
W zeszłym tygodniu spędziłem całe popołudnie, próbując zmusić agenta AI do wypełnienia formularza dostawcy na portalu za logowaniem. Po trzech godzinach patrzyłem już tylko na błąd „Connection Refused”, mój VPS skończył pamięć i serio rozważałem zrobienie wszystkiego ręcznie.
To doświadczenie to właściwie klasyczny pakiet startowy automatyzacja przeglądarki OpenClaw. Narzędzie potrafi poruszać się po stronach, scrapować dane, wypełniać formularze i łączyć złożone procesy w oparciu o zwykłe instrukcje po angielsku — naprawdę robi wrażenie. Ale właśnie przepaść między „to brzmi świetnie” a „to naprawdę działa u mnie” sprawia, że większość osób się zatrzymuje.
Spędziłem sporo czasu po obu stronach tej przepaści — budując narzędzia automatyzacji w Thunderbit i testując, co oferuje ekosystem open source. Ten poradnik to materiał, którego sam kiedyś potrzebowałem: prawdziwy walkthrough konfiguracji, decyzja o trybie przeglądarki, która wywraca każdego do góry nogami, ścieżka natywna dla Windows (bo WSL nie powinien być wymogiem), przewodnik przetrwania anty-botów, realne przykłady wyników, częste błędy z konkretnymi poprawkami i uczciwe spojrzenie na to, kiedy OpenClaw jest właściwym wyborem — a kiedy to już przesada.
Wypróbuj Thunderbit do bezproblemowego scrapowania stron
Zbieraj dane z dowolnej strony dzięki AI Get Started Free
Czym jest automatyzacja przeglądarki OpenClaw?
OpenClaw to darmowa, open-source’owa platforma agentów AI (licencja MIT), która może sterować przeglądarką w Twoim imieniu. Zamiast pisać skrypty Selenium albo kod w Puppeteer, po prostu opisujesz, co ma zostać zrobione — „Wejdź na tę stronę i wyciągnij wszystkie nazwy produktów oraz ceny” — a AI samo ustala, jak to wykonać. Korzysta z systemu numerowanych zrzutów ekranu, w którym agent identyfikuje elementy strony, nadaje im numery referencyjne i wchodzi z nimi w interakcję krok po kroku.
Architektura składa się z trzech elementów — dlatego konfiguracja to coś więcej niż tylko instalacja rozszerzenia:
- Gateway (VPS/serwer): „Mózg”, który przetwarza Twoje instrukcje i łączy się z LLM-ami. Domyślnie działa na porcie 18789.
- Node Host (lokalny komputer): przekaźnik, który pozwala Gateway wysyłać polecenia przeglądarki do Twojego lokalnego Chrome. Łączy się przez bezpieczny tunel, np. Tailscale.
- Rozszerzenie Chrome (Browser Relay): daje agentowi bezpośrednią kontrolę nad kartami w Twojej prawdziwej przeglądarce.
Dodatkowe porty to Control Service (18791), CDP Relay (18792) oraz zarządzany browser CDP (18800–18899, obsługujący do 100 równoległych profili).
Tak, to sporo ruchomych części. Ale kiedy zrozumiesz, za co odpowiada każdy element, całość zaczyna mieć sens. Pomyśl o tym jak o zdalnie sterowanym aucie: Gateway to sterownik, Node Host to sygnał radiowy, a rozszerzenie Chrome to samo auto.

Dlaczego automatyzacja przeglądarki OpenClaw ma znaczenie dla zespołów biznesowych
Pracownicy wiedzy mogą poświęcać nawet 60% czasu na rutynową administrację zamiast na zadania o wyższej wartości, w tym 1,8 godziny dziennie tylko na szukanie i zbieranie informacji. Smartsheet ustalił, że ponad 40% pracowników spędza co najmniej jedną czwartą tygodnia pracy na ręcznych, powtarzalnych zadaniach. Sama ręczna wpisywanie danych kosztuje amerykańskie firmy szacunkowo $8,500 na pracownika rocznie.
Właśnie ten problem ma rozwiązywać automatyzacja przeglądarki OpenClaw. W praktyce przekłada się to na konkretne procesy biznesowe:
| Przypadek użycia | Co robi OpenClaw | Efekt biznesowy |
|---|---|---|
| Pozyskiwanie leadów | Zbiera dane kontaktowe z katalogów i stron firmowych | Szybsze zapełnianie lejka sprzedaży |
| Monitorowanie cen konkurencji | Codziennie odwiedza strony produktów i wyciąga ceny | Bieżący wgląd w ruchy konkurencji |
| Wypełnianie formularzy / wprowadzanie danych | Wypełnia powtarzalne formularze internetowe (CRM, portale, wnioski) | Oszczędność godzin tygodniowo |
| Monitorowanie treści | Sprawdza blogi konkurencji, tablice ofert pracy, komunikaty prasowe | Wczesne sygnały rynkowe |
| QA / testowanie | Przechodzi przez ścieżki webowe, by sprawdzić ich działanie | Mniej zepsutych doświadczeń użytkownika |
Rynek agentów AI osiągnął $7,38 mld w 2025 roku, niemal podwajając się względem 3,7 mld dolarów w 2023 roku, a 88% organizacji korzysta dziś z automatyzacji AI przynajmniej w jednym obszarze. To już nie niszowa kategoria.
