
Afgelopen week zat ik 40 minuten te debuggen aan een prima werkend Python-script dat op drie testsites zonder problemen draaide — om er vervolgens achter te komen dat de vierde site achter Cloudflare zat. De scraper bleef maar hangen op een pagina met "Checking your browser…" en gaf alleen challenge-HTML terug. Klinkt bekend?
Als je hier tegenaan bent gelopen, ben je echt niet de enige. gebruiken inmiddels Cloudflare, waaronder op internet. Daarmee is Cloudflare de meest voorkomende blokkade voor iedereen die webdata probeert te verzamelen — of dat nu gaat om leadgeneratie, prijsmonitoring, vastgoedonderzoek of concurrentieanalyse.
Het probleem met de meeste handleidingen is dat ze alle omzeiltechnieken in één lange lijst gooien, zonder te zeggen welke je in jouw situatie het beste als eerste probeert. Deze gids pakt het anders aan: met een gerangschikte beslisboom, eerlijke inschattingen van betrouwbaarheid en een no-code route die de meeste artikelen helemaal overslaan.
- Moeilijkheidsgraad: Beginner tot gemiddeld (afhankelijk van de methode die je kiest)
- Benodigde tijd: ~10–30 minuten voor de no-code route; variabel voor code-methoden
- Wat je nodig hebt: Chrome-browser (voor de no-code route), eventueel Python 3.9+ (voor code-methoden) en een doel-URL
Wat is Cloudflare-beveiliging (en waarom blokkeert het je scraper)?
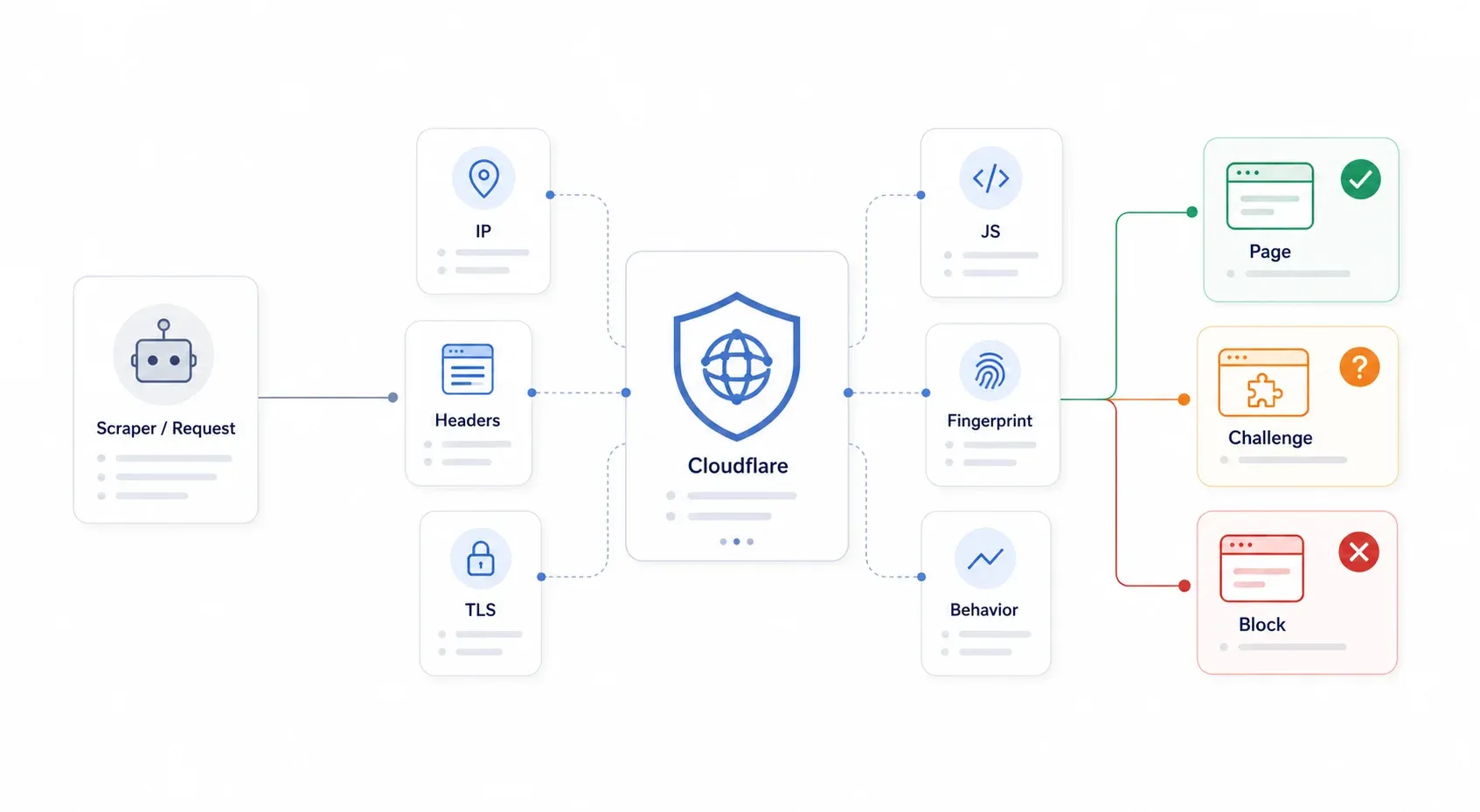
Cloudflare is een reverse proxy die tussen bezoekers en de origin server van een website zit. Elke request komt eerst langs Cloudflare’s edge, en daarna beslist Cloudflare of de pagina wordt geleverd, of de bezoeker een challenge krijgt, of dat de toegang meteen wordt geblokkeerd. Belangrijk om te snappen: Cloudflare hoeft niet te weten dat jouw scraper kwaadaardig is. Het hoeft je request alleen maar als voldoende geautomatiseerd of verdacht te zien.
Cloudflare’s werkt met een gelaagde aanpak — niet één slot, maar een complete beveiligingscontrole. Er wordt gekeken naar IP-reputatie, HTTP-headers, TLS-fingerprints, JavaScript-uitvoering, browser fingerprinting en gedragspatronen. Wanneer je Python requests-library een GET stuurt naar een Cloudflare-beveiligde pagina, loop je op meerdere lagen tegelijk vast: een verkeerde TLS-handshake, geen JavaScript-uitvoering, geen cookies, geen browser fingerprint. Daarom werkte simpele header-spoofing jaren geleden misschien nog, maar nu niet meer.
