

Let me take you back to the first time I tried to scrape product data from an ecommerce site. I was armed with Python, a cup of coffee, and a dream: to build a price tracker for Amazon. Fast forward a few hours, and my “quick project” had turned into a tangle of XPath selectors, pagination headaches, and more debugging than I care to admit. If you’ve ever tried to wrangle web data with code, you probably know the feeling—equal parts excitement and “why is this so complicated?”
Here’s the thing: web scraping is no longer just for data scientists or engineers. It’s become a must-have skill for sales teams, ecommerce managers, marketers, and anyone who wants to turn the web’s chaos into business intelligence. In fact, the web scraping software market hit $1.01 billion in 2024 and is projected to reach $2.49 billion by 2032, and the curve isn't flattening. But while Python and frameworks like Scrapy are still the gold standard for large-scale, custom scraping, they’re not exactly beginner-friendly. That’s why, in this tutorial, I’ll walk you through Scrapy step by step—using a real-world Amazon use case—and show you a much easier, AI-powered alternative for non-coders: Thunderbit.
What is Scrapy Python? Your Web Scraping Power Tool
Let’s start with the basics. Scrapy is an open-source Python framework built specifically for web crawling and scraping. Think of it as your all-in-one toolkit for building custom spiders (that’s what Scrapy calls its crawlers) that can navigate websites, follow links, handle pagination, and extract structured data at scale.
How does Scrapy differ from just using Python’s requests and BeautifulSoup? Well, while those libraries are great for simple, one-off scrapes, Scrapy is designed for large, complex projects—the kind where you need to:
- Crawl thousands of pages (think: every product in an ecommerce catalog)
- Automatically follow links and handle pagination
- Process data asynchronously for speed
- Structure, clean, and export data in a repeatable way
In short, Scrapy is like the Swiss Army knife for web scraping—powerful, flexible, and (for better or worse) a little intimidating for beginners.
Why Use Scrapy Python for Web Scraping?
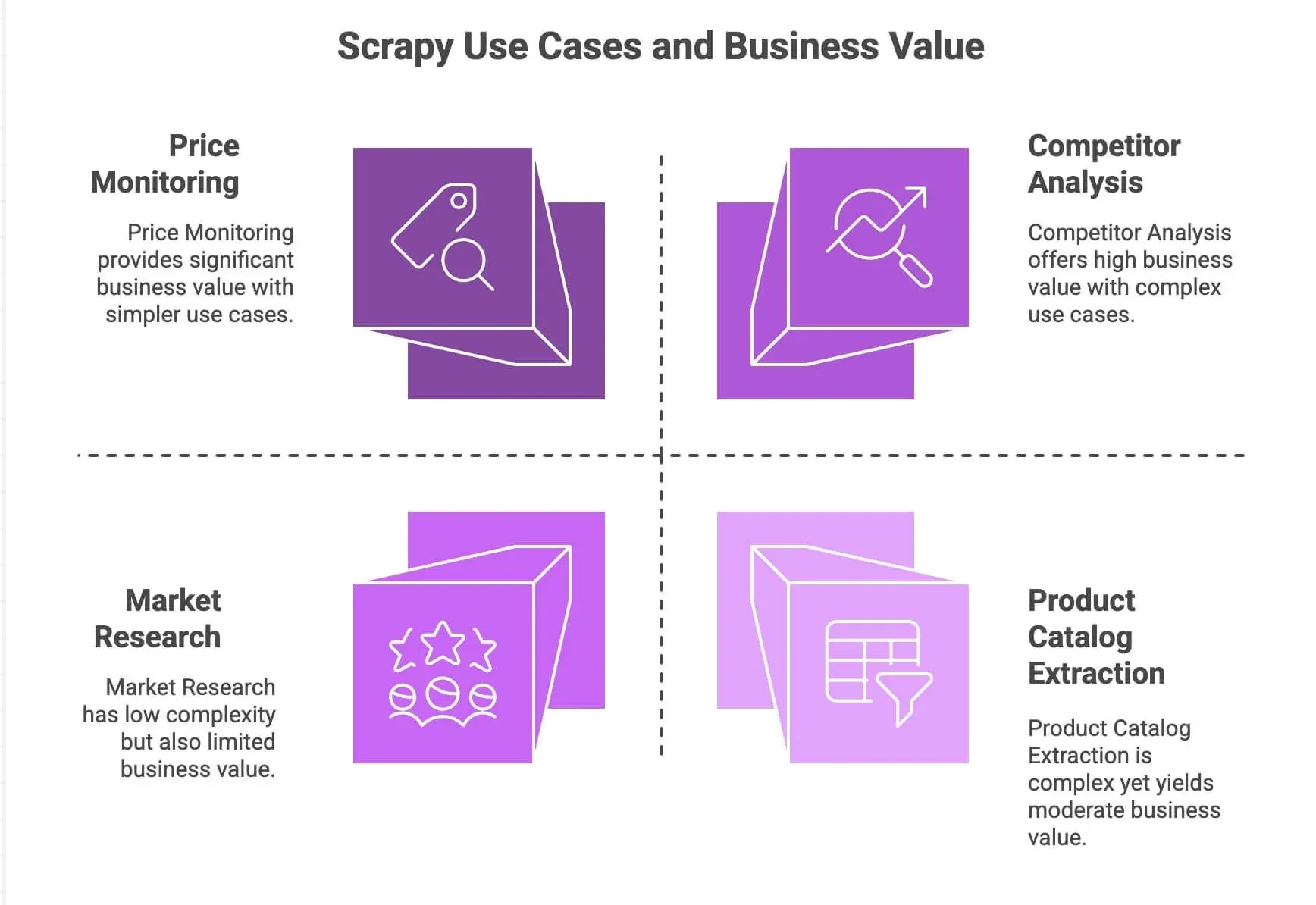
So, why do developers and data teams keep reaching for Scrapy? Here’s a quick rundown of what makes it stand out:
| Use Case | Scrapy Strengths | Business Value |
|---|---|---|
| Price Monitoring | Handles pagination, async requests, scheduling | Stay ahead of competitors, dynamic pricing |
| Product Catalog Extraction | Follows links, extracts structured data | Build product databases, feed analytics |
| Competitor Analysis | Scalable, robust against site changes | Track trends, new launches, stock levels |
| Market Research | Modular pipelines for cleaning/transforming data | Aggregate reviews, run sentiment analysis |
