

Czy zdarzyło Ci się kiedyś dostać od przełożonego stos plików PDF i mieć za zadanie wyciągnięcie z nich danych, które mają być idealnie sformatowane i w 100% poprawne? Robienie tego ręcznie to pewny przepis na nadgodziny. Wyodrębnianie danych z PDF-ów potrafi być naprawdę uciążliwe, bo w przeciwieństwie do danych z internetu pliki PDF często mają niespójne formatowanie. W jednych są tabele, inne to po prostu obrazy albo zeskanowane dokumenty, więc bezpośrednie pobieranie danych bywa dość trudne.
Wyodrębniaj dane z dowolnej strony internetowej za pomocą AI Get Started Free
Na przykład, jeśli chcesz wyciągnąć adresy e-mail z PDF-a, część z nich może być w formie obrazu, a część ukryta w złożonych kodowaniach znaków. Weźmy taki przykład: {john.doe,jane.doe}@example.com. To tak naprawdę oznacza dwa osobne adresy e-mail: john.doe@example.com i jane.doe@example.com. A potem jest jeszcze {first.last}@example.com, gdzie „first” i „last” zastępujesz odpowiednio imieniem i nazwiskiem autora. Tradycyjne narzędzia do rozpoznawania tekstu po prostu sobie z tym nie poradzą. Właśnie wtedy z pomocą przychodzi wygodne narzędzie — PDF Scraper.
Czym jest PDF Scraper
PDF Scraper to sprytne narzędzie, które automatycznie wyodrębnia dane z plików PDF, zamieniając treści takie jak tabele i tekst na potrzebne Ci formaty, na przykład Excel, CSV lub JSON. Mówiąc prościej, zamienia żmudne kopiowanie i wklejanie w rozwiązanie na jedno kliknięcie.
Wyobraź sobie stertę faktur, umów, prac naukowych, a nawet zeskanowanych PDF-ów, których przepisanie ręcznie zajęłoby godziny. Z PDF Scraperem wystarczy wgrać plik, a po kilku sekundach dane zostają wyodrębnione, oszczędzając czas i wysiłek oraz zapewniając dokładność. Koniec z uciążliwym ręcznym wprowadzaniem danych.
Jeśli Twój PDF zawiera różne typy danych, takie jak tabele, linki i obrazy, pozwól AI PDF Scraperowi zająć się tym za Ciebie. AI PDF Scrapery korzystają z dużych modeli językowych (LLM), które potrafią jednocześnie przetwarzać tekst, obrazy i tabele, dając imponujące rezultaty.
Zalety AI PDF Scrapera nie kończą się na szybkości i dokładności — jego elastyczność sprawia, że korzystanie z niego jest bezstresowe. Niezależnie od tego, czy masz do czynienia z zeskanowanymi dokumentami, obrazami czy wielojęzycznymi PDF-ami, AI radzi sobie z tym wszystkim bez trudu. Dostępnych jest wiele świetnych narzędzi AI, takich jak Thunderbit, ChatGPT i ChatPDF, z których każde ma unikalne funkcje odpowiadające różnym potrzebom. Niezależnie od tego, czy chcesz szybko wyodrębnić dane, czy przeanalizować złożone dokumenty, wybór odpowiedniego narzędzia może sprawić, że Twoja praca będzie łatwiejsza i bardziej efektywna.
Wypróbuj: wyodrębnianie danych z PDF-ów przy użyciu AI
Spróbuj! Możesz klikać, eksplorować i uruchomić proces, obserwując go na żywo.
