
Welcome to the Jungle की जॉब लिस्टिंग्स और कंपनी प्रोफाइल्स से के साथ संरचित डेटा निकालें। यह एक AI Web Scraper है जो पेज को पढ़कर आपके लिए उसे साफ-सुथरी टेबल में बदल देता है। आप AI Suggest Fields पर क्लिक करते हैं ताकि AI आपके लिए सबसे उपयुक्त कॉलम सुझा दे, फिर Scrape पर क्लिक करके डेटा इकट्ठा कर लेते हैं। चाहें तो subpage scraping का इस्तेमाल करके हर जॉब/कंपनी के डिटेल पेज पर जाकर अतिरिक्त जानकारी भी अपने-आप जोड़ सकते हैं।
🧭 Welcome to the Jungle Scraper क्या है
Welcome to the Jungle Scraper एक है, जिसे AI की मदद से से डेटा निकालने के लिए बनाया गया है—बिना किसी कोडिंग के। बस वह पेज खोलें जिससे आप डेटा लेना चाहते हैं (जैसे या ), AI Suggest Fields पर क्लिक करें, और Thunderbit आपके लिए एक संरचित स्कीमा (कॉलम + डेटा टाइप) बना देगा। फिर Scrape पर क्लिक करके रोज़ (rows) कलेक्ट करें और Excel, Google Sheets, Airtable, या Notion में एक्सपोर्ट कर दें।

🧰 Welcome to the Jungle से आप क्या-क्या स्क्रैप कर सकते हैं
Welcome to the Jungle हायरिंग और एम्प्लॉयर-ब्रांड से जुड़े डेटा का बेहतरीन स्रोत है। Thunderbit के साथ आप पहले लिस्टिंग पेज (तेज़ी से बहुत सारी rows) स्क्रैप कर सकते हैं, और फिर Subpage Scraping से हर जॉब पोस्ट या कंपनी प्रोफाइल के अंदर की गहरी जानकारी भी निकाल सकते हैं।
Welcome to the Jungle से जॉब लिस्टिंग्स स्क्रैप करें
से रोल्स स्क्रैप करके आप एक सर्चेबल जॉब डेटाबेस बना सकते हैं, हायरिंग ट्रेंड्स ट्रैक कर सकते हैं, या खास कीवर्ड्स, लोकेशन्स और कंपनियों पर नज़र रख सकते हैं।

Steps:
- डाउनलोड करें और अकाउंट रजिस्टर करें।
- जिस पेज से डेटा चाहिए, वहाँ जाएँ—उदाहरण: ।
- सुझाए गए कॉलम नाम और डेटा टाइप जनरेट करने के लिए AI Suggest Fields पर क्लिक करें।
- स्क्रैपर चलाने के लिए Scrape पर क्लिक करें, फिर Excel, Google Sheets, Airtable, या Notion में एक्सपोर्ट करें।
Column names
| Column | Description |
|---|---|
| 🧑💻 Job Title | लिस्टिंग कार्ड पर दिखने वाला रोल/पद का नाम (जैसे Product Manager, Sales Executive)। |
| 🏢 Company Name | जॉब लिस्टिंग से जुड़ी कंपनी/एम्प्लॉयर का नाम। |
