

Está a acontecer uma revolução silenciosa em escritórios de todo o mundo — e não tem nada a ver com mesas de pingue-pongue ou kombucha na torneira. Trata-se da ascensão da “extração web fácil”: a capacidade de qualquer pessoa, e não só de programadores, obter dados úteis da web em minutos, e não em dias. Se já ficou a olhar para um site, a pensar como seria bom puxar aqueles nomes, preços ou e-mails e levá-los diretamente para uma folha de cálculo, não está sozinho. Na verdade, já falei com equipas de vendas, profissionais de marketing e equipas de operações que dizem exatamente o mesmo: “Porque é que isto continua a ser tão difícil?”
A verdade é que a procura por métodos simples de web scraping está a disparar. De acordo com o State of AI 2025 da McKinsey, 71% das organizações já usam IA generativa em pelo menos uma função de negócio, acima dos 65% no início de 2024, e a extração de dados da web está rapidamente a tornar-se uma das aplicações mais procuradas. O mercado de web scraping deverá atingir US$ 1,17 mil milhões em 2026 e US$ 2,23 mil milhões até 2031, e os utilizadores de negócio — especialmente os sem formação técnica — estão a liderar a procura por ferramentas que tornem a extração de dados tão fácil como copiar e colar. Mas o que quer realmente dizer “extração web fácil” e como pode simplificar o seu fluxo de trabalho? Vamos destrinçar isso.
Experimente a extração web fácil com o Thunderbit (Grátis)
Extração web fácil para utilizadores sem conhecimentos técnicos: sem código, sem dor de cabeça
Vamos começar pelo básico: o que é “extração web fácil”? Em essência, é transformar a web caótica e em constante mudança em tabelas limpas e estruturadas — sem escrever uma única linha de código. Para utilizadores empresariais sem perfil técnico, isto muda tudo. Chega de pedir ajuda ao TI, de lutar com scripts em Python e de desistir quando um site muda o layout de um dia para o outro.