Sandbox Chromium vs. Browser Relay vs. Chrome Remote Debugging: jak wybrać właściwy tryb
Z mojego doświadczenia wynika, że wybór złego trybu przeglądarki to największe źródło frustracji nowych użytkowników OpenClaw. Widziałem ludzi tracących godziny na debugowanie połączeń, których można było uniknąć, gdyby od razu wybrali inny tryb. OpenClaw oferuje trzy sposoby połączenia i każdy ma realne kompromisy:
- Sandbox Chromium (Managed Profile): OpenClaw uruchamia własną przeglądarkę headless na serwerze. Bez sesji logowania, szybko, z minimalną konfiguracją — ale łatwiejsze do wykrycia przez systemy anty-bot.
- Browser Relay (Existing-Session): node host na Twoim lokalnym komputerze przekazuje instrukcje z VPS do Twojego prawdziwego Chrome. Obsługuje sesje logowania i ciasteczka, korzysta z faktycznego odcisku przeglądarki.
- Chrome Remote Debugging (Remote CDP): łączy się z zdalnymi przeglądarkami przez WebSocket URL. Pełny dostęp do sesji, najwyższy poziom złożoności konfiguracji. Działa z dostawcami chmurowymi, takimi jak Browserless lub Browserbase.

Tabela porównawcza: wszystkie trzy tryby przeglądarki
| Czynnik | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| Obsługa logowania | ❌ Nie (świeży profil) | ✅ Tak (prawdziwe sesje) | ✅ Tak (już uwierzytelnione) |
| Ryzyko wykrycia przez anty-bot | ⚠️ Średnie-wysokie | ✅ Niskie (prawdziwy fingerprint) | ✅ Niskie (zarządzane przez dostawcę) |
| Szybkość | ✅ Szybkie | ⚠️ Wolniejsze (relay sieciowy) | ⚠️ Zależne od usługi |
| Złożoność konfiguracji | Niska | Średnia | Wysoka |
| Pełna obsługa funkcji | ✅ Tak (wszystkie funkcje) | ⚠️ Ograniczona (brak batch, brak przechwytywania pobrań) | Zależy od dostawcy |
| Najlepsze do | Stron publicznych, szybkich scrapingów | Stron za logowaniem, wypełniania formularzy | Infrastruktury chmurowej, monitoringu 24/7 |
Schemat decyzyjny: który tryb wybrać?
Przejdź przez te pytania po kolei:
- „Czy musisz być zalogowany?” — Nie → Sandbox Chromium. Tak → następne pytanie.
- „Czy strona jest mocno chroniona przed botami?” — Tak → Browser Relay (prawdziwy fingerprint przeglądarki zmniejsza wykrywalność). Nie → Browser Relay albo Remote CDP.
- „Czy potrzebujesz trwałej sesji działającej bez przerwy, np. monitoringu dashboardu 24/7?” — Tak → Remote CDP z dostawcą chmurowym. Nie → Browser Relay.
Mapowanie na realne scenariusze:
- Scrapowanie publicznych ofert Amazon → Sandbox Chromium
- Wypełnianie formularza w CRM za logowaniem → Browser Relay
- Całodobowe monitorowanie wewnętrznego dashboardu analitycznego → Remote CDP z Browserless/Browserbase
Dobrze wybierz ten tryb, a oszczędzisz sobie godzin debugowania. Naprawdę.
Zanim zaczniesz
- Poziom trudności: Średni (wymagana swoboda w CLI)
- Czas potrzebny: 45–75 minut na pełną konfigurację; 10–15 minut na każdy krok
- Czego potrzebujesz: VPS (minimum 2 GB RAM, zalecane 4 GB), Node.js v22.12.0+, konto Tailscale (darmowe), przeglądarka Chrome i cierpliwość
Krok 1: Uruchom OpenClaw na VPS (albo lokalnie)
VPS to miejsce, w którym mieszka „mózg” OpenClaw. Masz dwie ścieżki, żeby go uruchomić:
Opcja A: hosting VPS jednym kliknięciem
Kilku dostawców oferuje gotowe obrazy OpenClaw:
| Dostawca | Cena startowa | Uwagi |
|---|---|---|
| Hostinger | od $6.99/mies. | Wstępnie skonfigurowany obraz |
| Tencent Cloud Lighthouse | od ok. $0.08/rok (promocja) | Zalecane 2 rdzenie / 4 GB |
| Hetzner | od $4.09/mies. (CX22) | Najlepszy stosunek ceny do jakości; ręczna instalacja |
| DigitalOcean | od $4/mies. | Ręczna instalacja |
| Vultr | od $3.50/mies. | Ręczna instalacja |
Opcja B: ręczna instalacja z CLI
# Instalacja przez npm (wymaga Node.js v22.12.0+)
npm install -g openclaw
# Uruchom kreator wdrożenia
openclaw onboard
# Wygeneruj token Gateway (zapisz go — będzie potrzebny do node host)
openclaw doctor --generate-gateway-token
# Sprawdź konfigurację
openclaw doctor --fix
Minimalne wymagania: 2 GB RAM (przy 1 GB potrafi się wysypać), zalecane 4 GB. Każda headless przeglądarka zużywa 400–800 MB w stanie spoczynku. Jeśli używasz Dockera, ustaw shm_size: '2gb' — to krytyczne dla stabilności.
