Firecrawl is uitgegroeid tot een van de meest gehypte webscraping-API’s onder AI-ontwikkelaars — , steun van Y Combinator en een klantenlijst met onder andere Shopify, Zapier en Apple. Maar als je de prijsdocumentatie, klachten van gebruikers, onafhankelijke benchmarks en praktijkvoorbeelden naast elkaar legt, lopen het grote verhaal en de echte ervaring behoorlijk uiteen.
Deze Firecrawl-review is niet zomaar weer een opsomming van functies. Heb je je aangemeld, een paar testscrapes gedraaid en vraag je je nu af: “Wat gaat dit me op schaal eigenlijk kosten?” — of probeer je überhaupt te bepalen of Firecrawl het juiste hulpmiddel is voor je team — dan zit je hier goed. Ik neem de echte kosten met je door (inclusief de dubbele factureringsval die de meeste reviews overslaan), waar Firecrawl echt uitblinkt, waar het tekortschiet (vooral op sites met botbeveiliging) en wanneer een heel ander hulpmiddel — inclusief no-code opties zoals — de slimmere keuze is. Mijn doel: je redden van een onverwachte creditcardafrekening.
Wat is Firecrawl en voor wie is het gemaakt?
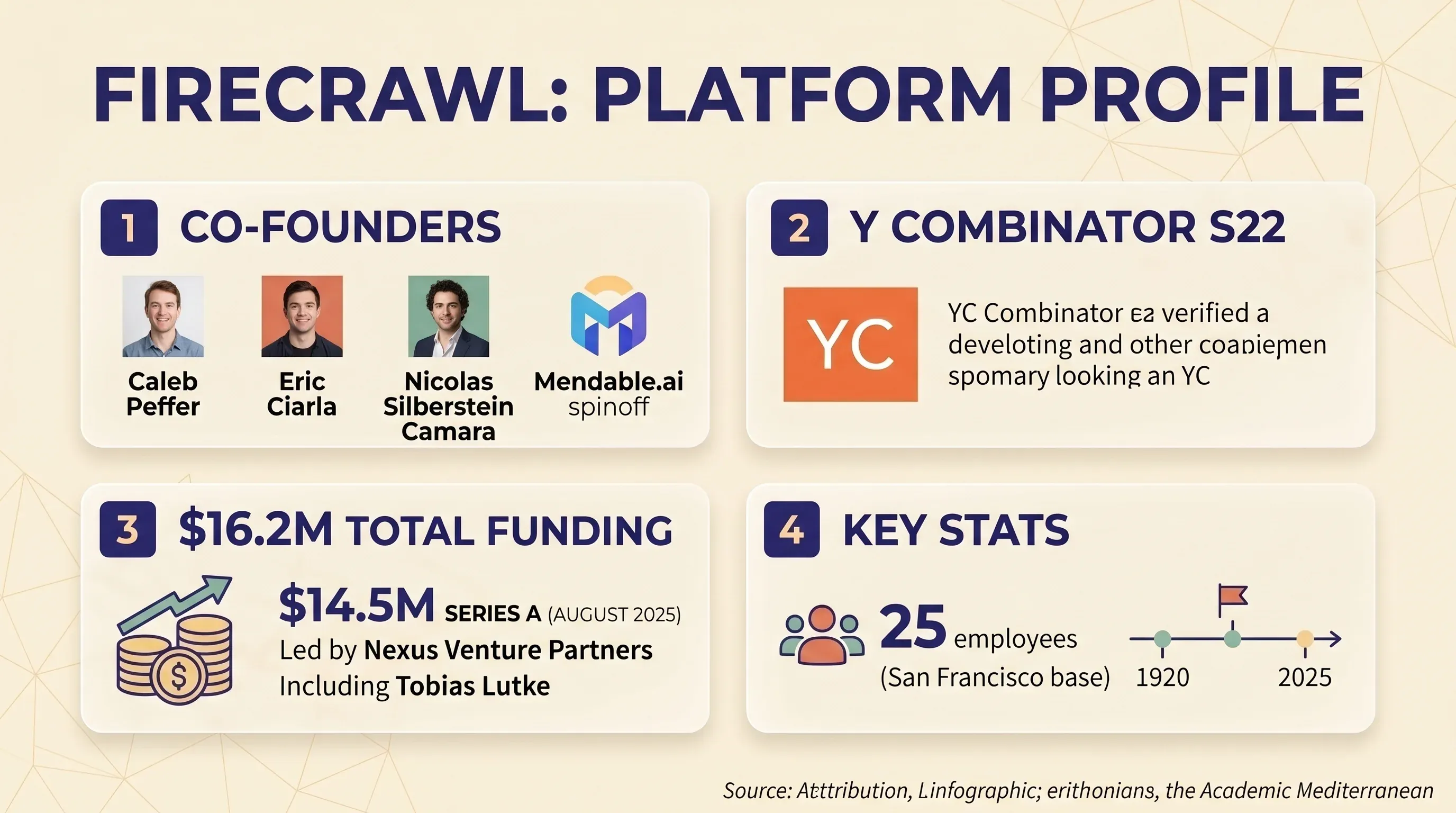
Firecrawl is een API-first webscraping- en crawlingplatform dat websites omzet naar nette markdown of gestructureerde JSON. Het is vooral bedoeld voor ontwikkelaars die AI- en LLM-toepassingen bouwen — denk aan RAG-pipelines, chatbot-kennisbanken en workflows voor AI-agents. Het bedrijf is opgericht door Caleb Peffer, Eric Ciarla en Nicolas Silberstein Camara als spin-off van Mendable.ai. Ze deden mee aan en haalden in augustus 2025 een op, geleid door Nexus Venture Partners, met deelname van Shopify-ceo Tobias Lutke. Totale financiering: $16,2 miljoen. Het team bestaat uit 25 mensen en zit in San Francisco.
Firecrawl biedt vier kernmodi, plus twee nieuwere toevoegingen:
| Modus | Wat het doet |
|---|---|
