
互联网的发展速度简直让人目不暇接,数据量每年都在疯狂飙升。到 2026 年,网络数据的体量将达到一个新高点,各行各业都在拼命追赶潮流。根据 的报告,超过 69% 的企业已经把网页数据视为“核心 AI 资产”,而对实时、AI 驱动的数据采集需求,预计明年还会再涨 85%。不管你是做销售、电商、运营还是研究,现在的现实就是:AI 网页爬虫已经成为企业保持竞争力的标配,而不是可选项。

我在 SaaS 和自动化圈子混了很多年,亲眼见证了数据采集的巨大变革。以前大家还在手动复制粘贴网页内容,或者为各种容易崩溃的脚本头疼,如今的 AI 网页爬虫已经变得超级智能、高效又好用。这份指南会带你认识 2026 年正在改变数据采集玩法的 12 款顶级 AI 网页爬虫。不管你是零编程基础的业务小白、数据专家,还是厌倦重复劳动的打工人,这里总有一款适合你。
为什么现代企业离不开 AI 网页爬虫工具
说句实话,手动采集数据真的就是在浪费时间和精力。销售团队要花大把时间整理客户名单,电商经理很难实时盯住竞品价格,运营同学也常常被重复调研拖得焦头烂额。AI 网页爬虫直接颠覆了这一切——原本要几个小时的活,现在几分钟就能搞定,还能大大减少人为失误。
AI 网页爬虫带来的好处包括:
- 线索挖掘: 一键从 LinkedIn、各类目录或垂直网站提取联系人信息,持续为 CRM 注入新鲜、精准的销售线索(参考 )。
- 竞品监控: 实时追踪成千上万商品的价格、评价和新品发布,市场动态一手掌握。
- 产品调研: 汇总多渠道的参数、评论和趋势,帮你科学决策。
- 流程自动化: 采集到的数据可以直接导入表格、CRM 或仪表盘,彻底告别手动搬运。
实际效果非常明显:用上 AI 网页爬虫的企业,数据采集速度提升高达 65%,人工错误大幅减少(参考 )。可以说,AI 网页爬虫已经成为数据驱动团队的“秘密武器”。
2026 年顶级 AI 网页爬虫评选标准
市面上的工具五花八门,挑选合适的 AI 网页爬虫就像在科技展上“相亲”。我筛选这 12 款工具时,主要看这几点:
- 易用性: 非技术用户能不能快速上手?界面友不友好?
- AI 自动化能力: 有没有 AI 字段识别、数据结构化或流程自动化?
- 数据准确性与灵活性: 能不能搞定非结构化页面、动态内容和子页面?
- 价格与免费功能: 有没有免费版?付费方案透明吗?
- 业务价值: 对销售、电商、运营等团队有没有实际帮助?
顶级 AI 网页爬虫横向对比:功能、价格与应用场景
下面这张对比表,帮你一眼锁定最适合自己的工具:
| 工具 | 最佳适用人群 | 易用性 | AI 功能 | 免费版 | 价格 | 导出选项 | 典型应用场景 |
|---|---|---|---|---|---|---|---|
| Thunderbit | 零编程、业务运营 | ⭐⭐⭐⭐⭐ | AI 字段识别、子页面采集 | 有 | $15/月起 | Excel、Sheets、Notion、Airtable | LinkedIn 线索、电商监控 |
| ParseHub | 视觉化、复杂网站 | ⭐⭐⭐⭐ | 可视化选择、动态内容 | 有 | $49/月起 | CSV、Excel、JSON | 调研、动态网站 |
| Octoparse | 无代码、快速上手 | ⭐⭐⭐⭐ | AI 结构识别 | 有 | $75/月起 | CSV、Excel、API | 电商、房产 |