Jak wybrać odpowiedni PDF Scraper
Wybór PDF Scrapera jest jak kupno samochodu — najlepszy jest ten, który odpowiada Twoim potrzebom. Oto kilka rzeczy, na które warto zwrócić uwagę:
| Cecha | Opis |
|---|---|
| Dokładność i stabilność | Sprawdź, czy narzędzie wyodrębnia dane precyzyjnie, zwłaszcza w przypadku informacji krytycznych. |
| Formaty wyjściowe | Upewnij się, że narzędzie obsługuje potrzebne Ci formaty wyjściowe, takie jak Excel, CSV lub JSON. |
| Integracja z innymi narzędziami | Jeśli musisz połączyć je z systemami swojej firmy, sprawdź, czy oferuje bezproblemową integrację. |
| Przyjazny interfejs | Narzędzie z prostym interfejsem lepiej sprawdzi się u zwykłych użytkowników, natomiast bardziej zaawansowane może być lepsze dla zespołów technicznych. |
Poszczególne narzędzia mają swoje mocne strony, a wybór odpowiedniego może znacząco zwiększyć produktywność. Oto trzy popularne PDF Scrapery, z których każdy ma własne funkcje dopasowane do różnych potrzeb:
| Narzędzie | Zalety | Wady |
|---|---|---|
| Thunderbit | Szybkie wyodrębnianie danych; łatwe w użyciu jako rozszerzenie do przeglądarki; świetne do współpracy zespołowej | Ograniczona skala przetwarzania danych |
| ChatPDF | Łatwe w użyciu, rozmowa w stylu czatu z pytaniami i odpowiedziami dla jednego pliku PDF | Brak natywnego eksportu do CSV/Excel/JSON — odpowiedzi zostają na czacie |
| ChatGPT | Elastyczne przy złożonej semantyce, szerokie zastosowanie | Wymaga ręcznego wpisywania promptu za każdym razem |
Jak zacząć korzystać z AI PDF Scrapera
Thunderbit
Chcesz szybko wyodrębniać dane z PDF-ów, nie tracąc przy tym czasu ani energii? Thunderbit jest właśnie dla Ciebie. Jest prosty w obsłudze i jednym kliknięciem pozwala wszystko załatwić. Wykonaj te kroki, aby łatwo zamienić złożone dane z PDF-a na potrzebny Ci format i znacząco zwiększyć wydajność:
-
Dodaj Thunderbit do Chrome i zarejestruj się:
Wejdź na oficjalną stronę Thunderbit i dodaj rozszerzenie Thunderbit do przeglądarki Chrome. Zarejestruj się za pomocą konta Google lub innego adresu e-mail.

-
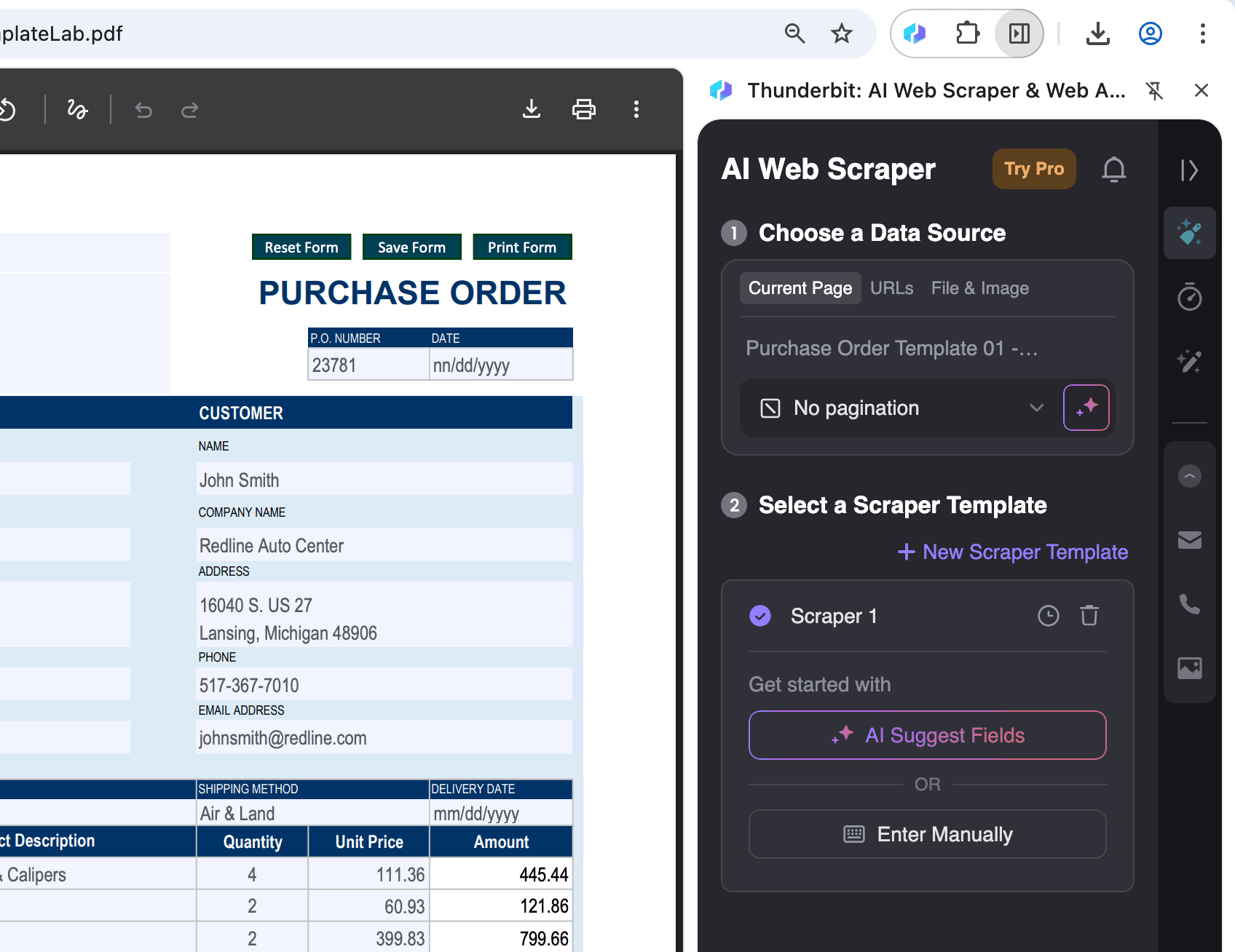
Otwórz PDF w Chrome:
Otwórz plik PDF, z którego chcesz wyodrębnić dane, w Chrome i kliknij ikonę Thunderbit w prawym górnym rogu.