| Scrape | Zet één URL om naar markdown, JSON of een screenshot |
| Crawl | Crawlt een URL en alle onderliggende pagina’s |
| Map | Ontdekt alle URL’s op een website in enkele seconden (tot 100K URL’s) |
| Search | Websearch met volledige paginainhoud als resultaat |
| Extract | Gestructureerde extractie met AI via prompts of schema’s |
| Agent (Research Preview) | Autonoom webonderzoek zonder URL’s op te geven |
Ik wil hier meteen eerlijk over zijn: Firecrawl is een ontwikkelaarstool. Je hebt API-aanroepen, programmeerkennis en technische setup nodig. Ben je een zakelijke gebruiker die gegevens van een website wilt halen zonder code te schrijven, dan is Firecrawl niet voor jou gemaakt (daar kom ik later op terug). Maar voor dev-teams die AI-apps bouwen is de belofte aantrekkelijk: schone, LLM-ready webdata met minimale infrastructuurhoofdpijn.
Firecrawl review: prijslagen in één oogopslag
Op het eerste gezicht lijkt Firecrawl’s prijsstructuur simpel. Dit staat op :
| Pakket | Maandprijs | Credits/maand | Gelijktijdigheid | Jaarprijs |
|---|---|---|---|---|
| Free | $0 | 500 (eenmalig, niet maandelijks) | 2 | — |
| Hobby | $19/maand | 3.000 | 10 | $16/maand bij jaarlijkse facturering |
| Standard | $99/maand | 100.000 | 50 | $83/maand bij jaarlijkse facturering |
| Growth | $399/maand | 500.000 | 100 | $333/maand bij jaarlijkse facturering |
| Scale | $749/maand | 1.000.000 | 1.000 | $599/maand bij jaarlijkse facturering |
Er springen meteen een paar dingen uit. De 500 credits van het gratis pakket zijn eenmalig, niet maandelijks — een detail dat veel gebruikers pas opmerken nadat ze ze in één testsessie hebben opgebruikt. En die pakketten lijken misschien simpel, maar de werkelijke kosten hangen sterk af van welke functies je gebruikt. De vermelde prijs is eigenlijk alleen het beginpunt. De echte rekening? Daarover gaat de volgende sectie.
