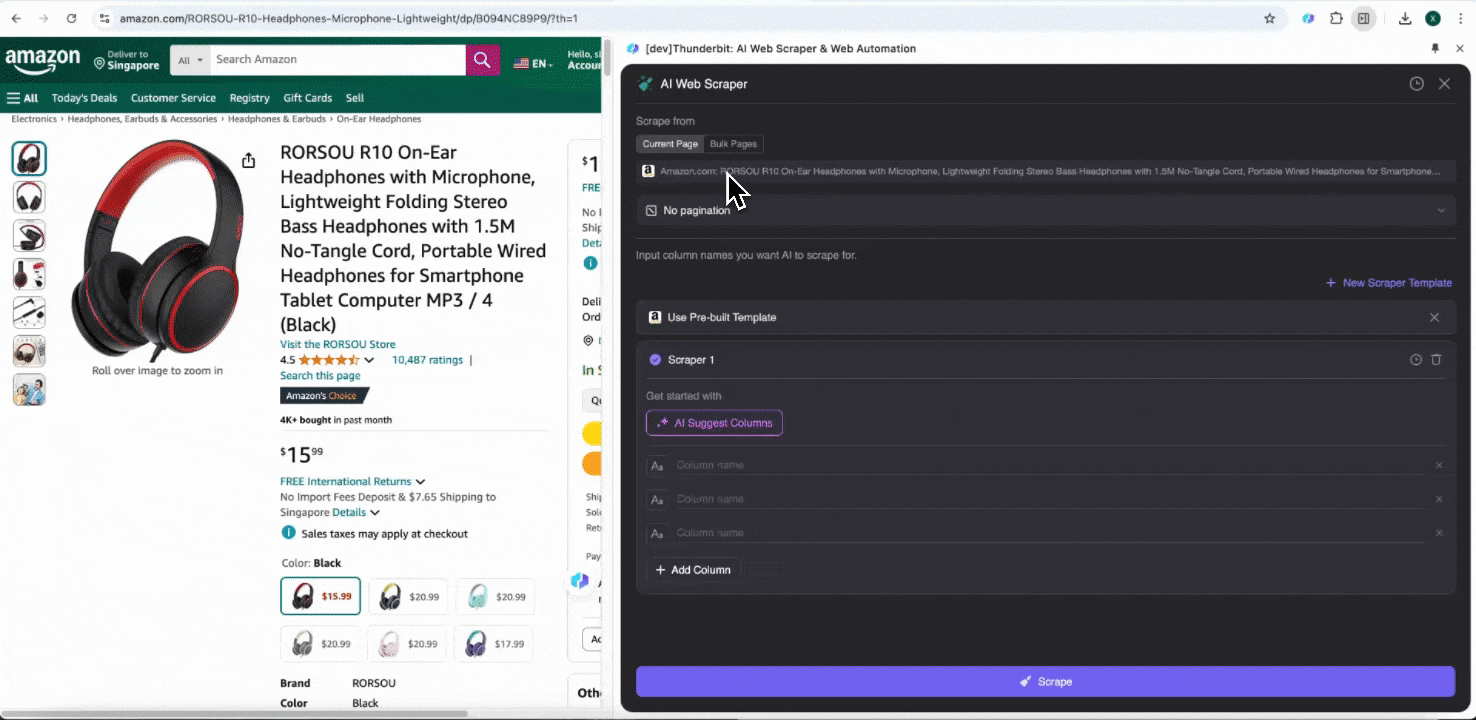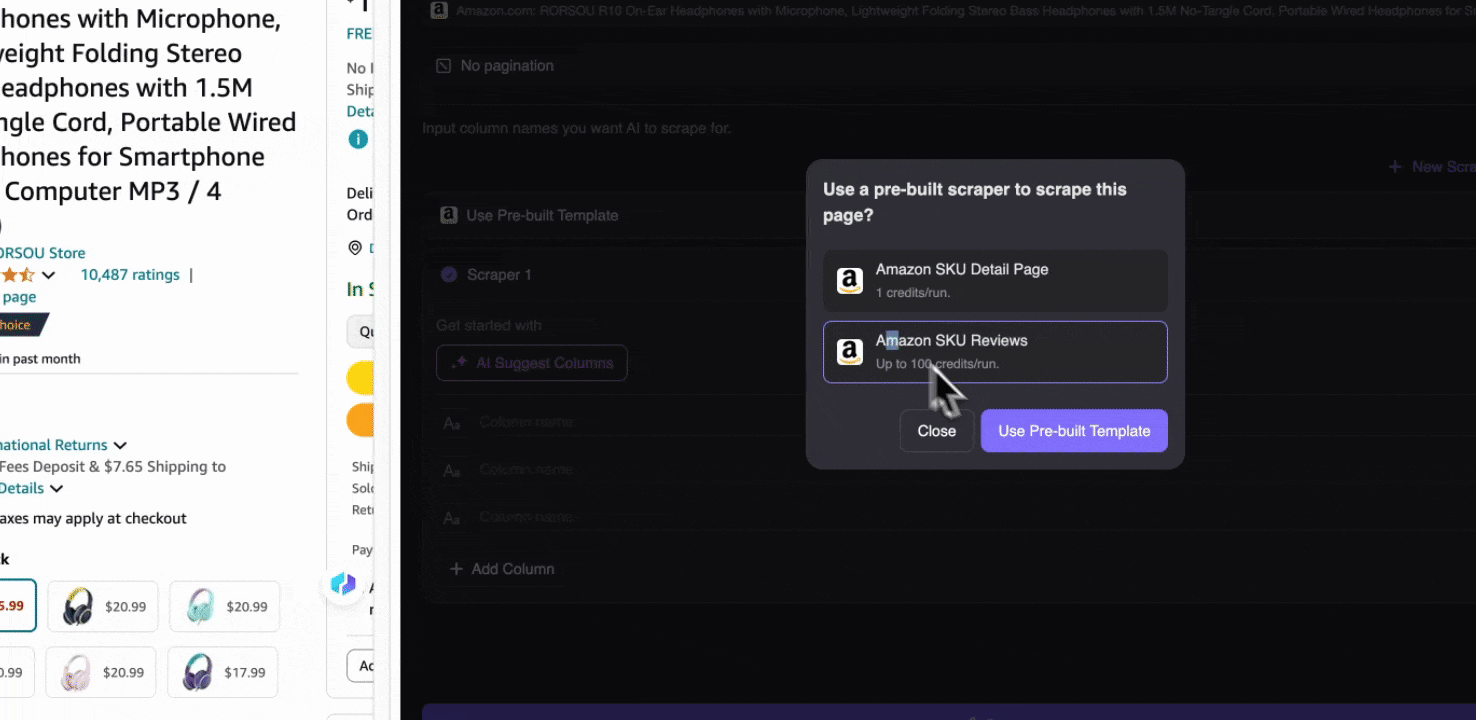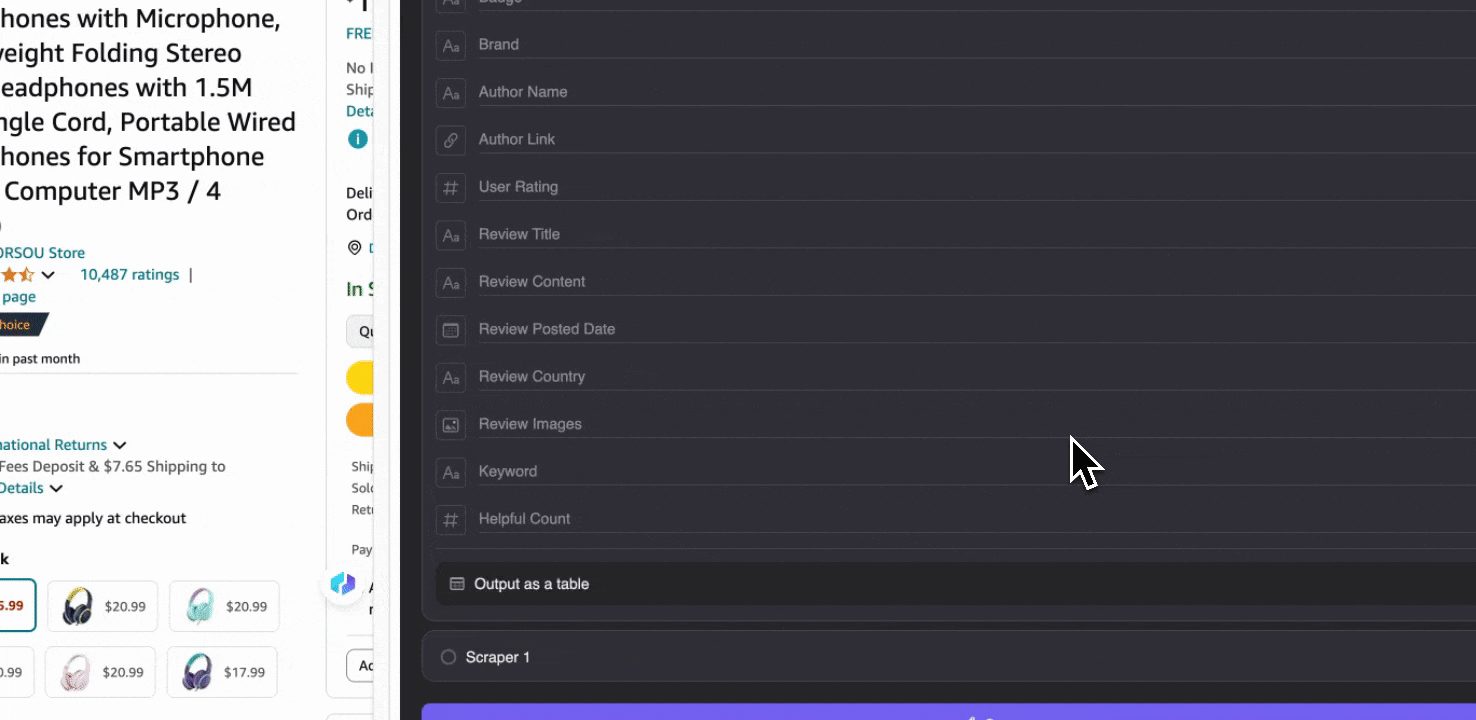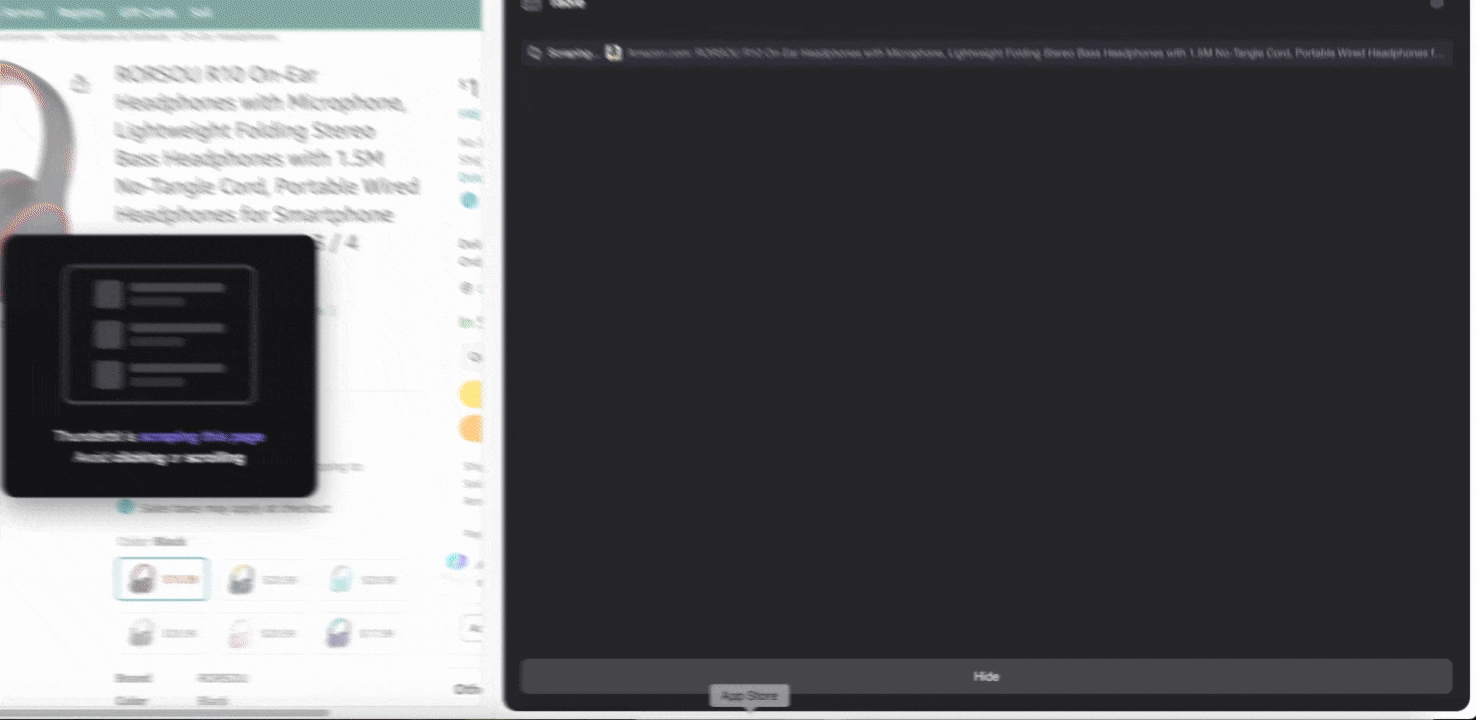
當您打開 Amazon 上的任何頁面時,開啟 Thunderbit 擴充功能中的網頁爬蟲。您會看到兩個欄位名稱豐富的內建爬蟲。只要勾選您想擷取的欄位名稱,剩下的就交給 Thunderbit。
-
Amazon 蒐集 SKU 評論
這個工具提供商品名稱、商品 URL、整體評分、詳細評分拆解、商品評分數、評論標題、作者名稱、評論內容、評論國家與關鍵字等預設欄位名稱。您可以勾選想擷取的欄位名稱,按下爬取,就能快速取得做商品評論分析所需的 SKU 評論資料。
-
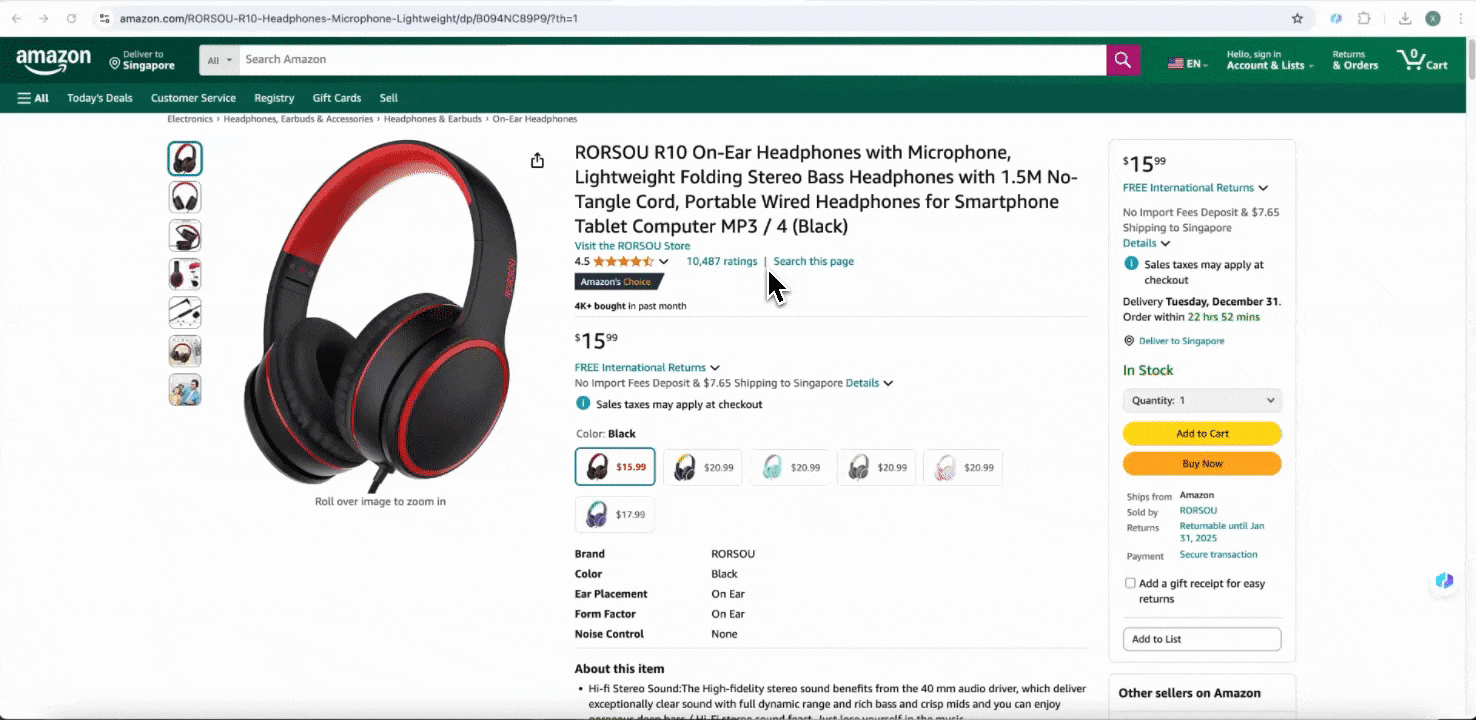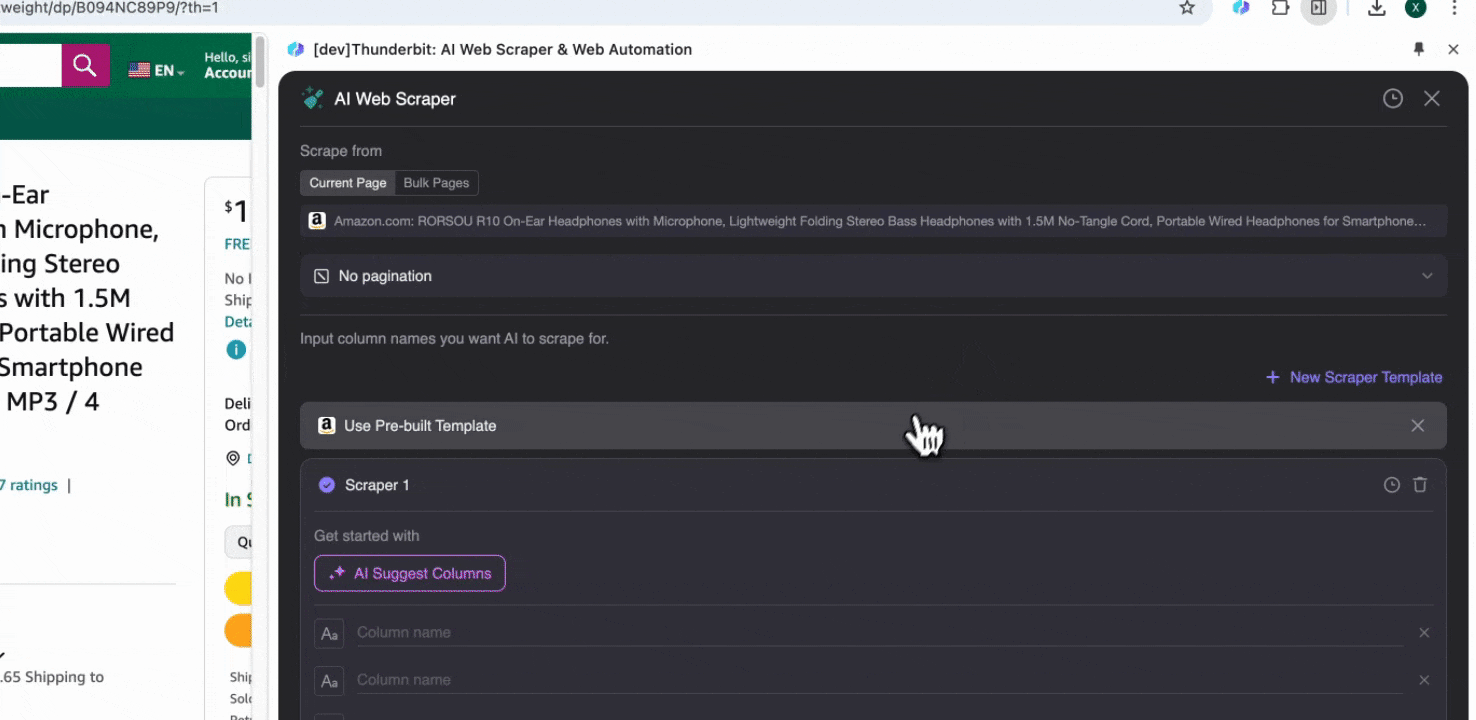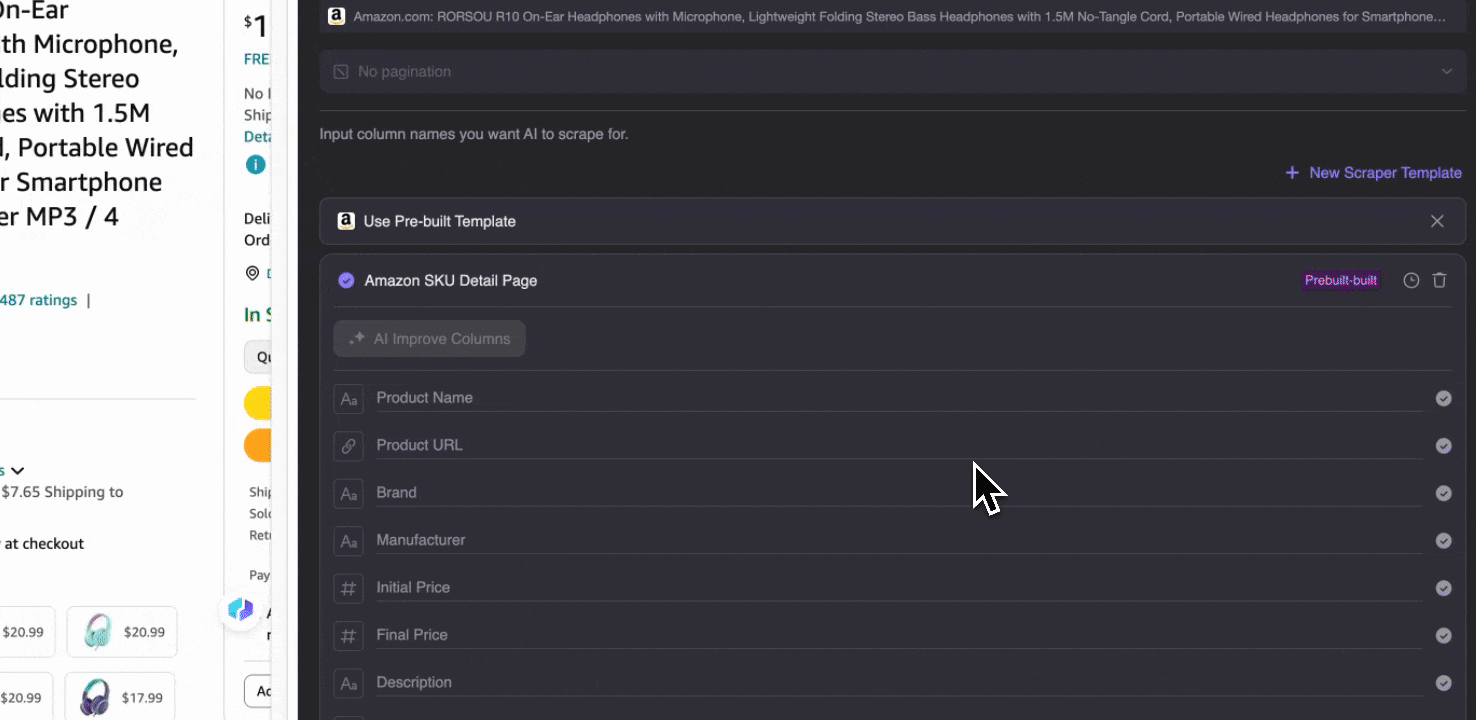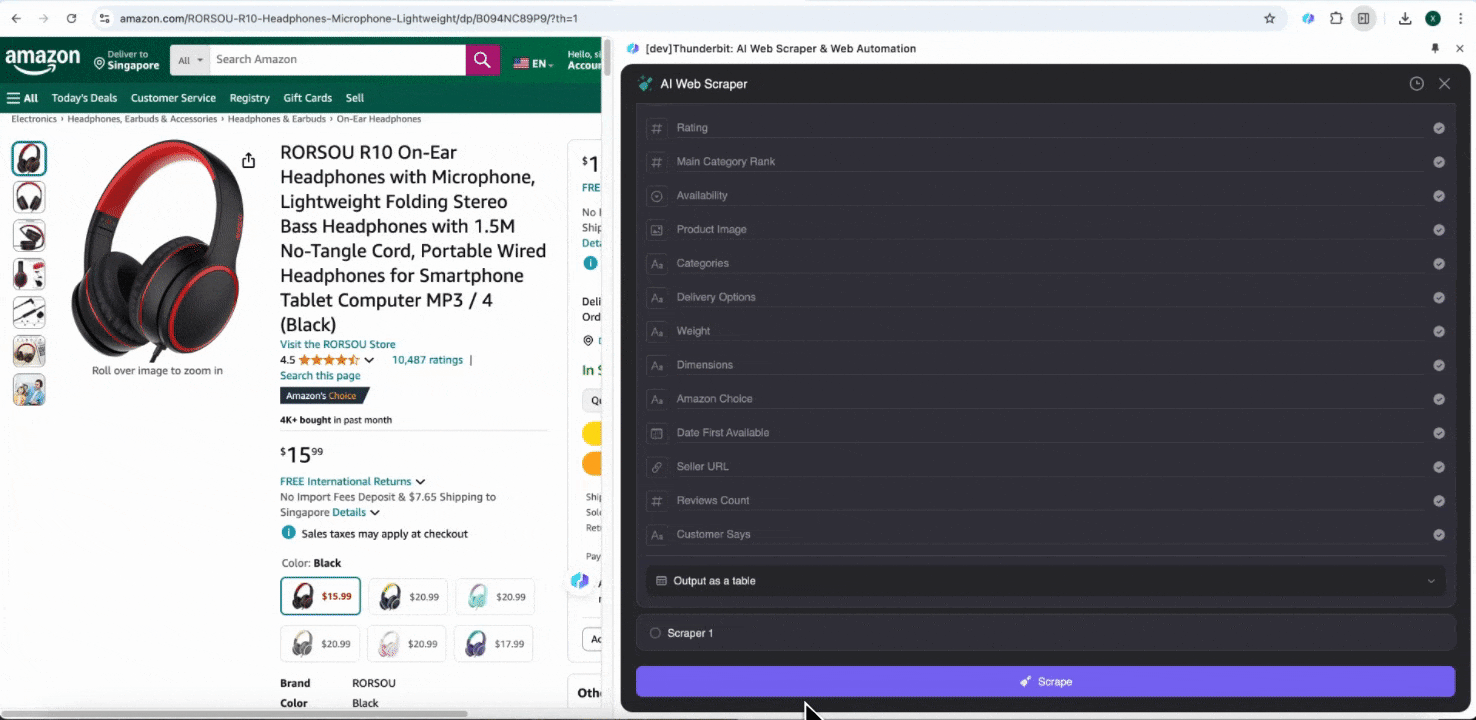
Amazon 蒐集 SKU 詳細資料