-
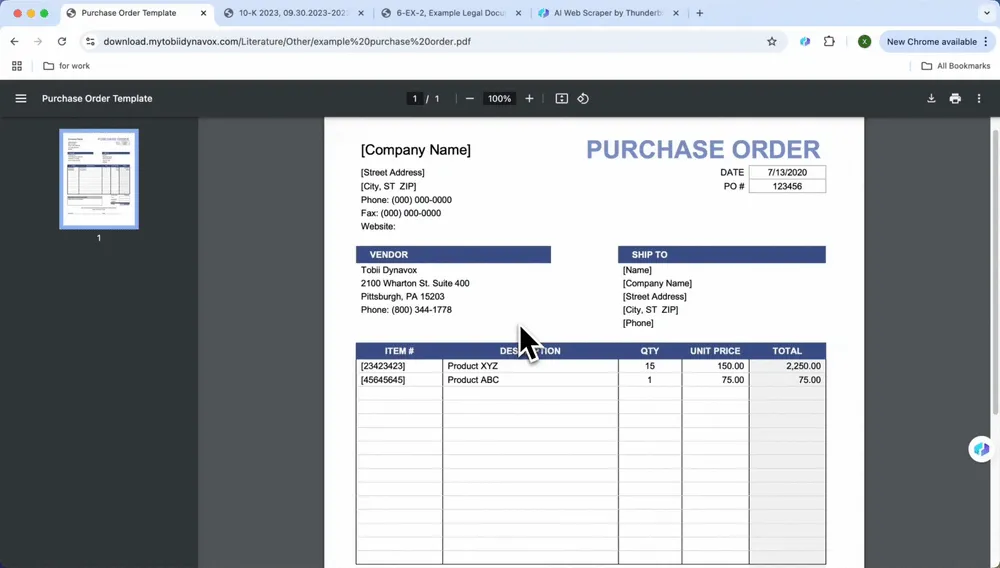
Wybierz format wyjściowy i eksportuj:
Po wybraniu opcji AI Suggest Columns możesz filtrować lub dostosować dane według potrzeb. Następnie wybierz preferowany format eksportu (CSV, Google Sheets, Airtable lub Notion) i kliknij Scrape, aby wyeksportować dane.
 Wyeksportowane dane można bezpośrednio połączyć z Notion, Airtable lub Google Sheets dla łatwej współpracy zespołowej.
Wyeksportowane dane można bezpośrednio połączyć z Notion, Airtable lub Google Sheets dla łatwej współpracy zespołowej.
Thunderbit to proste narzędzie do wyodrębniania danych z PDF-ów, które pozwala szybko pobrać potrzebne informacje z plików PDF i przekonwertować je do użytecznego formatu. Niezależnie od tego, czy używasz go prywatnie, czy w zespole, Thunderbit może znacząco zwiększyć Twoją produktywność, sprawiając, że ekstrakcja danych staje się łatwiejsza i wygodniejsza.
ChatPDF
Jeśli musisz przetwarzać PDF-y hurtowo i chcesz wyciągnąć tylko konkretne, kluczowe informacje zamiast pełnych danych, ChatPDF będzie świetnym pomocnikiem. Umożliwia on wyodrębnianie danych w formie rozmowy, dzięki czemu dobrze sprawdza się u początkujących.
Oto jak wyodrębniać dane z PDF za pomocą ChatPDF:
- Wejdź na stronę ChatPDF: Otwórz stronę ChatPDF lub odpowiednią stronę platformy.