De meest voorkomende signalen die je ziet zijn: 403 Forbidden, 503 met "Checking your browser…", 1020 Access Denied, eindeloze challenge-loops, Turnstile-widgets die nooit oplossen en HTML-challengepagina’s terwijl je eigenlijk JSON verwachtte.
Passieve detectie: wat Cloudflare controleert vóór de pagina überhaupt laadt
Nog vóór je de pagina ziet, heeft Cloudflare’s passieve laag je request al beoordeeld:
- IP-reputatie: Datacenter-IP’s, cloud-ranges en bekende proxy-uitgangen worden gemarkeerd. Residential en mobiele carrier-IP’s worden . Community-rapporten in 2026 beschrijven consequent dat lokaal browsen via residential gewoon werkt, terwijl Docker- of VPS-omgevingen worden geblokkeerd.
- HTTP-headeranalyse: Cloudflare vergelijkt je User-Agent, Accept-Language, header-volgorde en HTTP-versie. Een mismatch — bijvoorbeeld zeggen dat je Chrome 136 bent terwijl je TLS-handshake schreeuwt “Python” — valt meteen op.
- TLS fingerprinting (JA3/JA4): Tijdens de TLS-handshake laat je client een patroon zien van ondersteunde cipher suites, extensies en protocolvoorkeuren. vat dat samen in één identifier. Een echte Chrome en een Python
requests-script zien er totaal anders uit. - HTTP/2 fingerprinting: Browsers en HTTP-libraries verschillen in HTTP/2 SETTINGS-frames, pseudo-header-volgorde en prioriteitsgedrag. Cloudflare’s werk rond kijkt verder dan één request en volgt patronen tussen requests door de tijd heen.
- AI Labyrinth: Dit is Cloudflare’s nieuwere val. In plaats van verdachte crawlers gewoon te blokkeren, die geloofwaardig lijken maar crawler-resources verspillen. Je scraper merkt misschien niet eens dat hij in de val zit.
Actieve detectie: challenges die in je browser draaien
Als passieve controles geen sluitend oordeel geven, schakelt Cloudflare over op actieve challenges:
- JavaScript-challenges: De klassieke tussenpagina met "Checking your browser…". Cloudflare’s draaien onzichtbare scripts om geautomatiseerde requests te herkennen.
- Turnstile: Cloudflare’s alternatief voor CAPTCHA. zijn onder andere Managed, Non-Interactive en Invisible. Het analyseert muisbewegingen, browseromgeving, TLS-fingerprint en meer — zonder per se een zichtbare puzzel te tonen.
- Canvas- en WebGL-fingerprinting: Deze checks pakken headless browsers die anders renderen dan echte browsers.
- Gedrags-signalen: Timing van requests, scrollpatronen, klikvolgorde. Een scraper die in 3 seconden 50 pagina’s ophaalt zonder muisbeweging ziet er totaal niet menselijk uit.
De praktische conclusie: als Cloudflare al is opgeschaald naar een actieve challenge, dan komen gewone HTTP-clients zoals requests, httpx of zelfs curl_cffi er niet doorheen. Dan heb je iets nodig dat een echte browseromgeving uitvoert.
Cloudflare-beveiligingsniveaus: waarom hetzelfde script op de ene site werkt en op de andere faalt
Dit is precies wat de meeste bypass-gidsen missen. Cloudflare-beveiliging is niet overal hetzelfde. Een site op Cloudflare’s gratis plan met "Security Level: Medium" is een totaal andere uitdaging dan een Enterprise-site met Bot Management en Turnstile ingeschakeld. Hetzelfde script dat de ene site moeiteloos passeert, loopt bij de andere keihard vast.