這個工具提供商品名稱、商品 URL、品牌、製造商、原價、售價、描述、評分、分類、配送選項與賣家 URL 等預設欄位名稱。勾選您想擷取的欄位名稱後,按下爬取,就能快速取得您需要的 SKU 詳細資料。無論您是要比較供應商、製造商與配送選項,進行市場研究,評估 SKU 的價格競爭力,或是掌握最新銷售趨勢,這些 SKU 詳細資料都能幫助您分析。
方案 2:使用 Thunderbit 的 AI 網頁爬蟲
步驟 1:開啟 並點擊側邊欄中的「」
在 Chrome 瀏覽器中開啟 ,搜尋或瀏覽到您想擷取資料的頁面,然後點擊 Chrome 右上角的 Thunderbit 圖示打開擴充功能,再點擊「」。
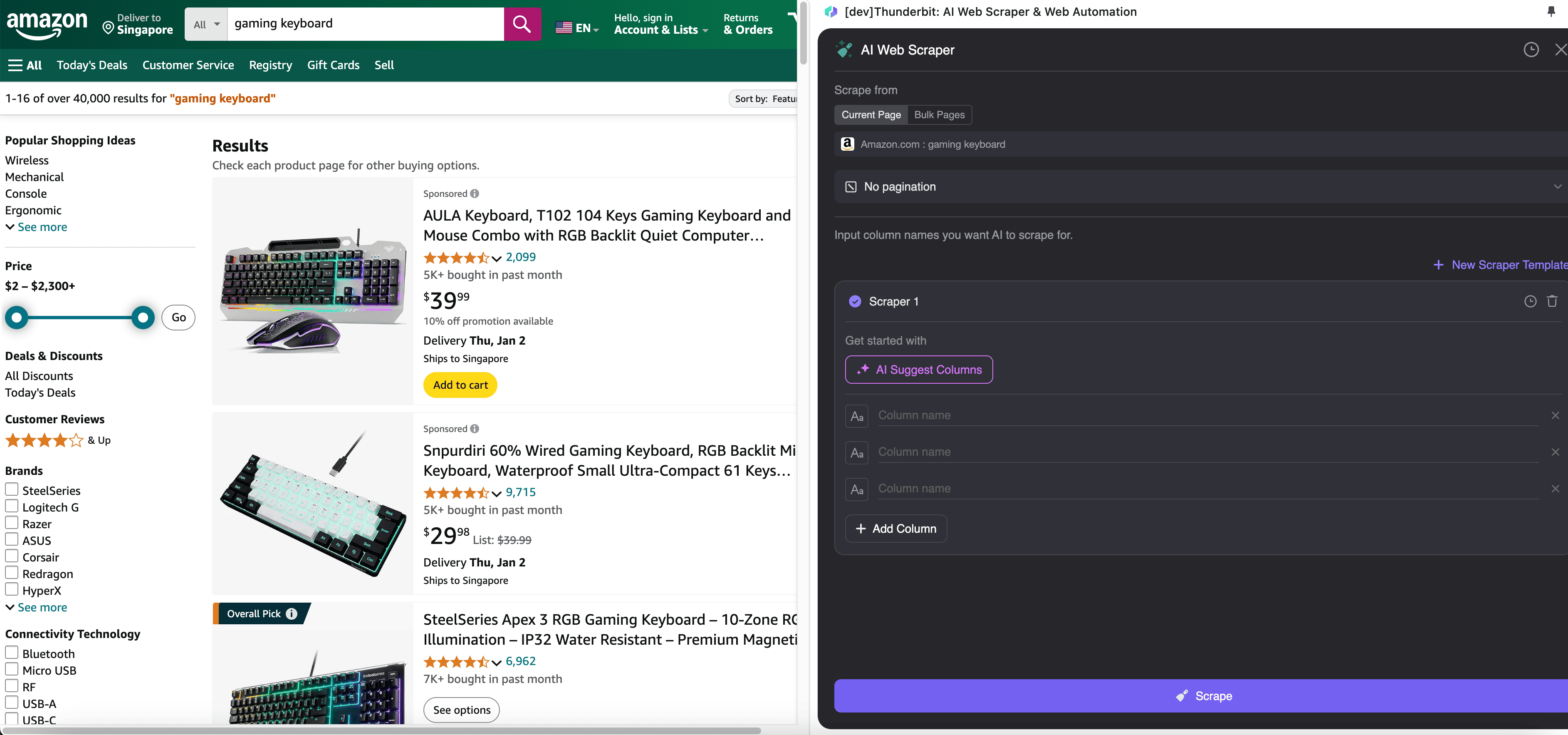
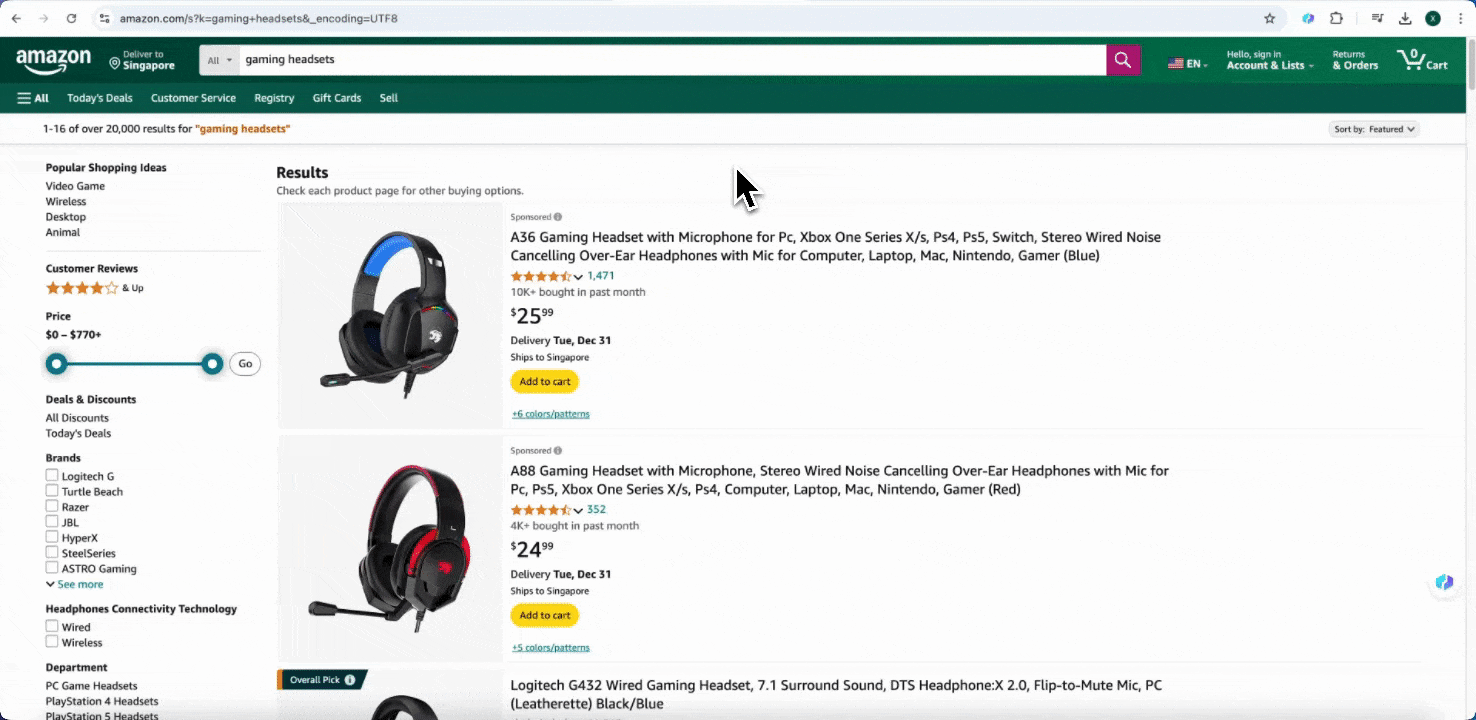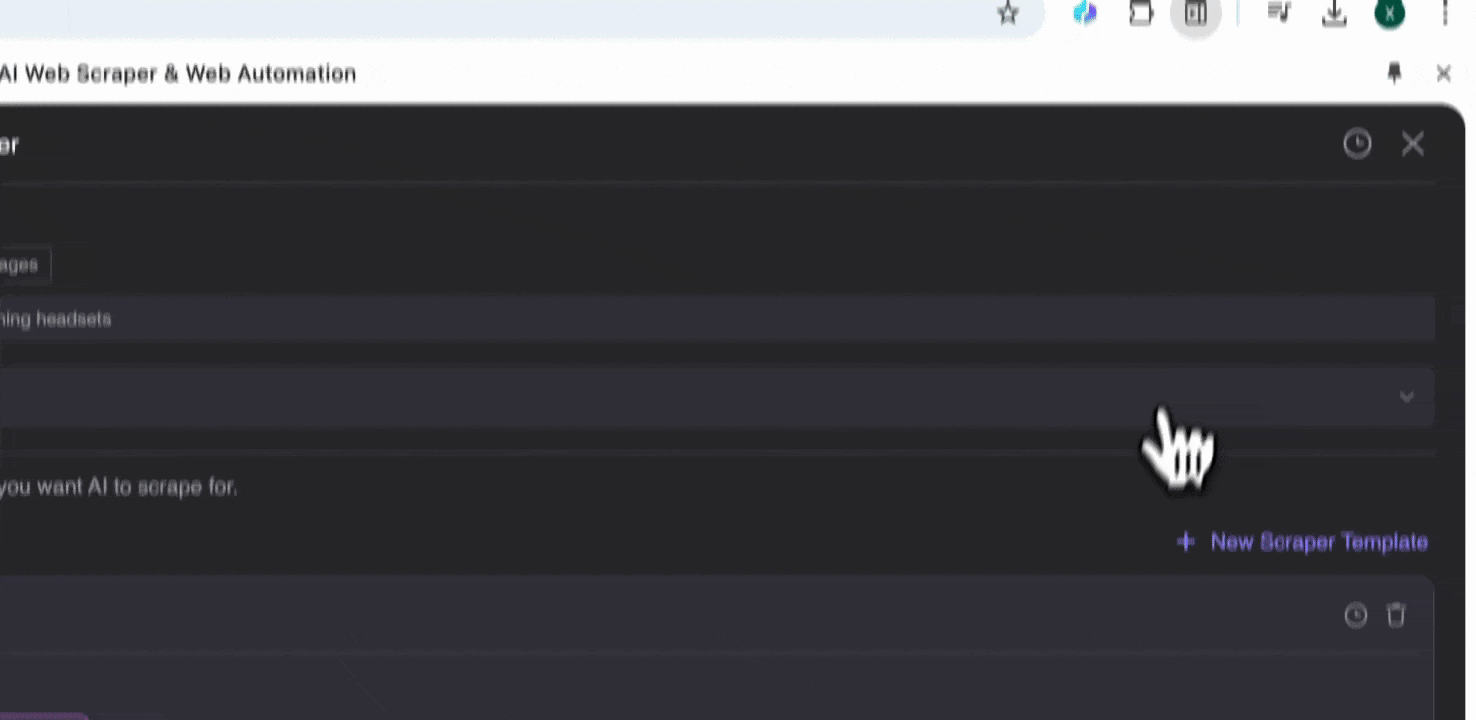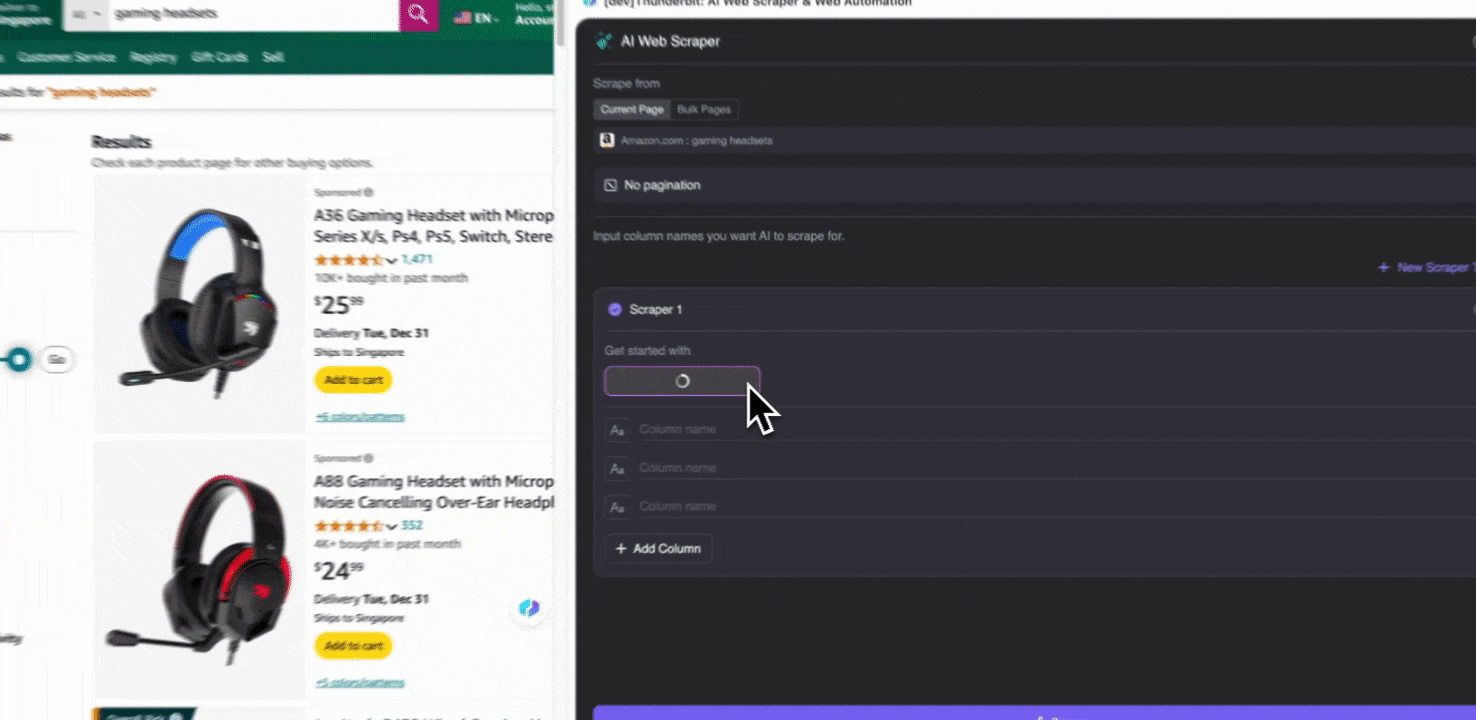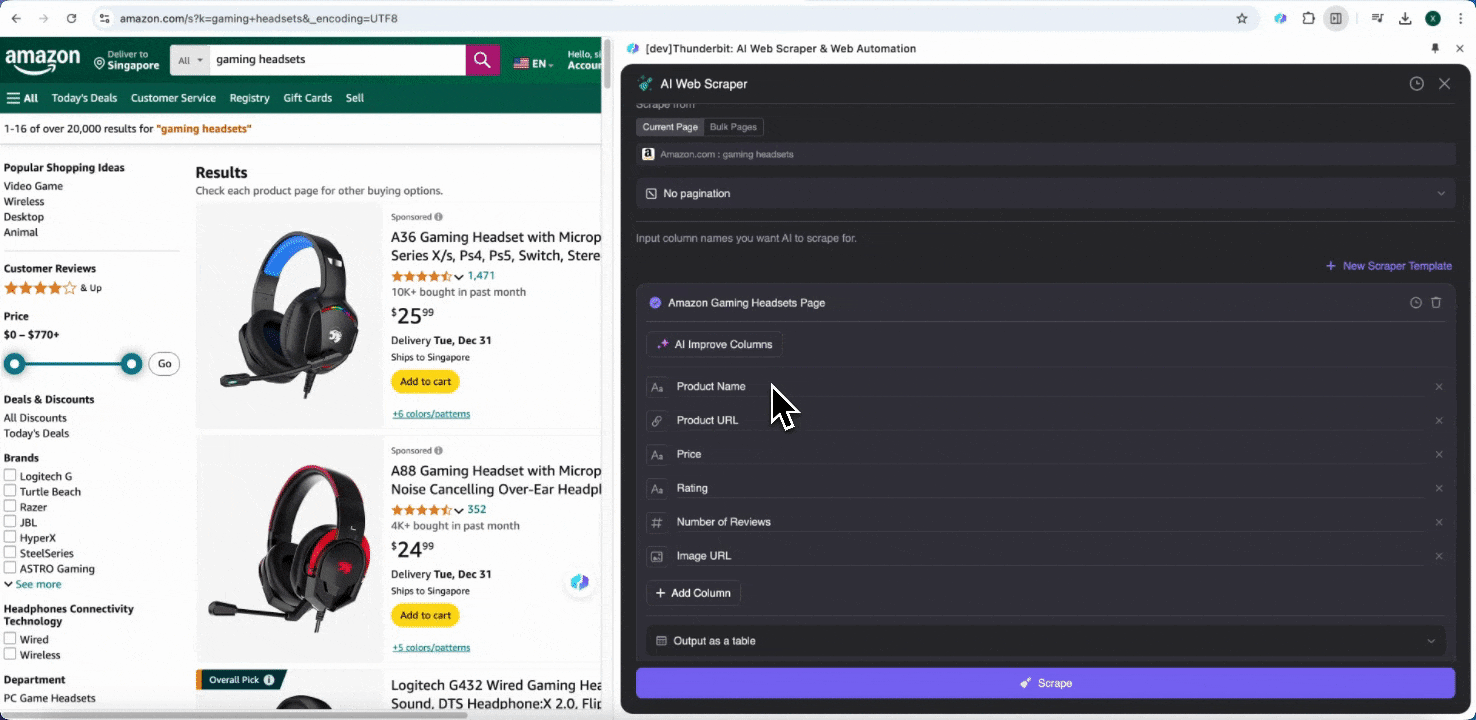
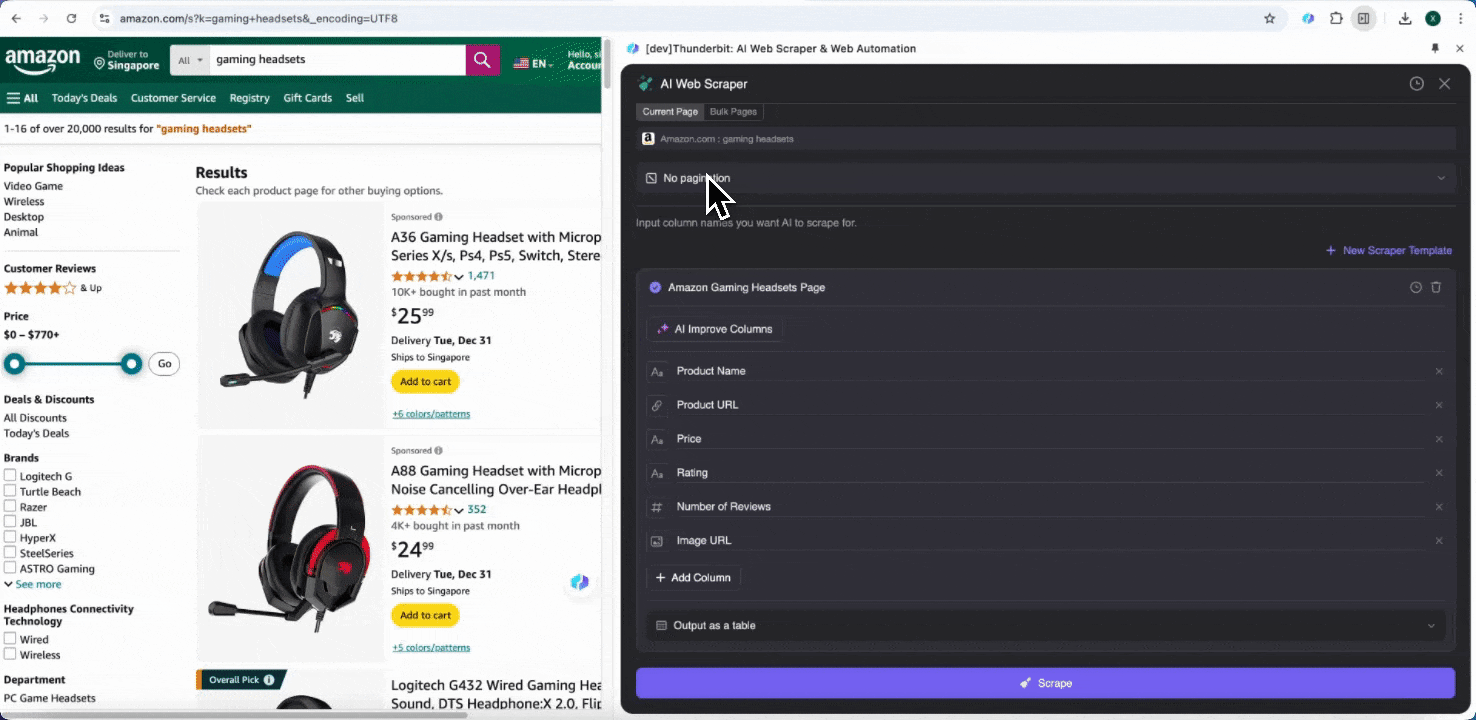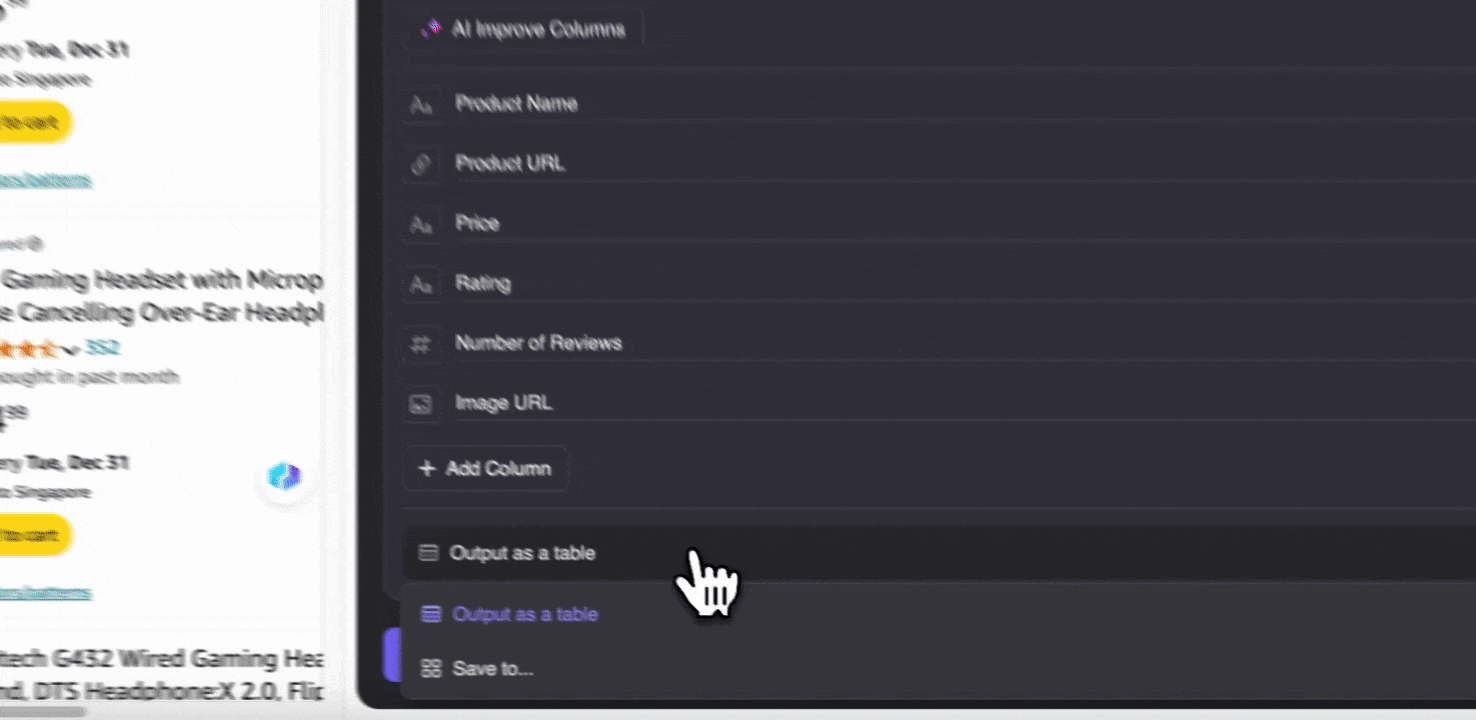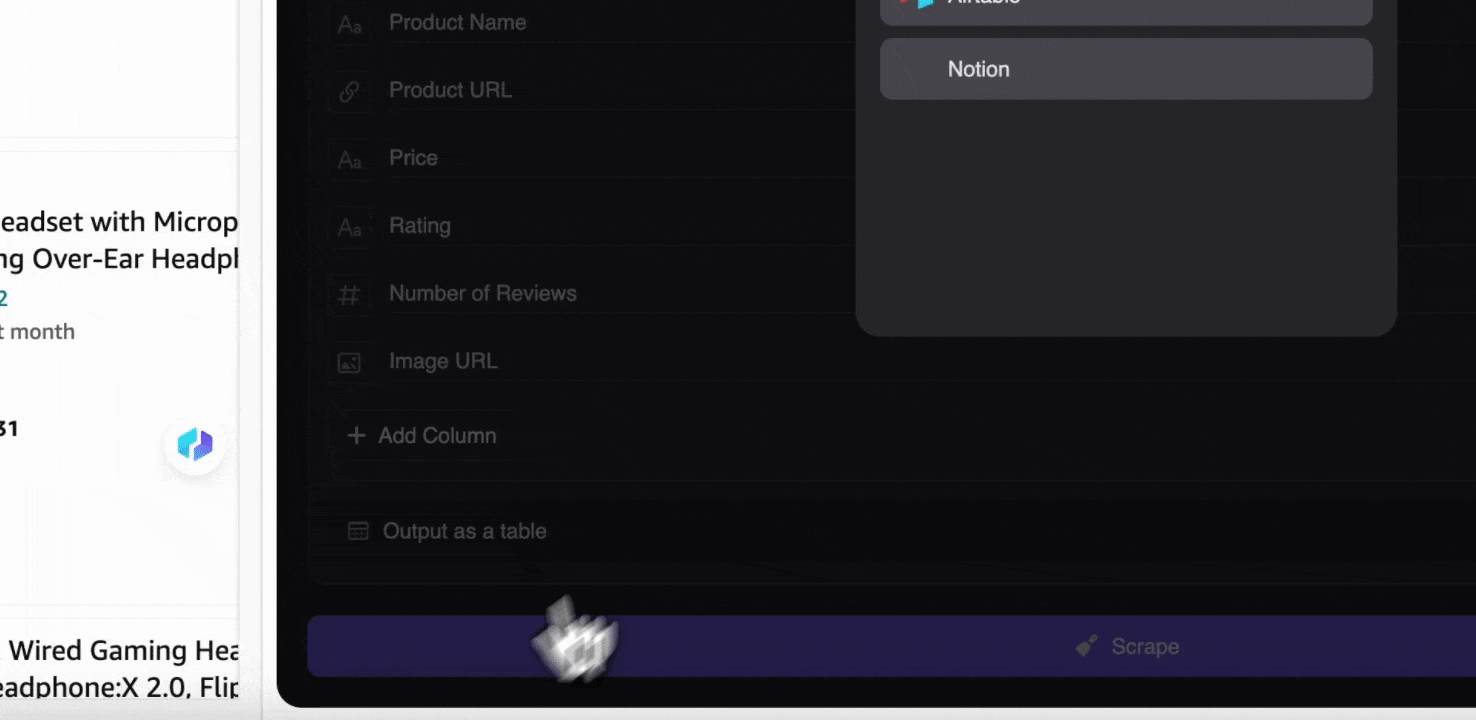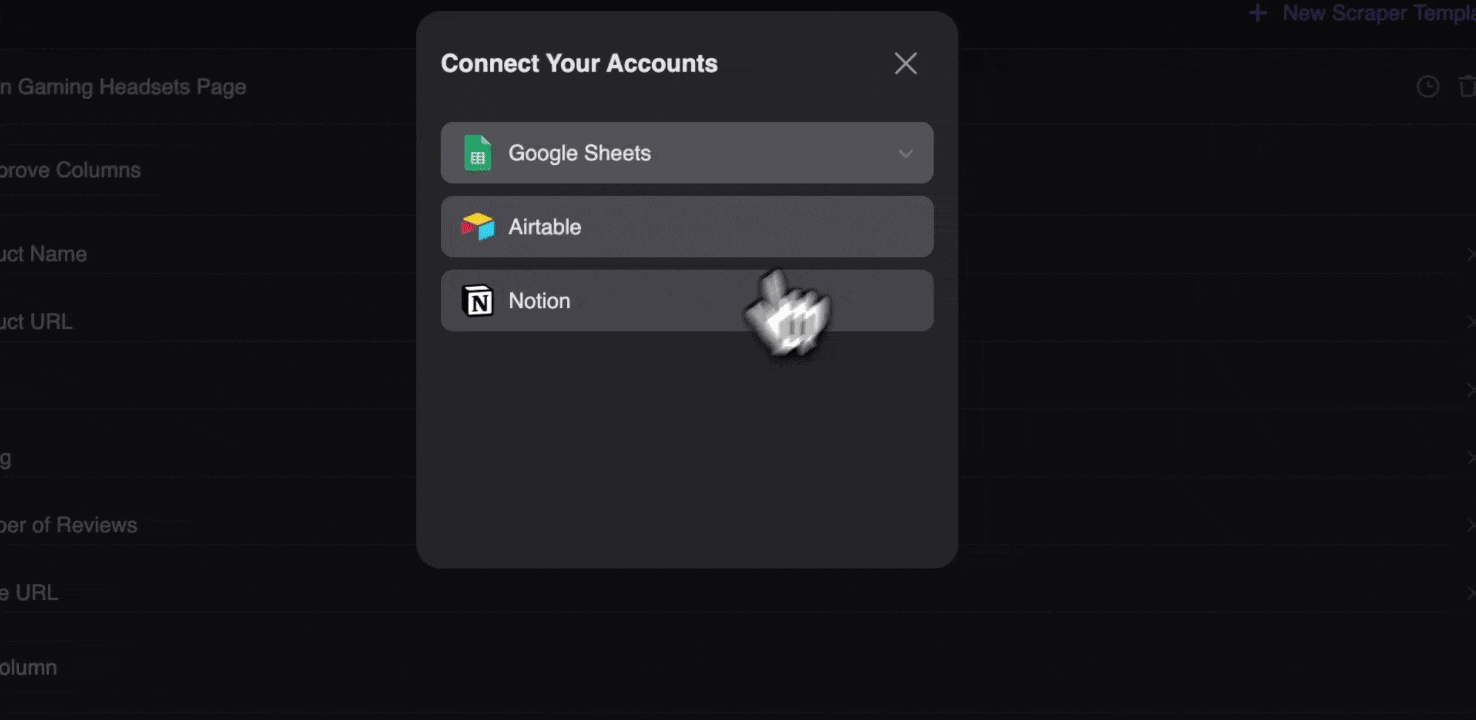
步驟 2:自訂您想擷取的資料欄位