De werkelijke kosten van Firecrawl: een creditcalculator voor jouw situatie
Prijs is zonder twijfel het grootste pijnpunt onder echte Firecrawl-gebruikers — “het is verdomd duur”, “ik zou voor mijn gebruik op het $99/maand-plan moeten zitten” en “schandalig duur” zijn letterlijke quotes uit Hacker News- en Reddit-draadjes. De reden? Er is een dubbel factureringssysteem dat de meeste Firecrawl-reviews volledig negeren.
Hier zit de val: Firecrawl’s creditpakketten dekken Scrape, Crawl, Map en Search. Maar Extract — de AI-gestuurde gestructureerde extractie, een van Firecrawl’s belangrijkste verkoopargumenten — draait op een volledig aparte tokenabonnementenstructuur.
| Extract-pakket | Maandprijs | Tokens/jaar | Tokens/maand (ongeveer) |
|---|---|---|---|
| Starter | $89/maand | 18M | ~1,5M |
| Standard | $189/maand | 48M | ~4M |
| Growth | $389/maand | 108M | ~9M |
| Pro | $719/maand | 192M | ~16M |
Dus een startup op het Standard-creditplan ($99/maand) die ook extractie nodig heeft, betaalt $99 + $89 = minimaal $188/maand — nog vóór eventuele creditvermenigvuldigers. Dat is de dubbele factureringsval waar mensen door verrast worden.
Verborgen creditvermenigvuldigers die de meeste gebruikers missen
De kop “1 credit per pagina” is misleidend. Dit kosten de functies in de praktijk:
| Functie | Creditkost | Effectieve vermenigvuldiger |
|---|---|---|
| Basis Scrape/Crawl | 1 credit/pagina | 1x |
| Search | 2 credits/10 resultaten | 2x per resultaatset |
| JSON-extractie (via Scrape) | +4 credits/pagina | 5x totaal |
| Enhanced Mode | +4 credits/pagina | 5x totaal |
| JSON + Enhanced Mode | +8 credits/pagina | 9x totaal |
| Browser-interacties | 2 credits/minuut | Variabel |
| Agent-modus (spark-1-mini) | Dynamisch, ~100–500/vraag | 100–500x |
| Agent-modus (spark-1-pro) | Dynamisch, ~200–1.500+/vraag | 200–1.500x |
En nog een paar belangrijke details: credits worden niet doorgeschoven naar de volgende maand. Mislukte requests verbruiken alsnog credits (gebruikers melden 20–30% verspilling op instabiele sites). Agent-modus heeft geen kostenraming vooraf — je stelt een maxCredits-parameter in, maar je gokt in feite. De 500 lifetime-credits van het gratis pakket komen neer op ongeveer 56 pagina’s als je extractie inschakelt. Dat is geen proefperiode — dat is een voorproefje.
Voorbeeldtabel met maandkosten per gebruikersprofiel
| Gebruikersprofiel | Pagina’s per maand | Gebruikte functies | Geschat creditverbruik | Geschatte maandkosten |
|---|---|---|---|---|
| Hobbyist / side project | 500 | Basis scrape + crawl | ~500 credits | $19/maand (Hobby-plan) |
| Hobbyist + JSON-extractie | 500 | Scrape + Extract | ~2.500 credits + $89 Extract | $108/maand |
| Startup / AI-app | 5.000 | Scrape + Extract + Search | ~30.000 credits + $89 Extract | $188/maand (Standard + Extract) |
| Enterprise / datapijplijn | 50.000 | Complete stack + Agent | ~250.000–450.000 credits + $389 Extract | $788–$1.138/maand |
Een ontwikkelaar op Hacker News die $190 per maand betaalde, noemde de ervaring “duur en half af” en verving Firecrawl door 2.700 regels eigen Elixir-code. Dat zegt genoeg.