- Prześlij pliki PDF: Kliknij przycisk „Upload File”, aby przeciągnąć i upuścić dokument PDF lub wybrać go do analizy. Obsługuje różne typy plików, takie jak umowy, prace naukowe czy sprawozdania finansowe.
- Przeanalizuj PDF: Po przesłaniu ChatPDF automatycznie przeanalizuje zawartość pliku i wygeneruje uporządkowane podsumowanie dokumentu. Następnie możesz sprawdzić wyodrębnione kluczowe informacje.
- Zadawaj pytania interaktywnie: Użyj pola tekstowego, aby zadać pytania takie jak „Jaki jest wniosek z tego raportu?” albo „Jaka jest łączna kwota zapisana na fakturze?”. ChatPDF wyodrębni odpowiednie treści na podstawie Twojego zapytania.
- Skopiuj odpowiedzi: ChatPDF zwraca odpowiedzi w oknie czatu. Skopiuj odpowiedź do arkusza kalkulacyjnego, dokumentu lub własnej tabeli — jeśli zależy Ci na bardzo uporządkowanym wyniku (czysty CSV/JSON ze spójnymi kolumnami dla wielu plików), lepszym wyborem będzie Thunderbit albo ChatGPT ze stałym promptem.
ChatPDF oferuje interaktywne doświadczenie, dzięki czemu szczególnie dobrze sprawdza się przy szybkim wyszukiwaniu informacji w dokumentach, na przykład przy znajdowaniu kluczowych szczegółów lub podsumowywaniu treści dokumentu.
ChatGPT
ChatGPT świetnie radzi sobie ze złożonymi danymi semantycznymi, takimi jak analiza klauzul w dokumentach prawnych. To narzędzie jest bardzo elastyczne, dzięki czemu możesz dostosowywać prompty do wyodrębniania konkretnych danych lub analizy treści. Trzeba jednak używać tego samego promptu wielokrotnie przy podobnych zadaniach, a także dobrze rozumieć zasady jego tworzenia.
Oto gotowy prompt, który możesz dostosować do swoich potrzeb (pamiętaj, aby podmienić kolumny na informacje, które chcesz wyodrębnić):
Jesteś teraz PDF Scraperem. Twoim zadaniem jest, gdy otrzymasz plik PDF, wyodrębnić jego treść na podstawie kolumn podanych przez użytkownika. Wynik powinien być plikiem CSV.
Oto kolumny:
1. Imię i nazwisko
2. E-mail
3. Numer telefonu
4. ...
- Zarejestruj się lub zaloguj: Otwórz stronę ChatGPT i załóż konto. Jeśli już je masz, po prostu się zaloguj.
- Prześlij PDF i wpisz zapytanie: Wpisz swoje pytanie bezpośrednio w polu tekstowym — im bardziej konkretne, tym lepiej. Na przykład: „Ten dokument PDF zawiera trzy wykresy, wyeksportuj je jako tabele.”
- Sprawdź i dopracuj wyniki: Zobacz, czy odpowiedź spełnia Twoje oczekiwania. Jeśli trzeba, doprecyzuj wynik, zadając pytania uzupełniające lub modyfikując prompt.
- Eksportuj dane jako Excel lub CSV: Jeśli dane wyodrębnione przez ChatGPT są tym, czego potrzebujesz, wpisz w polu tekstowym: „Eksportuj te dane jako Excel lub CSV.”
- Zapisz wyniki: Kliknij link do pliku udostępniony przez ChatGPT, aby pobrać plik.
