

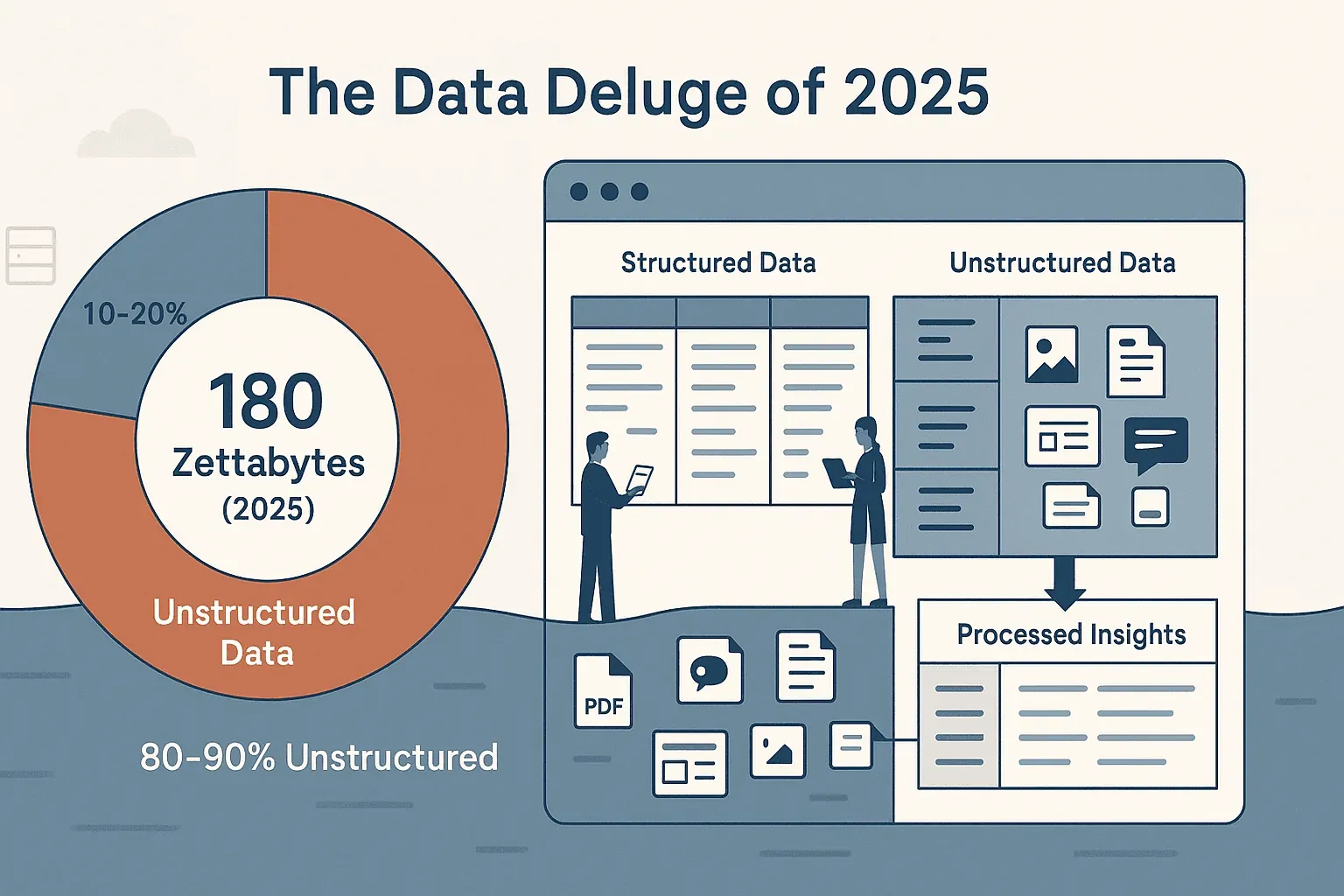
Als je ooit hebt geprobeerd gegevens van een website te verzamelen—of het nu gaat om verkoopkansen, concurrentieprijzen of gewoon het opschonen van een rommelige productcatalogus—dan weet je dat het web nu eenmaal niet is gemaakt voor simpel kopiëren en plakken. De hoeveelheid online data is enorm: IDC en Statista schatten de wereldwijde datasfeer op ongeveer 180 zettabyte in 2025, en we zitten inmiddels al op koers voor zo’n 221 zettabyte in 2026. Het grotere probleem is niet de hoeveelheid, maar de vorm: ongeveer 80% van die data is ongestructureerd, verstopt in webpagina’s, pdf’s, afbeeldingen en dynamische feeds. De meeste business teams—ikzelf inbegrepen—hebben veel te veel tijd verspild aan het worstelen met die chaos, om uiteindelijk uit te komen bij halfbakken spreadsheets en een gevoel van déjà vu.