Zelf gehoste Firecrawl: wat is echt gratis, en wat is alleen cloud?
“Kan ik Firecrawl gewoon gratis zelf hosten?” is een van de meest gestelde vragen die ik zie. Het antwoord is: min of meer, maar waarschijnlijk niet zoals je hoopt.
Firecrawl heeft een open-source kern (AGPL-3.0-licentie), maar verschillende belangrijke functies zijn alleen in de cloud beschikbaar. Dit is de uitsplitsing:
| Mogelijkheid | Zelf gehost (gratis) | Cloud (betaald) |
|---|---|---|
| Basis Scrape/Crawl naar markdown | ✅ | ✅ |
| Map (URL-ontdekking) | ✅ | ✅ |
| LLM-gestuurde Extract | ⚠️ (gebruik je eigen LLM-keys) | ✅ (beheerd) |
| Agent-modus | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-bot / proxyrotatie (Fire-engine) | ❌ (gebruikt je statische IP) | ✅ |
| Batchverwerking | ❌ | ✅ |
| Dashboard / analytics | ❌ | ✅ |
| Beheerde infrastructuur | ❌ (Docker + PostgreSQL + Redis vereist) | ✅ |
Fire-engine, Firecrawl’s eigen anti-botsysteem, is . Zelfgehoste gebruikers krijgen nul anti-botcapaciteiten en moeten hun eigen proxies aanleveren.
Voor wie zelf hosten nog steeds logisch is
Zelf hosten werkt als je een ontwikkelaar bent die een basis crawl-naar-markdown-pijplijn wil en je comfortabel bent met het beheren van Docker Compose met 5+ services. Minimumeisen: 4 GB RAM, 2 CPU-cores, plus LLM-API-keys voor extractie ($0,01–$0,10/pagina) en proxydiensten als je die nodig hebt. Alles bij elkaar lopen de kosten van zelf hosten op tot $90–$340/maand — wat bij gemiddeld gebruik vaak vergelijkbaar is met de cloudpakketten.
Waarom gebruikers gefrustreerd raken door de zelfgehoste versie
Feedback van echte gebruikers schetst een pittig beeld. Meerdere Reddit- en GitHub-draadjes beschrijven hoe de zelfgehoste versie na verloop van tijd achteruitgaat doordat functies naar de cloud verhuizen. Eén gebruiker vatte het bot samen: het bedrijf “probeert nu alle gebruikers te pushen om te betalen en maakt zelf hosten nutteloos.” De community heeft zelfs een firecrawl-simple-fork gemaakt om pijnpunten aan te pakken. Als je rekent op zelf hosten als langdurige gratis oplossing, zet je verwachtingen dan goed — het is een prima startpunt om te experimenteren, maar geen vervanging voor het betaalde cloudproduct op schaal.
Firecrawl anti-botprestaties: waar het werkt en waar niet
Dit is de sectie die het belangrijkst is als je je afvraagt: “Gaat Firecrawl echt werken op de sites die ik moet scrapen?”
Het korte antwoord: dat hangt volledig af van hoe goed die sites zijn beveiligd.
De benchmarkcijfers
testte onafhankelijk 10 webscraping-API’s tegen 15 zwaar met botbeveiliging afgeschermde sites. Firecrawl’s resultaten:
| Aanbieder | Succespercentage (2 req/s) | Succespercentage (10 req/s) |
|---|---|---|
| Zyte | 93,14% | 89,2% |
| ScrapFly | 91,8% | 88,5% |
| Bright Data | 88,7% | 84,9% |
| Firecrawl | 33,69% | 26,69% |
Firecrawl eindigde van de 10 aanbieders op beschermde sites. De snelle responstijd (gemiddeld 7,92 seconden) wordt deels verklaard door een “fail fast”-strategie — het geeft snel fouten terug in plaats van opnieuw te proberen.
bredere doorlopende benchmark geeft Firecrawl een algemeen succespercentage van 65,4% (boven het branchegemiddelde van 59,5%), met sterke resultaten op makkelijke targets maar zwakke resultaten op beschermde sites.