Scrapy’s asynchronous engine (built on Twisted) means it can fetch multiple pages in parallel, making it fast and scalable. Its modular design lets you plug in custom logic (like proxies, user-agents, or data cleaning steps). And with pipelines, you can process, validate, and export data however you like—CSV, JSON, databases, you name it.
For teams with Python skills, Scrapy is a powerhouse. But let’s be honest: it’s not exactly “plug and play” for the average business user.
Setting Up Your Scrapy Python Environment
Ready to get your hands dirty? Here’s how to set up Scrapy from scratch:
1. Install Scrapy
First, make sure you have Python 3.10+ installed (Scrapy 2.15.x dropped support for 3.9 in 2026). Then, open your terminal and run:
pip install scrapy
Check your install with:
scrapy version
If you’re on Windows or using Anaconda, you might want to set up a virtual environment to avoid conflicts. Scrapy works on Windows, macOS, and Linux.
2. Create a New Scrapy Project
Let’s start a new project called amazonscraper:
scrapy startproject amazonscraper
You’ll get a folder structure like this:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
What do these files do?
scrapy.cfg: Project config (you rarely touch this)items.py: Define your data models (like a Product with name, price, etc.)pipelines.py: Where you clean, validate, and export your datamiddlewares.py: Advanced stuff (proxies, custom headers)settings.py: Tweak Scrapy’s behavior (concurrency, delays, etc.)spiders/: Where your actual scraping logic lives
If you’re already feeling a little overwhelmed, you’re not alone. This is where many non-coders start to sweat.
Building a Python Scraper: Scraping Amazon Product Data with Scrapy
Let’s walk through a real-world example: scraping product data from Amazon’s search results. (Heads up: Amazon’s terms of service don’t allow scraping, and they’re aggressive with anti-bot measures. This is for educational purposes only!)
1. Create a Spider
Inside the spiders/ folder, create a file called amazon_spider.py:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
What’s happening here?
- We start at an Amazon search results page for “smartphones.”
- For each product, we extract the name, price, and rating using XPath selectors.
- We look for the “next page” link and tell Scrapy to follow it, scraping more products.
2. Run Your Spider
From your project root, run:
scrapy crawl amazon_example -o products.json
Boom—Scrapy will crawl through the search results, follow pagination, and save your data to a JSON file.
Handling Pagination and Dynamic Content
Scrapy’s built-in support for following links and handling pagination is one of its superpowers. But what about dynamic content—pages that load data with JavaScript? Out of the box, Scrapy only sees static HTML. If you need to scrape content loaded by JavaScript (like infinite scroll or pop-up reviews), you’ll need to integrate with tools like Selenium or Splash. That’s a whole other rabbit hole.
