
“你可以拥有数据却没有信息,但没有数据就不可能有信息。” —
最新数据说,互联网网站数量已经超过 ,而且每天还会新增大约 200 万篇内容。面对这么夸张的数据海,里面当然藏着一堆能帮你做决策的洞察;但麻烦点在于:其中大约 都是非结构化数据——想真正拿来用,基本都得再“加工”一轮。这也是为什么网页爬虫工具越来越像刚需:它能把线上数据直接“搬运”出来,并整理成你能直接分析的格式。
如果你是网页数据抓取新手,看到 、 这种词,可能会瞬间头大。但到了 AI 时代,这些门槛真的低很多了。现在的 AI 驱动抓取工具,让你不用很硬核的技术背景也能快速上手:采集、整理、处理数据都能更快搞定,而且大多数情况下几乎不用写代码。
最值得推荐的网页爬虫工具与软件
- :上手最简单、效果也很出色的 AI 网页爬虫
- :适合实时监控与批量数据抓取
- :主打无代码自动化,应用集成非常丰富
- :更偏专业的可视化网页抓取
- :功能强的无代码抓取,擅长规避封 IP 与反爬检测
- :面向高级场景的 AI 数据抽取 API 与知识图谱
试试用 AI 来做网页抓取
可以直接点一点、跟着演示探索,并在观看时运行整个流程。
网页爬虫是怎么工作的?
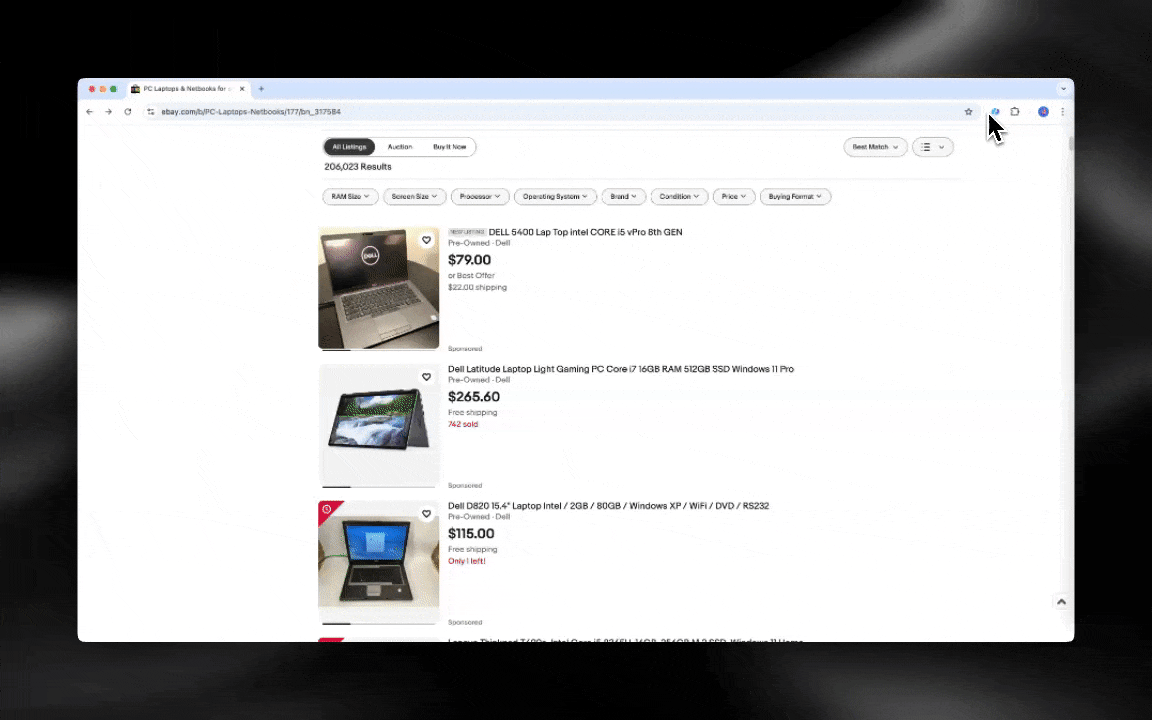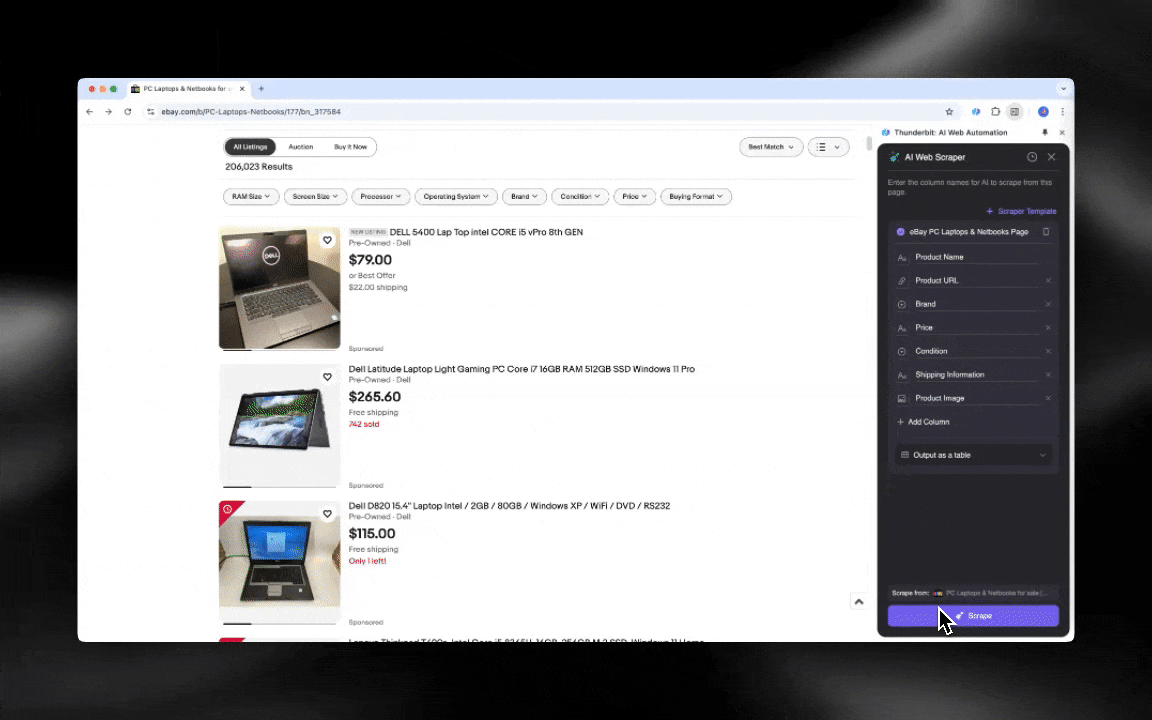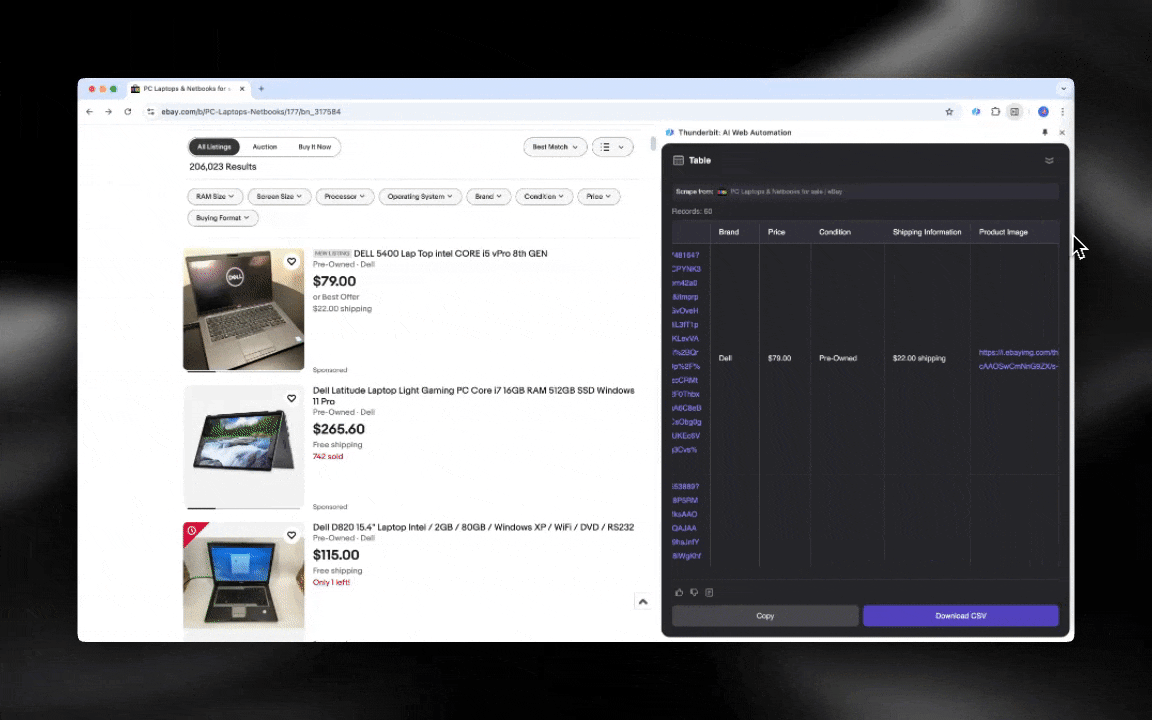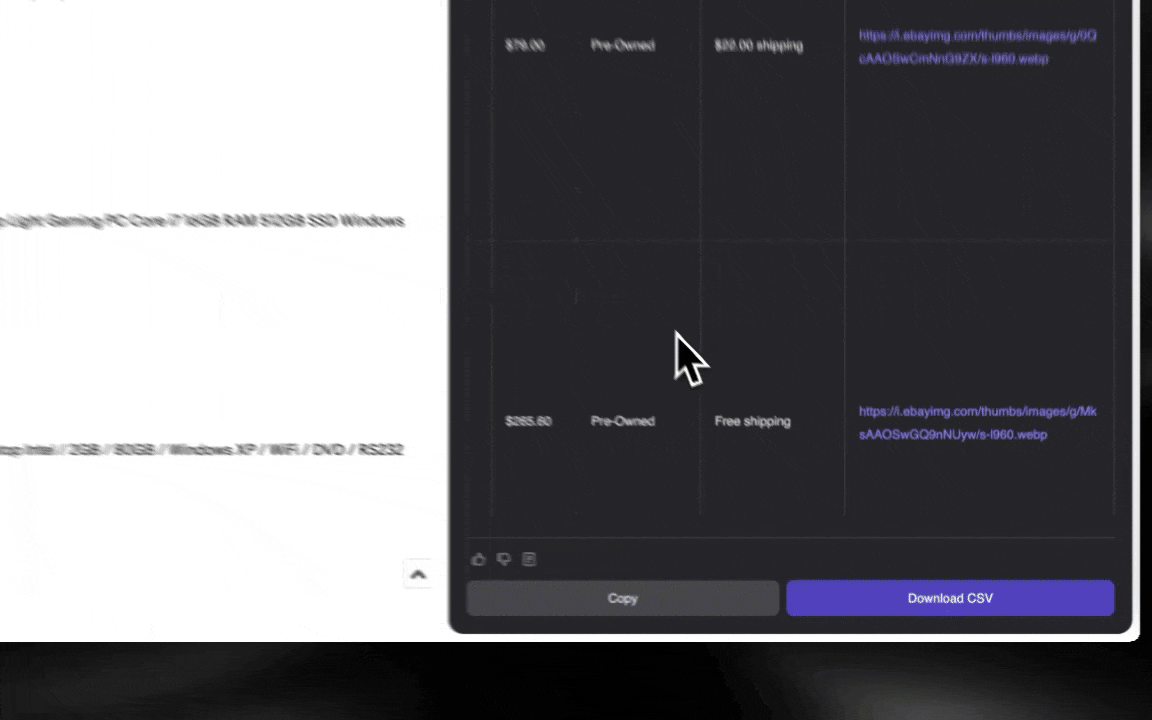