Uitsplitsing naar moeilijkheid: makkelijke, gemiddelde en lastige doelen
| Moeilijkheid | Voorbeeldsites | Succespercentage Firecrawl | Aanbeveling |
|---|---|---|---|
| Makkelijk | Blogs, documentatie, openbare SaaS-pagina’s | 85–98% | Gebruik Firecrawl met vertrouwen |
| Gemiddeld | Productcatalogi, nieuwssites met basis botbeveiliging, Etsy, Realtor.com | 53–65% | Test zorgvuldig, reken op fouten |
| Moeilijk | Amazon, LinkedIn, Instagram, pagina’s met veel Cloudflare | 0–33% | Vertrouw niet op Firecrawl — gebruik gespecialiseerde anti-botaanbieders |
Sites met Cloudflare-beveiliging zijn het vaakst de oorzaak van problemen. Meerdere GitHub-issues documenteren het probleem: Cloudflare’s op fingerprint gebaseerde detectie blokkeert Firecrawl zelfs als IP-rotatie wordt gebruikt. Zelfgehoste gebruikers worden het hardst geraakt, omdat ze de proxy-infrastructuur van Fire-engine missen.
Wat te doen als Firecrawl niet genoeg is
Voor zwaar beveiligde sites stappen gebruikers meestal over op gespecialiseerde proxydiensten zoals ScrapFly of Bright Data, of op headless-browsertooling met aangepaste stealth-instellingen. Ben je een zakelijke gebruiker die geen zin heeft in proxyrotatie of het rekenen met succespercentages, dan handelen no-code tools zoals de anti-botproblemen achter de schermen af — jij klikt gewoon en krijgt je data.
Firecrawl voor- en nadelen: een eerlijke samenvatting
Waar Firecrawl goed in is
- Schone markdown-output, klaar voor LLM’s — consistent netjes opgemaakt met een duidelijke koppenstructuur. Dit is echt Firecrawl’s sterkste verkoopargument.
- Geen infrastructuurgedoe voor cloudgebruikers — geen browseropzet, proxybeheer of headless-browserconfiguratie.
- Brede framework-integraties — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (7+ integraties voor AI-pipelines).
- Snelle URL-ontdekking via het Map-endpoint — 2–3 seconden voor een volledige sitemap.
- Open-source kern met — transparantie en bijdragen van de community.
- MCP-serverondersteuning met FIRE-1-model voor AI-agentworkflows.
- op pagina’s met veel JavaScript (React, Vue, Angular SPA’s).
Waar Firecrawl tekortschiet
- Dubbele prijsstelling (credits + apart Extract-tokenpakket) zorgt voor factureringsverrassingen die niemand verwacht.
- Creditvermenigvuldigers maken de echte kosten 5–9x hoger dan de geadverteerde prijs.
- Anti-botprestaties: roemloos laatste in de Proxyway-benchmark ( tegenover 93,14% voor de beste speler).
- Agent-modus heeft onvoorspelbaar creditverbruik zonder kostenraming vooraf.
- Mislukte requests verbruiken alsnog credits — 20–30% verspilling op instabiele sites.
- Zelfgehoste versie mist Agent, Browser Sandbox, Fire-engine anti-bot en dashboard.
- Geen native CAPTCHA-oplossing — een flinke achterstand ten opzichte van Bright Data en Zyte.
- Niet toegankelijk voor niet-technische gebruikers — vereist code- en API-kennis.
- 500 credits van het gratis pakket zijn lifetime, niet maandelijks — te weinig voor echt testen.
