网络上充斥着海量数据——多到到 2025 年,我们每天产生的数据量预计将达到惊人的 。如果你在做销售、电商、运营或研究,你一定很清楚,把这些杂乱的数据变成有用信息有多难。手动复制粘贴?别想了。它又慢、又容易出错,而且无聊程度堪比看油漆干掉。这也是为什么越来越多团队————正在用 AI 自动化网页数据提取,把原本要花几周的工作压缩到几分钟完成。
我在 SaaS 和自动化领域做了很多年,也亲眼见过合适的 AI 网页爬虫工具如何显著提升生产力。但市面上选择这么多,该怎么挑出最适合你的那一款?下面我们就来拆解 10 款利用 AI 高效抓取网站的工具——从点选式 Chrome 扩展,到企业级云平台,一次看懂。
为什么要用 AI 抓取网站?解锁更多可能性
传统网页爬虫就像老式 GPS——你知道的,就是那种路一变就立刻迷路的设备。它们依赖固定规则和选择器,只要网站一改版,功能就容易失效。相比之下,AI 驱动的爬虫会用机器学习和自然语言处理来识别模式、适应变化,甚至只靠一段普通英文描述就能理解你想要什么()。
AI 能带来什么?
- 速度更快: AI 爬虫能把原本需要数周的手工调研,变成几分钟的自动提取()。
- 准确性更高: 它们会用计算机视觉和 NLP 区分商品标题、描述等字段,让数据更干净、更可靠。
- 更强的适应性: 网站改版时,AI 能自动适应,不用你反复维护。
- 更易上手: 非技术用户也能通过描述需求直接抓数据,像获客、比价监控、市场研究这类场景,都能快速落地。
- 节省成本: 团队普遍报告,同时大幅减少人工劳动。
简单来说,用 AI 抓网站,意味着你能更快拿到更可靠的数据,而且不需要懂 regex、也不用随时叫开发来救场。
我们是如何挑选最值得用来抓网站的 AI 工具的
市场上的工具这么多,我主要从以下几个维度筛选出前 10 名:
- 易用性: 非程序员能不能很快上手?有没有可视化界面或自然语言支持?
- AI 能力: 是否使用 AI 做字段识别、适应页面变化,或理解自然语言指令?
- 功能完整度: 是否支持分页、定时、代理管理、验证码处理,以及多种导出格式?
- 可扩展性: 能不能从少量页面扩展到百万级?是否有云端版本?
- 价格与可访问性: 有没有免费方案?对个人、中小企业和大型企业是否都负担得起?
- 支持与社区: 文档是否完善、支持是否及时、用户社区是否活跃?
- 口碑: 真实用户评价、推荐案例,以及长期稳定性。