Gegevens van elke website halen met AI Get Started Free
Daarom ben ik zo gefocust op efficiënt websites crawlen. In deze gids laat ik je stap voor stap zien hoe je op een praktische manier elke website kunt crawlen—zonder code en zonder gedoe—met Thunderbit, onze AI-aangedreven webcrawler. Of je nu in sales werkt, operations doet of gewoon klaar bent met handmatige datainvoer: ik laat je zien hoe je omgaat met complexe layouts, paginering, subpagina’s en zelfs gegevens uit pdf’s en afbeeldingen haalt. Laten we de chaos van het web omzetten in jouw volgende zakelijke voordeel.
Wat betekent het om een website efficiënt te crawlen?
Laten we het simpel houden: een website crawlen betekent dat je een geautomatiseerde tool gebruikt—denk aan een robotassistent—om systematisch webpagina’s te bezoeken en de informatie op te halen die je nodig hebt: namen, prijzen, e-mails, productspecificaties, noem maar op. Efficiënt crawlen draait niet alleen om snelheid; het gaat ook om nauwkeurigheid, zo min mogelijk handmatig werk en de mogelijkheid om echte webhindernissen aan te kunnen, zoals paginering, subpagina’s en ongestructureerde data (Wikipedia).
Wat onderscheidt een efficiënt crawlproces van eindeloos kopiëren en plakken? Dit zijn de belangrijkste punten:
- Snelheid: Honderden pagina’s of records ophalen in minuten, niet in uren.
- Nauwkeurigheid: Precies de data pakken die je nodig hebt, zonder missende velden of typefouten.
- Automatisering: De tool repetitieve taken laten doen, zoals op ‘Volgende’ klikken of links naar detailpagina’s volgen.
- Veerkracht: Omgaan met complexe layouts, dynamische content en zelfs wijzigingen in de structuur van de website.
- Minimale setup: Geen code, geen gedoe met selectors, geen constant onderhoud.