Verder dan ontwikkelaarstools: no-code alternatieven die Firecrawl-reviews nooit noemen
Elke Firecrawl-review die ik heb gelezen vergelijkt het uitsluitend met andere ontwikkelaarstools — Crawl4AI, Scrapy, Playwright, Apify. Dat is logisch als je ontwikkelaar bent. Maar een groot deel van de mensen die naar webscraping-oplossingen zoeken, zijn geen ontwikkelaars: salesteams die prospectlijsten opbouwen, e-commerce teams die concurrentieprijzen volgen, marketeers die contentdata verzamelen, makelaars die aanbod bijhouden.
Dat is een gat dat het waard is om op te vullen.
Vergelijkingstabel Firecrawl-alternatieven
| Tool | Best voor | Code nodig? | LLM-ready output | Startprijs |
|---|---|---|---|---|
| Firecrawl | Devs die AI-apps bouwen | Ja (API) | ✅ Markdown/JSON | $19/maand |
| Crawl4AI | Devs die gratis/OSS willen | Ja (Python) | ✅ Markdown | Gratis |
| Apify | Devs die schaal + marketplace nodig hebben | Ja (SDK) | ⚠️ Met setup | $39/maand |
| Thunderbit | Zakelijke gebruikers (no-code) | Nee (Chrome-extensie) | ✅ Gestructureerde data | Gratis pakket beschikbaar |
| ScrapingBee | Devs die proxy nodig hebben | Ja (API) | ❌ Ruwe HTML | $49/maand |
| Bright Data | Enterprise-datateams | Ja (API/SDK) | ⚠️ Met setup | $500+/maand |
Waarom Thunderbit de standaardkeuze is voor niet-technische teams
Ik werk bij het Thunderbit-team, dus daar ben ik transparant over. Thunderbit hoort in deze vergelijking omdat het een ander probleem oplost dan Firecrawl, voor een andere doelgroep, zonder dat je hoeft te coderen.
Thunderbit werkt in twee klikken: open de , klik op “AI Suggest Fields” en daarna op “Scrape.” De AI leest de pagina, stelt de juiste kolommen voor en haalt gestructureerde data uit in een tabel. Geen API-keys, geen selectors, geen code. Je kunt gratis exporteren naar Excel, Google Sheets, Airtable of Notion.
Belangrijke pluspunten voor zakelijke gebruikers:
- Subpagina-verrijking — klik door naar detailpagina’s en haal automatisch extra velden op
- AI die zich aan lay-outwijzigingen aanpast — geen onderhoud wanneer een site een redesign krijgt
- Ingebouwde datalabeling en vertaling — handig voor meertalige datasets
- Directe templates voor populaire sites (Amazon, Zillow, LinkedIn, enz.)
Voor ontwikkelaars die een API-alternatief willen, biedt Thunderbit ook met simpelere prijsstelling dan Firecrawl’s dubbele credit/token-systeem. Het vervangt Firecrawl niet voor ontwikkelaars van LLM-pipelines. Maar voor sales-, e-commerce-, marketing- en operationele teams die gestructureerde data nodig hebben zonder code te schrijven, is het de snellere en goedkopere route.
Zelf bouwen versus kopen: wanneer betaalt Firecrawl zichzelf terug en wanneer niet?
“Ik dacht eraan om zelf een webscraper te schrijven… simpeler dan Firecrawl, maar in elk geval goedkoper.” Dat punt komt vaak terug. In plaats van een subjectieve mening hier is een gestructureerd besliskader.
