

网络上到处都是数据,而到了 2026 年,把这些杂乱信息转化为商业价值的竞争,比以往任何时候都更激烈。我看到销售、电商和运营团队通过自动化那些原本要花上好几个小时、枯燥又机械的复制粘贴任务,彻底改造了工作流程。现在,如果你还没用网页数据抓取软件,你不只是落后了——你很可能还困在表格地狱里,而你的竞争对手已经在喝第二杯咖啡了。
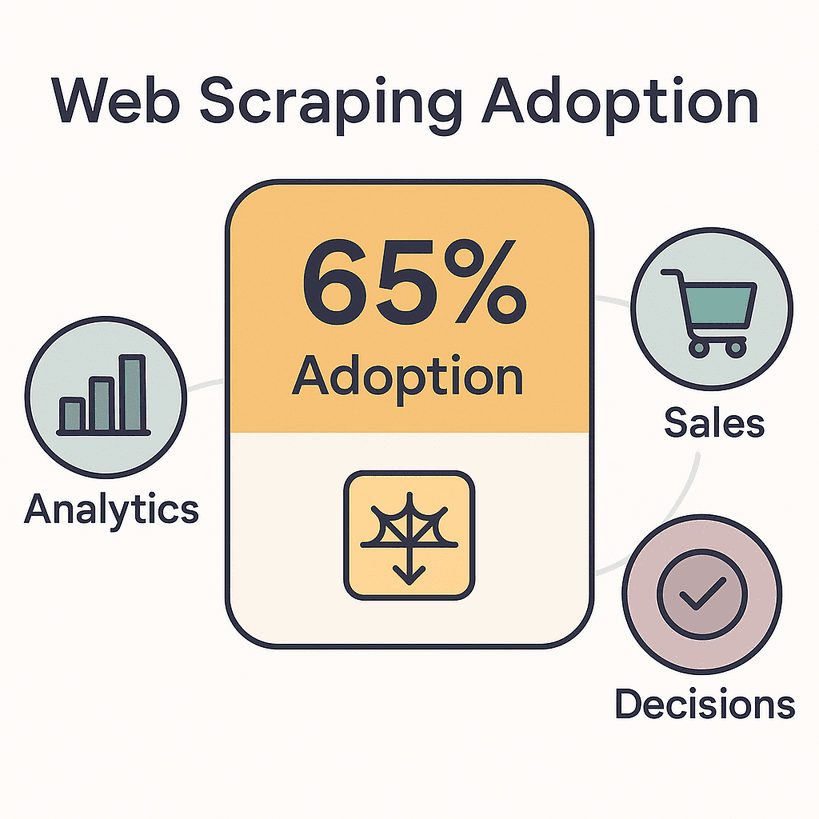
现实情况是:65% 的企业现在都在使用网页爬虫工具 来支持分析、销售和决策。全球网页数据提取市场的规模已经超过 10 亿美元,并且预计到 2030 年将翻一番。销售人员有多达70% 的时间 花在数据录入和调研这类非销售任务上。这意味着大量时间本可以真正用来促成交易——或者至少享受一顿午休。

那么,2026 年最好的网页数据抓取软件是什么?我深入研究了五款顶尖工具,它们正在改变不同规模、不同技术背景团队的工作方式。无论你是不懂代码、只想点几下就开始,还是开发者、想要极致灵活性,这里都能找到适合你的选择。
什么才算最好的网页数据抓取软件?
什么是数据抓取,以及如何在 2025 年完成它 Get Started Free
说实话:不是所有网页爬虫都一样。2026 年最好的网页数据抓取软件,关键在于让数据提取变得更快、更可靠、人人都能用——而不只是让会 Python 的人受益。
下面是我重点关注的标准(也正是企业用户最在意的点):
- 易用性: 非技术用户能否在几分钟内完成抓取配置?对大多数团队来说,无代码和 AI 驱动界面几乎是必备。
- 数据源灵活性: 能否处理网页、PDF、图片,以及动态内容(比如无限滚动或 AJAX)?支持的数据源越多越好。
- 自动化与定时: 能否设置重复抓取、处理分页,并自动进入子页面?自动化决定了你是“设置完就不用管”,还是“设置完还得一直盯着”。
- 集成与导出: 能否直接导出到 Excel、Google Sheets、Notion、Airtable,或者通过 API 导出?越少手工折腾,团队越省心。
- 所需技术能力: 真的是无代码,还是你得先补补正则表达式?最好的工具应该同时照顾非技术用户和高级用户。
- 可扩展性: 能否轻松抓取几百页甚至几千页而不出问题?