De echte wereld bestaat niet uit perfecte tabellen. Moderne sites hebben oneindig scrollen, navigatie in meerdere stappen, inlogvereisten en data die verstopt zit in pdf’s of afbeeldingen. Efficiënt crawlen betekent dat je dat allemaal aankunt—zodat je minder tijd kwijt bent aan handwerk en meer tijd overhoudt voor analyse en actie (AIMultiple).
Waarom efficiënt website crawlen belangrijk is voor sales en operations
Waarom hechten business teams zoveel waarde aan web crawlen? Omdat de juiste data—snel aangeleverd—je volgende campagne, productlancering of verkoopkwartaal kan maken of breken. Dit zijn een paar van de meest voorkomende (en meest rendabele) use cases die ik wekelijks zie:
| Use case | Voordeel & ROI | Voorbeeldresultaat |
|---|---|---|
| Leadgeneratie | Vul de salesfunnel sneller, bespaar uren aan prospectonderzoek, verminder handmatige fouten | 5.000 gerichte leads ’s nachts ophalen, campagnes 2 weken eerder starten, 30% meer afspraken |
| Prijsmonitoring van concurrenten | Dynamische prijsstelling mogelijk maken, direct reageren op marktveranderingen, marges beschermen | Een retailer past prijzen dagelijks aan en ziet een stijging van 4% in omzet |
| Extractie van productcatalogus/voorraad | Listings up-to-date houden, handmatige invoer verminderen, oververkoop of verkeerde prijsstelling voorkomen | E-commerceteam werkt dagelijks 10.000 SKU’s bij en verkort de update tijd met 90% |
| Marktonderzoek & analyse van reviews | Inzicht krijgen in klantsentiment en trends op grote schaal, kansen zien vóór concurrenten | Meer dan 10.000 reviews analyseren, nieuwe productkansen identificeren, marketingboodschappen verbeteren |
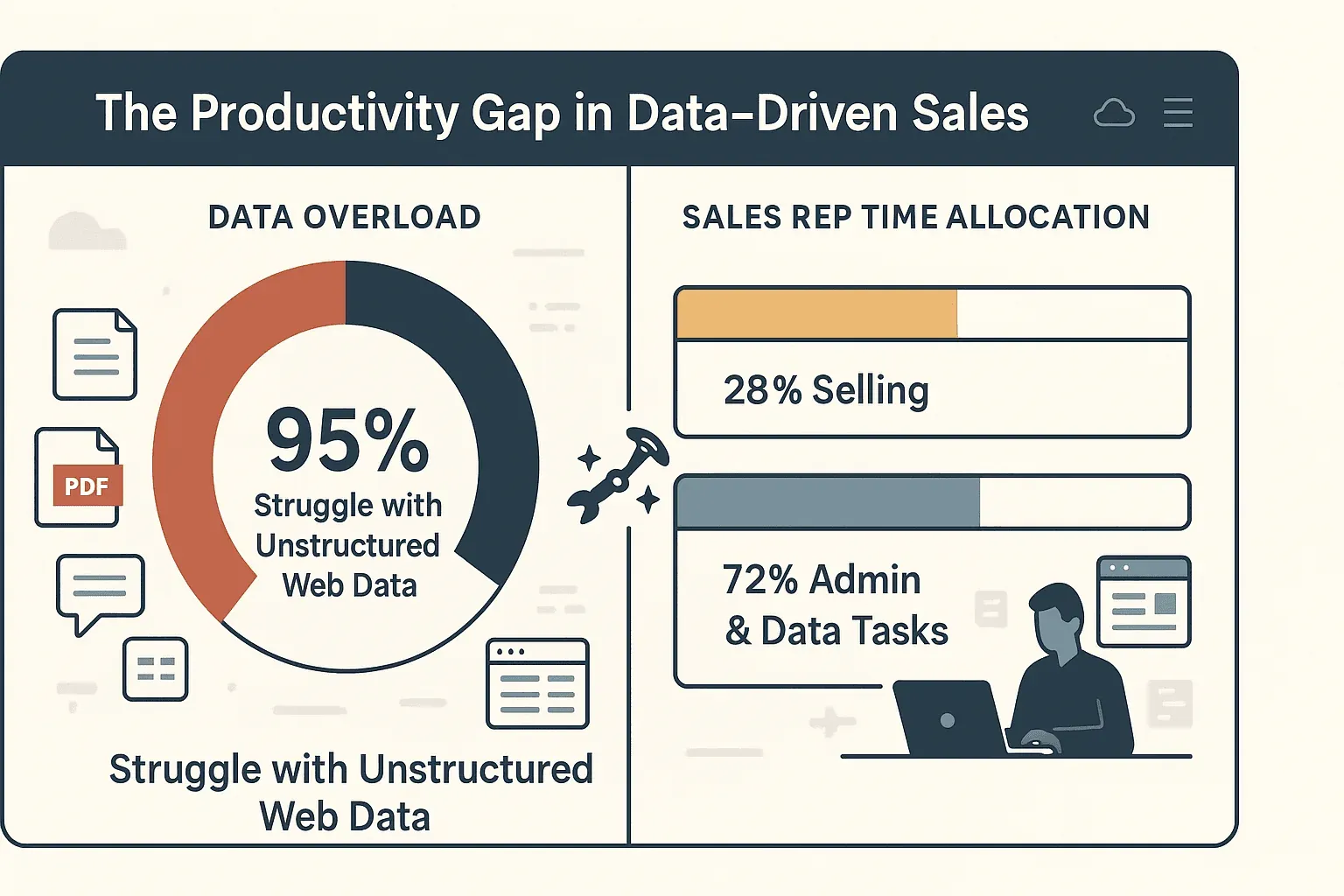
Kort gezegd? Efficiënt crawlen leidt tot snellere, slimmere beslissingen—en veel minder tijd achter kopiëren en plakken. Sterker nog, 95% van de bedrijven geeft toe moeite te hebben met ongestructureerde webdata, en salesmedewerkers besteden slechts 28% van hun tijd daadwerkelijk aan verkopen. De rest gaat op aan handmatige invoer en administratie.