我挑选的工具包含浏览器扩展、桌面应用、云平台和开发者框架——所以无论你是独立创业者、数据分析师,还是企业团队,都能找到适合自己的方案。
1. Thunderbit
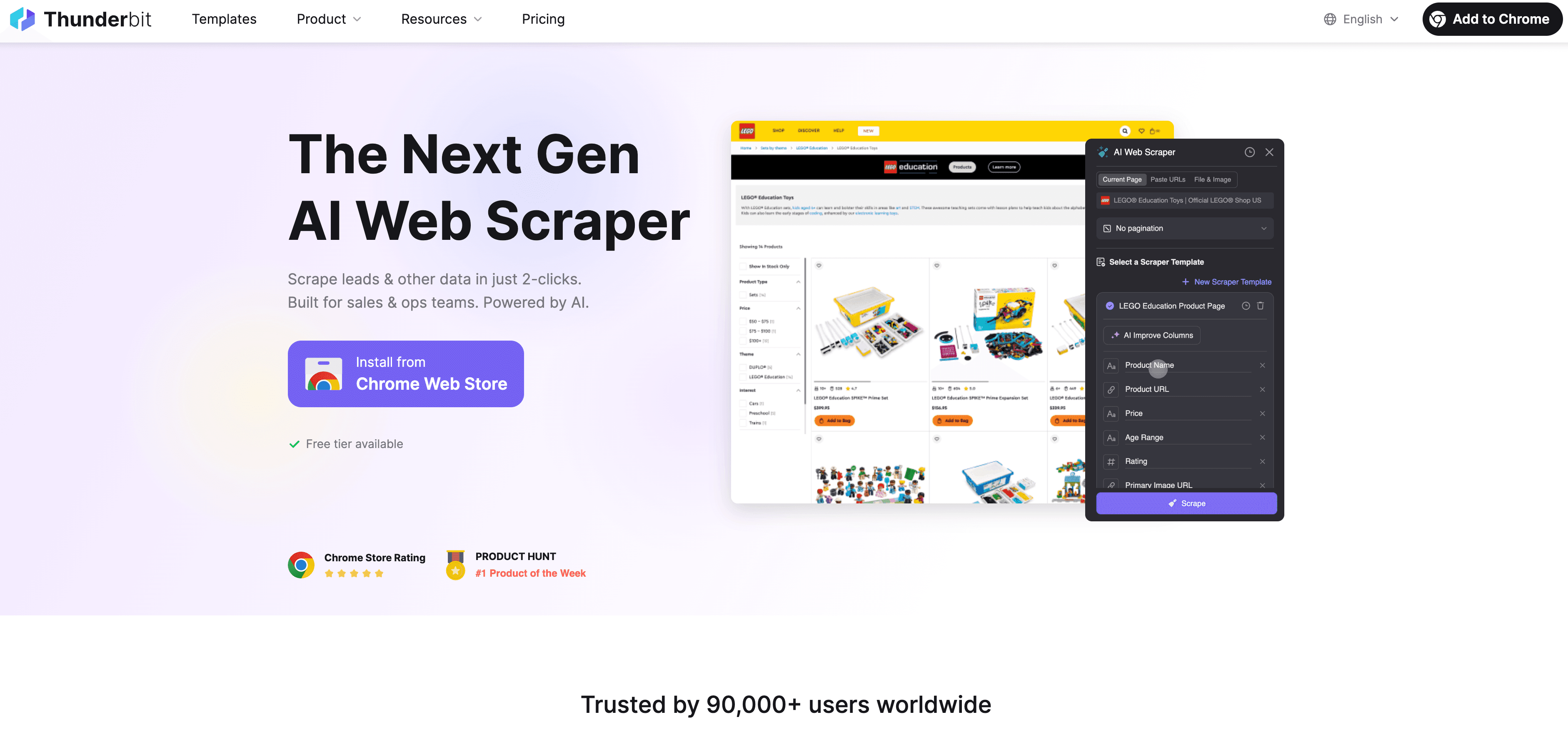 是我最推荐给业务用户的工具,尤其适合想快速用 AI 抓取网站的人。作为一款 Chrome 扩展,Thunderbit 就像一个 AI 助手,能读取任何网页(甚至 PDF 或图片),只需两步就能输出结构化数据。
是我最推荐给业务用户的工具,尤其适合想快速用 AI 抓取网站的人。作为一款 Chrome 扩展,Thunderbit 就像一个 AI 助手,能读取任何网页(甚至 PDF 或图片),只需两步就能输出结构化数据。
Thunderbit 的特别之处在哪里?
- 自然语言界面: 只要描述你想要什么(比如“提取此页面上的所有商品名称、价格和图片”),Thunderbit 的 AI 就会自动处理后续步骤。
- AI 推荐字段: 点一下按钮,AI 就会扫描页面,推荐最合适的提取列。你可以调整或直接接受,然后点击“抓取”。
- 子页面与分页抓取: Thunderbit 可以自动跟进子页面链接(比如商品详情页),也能处理分页,连无限滚动也不在话下。
- 即时导出数据: 可直接导出到 Excel、Google Sheets、Airtable 或 Notion,无需额外付费。
- 免费联系方式提取器: 一键提取邮箱、电话和图片,完全免费。
- 定时抓取: 通过自然语言设置定期任务(比如“每周一上午 9 点”),其余交给 AI 处理。
Thunderbit 在处理杂乱、复杂或非标准网页时尤其强大——像小众目录、房产列表,或者会让其他爬虫抓狂的电商商品页。用户评价一直很高,普遍称赞它既简单又强大,在 。
价格: 免费额度可抓取 6–10 个页面;付费计划起价约为每月 15 美元,可获得 500 积分(页面),更高等级适合更大需求。数据导出始终免费。
适合人群: 销售、市场、电商运营,以及任何想在不写代码、也不头疼的情况下抓取数据的人。
2. import.io
 是一款企业级 AI 网页爬虫平台,深受联合利华、沃尔沃等知名企业信赖。它专为大规模、关键任务级的数据提取而设计。
是一款企业级 AI 网页爬虫平台,深受联合利华、沃尔沃等知名企业信赖。它专为大规模、关键任务级的数据提取而设计。
为什么选择 import.io?