Po tym kroku OpenClaw powinien już działać, a token Gateway powinien być bezpiecznie zapisany. (Ja trzymam go w menedżerze haseł. Nie zgub tego.)
Krok 2: Skonfiguruj Tailscale, aby połączyć VPS i komputer lokalny
Tailscale tworzy prywatny, szyfrowany tunel między VPS a Twoim urządzeniem lokalnym, dzięki czemu instrukcje dla przeglądarki nie są wystawione do publicznego internetu. Biorąc pod uwagę, że OpenClaw miał 512 podatności oznaczonych przez Kaspersky na początku 2026 roku, pomijanie tego kroku to zły pomysł.
# Na VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Zanotuj adres Tailscale VPS (100.x.x.x)
# Skonfiguruj Gateway, aby nasłuchiwał w sieci Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
Zainstaluj Tailscale na swoim komputerze lokalnym z tailscale.com/download. Oba urządzenia muszą korzystać z tego samego konta Tailscale.
Alternatywy, jeśli Tailscale Ci nie odpowiada:
| Czynnik | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Czas konfiguracji | 5 min | 10–15 min | 20–30 min |
| Koszt | Darmowy (użytek osobisty) | Darmowy | Darmowy |
| Traversal NAT | Automatyczny | Automatyczny | Ręczny |
Powinieneś teraz móc pingować adres Tailscale VPS z lokalnego komputera. Jeśli nie, sprawdź, czy oba urządzenia są na tym samym koncie Tailscale.
Krok 3: Zainstaluj Node Host na swoim lokalnym urządzeniu
Node Host przekazuje instrukcje przeglądarki z Gateway na VPS do lokalnego Chrome — to tłumacz między serwerem a przeglądarką.
# Zainstaluj pakiet node host
npm install -g @openclaw/node-host
# Ustaw token Gateway z kroku 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Uruchom node host, wskazując na adres Tailscale VPS
openclaw node install --host 100.x.x.x --port 18789
# Zatwierdź połączenie po stronie VPS
openclaw node approve <node-id>
Powinieneś zobaczyć potwierdzenie, że node jest połączony i zatwierdzony. Jeśli etap zatwierdzania się zawiesza, zrestartuj proces Gateway na VPS.
Krok 4: Zainstaluj rozszerzenie OpenClaw do Chrome
Rozszerzenie daje agentowi bezpośrednią kontrolę nad kartami przeglądarki. Możesz je też pobrać ze sklepu Chrome Web Store, wyszukując „OpenClaw Browser Relay”.
# Zainstaluj pliki rozszerzenia
openclaw browser extension install
# Albo ręcznie:
# 1. Otwórz chrome://extensions
# 2. Włącz „Tryb dewelopera” (przełącznik w prawym górnym rogu)
# 3. Kliknij „Load unpacked” → wybierz katalog rozszerzenia
# 4. Przypnij do paska narzędzi
# 5. Sprawdź, czy plakietka pokazuje „ON”
Jeśli plakietka pokazuje „ON”, wszystko działa. Jeśli zostaje „OFF”, przejdź do sekcji rozwiązywania problemów poniżej.
Krok 5: Uruchom swoje pierwsze zadanie automatyzacji przeglądarki OpenClaw
Otwórz docelową kartę, a następnie w interfejsie czatu OpenClaw spróbuj czegoś prostego:
Wejdź na https://books.toscrape.com i wyciągnij tytuł oraz cenę każdej książki na stronie
Oczekiwany przebieg: wysłanie instrukcji → agent robi zrzut strony (identyfikuje elementy z numerami referencyjnymi) → agent wyciąga dane → uporządkowany wynik wraca jako JSON lub CSV.
Wskazówka z doświadczenia: zaczynaj od bardzo prostych promptów. Nadmierne opisywanie tego, czego chcesz, może wręcz zdezorientować AI — dodawaj szczegóły dopiero wtedy, gdy agent źle zinterpretuje pierwszą instrukcję.
Dla 20 książek na pierwszej stronie spodziewaj się około 30–60 sekund. Jeśli wróci ustrukturyzowany zestaw danych, Twoja automatyzacja przeglądarki OpenClaw działa.
Automatyzacja przeglądarki OpenClaw na Windows: natywna ścieżka konfiguracji
Większość poradników o OpenClaw zakłada macOS albo Linux. Jeśli używasz Windows, pewnie już to zauważyłeś. Jeden z użytkowników na forum ujął to idealnie: „wiele rozwiązań wyglądało sensownie w teorii, ale żadne nie było projektowane z myślą o natywnym Windows”.
Oto, co naprawdę działa.