| Cloudflare-niveau | Typische beveiliging | Moeilijkheid om te omzeilen | Wat meestal werkt |
|---|---|---|---|
| Gratis plan (lage beveiliging) | Bot Fight Mode, basis-WAF-regels, IP-reputatie | ⭐ Laag | Interne API ontdekken, curl_cffi met juiste headers, echte browsersessie |
| Pro plan (gemiddeld) | Super Bot Fight Mode, Managed Challenge, JavaScript-detectie | ⭐⭐ Gemiddeld | Echte browsersessie, stealth browser automation, residential proxies |
| Business | Sterkere WAF, Bot Analytics, strengere challenges op belangrijke paden | ⭐⭐⭐ Gemiddeld–hoog | Extractie binnen browsersessie, sessiebehoud, residential/mobile proxies, betaalde scraping-API’s |
| Enterprise / Bot Management | Botscores, JA3/JA4-velden, regels per endpoint, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Hoog | Interne API (indien toegankelijk), tools voor echte gebruikerssessies, scraping-API’s van provider-niveau |
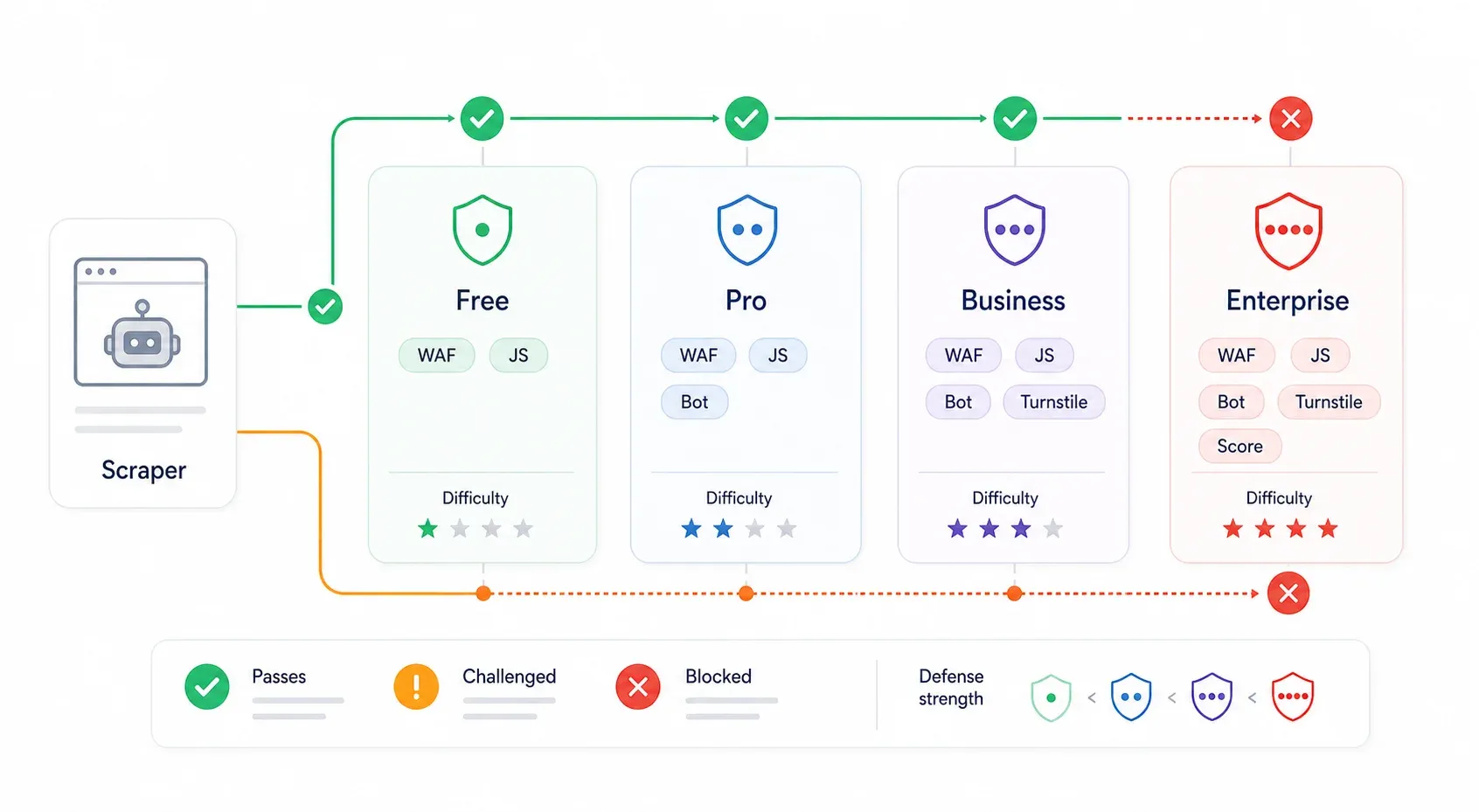
vermeldt Free vanaf $0, Pro vanaf $20/maand, Business vanaf $200/maand en Enterprise met maatwerkprijzen. is de eenvoudige schakelaar voor het Free-plan; voegt extra controles toe voor Pro/Business; Enterprise Bot Management biedt gedetailleerde botscores en regels per endpoint.
Hoe je grofweg bepaalt met welk niveau je te maken hebt: Een 403 met een Cloudflare-blokkade zonder challenge-script betekent vaak WAF- of fingerprint-afwijzing. Een cf-turnstile-div of challenges.cloudflare.com/turnstile/v0/api.js-script wijst op Turnstile. Een tussenpagina met "Checking your browser" betekent meestal een Managed Challenge. Fouten die alleen op specifieke paden optreden nadat de homepage wel werkt, duiden vaak op endpoint-specifieke WAF- of Bot Management-regels.
Bepaal het beveiligingsniveau vóór je een aanpak kiest. Dat scheelt uren debuggen.
De "probeer dit eerst"-beslisboom voor het omzeilen van Cloudflare
In plaats van willekeurig methoden uit te proberen, kun je beter een geordende aanpak volgen. Begin met de makkelijkste en meest betrouwbare optie, en ga alleen een stap verder als dat nodig is:
| Stap | Probeer eerst dit | Waarom | Als het faalt → |
|---|---|---|---|
| 1 | Controleer of er een interne/ongedocumenteerde API is | Omzeilt Cloudflare volledig; het snelst en het betrouwbaarst | Stap 2 |
| 2 | Gebruik een no-code tool met ingebouwde browser-rendering (bijv. Thunderbit) | Geen setup, behandelt JS-challenges automatisch | Stap 3 |
| 3 | TLS-fingerprint impersonation (curl_cffi) | Snel, lichtgewicht, geen browser nodig | Stap 4 |
| 4 | Stealth browser automation (SeleniumBase UC / Puppeteer stealth) | Kan JS-challenges + fingerprinting aan | Stap 5 |
| 5 | FlareSolverr + Docker | Open source, servervriendelijk | Stap 6 |
| 6 | Betaalde scraping-API (ScrapingBee, ZenRows, Scrapfly, enz.) | Haalt de wapenwedloop volledig van je bord | — |
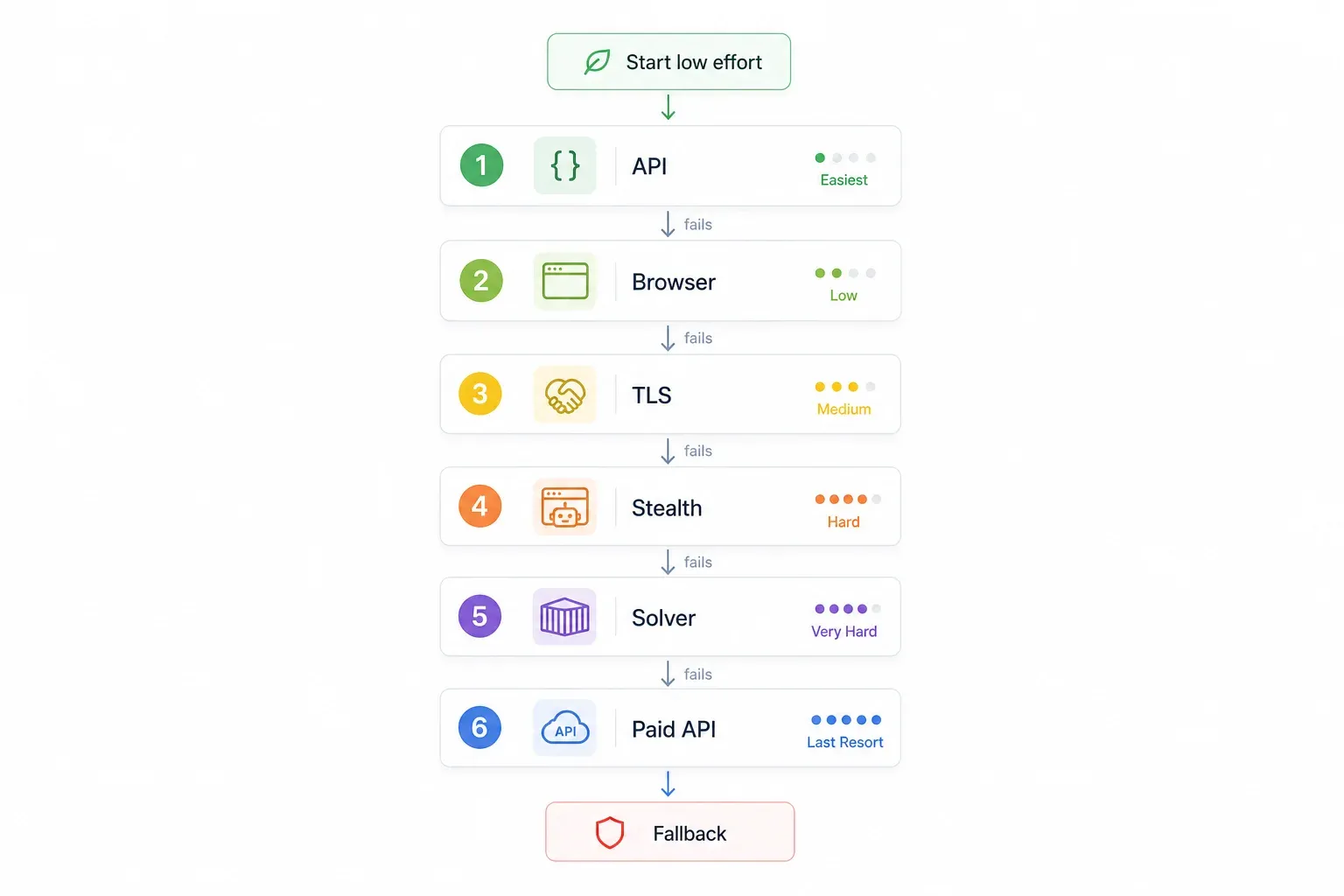
De logica: eerst gratis en laagdrempelig, code- en betaalopties pas als laatste. Spring gewoon naar de stap die past bij jouw situatie.