网页抓取的本质,就是把网站上的数据“抽”出来。你给工具一套规则或指令,它就会从网页里把文本、图片或其他你需要的内容抓出来,然后整理成表格。无论你是做电商价格监控、收集研究资料,还是想做一份更完整的 Excel / Google Sheets 数据表,这类工具都特别好用。
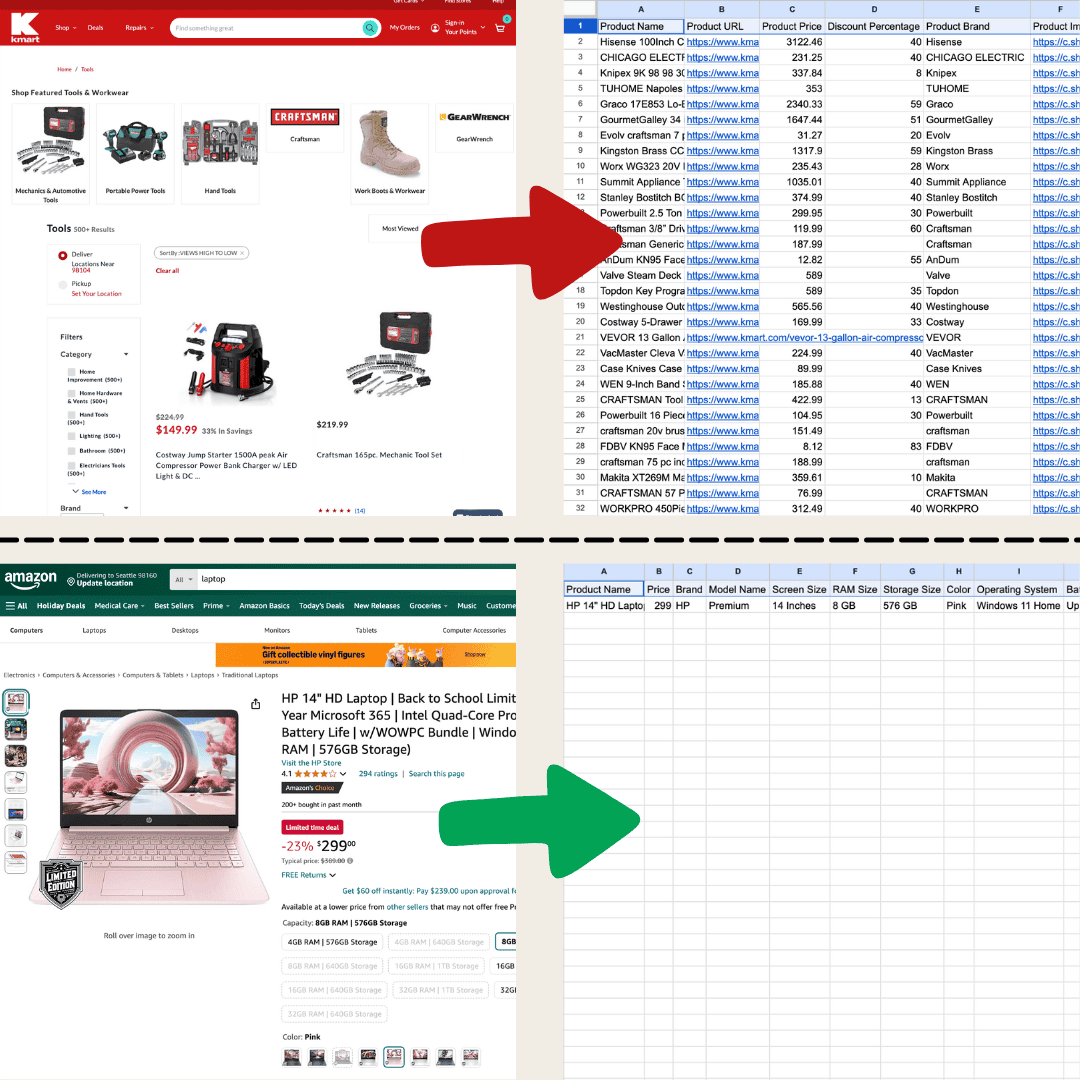 这张表是我用 Thunderbit 的 AI 网页爬虫做出来的。
这张表是我用 Thunderbit 的 AI 网页爬虫做出来的。
实现方式其实很多。最原始的当然是手动复制粘贴,但数据一多就会非常折磨人。所以大多数人会在三种方案里选:传统网页爬虫、AI 网页爬虫,或者自己写代码。
传统网页爬虫一般是靠页面结构来设规则:比如指定从某些 HTML 标签里抓商品名、价格等字段。页面结构稳定时它们很稳;但只要网站改版、布局微调,你往往就得回去重新配规则,维护成本会明显上来。
 传统爬虫的学习成本通常不低,配置时可能要点很多次才能完成。
传统爬虫的学习成本通常不低,配置时可能要点很多次才能完成。
AI 网页爬虫你可以把它理解成:先让 ChatGPT 这种能力把网页“看懂”,再按你的需求把内容抽出来。很多时候它还能顺手把抽取、翻译、总结等处理一起做完。因为它用自然语言处理去理解页面结构,所以网站就算有小幅改动,AI 网页爬虫也更容易自适应,不一定要你重新写规则。也因此,它特别适合结构复杂、经常变化、维护成本高的网站。
 AI 网页爬虫上手很快,点几下就能拿到更细致的数据!
AI 网页爬虫上手很快,点几下就能拿到更细致的数据!
到底该选哪一种? 还是看你的使用场景。如果你愿意折腾代码,或者要在热门网站上做超大规模采集,传统爬虫可能更高效;但如果你是新手,或者希望工具能更好应对网站更新,AI 网页爬虫通常更省心。更细的选择建议在下表。
| 场景 | 更推荐的选择 |