Processing and Exporting Data with Scrapy Python
Once you’ve scraped your data, you’ll probably want to clean it up and export it somewhere useful.
- Pipelines: In
pipelines.py, you can write Python classes to clean, validate, or enrich your data (like converting prices to numbers, dropping incomplete rows, or even calling a translation API). - Exporting: Scrapy can export directly to CSV, JSON, or XML with the
oflag. For more advanced exports (like pushing to Google Sheets), you’ll need to write extra code or use third-party libraries.
Want to do sentiment analysis or translate product descriptions? You’ll have to integrate with external APIs or Python libraries—nothing is built-in.
The Hidden Costs: Challenges of Scrapy Python for Business Users
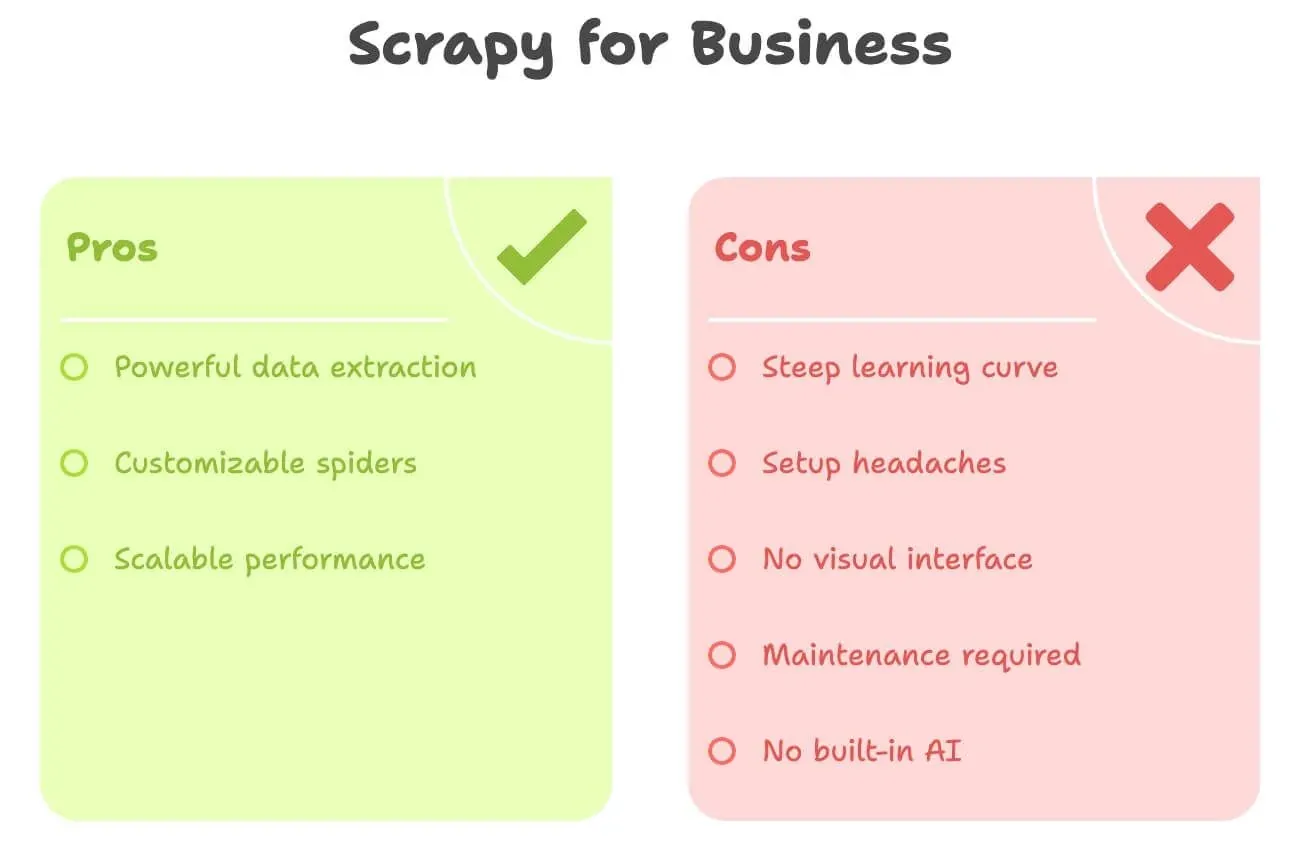
Let’s be real: Scrapy is powerful, but it’s not exactly user-friendly for non-developers. Here’s what trips up most business users:
- Steep Learning Curve: You need to know Python, HTML, XPath/CSS selectors, and Scrapy’s project structure. It can take days or even weeks to get comfortable.