Porque é que isto é tão importante agora? A web está mais dinâmica do que nunca. Os sites usam scroll infinito, pop-ups e JavaScript complexo que rebenta com os scrapers tradicionais por todo o lado. Ao mesmo tempo, a pressão sobre as equipas de negócio para entregarem insights rapidamente nunca foi tão alta. No retalho e ecommerce, 98% das organizações dizem que os dados públicos da web são cruciais ou muito importantes para as suas operações, e mais de metade usa-os diariamente.
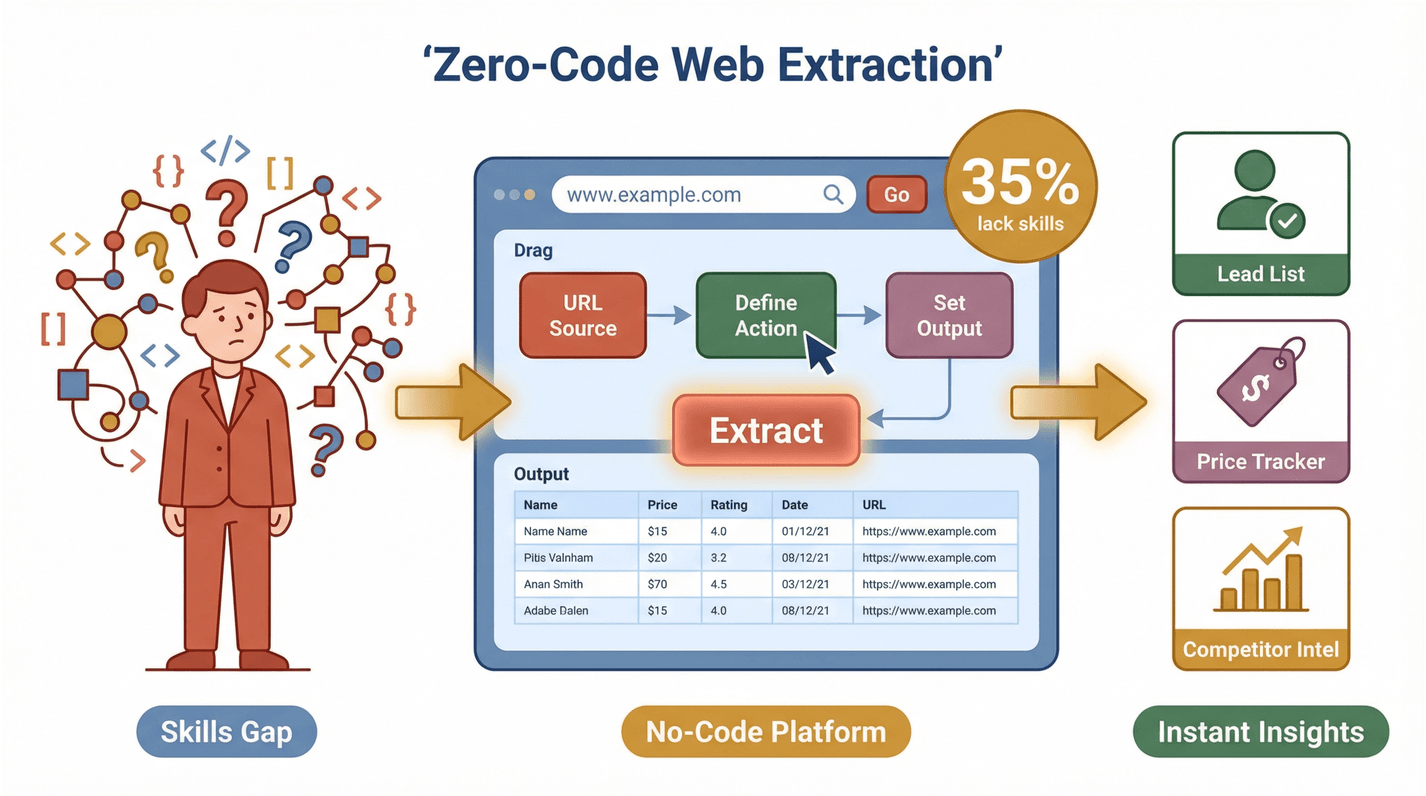
Mas aqui está o ponto-chave: a maioria destas equipas não é técnica. Um estudo recente mostrou que 35% das organizações não têm as competências certas para extração de dados da web, e 33% não têm as ferramentas certas. Isto abre uma enorme oportunidade para soluções sem código. Quando qualquer pessoa consegue extrair e usar dados da web, desbloqueia-se um novo nível de produtividade — seja para criar uma lista de leads, monitorizar concorrentes ou acompanhar preços.
O movimento no-code/low-code: porque é importante
A ascensão das ferramentas no-code e low-code tem muito que ver com democratizar a tecnologia. Não é só mais uma moda do Vale do Silício; é uma mudança real na forma como o trabalho é feito. No universo do web scraping, isso significa:
- Sem necessidade de programar: qualquer pessoa pode extrair dados, e não apenas engenheiros.
- Velocidade: obtenha resultados em minutos, e não em dias.
- Flexibilidade: adapte-se de imediato a novos sites e a novas necessidades de dados.
- Menos erros: a automação reduz falhas de copiar e colar.