| 🌍 Location | लिस्टिंग में दिखने वाला शहर/क्षेत्र/देश या रिमोट संकेत। |
| 🧭 Work Type | On-site, hybrid, या remote (यदि लिस्टिंग में उपलब्ध हो)। |
| 🕒 Employment Type | Full-time, part-time, internship, contract (यदि उपलब्ध हो)। |
| 💰 Salary Range | लिस्टिंग में दिखने वाली सैलरी जानकारी, या subpage scraping से जॉब डिटेल पेज से निकाली गई सैलरी। |
| 🗓️ Posted Date | पोस्ट की तारीख या रिलेटिव टाइम (जैसे “3 days ago”), यदि उपलब्ध हो। |
| 🏷️ Tags / Keywords | टेक स्टैक, डिपार्टमेंट, सीनियरिटी, या अन्य टैग्स जो लिस्टिंग में दिखते हैं। |
| 🔗 Job URL | जॉब डिटेल पेज का डायरेक्ट लिंक (subpage scraping के लिए उपयोगी)। |
| 🖼️ Company Logo | लोगो इमेज का URL (Airtable/Notion में एनरिचमेंट के लिए मददगार)। |
Tip: लिस्टिंग टेबल स्क्रैप करने के बाद, Thunderbit में Scrape Subpages पर क्लिक करें ताकि हर Job URL पर जाकर responsibilities, requirements, benefits, और पूरी compensation जानकारी जैसी डिटेल्स अपने डेटासेट में अपने-आप जुड़ जाएँ।
Welcome to the Jungle से कंपनी प्रोफाइल्स स्क्रैप करें
से एम्प्लॉयर डेटा स्क्रैप करके आप लीड लिस्ट बना सकते हैं, एम्प्लॉयर ब्रांडिंग का विश्लेषण कर सकते हैं, या यह ट्रैक कर सकते हैं कि कौन-सी कंपनियाँ सक्रिय रूप से हायर कर रही हैं।
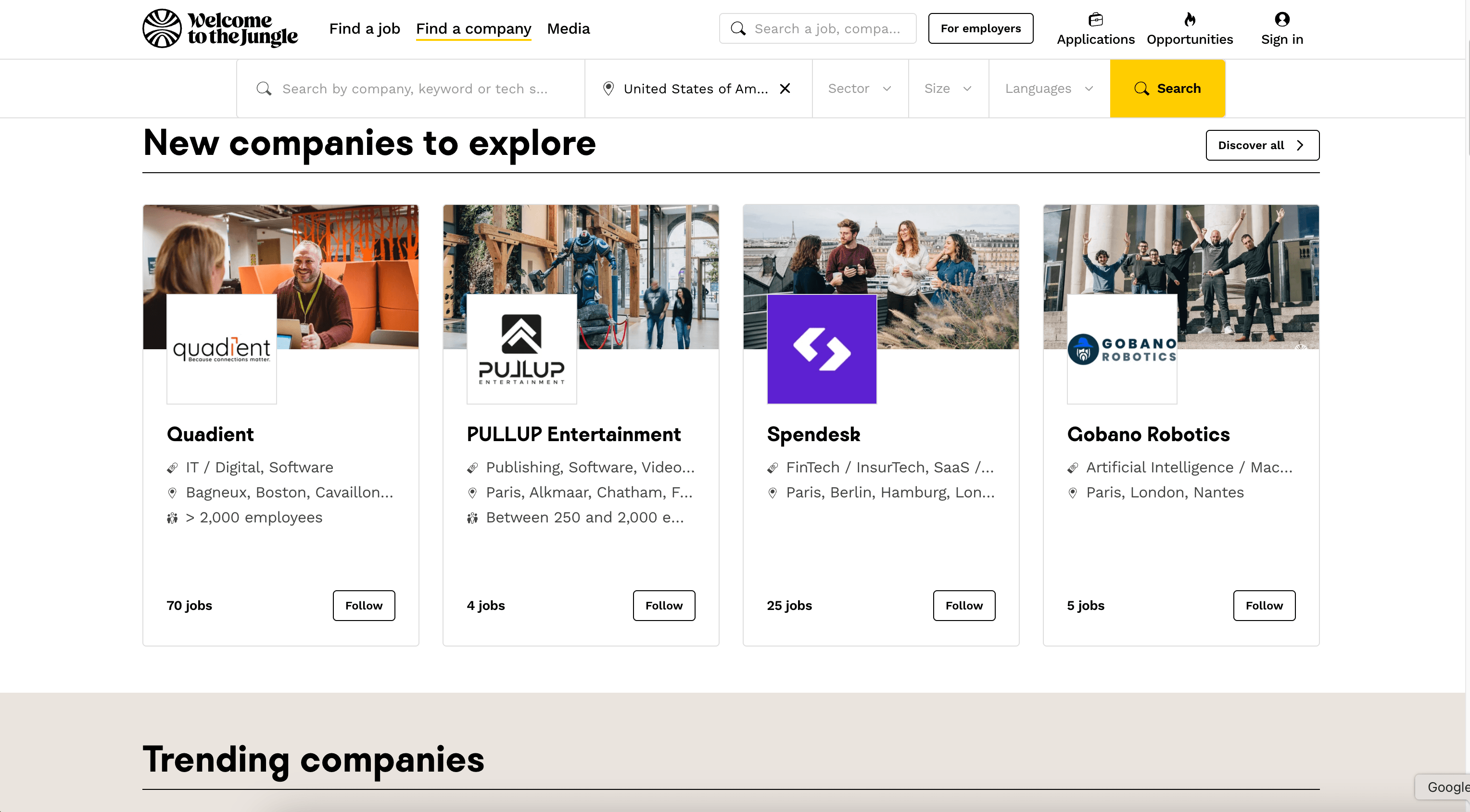
Steps:
- डाउनलोड करें और अकाउंट रजिस्टर करें।
- जिस पेज से डेटा चाहिए, वहाँ जाएँ—उदाहरण: ।
- सुझाए गए कॉलम नाम और डेटा टाइप जनरेट करने के लिए AI Suggest Fields पर क्लिक करें।
- स्क्रैपर चलाने के लिए Scrape पर क्लिक करें, फिर Excel, Google Sheets, Airtable, या Notion में एक्सपोर्ट करें।
Column names
| Column | Description |
|---|---|
| 🏢 Company Name | डायरेक्टरी में दिखने वाला कंपनी का नाम। |
| 🔗 Company URL | कंपनी प्रोफाइल पेज का लिंक (subpage scraping के लिए आदर्श)। |
| 🏷️ Industry | कैटेगरी/इंडस्ट्री लेबल (जैसे SaaS, FinTech, Marketplace), यदि उपलब्ध हो। |
| 📍 Headquarters / Location | कंपनी कार्ड या प्रोफाइल में दिखने वाला मुख्य लोकेशन। |
| 👥 Company Size | कर्मचारियों की संख्या की रेंज (यदि उपलब्ध हो)। |