Opcja A: Chrome Remote Debugging na Windows (zalecana natywna ścieżka)
Najbardziej niezawodne podejście natywne dla Windows. Otwórz PowerShell i uruchom Chrome z włączonym debugowaniem zdalnym:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Jeśli Chrome nie jest w tej lokalizacji, spróbuj:
# Sprawdź alternatywne lokalizacje
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# Albo sprawdź AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Następnie skonfiguruj OpenClaw tak, aby łączył się przez Remote CDP, ustawiając cdpUrl na ws://localhost:9222 w pliku openclaw.json.
Opcja B: Docker Desktop jako obejście dla Windows
Jeśli ścieżka natywna sprawia problemy, Docker Desktop na Windows może uruchomić headless kontener Chromium:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# Wskaż OpenClaw na: cdpUrl: "ws://localhost:9222"
Dodaje kolejną warstwę złożoności, ale dla niektórych użytkowników jest stabilniejsze. Działa, choć nie jest to eleganckie.
Katalog błędów specyficznych dla Windows
| Błąd | Przyczyna | Naprawa (PowerShell) |
|---|---|---|---|
| Port 9222 jest już zajęty | Otwarta inna sesja DevTools | Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force |
| Nie znaleziono binarki Chrome | Zła ścieżka | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Odrzucono połączenie Tailscale | Firewall Windows blokuje port | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| Błędy uprawnień npm | Brak uruchomienia jako administrator | Uruchom PowerShell jako Administrator albo użyj nvm-windows |
Wszystkie powyższe komendy są w PowerShell, nie w bashu. Możesz je kopiować i wklejać bezpośrednio.
Przewodnik przetrwania anty-botów dla automatyzacji przeglądarki OpenClaw
Wykrywanie botów to największa frustracja użytkowników automatyzacji przeglądarki OpenClaw. Domyślny Chromium w OpenClaw nie ma wbudowanych mechanizmów stealth — strony wykrywają go po fladze WebDriver, wymiarach ekranu, fingerprintingu fontów i reputacji IP. Widziałem, jak agenci byli blokowani w kilka sekund na niektórych stronach.
Ale istnieje podejście warstwowe. Zacznij od najprostszej poprawki i eskaluj tylko wtedy, gdy to konieczne.
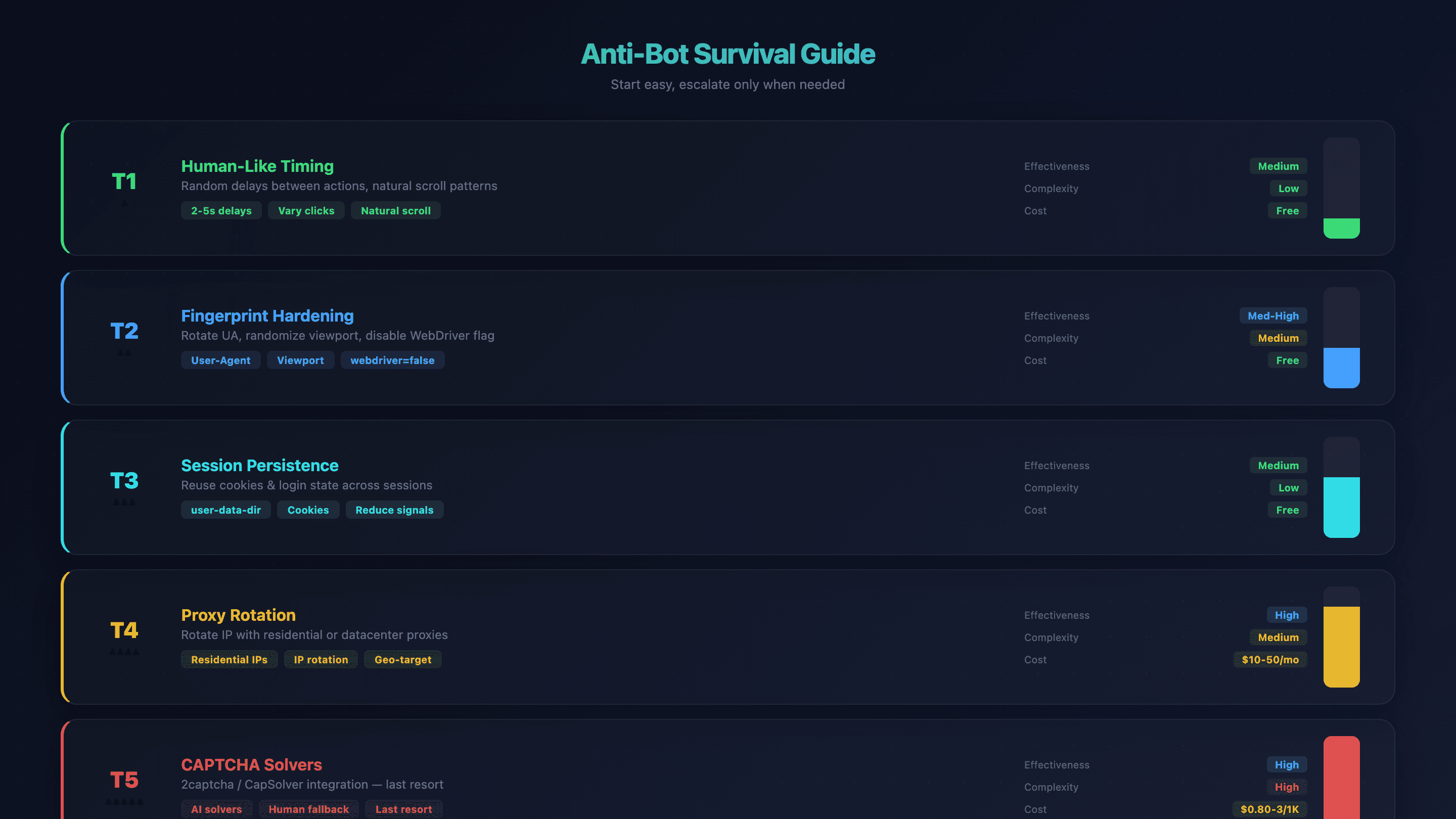
Poziom 1: zachowanie i tempo jak u człowieka
Dodawaj losowe opóźnienia między akcjami w swoich promptach. Zamiast klikać z prędkością maszyny, poinstruuj agenta: „czekaj 2–5 sekund między każdym kliknięciem”. AI i tak naturalnie nieco zmienia tempo, ale wyraźne wskazówki pomagają.