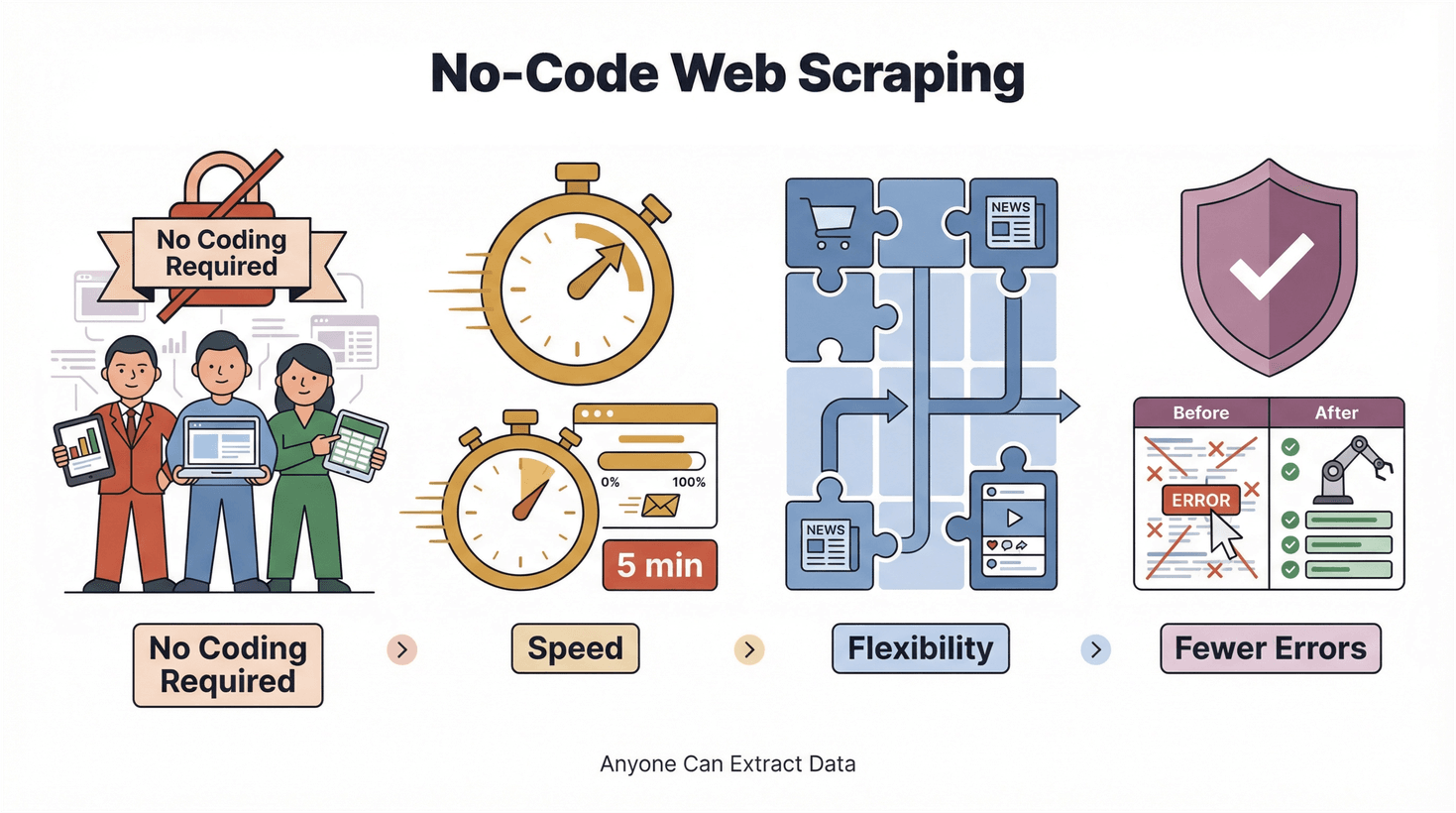
E o melhor? Não precisa de se tornar um guru da tecnologia para participar.
Porque é que as ferramentas tradicionais de web scraping são tão frustrantes
Sejamos honestos: as ferramentas tradicionais de web scraping podem parecer feitas por programadores e para programadores, e não para utilizadores de negócio. Já vi isso acontecer de perto — as equipas entusiasmam-se com um novo projeto, mas batem numa parede quando a ferramenta pede seletores CSS, XPath ou expressões regulares. Depois vêm os olhos vidrados e os e-mails do género “talvez no próximo trimestre”.
O que costuma correr mal:
- É preciso programar: a maioria das ferramentas legadas espera que escreva scripts ou configure modelos complexos.
- Configuração dolorosa: é preciso mapear cada campo, lidar com login e configurar proxies para evitar bloqueios.
- Lógica frágil: os sites mudam de layout e, de repente, o seu scraper avaria. Aí passa a depurar código em vez de fazer o seu trabalho.
- Manutenção pesada: sempre que um site é atualizado, volta à estaca zero.
Não admira que as mesmas equipas que referem falta de competências também digam que lhes faltam ferramentas — a pesquisa de 2024 da Bright Data mostrou que 35% das organizações não têm as competências certas e 33% não têm as ferramentas certas para trabalhar com dados públicos da web. Até equipas sofisticadas têm dificuldade em acompanhar bloqueios de IP, conteúdo dinâmico e CAPTCHAs, entre outros obstáculos.