| 🧾 Company Description | डायरेक्टरी का छोटा सारांश, या subpage scraping से पूरा “About” सेक्शन। |
| 💼 Open Roles Count | ओपन जॉब्स की संख्या (यदि दिखाई जाती हो)। |
| 🌐 Website | कंपनी की आधिकारिक वेबसाइट का लिंक (अक्सर प्रोफाइल पेज पर मिलता है)। |
| 🧑🤝🧑 Social Links | LinkedIn/Twitter/GitHub लिंक, यदि प्रोफाइल पर उपलब्ध हों। |
| 🖼️ Company Logo | CRM या डेटाबेस एनरिचमेंट के लिए लोगो इमेज URL। |
Tip: Subpage Scraping से mission, benefits, tech stack, funding info (यदि मौजूद हो), और open roles के लिंक जैसे गहरे फील्ड्स भी निकाले जा सकते हैं।
🎯 Welcome to the Jungle Tool क्यों इस्तेमाल करें
Welcome to the Jungle को स्क्रैप करने से आप एक बड़े और लगातार बदलते जॉब मार्केटप्लेस को ऐसे डेटासेट में बदल सकते हैं जिसे आप आसानी से फ़िल्टर, विश्लेषण और अपने काम में लागू कर सकें।
इसे इस्तेमाल करने के आम तरीके:
- Recruiting & talent teams: रोल, लोकेशन, सीनियरिटी और कंपनी टाइप के आधार पर टार्गेटेड पाइपलाइन बनाएं। समय के साथ नई पोस्टिंग्स ट्रैक करें और एक संरचित जॉब फीड बनाए रखें।
- Sales & partnerships: तेज़ी से बढ़ती कंपनियों और हायरिंग सिग्नल्स की पहचान करें, फिर company URLs, websites और social links जोड़कर अपनी लीड लिस्ट को एनरिच करें।
- Market research & analysts: क्षेत्र, इंडस्ट्री और कीवर्ड के हिसाब से हायरिंग ट्रेंड्स मॉनिटर करें। रिपोर्टिंग के लिए साप्ताहिक स्नैपशॉट बनाएं।
- Job seekers & career coaches: Google Sheets या Notion में अवसरों को पर्सनल ट्रैकर में व्यवस्थित करें, फिर सैलरी, रिमोट स्टेटस या कंपनी साइज के आधार पर प्राथमिकता तय करें।
- Ecommerce/ops teams hiring: प्रतिस्पर्धियों के हायरिंग पैटर्न ट्रैक करके रणनीतिक संकेत समझें (नए मार्केट, नए प्रोडक्ट लाइन, विस्तार)।
Thunderbit बिज़नेस वर्कफ़्लोज़ के लिए बनाया गया है: आप मिनटों में स्क्रैप, स्ट्रक्चर और एक्सपोर्ट कर सकते हैं, और pagination support व Scheduled Scraper के साथ अपने डेटासेट को नियमित रूप से अपडेट भी रख सकते हैं।
🧩 Welcome to the Jungle Chrome Extension कैसे इस्तेमाल करें
- Thunderbit Chrome Extension इंस्टॉल करें: इसे से लें और पर अपना अकाउंट बनाएं।
