

האינטרנט מוצף בנתונים, והביקוש לשליפה שלהם רק הולך וגדל — אבל אם תחפשו מספר אחד שמייצג את גודל השוק, תגלו שההערכות קופצות בין סדרי גודל שונים, תלוי אם האנליסט כולל תוכנה, שירותים, פרוקסי או את שלושתם יחד. האמת היא שגריפת אתרים כבר הפכה לרכיב שקט אבל הכרחי בערמת הנתונים.
בין אם אתם אנליסטים עסקיים, אנשי שיווק או סתם מתחילים סקרנים, היכולת לשלוף נתונים מאתר הופכת מהר מאוד לכישור בסיסי. ואם אתם כמוני, כנראה הייתם מעדיפים לוותר על אינסוף העתק-הדבק ולהגיע ישר לחלק המעניין: תובנות שימושיות, גיליונות מסודרים, ואולי אפילו קצת קסם של אוטומציה.
כאן נכנס Python. הוא כמו אולר שווייצרי של עולם הנתונים — פשוט מספיק למתחילים, אבל חזק מספיק כדי להתמודד עם הכול, מהגריפת דף בודד ועד סריקה של אלפי עמודים. במדריך המעשי הזה אעבור איתכם על היסודות של גריפת אתרים עם Python, אראה איך להתמודד עם אתרים דינמיים, ואפילו אציג את Thunderbit, גריפת האתרים שלנו מבוססת ה-AI וללא קוד, שהופכת חילוץ נתונים לפשוט כמו הזמנת טייק-אוויי. אם באתם ללמוד קוד או רק מחפשים קיצור דרך, הגעתם למקום הנכון.
מהי גריפת אתרים ולמה להשתמש ב-Python כדי לשלוף נתונים מאתר?
לחלץ נתונים מכל אתר בעזרת AI Get Started Free
גריפת אתרים היא תהליך אוטומטי של חילוץ מידע מאתרים והמרתו לפורמט מובנה — למשל גיליונות, קובצי CSV או מסדי נתונים — לצורכי ניתוח או שימוש עסקי (PromptCloud). במקום להעתיק ולהדביק נתונים ידנית, כלי גריפה מחקה את מה שבני אדם היו עושים, אבל הרבה יותר מהר ובקנה מידה עצום.
למה זה כל כך חשוב? כי בעולם העסקי של היום, קבלת החלטות מבוססת נתונים היא שם המשחק. ככל שהארגון גדול יותר, כך יותר החלטות צריכות להישען על מספרים אמיתיים ולא על תחושות — והרבה מהמספרים האלה מתחילים את דרכם בדף אינטרנט של מישהו אחר.
תארו לעצמכם שאתם יכולים לעקוב מדי יום אחרי מחירי מתחרים, לאגד רשימות נדל״ן או לבנות רשימת לידים מותאמת אישית — והכול בלי להזיע.
אז למה דווקא Python? הנה הסיבות שהוא השפה המועדפת לגריפת אתרים:
- קריאות ופשטות: התחביר של Python נקי וידידותי למתחילים, כך שקל לכתוב ולהבין סקריפטים לגריפה (PromptCloud).
- מערכת אקולוגית עשירה: ספריות כמו
requests,BeautifulSoup,Scrapyו-Seleniumהופכות גריפה, ניתוח ואוטומציה של פעולות בדפדפן לקלי קלות. - תמיכה קהילתית: Python מדורג בעקביות כ-שפת התכנות הפופולרית בעולם, ולכן יש אינספור מדריכים, פורומים ודוגמאות קוד שיעזרו לכם.
- יכולת הרחבה: Python יכול להתמודד עם הכול — מסקריפטים פשוטים חד-פעמיים ועד סורקים בקנה מידה גדול.
בקיצור: Python הוא כרטיס הכניסה שלכם לעולם נתוני האינטרנט, בין אם אתם מתחילים לגמרי ובין אם אתם אנליסטים מנוסים.