Entretanto, os utilizadores de negócio só querem uma forma simples e fiável de colocar dados em folhas de cálculo ou CRMs. É aqui que entram a extração web fácil e os métodos simples de web scraping.
Como o Thunderbit torna a extração web fácil possível
Extraia dados de qualquer site com IA Get Started Free
É aqui que fico entusiasmado — porque este é exatamente o problema que nos propusemos resolver no Thunderbit. A nossa missão é tornar o web scraping tão simples que qualquer pessoa o consiga usar, independentemente do nível técnico.
O Thunderbit é uma Extensão Chrome de AI Web Scraper que transforma a extração web num processo de dois cliques. Funciona assim:
- Descreva o que quer: use linguagem natural para dizer ao Thunderbit de que dados precisa. Por exemplo: “Extraia todos os nomes e preços dos produtos desta página.”
- Clique em “AI Suggest Fields”: a IA do Thunderbit lê a página e sugere as melhores colunas para extrair — como “Nome”, “Preço”, “E-mail” ou “Imagem”.
- Clique em “Scrape”: o Thunderbit trata do resto, incluindo paginação, subpáginas e até conteúdo protegido por login, se necessário.
Pronto. Sem código, sem modelos, sem dores de cabeça na configuração. A interface foi pensada para utilizadores de negócio — vendas, marketing, ecommerce, imobiliário — que só querem resultados.
O fluxo de trabalho orientado por IA do Thunderbit: mais inteligência, menos esforço
A verdadeira magia está na IA. O Thunderbit não se limita a adivinhar o que quer — lê a página, percebe o contexto e estrutura os dados automaticamente. Se quiser ir um pouco mais longe, pode adicionar instruções personalizadas a cada campo (como “categorize esta coluna” ou “traduza para inglês”), mas a maioria dos utilizadores só clica e avança.
Esta abordagem orientada por IA significa:
- Menos erros: a IA adapta-se a diferentes layouts, por isso obtém resultados consistentes mesmo quando os sites mudam.
- Configuração mais rápida: sem necessidade de criar modelos ou escrever scripts.
- Dados acionáveis: o Thunderbit pode etiquetar, categorizar e até enriquecer os seus dados enquanto faz a extração.
Para se aprofundar, consulte a documentação do Thunderbit ou o nosso post no blog sobre extração automatizada de dados. Também pode explorar mais guias no Blog do Thunderbit, como Como Extrair Qualquer Site Usando IA e O que é Data Scraping e Como Fazer Isso em 2025.
Recursos exclusivos do Thunderbit para métodos simples de web scraping
O que distingue o Thunderbit não é só a IA — é todo o fluxo de trabalho, pensado para necessidades reais de negócio. Aqui estão alguns recursos de que os nossos utilizadores gostam particularmente:
- Paginação automática: o Thunderbit lida com sites com várias páginas e scroll infinito sem qualquer configuração.
- Extração de subpáginas: precisa de mais detalhes? O Thunderbit pode visitar cada subpágina (como detalhes de produtos ou perfis do LinkedIn) e enriquecer automaticamente o seu conjunto de dados.
- Exportação para qualquer lugar: envie os seus dados diretamente para Excel, Google Sheets, Airtable, Notion ou descarregue em CSV/JSON. Chega de maratonas de copiar e colar.
- Funciona em páginas com login: extraia dados de sites que exigem autenticação — o Thunderbit corre no seu navegador, por isso vê o que você vê.
- Rotulagem e categorização com IA: adicione instruções para classificar, etiquetar ou traduzir dados enquanto os extrai.
- Extração agendada: configure tarefas recorrentes para manter os seus dados atualizados — perfeito para monitorização de preços ou acompanhamento de leads.
E sim, tudo isto está disponível numa ferramenta de confiança para mais de 100.000 utilizadores em todo o mundo.
Paginação automática e extração de subpáginas
Um dos maiores pesadelos no web scraping é lidar com listas paginadas ou páginas de detalhe aninhadas. Com o Thunderbit, não precisa de se preocupar. A IA deteta a paginação (seja um botão “Seguinte” ou scroll infinito) e segue automaticamente os links para subpáginas. Isto significa que pode extrair centenas ou milhares de registos de uma só vez — sem cliques manuais.