Thunderbit: de eenvoudigste manier om een website te crawlen
Laten we eerlijk zijn: de meeste webscrapingtools zijn gebouwd voor developers, niet voor zakelijke gebruikers. Daarom hebben we Thunderbit gemaakt, een AI-aangedreven webcrawler die net zo makkelijk werkt als eten bestellen. Dit maakt Thunderbit anders:
- Natuurlijke taal prompts: Beschrijf gewoon de data die je wilt (“Haal alle productnamen en prijzen van deze pagina op”), en Thunderbit’s AI doet de rest.
- AI-veldsuggesties: Klik op “AI Suggest Fields” en Thunderbit scant de pagina, stelt de beste kolommen voor om te extraheren en zet de crawler voor je op.
- 2-klikken workflow: Zodra je tevreden bent met de velden, klik je op “Scrape”. Dat is alles—geen code, geen sjablonen, geen gevecht met selectors.
- Ondersteunt paginering & subpagina’s: Thunderbit herkent en navigeert automatisch door meerpagina-lijsten en kan links naar detailpagina’s (subpagina’s) volgen om je data verder aan te vullen.
- Direct exporteren: Verstuur je data rechtstreeks naar Excel, Google Sheets, Airtable of Notion—of download als CSV/JSON, helemaal gratis.
- OCR voor pdf’s & afbeeldingen: Gegevens nodig uit een pdf, afbeelding of gescand document? Thunderbit’s ingebouwde OCR extraheert en structureert die content ook.
Thunderbit is ontworpen voor niet-technische gebruikers—als je kunt surfen op het web en een zin kunt typen, kun je als een pro een website crawlen. En ja, er is een gratis versie, zodat je het zonder risico kunt proberen.
Probeer Thunderbit gratis – begin direct met crawlen
Website-crawlingoplossingen vergelijken: Thunderbit versus traditionele methoden
Zet Thunderbit eens naast de gebruikelijke alternatieven:
| Aanpak | Installatietijd & complexiteit | Benodigde vaardigheden | Onderhoud & betrouwbaarheid |
|---|---|---|---|
| Handmatig kopiëren en plakken | Extreem hoog, niet schaalbaar | Geen, maar foutgevoelig | 100% handmatig, voor elke update opnieuw doen |
| Aangepaste code (Python, etc.) | Hoge initiële setup, uren/dagen per site | Programmeerkennis vereist | Breekt bij sitewijzigingen, vraagt voortdurend fixes |
| Traditionele no-code tool | Middelmatig, point-and-click setup | Laag/gemiddeld | Updates nodig bij layoutwijzigingen, kan niet altijd dynamische sites aan |
| Thunderbit (AI-aangedreven) | Zeer laag, 2-klikken setup | Geen | AI past zich aan wijzigingen aan, minimaal onderhoud |
Traditionele tools brengen je soms halverwege, maar lopen vaak vast op dynamische content, paginering of vereisen dat je elke wijziging zelf in de gaten houdt. Thunderbit’s AI leest de site als een mens, past zich aan nieuwe layouts aan en handelt de lastige onderdelen af—zodat jij dat niet hoeft te doen (Thunderbit Blog).
Stap 1: Je websitecrawl instellen met Thunderbit
Aan de slag gaan is zo gepiept:
- Installeer de Thunderbit Chrome-extensie. Maak een gratis account aan.
- Ga naar de website die je wilt crawlen. Open de pagina die je wilt verwerken—dat kan een productoverzicht, directory of zelfs een pdf zijn.
- Open Thunderbit. Klik op het Thunderbit-icoon in je Chrome-werkbalk.
- Beschrijf wat je nodig hebt. Klik op “AI Suggest Fields” om Thunderbit kolommen te laten voorstellen, of typ een prompt in natuurlijke taal (bijvoorbeeld: “Extraheer voor elk item de productnaam, prijs en afbeeldings-URL”).
- Voorbeeld bekijken en aanpassen. Thunderbit toont een previewtabel—bewerk veldnamen, verwijder extra velden of voeg indien nodig eigen instructies toe.
Pro tip: wees specifiek maar beknopt in je prompts. Noem de datapunten zoals ze op de site voorkomen (“prijs”, “adres”, enz.) en laat Thunderbit’s AI het zware werk doen.