מתחילים: היסודות של מדריך גריפת אתרים עם Python
לפני שנצלול לקוד, נפרק את תהליך העבודה הבסיסי לשליפת נתונים מאתר בעזרת Python:
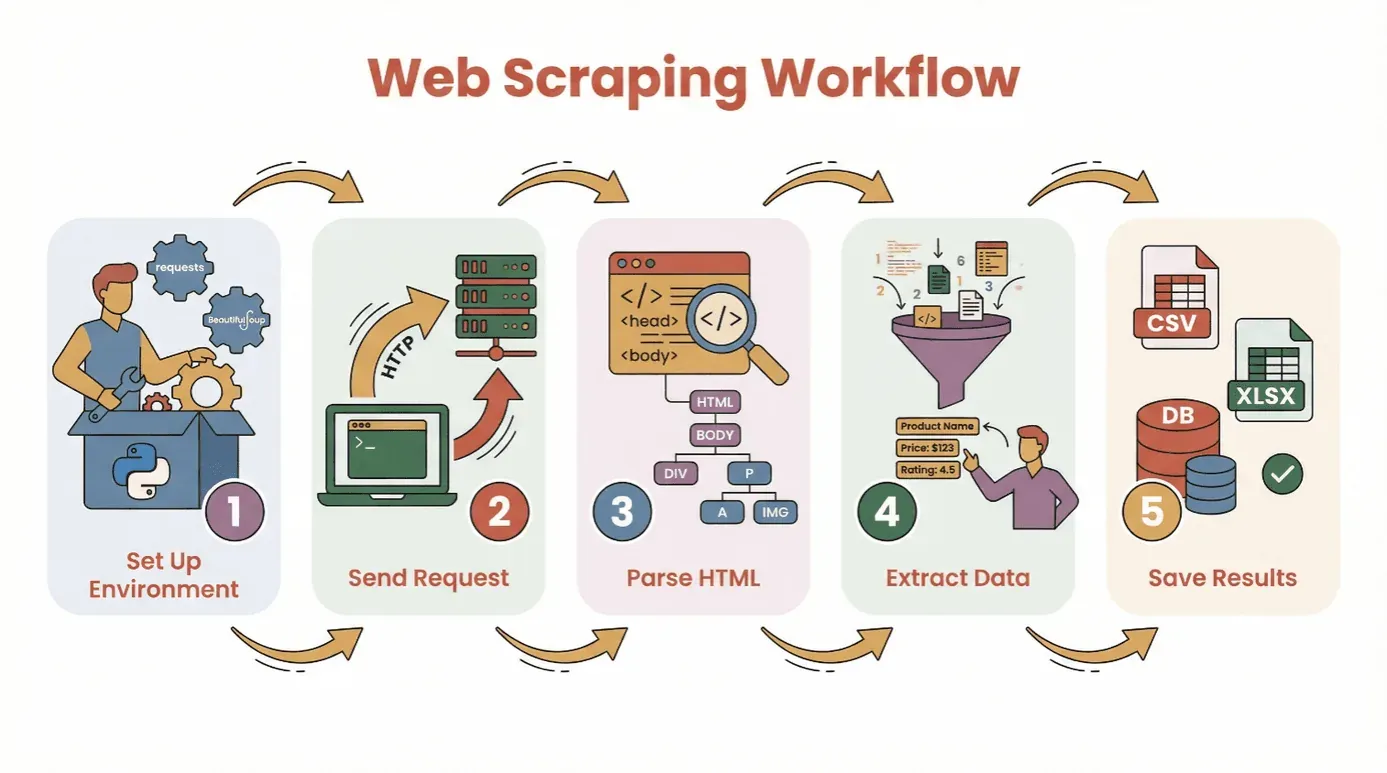
- הגדירו את הסביבה שלכם: התקינו את Python ואת הספריות הנחוצות (
requests,BeautifulSoupוכו'). - שלחו בקשה: השתמשו ב-Python כדי למשוך את תוכן ה-HTML של דף היעד.