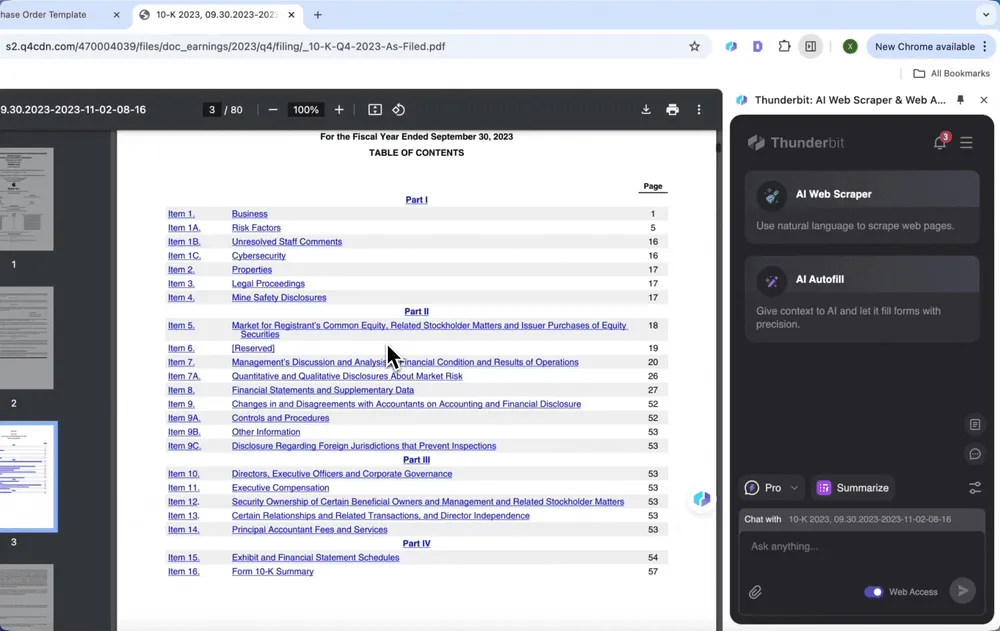
Przykłady praktycznego użycia AI PDF Scrapera
AI PDF Scraper działa jak wszechstronny asystent w pracy — niezależnie od tego, czy zajmujesz się fakturami, umowami, raportami finansowymi czy zamówieniami zakupu. Oto kilka praktycznych scenariuszy, w których pokazuje pełnię możliwości:
Przetwarzanie faktur i paragonów
Przetwarzaj hurtowo faktury i paragony firmowe, wyodrębniając kluczowe informacje, takie jak kwoty i daty, na potrzeby klasyfikacji i archiwizacji.
- Uruchom Thunderbit, kliknij AI Web Scraper, a następnie Bulk Pages
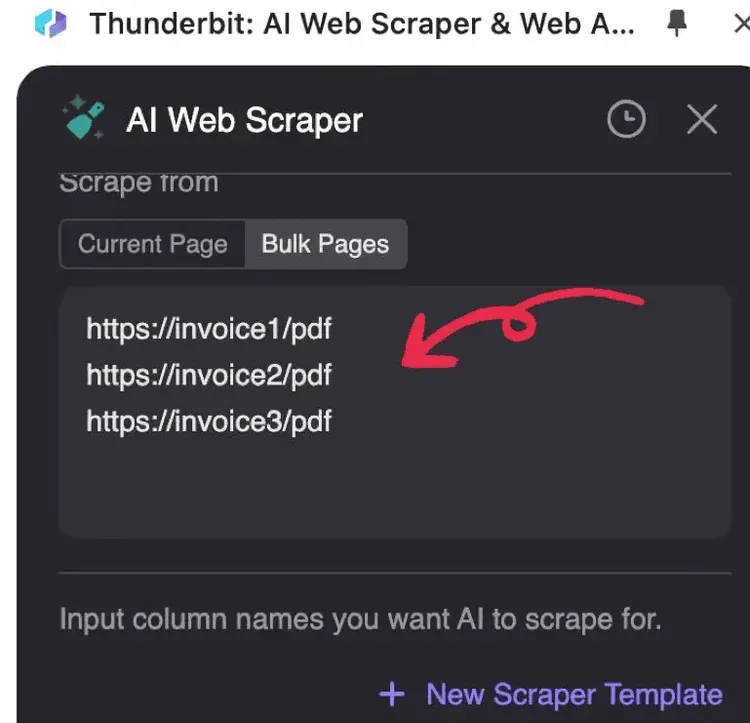