| Diffbot | 企业、知识图谱 | ⭐⭐ | AI 实体提取、知识图谱 | 无 | 定制,价格较高 | API、JSON | 市场情报、AI 训练 |
| Import.io | 企业、集成 | ⭐⭐⭐ | AI 数据清洗、预警 | 无 | 定制,价格较高 | API、Excel | 销售运营、价格预警 |
| WebHarvy | 视觉化、易用 | ⭐⭐⭐⭐ | 模式识别 | 无 | $199 一次性 | Excel、CSV、XML | 销售线索、产品调研 |
| Scrapy | 开发者、自定义任务 | ⭐ | AI/ML 插件 | 有 | 免费 | CSV、JSON、数据库 | 定制爬虫、数据工程 |
| Apify | 自动化、集成 | ⭐⭐⭐ | AI actor、定时任务 | 有 | $49/月起 | API、Sheets | 持续监控、流程自动化 |
| Helium Scraper | 自定义、视觉化 | ⭐⭐⭐ | AI 模式学习 | 无 | $99 一次性 | Excel、数据库 | 房产、调研 |
| UiPath | 企业、RPA | ⭐⭐ | RPA+AI 采集 | 无 | 定制,价格较高 | API、数据库 | 全流程自动化 |
| DataMiner | 快速、浏览器插件 | ⭐⭐⭐⭐ | 模板库 | 有 | $19/月起 | CSV、Excel、Sheets | 快速数据采集 |
| Visual Web Ripper | 批量、性价比 | ⭐⭐⭐ | 批量、定时任务 | 无 | $349 一次性 | Excel、CSV、XML | 批量销售数据 |
从无代码 Chrome 插件到企业级平台,覆盖了各种业务需求和预算。
1. Thunderbit
是我 2026 年的首选,尤其适合追求高效和易用的用户。作为联合创始人兼 CEO,难免有点偏心,但理由很充分:Thunderbit 专为追求结果的业务用户设计,省心又省力。
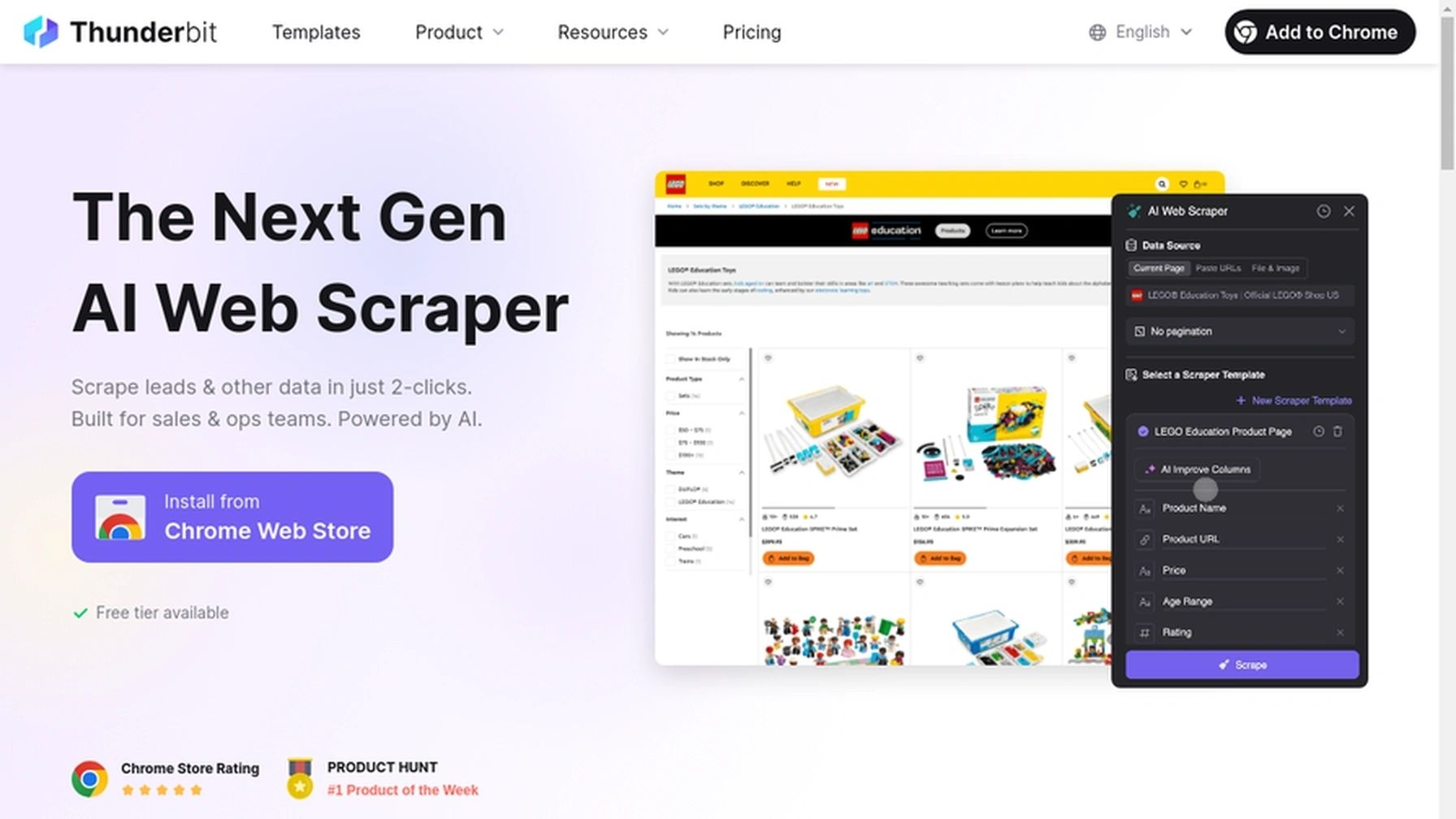
Thunderbit 的亮点:
- AI 智能字段推荐: 只需用自然语言描述需求(比如“抓取本页所有 LinkedIn 姓名和邮箱”),Thunderbit 的 AI 就能自动识别所需字段和数据类型,无需编程、无需模板、无需猜测。
- 子页面与分页采集: 想要更详细信息?Thunderbit 能自动访问每个子页面(比如产品详情页、个人主页),让你的数据表更丰富,非常适合销售线索挖掘或电商监控。
- 一键模板: 针对 Amazon、Zillow、Shopify 等热门网站,内置模板一键导出数据。
- 免费数据导出: 支持导出到 Excel、Google Sheets、Airtable、Notion,数据归你所有,无需额外付费。
- AI 自动填表: 不仅能采集,还能自动填写表单、自动化流程。
- 灵活定价: 免费版支持最多 6 个页面,付费方案只要 $15/月起()。
小案例分享:
某销售团队需要从 LinkedIn 和行业目录采集 500+ 潜在客户。用 Thunderbit 的“AI 智能字段推荐”,快速提取姓名、职位、邮箱、公司网址,并通过子页面采集补充更多信息。不到一小时就生成了可直接导入 CRM 的数据文件,销售经理都说太省事了。
Thunderbit 已获得 ,也是我当年最想早点拥有的高效数据工具。
2. ParseHub