Skuteczność: Średnia | Złożoność: Niska | Koszt: Darmowy
Poziom 2: wzmocnienie fingerprintu
Rotuj user-agent, losuj rozmiar okna i pozwól OpenClaw automatycznie wyłączyć flagę navigator.webdriver (przez --disable-blink-features=AutomationControlled).
# Ustaw własne nagłówki
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Losuj viewport
openclaw browser set viewport 1366 768
# Ustaw strefę czasową i lokalizację
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Dla głębszego ukrywania się przed wykrywaniem społeczność poleca Camoufox (przeglądarkę anti-detect opartą na Firefoxie z maskowaniem fingerprintu na poziomie silnika C++).
Skuteczność: Średnio-wysoka | Złożoność: Średnia | Koszt: Darmowy
Poziom 3: utrwalanie sesji
Użyj user-data-dir, aby zachować ciasteczka i stan logowania między sesjami. Dzięki temu ograniczasz sygnały „świeżej przeglądarki”, które uruchamiają systemy anty-bot.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Skuteczność: Średnia | Złożoność: Niska | Koszt: Darmowy
Poziom 4: rotacja proxy
Gdy czas i fingerprint to za mało, rotuj adres IP. Proxy residential są trudniejsze do wykrycia; proxy datacenter są szybsze i tańsze.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Uwaga: konfiguracja proxy na poziomie przeglądarki to wciąż funkcja zgłoszona jako feature request (GitHub Issue #8079). Obecnie proxy trzeba ustawiać na poziomie systemu operacyjnego lub środowiska.
| Dostawca | Residential | Datacenter | Najlepsze do |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | Enterprise, najwyższa jakość |
| Oxylabs | $6–8/GB | $0.48–5/GB | Scrapowanie na dużą skalę |
| Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | Średnie budżety |
| IPRoyal | $5–7/GB | -- | Budżetowe rozwiązania |
| DataImpulse | $1/GB | -- | Najniższy koszt |
Skuteczność: Wysoka | Złożoność: Średnia | Koszt: $10–50/mies.
Poziom 5: solvery CAPTCHA
Ostateczność. Zintegruj usługi takie jak 2captcha lub CapSolver.
| Usługa | reCAPTCHA v2 | Cloudflare Turnstile | Opóźnienie |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15–45 s (ludzkie rozwiązywanie) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10 s (AI) |
FlareSolverr (open-source’owe obejście Cloudflare) jest opisywany jako zawodny w latach 2025–2026 ze względu na coraz mocniejsze zabezpieczenia Cloudflare.
Skuteczność: Wysoka | Złożoność: Wysoka | Koszt: $0.80–3/1K rozwiązań
Podsumowanie metod anty-bot
| Technika | Skuteczność | Złożoność | Koszt |
|---|---|---|---|
| Tempo jak u człowieka | Średnia | Niska | Darmowy |
| Wzmocnienie fingerprintu | Średnio-wysoka | Średnia | Darmowy |
| Utrwalanie sesji | Średnia | Niska | Darmowy |
| Rotacja proxy | Wysoka | Średnia | $10–50/mies. |
| Solvery CAPTCHA | Wysoka | Wysoka | $0.80–3/1K rozwiązań |
Dla użytkowników, którzy ciągle wpadają na blokady anty-bot i po prostu potrzebują danych: cloud scraping w Thunderbit obsługuje zabezpieczenia anty-bot od razu dla publicznych stron — bez konfiguracji proxy, bez strojenia fingerprintu. To zupełnie inne podejście (AI odczytuje stronę za każdym razem przez zarządzaną infrastrukturę chmurową), które omija cały wyścig zbrojeń anty-botowych przy standardowych zadaniach ekstrakcji danych.
Realny wynik: co właściwie produkuje automatyzacja przeglądarki OpenClaw
Zanim zainwestujesz 45–75 minut w konfigurację, pewnie chcesz zobaczyć, jak wygląda efekt końcowy. Słusznie — oto trzy przykłady workflow z prawdziwym wynikiem.