|---|---|
| 目录站、购物网站或任何列表型页面的轻量抓取 | AI 网页爬虫 |
| 页面数据少于 200 行,用传统爬虫搭建规则太耗时 | AI 网页爬虫 |
| 需要按特定格式抓取后再导入其他系统(例如抓联系人信息导入 HubSpot) | AI 网页爬虫 |
| 在高频网站上进行大规模抓取,例如数万条 Amazon 商品页或 Zillow 房源列表 | 传统网页爬虫 |
6 款网页爬虫工具速览
| 工具 | 价格 | 核心能力 | 优点 | 缺点 |
|---|---|---|---|---|
| Thunderbit | $9/月起,提供免费档 | AI 网页爬虫、自动识别并格式化数据、支持多种格式、一键导出、界面友好 | 无需写代码、AI 辅助强、可与 Google Sheets 等应用联动 | 超大规模抓取可能偏慢,部分高级功能需付费 |
| Browse AI | $48.75/月起,提供免费档 | 无代码操作、实时监控、批量抓取、流程串联 | 易上手,可对接 Google Sheets 与 Zapier | 复杂页面需要额外配置,批量抓取可能出现超时 |
| Bardeen AI | $60/月起,提供免费档 | 无代码自动化、集成 130+ 应用、MagicBox 将任务描述转为流程 | 集成丰富,适合企业扩展 | 新手学习曲线较陡,前期配置耗时 |
| Web Scraper | 本地免费,云端 $50/月起 | 可视化搭建任务、支持动态站点(AJAX/JavaScript)、云端抓取 | 动态站点表现不错 | 想用好需要一定技术基础 |
