
지난주에 한 사용자가 SuperPages의 배관공 목록을 스프레드시트에 옮기느라 오후 내내 복사·붙여넣기만 했다고 제게 말해줬습니다. 3시간 동안 47행을 처리했는데, 손목은 아팠고 데이터에는 오타가 있었고, 이메일 주소는 끝내 얻지 못했다고 하더군요. 저도 비슷한 경험이 있어서 그 이야기가 유독 와 닿았습니다. 바로 이런 문제를 해결하려고 를 만들었습니다.
SuperPages는 Thryv가 운영하는 미국의 대표적인 지역 비즈니스 디렉터리 중 하나로, 주요 도시와 다양한 업종을 폭넓게 다룹니다. 배관, 치과, 변호사, HVAC 기술자 등 없는 게 없죠. 예전 기술 문서에서는 1,100만 개가 넘는 목록을 보유한 전국 단위 옐로 페이지 데이터베이스로 설명되기도 했고, 지금도 사이트에는 촘촘한 지역 카테고리가 여전히 잘 정리되어 있습니다. 문제는 목록을 찾는 게 아닙니다. 그 데이터를 깔끔하게 정리하고, 필요한 정보를 더 보강해서, 정신 건강이나 오후 시간을 잃지 않고 리드 리스트로 바꾸는 일이죠.
HubSpot의 2024 Sales Trends 보고서에 따르면, 영업 담당자가 실제로 판매에 쓰는 시간은 하루 약 2시간에 불과합니다. 나머지 시간은 데이터 입력과 리서치 같은 업무에 빨려 들어갑니다. 또한 영업 전문가의 81%는 AI가 수작업 시간을 줄이는 데 도움이 될 수 있다고 답했습니다. 이 가이드에서는 코드 없이 쓰는 AI부터 Python까지, SuperPages에서 리드를 추출하는 3가지 방법을 소개합니다. 자신의 수준에 맞는 방식을 골라서, 진짜 성과를 만드는 일로 다시 돌아가 보세요.
SuperPages란 무엇이며, 영업팀이 리드 발굴에 선호하는 이유
SuperPages는 미국 중심의 온라인 비즈니스 디렉터리로, 지역 업체가 연락처, 카테고리, 평점 등과 함께 등록됩니다. 쉽게 말해 옛날 전화번호부인 옐로 페이지가 디지털로 진화한 버전이라고 보면 됩니다. 다만 이제는 지역과 카테고리별 검색이 가능하고, 각 목록에 담긴 정보도 훨씬 풍부합니다.
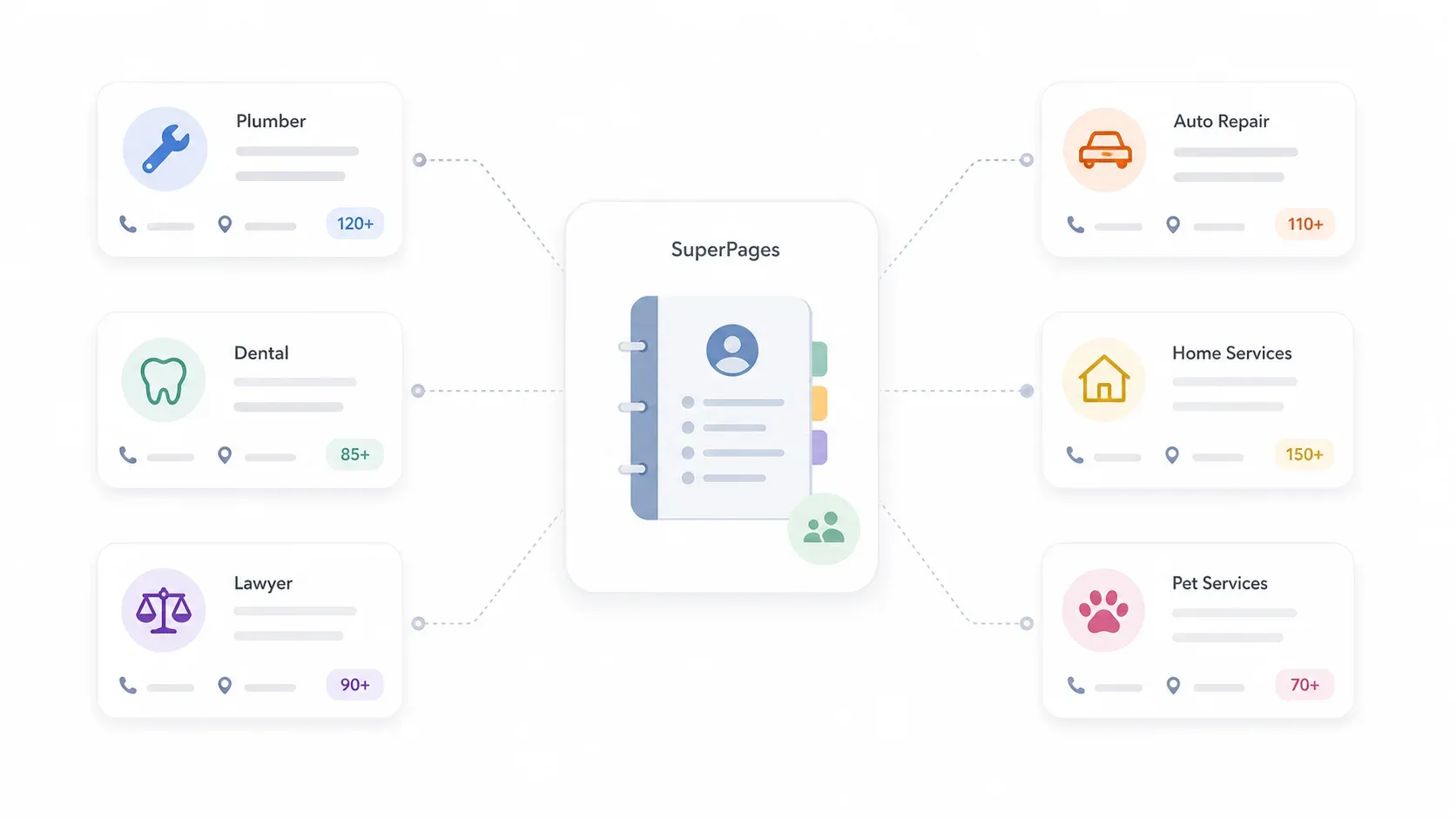
일반적인 SuperPages 목록에는 다음 정보가 포함될 수 있습니다:
- 업체명
- 전화번호
- 도로명 주소
- 웹사이트 URL(있을 경우)
- 카테고리(예: 배관, 가족법, HVAC)
- 평점 및 리뷰
- 영업시간(보통 상세 페이지에 표시)
- 소개 설명(상세 페이지)
SuperPages 홈에서는 Home Services, Plumbers, Electricians, Dentists, Legal Services, Auto Repair, Restaurants, Pet Services 같은 인기 카테고리를 강조합니다. 놀랍게도 이런 분야는 영업팀, 에이전시, 지역 서비스 공급업체가 아웃바운드 영업 대상으로 정확히 노리는 업종과 일치합니다.
