
웹 크롤러는 인터넷의 숨은 일꾼이에요. 새 레시피를 찾을 때, 스니커즈 최신 가격을 볼 때, 여행지 호텔을 비교할 때도, 이미 크롤러가 먼저 다녀가 조용히 정보를 모아 뒀을 가능성이 커요. 최근 업계 조사를 보면 전체 인터넷 트래픽의 절반쯤이 이제 사람이 아니라 봇과 크롤러에서 나와요. 봇 비중은 49~51% 수준으로 추정되죠. 여러분이 자는 사이에도 이 디지털 정찰병들은 쉬지 않고 웹을 지도처럼 그리며, 세상의 정보를 클릭 한 번으로 닿을 수 있게 만들고 있어요.
그럼 웹 크롤러는 정확히 뭘까요? 왜 기업과 연구자, 최신 데이터에 기대는 사람들에게 그렇게 중요할까요? Thunderbit 같은 요즘 도구는 어떻게 웹 크롤링을 프로그래머만의 영역에서 모두의 것으로 끌어냈을까요? 자동화와 AI 도구를 오래 만들면서, 저는 크롤러가 신비로운 "스파이더"에서 일상 비즈니스 도구로 바뀌는 과정을 곁에서 봐 왔어요. 이제 그게 뭔지, 어떻게 작동하는지, 왜 2026년 더 똑똑한 데이터 접근의 핵심인지 하나씩 짚어 볼게요.
웹 크롤러는 인터넷의 데이터 정찰병이에요
AI로 어떤 웹사이트든 데이터 추출 Get Started Free
그럼 웹 크롤러는 실제로 뭘까요? 핵심만 말하면, 웹 크롤러(스파이더 또는 봇이라고도 해요)는 인터넷을 체계적으로 훑으며 한 페이지에서 다음 페이지로 옮겨 다니며 정보를 모으는 자동화 프로그램이에요. 세상에서 가장 성실한 리서치 인턴인데, 잠도 안 자고 불평도 없이 하루에 수백만 페이지를 방문하는 친구라고 보면 돼요.
크롤러는 웹 주소 목록, 이른바 "시드(seed)"에서 출발해요. 각 주소를 방문하고, 거기서 찾은 링크를 따라 새 페이지로 넘어가죠. 그러면서 콘텐츠를 복사하고, 데이터를 인덱싱하고, 끊임없이 변하는 웹의 지형도를 그려요(Cloudflare). 구글이 세상에 뭐가 있는지 파악하는 방식도, 가격 비교 사이트나 시장 조사 도구가 데이터를 최신으로 유지하는 방식도 다 이래요.
간단히 말하면, 웹 크롤러는 인터넷을 검색 가능하고, 비교 가능하고, 바로 쓸 수 있게 만들어 주는 정찰병이에요.
웹 크롤러의 다양한 모습: 유형과 핵심 기능
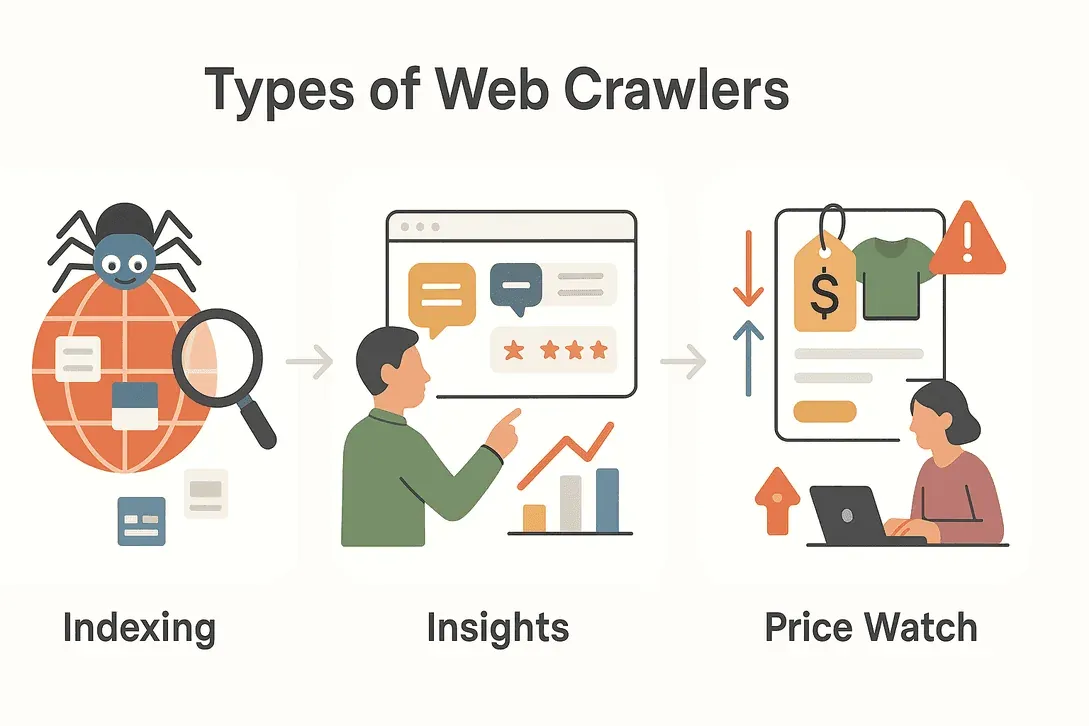 웹 크롤러가 다 같은 역할을 하는 건 아니에요. 임무에 따라 여러 종류가 있고, 각각 전문 영역도 달라요. 대표 유형을 간단히 볼게요.