Besliskader-tabel
| Factor | Zelf bouwen (Scrapy/Playwright) | Firecrawl Cloud kopen | Thunderbit gebruiken (no-code) |
|---|---|---|---|
| Opstarttijd | 10–40+ uur | ~30 minuten | ~5 minuten |
| Doorlopend onderhoud | Hoog (selectors breken) | Bijna nul (beheerd) | Nul (AI past zich aan) |
| Anti-botafhandeling | Handmatig (proxy, headers, retries) | Ingebouwd (deels — zwak op beschermde sites) | Ingebouwd (browser + cloudmodi) |
| Kosten bij 1K pagina’s/maand | $50–150 (server + proxy) | $19–$108 (afhankelijk van functies) | $0–$15 |
| Kosten bij 50K pagina’s/maand | $500–$1.500 (infrastructuur) | $399–$1.138 | $39–$249 |
| LLM-ready output | Aangepaste code vereist | Ingebouwd (markdown/JSON) | Gestructureerde tabellen (exporteerbaar) |
| Best voor | Volledige controle, niche-sites, DevOps-teams | AI/LLM-devs, RAG-pipelines | Sales, e-commerce, marketing, operations |
Zelf bouwen kost voor de meeste organisaties dan API’s over drie jaar. Het omslagpunt waarop zelf bouwen goedkoper wordt, ligt rond 10 miljoen+ pagina’s per maand — een schaal die heel weinig teams echt halen.
Het eerlijke oordeel: welke route past bij jou?
Firecrawl betaalt zichzelf terug wanneer:
- Je team al code schrijft in Python/JS en schone markdown nodig heeft voor LLM/RAG-pipelines
- Je vooral onbeschermde of licht beschermde sites target
- Je beheerde infrastructuur wilt zonder DevOps-overhead
- Het volume onder ongeveer 50.000 pagina’s per maand blijft
Firecrawl betaalt zichzelf niet terug wanneer:
- Je een zakelijke gebruiker bent die data ophaalt zonder dev-team → Thunderbit is makkelijker en sneller
- Je zwaar beveiligde sites target (Amazon, LinkedIn, veel Cloudflare) → Bright Data of Zyte
- Je voorspelbare facturatie op schaal nodig hebt → creditvermenigvuldigers maken kosten onvoorspelbaar
- Je volledig zelf wilt hosten met alle functies → Agent, Browser Sandbox en Fire-engine zijn alleen in de cloud
Zelf bouwen is alleen logisch wanneer:
- Je team toegewijde DevOps-capaciteit heeft
- Je op enorme schaal werkt (10M+ pagina’s/maand)
- Je volledige controle nodig hebt over niche- of eigenzinnige sites
- Je comfortabel bent met doorlopend selectoronderhoud
Firecrawl review: vergelijking naast elkaar
Hier staat alles naast elkaar:
| Tool | Type | Best voor | Code nodig | Anti-botafhandeling | LLM-ready output | Zelf hosten mogelijk | Startprijs |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | AI/LLM-devs | Ja | Zwak op beschermde sites | ✅ Markdown/JSON | ✅ (beperkt) | $19/maand |
| Crawl4AI | Python-bibliotheek | OSS-first devs | Ja | Geen (zelf doen) | ✅ Markdown | ✅ | Gratis |
| Apify | Cloudplatform | Schaal + marketplace | Ja | Gemiddeld | ⚠️ Met setup | ✅ | $39/maand |
| Thunderbit | Chrome-extensie + API | Zakelijke gebruikers, no-code | Nee | Ingebouwd | ✅ Gestructureerde data | ❌ | Gratis pakket |
| ScrapingBee | API | Devs met focus op proxy’s | Ja | Sterk | ❌ Ruwe HTML | ❌ | $49/maand |
| Bright Data | API + proxy-netwerk | Enterprise-datateams | Ja | Het beste (~99,9%) | ⚠️ Met setup | ❌ | $500+/maand |
Eindconclusie: is Firecrawl het waard?
Firecrawl is een solide tool voor een specifieke use case: ontwikkelteams die LLM-apps, RAG-pipelines of AI-agents bouwen en schone webdata op gemiddelde schaal nodig hebben, terwijl ze comfortabel zijn met API-gestuurde workflows. De kwaliteit van de markdown-output is echt toonaangevend, en de framework-integraties (LangChain, LlamaIndex, CrewAI) zijn volwassen. Als je team al in Python of JavaScript werkt en je doelwebsites niet zwaar met botbeveiliging zijn afgeschermd, kan Firecrawl je serieus veel engineeringtijd besparen.