| Octoparse | $119/月起,提供免费档 | 无代码抓取、自动识别元素、云端定时任务、常见网站模板库 | 动态站能力强,能应对限制 | 复杂站点需要时间学习与调试 |
| Diffbot | $299/月起 | 数据抽取 API、无规则 API、NLP 处理非结构化文本、知识图谱 | AI 抽取能力强、API 集成空间大、适合大规模抓取 | 非技术用户上手门槛较高,配置与接入需要时间 |
AI 时代最值得入手的网页爬虫
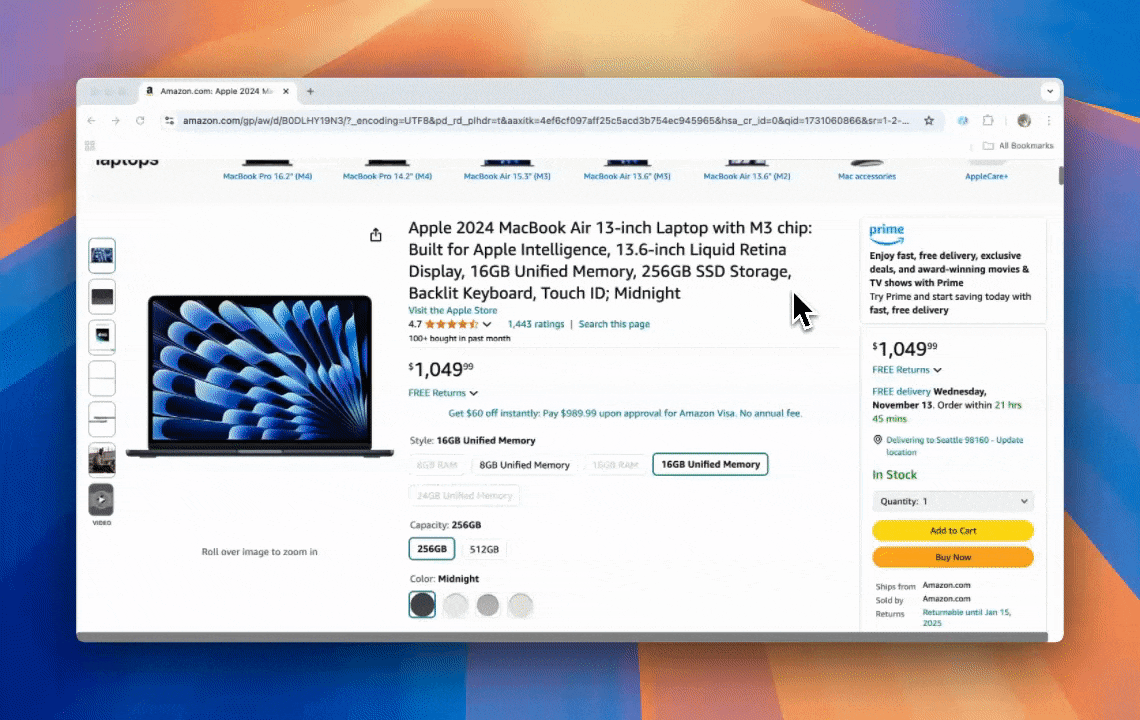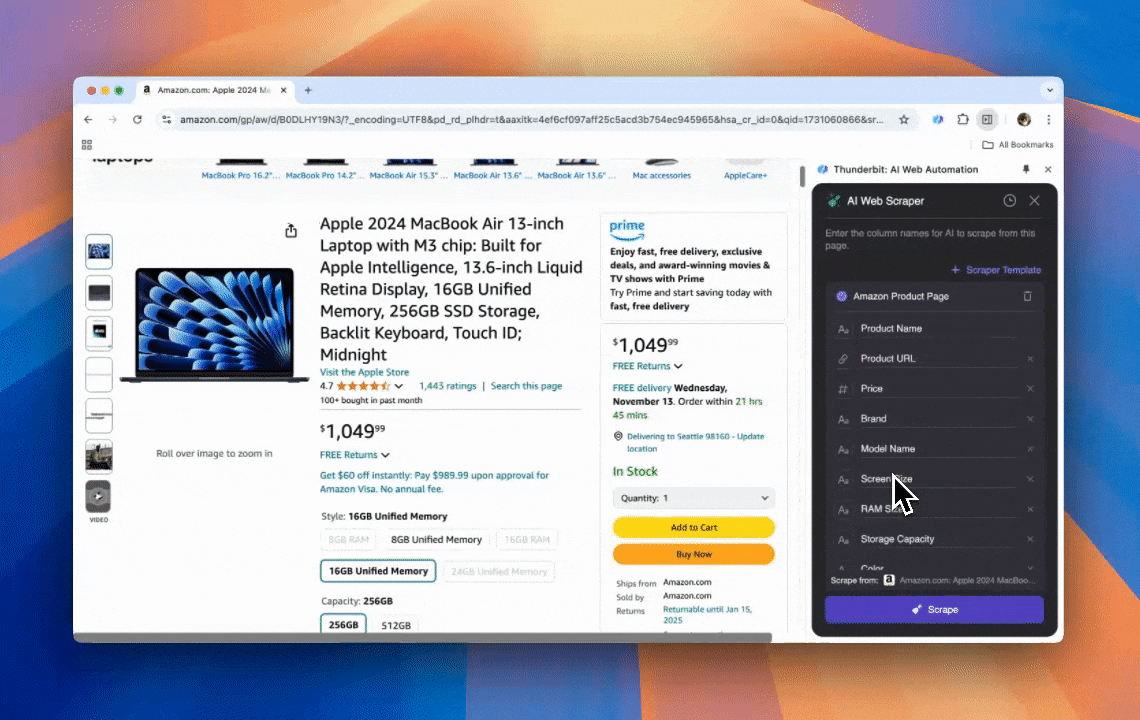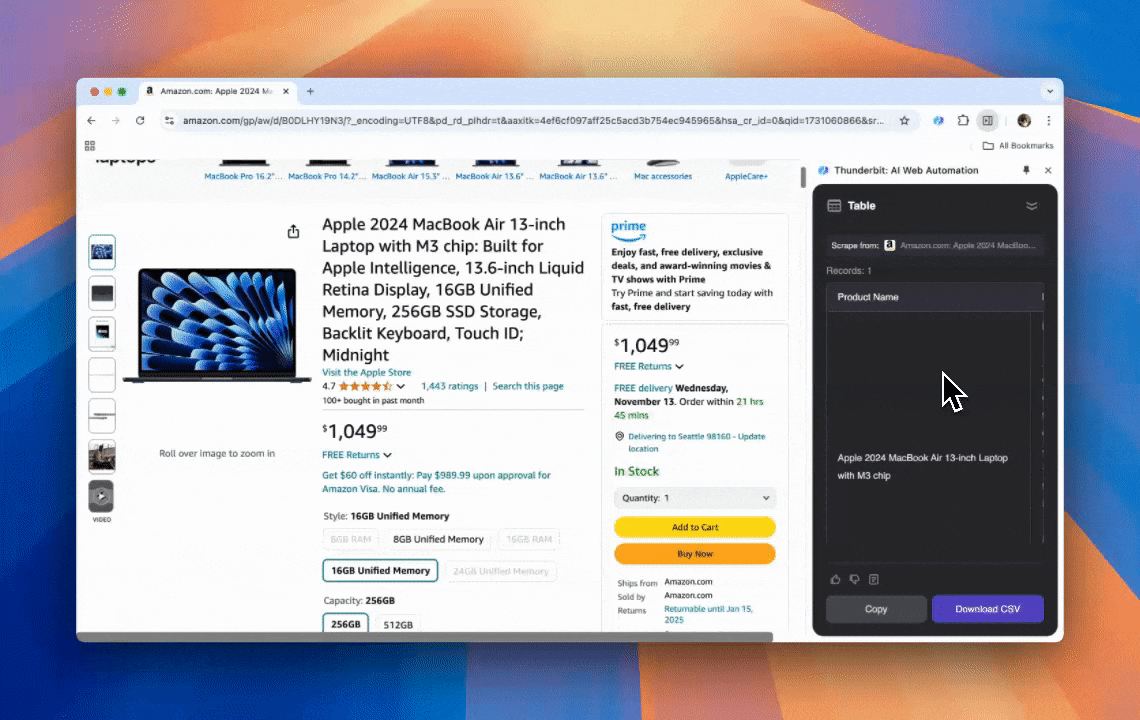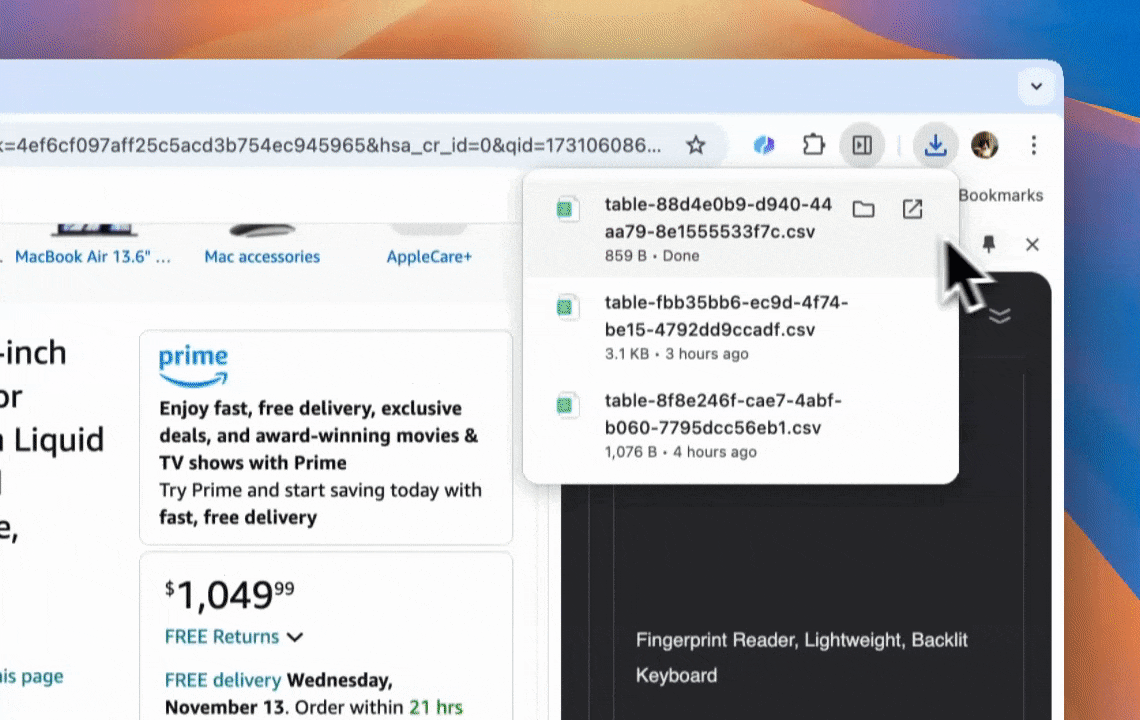
Thunderbit 是一款又强又好用的 AI 网页自动化工具,就算你完全不会写代码,也能把网页数据抓出来并整理得明明白白。通过它的 ,Thunderbit 的 把整个抓取流程做得非常“傻瓜”:你不用一个个点网页元素,也不用针对不同页面结构分别搭规则,就能很快拿到数据。
核心功能
- AI 驱动的高适配性:Thunderbit 的 AI 网页爬虫可自动识别并格式化网页数据,无需使用 CSS selector。
- 最省心的抓取体验:在目标页面点击“AI suggest column”,再点“Scrape”即可完成抓取。
- 支持多种数据形态:可抓取 URL、图片等,并以多种格式展示结果。
- 自动化数据处理:AI 可在抓取过程中同步完成重排格式、总结、分类、翻译等处理,输出你需要的结构。
- 一键导出:可一键导出到 Google Sheets、Airtable 或 Notion,数据管理更轻松。