- AI“自我修复”流水线: 如果网站发生变化,import.io 的 AI 可以自动适配,不再因为页面改动而抓取失效。
- 基于提示词的提取: 只需输入高层级指令,AI 会自动补全细节。
- 自动化合规: 内置隐私法规过滤(GDPR、CCPA)和可自定义的 PII 脱敏功能。
- 全托管云端: 代理轮换、调度和基础设施都由平台帮你处理。
- API 集成: 可把任何网站变成一个实时 API,供分析系统或业务系统调用。
价格: 起价约每月 299 美元,支持定制企业方案,也提供免费试用。
适合人群: 需要可靠、可扩展、且合规的网页数据流水线的企业和数据团队。
3. Bright Data
 的核心就是规模。如果你需要抓取数百万页面、全球价格监控,或者给 AI 模型喂数据,它会很适合你。
的核心就是规模。如果你需要抓取数百万页面、全球价格监控,或者给 AI 模型喂数据,它会很适合你。
核心功能:
- 1 亿+ 代理网络: 覆盖住宅、移动和数据中心 IP,抗封锁能力极强。
- AI 驱动解封器: 可解决验证码、轮换请求头,并实时适应反爬措施。
- 预置爬虫: 为 120+ 热门网站提供 API(Amazon、LinkedIn、Google 等)。
- 数据集市场: 可购买或直接使用海量预抓取数据集。
- 适配 LLM 的数据流: 将实时网页数据直接送入 AI 系统。
价格: 按使用量计费;大规模使用时成本可能较高。提供免费试用和部分免费数据集。
适合人群: 大型组织、AI 项目,以及任何需要海量、可靠且合规网页数据的人。
4. ParseHub
 是一款桌面应用(Windows、Mac、Linux),可以让可视化网页抓取变得很简单——即使面对动态、JavaScript 很重的网站也没问题。
是一款桌面应用(Windows、Mac、Linux),可以让可视化网页抓取变得很简单——即使面对动态、JavaScript 很重的网站也没问题。
为什么选 ParseHub?
- 机器学习模式识别: 点击一个元素后,ParseHub 会自动找出所有相似元素。
- 支持动态内容: 可处理 AJAX、无限滚动和交互式元素。
- 可视化流程构建器: 无需写代码,就能搭建多步骤抓取流程。
- 云端调度: 可在云端运行任务并设置定期执行。
- 灵活导出: 支持 CSV、Excel、JSON 或 API。
价格: 免费版最多 5 个项目(每次运行 200 页);付费计划起价 189 美元/月。
适合人群: 想要一个功能强大、点选式爬虫来处理复杂网站的分析师、研究人员和小企业。
5. Scrapy
 是开发者专用的网页爬取工具包。它基于 Python,开源,而且高度可扩展。
是开发者专用的网页爬取工具包。它基于 Python,开源,而且高度可扩展。
Scrapy 的特别之处:
- 极致灵活: 你可以编写自定义蜘蛛程序,按任何规模抓取任何内容。
- AI 集成: 可通过 Scrapy-LLM 等扩展,使用大语言模型(LLM)解析数据,或集成 NLP,让提取更智能。
- 异步爬取: 在大任务场景下速度极快、效率很高。
- 开放生态: 有大量代理、浏览器自动化等插件可用。
价格: 免费且开源;你只需承担自己的基础设施成本。
适合人群: 想要完全掌控流程,并能把 AI 集成进自定义抓取工作流的开发者和技术团队。
6. Octoparse
 是一款无需代码、基于云端的网页爬虫,面向业务用户和团队设计。
是一款无需代码、基于云端的网页爬虫,面向业务用户和团队设计。
亮点功能:
- AI 自动识别: AI 会扫描页面并建议提取哪些数据,无需手动配置。
- 拖拽式工作流: 可视化构建爬虫,支持登录、分页和动态内容。
- 预置模板: 提供数百个热门网站的现成模板。
- 云端调度: 可在云端运行并安排抓取任务,导出到 Sheets、Excel 或通过 API 获取。
- AI 正则助手: 借助 AI 生成正则表达式模式。
价格: 免费版(10 个任务);付费计划起价约 75 美元/月。
适合人群: 想要简单易用、无需编码的抓取方案的非技术用户、市场团队和中小企业。
7. WebHarvy
 是一款 Windows 桌面应用,以智能模式识别和一次性授权模式闻名。
是一款 Windows 桌面应用,以智能模式识别和一次性授权模式闻名。
为什么选 WebHarvy?