한마디로, SuperPages는 미국 지역 비즈니스를 공략하는 누구에게나 보물창고 같은 데이터 소스입니다. 구조화가 잘 되어 있고, 커버 범위도 넓으며, 실제 아웃바운드 캠페인에 바로 연결하기 좋은 카테고리 구성이 되어 있습니다.
SuperPages를 리드 발굴용으로 크롤링해야 하는 이유
SuperPages를 직접 하나씩 열어보며 데이터를 스프레드시트에 옮기는 건 생산성의 블랙홀입니다. 크롤링을 쓰면 그 과정을 자동화해, 몇 시간 걸리던 작업을 몇 분 만에 끝낼 수 있습니다. 게다가 검색 조건을 직접 통제할 수 있어(카테고리 + 도시 + 키워드), 결과가 흔히 구매형 범용 리스트보다 더 정확하고 관련성도 높습니다.
사용자들로부터 자주 보는 대표적인 활용 사례는 다음과 같습니다:
| 활용 사례 | 주요 대상 | 예시 |
|---|---|---|
| 지역 리드 발굴 | 영업팀, 에이전시 | 달라스의 배관 업체 리스트를 만들어 콜드 아웃리치에 활용 |
| 경쟁사 리서치 | 운영, 마케팅 | 한 시장 내 경쟁사별 평점과 서비스를 비교 |
| 시장 매핑 | 사업개발 | 신제품 출시를 위해 특정 우편번호 지역의 모든 치과를 파악 |
| 공급업체 소싱 | 구매, 운영 | 전화번호와 웹사이트 정보가 포함된 지역 공급업체 찾기 |
| 로컬 SEO 잠재고객 발굴 | 에이전시 | 웹사이트가 없거나 목록 정보가 부실한 업체 찾기 |
| 영업 구역 설계 | 현장 영업 | 도시, 우편번호, 서비스 지역별로 업체를 묶어 관리 |
미국 B2B 리드 생성 시장은 2024년 85억 달러 규모로 추정되며, 2034년에는 182억 달러까지 성장할 것으로 전망됩니다. 즉, 이런 데이터에 대한 수요는 앞으로도 계속 커질 가능성이 높습니다. 새로 크롤링한 카테고리·지역별 리스트는 구매형 범용 리스트보다 더 타깃이 분명할 수 있지만, 실제 아웃리치 전에는 반드시 검증과 중복 제거가 필요합니다(이 부분은 뒤에서 더 설명합니다).
최종 결과 예시: SuperPages에서 수집한 샘플 데이터
방법을 소개하기 전에, 실제로 어떤 결과물이 나오는지 먼저 보여드리겠습니다. 많은 가이드가 이 부분을 건너뛰는데, 시간과 노력을 투자한다면 결과물이 어떤 모습인지 아는 게 중요합니다.
아래는 예시 출력 테이블입니다(가상 데이터이지만 현실적인 형태입니다).
| 업체명 | 전화번호 | 주소 | 웹사이트 | 카테고리 | 평점 | 영업시간 | 이메일(보강) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Plumbing | 4.6 | 월-금 7:00-18:00 | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4.8 | 월-토 8:00-19:00 | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Dentists | 4.4 | 월-목 9:00-17:00 | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Legal Services | 4.2 | 월-금 8:30-17:30 | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Auto Repair | 4.7 | 월-토 8:00-18:00 | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Pet Grooming | 4.9 | 화-일 9:00-17:00 | booking@echoparkpets.example |
참고할 점은 다음과 같습니다:
- 검색 결과 페이지에서 가져오는 정보: 업체명, 전화번호, 일부 주소, 카테고리, 평점, 목록 URL
- 업체 상세 페이지(서브페이지)에서 가져오는 정보: 전체 주소, 영업시간, 소개, 리뷰, 때로는 웹사이트
- 보강(enrichment)으로 얻는 정보: 이메일(대개 업체 자체 웹사이트나 보강 도구에서만 찾을 수 있음)
- 정리(cleaning) 과정에서 추가하는 정보: E.164 형식으로 정규화된 전화번호, 표준화된 주/우편번호, 중복 제거 키, 소스 URL, 수집일
이런 형태의 결과는 CRM, Google Sheets, Airtable 베이스에 바로 넣고 즉시 활용할 수 있습니다.
SuperPages를 리드 발굴용으로 크롤링하는 3가지 방법: 빠른 비교

모든 사람이 기술 수준이나 인내심이 같은 건 아닙니다. 그래서 아래에 3가지 방법을 나란히 비교해 두었습니다. 자신에게 맞는 방식을 고르세요.
| 기준 | Thunderbit(AI 노코드) | 비주얼 스크래퍼(예: Octoparse) | Python(Requests + BS4) |
|---|---|---|---|
| 설정 시간 | 약 2분(확장 프로그램 설치) | 약 15분(워크플로우 생성) | 약 30분(라이브러리 설치, 코드 작성) |
| 코딩 필요 여부 | 없음 | 없음 | 필요(Python) |
| 페이지네이션 처리 | 내장됨(클릭 또는 스크롤) | 설정 필요 | 수동 코드 작성 |
| 서브페이지 보강 | 1클릭 서브페이지 크롤링 | 별도 워크플로우/루프 필요 | 별도 스크립트 필요 |
| 차단 회피 | Cloud Scraping이 처리 | 요금제/프록시 옵션에 따라 다름 | 직접 처리(프록시, 헤더, 속도 제한) |
| 내보내기 옵션 | Excel, Google Sheets, Airtable, Notion, CSV, JSON | CSV, Excel, 데이터베이스 | 직접 구현한 형식 |
| 추천 대상 | 영업팀, 에이전시, 비개발자 | 어느 정도 기술이 있는 사용자 | 완전한 제어를 원하는 개발자 |
제 추천은 이렇습니다. 2분 안에 바로 시작하고 싶다면 방법 1로 가세요. 시각적인 워크플로우를 선호하고 어느 정도 설정을 감수할 수 있다면 방법 2가 좋습니다. Python을 잘 다루고 완전한 제어가 필요하다면 방법 3이 맞습니다.