- 界面友好:交互直观,适合不同水平的用户。
价格
Thunderbit 提供分级套餐:$9/月起(5,000 credits),最高到 $199(240,000 credits)。选择年付方案时,credits 会一次性发放。
优点:
- AI 能力强,抽取与处理数据更省事。
- 无需写代码,任何水平都能用。
- 非常适合目录站、购物网站等轻量抓取。
- 与常用应用的导出集成做得很好。
缺点:
- 超大规模抓取为了保证准确性可能需要更多时间。
- 部分高级功能需要付费订阅。
想了解更多? 你可以先 ,或在 YouTube 上看看 Thunderbit 的教程,了解 。
最适合数据监控与批量抓取的网页爬虫
Browse AI
Browse AI 是一款比较成熟的无代码数据抓取工具,主打“不会写代码也能抓取和监控数据”。它也有一些 AI 功能,但整体还没到“全 AI 抓取”的程度。不过对新手来说,它确实能让你更快进入状态。
核心功能
- 无代码操作:通过简单点击即可搭建自定义流程。
- 实时监控:用机器人跟踪网页变化,并推送更新信息。
- 批量数据抽取:单次可处理多达 50,000 条数据。
- 流程串联:可把多个 bot 连接起来,完成更复杂的数据处理。
价格
$48.75/月起,包含 2,000 credits;也提供免费档,每月 50 credits,可用于体验基础功能。
优点:
- 支持与 Google Sheets、Zapier 集成。
- 预置 bot 能覆盖不少常见抓取需求。
缺点:
- 面对复杂页面可能需要额外配置。
- 批量抓取速度不稳定,偶尔会出现超时。
最适合工作流集成的网页爬虫
Bardeen AI