- 自动模式识别: 点击一个元素后,WebHarvy 会找出页面上所有相似数据。
- 可视化抓取: 内置浏览器支持通过点击选择数据,无需写代码。
- 图片和邮箱抓取: 轻松下载图片或提取邮箱。
- 一次性购买: 终身授权起价 129 美元,可选付费更新。
价格: 单用户一次性 129 美元起。
适合人群: 想要一款性价比高、可离线使用的抓取工具的中小企业、研究人员或 Windows 用户。
8. Apify
 是一个面向网页抓取和工作流集成的云自动化平台,开发者和非程序员都在用。
是一个面向网页抓取和工作流集成的云自动化平台,开发者和非程序员都在用。
核心功能:
- Actors 市场: 提供 200+ 预构建机器人,覆盖常见抓取任务。
- 自定义 Actors: 你可以用 JavaScript/Python 编写自己的机器人,也能使用可视化工具。
- AI 集成: 把抓取数据喂给 LLM,或由 AI 智能体触发爬虫运行。
- 云端调度与存储: 支持规模化运行任务、存储结果,并与 API 或工作流工具集成。
- 代理与无头浏览器支持: 轻松处理动态网站和反爬措施。
价格: 免费版(每月 5 美元额度);付费计划起价 49 美元/月。
适合人群: 想要可扩展、自动化、并能与工作流结合的抓取方案的开发者、初创公司和团队。
9. Diffbot
 是 AI 驱动网页数据提取和知识图谱领域的“王者”。
是 AI 驱动网页数据提取和知识图谱领域的“王者”。
Diffbot 的独特之处:
- 完全由 AI 驱动的提取: 把任何 URL 丢给 Diffbot 的 API,就能得到结构化 JSON,无需配置。
- 知识图谱: 可访问一个庞大且持续更新的图谱,包含 100 亿+ 实体(公司、人物、产品、文章)。
- 计算机视觉 + NLP: 可从文本、图片中提取数据,甚至推断关系。
- 有依据的 LLM: 你可以提问,并获得带网页引用来源的答案。
价格: 免费开发者试用(每月 10,000 次调用);Startup 方案 299 美元/月,提供 25 万积分。
适合人群: 想要从任意页面即时获取结构化数据,或建立一个可直接查询的网页知识库的企业、AI 公司和研究人员。
10. Data Miner
 是一款 Chrome/Edge 扩展,让所有人都能轻松使用基于模板的快速抓取。
是一款 Chrome/Edge 扩展,让所有人都能轻松使用基于模板的快速抓取。
为什么选 Data Miner?
- 50,000+ 公共配方: 一键抓取 15,000+ 网站(LinkedIn、黄页、Amazon 等)。
- 点选式自定义: 可视化创建你自己的抓取配方。
- 分页与自动化: 在浏览器中抓取多页或网址列表。
- 直接导出: 下载为 CSV/Excel,或上传到 Google Sheets。
价格: 每月最多 500 页免费;付费计划起价约 19 美元/月。
适合人群: 想要快速、基于浏览器、适合中小任务的非技术用户。
对比这些使用 AI 抓取网站的顶级工具
下面是这 10 款工具的快速对比:
| 工具 | 最适合 | AI 功能 | 易用性 | 可扩展性 | 价格 | 支持/社区 |
|---|---|---|---|---|---|---|
| Thunderbit | 非程序员、业务用户 | LLM 字段识别、自然语言界面 | 非常容易 | 中等(云端) | 免费,起价 15 美元/月 | 邮件响应快、开发活跃 |
| import.io | 企业、数据团队 | 自我修复、提示词 AI | 中等 | 非常高 | 起价 299 美元/月 | 企业专属支持 |
| Bright Data | 大型组织、AI 项目 | 解封器、1 亿+ 代理 | 中等 | 极高 | 按使用量计费 | 企业级、文档完善 |
| ParseHub | 分析师、中小企业、动态网站 | 机器学习模式识别 | 容易/中等 | 中高 | 免费,起价 189 美元/月 | 文档、论坛 |
| Scrapy | 开发者、自定义工作流 | LLM/NLP 插件 | 较难(代码) | 非常高 | 免费(开源) | 社区、文档 |
| Octoparse | 中小企业、非程序员、团队 | AI 自动识别、模板 | 非常容易 | 高(云端) | 免费,起价 75 美元/月 | 在线客服、教程 |