Przykład 1: web scraping — wyciąganie danych o produktach
Prompt: „Wejdź na https://books.toscrape.com i wyciągnij tytuł oraz cenę każdej książki na stronie”
Wynik (pierwsze 5 wierszy):
| Tytuł | Cena |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Czas: ~45 sekund dla 20 wierszy (jedna strona). Pagination wymagała kolejnej instrukcji: „Kliknij Next i powtórz dla 5 stron”. Łącznie: ~100 wierszy w około 3 minuty.
Przykład 2: automatyzacja formularzy — wypełnienie formularza z wieloma polami
Scenariusz: wypełnianie formularza zapytania do dostawcy z nazwą firmy, danymi kontaktowymi i zainteresowaniem produktem.
Agent robi zrzut formularza, identyfikuje każde pole po numerze referencyjnym i wypełnia je po kolei. Przed: puste pola. Po: wszystkie pola uzupełnione, wyświetlona wiadomość potwierdzająca. Wszystkie rozwijane listy i checkboxy są obsługiwane przez system snapshotów — agent „widzi” opcje i wybiera właściwą.
Czas: ~30 sekund dla formularza z 6 polami.
Przykład 3: pagination — scrapowanie wielu stron
Początkowy wynik: 20 wierszy ze strony 1. Po instrukcji „kliknij Next i powtórz dla wszystkich stron”: 1,000 wierszy z 50 stron na books.toscrape.com. Agent wykrywa przycisk „Next” przez snapshot i klika go w pętli.
Czas: ~12 minut dla pełnego zbioru 1,000 wierszy.
Porównanie obok siebie: to samo zadanie scrapowania w Thunderbit
Dla tego samego przykładu books.toscrape.com workflow w Thunderbit wygląda tak:
- Zainstaluj Thunderbit Chrome Extension (~30 sekund)
- Przejdź na stronę
- Kliknij „AI Suggest Fields” → AI wykrywa Title, Price, Availability, Rating
- Kliknij „Scrape” → wyciąga 20 wierszy
- Użyj opcji paginacji → zeskrob wszystkie strony
- Wyeksportuj do Google Sheets (darmowe)
Łączny czas: ~3 minuty od zera do wyeksportowanych danych, bez VPS, bez CLI, bez konfiguracji.
Nie chodzi o to, że jedno narzędzie jest „lepsze”. Właściwy wybór zależy od tego, co naprawdę chcesz zrobić.
Wypróbuj rozszerzenie Thunderbit do Chrome
Kiedy automatyzacja przeglądarki OpenClaw to przesada (i co wybrać zamiast)
OpenClaw świetnie sprawdza się przy złożonej, wieloetapowej automatyzacji agentowej — workflow za logowaniem, łączenie akcji w przeglądarce z komendami shellowymi, działanie 24/7 na VPS. Ale jeśli celem jest „wyciągnij dane produktowe ze strony z listą” albo „pobierz e-maile z katalogu”, pełny stos VPS + Tailscale + node host jest prawdopodobnie przewymiarowany.
Widziałem ludzi, którzy inwestowali ponad 60 minut konfiguracji w zadanie, które prostsze narzędzie wykonuje w 2 minuty. Słaby interes.

Właściwe narzędzie do zadania: tabela porównawcza
| Czynnik | Automatyzacja przeglądarki OpenClaw | Thunderbit |
|---|---|---|
| Czas konfiguracji | 45–75 min (VPS + Tailscale + node host) | ~2 min (instalacja rozszerzenia Chrome) |
| Wymagany kod | CLI + prompty w naturalnym języku | Zero — kliknij „AI Suggest Fields” → „Scrape” |
| Obsługa anty-bot | Ręczna (proxy, konfiguracja fingerprintu) | Wbudowany cloud scraping |
| Nawigacja po stronach za logowaniem | ✅ Browser Relay / remote debug | ✅ tryb scraping przeglądarki |
| Wzbogacanie podstron | Własny skrypt dla każdego workflow | Scrapowanie podstron jednym kliknięciem |
| Harmonogram / uruchomienia 24×7 | Oparte na VPS, zawsze aktywne | Wbudowany scheduled scraper |
| Miesięczny koszt | $8–14 (hobby) do $110–280 (duże użycie) | $0 (darmowy plan) do $15/mies. |
| Koszt utrzymania | Wysoki (aktualizacje, VPS, debugowanie) | Prawie zerowy — AI dostosowuje się do zmian układu |
| Najlepsze do | Złożone workflow agentowe, niestandardowe pipeline’y | Ekstrakcja danych, wypełnianie formularzy, lead gen, monitoring cen |
Routing zastosowań
- Potrzebujesz wieloetapowych workflow agentowych łączących akcje w przeglądarce z komendami shell, aplikacjami do komunikacji i bazami danych → OpenClaw to dobry wybór.
- Chcesz scrapować dane ze stron, wypełniać formularze albo monitorować ceny bez dotykania terminala → Thunderbit zrobi to szybciej. Możesz też zajrzeć na kanał Thunderbit na YouTube, żeby zobaczyć krótkie demonstracje.
- Potrzebujesz lekkiego skryptu do jednego konkretnego endpointu API → zwykły skrypt w Pythonie z requests może w zupełności wystarczyć.