- 支持与社区: 是否有完善文档、响应及时的支持,以及活跃的用户社区?
这些标准不只是锦上添花,它们决定了一款工具是帮你省下几小时,还是让你多花几天。到了 2026 年,几乎一半的互联网流量来自机器人,拥有合适的爬虫本身就是竞争优势。
接下来,我们直接看前五名。
2026 年五款最佳网页数据抓取软件
- Thunderbit 适合无代码、AI 驱动、多数据源抓取
- Import.io 适合企业级、集成式数据管道
- Scrapy 适合开源、面向开发者的灵活方案
- Octoparse 适合带定时任务的可视化无代码抓取
- ParseHub 适合日常任务中易上手的数据提取
1. Thunderbit:最简单的 AI 网页数据抓取软件
用 AI 从任何网站抓取数据 Get Started Free
Thunderbit 是我最推荐给想要在不写一行代码的情况下抓取网页数据的人。没错,我确实有点偏爱它——因为我参与了它的打造。但听我说完:Thunderbit 是专门为想要结果、而不是头疼问题的商业用户设计的。
Thunderbit 为什么这么突出?
- AI 智能推荐字段: 只要点击“AI 智能推荐字段”,Thunderbit 的 AI 就会读取页面、推荐要提取的内容,并帮你完成爬虫设置。无需选择器、无需模板、无需折腾。
- 多数据源抓取: 不只抓网页,还能抓 PDF 和图片。Thunderbit 可以提取文本、链接、邮箱、电话号码和图片——两次点击就能搞定。
- 子页面与分页自动化: 需要抓取每个产品页或个人资料页的详细信息?Thunderbit 的子页面抓取会自动跟随链接、提取额外信息,并合并到你的表格里。它处理无限滚动和分页也同样稳。
- 批量与定时抓取: 粘贴一批 URL,设置重复任务,然后让 Thunderbit 去干重活——无论是每天监控价格,还是每周更新线索。
- 即时导出: 可直接导出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON。再也不用长时间复制粘贴了。
- 自定义 AI 提示词: 想在抓取时顺便分类、翻译或打标签?添加一条自定义指令,Thunderbit 的 AI 就会处理。
- 云端或浏览器模式: 可以在云端运行抓取任务以获得更快速度(一次最多 50 页),也可以在本地处理需要登录的网站。
Thunderbit 受到全球超过30,000 名用户的信赖,用户从销售团队到房产经纪人,再到独立电商商家都有。免费版最多可抓取 6 个页面(试用加成后可达 10 个),而且按需付费——每输出一行只消耗 1 个积分。
我为什么喜欢它: 我见过的工具里,只有它能让非技术用户在不到五分钟内,从“我需要这些数据”变成“这是我的表格”。界面真的很友好(我们在这点上花了很多心思),而且 AI 能适应网站变化,所以你不会总是在修坏掉的爬虫。
最适合: 销售、电商、运营,以及任何想要无代码、AI 驱动抓取且无需维护的人。
更多指南请查看 Thunderbit 博客。
2. Import.io:企业级网页数据抓取与集成
Import.io 是面向企业的重量级选手,适合那些既需要大规模网页数据、又需要把数据直接接入业务系统的团队。
Import.io 的优势是什么?