방법 1: Thunderbit로 SuperPages 리드 크롤링하기(AI, 노코드)
이 방법은 “SuperPages 검색 결과를 갖고 있다”에서 “리드 리스트를 손에 넣었다”로 가장 빠르게 넘어가는 경로입니다. 코딩도 없고, 워크플로우 빌더도 없고, 프록시 설정도 필요 없습니다. Thunderbit를 만든 입장이라 편향이 있을 수는 있지만, 정확히 어떤 일이 벌어지는지 직접 보시면 판단하실 수 있을 겁니다.
난이도: 초급
소요 시간: 카테고리/도시 기준 전체 크롤링에 약 5분
준비물: Chrome 브라우저, Thunderbit Chrome 확장 프로그램(무료 플랜 가능)
1단계: Thunderbit를 설치하고 SuperPages를 연다
로 가서 Thunderbit 확장 프로그램을 설치하세요. 1분이면 충분합니다. 설치 후에는 SuperPages 검색 결과 페이지로 이동합니다. 예를 들어 superpages.com에서 “Plumbers in Los Angeles, CA”를 검색하면 됩니다.
브라우저 툴바에 Thunderbit 아이콘이 보이고, 바로 사용할 수 있는 사이드바 패널이 열려 있어야 합니다.
2단계: “AI Suggest Fields”를 눌러 데이터 컬럼을 자동 인식한다
Thunderbit 사이드바를 열고 “AI Suggest Fields”를 클릭하세요. Thunderbit의 AI가 페이지를 읽고, 발견한 내용을 바탕으로 자동으로 컬럼을 추천합니다. 보통 업체명, 전화번호, 주소, 웹사이트, 카테고리, 평점, 목록 URL 등이 잡힙니다.
크롤링 전에 컬럼을 조정하거나, 추가하거나, 삭제할 수 있습니다. “웹사이트가 있는가?” 또는 “서비스 지역인가?” 같은 사용자 지정 컬럼을 넣고 싶다면 Field AI Prompt에 일반 영어로 설명만 입력하면 됩니다. 예를 들어 “전화번호를 +1XXXXXXXXXX 형식으로 맞춰줘” 또는 “주거용/상업용으로 분류해줘”라고 지시할 수 있습니다.
이제 Thunderbit 패널에 설정한 컬럼이 담긴 테이블 미리보기가 보여야 합니다.
3단계: “Scrape”를 눌러 데이터를 채운다
파란색 “Scrape” 버튼을 누르세요. Thunderbit가 현재 페이지의 모든 목록을 추출해 표를 한 행씩 채워 넣습니다. 일반적인 SuperPages 결과 페이지라면 이 작업은 30~45초 정도 걸립니다.
Thunderbit는 페이지네이션도 자동으로 처리합니다. “Next” 버튼이나 무한 스크롤을 감지해, 페이지가 끝나거나 한도에 도달할 때까지 계속 진행합니다. 대규모 결과 세트(예: 대도시권의 모든 배관 업체)를 크롤링한다면 Cloud Scraping 모드로 전환하세요. 브라우저를 점유하지 않고 한 번에 최대 50페이지까지 처리할 수 있습니다.
4단계: Subpage Scraping으로 각 목록을 보강한다
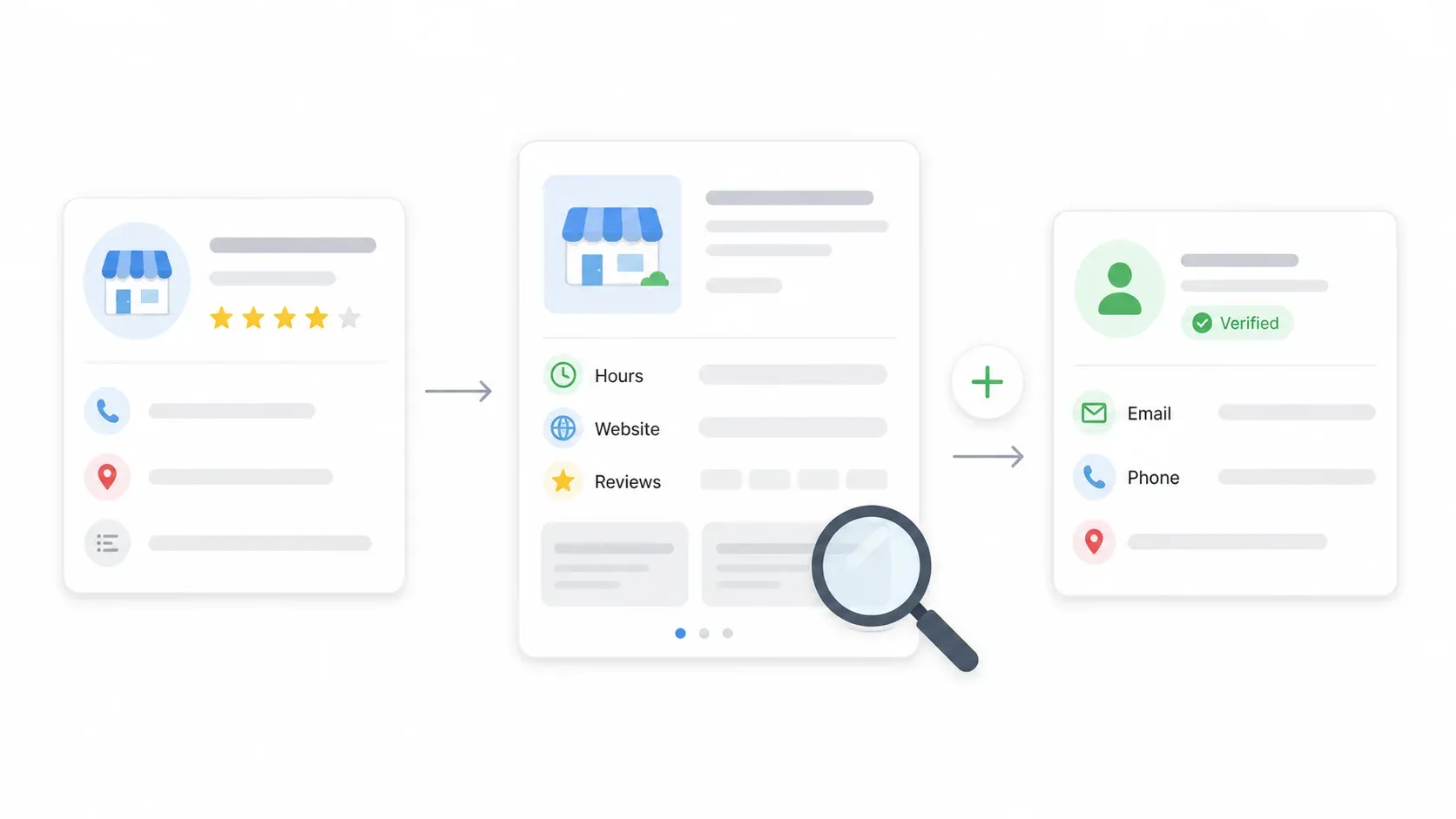
검색 결과 페이지에는 기본 정보만 나오지만, 진짜 핵심인 영업시간, 전체 소개, 리뷰, 때로는 이메일은 각 업체의 상세 페이지에 있습니다. “Scrape Subpages”를 클릭하면 Thunderbit가 각 목록의 상세 페이지를 방문해, 영업시간, 설명, 웹사이트 URL, 그리고 거기에 보이는 모든 연락처 정보를 보강 컬럼으로 가져옵니다.