| WebHarvy | Windows 用户、中小企业、研究人员 | 模式识别 | 非常容易 | 中等 | 129 美元一次性 | 邮件、评价 |
| Apify | 开发者、初创公司、自动化 | AI 集成、Actors | 中等 | 非常高 | 免费,起价 49 美元/月 | 文档、Slack、支持 |
| Diffbot | AI/数据科学、企业 | 全流程 AI 提取、知识图谱 | 容易(API) | 极高 | 免费,起价 299 美元/月 | 专属、学术支持 |
| Data Miner | 非技术用户、快速浏览器任务 | 5 万+ 配方、模式 AI | 非常容易 | 低到中等 | 免费,起价 19 美元/月 | 办公时间、配方库 |
如何根据你的需求选择合适的 AI 网页爬虫工具
这是我给你准备的选型速查表:
- 非程序员、快速任务: Thunderbit、Octoparse、Data Miner 或 WebHarvy。
- 大规模、企业级需求: import.io、Bright Data、Diffbot。
- 自定义、开发者工作流: Scrapy、Apify。
- 动态或复杂网站: ParseHub、Octoparse、Apify(配合浏览器自动化)。
- 需要从任意页面即时获得结构化数据: Diffbot。
- 想要一次性购买(不订阅): WebHarvy。
小贴士: 有时把多个工具组合起来效果最好。比如先用 Thunderbit 快速把杂乱数据结构化,再用 WebHarvy 的模式识别做进一步处理,整个流程会更顺。
关键决策因素:
- 预算: 免费版很适合测试;企业工具更贵,但功能、规模和支持也更强。
- 技术水平: 业务用户适合无代码工具;开发者适合框架类产品。
- 数据量: 小任务用浏览器工具;大任务用云平台。
- 支持需求: 企业工具通常有 SLA;其他工具更多依赖社区或邮件支持。
结语:用 AI 抓取网站的未来
AI 正在把网页爬虫从小众开发者任务,变成主流商业能力。无论你是在构建销售线索名单、监控价格,还是把数据喂给 AI 模型,现在都有适合你的工具,也有适合你的技术水平。上面这 10 款工具,充分说明了这个生态已经变得多么多样、又多么强大。
随着 AI 继续进化,网页抓取也会变得更聪明:更自然的语言界面、更强的网页变化适应能力,以及与业务工作流更深度的集成。我的建议是:不妨多试几款,看看哪一款最适合你的流程,也别害怕把不同工具组合起来,往往能得到最佳结果。
如果你想看看现代 AI 驱动的抓取到底是什么样子, ,或者到 看看更多指南。网页数据的未来已经到来,而且它比无休止的复制粘贴好玩得多,也高效得多。
常见问题
1. 为什么我应该用 AI 抓取网站,而不是传统工具?
AI 驱动的爬虫能适应不断变化的网页布局,自动识别模式,还能让非技术用户只通过描述需求就提取数据。这意味着更快、更可靠的数据提取,维护更少,麻烦也更少。
2. 哪款 AI 网页爬虫最适合非程序员?
Thunderbit、Octoparse、Data Miner 和 WebHarvy 都非常适合非技术用户。它们提供可视化界面、自然语言支持,而且不需要编程技能。
3. 大规模或企业级网页抓取最好的工具是什么?
import.io、Bright Data 和 Diffbot 都是为规模、稳定性和合规性而生的。它们可以处理数百万页面,提供强大的 API,并为企业客户提供专属支持。
4. 我可以把不同工具组合起来优化我的网页抓取流程吗?
当然可以!很多团队都会组合使用——比如用 Thunderbit 快速结构化,再用 WebHarvy 做模式识别,或者用 Apify 做工作流自动化。混合使用能让每个工具发挥各自优势。
5. 有免费的方式试用这些 AI 网页爬虫工具吗?
有的!大多数工具都提供免费版或试用。Thunderbit、Octoparse、Data Miner 和 Apify 都有免费方案,你可以先体验再决定是否付费。
准备好提升你的网页数据效率了吗?试试上面这些工具,看看能帮你节省多少时间和精力。如果你想了解更多网页抓取、自动化和 AI 的技巧,欢迎查看 或订阅我们的 。祝你抓取顺利!
延伸阅读