如果您不確定要擷取哪些資料欄位,可以點擊 AI 建議欄位,讓 Thunderbit 的 AI 自動產生可靠的欄位名稱。您也可以用自然語言描述想要的資料標籤,直接填入欄位名稱欄位。再透過圖示切換您要的資料類型,不論是圖片、URL、文字、數字或其他資料類型,都能抓取對應資料。
填好初始欄位名稱後,您還可以選擇 AI 優化欄位,讓 AI 進一步調整您的欄位設定。您也可以新增欄位詳細指示來客製化需求。例如,您可以要求商品類型欄位將商品分類為男裝、女裝、童裝與其他類別。Thunderbit 會把該欄位中的每筆資料對應分類到您定義的四個類別中。您也可以要求 Thunderbit 依照目前匯率,把價格欄位中的所有金額轉換成您想要的幣別,讓您輕鬆取得分析所需數值,不必擔心幣別不一致。
最後,您還可以自訂想要的資料量。對於 Amazon 商品頁面,您可以選擇分頁點擊,並設定要爬取的頁數。Thunderbit 會自動翻頁並擷取每一頁的所有資料。
步驟 3:下載爬取到的資料或匯出成表格
透過 Thunderbit 網頁爬蟲擴充功能,您可以。您可以選擇輸出成表格,再將 CSV 檔下載到本機,或選擇、Notion 或 Airtable。登入您的帳戶後,就能直接匯出到這些線上檔案管理與協作平台。
使用傳統網頁爬蟲進行爬取
除了最新的 AI 工具之外,您也可以使用傳統網頁爬蟲工具,搭配輕量程式碼與 API 來抓取 Amazon 商品資料。