이 과정은 클릭 한 번이면 됩니다. 별도 워크플로우도 없고, 복잡한 설정도 없습니다. 보강된 데이터는 기존 테이블에 바로 이어 붙습니다.
5단계: 리드를 Excel, Google Sheets, Airtable, Notion으로 내보낸다
데이터가 만족스러우면 Export를 클릭하세요. Thunderbit는 리드를 다음으로 바로 보낼 수 있습니다:
- Google Sheets(CRM 준비 및 공유에 유용)
- Airtable(가벼운 파이프라인 테이블)
- Notion(리서치 데이터베이스)
- Excel / CSV(CRM 가져오기용)
- JSON(개발자 전달용)
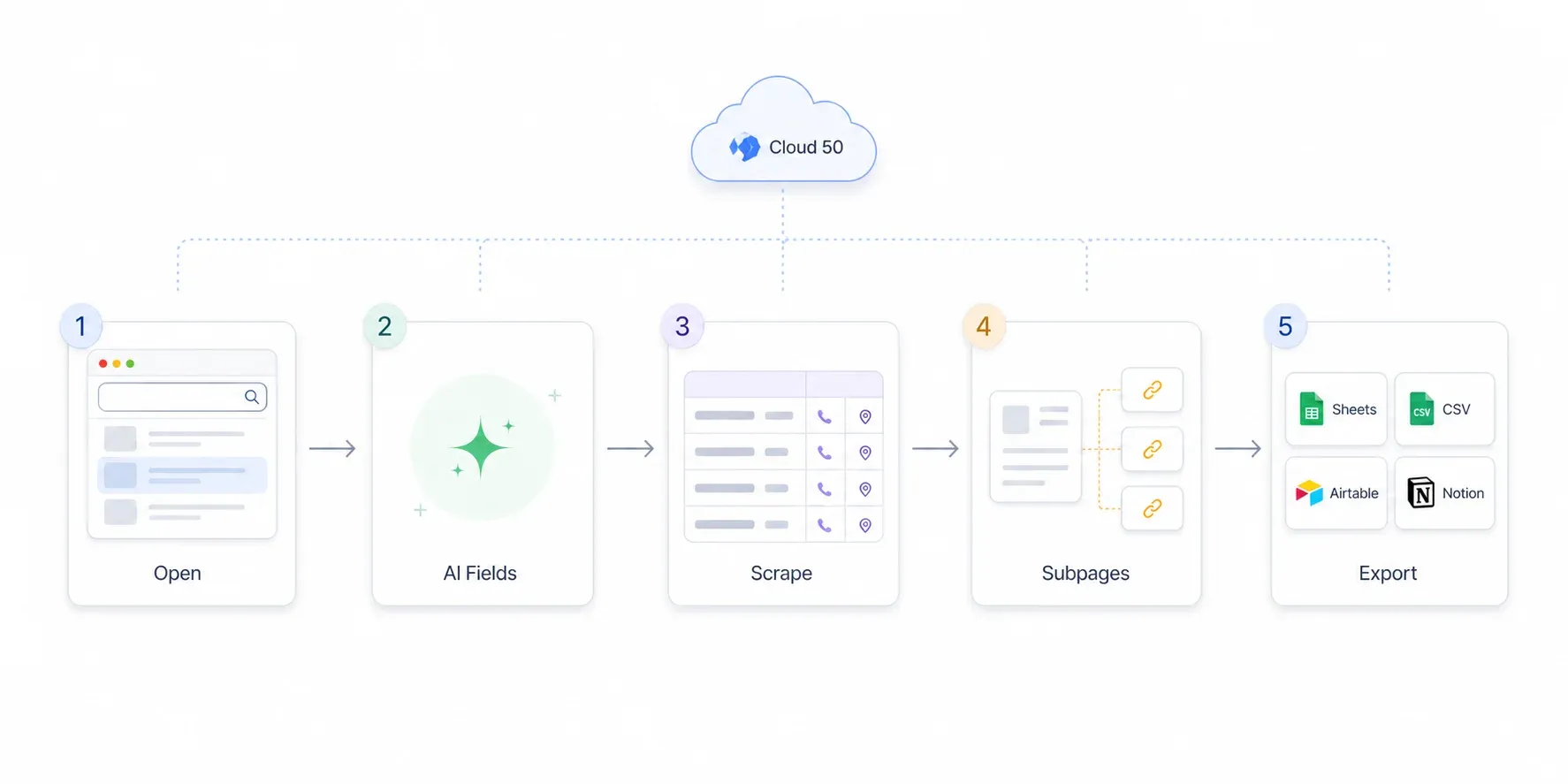
모든 내보내기 옵션은 무료입니다. HubSpot이나 Salesforce로 리드를 넣는다면 CSV나 Google Sheets로 내보내는 것이 보통 가장 빠릅니다.