웹 크롤러가 다 같은 역할을 하는 건 아니에요. 임무에 따라 여러 종류가 있고, 각각 전문 영역도 달라요. 대표 유형을 간단히 볼게요.
| 유형 | 핵심 기능 | 대표 활용 사례 |
|---|---|---|
| 검색 엔진 크롤러 | 검색 결과를 위해 웹을 인덱싱 | Googlebot, Bingbot이 새 웹사이트를 인덱싱 |
| 데이터 마이닝 크롤러 | 분석용 대규모 데이터셋 수집 | 시장 조사, 학술 연구 |
| 가격 모니터링 크롤러 | 상품 가격과 재고 상태 추적 | 이커머스 가격 비교, 동적 가격 책정 |
| 콘텐츠 집계 크롤러 | 기사, 뉴스, 게시물을 모아 집계 | 뉴스 포털, 콘텐츠 큐레이션 |
| 리드 생성 크롤러 | 연락처와 비즈니스 정보 추출 | 영업 발굴, B2B 디렉터리 |
이 중 몇 가지를 조금 더 자세히 볼게요.
검색 엔진 크롤러
구글에 질문을 입력할 때, 사실 검색 엔진 크롤러의 일을 쓰는 거예요. 이 봇들은 24시간 웹을 돌며 새 페이지를 찾고, 기존 페이지를 갱신하고, 검색 결과에 뜰 수 있게 콘텐츠를 인덱싱해요. 크롤러가 없으면 검색 엔진은 눈을 가린 채 움직이는 셈이라, 뭐가 새로 생겼는지조차 알 수 없죠(TechTarget).
데이터 마이닝 및 시장 조사 크롤러
기업과 연구자들은 방대한 데이터를 모아 분석하려고 크롤러를 써요. 경쟁사 브랜드가 온라인에서 몇 번이나 언급되는지 알고 싶거나, 새 제품 출시에 대한 반응을 추적하고 싶을 수 있죠. 데이터 마이닝 크롤러는 포럼, 리뷰, 소셜 미디어를 훑으며 어수선한 웹을 구조화된 인사이트로 바꿔 줘요(DataHut).
가격 모니터링 및 상품 추적 크롤러
빠르게 변하는 이커머스에서는 가격과 상품 정보가 끊임없이 바뀌어요. 가격 모니터링 크롤러는 경쟁사 가격, 재고 변화, 새 제품 출시를 추적해 기업에 알려 줘요. 이걸로 동적 가격 책정 전략을 돌릴 수 있고, 경쟁력을 지키는 데도 도움이 돼요(AIMultiple).
웹 크롤러가 현대 데이터 접근에 필수적인 이유
인터넷은 너무 거대해서 사람이 손으로 따라갈 수 없어요. 지금은 14억 개가 넘는 웹사이트가 있고, 매일 약 100만 개가 새로 생겨요. 웹 크롤러가 있으면 이런 게 가능해져요.
- 데이터 수집을 대규모로 확장: 수개월이 아니라 수시간 만에 수백만 페이지를 방문할 수 있어요.
- 최신 상태 유지: 변경 사항, 새 콘텐츠, 속보를 계속 모니터링할 수 있어요.
- 동적이고 실시간인 정보에 접근: 시장 변화, 가격 변동, 인기 주제에 즉시 반응할 수 있어요.
- 데이터 기반 의사결정 지원: 검색 엔진부터 시장 조사, 리스크 관리, 재무 모델링까지 다양한 분야를 떠받쳐요(DEV Community).