:透過 API 以 JSON 格式取得 Amazon 商品資料
ScraperAPI 提供高效率的 Amazon 資料蒐集 API,可協助您從 Amazon 抓取商品詳情、評論、搜尋結果與價格資訊,並以結構化 JSON 格式回傳。以下是使用這個 API 進行爬取的方法。
步驟 1:設定 Python 環境
首先,請確認您已安裝 Python 3.8 或更新版本。接著,安裝常見的分析套件,例如 Pandas,以及網頁爬蟲套件,例如 requests 和 BeautifulSoup。這些套件能幫助您輕鬆從網頁擷取資料。
步驟 2:建立 ScraperAPI 帳號
前往 建立免費帳號並取得 API 金鑰。您可以用這組金鑰在程式中存取 ScraperAPI。
步驟 3:準備程式碼
在本機建立專用資料夾,並撰寫 Python 腳本來實作資料爬取。以下是一個基本流程:
- 取得 Amazon 搜尋 URL:在 Amazon 搜尋您想要的商品,並複製搜尋結果頁面的 URL。
- 建立請求:ScraperAPI 會自動迴圈抓取前五頁搜尋結果。每一頁的 URL 都是透過在基礎 URL 後加上 &page= 與對應頁碼來組成。
- 送出請求並解析資料:使用 get() 方法向 ScraperAPI 發送請求。如果請求成功(回傳狀態碼 200),就解析頁面內容,擷取所需的 ASIN(Amazon Standard Identification Number)。