Een meldde dat curl_cffi 16 van 20 geteste domeinen haalde (80%), FlareSolverr ongeveer 55–70% dekte en betaalde proxy-aggregators gemiddeld rond 97% succes haalden — maar dezelfde thread waarschuwt dat die cijfers verschuiven zodra Cloudflare updates uitrolt. Zie succespercentages dus als richtinggevend, niet als garantie.
Stap 1: sla de strijd over — vind de interne API achter Cloudflare
Vier verschillende forumberichten die ik tegenkwam raden aan om de interne API van een site te vinden in plaats van rechtstreeks tegen Cloudflare te vechten. En eerlijk gezegd: dat is de slimste eerste zet. Als de site een interne API heeft, omzeil je Cloudflare volledig — geen trucs, geen fingerprint-spoofing, geen stealth-plugins.
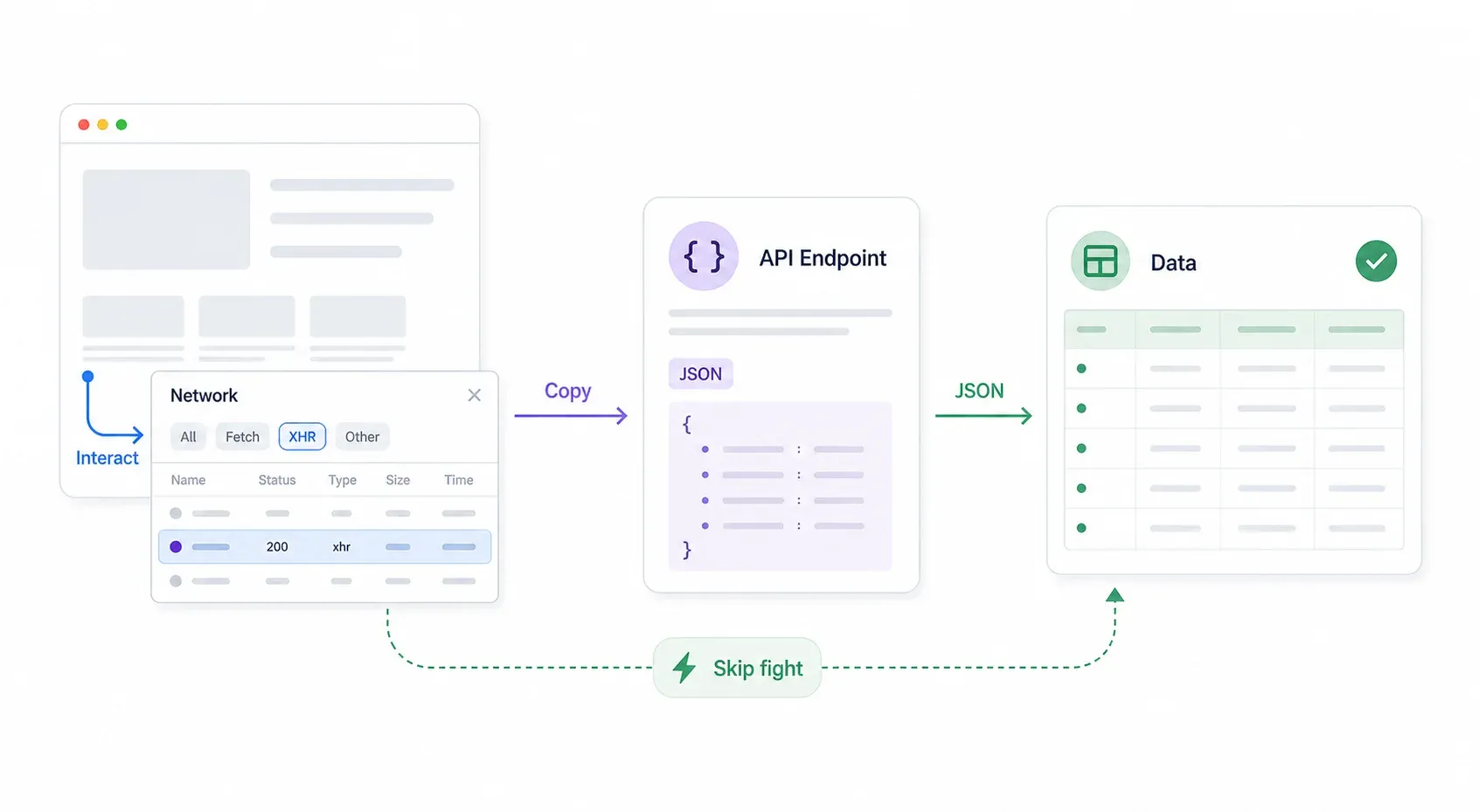
De systematische aanpak:
- Open Chrome DevTools → ga naar het tabblad Network → filter op XHR/Fetch.