팁: 넓은 주 단위 검색보다 카테고리 + 도시 기준으로 크롤링하세요. “Texas의 plumbers”보다 “Dallas TX의 emergency plumbers”가 훨씬 더 정교하고 실행 가능한 리스트를 만듭니다. 추적성을 위해 “Source URL”과 “Scraped At” 컬럼도 추가해 두는 것이 좋습니다.
방법 2: 비주얼 스크래핑 도구로 SuperPages 크롤링하기(Octoparse 예시)
Octoparse 같은 비주얼 스크래핑 도구는 중간 지점에 있습니다. 코딩은 필요 없지만, Thunderbit보다 설정과 구성이 조금 더 많습니다. Octoparse에는 간단한 활용을 위한 SuperPages 사전 제작 템플릿도 있습니다.
난이도: 중급
소요 시간: 설정 + 크롤링에 약 20~30분
준비물: Octoparse 계정(무료 플랜 제공, 단 제약 있음)
1단계: 새 작업을 만들고 SuperPages URL을 불러온다
Octoparse를 열고 “New Task”를 클릭한 뒤 SuperPages 검색 URL을 붙여넣으세요(예: “https://www.superpages.com/los-angeles-ca/plumbers”). 내장 브라우저가 페이지를 불러옵니다.
2단계: 데이터 필드를 자동 감지하거나 수동으로 선택한다
“Auto-detect”를 클릭하면 Octoparse가 페이지를 스캔해 관련 있다고 판단한 데이터 필드를 강조 표시합니다. Data Preview 패널을 확인하세요. 제 경험상 자동 감지는 대부분의 필드를 잘 잡지만, 광고 라벨이나 내비게이션 텍스트 같은 불필요한 요소를 포함하거나 일부 필드를 놓칠 때도 있습니다. 그래서 몇 개는 수동으로 추가하거나 제거해야 할 가능성이 높습니다.
Octoparse 도움말 문서에 따르면, 자동 감지는 페이지네이션과 데이터 추출 단계를 포함한 기본 워크플로우를 만들어 주지만, 누락된 데이터는 사용자가 직접 추가해야 할 수 있습니다.
3단계: 워크플로우를 만들고 페이지네이션을 설정한다
“Create workflow”를 클릭하세요. Octoparse가 단계별 작업 시퀀스를 자동 생성합니다. 페이지네이션 단계를 확인해서 “Next”를 제대로 클릭하거나 추가 결과를 올바르게 불러오는지 점검하세요. 각 업체의 상세 페이지에서 영업시간, 이메일, 설명 같은 데이터를 가져오려면 워크플로우 안에 상세 페이지 루프나 서브페이지 동작을 추가해야 합니다. 이 부분은 Thunderbit의 원클릭 서브페이지 방식보다 복잡합니다.
4단계: 작업을 실행하고 데이터를 내보낸다
작업을 로컬에서 실행할 수 있고(작업량이 적을 때), Octoparse 클라우드에서 실행할 수도 있습니다(예약 작업이나 대규모 작업용이며, 클라우드는 유료 기능입니다). 완료되면 CSV, Excel, JSON으로 내보내세요.
알아두면 좋은 제한 사항: Octoparse 무료 플랜에는 10개 작업, 월 50,000행, 로컬 추출만 포함됩니다. 클라우드 실행, IP 회전, CAPTCHA 해결, 일부 내보내기 연동은 연간 결제 기준 월 약 69달러부터 시작하는 유료 플랜이 필요합니다.
방법 3: Python(Requests + BeautifulSoup)으로 SuperPages 크롤링하기
이것은 개발자용 경로입니다. 제어권은 완전하지만, 책임도 전부 사용자에게 있습니다. Python 스크립트를 직접 작성하고 유지보수할 수 있다면 가장 유연한 방법이지만, 그만큼 골치 아픈 일도 많습니다.
난이도: 고급
소요 시간: 약 30~60분(설정 + 코딩 + 디버깅)
준비물: Python 3.x, pip, requests, beautifulsoup4, lxml, 코드 에디터
1단계: Python 환경을 준비한다
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandas2단계: SuperPages의 HTML 구조를 확인한다
SuperPages 결과 페이지에서 개발자 도구(F12)를 여세요. 업체명, 주소, 전화번호, 웹사이트, 상세 페이지 링크에 해당하는 CSS 선택자를 찾아야 합니다. HTML 구조는 예고 없이 바뀔 수 있으므로, 지금 맞던 선택자가 언제든 깨질 수 있다는 점을 기억하세요.
3단계: 목록 크롤러를 작성하고 페이지네이션을 처리한다
아래는 단순화한 예시입니다. 중요한 주의점이 하나 있습니다. 제 테스트에서는 SuperPages에 직접 요청했을 때 Cloudflare의 “Attention Required” 차단 페이지가 반환되었습니다. 단순한 Requests 스크립트는 대규모에서는 실패할 수 있으므로, 브라우저 세션 컨텍스트, 속도 제한, 재시도, 또는 허가된 대안이 필요할 수 있습니다.
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("차단됨. 속도를 낮추거나 브라우저/클라우드 스크래핑으로 전환하세요.")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)4단계: 상세 페이지를 크롤링해 데이터를 보강한다
각 상세 페이지 URL을 방문해 영업시간, 이메일, 설명, 리뷰를 추출하는 별도 함수를 작성하세요. 즉, 속도 제한 관리, 오류 처리, 경우에 따라 프록시까지 모두 직접 다뤄야 합니다.
5단계: 데이터를 CSV 또는 JSON으로 저장한다
Python의 csv 또는 json 모듈을 사용하면 됩니다. 중복 제거, 정리, 내보내기 로직도 직접 작성해야 합니다.
자주 발생하는 문제는 다음과 같습니다:
- SuperPages는 Cloudflare 같은 봇 차단 시스템으로 요청을 막을 수 있습니다(테스트에서 확인됨).
- 여기서는 선택자를 넓게 잡았는데, SuperPages의 마크업이 바뀔 수 있기 때문입니다.
- 검색 결과 페이지에 이메일이 있다고 가정하지 마세요. 대부분 없습니다.
- 운영용 크롤러에는 robots/TOS 검토, 속도 제한, 재시도/백오프, 구조화된 로그, 오류 캡처가 필요합니다.
Python 크롤링을 더 깊게 배우고 싶다면, 웹 스크래핑 with Python 가이드나 BeautifulSoup 튜토리얼을 참고하세요.