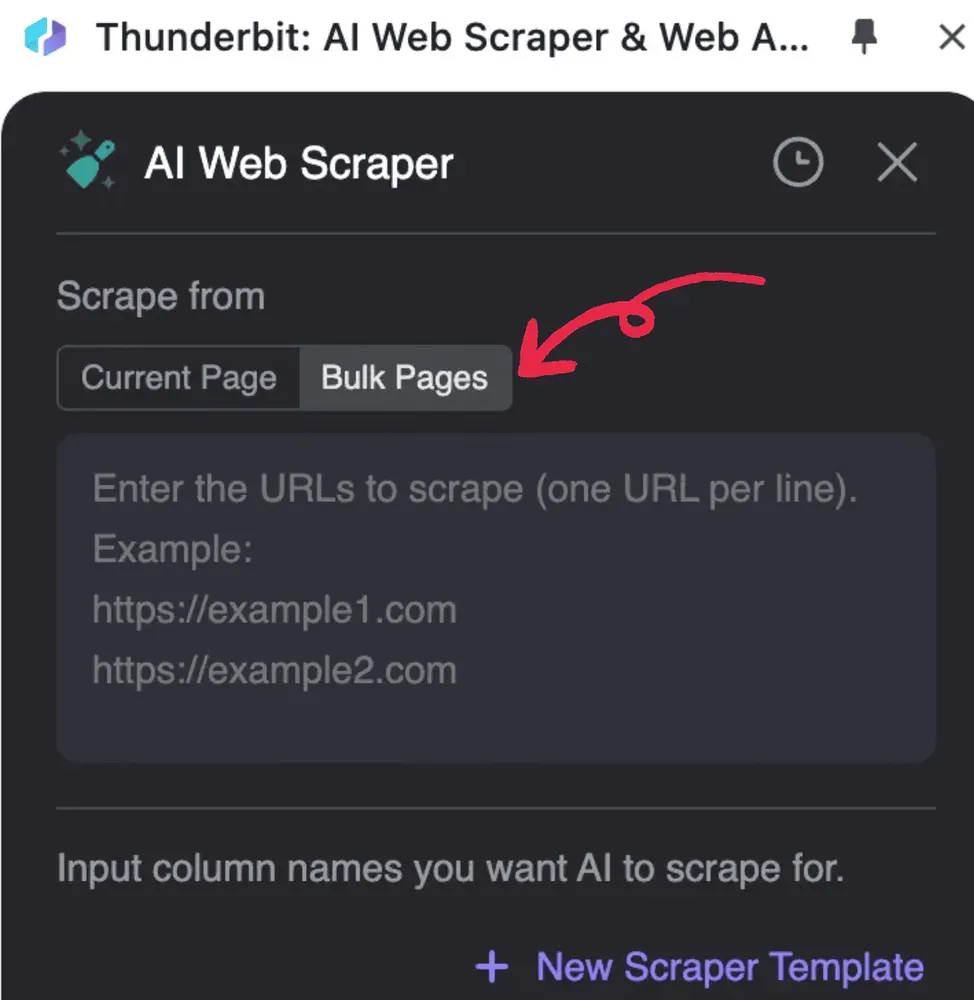 2. Wpisz adresy URL plików PDF, które chcesz przetworzyć, jeden adres w każdej linii
2. Wpisz adresy URL plików PDF, które chcesz przetworzyć, jeden adres w każdej linii
 3. Kliknij AI Suggest Columns (AI odczyta PDF i zasugeruje, jak uporządkować dane)
4. Kliknij Scrape i wyeksportuj dane
3. Kliknij AI Suggest Columns (AI odczyta PDF i zasugeruje, jak uporządkować dane)
4. Kliknij Scrape i wyeksportuj dane
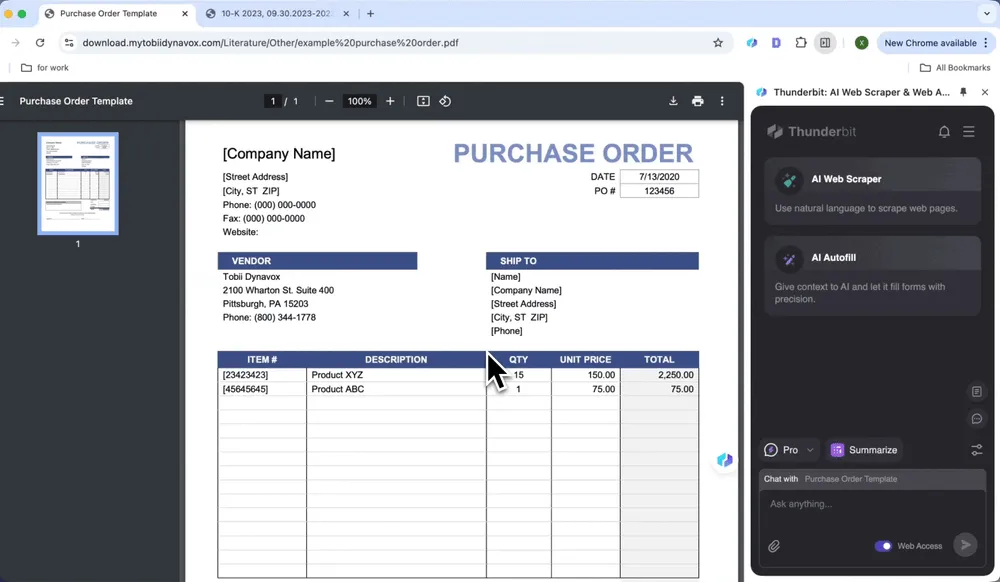
Przetwarzanie zamówień zakupu
Automatycznie identyfikuj pozycje, ilości i ceny jednostkowe w zamówieniach zakupu, generując ustandaryzowane rekordy danych i wyodrębniając dane z PDF-ów, co oszczędza czas ręcznego przetwarzania.