- Setup Headaches: Installing Python, managing dependencies, and troubleshooting errors can be a pain—especially on Windows.
- No Visual Interface: Everything is code. You can’t just “click” on a page to select data.
- Maintenance: If the website changes, your spider breaks. You’re on the hook for fixing it.
- No Built-in AI: Want to translate, summarize, or analyze sentiment? That’s all extra code.
Here’s a quick comparison:
| Challenge | Scrapy (Python) | Business User Needs |
|---|---|---|
| Coding Required | Yes | Prefer no code |
| Setup Time | Hours (or days) | Minutes |
| Maintenance | Ongoing (site changes) | Minimal |
| Data Export | CSV/JSON (manual integration) | Direct to Excel/Sheets/Notion |
| AI Features | None (DIY integration) | Built-in translation/sentiment |
If you’re a solo marketer, sales rep, or ops manager, Scrapy can feel like bringing a bazooka to a water balloon fight.
Meet Thunderbit: The No-Code Alternative to Scrapy Python
This is where Thunderbit comes in. As someone who’s spent years building automation tools, I can tell you: most business users don’t want to code—they just want the data, fast.
Thunderbit is an AI-powered web scraper delivered as a Chrome extension. It’s designed for non-technical users who want to:
- Scrape data from any website in a few clicks
- Use natural language to describe what they want (“Product Name, Price, Rating”)
- Handle pagination and subpages automatically
- Export data directly to Excel, Google Sheets, Airtable, or Notion
- Translate, summarize, or analyze sentiment on the fly
No Python. No selectors. No maintenance headaches.
How to Scrape Any Website Using AI Get Started Free
Thunderbit is designed for business users who want to move fast and let AI handle the heavy lifting.
Thunderbit vs. Scrapy Python: Side-by-Side Comparison
Let’s put them head to head:
| Aspect | Scrapy (Python) | Thunderbit (AI Tool) |
|---|---|---|
| Skill Required | Python, HTML, selectors | None—point and click, natural language |
| Setup Time | Hours (install, code, debug) | Minutes (install Chrome extension, sign in) |
| Data Structuring | Manual (define items, pipelines) | AI auto-detects columns, suggests fields |
| Pagination/Subpages | Code required | 1-click (AI handles it) |
| Translation | Custom code or API integration | Built-in—just toggle “Translate” |
| Sentiment Analysis | External library/API | Built-in—add a “Sentiment” column |
| Export Options | CSV/JSON (manual import to Sheets/Excel) | 1-click export to Excel, Google Sheets, Airtable, Notion |
| Maintenance | Manual (update code if site changes) | AI adapts to minor site changes automatically |
| Scale | Best for large, ongoing projects | Best for quick tasks, moderate scale (hundreds/thousands of rows) |
| Cost | Free (but costs time/developer resources) | Free tier + paid plans (starts at $9/month, but saves tons of time and headaches) |
When to Choose Scrapy Python vs. Thunderbit for Web Scraping
Here’s my rule of thumb:
- Use Scrapy if:
- You’re a developer or have one on your team
- You need to scrape tens of thousands of pages, or build a custom, ongoing pipeline
- The site is highly complex or needs advanced logic
- You want full control (and don’t mind maintenance)
- Use Thunderbit if:
- You don’t code (or don’t want to)
- You need data quickly, for a one-off or recurring business task
- You want built-in translation, sentiment, or data enrichment
- You value speed and flexibility over raw customization
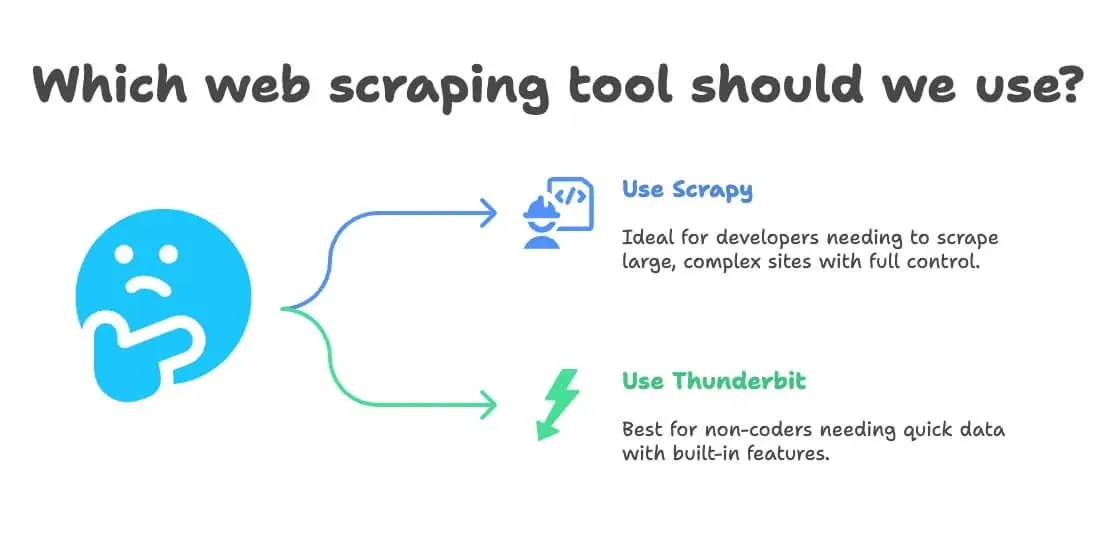
Here’s a quick decision flow:
- Can you code in Python?