Bardeen AI 是一款无代码自动化工具,它的核心价值是把各种应用串起来,让你的工作流更顺滑。它会用 AI 来生成自定义自动化,但在网页抓取的自适应能力上,还是不如真正的 AI 抓取工具那么“聪明”。
核心功能
- 无代码自动化:点击即可搭建流程。
- MagicBox:用自然语言描述你要做的事,Bardeen AI 会把它转成可执行的工作流。
- 丰富的集成:可对接 130+ 应用,包括 Google Sheets、Slack、LinkedIn 等。
价格
$60/月起,包含 1,500 credits(大约对应 1,500 行数据)。免费档每月提供 100 credits,用于体验基础功能。
优点:
- 集成范围广,能覆盖多种业务场景。
- 可扩展性强,适合不同规模团队。
缺点:
- 新用户需要时间熟悉平台。
- 初次搭建流程可能比较耗时。
更适合有经验用户的可视化网页爬虫
Web Scraper
没看错,这个工具就叫 “Web Scraper”。它是 Chrome 和 Firefox 上很火的浏览器扩展,用可视化方式创建抓取任务,让你不写代码也能抓数据。不过如果你想真正用得顺手,可能得花几天把教程看完再练一练。如果你更想“少动脑、快出结果”,那 AI 网页爬虫会更适合。
核心功能
- 可视化搭建:通过点击网页元素来配置抓取任务。
- 支持动态网站:可处理 AJAX 与 JavaScript 驱动的动态页面。
- 云端抓取:通过 Web Scraper Cloud 可定时运行任务,周期性抓取。
价格
本地使用免费;云端功能 $50/月起。
优点:
- 动态网站抓取能力不错。
- 本地使用免费。
缺点:
- 想配置得更稳更准,需要一定技术理解。
- 网站变动后往往需要重新测试与调整。