- Interageer met de pagina: zoek, filter, pagineer, scroll. Let op JSON-responses die in het Network-tabblad verschijnen.
- Inspecteer de request-URL en headers. Vaak heeft het API-endpoint geen Cloudflare-bescherming of veel lichtere bescherming dan de frontendpagina.
- Rechtermuisknop op de request → Copy → Copy as cURL. Plak dit in je terminal of Postman en test het.
- Implementeer de request in Python (met
requestsofcurl_cffi) met dezelfde headers, cookies en queryparameters.
Als de API gestructureerde JSON teruggeeft, heb je misschien helemaal geen traditionele scraper nodig. Een beschreef precies zo’n situatie: een gebruiker die ondanks curl_cffi door Cloudflare werd geblokkeerd, ontdekte dat de enige werkbare route was om de API-response direct af te vangen.
Praktische tip: Zodra de gekopieerde cURL werkt, begin dan onnodige headers weg te halen. Headers zoals sec-ch-ua, cookies, CSRF-tokens en referer kunnen nodig zijn; browser-cachecontrols meestal niet. Houd de TLS-fingerprint consistent met de User-Agent als je van browser-cURL naar code gaat.
Beperkingen: Niet elke site heeft een toegankelijke API. Sommige API’s vereisen authenticatie, CSRF-tokens, gesigneerde request-parameters of cookies die aan een sessie zijn gekoppeld. Maar als het werkt, is dit de methode met ongeveer 99% succes en vrijwel geen onderhoud.
Stap 2: de no-code route — omzeil Cloudflare met een browser-extensie (Thunderbit)
Bijna elke concurrerende gids gaat ervan uit dat de lezer Python of JavaScript schrijft. Maar op dit zoekwoord zoeken ook salesteams die leadlijsten bouwen, e-commerce teams die concurrentieprijzen volgen en vastgoedanalisten die pandgegevens verzamelen. Die mensen willen geen Docker-containers opzetten.
Een Chrome-extensie zoals handelt veel Cloudflare-controles van nature af, omdat hij in je echte browsersessie draait. Daardoor erft hij Chrome’s echte TLS-fingerprint, je cookies, je loginstatus en je gedrags-signalen — precies wat Cloudflare vertrouwt. Geen stealth-plugins, geen xvfb-run, geen terminalcommando’s.
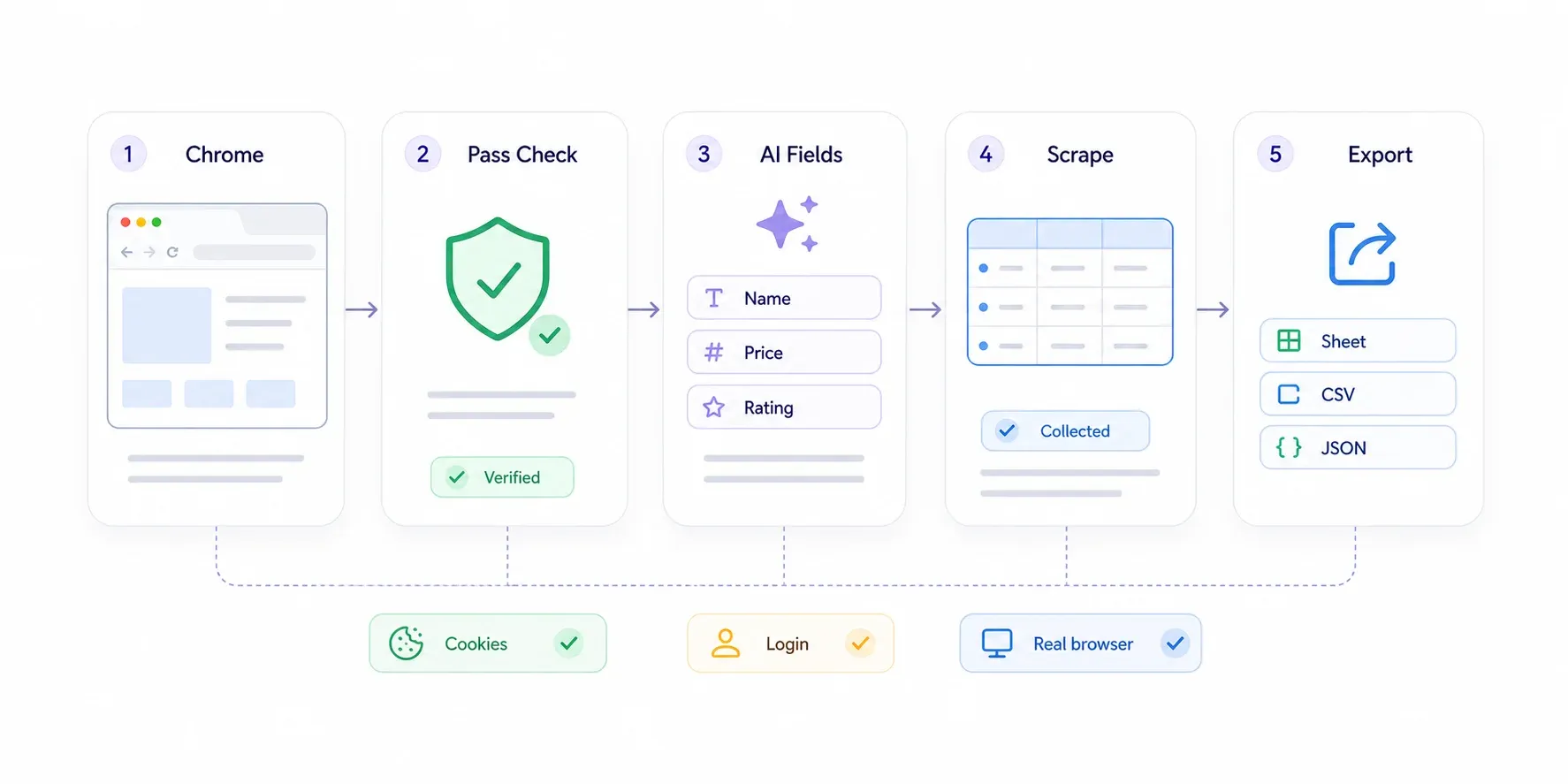
Stap-voor-stap uitleg
- Installeer de vanuit de Chrome Web Store.