원시 데이터를 진짜 리드로 바꾸는 전체 파이프라인(크롤링 → 정리 → 검증 → CRM)
대부분의 크롤링 가이드는 여기서 끝나지만, 실제 가치는 지금부터 시작됩니다. 크롤링은 재료를 가져오는 일이고, 이를 실제로 쓸 수 있는 리드 리스트로 바꾸려면 몇 단계가 더 필요합니다.
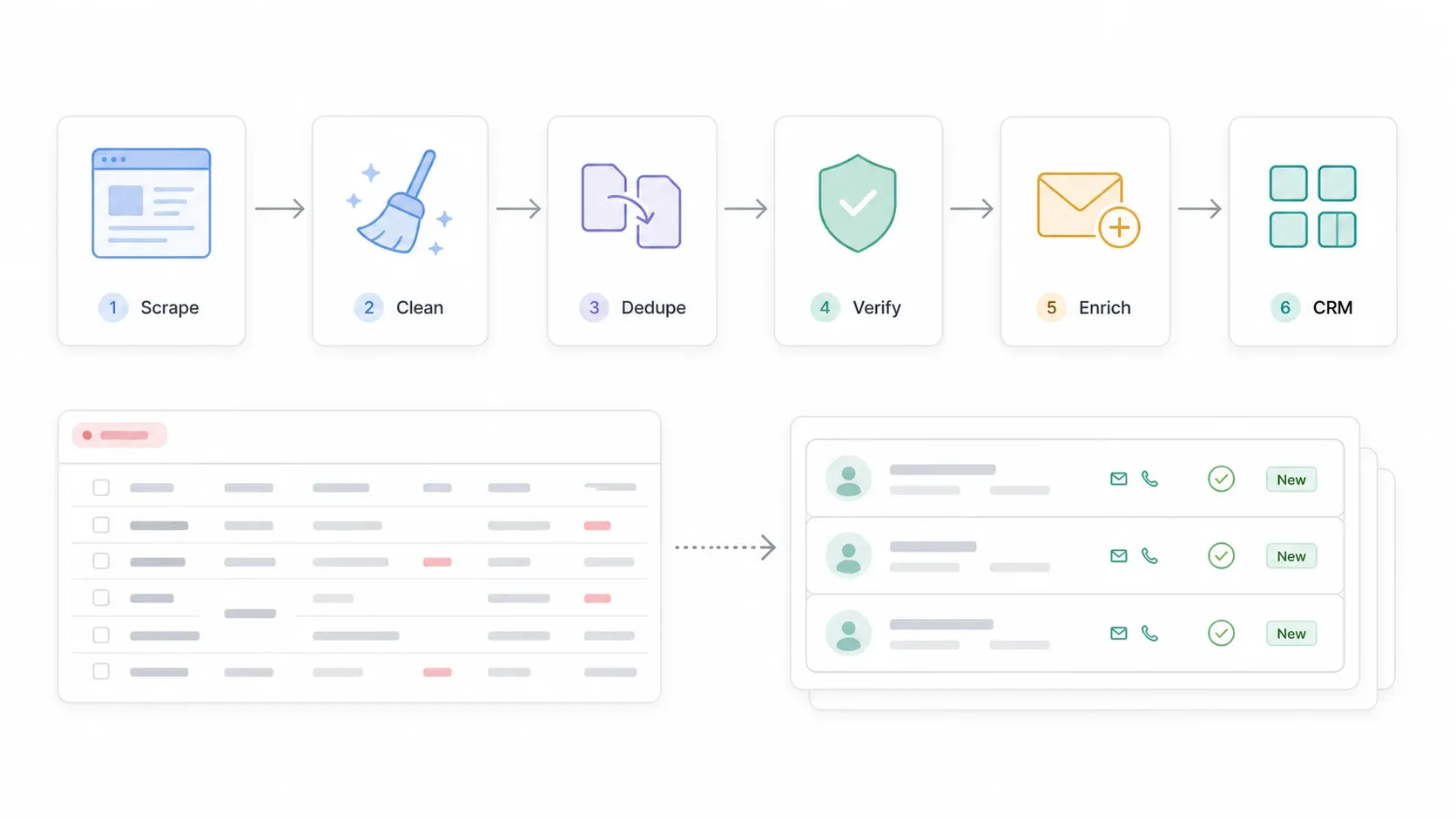
파이프라인은 이렇게 흘러갑니다:
SuperPages 검색 → 목록 크롤링 → 상세 페이지/웹사이트 크롤링 → Google Sheets 또는 CSV로 내보내기 → 전화번호, 주소, 카테고리 정리 → 중복 제거 → 이메일/전화번호 검증 → 누락 연락처 보강 → CRM 가져오기 → 규정 준수 아웃리치
중복 제거: 중복 목록 없애기
SuperPages에는 같은 업체가 여러 카테고리에 동시에 등장하는 경우가 많습니다. 같은 도시에서 “plumbers”와 “drain cleaning”을 함께 크롤링했다면 겹치는 항목이 생깁니다.
- 1차 중복 제거 키: 정규화된 전화번호 + 정규화된 도로명 주소
- 2차: 도메인 + 도시
- 최후의 대안: 업체명 + 우편번호(프랜차이즈는 수동 검토)
Google Sheets에서는 정확히 같은 행을 제거할 때 =UNIQUE(A:H)를 쓰거나, 근사 중복을 잡기 위해 =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")) 같은 보조 열을 만들 수 있습니다. Excel에서는 데이터 > 중복 항목 제거를 사용하면 됩니다.
데이터 정리: 전화번호, 주소, 형식 표준화
- 전화번호는 E.164 형식으로 맞추세요. 미국 기준으로는 +1 뒤에 10자리 숫자를 붙이면 됩니다. 대부분의 CRM과 다이얼러가 이 형식을 기대합니다. Thunderbit의 Field AI Prompt를 쓰면 크롤링 중 자동 포맷도 가능합니다.
- 주소를 표준화하세요. 약어를 풀고, 빠진 우편번호를 채우고, 필요하면 거리/도시/주/우편번호로 나눠 두세요.
- URL에서 HTML 잔여물, 불필요한 공백, 추적 쿼리 파라미터를 제거하세요.
- 추적을 위해
source_directory,source_url,scraped_at컬럼을 추가하세요.
아웃리치 전에 이메일과 전화번호 검증하기
크롤링한 모든 이메일 주소에 무작정 콜드 메일을 보내지 마세요. 검증은 발신자 평판을 지키고 반송률을 낮춰 줍니다.