To naprawdę ramy, z których korzystam, gdy ktoś z mojego zespołu pyta: „jakiego narzędzia powinienem użyć do tego zadania?”
Najczęstsze błędy automatyzacji przeglądarki OpenClaw i jak je naprawić
Dodaj tę sekcję do zakładek. Jest uporządkowana według objawów, więc możesz szybko znaleźć poprawkę przez Ctrl+F.
„Connection Refused” albo Node Host nie chce się połączyć
Najbardziej prawdopodobne przyczyny (sprawdzaj po kolei):
- Tailscale nie działa na obu urządzeniach → uruchom
tailscale statusna obu - Gateway nie nasłuchuje w sieci Tailscale (wciąż ustawiony na localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - Zły adres IP → sprawdź dokładnie przez
tailscale ip -4 - Firewall blokuje port 18789 →
sudo ufw allow 18789/tcp(Linux) albo dodaj regułę Windows Firewall
Plakietka rozszerzenia ciągle pokazuje „OFF” albo karta nie jest wykrywana
- Rozszerzenie nie zostało załadowane w trybie deweloperskim →
chrome://extensions→ włącz Developer mode → przeładuj - Node Host nie działa → uruchom ponownie
openclaw node start - Konflikt instancji Chrome → zamknij wszystkie okna Chrome, uruchom ponownie i przeładuj rozszerzenie
Agent zwraca puste albo błędne dane
- Strona nie załadowała się w pełni: poleć agentowi „odczekaj 3 sekundy po wejściu na stronę, zanim zaczniesz ekstrakcję”. Wiele SPA potrzebuje czasu na renderowanie.
- Blokada anty-bot: sprawdź, czy zamiast prawdziwej treści nie widzisz strony CAPTCHA. Przełącz się z Sandbox Chromium na Browser Relay.
- Nieaktualny snapshot: poproś agenta, aby „zrobił nowy snapshot” — numery referencyjne stają się nieaktualne po nawigacji.
„Port 9222 Already in Use”
Częsty problem, gdy Chrome DevTools albo inne narzędzie automatyzujące już używa tego portu.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS kończy pamięć
Każda headless przeglądarka zużywa 400–800 MB RAM. Uruchamianie wielu jednocześnie może wywrócić mały VPS.
Naprawy:
- Wyłącz ładowanie obrazów/CSS/fontów:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Ogranicz liczbę równoczesnych instancji do tego, co wytrzyma Twoja pamięć
- Ustaw
shm_size: '2gb'w konfiguracji Dockera - Włącz hibernację sesji:
OPENCLAW_HIBERNATE_AFTER=300 - Zaktualizuj VPS do 4 GB+ RAM, jeśli potrzebujesz większego zapasu
Jak utrzymać automatyzację przeglądarki OpenClaw w dobrej kondycji
Kilka najlepszych praktyk, które wypracowałem podczas długotrwałego używania takich konfiguracji:
- Wyłącz obrazy, arkusze stylów i fonty przy zadaniach polegających wyłącznie na zbieraniu danych. To znacząco zmniejsza zużycie zasobów i przyspiesza działanie.
- Wielokrotnie używaj tych samych instancji przeglądarki zamiast uruchamiać nową dla każdego zadania. Świeże instancje są kosztowne pod względem pamięci i częściej wywołują sygnały anty-bot.
- Zaczynaj od prostych promptów. Dodawaj szczegóły dopiero, jeśli agent źle interpretuje polecenie. Przesadne opisywanie może bardziej zaszkodzić niż pomóc.
- Monitoruj użycie zasobów VPS (CPU, RAM) i zwiększaj moc zanim dojdziesz do limitu. Crash VPS-a o 2 w nocy nie jest przyjemny do debugowania.
- Trzymaj OpenClaw i rozszerzenie Chrome zaktualizowane — ale testuj aktualizacje najpierw w środowisku stagingowym. OpenClaw wypuszcza mniej więcej 13 wydań miesięcznie, i nie wszystkie są bezproblemowe.
- Do zadań cyklicznych (codzienne sprawdzanie cen, cotygodniowe pobieranie leadów) Thunderbit ma scheduled scraper, który pozwala ustawić harmonogram w zwykłym języku i całkowicie zapomnieć o utrzymaniu VPS.
Kwestie etyczne i prawne
Krótko, ale ważne. Szanuj robots.txt (sformalizowany jako standard IETF w RFC 9309), ograniczaj tempo zapytań, sprawdzaj regulamin stron docelowych i przetwarzaj dane osobowe zgodnie z GDPR oraz lokalnym prawem prywatności. Precedens hiQ v. LinkedIn (2022) ustalił, że scrapowanie publicznie dostępnych danych nie narusza CFAA, ale to nie znaczy, że wolno wszystko. Odpowiedzialne korzystanie z automatyzacji chroni zarówno Ciebie, jak i Twoją firmę. Więcej na ten temat znajdziesz w naszym przewodniku o prawnych aspektach web scrapingu.