- Open de Cloudflare-beveiligde pagina in Chrome. Als Cloudflare je een challenge geeft, doorloop die dan als normale gebruiker — klik het Turnstile-vakje aan, wacht tot de "Checking your browser"-pagina verdwijnt. Je bent een echte persoon in een echte browser; Cloudflare laat je door.
- Klik op "AI Suggest Fields" in de Thunderbit-zijbalk. De AI scant de pagina en stelt datavelden voor zoals "Product Name", "Price", "Rating" of wat dan ook relevant is.
- Controleer de voorgestelde velden. Verwijder wat je niet nodig hebt en voeg aangepaste velden toe door in gewoon Engels te beschrijven wat je wilt.
- Klik op "Scrape." Thunderbit haalt de data uit de zichtbare pagina.
- Exporteer naar Google Sheets, Excel, Airtable, Notion, CSV of JSON.
Voor pagina’s met paginering verwerkt Thunderbit zowel klik-gebaseerde paginering als infinite scroll. Voor detailpagina’s (stel, je hebt een lijst met productlinks en wilt specificaties van elke afzonderlijke pagina halen) gebruik je — Thunderbit bezoekt elke gelinkte detailpagina en vult je tabel aan.
In mijn ervaring kost deze workflow voor een dataset van 50–100 rijen meestal zo’n 5–10 minuten, van installatie tot geëxporteerd spreadsheet.
Wanneer browsergebaseerd scrapen het best werkt (en wanneer niet)
Ik wil eerlijk zijn over de beperkingen. Browsergebaseerd scrapen is gekoppeld aan je sessiesnelheid. Het is ideaal voor middelgrote taken — van honderden tot enkele duizenden pagina’s. Als je miljoenen pagina’s volgens een schema moet crawlen, wil je code- of API-methoden gebruiken.
Thunderbit’s Cloud Scraping-optie kan de snelheid verhogen door tot 50 pagina’s tegelijk te scrapen voor publiek toegankelijke sites. En voor developer-workflows of grotere schaal verwerkt Thunderbit’s JavaScript-rendering, anti-botbeveiliging en proxyrotatie met batchverwerking van maximaal .
Maar voor zakelijke gebruikers die leads, prijsdata of vastgoedaanbiedingen op redelijke schaal scrapen? Vaak is dit de enige methode die je nodig hebt. Geen code, geen proxies, geen onderhoud.
Stap 3: TLS fingerprint spoofing met curl_cffi (lichte code-aanpak)
Als je prettig met Python werkt en de no-code route niet in je workflow past, is de lichtste code-optie. Het is een Python-binding rond libcurl die echte browser-TLS-fingerprints kan nabootsen. In tegenstelling tot requests of httpx lijkt je TLS-handshake op die van Chrome of Safari.
In 2026 zijn onder meer chrome136, safari184 en veel historische profielen. De library had , dus hij wordt actief onderhouden.
Wanneer gebruiken: Sites met Cloudflare-beveiliging op Free- of Pro-niveau die vooral leunen op passieve fingerprinting — dus geen actieve JavaScript-challenge en geen Turnstile.
Basisvoorbeeld:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Iets waar mensen vaak op vastlopen: Houd je User-Agent consistent met het impersonation-doel. Als je Chrome 136 nabootst, stuur dan geen User-Agent-string voor Chrome 120. Die mismatch is een signaal.
Beperkingen: curl_cffi voert geen JavaScript uit. Als de site een "Checking your browser"-challenge of een Turnstile-widget toont, werkt deze methode niet. Ook is het niet handig voor sites die browser-challenge-gebonden cookie-sessiegegevens vereisen. Zie het als een snelle, goedkope eerste poging voor alleen passieve beveiliging.
Alternatieven in dezelfde familie: tls-client en curl-impersonate bieden vergelijkbare TLS-impersonatiemogelijkheden.
Stap 4: stealth browser automation (Puppeteer Stealth en SeleniumBase UC)
TLS-spoofing schiet tekort zodra een site JavaScript-uitvoering, actieve challenges of Turnstile vereist. Dan heb je een volledige browser nodig. Twee hoofdopties:
- SeleniumBase UC Mode (Python): De als een manier om automatisering menselijker te laten lijken en anti-botdiensten te omzeilen. Er staan voorbeelden in voor het omgaan met Cloudflare Turnstile.
- Puppeteer met
puppeteer-extra-plugin-stealth(Node.js): Nog steeds breed gebruikt, maar . Community-rapporten noemen faalgevallen door CDP-detectieflags (Chrome DevTools Protocol) en niet-passende browserprofielen.
Beide tools starten een echte Chromium-browser, maar patchen herkenbare automatiseringssignalen: navigator.webdriver, WebGL-metadata, pluginlijsten en meer.
Configuratietips die echt tellen:
- Gebruik headed mode (niet headless). SeleniumBase waarschuwt in de documentatie dat UC Mode in headless mode detecteerbaar is. Gebruik op Linux-servers een virtueel display.
- Willekeurige viewportgrootte en User-Agent, maar zorg dat ze onderling kloppen en passen bij de geolocatie van je proxy.
- Voeg realistische vertragingen toe tussen acties. Een gat van 200 ms tussen paginaladingen schreeuwt “bot”.
- Behoud cookies en browserprofielen nadat je de eerste challenge hebt doorstaan. Los de challenge niet opnieuw op bij elk request.
- Combineer met residential proxies voor een betere IP-reputatie.
Het risico van deze aanpak zit in het onderhoud. Browser-automationstacks breken wanneer Chrome update, Cloudflare een nieuw signaal toevoegt, een stealth-plugin achterloopt of een target path-specifieke Turnstile toevoegt. Een liet zien dat veel stealth-browseropstellingen fingerprint-tests falen door "franken-fingerprint"-combinaties — bijvoorbeeld een mismatch tussen tijdzone, taal en proxygeografie.
Deze methode is krachtig, maar operationeel duur. Reserveer tijd voor doorlopende fixes.
Proxyrotatie: waarom IP net zo belangrijk is als fingerprints
Zelfs met perfecte browser-stealth triggert te veel verkeer vanaf één IP rate limits. Cloudflare vertrouwt residential en mobile IP’s veel meer dan datacenter-IP’s.
- Residential proxies: bij instapvolumes in 2026. Meer vertrouwen, maar duurder.
- Datacenter proxies: Goedkoper, maar .