最擅长规避封 IP 与反爬检测的网页爬虫
Octoparse
Octoparse 更偏向技术型用户:它在不写代码的前提下,也能采集和监控指定网页数据,尤其适合大规模数据需求。Octoparse 不靠你的浏览器跑任务,而是用云服务器执行抓取,所以在绕过封 IP、应对部分网站的机器人检测方面,通常会给到更多手段和空间。
核心功能
- 无代码操作:无需编程即可创建抓取任务,适合不同技术水平的用户。
- 智能自动识别:自动识别页面可抓取的数据元素,减少配置成本。
- 云端抓取:支持 7×24 小时云端运行,并可设置定时任务。
- 模板库丰富:提供数百个预置模板,常见网站可快速上手,无需复杂配置。
价格
$119/月起,包含 100 个任务;也提供免费档,每月 10 个任务,用于测试基础能力。
优点:
- 功能强,适配动态站点的能力较好。
- 对抓取限制与动态内容问题有较完整的应对方案。
缺点:
- 网站结构越复杂,配置与调试越耗时。
- 新用户需要一定学习成本。
最适合高级 AI 数据抽取 API 的网页爬虫
Diffbot
Diffbot 更偏企业级,它用 AI 把非结构化网页内容转成结构化数据。它的 API 和知识图谱能力很强,能帮你从网页里抽取、分析并管理信息,适用于很多行业和不同应用场景。
核心功能
- 数据抽取 API:提供“无规则”抽取 API,你只要给 URL,就能自动抽取数据,不必为每个网站单独写规则。
- 自然语言处理 API:从非结构化文本中抽取实体、关系与情绪等结构化信息,便于构建自己的知识图谱。
- 知识图谱:Diffbot 拥有规模很大的知识图谱之一,覆盖大量实体数据,包括个人与组织信息。
价格