Stap 2: Paginering en subpagina’s afhandelen tijdens website crawlen
Hier schittert Thunderbit echt. De meeste data uit de praktijk staat niet op één pagina—die is verspreid over gepagineerde lijsten of verborgen in subpagina’s.
- Paginering: Thunderbit herkent automatisch knoppen als “Volgende”, paginanummers of oneindig scrollen. Wanneer je op “Scrape” klikt, blijft het pagina’s laden totdat alles binnen is—je hoeft dus niet handmatig URL’s in te voeren of door elke pagina te klikken.
- Subpagina crawlen: Meer details nodig? Na het scrapen van de hoofdlijst klik je op “Scrape Subpages”. Thunderbit volgt links (zoals productdetailpagina’s of bedrijfsprofielen), extraheert extra informatie en voegt die samen in je tabel.
Voorbeeld: Een e-commercesite scrapen? Thunderbit pakt eerst de productlijst en bezoekt daarna van elk product de detailpagina om specificaties, reviews of afbeeldingen op te halen—all in one go.
Best practice: laat Thunderbit eerst de hoofdcrawl afronden en gebruik daarna subpage scraping voor diepere data. Je ziet voortgangsupdates en kunt controleren op ontbrekende records.
Stap 3: Slimme extractie van ongestructureerde data met Thunderbit
Niet alle data staat netjes in tabellen. Productbeschrijvingen, reviews of velden met gemengde formats kunnen een ramp zijn voor traditionele scrapers. Thunderbit’s AI pakt dat direct aan:
- Schoont en formatteert data op: Haalt valutasymbolen weg, verwerkt getallen en splitst complexe velden op (bijvoorbeeld: “USD 299 (50% korting!)” wordt “299” en “50% korting”).
- Parseert complexe tekst: Extraheert gestructureerde informatie uit alinea’s (bijvoorbeeld: vindt “Locatie: New York” in een vacaturetekst).
- Classificeert en labelt: Voegt categorieën of tags toe op basis van de inhoud (bijvoorbeeld: “Elektronica” versus “Kleding”).
- Gaat om met inconsistenties: Past zich aan ontbrekende velden of layoutwijzigingen aan, zodat je data netjes uitgelijnd en accuraat blijft.
- Vat samen of vertaalt: Heb je een samenvatting in één zin nodig of een vertaling? Voeg een aangepaste instructie toe—Thunderbit’s AI kan dat ook.
Het resultaat? Schone, direct bruikbare data—geen uren meer kwijt aan opschonen in Excel.
Stap 4: Kiezen tussen cloud crawlen en browser crawlen
Thunderbit biedt twee manieren om te crawlen, afhankelijk van je behoefte:
- Browser crawlen: Draait in je Chrome-browser met je ingelogde sessie. Perfect voor sites waarvoor authenticatie nodig is of die sterke anti-botmaatregelen hebben. Je ziet de crawl live gebeuren en het bootst menselijk surfgedrag na.
- Cloud crawlen: Verplaatst het werk naar Thunderbit’s cloudservers. Ondersteunt tot 50 pagina’s parallel—ideaal voor grote jobs of geplande taken. Je kunt je laptop dichtklappen en Thunderbit het zware werk laten doen.
Wanneer gebruik je welke?
- Gebruik Browser Mode voor sites waarvoor je moet inloggen of wanneer je met de pagina moet interacteren.
- Gebruik Cloud Mode voor openbare sites, bulkjobs of wanneer je snelheid en automatisering wilt.
Van modus wisselen is eenvoudig: kies gewoon je voorkeur voordat je de crawl start.
Stap 5: Data uit documenten en afbeeldingen halen met OCR
Soms zit de data die je nodig hebt vast in pdf’s, afbeeldingen of gescande documenten. Thunderbit’s ingebouwde OCR (Optical Character Recognition) verandert het spel:
- PDF’s: Extraheer tabellen, e-mails of tekst uit rapporten, facturen of catalogi.
- Afbeeldingen: Haal tekst uit screenshots, productlabels of zelfs infographics.
- Gescande formulieren: Automatiseer datainvoer uit bonnetjes, contracten of visitekaartjes.
Wijs Thunderbit gewoon naar de pdf- of afbeeldings-URL, en het extraheert en structureert de inhoud—geen aparte software nodig. Je kunt OCR zelfs combineren met AI-prompts voor geavanceerde extractie (“Vind alle e-mailadressen in deze pdf”).