- 이메일 검증: ZeroBounce(2,000 크레딧 기준 약 39달러부터, 매월 100개 무료 크레딧 포함) 또는 Bouncer(1,000 크레딧에 8달러, 크레딧 만료 없음)가 좋은 선택입니다.
- 전화번호 검증: Twilio Lookup은 포맷팅과 검증을 무료로 제공하며, Caller ID는 요청당 0.01달러입니다.
- Thunderbit의 무료 Email Extractor와 Phone Number Extractor를 사용하면 목록 페이지에서 놓친 연락처도 찾을 수 있습니다.
보강: SuperPages에 이메일이 없을 때 연락처 찾는 방법
많은 SuperPages 목록에는 이메일이 표시되지 않습니다. 특히 검색 결과 페이지에는 거의 안 나옵니다. 이럴 때는 이렇게 하세요:
- 업체 웹사이트의 Contact, About, 또는 푸터 페이지를 크롤링합니다. Thunderbit의 Subpage Scraping이나 Email Extractor를 쓰면 대량 처리도 가능합니다.
- Apollo, BetterContact, Icypeas, Prospeo 같은 보강 도구를 사용합니다. 다만 작은 지역 업체(직원 2명의 배관점, 혼자 하는 치과)에서는 대형 B2B 데이터베이스가 비어 있는 경우가 많습니다. 이런 경우에는 웹사이트 우선 추출이 더 잘 맞습니다.
- 여러 디렉터리를 함께 사용합니다. SuperPages, Yellow Pages, Google Maps를 같은 카테고리/도시 기준으로 크롤링한 뒤 병합하고 중복을 제거하세요. 서로 겹치는 부분이 더 완성도 높은 레코드를 만들어 줍니다.
지역 SMB 리스트를 Apollo에 넣었다가 대부분 빈칸만 나오는 경험을 해보셨다면, 혼자가 아닙니다. 그래서 이런 대상에는 웹사이트 우선 방식이 중요합니다.
CRM 가져오기: HubSpot, Salesforce, Google Sheets에 리드 넣기
- HubSpot: Data Management > Data Integration > Import data > Quick import(contacts only)로 이동하세요.
.csv또는.xlsx파일을 업로드하면 됩니다. HubSpot의 가져오기 가이드에 필드 매핑 방법이 나와 있습니다. - Salesforce: Data Import Wizard를 사용하세요. CSV를 준비하고, 원본 필드를 Salesforce 필드에 매핑한 뒤 가져오기를 실행합니다.
- Google Sheets / Airtable / Notion: Thunderbit는 세 서비스 모두로 직접 내보낼 수 있어 CSV를 거칠 필요가 없습니다.
팁: 가져오기 전에 크롤링한 컬럼을 CRM 필드와 미리 매핑해 두세요. 몇 분만 투자하면 나중에 수시간의 수작업 정리를 줄일 수 있습니다.
SuperPages와 다른 지역 비즈니스 디렉터리 비교: 가장 좋은 리드는 어디에 있나
SuperPages는 좋은 출발점이지만, 크롤링할 가치가 있는 디렉터리는 이것만이 아닙니다. 아래처럼 비교할 수 있습니다:
| 디렉터리 | 리드 수량 | 사용 가능한 데이터 항목 | 데이터 최신성 | 크롤링 난이도 | 추천 용도 |
|---|---|---|---|---|---|
| SuperPages | 많음(미국 중심) | 이름, 전화, 주소, 웹사이트, 카테고리, 평점 | 보통 | 중간 | 홈 서비스, 시공업체, SMB |
| Yellow Pages | 많음(미국 중심) | SuperPages와 유사 | 보통 | 중간 | 일반적인 지역 비즈니스 아웃리치 |
| Google Maps | 매우 많음(글로벌) | 이름, 전화, 주소, 웹사이트, 리뷰, 영업시간, 사진 | 높음(소유자 업데이트) | 높음(강한 봇 차단) | 가장 최신의 지역 데이터 |
| Yelp | 많음(미국 중심) | 이름, 전화, 주소, 리뷰, 가격대 | 높음 | 높음 | 음식점, 리테일, 서비스 업종 |
| Manta | 중간 | 이름, 전화, 주소, 추정 매출, 직원 수 | 보통 | 낮음 | B2B 잠재고객 발굴(매출/인원 데이터) |
| BBB | 중간 | 이름, 전화, 주소, 인증, 민원 | 보통 | 낮음 | 신뢰할 수 있는 검증 업체 |
출처: SuperPages 홈페이지, VLDB SuperPages 논문, Google Places API 문서, Yelp Places API 문서, Manta 홈페이지, BBB 가이드.
Thunderbit는 이 모든 사이트에서 사용할 수 있으며, Google Maps나 SuperPages처럼 인기 사이트에는 즉시 사용할 수 있는 템플릿도 제공합니다. 덕분에 같은 워크플로우를 여러 소스에 적용하고 리드 리스트를 통합할 수 있습니다. 제 경험상 가장 좋은 방법은 같은 카테고리/도시를 기준으로 2~3개 디렉터리를 크롤링한 뒤 중복 제거하는 것입니다. 겹치는 데이터가 빈칸을 채워 주고, 더 완전한 그림을 만들어 줍니다.
다른 디렉터리 크롤링에 대해 더 알고 싶다면 , , 가이드를 참고하세요.
SuperPages 리드 크롤링 시 알아야 할 법적·윤리적 팁
저는 변호사가 아니며, 이것은 법률 자문이 아닙니다. 하지만 이 분야에서 충분히 오래 일해 본 결과, 규정을 무시하는 건 금방 문제를 부르는 지름길이라는 걸 압니다. 실무적으로 꼭 알아야 할 사항만 정리해 드리겠습니다.
공개 비즈니스 데이터와 개인 데이터
업체명, 비즈니스 전화번호, 비즈니스 주소, 비즈니스 웹사이트 같은 목록 정보는 일반적으로 공개된 상업 데이터로 간주됩니다. GDPR이나 CCPA의 개인 소비자 데이터와는 다릅니다. 하지만 “공개”라고 해서 “아무 규칙도 없다”는 뜻은 아닙니다. 항상 사이트의 서비스 약관을 확인하세요.
SuperPages의 이용 약관(2019년 7월 업데이트)에는 “Data Mining Prohibited” 조항이 있으며, Thryv의 사전 동의 없이 봇, 크롤러, 스파이더 또는 유사한 도구로 데이터를 수집하거나 추출해서는 안 된다고 명시되어 있습니다. 이 글에서는 방법과 워크플로우를 설명하지만, 대량 크롤링 전에 해당 약관을 검토하고 필요하면 허가를 받는 것이 좋습니다.