 是一款灵活的可视化 AI 网页爬虫,适合处理从简单到复杂的项目。通过点选界面,用户可以直接在网页上选择需要采集的数据,就算是 JavaScript 动态页面也能轻松搞定。
是一款灵活的可视化 AI 网页爬虫,适合处理从简单到复杂的项目。通过点选界面,用户可以直接在网页上选择需要采集的数据,就算是 JavaScript 动态页面也能轻松搞定。
- 可视化数据选择: 直接点击网页元素,无需编程。
- 支持动态内容: 能处理 AJAX、下拉菜单、多步导航等复杂页面。
- 云端与本地运行: 可选择在云端或本地执行任务。
- 多种导出方式: 支持导出为 CSV、Excel、JSON,或推送到 Dropbox/Amazon S3。
ParseHub 特别受研究人员和市场营销人员欢迎,适合需要采集复杂网站的场景。上手门槛比 Thunderbit 稍高,但熟练后功能非常强大()。
3. Octoparse
 是一款无代码 AI 网页爬虫,以拖拽式操作和极速部署著称,深受业务团队喜欢。
是一款无代码 AI 网页爬虫,以拖拽式操作和极速部署著称,深受业务团队喜欢。
- AI 辅助采集: 智能识别表格、列表、详情页结构。
- 云端自动化: 支持定时任务和大规模采集。
- 内置模板: 针对 Amazon、Instagram 等热门网站。
- 多种导出方式: 支持 CSV、Excel、API。
Octoparse 在电商和房产领域表现特别突出,但如果采集量大,免费版很快就会用完()。
4. Diffbot
 是企业级大规模结构化数据采集的“重型选手”。它的 AI “知识图谱”能抓取并结构化数十亿网页,把非结构化内容变成可检索数据库。
是企业级大规模结构化数据采集的“重型选手”。它的 AI “知识图谱”能抓取并结构化数十亿网页,把非结构化内容变成可检索数据库。
- AI 知识图谱: 自动提取网页中的关系、实体和事实。
- API 接入: 结构化数据可直接集成到 BI 或 AI 流程。
- 企业级应用: 被众多世界 500 强用于市场情报和研究。
如果你想自建类似 Google 的搜索引擎,或者为 AI 模型提供大规模网页数据,Diffbot 是业内标杆()。
5. Import.io
 是专注于大规模自动化数据采集与集成的企业级 AI 网页爬虫。
是专注于大规模自动化数据采集与集成的企业级 AI 网页爬虫。
- 自动数据转换: AI 自动清洗和结构化采集到的数据。
- 实时监控: 可设置价格变动、评论、新品等预警。
- 合规保障: 符合 GDPR 和 CCPA 要求。
- 系统集成: 数据可直接推送到业务系统、仪表盘或 API。
Import.io 很受销售运营和电商团队欢迎,适合需要大规模情报的企业()。
6. WebHarvy
 是一款 Windows 平台的可视化 AI 网页爬虫,主打零代码、易上手。
是一款 Windows 平台的可视化 AI 网页爬虫,主打零代码、易上手。
- 点选操作: 内置浏览器直接选择数据。
- 模式识别: 自动识别重复数据(如商品列表)。
- 支持分页与子页面: 可采集多页列表和详情页。
- 多种导出格式: 支持 Excel、CSV、XML。
WebHarvy 适合销售线索挖掘、产品调研以及喜欢桌面应用的用户()。
7. Scrapy
 是基于 Python 的开源 AI 网页爬虫,专为开发者打造。如果你追求极致定制和可扩展性,Scrapy 是不二之选。
是基于 Python 的开源 AI 网页爬虫,专为开发者打造。如果你追求极致定制和可扩展性,Scrapy 是不二之选。