- נתחו את ה-HTML: השתמשו במנתח כדי לנווט במבנה הדף.
- חלצו את הנתונים: אתרו ושלפו את המידע שאתם צריכים.
- שמרו את התוצאות: אחסנו את הנתונים בקובץ CSV, בקובץ Excel או במסד נתונים לצורך ניתוח.
לא צריך להיות קוסם קוד כדי להתחיל. אם אתם יודעים להתקין Python ולהריץ סקריפט, אתם כבר חצי דרך שם. למתחילים גמורים, אני ממליץ להשתמש ב-סביבת עבודה וירטואלית או ב-Jupyter Notebook, אבל אפשר גם להשתמש בכל עורך טקסט בסיסי.
ספריות חיוניות:
requests— לשליפת דפי אינטרנטBeautifulSoup— לניתוח HTMLpandas— לשמירה ולניקוי נתונים (אופציונלי, אבל מומלץ מאוד)
איך לבחור את ספריית גריפת האתרים הנכונה ב-Python: BeautifulSoup, Scrapy או Selenium?
לא כל כלי גריפה ב-Python נולדו שווים. הנה סקירה מהירה של שלוש האפשרויות הפופולריות ביותר:
| כלי | הכי מתאים ל | חוזקות | חסרונות |
|---|---|---|---|
| BeautifulSoup | דפים פשוטים וסטטיים; מתחילים | קל לשימוש, מעט מאוד הגדרה, תיעוד מצוין | פחות מתאים לסריקות גדולות או לתוכן דינמי |
| Scrapy | סריקה רחבת היקף, רב-עמודית | מהיר, אסינכרוני, צינורות מובנים, מטפל בסריקה ובאחסון נתונים | עקומת למידה תלולה יותר, מוגזם למשימות קטנות, לא מריץ JavaScript |
| Selenium | אתרים דינמיים/עמוסי JavaScript, אוטומציה | יכול לרנדר JS, לדמות פעולות משתמש, תומך בכניסות ולחיצות | איטי יותר, צורך יותר משאבים, הגדרה מורכבת יותר |
BeautifulSoup: הבחירה המובילה לניתוח HTML פשוט
BeautifulSoup מושלם למתחילים ולפרויקטים קטנים. הוא מאפשר לנתח HTML ולחלץ רכיבים בכמה שורות קוד בלבד. אם האתר שלכם ברובו סטטי (בלי טעינת JavaScript מתוחכמת), BeautifulSoup יחד עם requests הם כל מה שאתם צריכים.
דוגמה:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
מתי להשתמש: שליפות חד-פעמיות, בלוגים פשוטים, דפי מוצרים או ספריות.
Scrapy: לסריקה רחבת היקף או מובנית
Scrapy הוא מסגרת מלאה לסריקת אתרים שלמים או לטיפול באלפי עמודים. הוא אסינכרוני (כלומר: מהיר), תומך בצינורות לניקוי/שמירת נתונים, ויכול לעקוב אחרי קישורים אוטומטית.
דוגמה:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
מתי להשתמש: פרויקטים גדולים, סריקות מתוזמנות, או כשצריך מהירות ומבנה.
Selenium: טיפול באתרים דינמיים ועמוסי JavaScript
Selenium שולט בדפדפן אמיתי (כמו Chrome או Firefox), ולכן הוא יכול להתמודד עם אתרים שטוענים נתונים באמצעות JavaScript, דורשים התחברות או מצריכים לחיצה על כפתורים.
דוגמה:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
מתי להשתמש: רשתות חברתיות, אתרי מניות, גלילה אינסופית, או כל דבר שנראה ריק כשעושים “view source”.
שלב אחר שלב: איך לשלוף נתונים מאתר באמצעות Python (מדריך למתחילים)
נלך על דוגמה אמיתית באמצעות requests ו-BeautifulSoup. נגרוף אתר פשוט של רשימות ספרים כדי לחלץ כותרות, מחברים ומחירים.