Podsumowanie
automatyzacja przeglądarki OpenClaw to potężna opcja dla złożonych, wieloetapowych workflow webowych sterowanych naturalnym językiem. Najważniejsze wnioski:
- Wybierz właściwy tryb przeglądarki na starcie (Sandbox, Relay, Remote CDP) — ta jedna decyzja oszczędza godziny debugowania.
- Użytkownicy Windows mają działającą ścieżkę, ale trzeba trzymać się komend specyficznych dla Windows i uważać na firewall oraz ścieżki plików.
- Obsługa anty-bot to realne wyzwanie — zacznij od najprostszych technik (czas, fingerprint) i eskaluj tylko wtedy, gdy trzeba.
- Najpierw zobacz wynik, zanim się zaangażujesz. Jeśli potrzebujesz tylko ustrukturyzowanych danych ze strony listy, narzędzie no-code takie jak Thunderbit da Ci to w kilka minut, bez żadnego utrzymania.
- Uwzględnij koszty utrzymania. OpenClaw wypuszcza około 13 wydań miesięcznie, koszty VPS rosną, a debugowanie jest częścią pakietu.
Jeśli chcesz najpierw wypróbować prostszą drogę, Thunderbit ma darmowy plan — zainstaluj rozszerzenie, zeskrob stronę i sprawdź, czy to wystarczy, zanim zainwestujesz w pełną konfigurację VPS. Jeśli jednak wybierzesz OpenClaw, dodaj ten poradnik do zakładek. Katalog błędów na pewno się przyda — i niech Twoje instancje przeglądarki zawsze mają wystarczająco dużo RAM.
FAQ
Jaka jest różnica między OpenClaw Sandbox Chromium a Browser Relay?
Sandbox Chromium uruchamia headless przeglądarkę na serwerze — jest szybki i prosty w konfiguracji, ale za każdym razem tworzy świeży profil (bez sesji logowania) i łatwiej go wykryć systemom anty-bot. Browser Relay przekazuje instrukcje do Twojego prawdziwego Chrome na lokalnym komputerze, więc obsługuje logowania, dziedziczy rzeczywisty fingerprint przeglądarki i jest trudniejszy do wykrycia przez strony. Minusem jest wolniejsze działanie ze względu na relay sieciowy oraz pewne ograniczenia funkcji (brak działań wsadowych, brak przechwytywania pobrań).
Czy mogę uruchomić automatyzację przeglądarki OpenClaw na Windows bez WSL?
Tak, ale z zastrzeżeniami. Najpewniejsza natywna ścieżka dla Windows to Chrome Remote Debugging przez PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop jest planem B, jeśli to okaże się niestabilne. Pełne natywne wsparcie Node Host na Windows może mieć ostre krawędzie — sprawdzaj aktualną dokumentację i przygotuj się na problemy typowe dla Windows, takie jak blokady firewalla i różnice w ścieżkach binarek. Wszystkie komendy w sekcji Windows w tym poradniku są w PowerShell, nie w bashu.
Jak obsługiwać CAPTCHA w automatyzacji przeglądarki OpenClaw?
Zacznij od zmniejszenia ryzyka wykrycia: dodaj tempo jak u człowieka, wzmocnij fingerprint przeglądarki i użyj utrwalania sesji, żeby uniknąć sygnałów świeżej przeglądarki. Jeśli CAPTCHA nadal się pojawiają, zintegruj usługę do rozwiązywania, taką jak 2captcha ($2.99/1K rozwiązań) lub CapSolver ($0.80–1.50/1K, oparty na AI). W przypadku publicznych stron, gdzie po prostu potrzebujesz danych, cloud scraping w Thunderbit obsługuje anty-bot automatycznie, bez potrzeby konfiguracji proxy czy CAPTCHA.
Czy automatyzacja przeglądarki OpenClaw jest darmowa?
Sam OpenClaw jest open source (licencja MIT) i darmowy. Jednak jego uruchomienie wymaga infrastruktury — VPS za $4–15 miesięcznie, plus opcjonalnie usługi takie jak rotacja proxy ($10–50 miesięcznie) albo solvery CAPTCHA (płatność za każde rozwiązanie). Całkowity miesięczny koszt waha się od $8–14 przy hobbystycznym użyciu do $110–280 przy intensywnych obciążeniach automatyzacją. Dla porównania, darmowy plan Thunderbit obejmuje podstawowe scrapowanie bez kosztów infrastruktury.
Co zrobić, jeśli agent OpenClaw ciągle zwraca puste wyniki?
Sprawdź trzy rzeczy, w tej kolejności: Po pierwsze, strona może nie być w pełni załadowana — każ agentowi „odczekać 3 sekundy po wejściu na stronę przed ekstrakcją”. Po drugie, możesz wpadać na blokadę anty-bot — jeśli agent „widzi” stronę CAPTCHA zamiast właściwej treści, przełącz się z Sandbox Chromium na Browser Relay. Po trzecie, referencje snapshotu mogą być nieaktualne — po każdej nawigacji poproś agenta, aby „zrobił nowy snapshot”. Jeśli nic nie pomaga, sprawdź zużycie pamięci VPS — crash instancji przeglądarki często kończy się po prostu pustym wynikiem bez komunikatu.
Wypróbuj Thunderbit do szybszej ekstrakcji danych webowych Get Started Free