De nadelen zijn echter ook echt. Het dubbele prijsmodel (credits + apart Extract-abonnement) zorgt voor onverwachte facturen. Het op beschermde sites betekent dat je er niet op kunt vertrouwen voor Amazon, LinkedIn of sites met veel Cloudflare. De zelfgehoste versie mist te veel functies om een echt gratis alternatief te zijn. En als je een niet-technische gebruiker bent — iemand in sales, e-commerce of marketing — is Firecrawl simpelweg niet voor jou gemaakt.
Test Firecrawl’s 500 gratis credits om te zien of de outputkwaliteit past bij je pipeline. Maar bereken je echte maandkosten eerst met de calculator hierboven voordat je je vastlegt op een betaald plan. Ben je een zakelijke gebruiker die gewoon gestructureerde data van websites nodig heeft zonder code te schrijven, begin dan liever met — je haalt data binnen minuten op in plaats van uren. Je kunt nu meteen de proberen, of bekijken om te zien wat voor jouw team schaalt. Voor videodemo’s heeft het stap-voor-stap demonstraties.
FAQ’s
Hoeveel kost Firecrawl per gescrapete pagina?
Een basis scrape of crawl kost 1 credit per pagina. JSON-extractie voegt 4 credits/pagina toe (5 totaal). Enhanced Mode voegt er nog eens 4 toe (tot 9 totaal). Search kost 2 credits per 10 resultaten, en Agent-modus kan 100–1.500+ credits per query verbruiken. Daarbovenop vereist de Extract-functie een apart tokenabonnement vanaf $89 per maand. Zie het gedeelte met de kostencalculator hierboven voor realistische schattingen per gebruikersprofiel.
Kun je Firecrawl gratis zelf hosten?
Ja, de open-source kern (AGPL-3.0) kun je gratis zelf hosten. Maar je mist Agent-modus, Browser Sandbox, anti-bot/proxyrotatie (Fire-engine is closed-source), batchverwerking en het beheerdashboard. Je moet je eigen LLM-keys meenemen voor extractie en zelf Docker, PostgreSQL en Redis beheren. Zelf hosten werkt voor basis crawl-naar-markdown-pijplijnen, maar is geen vervanging voor het cloudproduct op productieschaal.
Is Firecrawl goed voor Amazon, LinkedIn of andere beschermde sites?
De laat zien dat Firecrawl op zwaar met botbeveiliging afgeschermde sites een succespercentage van 33,69% haalt — roemloos laatste van de 10 geteste aanbieders. Het werkt prima op onbeschermde pagina’s (blogs, docs, SaaS-sites — 85–98% succes), maar is niet betrouwbaar voor grote e-commerce- of socialplatforms. Voor die doelen kun je beter gespecialiseerde anti-botaanbieders zoals Bright Data of Zyte overwegen, of no-code tools zoals Thunderbit die anti-bot achter de schermen afhandelen.
Wat is het beste Firecrawl-alternatief voor niet-technische gebruikers?
is het beste no-code alternatief. Het is een Chrome-extensie waarin je op “AI Suggest Fields” en daarna op “Scrape” klikt — geen API-aanroepen, geen code, geen selectors. Data exporteer je gratis naar Excel, Google Sheets, Airtable of Notion. Het is gebouwd voor sales-, e-commerce-, marketing- en operationele teams die gestructureerde webdata nodig hebben zonder ontwikkelaar.
Biedt Firecrawl een gratis proefperiode aan?
Firecrawl geeft zonder dat je een creditcard nodig hebt. Dat is genoeg om de basisfunctionaliteit van scrape/crawl op een handvol pagina’s te testen, maar niet genoeg voor productiegebruik — vooral niet als je extractie inschakelt (wat 5 credits per pagina kost). Credits worden op het gratis plan niet maandelijks vernieuwd.
Meer lezen