Por exemplo, se estiver a extrair uma lista de produtos da Amazon, o Thunderbit pode capturar todos os produtos em várias páginas e depois entrar em cada página de produto para recolher avaliações, classificações ou informações do vendedor. É como ter um assistente incansável que nunca se cansa.
Exportação em vários formatos e integração com CRM
Os dados só servem se realmente conseguir usá-los. O Thunderbit permite exportar os resultados no formato de que a sua equipa precisar — Excel, Google Sheets, Airtable, Notion ou CSV/JSON. Também pode enviar os dados diretamente para o seu CRM ou para ferramentas de fluxo de trabalho, para que as equipas de vendas e operações tenham sempre as informações mais recentes.
Esta integração direta poupa imenso tempo. Chega de limpar exportações desorganizadas ou de reformatar colunas — a IA do Thunderbit trata de tudo.
Casos de uso reais para a extração web fácil
Então, onde é que a extração web fácil tem mais impacto? Aqui estão alguns cenários reais que vi entre utilizadores do Thunderbit:
Extração de leads para vendas
As equipas de vendas vivem e morrem pela qualidade das suas listas de leads. Com o Thunderbit, pode extrair informações de contacto do LinkedIn, Google Maps ou diretórios empresariais em minutos. Basta abrir a página, clicar em “AI Suggest Fields” e deixar o Thunderbit puxar nomes, e-mails, números de telefone e dados da empresa para uma folha de cálculo pronta a usar.
Um gestor de vendas disse-me que antes passava horas todas as semanas a copiar e colar leads. Agora, com o Thunderbit, constroem listas segmentadas numa fração do tempo — e a equipa pode concentrar-se em contactar clientes, e não em introduzir dados.
Ecommerce e monitorização de mercado
As equipas de ecommerce usam o Thunderbit para acompanhar SKUs, preços e avaliações da concorrência na Amazon, Shopify e noutras plataformas. Precisa de monitorizar alterações de preços ou lançamentos de novos produtos? Configure uma extração agendada e receba dados atualizados na sua folha de cálculo do Google todas as manhãs.
A extração de subpáginas do Thunderbit é especialmente útil aqui — pode recolher detalhes de produtos, imagens e até avaliações de clientes sem mexer uma palha.
Recolha de dados imobiliários
Os profissionais do setor imobiliário usam o Thunderbit para reunir anúncios de imóveis, preços e informações de agentes em sites como Zillow ou Realtor.com. A IA lida com a paginação e as subpáginas, por isso obtém uma visão completa e atualizada do mercado — perfeita para análises ou relatórios para clientes.
Um analista imobiliário partilhou que algo que antes levava uma tarde inteira agora leva apenas alguns cliques. Esse é o poder dos métodos simples de web scraping.
Comparando métodos tradicionais e métodos simples de web scraping
Vamos juntar tudo numa comparação lado a lado:
| Recurso | Scrapers Tradicionais | Extração Web Fácil (Thunderbit) |
|---|---|---|
| Necessita de programação | Sim (scripts, seletores) | Não (IA + linguagem natural) |
| Tempo de configuração | Elevado (modelos, configuração) | Baixo (2 cliques) |
| Manutenção | Frequente (quebra com alterações no site) | Mínima (a IA adapta-se) |
| Lida com paginação | Configuração manual | Automática |
| Extração de subpáginas | Lógica complexa | 1 clique |
| Formatos de exportação | Muitas vezes limitados | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Funciona em páginas com login | Às vezes (com configuração) | Sim (baseado no navegador) |
| Rotulagem/categorização de dados | Pós-processamento manual | Com IA, integrado |
| Agendamento/monitorização | Às vezes (avançado) | Sim (configuração fácil) |
A diferença é enorme. Com o Thunderbit, qualquer pessoa pode extrair, organizar e usar dados da web — sem precisar de competências técnicas.
Tendências futuras em extração web fácil e métodos simples de web scraping
Olhando para o futuro, o caminho da extração web fácil é promissor. A IA está cada vez mais inteligente, e a procura por ferramentas sem código está a crescer rapidamente. De acordo com o State of AI 2025 da McKinsey, 88% das organizações já usam IA regularmente em pelo menos uma função, acima dos 78% do ano anterior, e os sistemas agentivos — ferramentas de IA capazes de lidar com fluxos de trabalho web em várias etapas — estão em alta.