- 企业级数据管道: Import.io 不只是一个爬虫,更是一个完整的网页数据集成平台。你可以把它理解为带持续自动数据流的“数据即服务”。
- 自我修复 AI: 如果网站发生变化,Import.io 的 AI 会尝试自动重新映射字段,这样你的数据管道就不容易一夜之间失效。
- 强大的自动化: 可按小时、按天或自定义间隔安排抓取。如果出现问题,或者数据看起来异常,还能收到提醒。
- 交互式流程: 可处理需要登录、表单或多步导航的网站。Import.io 能记录并回放复杂操作流程。
- 合规与治理: 自动识别并遮蔽个人身份信息(PII),同时保留审计日志——这对受监管行业尤其重要。
- API 与集成: 可通过 API 将数据直接流向 Google Sheets、Excel、Tableau、Power BI、数据库,或你自己的应用。
Import.io 受到联合利华、沃尔沃和 RedHat 等品牌信赖。它常用于跨数千个电商网站的价格监控、市场情报,或为 AI/ML 模型提供最新网页数据。
价格: Import.io 属于高端方案,自助服务套餐起价约为每月 299 美元。它提供免费试用,但没有长期免费版。如果网页数据是你的核心任务,这个投入是值得的。
最适合: 需要可靠性、规模、合规性和深度集成的企业及数据驱动型组织。
3. Scrapy:面向开发者的开源网页爬虫框架
Scrapy 是开发者的开源利器,适合那些想要极致灵活性和控制权的人。如果你(或你的团队)会用 Python 写代码,Scrapy 就是网页爬虫界的瑞士军刀。
开发者为什么喜欢 Scrapy:
- 高度可定制: 你可以编写蜘蛛程序(脚本)来按你想要的方式抓取、解析和处理数据。多页面流程、自定义逻辑和复杂数据清洗都能轻松处理。
- 异步且高效: Scrapy 的架构就是为速度和规模而生——可以每分钟抓取数百页,或借助分布式爬虫抓取数百万页。
- 可扩展: 拥有庞大的插件和中间件生态,可用于代理、无头浏览器(Splash/Playwright)以及各种集成。
- 免费且开源: 没有许可费用。你可以在自己的硬件或云端运行,并按需扩展。
- 社区支持: GitHub 上有超过 55,000 个 star,用户群体非常庞大。如果你遇到问题,十有八九别人已经解决过。
注意事项: Scrapy 需要 Python 技能和命令行使用习惯。它没有可点击的图形界面——这是一个以代码为先的工具。但如果是定制项目、AI 训练数据或大规模抓取,它几乎无可替代。
最适合: 拥有内部开发团队、需要自定义数据管道,或有大规模复杂抓取需求的组织。
4. Octoparse:让可视化网页数据抓取变简单
Octoparse 是很多非技术用户的最爱,因为它既强大,又有可视化、点选式界面。
Octoparse 为什么受欢迎:
- 可视化流程构建器: 在内置浏览器里点击元素,Octoparse 会自动识别模式。无需编码,点一点就能提取。
- 支持动态内容: 可抓取 AJAX、无限滚动以及有登录保护的网站。还能模拟点击、滚动和表单提交。
- 云端抓取与定时任务: 在云端运行任务(更快、可并行),并为始终最新的数据设置重复任务。
- 预置模板: 针对 Amazon、Twitter、Zillow 等热门网站提供数百个模板,让你可以立刻开始抓取。
- 导出与 API: 可将结果下载为 CSV、Excel、JSON,或通过 API 拉取数据。也能与 Google Sheets 或数据库集成。
Octoparse 经常被形容为“即使是初学者也能轻松上手”。免费版限制较多,但付费套餐(起价约每月 83 美元)可解锁云端运行、定时任务和更快速度。
最适合: 非技术用户、营销人员、研究人员,以及需要定期自动收集数据但不想写代码的小团队。
5. ParseHub:适合日常任务的友好型数据提取工具
ParseHub 也是一款很受欢迎的无代码工具,特别适合想要自动化日常数据任务的小企业和自由职业者。
ParseHub 的亮点:
- 点选式操作: 在浏览器视图中点击元素即可选择数据。可视化构建工作流——无需编码。
- 支持 JS 与动态网站: 可抓取 JavaScript 内容丰富的页面、无限滚动以及多步导航。
- 云端与本地运行: 你可以在电脑上或云端运行抓取任务。还能设置重复任务,并在更高级套餐中通过 API 访问结果。
- 导出选项: 可将数据下载为 CSV、Excel 或 JSON。也支持 API 自动化。
- 跨平台: 支持 Windows、Mac 和 Linux。
ParseHub 的免费计划有一定限制(每次运行 200 页),但付费套餐(起价约每月 189 美元)能解锁更多性能、速度和 API 访问权限。
最适合: 需要可靠、可视化工具的小企业、自由职业者,以及有简单抓取需求的团队。
对比表:一览最佳网页数据抓取软件