שלב 1: הגדרת סביבת Python שלכם
קודם כול, התקינו את הספריות שתצטרכו:
pip install requests beautifulsoup4 pandas
ואז ייבאו אותן בסקריפט:
import requests
from bs4 import BeautifulSoup
import pandas as pd
שלב 2: שליחת בקשה לאתר
משכו את תוכן ה-HTML:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"נכשל האחזור של הדף: {response.status_code}")
שלב 3: ניתוח תוכן ה-HTML
צרו אובייקט BeautifulSoup:
soup = BeautifulSoup(html, 'html.parser')
מצאו את כל מכולות הספרים:
books = soup.find_all('article', class_='product_pod')
print(f"נמצאו {len(books)} ספרים בדף הזה.")
שלב 4: חילוץ הנתונים שאתם צריכים
עברו בלולאה על כל ספר ושלפו את הפרטים:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Title": title, "Price": price})
שלב 5: שמירת הנתונים לניתוח
המרו ל-DataFrame ושמרו:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
עכשיו יש לכם קובץ CSV נקי ומוכן לניתוח!
טיפים לפתרון בעיות:
- אם אתם מקבלים תוצאות ריקות, בדקו אם הנתונים נטענים באמצעות JavaScript (ראו את הסעיף הבא).
- תמיד בדקו את מבנה ה-HTML בעזרת כלי המפתחים של הדפדפן.
- טפלו בנתונים חסרים באמצעות
get_text(strip=True)ובדיקות תנאי.
התמודדות עם תוכן דינמי: שליפת נתונים מאתרים שמרונדרים ב-JavaScript
אתרים מודרניים אוהבים JavaScript. לפעמים הנתונים שאתם צריכים לא נמצאים ב-HTML הראשוני — הם נטענים אחרי שהדף מופיע. אם הגריפה שלכם מחזירה כלום, יכול להיות שאתם מתמודדים עם תוכן דינמי.
איך מטפלים בזה:
- Selenium: מדמה דפדפן אמיתי, מחכה לטעינת התוכן ויכול ללחוץ על כפתורים או לגלול.
- Playwright/Puppeteer: מתקדמים יותר, אבל עם רעיון דומה (דפדפנים ללא ממשק).
מדריך קצר ל-Selenium:
- התקינו את Selenium ואת מנהל ההתקן של הדפדפן (למשל ChromeDriver).
- השתמשו ב-explicit waits כדי לתת לתוכן להיטען.
- חלצו את ה-HTML המרונדר ונתחו אותו עם BeautifulSoup אם צריך.
דוגמה:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# חילוץ הנתונים כמו קודם
driver.quit()
מתי צריך Selenium?
- אם
requests.get()מחזיר HTML בלי נתונים, אבל אתם כן רואים אותם בדפדפן. - אם האתר משתמש בגלילה אינסופית, חלונות קופצים, או מחייב התחברות.
פישוט גריפת אתרים בעזרת AI: שימוש ב-Thunderbit כדי לשלוף נתונים מאתר
לנסות את Thunderbit AI Web Scraper Get Started Free
בואו נהיה כנים — לפעמים אתם פשוט רוצים את הנתונים, לא את הקוד. כאן נכנס Thunderbit. Thunderbit הוא תוסף Chrome מבוסס AI שמאפשר לכם לשלוף נתונים מכל אתר בכמה לחיצות בלבד — בלי צורך ב-Python.
איך Thunderbit עובד:
- התקינו את תוסף Chrome של Thunderbit.
- פתחו את האתר הרצוי.
- לחצו על אייקון Thunderbit והקישו “AI Suggest Fields”. ה-AI של Thunderbit סורק את הדף וממליץ אילו נתונים לחלץ (למשל שמות מוצרים, מחירים, אימיילים).
- כווננו את השדות אם צריך, ואז לחצו “Scrape”.
- ייצאו את הנתונים ישירות ל-Excel, Google Sheets, Notion או Airtable.
למה Thunderbit מעולה:
- אין צורך בקוד. אפילו אמא שלי יכולה להשתמש בו (והיא עדיין מתקשרת אליי בשביל בעיות Wi‑Fi).