Stap 6: Je gecrawlde data exporteren en gebruiken
Zodra je crawl klaar is, is het tijd om die data aan het werk te zetten:
- Exportopties: Download als CSV of JSON, of exporteer direct naar Google Sheets, Excel, Airtable of Notion. Alle formaten zijn gratis—zelfs op het basisplan.
- Sales & CRM: Importeer leadlijsten in je CRM, start outreachcampagnes of verrijk bestaande contacten.
- Marketing & analyse: Analyseer concurrentieprijzen, volg markttrends of visualiseer data in dashboards.
- Operations & voorraad: Monitor voorraad, werk catalogi bij of stel meldingen in voor belangrijke wijzigingen.
- Automatisering: Gebruik integraties (zoals Zapier of Google Apps Script) om follow-ups, rapportage of data-verrijking te automatiseren.
Thunderbit’s gestructureerde output betekent dat je in minuten van crawl naar actie gaat—niet in dagen.
Begin met crawlen met Thunderbit AI
Conclusie & belangrijkste inzichten
Een website efficiënt crawlen is niet alleen een droom van techneuten—het is een zakelijke superkracht. Met Thunderbit kan iedereen:
- In seconden een crawl opzetten met natuurlijke taal of AI-voorgestelde velden.
- Complexe sites afhandelen met paginering, subpagina’s en dynamische content—zonder code.
- Schone, gestructureerde data extraheren uit rommelige webpagina’s, pdf’s en afbeeldingen.
- De beste modus kiezen (browser of cloud) voor snelheid, schaal en veiligheid.
- Data direct exporteren naar je favoriete tools en workflows.
De tijd van eindeloos kopiëren en plakken en kapotte scrapers is voorbij. Download Thunderbit, probeer een gratis crawl en ontdek hoeveel tijd (en rust) je kunt besparen. Je volgende grote inzicht—or verkoopsucces—kan zomaar een klik verderop liggen.
Wil je meer tips en diepgaande uitleg? Bekijk de Thunderbit Blog voor tutorials, use cases en het laatste nieuws over AI-aangedreven web crawlen.
FAQ’s
1. Wat is het verschil tussen web crawlen en webscraping?
Web crawlen verwijst naar het systematisch doorzoeken van websites om pagina’s en links te ontdekken, terwijl webscraping draait om het extraheren van specifieke data uit die pagina’s. Thunderbit combineert beide—het vindt, navigeert en extraheert de informatie die je nodig hebt.
2. Kan Thunderbit websites met inlogvereisten aan?
Ja! Gebruik Thunderbit’s Browser Mode om sites te crawlen waarvoor authenticatie nodig is. Het gebruikt je ingelogde Chrome-sessie, zodat je toegang hebt tot data achter inlogschermen of betaalmuren (zolang dat binnen de gebruiksvoorwaarden van de site valt).
3. Hoe gaat Thunderbit om met paginering en oneindig scrollen?
Thunderbit detecteert en navigeert automatisch door gepagineerde lijsten en pagina’s met oneindig scrollen. Het klikt op “Volgende”, scrolt of laadt meer content totdat alle data is vastgelegd—geen handmatige setup nodig.
4. Welke soorten data kan Thunderbit extraheren?
Thunderbit kan tekst, getallen, datums, URL’s, e-mails, telefoonnummers, afbeeldingen en zelfs data uit pdf’s en afbeeldingen extraheren met OCR. Je kunt velden aanpassen en AI-prompts gebruiken voor geavanceerde structurering en opschoning.
5. Is Thunderbit gratis te gebruiken?
Thunderbit biedt een gratis versie waarmee je een beperkt aantal pagina’s kunt crawlen. Alle exportformaten (CSV, Excel, Google Sheets, Airtable, Notion) zijn gratis inbegrepen. Betaalde abonnementen beginnen bij $15/maand voor hogere volumes en geavanceerde functies.
Klaar om slimmer te crawlen in plaats van harder? Probeer Thunderbit vandaag nog en laat AI het zware werk doen voor je volgende webdataproject. Meer weten
- Hoe crawl je een website? Een beginnersgids
- Hoe websites crawlen: een stapsgewijze beginnersgids
- Hoe je alle links op een website crawlt: een uitgebreide gids
Probeer AI Web Scraper gratis Get Started Free