$299/月起,包含 250,000 credits(约等于 250,000 次基于 API 的网页抽取)。
优点:
- 无规则抽取能力强,适配性高。
- API 集成空间大,便于接入现有系统。
- 支持大规模抓取,适合企业级应用。
缺点:
- 非技术用户需要一定学习与上手时间。
- 需要编写程序调用 API 才能使用。
网页爬虫能用来做什么?
如果你刚开始接触网页抓取,下面这些是最常见、也最容易上手的用途:抓取 Amazon 商品列表、从 Zillow 获取房产数据、从 Google Maps 收集商家信息等。但这只是起点——你也可以用 Thunderbit 的 从几乎任何网站采集数据,把日常工作流里那些重复劳动自动化掉,省下大把时间。不管你是做研究、盯价格,还是搭数据库,网页抓取都能让互联网数据真正变成你的生产力。
常见问题(FAQs)
-
网页抓取合法吗?
一般来说,网页抓取本身不一定违法,但你需要遵守网站的服务条款,并结合你访问的数据类型来判断风险。建议先看清相关政策,同时确保符合当地法律与合规要求。
-
使用网页爬虫工具需要编程能力吗?
本文提到的大多数工具都不要求编程能力;但像 Octoparse、Web Scraper 这类工具,如果你对网页结构有基础理解,再加一点“工程化思维”,通常会用得更顺、更稳。
-
有没有免费的网页爬虫工具?
有。比如 BeautifulSoup、Scrapy、Web Scraper 等都能免费用;另外不少商业工具也会提供功能受限的免费方案。
-
网页抓取常见难点有哪些?
常见挑战包括:动态内容处理、验证码(CAPTCHA)、封 IP、以及复杂的 HTML 结构。用更高级的工具和技巧,通常都能把这些问题压下去。
延伸阅读:
-
用 AI 轻松搞定工作。