데이터가 디지털 비즈니스 전략의 근간이 된 지금, 웹 크롤러는 그 데이터를 흐르게 하는 엔진이에요.
업종별 웹 크롤러의 대표 활용 사례
웹 크롤러는 거대 기술 기업이나 검색 엔진만을 위한 도구가 아니에요. 산업별로 어떻게 쓰이는지 볼게요.
| 산업 | 활용 사례 | 효과 |
|---|---|---|
| 영업 | 리드 생성 | 디렉터리에서 타깃 잠재 고객 목록 구축 |
| 이커머스 | 가격 모니터링 | 경쟁사 가격, 재고, 상품 변경 추적 |
| 마케팅 | 콘텐츠 집계 | 뉴스, 기사, 소셜 미디어 언급 큐레이션 |
| 부동산 | 매물 목록 집계 | 여러 출처의 매물 정보를 하나로 통합 |
| 여행 | 항공료 및 호텔 비교 | 가격, 재고, 정책 모니터링 |
| 금융 | 리스크 모니터링 | 투자 관련 뉴스, 공시, 감성 추적 |
실제 사례:
한 부동산 중개사는 크롤러로 여러 매물 사이트에서 부동산 정보, 사진, 편의시설을 가져와 고객에게 시장을 한눈에 보여 주는 최신 정보를 제공해요(DataHut).
한 이커머스 팀은 경쟁사 SKU와 가격을 모니터링하도록 크롤러를 걸어 두고, 자사 전략을 실시간으로 조정해요(AIMultiple).
웹 크롤러가 작동하는 방식: 단계별 개요
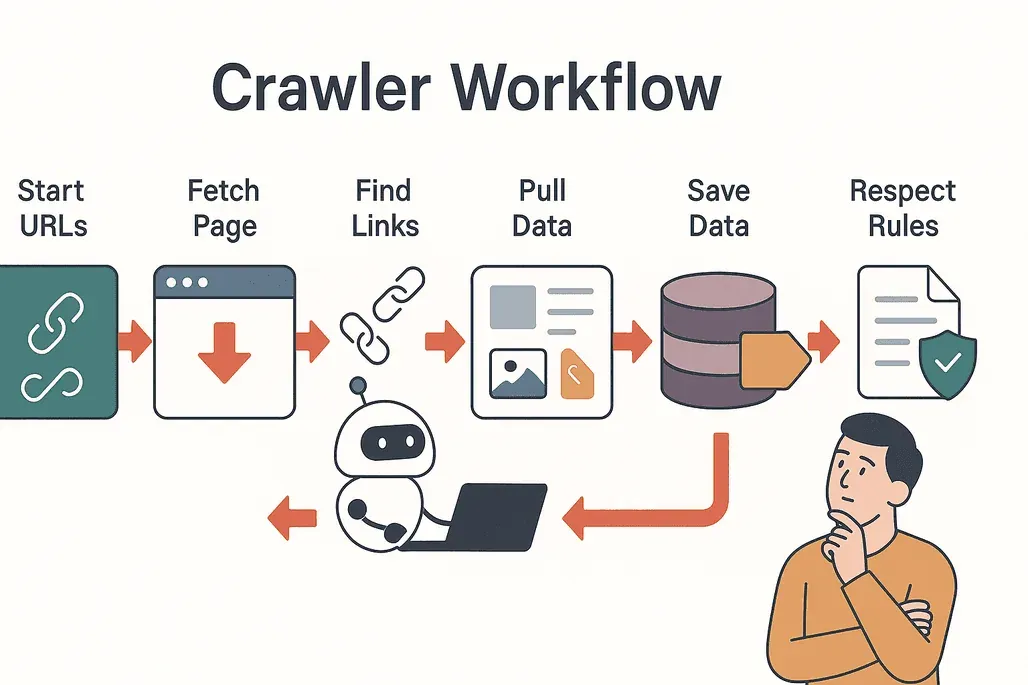 과정을 쉽게 풀어 볼게요. 일반적인 웹 크롤러는 이렇게 움직여요.
과정을 쉽게 풀어 볼게요. 일반적인 웹 크롤러는 이렇게 움직여요.
- 시드로 시작: 크롤러는 시작 URL 목록에서 출발해요.
- 방문 및 가져오기: 각 페이지를 방문해 콘텐츠를 다운로드해요.
- 링크 추출: 페이지에 있는 모든 링크를 찾아요.
- 링크 따라가기: 새롭고 아직 안 본 링크를 큐에 추가해요.
- 데이터 추출: 관련 정보(텍스트, 이미지, 가격 등)를 복사해 구조화해요.