| 工具 | 易用性 | 数据源 | 自动化与定时 | 集成与导出 | 技术要求 | 价格 |
|---|---|---|---|---|---|---|
| Thunderbit | 无代码,AI 驱动 | 网页、PDF、图片 | 子页面、分页、定时、批量 | Excel、Sheets、Notion、Airtable、CSV、JSON | 无 | 免费增值(按行付费) |
| Import.io | 点选式界面 | 网页(静态/动态、登录) | 自我修复、定时、提醒 | API、BI 工具、Sheets、Excel、数据库 | 低到中等 | 每月 299 美元起 |
| Scrapy | 需要编码 | 网页、API、(通过插件支持 JS) | 通过代码实现完全自动化 | 任意(通过代码) | Python 开发者 | 免费(开源) |
| Octoparse | 可视化,无代码 | 网页(动态、登录) | 云端定时、模板 | CSV、Excel、JSON、API | 无 | 每月 83 美元起 |
| ParseHub | 可视化,无代码 | 网页(JS、动态) | 云端/本地、定时 | CSV、Excel、JSON、API | 无 | 每月 189 美元起 |
如何为你的业务选择最佳网页数据抓取软件
不确定该选哪款工具?这是我的简明指南:
- 非技术用户,想快速出结果: 选 Thunderbit 或 Octoparse。Thunderbit 在即时、AI 驱动抓取和多数据源支持(网页、PDF、图片)方面几乎无可匹敌。Octoparse 则非常适合可视化、定时抓取。
- 企业集成、合规与规模: Import.io 是最稳妥的选择。它专为持续、可靠的数据管道和深度集成而打造。
- 开发者、自定义项目或大规模抓取: Scrapy 是最佳路线。你需要会 Python,但可以获得几乎无限的灵活性。
- 小企业、自由职业者或日常任务: ParseHub 是一个扎实、易用的点选式抓取工具,适合中等程度的自动化需求。
挑选工具时的小建议:
- 让工具与你团队的技术能力和数据需求匹配。
- 考虑你要抓取的网站有多复杂(动态内容?登录?)。
- 想清楚你会怎么用这些数据——是需要直接导出到 Sheets,还是要深度 API 集成?
- 先用免费试用或免费增值方案测试真实任务。
- 不要低估优质支持和文档的价值。
结语:用最好的网页数据抓取软件释放商业价值
在 2026 年,网页数据就是更聪明商业决策的燃料。合适的网页数据抓取软件可以帮你节省大量时间、减少错误,并为团队带来真正优势——无论你是在构建线索名单、监控竞争对手,还是为分析引擎提供数据。
总结一下:
- Thunderbit 是最简单、AI 驱动、适合商业用户的无代码爬虫。
- Import.io 是面向企业的方案,适合持续、集成式的数据管道。
- Scrapy 是给想要完全掌控权的开发者准备的开源工具。
- Octoparse 和 ParseHub 让人人都能使用可视化、无代码抓取。
这些工具大多都提供免费试用或免费增值方案——所以不妨亲自试试。把枯燥的工作自动化,释放新的洞察,让你的团队专注于真正重要的事情。
祝你抓取顺利——也愿你的数据始终新鲜、结构清晰,并随时可用。
常见问题
1. 网页数据抓取软件是用来做什么的?
网页数据抓取软件会自动从网站、PDF 和图片中提取信息。常用于线索生成、价格监控、市场研究、内容聚合等。
2. 网页数据抓取合法吗?
当你抓取的是公开可访问的数据,并遵守网站服务条款和隐私法律时,网页抓取是合法的。请始终查看网站政策,并负责任地使用数据。
3. 使用网页数据抓取软件一定要会编程吗?
不一定!像 Thunderbit、Octoparse 和 ParseHub 这类工具就是为非程序员设计的。对于更复杂或定制化的项目,可能就需要像 Scrapy 这样的开发者工具。
4. 如何把抓取的数据导出到 Excel 或 Google Sheets?
大多数现代爬虫(Thunderbit、Octoparse、ParseHub)都支持一键导出到 Excel、Google Sheets、CSV,甚至可以直接与 Notion 和 Airtable 集成。
5. 网页数据抓取软件能处理动态网站或登录页面吗?
可以——像 Import.io、Octoparse 和 ParseHub 这类顶级工具都能处理动态内容(AJAX、无限滚动)和需要登录保护的网站。Thunderbit 也支持抓取动态页面和子页面。
想看看现代网页抓取是什么样子?下载 Thunderbit 的 Chrome 扩展 或浏览 Thunderbit 博客,获取更多技巧、教程,以及关于 AI 驱动数据提取世界的深度解析。
试用 AI 网页爬虫 Get Started Free