- 取得詳細商品資料:透過呼叫結構化資料端點,您可以取得每個 ASIN 的詳細商品資訊,以便進一步分析。
步驟 4:參考更多教學
若想了解更完整的使用說明,請參考 了解更多細節。
:避免被封鎖並大規模爬取
在爬取 Amazon 資料時,IP 封鎖、CAPTCHA 與動態內容載入等反爬機制,常常會為爬蟲開發者帶來挑戰。ScrapFly 提供強大的 API,協助您繞過這些反爬限制,確保資料擷取順暢。
ScrapFly 的核心功能包括:
- :自動切換 IP 位址,避免 IP 被封鎖。
- :處理動態內容載入,並爬取由 JavaScript 渲染的網頁。
- :控制瀏覽器捲動、輸入與點擊物件。
- :可將爬取結果輸出為 HTML、JSON、文字或 Markdown。
只要幾行程式碼,您就能用 ScrapFly 抓取 Amazon 資料。以下是一個簡單範例:
1import scrapfly_sdk
2# 建立客戶端
3client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
4# 發送請求
5response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
6# 取得回傳資料
7print(response.json())使用 ScrapFly 後,您的爬蟲就能處理 Amazon 各種反爬機制,提高資料爬取成功率。無論是簡單的商品資訊爬取,還是複雜的評論分析,ScrapFly 都是相當實用的工具。若想了解更完整的使用說明,請參考 。