- מטפל בתתי-עמודים ובעימוד. צריכים לגרוף פרטי מוצר ממספר עמודים? Thunderbit יכול ללחוץ דרך העמודים ולמזג עבורכם את הנתונים.
- הוראות בשפה טבעית. פשוט תגידו לו מה אתם רוצים (“לחלץ את כל כותרות המוצרים והמחירים”) וה-AI כבר יבין.
- תבניות מיידיות לאתרים פופולריים. Amazon, Zillow, LinkedIn ועוד — לחיצה אחת וזהו.
- ייצוא נתונים חינם. הורידו כ-CSV, Excel או שלחו ישירות לכלים המועדפים עליכם.
Thunderbit זוכה לאמון של יותר מ-100,000 משתמשים ברחבי העולם. יש רמה חינמית שאפשר לנסות בלי לשלם — ראו את דף התמחור כדי לבדוק את מגבלת השימוש הנוכחית, כי המגבלות השתנו כמה פעמים. למשתמשים עסקיים זה חוסך זמן; ולמי שעובד עם Python, זו דרך שימושית להעריך עבודה לפני שמחליטים אם שווה לכתוב גריפר משלכם.
לנסות את Thunderbit בחינם – בלי צורך בקוד
אחרי הגריפה: ניקוי וניתוח נתונים עם Pandas ו-NumPy
שליפת נתונים היא רק הצעד הראשון. נתוני אינטרנט גולמיים הם לעיתים קרובות מבולגנים — כפילויות, ערכים חסרים, פורמטים מוזרים. כאן הספריות pandas ו-NumPy של Python מצטיינות.
משימות ניקוי נפוצות:
- הסרת כפילויות:
df.drop_duplicates(inplace=True) - טיפול בערכים חסרים:
df.fillna('Unknown')אוdf.dropna() - המרת טיפוסי נתונים:
df['Price'] = df['Price'].str.replace('$','').astype(float) - פירוק תאריכים:
df['Date'] = pd.to_datetime(df['Date']) - סינון חריגות:
df = df[df['Price'] > 0]
ניתוח בסיסי:
- סטטיסטיקות סיכום:
df.describe() - קיבוץ לפי קטגוריה:
df.groupby('Category')['Price'].mean() - גרפים מהירים:
df['Price'].hist()אוdf.groupby('Category')['Price'].mean().plot(kind='bar')
למתמטיקה מתקדמת יותר או לפעולות מהירות על מערכים, NumPy הוא חבר טוב. אבל עבור רוב המשתמשים העסקיים, pandas מכסה 95% ממה שתצטרכו.
משאבים: אם אתם חדשים ב-pandas, בדקו את המדריך 10 Minutes to pandas.
שיטות עבודה מומלצות וטיפים להצלחה בגריפת אתרים עם Python
גריפת אתרים היא כלי חזק, אבל היא גם מגיעה עם אחריות. הנה רשימת הבדיקה שלי לגריפה כמו מקצוענים (ולא להיחסם או להיתבע):
- כבדו את robots.txt ואת תנאי השימוש. תמיד בדקו אם האתר מאפשר גריפה (PromptCloud).
- אל תעמיסו על השרתים. הוסיפו השהיות בין בקשות (
time.sleep(2)) וגרפו בקצב אנושי. - השתמשו בכותרות מציאותיות. הגדירו מחרוזת User-Agent שתדמה דפדפן.
- טפלו בשגיאות באלגנטיות. השתמשו בבלוקים של try/except ובנסיונות חוזרים לבקשות שנכשלו.
- סובבו פרוקסי אם צריך. לגריפה בהיקף גדול, שקלו להשתמש במאגרי פרוקסי כדי להימנע מחסימות IP.
- היו אתיים וחוקיים. אל תגרפו נתונים אישיים או תוכן מאחורי התחברות בלי רשות.
- תעדו את התהליך. שמרו הערות על מה גרפתם, מאיפה ומתי.