- Welcome to the Jungle का पेज खोलें: आप जो डेटा लेना चाहते हैं उसके अनुसार या खोलें।
- AI-पावर्ड स्क्रैपर चालू करें: कॉलम जनरेट करने के लिए AI Suggest Fields पर क्लिक करें, जरूरत हो तो फील्ड नाम/डेटा टाइप एडजस्ट करें, फिर Scrape पर क्लिक करें।
Optional: हर जॉब/कंपनी पेज पर जाकर गहरी जानकारी जोड़ने के लिए Scrape Subpages का उपयोग करें।
अगर आप AI scraping में नए हैं, तो ये गाइड्स मदद कर सकते हैं:
💳 Welcome to the Jungle Scraper की Pricing
Thunderbit की AI-powered scraping Free tier से शुरू होती है, और जितनी rows आपको चाहिए उसके हिसाब से आप स्केल कर सकते हैं।
Pricing ऐसे काम करती है:
- AI Suggest Fields के मुख्य अनुभव का हिस्सा है।
- Thunderbit क्रेडिट सिस्टम इस्तेमाल करता है: 1 credit = रिज़ल्ट टेबल में 1 output row।
- Free tier: प्रति माह 6 pages स्क्रैप (Free में page-based allowance)।
- Free trial: 10 pages मुफ्त स्क्रैप—अपग्रेड से पहले जॉब लिस्टिंग्स + subpage enrichment टेस्ट करने का अच्छा तरीका।
Paid plans (monthly बनाम yearly) अलग-अलग वॉल्यूम के लिए बने हैं। अगर आप नियमित रूप से स्क्रैप करते हैं (साप्ताहिक जॉब मॉनिटरिंग, बार-बार लीड बिल्डिंग), तो yearly plan आमतौर पर ज्यादा किफायती होता है क्योंकि इसमें डिस्काउंट शामिल रहता है।
लेटेस्ट विकल्प देखने के लिए देखें।
❓ FAQ
-
AI Powered Welcome to the Jungle Scraper क्या है?
AI Powered Welcome to the Jungle Scraper, के अंदर एक वर्कफ़्लो है जो Welcome to the Jungle के जॉब लिस्टिंग्स और कंपनी डायरेक्टरी जैसे पेजों से संरचित डेटा निकालता है। यह AI की मदद से पेज पर मौजूद फील्ड्स पहचानता है, टेबल बनाता है, और rows कलेक्ट करता है जिन्हें आप Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट कर सकते हैं। -
Thunderbit क्या है?
Thunderbit एक AI Web Scraper Chrome Extension है जो वेबसाइट्स, PDFs और इमेजेज से डेटा निकालकर उसे संरचित डेटासेट में बदलने में मदद करता है। यह उन बिज़नेस यूज़र्स के लिए बनाया गया है जिन्हें तेज़ सेटअप, भरोसेमंद एक्सट्रैक्शन और रोज़मर्रा के वर्कफ़्लो के अनुरूप एक्सपोर्ट चाहिए। -
क्या आप लिस्टिंग पेज और डिटेल पेज (subpages) दोनों स्क्रैप कर सकते हैं?