- 결과 저장: 데이터를 데이터베이스에 저장하거나 분석용으로 내보내요.
- 규칙 준수: 각 사이트의
robots.txt파일을 확인해 허용 범위를 파악하고, 제한된 영역은 피해요(Cloudflare).
모범 사례:
- 예의 있게 크롤링하세요(서버에 과부하를 주지 마세요).
- 개인정보와 법적 경계를 존중하세요.
- 중복 콘텐츠와 불필요한 요청을 피하세요.
웹 크롤러를 사용할 때의 과제와 고려 사항
웹 크롤링이 늘 순탄한 건 아니에요. 흔한 어려움은 이래요.
- 서버 부하: 요청이 너무 많으면 웹사이트가 느려지거나 멈출 수 있어요.
- 중복 콘텐츠: 크롤러가 같은 페이지를 반복 방문하거나 루프에 빠질 수 있어요.
- 개인정보와 법적 문제: 모든 데이터를 자유롭게 모을 수 있는 건 아니에요. 항상 서비스 약관과 개인정보 보호법을 확인하세요.
- 기술적 장벽: 일부 사이트는 CAPTCHA, 동적 콘텐츠, 봇 차단 장치로 크롤러 접근을 막아요(DEV Community).
성공 팁:
- 정중한 크롤링 속도를 지키세요.
- 웹사이트 구조 변경을 계속 모니터링하세요.
- 데이터 개인정보 보호 규정을 최신으로 따라가세요.
Thunderbit: 누구나 쉽게 웹 크롤러를 활용하게 만들다
여기서부터가 정말 흥미로운 부분이에요. 전통적으로 웹 크롤러를 설정하려면 코드를 짜고, 설정을 만지고, 문제를 잡느라 오랜 시간을 써야 했어요. 그런데 Thunderbit이 그 흐름을 완전히 바꿔 놨어요.
Thunderbit은 코딩 없이 쓰도록 만든 AI 기반 웹 스크래퍼 Chrome 확장 프로그램이에요. 비즈니스 사용자를 겨냥했죠. 돋보이는 이유는 이래요.
- 자연어 지시: 필요한 데이터를 그냥 말로 설명하면 돼요. ("이 페이지에서 모든 상품명과 가격을 가져와 줘"처럼요.) 그러면 Thunderbit의 AI가 나머지를 알아서 해요.
- AI 기반 필드 추천: "AI 필드 추천"을 클릭하면 Thunderbit이 페이지를 읽고 추출할 최적의 열을 제안해요.
- 하위 페이지 크롤링: 더 자세한 정보가 필요하다면, Thunderbit이 각 하위 페이지(상품 상세 페이지나 LinkedIn 프로필 등)를 방문해 데이터를 자동으로 풍부하게 만들어 줘요.
- 즉시 사용 가능한 템플릿: Amazon, Zillow, Shopify 같은 인기 사이트는 미리 만든 템플릿으로 한 번만 클릭하면 데이터를 뽑을 수 있어요.
- 간편한 내보내기: Excel, Google Sheets, Airtable, Notion으로 바로 보낼 수 있어요. 추가 단계가 없어요.
- 무료 데이터 내보내기: 결과를 CSV나 JSON으로 완전히 무료로 다운로드할 수 있어요.
Thunderbit은 전 세계 10만 명 이상의 사용자, 그러니까 영업팀부터 이커머스 운영자, 부동산 전문가까지 신뢰하고 있어요.
Thunderbit AI 웹 스크래퍼를 무료로 사용해 보기
Thunderbit과 전통적인 웹 크롤러 비교
Thunderbit이 기존 방식과 어떻게 다른지 볼게요.
| 기능 | Thunderbit | 전통적인 크롤러 |
|---|---|---|
| 설정 시간 | 2번 클릭(설정을 AI가 처리) | 수시간/수일(수동 설정, 코딩) |
| 필요한 기술 수준 | 없음(평범한 영어 지시) | 높음(코딩, 셀렉터, 스크립팅) |
| 유연성 | 어떤 사이트에서도 작동, 변경 사항에 적응 | 레이아웃이 바뀌면 깨짐 |
| 하위 페이지 크롤링 | 내장, 추가 설정 없음 | 수동 스크립팅 필요 |
| 내보내기 옵션 | Excel, Sheets, Airtable, Notion, CSV, JSON | 보통 CSV/JSON만 가능 |
| 유지 관리 | AI가 자동으로 적응 | 자주 수동 수정 필요 |
Thunderbit을 쓰면 개발자가 아니어도 되고, 설정을 몇 시간씩 만지지 않아도 돼요. 그냥 가리키고, 클릭하고, 힘든 작업은 AI에게 맡기면 돼요(Thunderbit Blog).