- Rotatiestrategie: Rotate per sessie, niet per request. Rotatie per request breekt sessiegebonden cookies en
cf_clearance. Houd IP, cookies en fingerprint binnen één sessie consistent.
Er bestaat geen magische "minimale proxy-poolgrootte". Een lead-scrape met laag volume kan werken met een handvol sticky residential sessies; een prijsmonitor met hoog volume kan honderden exits plus retry-logica nodig hebben.
Stap 5: FlareSolverr — de open-source Cloudflare bypass-server
is een open-source proxyserver die Chromium met undetected-chromedriver in een Docker-container gebruikt om Cloudflare-challenges op te lossen en cookies/headers terug te geven voor hergebruik. Er kwam , dus het project wordt nog steeds actief onderhouden.
Wanneer gebruiken: Server-side scraping pipelines waarbij je een blijvende challenge-oplossingsservice nodig hebt — bijvoorbeeld een geautomatiseerde taak die elke nacht draait en verse cf_clearance-cookies nodig heeft.
Hoe het werkt: Je scraper stuurt een URL naar de API van FlareSolverr. FlareSolverr opent de pagina in een browser, probeert de challenge op te lossen en geeft de HTML plus cookies terug. Die cookies kun je daarna hergebruiken in je gewone HTTP-client voor vervolgrequests.
Setup in het kort: Docker Compose, container starten en POST-requests sturen naar het lokale API-endpoint. .
Beperkingen die ik vooraf graag noem:
- Kan interactieve Turnstile-challenges of Enterprise Bot Management niet betrouwbaar oplossen.
- en laten inconsistent gedrag zien: gemiste challenge-detectie, Turnstile-timeouts, crashende pagina’s.
- Vereist Docker-infrastructuur en doorlopend onderhoud.
- Zwaar qua resources — elke challenge-oplossing start een browsercontext.
Geschatte betrouwbaarheid: 60–80% op targets met middelmatige beveiliging. Lager voor Enterprise, hoger voor eenvoudigere challengepagina’s. Als FlareSolverr niet genoeg is, is het tijd om betaalde API’s te overwegen.
Stap 6: betaalde scraping-API’s die Cloudflare voor je afhandelen
Soms is de rekensom gewoon simpel: het onderhouden van je eigen stealth-infrastructuur kost meer uren van engineers dan een abonnement. Betaalde scraping-API’s nemen de hele wapenwedloop over van een gespecialiseerde provider — jij stuurt een URL, zij regelen fingerprinting, proxies, challenge-oplossing en retries.
Zo vergelijk je ze:
| Provider | Cloudflare-ondersteuning | JS-rendering | Residential proxies | Gestructureerde output | Prijsmodel |
|---|---|---|---|---|---|
| ScrapingBee | Ja | Ja | Ja | Alleen HTML | Credits per request |
| ZenRows | Ja (claimt >99% succes) | Ja | Ja (premium) | HTML, sommige parsing | CPM met multipliers |
| Scrapfly | Ja (vermeldt CF, Akamai, DataDome) | Ja | Ja | HTML, sommige parsing | Credit-based |
| Browserless | Ja | Ja (headless Chrome) | Ja (ingebouwd) | HTML, screenshots | Unit-based |
| Thunderbit API | Ja | Ja | Ja | Gestructureerde JSON/CSV met AI-schema | Gratis tier + betaalde plannen |
Wanneer dit logisch is: Scraping op hoog volume, enterprise-betrouwbaarheidseisen, of als je team geen zin heeft om scraping-infrastructuur te onderhouden. Kostenindicatie: grofweg $30–$500+/maand voor klein tot middelgroot gebruik, oplopend voor enterprise-volumes.
De Thunderbit API verdient hier aparte vermelding, omdat hij gestructureerde data uitspuugt en niet alleen ruwe HTML. Het kan tot 50 URL’s per request in batch verwerken en JSON/CSV teruggeven op basis van een AI-gedreven schema — handig als je schone, direct analyseklare data nodig hebt in plaats van HTML die je zelf nog moet parsen.
Eerlijke betrouwbaarheids-score: wat echt werkt (en wat stukgaat)
Ik heb in 2025–2026 community-rapporten, GitHub-issues en vendorclaims gevolgd. Wat volgt is een nuchtere vergelijking. Dit zijn richtinggevende schattingen, geen laboratoriumbenchmarks:
| Methode | Geschat succespercentage | Onderhoudsbelasting | Breekt wanneer… | Kosten |
|---|---|---|---|---|
| Interne API (als die bestaat) | ~90–99% | Laag | API verandert, authenticatie wordt toegevoegd, tokens worden gesigneerd | Gratis |
| Browserextensie (Thunderbit) | ~85–95% (echte sessie) | Laag (AI past zich aan layoutwijzigingen aan) | Site vereist een speciale auth-flow, agressieve Turnstile per actie | Gratis tier beschikbaar |
curl_cffi / TLS-spoofing | ~70–85% | Gemiddeld (fingerprint-updates) | Cloudflare roteert JA3-controles, actieve JS-challenge vereist | Gratis |
| Puppeteer + stealth-plugin | ~70–90% | Hoog (plugin-updates lopen achter) | CDP-detectie, nieuwe fingerprint-signalen, headless-detectie | Gratis + proxykosten |
| FlareSolverr | ~60–80% | Hoog (Docker, dependency-drift) | Enterprise-beveiliging, Turnstile-interactie | Gratis + infrastructuurkosten |
| Betaalde scraping-API | ~85–95% | Laag (provider onderhoudt alles) | Provider is niet bijgewerkt; budget overschreden | ~$30–500+/maand |
De belangrijkste kolom is niet het succespercentage — het is "Breekt wanneer". Elke methode heeft een faalmodus. De beste strategie is de minst arbeidsintensieve methode kiezen die werkt voor jouw target, en een fallback-plan achter de hand houden.
Er is geen permanente oplossing. Cloudflare blijft continu updaten. De wapenwedloop is echt.
Tips om onder Cloudflare’s radar te blijven (ongeacht de methode die je gebruikt)
Welke methode je ook kiest, met een paar gewoontes blijf je langer buiten Cloudflare’s vizier:
- Respecteer rate limits. Voeg realistische vertragingen toe tussen requests — minimaal 2–5 seconden voor menselijk browsegedrag. Een site op machine-snelheid bestoken is de snelste manier om geblokkeerd te worden.