हाँ। आप पहले लिस्टिंग पेज (jobs या companies) स्क्रैप कर सकते हैं, फिर Subpage Scraping से हर जॉब या कंपनी प्रोफाइल URL पर जाकर और कॉलम जोड़ सकते हैं। यह तब खास तौर पर उपयोगी है जब सैलरी, benefits या कंपनी वेबसाइट जैसी अहम जानकारी सिर्फ डिटेल पेज पर होती है। -
Welcome to the Jungle से Google Sheets या Excel में कौन-सा डेटा एक्सपोर्ट कर सकता/सकती हूँ?
आप अपने तय किए हुए किसी भी कॉलम को एक्सपोर्ट कर सकते हैं—जैसे job title, company, location, tags, job URL आदि। Thunderbit Excel/CSV/JSON में एक्सपोर्ट सपोर्ट करता है, साथ ही Google Sheets, Airtable और Notion में डायरेक्ट एक्सपोर्ट भी देता है—जो ट्रैकर्स और इंटरनल डेटाबेस बनाने में मददगार है। -
Thunderbit जॉब लिस्टिंग्स में pagination और infinite scroll को कैसे संभालता है?
Thunderbit pagination scraping सपोर्ट करता है—जिसमें next पर क्लिक करके pagination और infinite scroll दोनों पैटर्न शामिल हैं। अगर jobs पेज स्क्रॉल करने पर और रिज़ल्ट लोड करता है, तो आप rows कलेक्ट करते रह सकते हैं और अपने टार्गेट वॉल्यूम तक स्क्रैप कर सकते हैं। -
Welcome to the Jungle पर Thunderbit इस्तेमाल करने के लिए क्या कोडिंग स्किल्स चाहिए?
नहीं। मुख्य प्रक्रिया है: पेज खोलें, AI Suggest Fields पर क्लिक करें, फिर Scrape पर क्लिक करें। अगर आपको ज्यादा कंट्रोल चाहिए, तो आप कॉलम रीनेम कर सकते हैं, डेटा टाइप (text, URL, date) बदल सकते हैं, और फील्ड इंस्ट्रक्शंस जोड़ सकते हैं—फिर भी यह no-code ही रहता है। -
अगर Welcome to the Jungle अपना लेआउट बदल दे तो क्या स्क्रैपर काम करेगा?
AI-based extraction आम तौर पर brittle selectors की तुलना में ज्यादा resilient होता है, क्योंकि यह हर रन में पेज की संरचना पढ़ता है। अगर साइट बदलती है, तो आप AI Suggest Fields दोबारा चलाकर नए लेआउट के अनुसार कॉलम फिर से जनरेट कर सकते हैं—स्क्रैपर को शुरू से बनाने की जरूरत नहीं पड़ती। -
Welcome to the Jungle के लिए cloud scraping बेहतर है या browser scraping?
अगर पेज पब्लिक हैं और लॉगिन की जरूरत नहीं है, तो Cloud Scraping आमतौर पर तेज़ होती है। अगर आपको आपके सेशन से जुड़ा कंटेंट चाहिए (जैसे personalized results या logged-in views), तो Browser Scraping बेहतर हो सकती है क्योंकि यह आपके Chrome context में चलती है। -
मैं जॉब डेटासेट को अपने-आप अपडेट कैसे रख सकता/सकती हूँ?
Thunderbit के Scheduled Scraper का उपयोग करें—यह वही job या company URLs आपके बताए शेड्यूल पर चलाता है, और आप इसे साधारण अंग्रेज़ी में बता सकते हैं। यह साप्ताहिक हायरिंग रिपोर्ट्स, खास रोल्स की मॉनिटरिंग, या समय के साथ नए मार्केट में आने वाली कंपनियों को ट्रैक करने के लिए उपयोगी है।
📚 Learn More
- से शुरुआत करें और इंस्टॉल करें
- Read:
- Read:
- Read:
- पर और ट्यूटोरियल्स देखें और पर वीडियो देखें