- Otwórz zamówienie zakupu w Chrome i uruchom Thunderbit
- Kliknij AI Web Scraper, a następnie AI Suggest Columns
- Sprawdź wygenerowaną listę nazw i kliknij Scrape
- Kliknij Download CSV
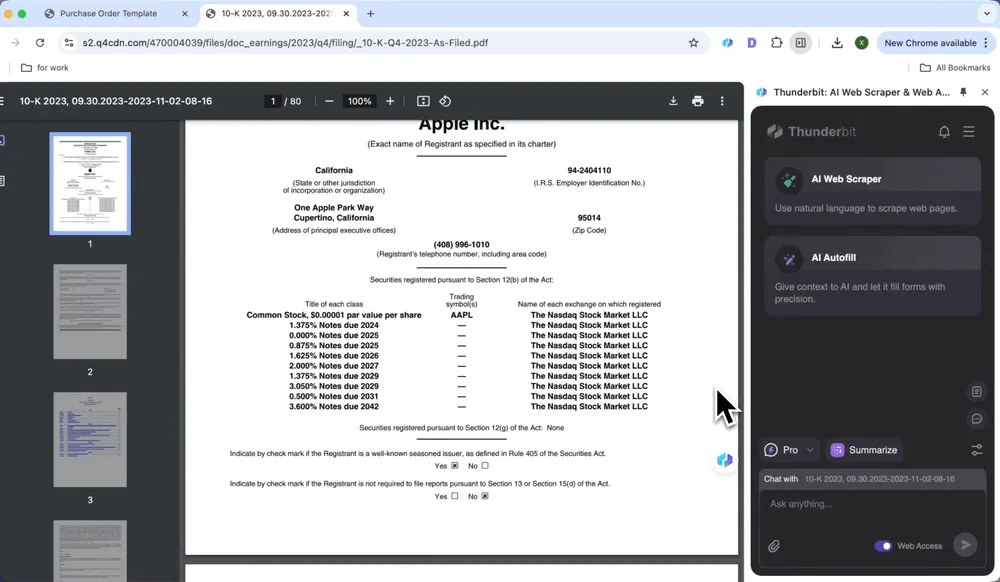
Wyodrębnianie danych finansowych
Wyodrębniaj dane z raportów finansowych jednym kliknięciem, na przykład marże zysku i wyniki sprzedaży, eliminując potrzebę żmudnej ręcznej analizy.
- Otwórz raport finansowy w Chrome i uruchom Thunderbit
- Kliknij Summarize
- Automatycznie wygeneruj podsumowanie kluczowych informacji, w tym treści tekstowych i tabelarycznych
Nie jesteś zadowolony z automatycznie wygenerowanego podsumowania? Możesz ręcznie wprowadzić informacje o projekcie, których potrzebujesz.
- Otwórz raport finansowy w Chrome i uruchom Thunderbit
- Kliknij AI Web Scraper, wpisz nazwy potrzebnych pól, takie jak Net Income, Sales itp.
- Kliknij Scrape, output Table
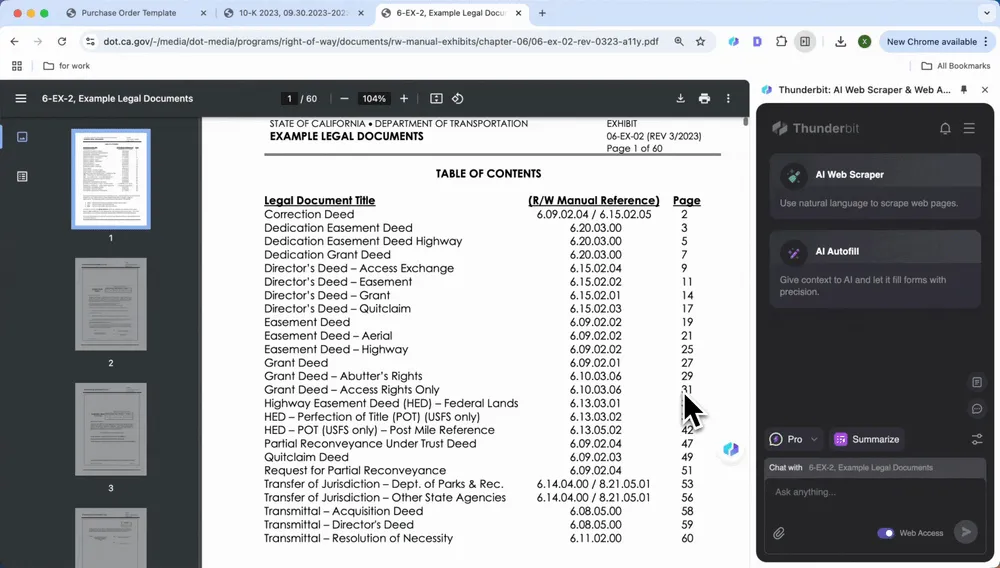
Analiza dokumentów prawnych
Masz problem z klauzulami w umowach i porozumieniach? Narzędzia AI potrafią szybko wskazać warunki płatności, klauzule naruszenia, okresy obowiązywania umowy i inne kluczowe punkty. Wyodrębnij je jednym kliknięciem, aby wygenerować zwięzłe podsumowanie lub listę klauzul, oszczędzając czas i mając pewność, że nic nie zostanie pominięte.