Thunderbit으로 웹 크롤러 시작하기
바로 해 보고 싶나요? Thunderbit을 몇 분 안에 시작하는 방법은 이래요.
- Thunderbit Chrome 확장 프로그램을 설치하세요.
- 크롤링하고 싶은 웹사이트를 여세요.
- Thunderbit 아이콘을 클릭하고 "AI 필드 추천"을 누르세요. AI가 페이지 내용을 보고 열을 추천해 줘요.
- 필요하면 필드를 손본 뒤 "스크래프"를 클릭하세요. 선택했다면 하위 페이지까지 포함해 Thunderbit이 데이터를 뽑아 줘요.
- 결과를 내보내세요. Excel, Google Sheets, Airtable, Notion으로 보내거나 CSV/JSON으로 다운로드할 수 있어요.
데이터 스크래핑이란 무엇이며 2025년에 어떻게 하는가 Get Started Free
그게 전부예요. 스크립트도, 코딩도, 골치 아픈 일도 없어요. 가격을 추적하든, 리드 리스트를 만들든, 뉴스를 모으든, Thunderbit은 대부분의 일상적인 웹 크롤링 작업을 비개발자도 오후 한 번이면 끝낼 수 있게 해 줘요.
결론: 웹 크롤러는 더 똑똑한 데이터 접근의 핵심이에요
웹 크롤러는 디지털 세상을 움직이는 보이지 않는 엔진이에요. 정보를 누구나 접근하고, 검색하고, 바로 쓰게 해 주죠. 검색 엔진부터 영업, 이커머스, 부동산까지, 믿을 만하고 최신인 데이터가 필요한 모두에게 필수 도구가 됐어요.
그리고 Thunderbit 같은 요즘 AI 도구 덕에, 이제 프로그래머가 아니어도 그 힘을 쓸 수 있어요. 클릭 몇 번이면 웹을 구조화되고 바로 쓸 수 있는 자원으로 바꿔, 더 똑똑한 판단과 새 기회를 만들죠.
웹 크롤러가 여러분의 비즈니스에 어떤 도움이 되는지 궁금한가요? Thunderbit을 다운로드하고 오늘부터 웹에 숨은 데이터를 캐 보세요. 더 많은 팁과 심층 가이드는 Thunderbit 블로그에서 볼 수 있어요.
AI 웹 스크래퍼 사용해 보기 Get Started Free
자주 묻는 질문
1. 웹 크롤러가 정확히 무엇인가요?
웹 크롤러는 인터넷을 체계적으로 훑으며 웹페이지를 방문하고, 링크를 따라가며, 인덱싱이나 분석을 위한 정보를 모으는 자동화 프로그램이에요. 스파이더나 봇이라고도 해요.
2. 웹 크롤러와 웹 스크래퍼는 어떻게 다른가요?
웹 크롤러는 웹의 큰 부분을 발견하고 지도처럼 파악하는 데 초점을 맞추고, 보통 페이지에서 페이지로 링크를 따라가요. 반면 웹 스크래퍼는 특정 페이지에서 필요한 데이터를 뽑는 데 집중하죠. Thunderbit 같은 요즘 도구는 이 두 기능을 함께 제공하는 경우가 많아요.
3. 웹 크롤러가 기업에 왜 중요한가요?
웹 크롤러는 기업이 대규모로 최신 정보에 접근하게 해 줘요. 경쟁사 가격 모니터링, 콘텐츠 집계, 리드 리스트 구축 같은 작업에 특히 유용해요. 실시간 의사결정을 돕고 경쟁력 유지에도 도움이 되고요.
4. 웹 크롤러를 사용하는 건 합법인가요?
웹 크롤링은 웹사이트의 서비스 약관과 개인정보 보호정책을 지키며 책임감 있게 쓴다면 보통 합법이에요. 항상 사이트의 robots.txt 파일을 확인하고 개인정보 보호 규정을 따르세요.
5. Thunderbit은 웹 크롤링을 어떻게 더 쉽게 만드나요?
Thunderbit은 AI로 설정, 필드 선택, 데이터 추출을 자동화해요. 자연어 지시와 즉시 사용 가능한 템플릿 덕분에 누구나 코딩이나 기술 지식 없이 웹사이트에서 데이터를 크롤링하고 추출할 수 있어요. 데이터는 Excel, Google Sheets, Airtable, Notion으로 바로 내보내 즉시 쓸 수 있고요.
더 알아보기