- Houd je fingerprint consistent. User-Agent, TLS-fingerprint, browserversie, tijdzone, locale en IP-geografie moeten allemaal hetzelfde verhaal vertellen. Een Chrome 136 User-Agent vanaf een Duits IP met
en-USlocale en een Python TLS-handshake is gewoon tegenstrijdig. - Herbruik cookies en sessies nadat je een challenge hebt gepasseerd. Los de challenge niet bij elk request opnieuw op.
- Wissel niet van IP midden in een sessie. Cloudflare volgt sessiecontinuïteit.
- Gebruik residential of mobile IP’s wanneer de use-case en het budget dat rechtvaardigen.
- Monitor soft blocks: challenge-HTML terwijl je JSON verwachtte, lege tabellen, login-redirects of pagina’s die verdacht veel lijken op -honeypots.
- Vermijd piekuren wanneer sitebeheerders WAF-regels mogelijk aanscherpen.
- Bouw fallback-routes: eerst API → dan browser-sessie → dan betaalde provider.
Specifiek voor Thunderbit-gebruikers: de AI past zich automatisch aan wijzigingen in de paginalayout aan, dus je bent minder tijd kwijt aan het onderhouden van CSS-selectors en meer tijd aan het daadwerkelijk gebruiken van de data.
Korte opmerking over juridische en ethische overwegingen
Niet het hoofdonderwerp van dit artikel, maar belangrijk genoeg om niet over te slaan.
Het scrapen van publiek beschikbare data heeft — de CFAA-redenering in hiQ v. LinkedIn hield stand na terugverwijzing door het Supreme Court, al schikten de partijen in 2022 en is de situatie genuanceerd. Recente voorbeelden zijn onder meer in 2025 vanwege vermeend scrapen van gebruikersreacties, en .
In de EU is de AVG/GDPR van toepassing zodra persoonsgegevens in het spel zijn, en de legt specifieke verplichtingen op rond .
Praktische vuistregels:
- Controleer altijd de Gebruiksvoorwaarden van de site.
- Cloudflare-bescherming is een signaal dat de eigenaar geautomatiseerde toegang wil sturen — respecteer dat.
- Verzamel geen persoonsgegevens zonder legitieme grondslag.
- Voor commerciële of grootschalige workflows kies je bij voorkeur officiële API’s, gelicentieerde data of schriftelijke toestemming als die beschikbaar zijn.
- Bij twijfel: raadpleeg juridisch advies voor jouw specifieke use-case en jurisdictie.
Thunderbit is ontworpen voor legitieme zakelijke use-cases — leadgeneratie, prijsmonitoring, marktonderzoek — met publiek toegankelijke data.
Afronding: wat je eerst probeert en wat daarna
De grootste tijdsbesparing in dit hele artikel is niet een tool of code-snippet — het is de beveiligingslaag identificeren vóórdat je begint. Alleen dat al voorkomt uren debuggen aan een methode die sowieso nooit had gewerkt.
Begin hier:
- Controleer of er een interne API is (gratis, snel en vaak over het hoofd gezien).
- Als je een zakelijke gebruiker bent die geen code schrijft, probeer — je echte browsersessie is je sterkste troef tegen Cloudflare.
- Als je ontwikkelaar bent en de target alleen passieve fingerprinting gebruikt, probeer
curl_cffi. - Schakel alleen over naar stealth browsers, FlareSolverr of betaalde API’s als de eenvoudigere methoden niet werken.
Geen enkele methode is permanent. Combineer de juiste tool voor jouw schaal met een fallback-plan, en je zult veel minder tijd kwijt zijn aan staren naar 403-pagina’s.
Als je dieper wilt gaan, hebben we op de Thunderbit-blog geschreven over , en . En als je de extensie in actie wilt zien, bekijk dan het voor walkthrough-video’s.
FAQ's
1. Kun je Cloudflare-beveiliging volledig omzeilen?
Geen enkele methode garandeert 100% succes, vooral niet tegen Enterprise Bot Management met Turnstile, JA4-fingerprinting en AI Labyrinth. De betrouwbaarste aanpak combineert echte browser-fingerprints met goede IP-reputatie. Het vinden van een interne API komt het dichtst bij een “volledige” bypass, omdat je Cloudflare dan helemaal overslaat — maar niet elke site heeft er een.
2. Is het legaal om Cloudflare te omzeilen bij scraping?
Dat hangt af van je jurisdictie, de Gebruiksvoorwaarden van de site en welke data je verzamelt. Het scrapen van publiek beschikbare data heeft in sommige contexten gunstige Amerikaanse jurisprudentie (hiQ v. LinkedIn), maar technische toegangscontroles omzeilen, ToS schenden of persoonsgegevens verzamelen zonder legitieme basis kan juridisch risico opleveren. Voor commerciële workflows: geef waar mogelijk de voorkeur aan officiële API’s of gelicentieerde data, en vraag juridisch advies als je twijfelt.
3. Wat is de makkelijkste manier om Cloudflare te omzeilen zonder code?
Browserextensies zoals die in je echte Chrome-sessie draaien, handelen Cloudflare-challenges automatisch af — jij gebruikt de site als normale gebruiker en laat daarna de extensie de data extraheren en exporteren. Geen Python, geen Docker, geen proxyconfiguratie.
4. Waarom werkt mijn scraper op sommige Cloudflare-sites wel en op andere niet?
Cloudflare’s beveiligingsniveau verschilt enorm per plan (Free, Pro, Business, Enterprise) en configuratie. Een methode die werkt tegen eenvoudige JS-challenges op een Free-site kan falen tegen Turnstile of volledig Bot Management op een Enterprise-site. Bepaal dus eerst de beveiligingslaag — kijk of je een simpele JS-check, een Managed Challenge of een Turnstile-widget ziet — voordat je je bypass-aanpak kiest.
5. Hoe vaak breken Cloudflare-bypassmethoden?
Code-gebaseerde methoden zoals stealth-plugins en TLS-spoofing kunnen op lastige targets om de paar weken tot maanden achteruitgaan zodra Cloudflare detectie-updates uitrolt. Betaalde API’s en tools die op echte browsersessies werken zijn doorgaans robuuster, omdat ze op infrastructuur- of sessieniveau meebewegen. Interne API’s breken zelden, tenzij de site zijn backend herontwerpt of het authenticatiemodel wijzigt. De veiligste langetermijnstrategie is meerdere fallback-methoden hebben in plaats van op één aanpak te vertrouwen.
Meer lezen