O que é que isto significa para os utilizadores de negócio? Mais poder, menos complicação. À medida que a IA continua a evoluir, vamos ver:
- Deteção de campos ainda mais inteligente: a IA vai compreender dados e relações mais complexas.
- Melhor integração: ligações diretas com mais ferramentas e plataformas de negócio.
- Confiabilidade melhorada: menos falhas, resultados mais consistentes, até em sites dinâmicos ou protegidos.
- Maior acessibilidade: a extração de dados da web tornar-se-á uma competência padrão para todos, e não só para quem é da área de tecnologia.
E sim, o Thunderbit está na linha da frente deste movimento.
Conclusão e principais aprendizagens
Veja os planos e créditos do Thunderbit Get Started Free
A web é a maior base de dados do mundo — mas, até há pouco tempo, só os programadores conseguiam explorá-la. Isso está a mudar rapidamente. Com a extração web fácil e os métodos simples de web scraping, qualquer pessoa pode transformar sites em dados acionáveis em minutos.
Aqui está o que aprendi — e o que espero que leve consigo:
- A extração web sem código veio para ficar: ferramentas como o Thunderbit tornam possível a qualquer pessoa recolher e usar dados da web — sem necessidade de competências técnicas.
- A IA é o ingrediente secreto: ao automatizar a seleção de campos, a paginação, a extração de subpáginas e a rotulagem de dados, os scrapers com IA poupam tempo e reduzem erros.
- O impacto no negócio é real: equipas de vendas, ecommerce e imobiliário já estão a ver ganhos de produtividade, dados mais atualizados e melhores decisões.
- O futuro é ainda mais promissor: à medida que a IA e as ferramentas no-code evoluem, a extração de dados da web tornar-se-á tão comum como enviar um e-mail.
Se está farto de copiar e colar manualmente, frustrado com scrapers avariados ou simplesmente curioso sobre o que é possível, experimente o Thunderbit. Pode descarregar a Extensão Chrome e começar a extrair dados gratuitamente — sem configuração, sem código, sem complicações.
E, se quiser ir mais fundo, consulte o Blog do Thunderbit para mais guias, dicas e exemplos reais.
Perguntas frequentes
1. O que é “extração web fácil” e para quem serve?
Extração web fácil refere-se a métodos de web scraping sem código e com IA que permitem a qualquer pessoa — especialmente utilizadores empresariais sem perfil técnico — extrair dados estruturados de sites de forma rápida e simples. É ideal para equipas de vendas, marketing, ecommerce e operações que precisam de dados acionáveis sem dores de cabeça técnicas.
2. Em que é que o Thunderbit difere das ferramentas tradicionais de web scraping?
O Thunderbit usa IA para automatizar a seleção de campos, a paginação e a extração de subpáginas. Ao contrário dos scrapers tradicionais, que exigem código ou modelos complexos, o Thunderbit permite descrever as suas necessidades em linguagem simples e extrair dados com apenas dois cliques.
3. O Thunderbit lida com sites dinâmicos ou com várias páginas?
Sim. O Thunderbit deteta e trata automaticamente a paginação — incluindo scroll infinito — e pode seguir links para subpáginas para uma extração de dados mais profunda, tudo com configuração mínima.
4. Que opções de exportação o Thunderbit oferece?
O Thunderbit permite exportar dados diretamente para Excel, Google Sheets, Airtable, Notion, CSV ou JSON. Também pode integrar com CRMs e outras ferramentas de fluxo de trabalho para processos empresariais sem atrito.
5. É seguro e ético usar ferramentas de extração web fácil como o Thunderbit?
O Thunderbit incentiva um web scraping responsável e ético. Respeite sempre os termos de serviço do site, evite extrair dados pessoais sem consentimento e use limitação de taxa para evitar interrupções no serviço. Para saber mais sobre boas práticas, veja o guia do Thunderbit sobre web scraping.
Pronto para desbloquear o poder dos dados da web? Experimente o Thunderbit hoje e veja como a extração web fácil pode transformar o seu fluxo de trabalho.
Experimente o Thunderbit para extração web fácil
Experimente o AI Web Scraper do Thunderbit Get Started Free
Saiba mais