- 自定义爬虫: 可构建任意复杂的网站采集任务。
- AI/ML 集成: 支持接入语言模型,实现更智能的数据提取()。
- 分布式采集: 支持多服务器协作,轻松应对大规模任务。
- 免费开源: 无需授权费,只需开发投入。
Scrapy 是技术团队和数据工程师的首选()。
8. Apify
 是一款云端 AI 网页爬虫与自动化平台,拥有丰富的“actor”市场(即预设爬虫),非常适合追求全流程自动化的团队。
是一款云端 AI 网页爬虫与自动化平台,拥有丰富的“actor”市场(即预设爬虫),非常适合追求全流程自动化的团队。
- 爬虫市场: 数千个热门网站的预设 actor。
- 云端自动化: 支持定时、监控和大规模集成。
- API 与集成: 数据可推送到 Sheets、CRM 或自定义流程。
- AI 驱动功能: 智能提取、数据清洗与丰富。
Apify 在持续监控和集成型项目中表现突出()。
9. Helium Scraper
 提供可视化流程构建器和 AI 辅助数据采集,兼顾易用性和深度定制。
提供可视化流程构建器和 AI 辅助数据采集,兼顾易用性和深度定制。
- 可视化流程: 拖拽式自定义采集逻辑。
- AI 模式识别: 自动学习数据结构,提取更智能。
- 数据库集成: 结果可直接存入 SQL 或导出为 Excel。
- 支持动态内容: 适配 AJAX、JavaScript 等复杂页面。
Helium Scraper 在房产、调研及结构复杂网站中表现优异()。
10. UiPath
 以 RPA(机器人流程自动化)平台闻名,其 AI 网页爬虫能力同样强大,尤其适合需要端到端自动化的企业。
以 RPA(机器人流程自动化)平台闻名,其 AI 网页爬虫能力同样强大,尤其适合需要端到端自动化的企业。
- RPA + AI 采集: 不仅能采集数据,还能自动化整个业务流程。
- 企业级应用: 全球大型企业用于合规、高效、精准的数据处理。
- 系统集成: 可与 ERP、CRM 等系统无缝对接。
- 高级调度: 支持定时或事件触发任务。
UiPath 是自动化发票处理、房产数据录入等场景的首选()。
11. DataMiner
 是一款 Chrome 扩展型 AI 网页爬虫,主打模板驱动的快速数据采集。
是一款 Chrome 扩展型 AI 网页爬虫,主打模板驱动的快速数据采集。
- 模板库: 数千个热门网站的预设模板。
- 点选操作: 可视化选择数据,或直接用模板一键采集。
- 多种导出方式: 支持导出到 CSV、Excel、Google Sheets。
- 免费与付费方案: 免费版对轻度用户非常友好。
DataMiner 适合追求高效、无需编程的业务用户()。
12. Visual Web Ripper
 是一款性价比高的 Windows AI 网页爬虫,专为批量数据采集设计。
是一款性价比高的 Windows AI 网页爬虫,专为批量数据采集设计。
- 批量采集: 轻松处理大规模数据。
- 定时任务: 支持自动化、周期性采集。
- 多种导出格式: 支持 Excel、CSV、XML。
- 一次性授权: 约 $349/用户,适合预算有限的团队。
Visual Web Ripper 适合销售、运营、电商等需要大量数据的团队()。
如何为你的企业选择合适的 AI 网页爬虫
到底该选哪款 AI 网页爬虫?这里有一份速查表:
- 零编程或业务用户: 和 WebHarvy 简单易用,完全不需要技术门槛。