使用 Python 爬取:傳統程式撰寫方式
如果您熟悉寫程式,也可以試著用 Python 撰寫程式來抓取 Amazon 商品資料。以下提供一個簡單範例供您參考。
步驟 1:設定前置條件
首先,為您的專案建立專用資料夾。
1mkdir amazonscraper接著,在這個資料夾中安裝必要套件。
1pip install beautifulsoup4
2pip install requests現在,建立一個您想命名的 Python 檔案。這會是我們放置程式碼的主檔案。我將它命名為 amazon.py。
步驟 2:對目標頁面發送 GET 請求
接下來,我們使用 requests 套件對目標頁面發送 GET 請求。
1import requests
2from bs4 import BeautifulSoup
3target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
4headers = {
5 "accept-language": "en-US,en;q=0.9",
6 "accept-encoding": "gzip, deflate, br",
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
9}
10response = requests.get(target_url, headers=headers)步驟 3:爬取 Amazon 商品資料
現在我們需要決定要從 擷取哪些內容。
1# 檢查請求是否成功
2if response.status_code == 200:
3 # 解析頁面內容
4 soup = BeautifulSoup(response.content, 'html.parser')
5 # 找出所有商品清單
6 products = soup.find_all('div', {'data-component-type': 's-search-result'})
7 # 逐一處理每個商品並擷取細節
8 for product in products:
9 # 擷取商品標題
10 title = product.h2.text.strip()
11 # 擷取商品價格
12 price = product.find('span', 'a-price')
13 if price:
14 price = price.find('span', 'a-offscreen').text.strip()
15 else:
16 price = "無法取得價格"
17 # 擷取商品評分
18 rating = product.find('span', 'a-icon-alt')
19 if rating:
20 rating = rating.text.strip()
21 else:
22 rating = "無法取得評分"
23 # 列印商品細節
24 print(f"標題:\{title\}")
25 print(f"價格:\{price\}")
26 print(f"評分:\{rating\}")
27 print("-" * 40)
28else:
29 print(f"無法取得頁面。狀態碼:\{response.status_code\}")常見問題
1. 抓取 合法嗎?
是的,抓取 Amazon 的公開資料是合法的!就像許多其他網站一樣,Amazon 也會讓任何人瀏覽其商品列表與其他公開資訊。您可以抓取並蒐集這些公開可取得的資料,而不會違反 Amazon 的服務條款。
2. 我可以免費試用 Thunderbit 嗎?
可以,Thunderbit 提供免費的頁面擷取與資料擷取功能。雖然部分進階功能可能需要付費,但基本的資料擷取能力通常是。
3. 我可以從 Amazon 抓取哪些資料?
您可以從 Amazon 抓取多種資料,包括商品標題、價格、描述、評論、評分與賣家資訊。這些資料對市場研究、價格監控與競品分析都很有價值。
4. 我應該多久抓取一次 Amazon 資料?
頻率取決於您要追蹤的資料類型。如果您是在監控價格或競爭對手活動,可能適合每天或每週抓取一次。若是商品詳情這類較靜態的資訊,每月抓取一次可能就足夠了。
了解更多