- השתמשו ב-API רשמי כשיש כזה. לפעמים יש דרך טובה יותר מאשר גריפת HTML.
לעוד טיפים, בדקו את המדריך האולטימטיבי לגריפת אתרים.
סיכום ומסקנות מרכזיות
גריפת אתרים עם Python היא כוח-על לכל מי שרוצה להפוך את הכאוס של האינטרנט לנתונים מובנים ושימושיים. בין אם אתם משתמשים בקוד (עם requests, BeautifulSoup, Scrapy או Selenium) או בכלי ללא קוד כמו Thunderbit, יש לכם את הכלים לשלוף נתונים מאתר ולפתוח תובנות חדשות.
זכרו:
- התחילו פשוט — גרפו עמוד אחד לפני שאתם ניגשים לפרויקטים גדולים.
- בחרו את הכלי הנכון לצרכים שלכם (BeautifulSoup לבסיס, Scrapy להיקף גדול, Selenium לאתרים דינמיים, Thunderbit ללא קוד).
- נקו ונתחו את הנתונים שלכם עם pandas ו-NumPy.
- תמיד גרפו באחריות ובאופן אתי.
מוכנים לנסות בעצמכם? התחילו בפרויקט קטן — אולי גריפת כותרות היום או רשימת מוצרים — ותראו כמה מהר אפשר לעבור מדף אינטרנט גולמי לגיליון מסודר. ואם בא לכם לדלג על הקוד, הורידו את Thunderbit ותנו ל-AI לעשות את העבודה הקשה.
לעוד מדריכים, טיפים וחוכמת גריפת אתרים, בדקו את בלוג Thunderbit.
לקרוא עוד מדריכים לגריפת אתרים
שאלות נפוצות
1. מהי גריפת אתרים ולמה Python פופולרית לכך?
גריפת אתרים היא חילוץ אוטומטי של נתונים מאתרים. Python פופולרית לגריפת אתרים בזכות התחביר הקריא שלה, הספריות החזקות (כמו BeautifulSoup, Scrapy ו-Selenium), והתמיכה הקהילתית החזקה (PromptCloud).
2. איזו ספריית Python כדאי לי להשתמש בה לגריפת אתרים?
השתמשו ב-BeautifulSoup לדפים פשוטים וסטטיים; ב-Scrapy לסריקה רחבת היקף או רב-עמודית; וב-Selenium לאתרים דינמיים או עמוסי JavaScript. לכל אחת יש חוזקות משלה בהתאם לצרכים שלכם (IPRoyal).
3. איך מטפלים באתרים שטוענים נתונים באמצעות JavaScript?
לתוכן שמרונדר ב-JavaScript, השתמשו ב-Selenium (או ב-Playwright) כדי לדמות דפדפן ולהמתין לטעינת התוכן לפני חילוץ הנתונים. לפעמים אפשר למצוא נקודת קצה של API בסיסי על ידי בדיקת תעבורת הרשת.
4. מהו Thunderbit ואיך הוא מפשט גריפת אתרים?
Thunderbit הוא תוסף Chrome מבוסס AI שמאפשר לכם לשלוף נתונים מכל אתר בלי קוד. הוא משתמש ב-AI כדי להציע שדות, לטפל בתתי-עמודים ובעימוד, ולייצא נתונים ישירות ל-Excel, Google Sheets, Notion או Airtable.
5. איך אפשר לנקות ולנתח נתונים שנגרפו ב-Python?
השתמשו ב-pandas כדי להסיר כפילויות, לטפל בערכים חסרים, להמיר טיפוסי נתונים ולבצע ניתוח. NumPy מצוין לפעולות מספריות. להמחשה ויזואלית, pandas משתלב עם Matplotlib לגרפים מהירים (10 Minutes to pandas).
גריפה מהנה — ושכל הנתונים שלכם יהיו תמיד נקיים, מובנים ומוכנים לפעולה.
לנסות AI Web Scraper Get Started Free
למידע נוסף