Podobnie jak przy wyodrębnianiu kluczowych informacji z raportów finansowych, możesz otworzyć PDF i kliknąć Summarize, aby jednym kliknięciem zobaczyć warunki płatności, klauzule naruszenia, okresy obowiązywania umowy i inne ważne informacje.
FAQ
-
Czy mogę wyodrębnić dane z wielu PDF-ów jednocześnie?
Tak, zaawansowane narzędzia do PDF scrapingu pozwalają wyodrębniać dane z wielu plików PDF jednocześnie. Ta możliwość przetwarzania wsadowego znacząco przyspiesza pracę w porównaniu z ręcznymi metodami ekstrakcji.
-
Czy PDF Scraper jest darmowy?
Tak, dostępnych jest kilka darmowych narzędzi do PDF scrapingu. Wiele narzędzi online, takich jak Thunderbit i ChatPDF, oferuje darmowe funkcje wyodrębniania stron i danych. Choć niektóre zaawansowane funkcje mogą być płatne, podstawowe możliwości ekstrakcji danych zazwyczaj są darmowe.
-
Czy do korzystania z PDF Scrapera potrzebna jest znajomość programowania?
Nie, wiele AI PDF Scraperów, takich jak Thunderbit, jest zaprojektowanych dla użytkowników bez umiejętności programistycznych. Oferują one intuicyjny interfejs, który pozwala przesłać pliki i wyodrębnić dane w zaledwie kilka kliknięć.
-
Jakie typy dokumentów można przetwarzać za pomocą PDF Scrapera?
PDF Scrapery obsługują różne typy dokumentów, w tym faktury, umowy, raporty finansowe, prace naukowe oraz wszelkie inne treści ustrukturyzowane lub półustrukturyzowane znajdujące się w plikach PDF.
-
Czy moje dane są bezpieczne podczas korzystania z PDF Scrapera?
Renomowane narzędzia do PDF scrapingu stawiają bezpieczeństwo użytkowników na pierwszym miejscu i często spełniają wymogi takich regulacji jak RODO. Zazwyczaj przechowują dane na zaszyfrowanych serwerach i nie mają do nich dostępu bez Twojej zgody.
-
Czy są inne sposoby wyodrębniania danych z PDF?
Istnieje kilka metod wyodrębniania danych z plików PDF poza ręcznym wprowadzaniem danych i skryptami Python. Należą do nich konwertery PDF, które przekształcają pliki do formatów takich jak Excel czy CSV, specjalistyczne narzędzia do ekstrakcji danych z PDF, takie jak Tabula i Excalibur, do dokumentów ustrukturyzowanych, rozwiązania oparte na AI z optycznym rozpoznawaniem znaków (OCR) dla PDF-ów natywnych i skanowanych, a także narzędzia open-source, takie jak Extractous i PymuPDF4llm, zaprojektowane z myślą o wydajnym wyodrębnianiu danych. Każda metoda ma swoje zalety i wady, więc wybór zależy od konkretnych wymagań i wiedzy technicznej użytkownika.
Dowiedz się więcej
- Jak wyodrębnić dane z dowolnej strony internetowej za pomocą AI
- 5 najlepszych narzędzi AI do wyodrębniania danych z PDF-ów
- Jak używać ChatGPT do wyodrębniania danych z PDF-ów
- Darmowy internetowy podsumowywacz PDF
Wypróbuj AI Web Scraper Get Started Free