아웃리치 준수: CAN-SPAM과 TCPA 기본사항
크롤링한 이메일로 콜드 아웃리치를 한다면, FTC의 CAN-SPAM 가이드에 따라 다음을 지켜야 합니다:
- 거짓되거나 오해를 부르는 헤더를 사용하지 말 것
- 기만적인 제목을 사용하지 말 것
- 필요한 경우 메시지가 광고임을 표시할 것
- 유효한 실제 우편 주소를 포함할 것
- 명확한 수신 거부 방법을 제공하고, 요청은 즉시 반영할 것
크롤링한 전화번호로 콜드 콜을 할 경우에는 National Do Not Call Registry를 확인하고 TCPA 규정을 준수해야 합니다. 특히 자동 통화, 녹음 메시지, SMS 관련 규정에 주의하세요. FTC는 2024년에 기만적인 B2B 텔레마케팅과 AI 기반 사기 전화에 대한 보호를 강화하는 변경 사항을 발표했습니다.
간단한 준수 체크리스트
- ✅ 공개적으로 등록된 비즈니스 데이터만 크롤링하기
- ✅ SuperPages 이용 약관을 검토하고 필요한 경우 허가 받기
- ✅ 아웃리치 전에 연락처 검증하기
- ✅ 이메일에는 수신 거부 옵션 포함하기
- ✅ robots.txt와 속도 제한을 존중하기
- ✅ DNC 및 이메일 차단 목록 유지하기
- ⚠️ 개인/소비자 데이터는 크롤링하지 않기
- ⚠️ 법률 검토 없이 원본 크롤링 데이터를 재판매하지 않기
자신에게 맞는 방법을 골라 리드 리스트 구축을 시작하세요
SuperPages를 리드용으로 크롤링하는 건 단순히 웹페이지에서 행을 뽑아내는 일이 아닙니다. 진짜 가치는 전체 파이프라인에 있습니다. 크롤링하고, 정리하고, 중복을 제거하고, 검증하고, 보강하고, CRM에 넣고, 규정을 지켜 아웃리치하는 과정 전체가 핵심입니다.
짧게 정리하면 이렇습니다:
- Thunderbit는 영업팀, 에이전시, 비개발자에게 가장 빠른 방법입니다. 두 번 클릭하면 크롤링되고, 한 번 클릭하면 서브페이지로 보강하며, Google Sheets, Airtable, Notion, Excel로 무료 내보내기가 가능합니다. 무료로 사용해 보세요.
- Octoparse는 설정을 좀 더 세밀하게 조정하고 싶은 어느 정도 기술이 있는 사용자에게 적합한 비주얼 워크플로우 도구입니다.
- Python은 개발자에게 완전한 유연성을 제공하지만, 유지보수와 차단 회피 문제, 내장된 보강 기능 부재라는 부담이 있습니다.
- 그리고 같은 방식이 Yellow Pages, Google Maps, Yelp, Manta, BBB에도 그대로 적용됩니다. 여러 소스를 크롤링하고 병합하고 중복을 제거하면, 가능한 한 가장 완전한 지역 리드 리스트를 만들 수 있습니다.
Thunderbit가 실제로 어떻게 작동하는지 보고 싶다면 에서 튜토리얼을 확인하거나, 팀에 맞는 요금을 보려면 를 살펴보세요.
이제 디렉터리 페이지를 파이프라인으로 바꿔 보세요. 전화번호는 항상 올바르게 포맷되고, 이메일은 언제나 검증되어 있기를 바랍니다.
자주 묻는 질문(FAQs)
SuperPages를 리드 발굴용으로 크롤링하는 것이 합법인가요?
공개된 비즈니스 디렉터리 데이터를 B2B 리서치에 활용하는 것은 일반적인 관행이지만, SuperPages의 이용 약관은 Thryv의 사전 동의 없이 데이터 마이닝을 금지합니다. 항상 사이트 약관을 확인하고, 필요한 경우 허가를 받으며, CAN-SPAM과 TCPA 같은 아웃리치 규정도 준수하세요. 이 글은 교육 목적으로 방법과 워크플로우를 설명한 것이며, 준법 사용의 책임은 사용자에게 있습니다.
SuperPages에서 어떤 데이터를 얻을 수 있나요?
일반적인 크롤링 결과에는 업체명, 전화번호, 주소, 웹사이트, 카테고리, 평점, 영업시간, 설명이 포함됩니다. 이메일은 검색 결과 페이지에 거의 표시되지 않으며, 보통은 업체 상세 페이지나 업체 자체 웹사이트를 방문해야 찾을 수 있습니다(서브페이지 크롤링 또는 이메일 추출기를 사용).
코딩 없이 SuperPages를 크롤링할 수 있나요?
네. Thunderbit(AI Chrome 확장 프로그램)나 Octoparse(비주얼 스크래퍼) 같은 도구를 사용하면 코드를 한 줄도 쓰지 않고 SuperPages를 크롤링할 수 있습니다. 가장 빠른 옵션은 Thunderbit입니다. 확장 프로그램을 설치하고 SuperPages 검색을 연 뒤, “AI Suggest Fields”, 다음에 “Scrape”를 클릭하면 됩니다.
SuperPages 크롤링에서 페이지네이션은 어떻게 처리하나요?
Thunderbit는 페이지네이션을 자동으로 처리합니다. “Next” 버튼이나 무한 스크롤을 감지하고 계속 진행합니다. Octoparse는 워크플로우에서 페이지네이션 단계를 직접 설정해야 합니다. Python에서는 페이지 번호를 증가시키고 마지막 페이지를 감지하는 루프를 직접 작성해야 합니다.
SuperPages 목록에서 이메일은 어떻게 얻나요?
대부분의 SuperPages 목록은 검색 결과 페이지에 이메일을 표시하지 않습니다. Thunderbit의 Subpage Scraping으로 각 상세 페이지를 방문하거나, 업체 웹사이트에서 무료 Email Extractor를 사용하세요. 그래도 부족하면 Apollo, BetterContact, Prospeo 같은 보강 도구를 써 볼 수 있습니다. 다만 작은 지역 비즈니스에는 대형 B2B 데이터베이스보다 웹사이트 우선 추출이 더 잘 맞는 경우가 많습니다.
더 알아보기