- 大规模或复杂项目: Scrapy、Diffbot、Apify 灵活强大,适合技术团队。
- 持续监控与流程自动化: UiPath 和 Apify 在企业自动化领域表现突出。
- 预算有限团队: Visual Web Ripper 和 Helium Scraper 一次性付费,性价比高。
- 快速浏览器采集: DataMiner 适合临时任务和模板驱动场景。
选工具前,建议结合团队技术能力、数据量和复杂度、以及数据后续用途(导出、集成、自动化)综合考虑。
真实业务案例:AI 网页爬虫如何赋能企业
来看看几个真实案例:
- 销售线索挖掘: 某 SaaS 销售团队用 抓取 LinkedIn 和行业目录,单下午就整理出 1000+ 高质量客户名单,省下了好几天的人工调研。
- 电商价格监控: 某电商用 Octoparse 和 Apify 实时监控数百个 SKU 的竞品价格和评价,实现动态定价和快速响应市场。
- 市场情报分析: 世界 500 强企业借助 Diffbot 知识图谱,梳理竞品新品发布、合作关系和新闻动态,为 BI 仪表盘提供实时洞察。
- 流程自动化: 某运营团队用 UiPath 自动采集供应商门户发票数据,人工录入时间减少 80%,准确率大幅提升()。
这些案例的共同点是什么?AI 网页爬虫正在让网络数据高效转化为业务价值——更快、更智能、更省力。
总结:AI 网页爬虫工具引领数据采集新未来
一句话总结:AI 网页爬虫已经成为所有依赖网络数据团队的核心生产力工具。2026 年最优秀的工具兼具易用性、强大 AI 自动化和灵活集成能力,让任何人(不仅仅是开发者)都能把互联网变成结构化、可用的数据资源。
如果你还停留在复制粘贴时代,现在正是升级的好时机。 以及同类产品正在让数据采集变得更快、更精准,甚至有点“好玩”。重新审视你的工作流程,选对工具,让 AI 帮你搞定那些繁琐的重复劳动。
想了解更多实用技巧、教程和深度解析?欢迎访问 ,掌握 AI 网页爬虫与自动化的最新动态。
常见问题解答
1. 什么是 AI 网页爬虫?它和传统爬虫有啥区别?
AI 网页爬虫用人工智能自动识别、提取和结构化网页数据,通常支持自然语言提示或智能字段推荐。相比传统爬虫,AI 工具能适应页面结构变化和非结构化数据,准确率更高,操作也更友好。
2. 哪款 AI 网页爬虫最适合非技术用户?
和 WebHarvy 都非常适合零编程用户,界面直观,AI 字段识别很强。Thunderbit 还支持自然语言提示和一键数据导出。
3. AI 网页爬虫能处理动态或 JavaScript 页面吗?
当然可以。ParseHub、Octoparse、Helium Scraper 等工具专为动态内容、AJAX、多步导航设计。对于特别复杂的网站,Scrapy 和 Apify 提供开发者级别的控制。
4. 各类 AI 网页爬虫的定价模式有啥不同?
价格差异很大:Thunderbit、WebHarvy、Helium Scraper 提供实惠或一次性授权,Diffbot、Import.io、UiPath 等企业级工具则需要定制报价。大多数工具对轻度用户都有免费版。
5. AI 网页爬虫最常见的业务应用有哪些?
主要包括销售线索挖掘、竞品价格监控、产品调研、流程自动化和市场情报分析。AI 网页爬虫能节省时间、减少错误,让网络数据更容易转化为业务价值。
想体验 AI 驱动的数据采集?,开启高效工作新篇章。
延伸阅读