- Yes → Scrapy or Thunderbit (for quick wins)
- No → Thunderbit
- Is your project huge and ongoing?
- Yes → Scrapy
- No → Thunderbit
- Do you need translation or sentiment analysis?
- Yes → Thunderbit
- No → Either
Step-by-Step: Scraping Amazon Product Data with Thunderbit (No Code Required)
Let’s redo our Amazon example—this time, the easy way.
1. Install Thunderbit
- Download the Thunderbit Chrome Extension
- Sign up (free tier available)
Try Thunderbit Chrome Extension for Free
2. Go to Amazon and Search for Your Product
- Open Amazon.com and search for “laptops” (or any product)
3. Launch Thunderbit on the Page
- Click the Thunderbit icon in your browser
- The side panel opens, recognizing the Amazon page
4. Use AI Suggest Fields
- Click “AI Suggest Fields”
- Thunderbit’s AI scans the page and suggests columns like “Product Name,” “Price,” “Rating,” “Number of Reviews”
- Add or remove columns as needed (want “Product URL” or “Prime eligibility”? Just type it in)
5. Enable Pagination and Subpage Scraping
- Toggle Pagination: Thunderbit will auto-click “Next” and scrape all pages
- Toggle Subpage Scraping: Thunderbit will visit each product’s detail page and grab extra info (like descriptions or ASIN numbers)
6. Run the Scrape
- Click Scrape
- Watch as Thunderbit collects data in real time, page by page
7. Translate and Analyze Sentiment (Optional)
- Want to translate product descriptions? Toggle “Translate” for that column
- Want to analyze sentiment on reviews? Add a “Sentiment” column—Thunderbit’s AI will fill it in
8. Export Your Data
- Click Export
- Choose Excel, Google Sheets, Airtable, or Notion
- Your data is ready to use—no manual import, no CSV wrangling
9. Schedule Recurring Scrapes (Optional)
- Set up a schedule (e.g., daily at 8am)
- Thunderbit will run the scrape automatically and update your chosen destination
That’s it. No code, no selectors, no maintenance. Just data, ready for business.
Bonus Tips: Getting More from Your Web Scraping Projects
Whether you’re using Scrapy, Thunderbit, or any other tool, here are a few best practices I’ve learned the hard way:
- Validate Your Data: Always check for missing or weird values (like $0 prices or empty names)
- Stay Compliant: Check the site’s terms of service, respect
robots.txt, and don’t overload servers - Automate Wisely: Use scheduling to keep data fresh, but don’t scrape more often than you need
- Leverage Free Tools: Thunderbit includes free email, phone, and image extractors—great for lead gen or content curation
- Organize for Analysis: Export directly to Sheets/Excel so you can filter, pivot, and visualize quickly
For more tips, check out Thunderbit’s blog or their guide to scraping any website using AI.
How to Scrape Website Data into Excel using AI Get Started Free
For more tips, check out Thunderbit’s blog or their guide to scraping any website using AI.
Conclusion: Web Scraping Made Simple—Choose the Right Tool for Your Team
Here’s the bottom line: Scrapy is a powerhouse for developers, but it’s overkill for most business users. If you’re comfortable with Python and need to build a custom, large-scale scraper, Scrapy is a great choice. But if you want to move fast, skip the code, and get data (with translation and sentiment analysis baked in), Thunderbit is the way to go.
I’ve seen firsthand how much time and frustration Thunderbit saves for non-technical teams. You can go from “I wish I had this data” to “it’s in my spreadsheet” in minutes—not hours or days. And with features like AI Suggest Fields, subpage scraping, and one-click exports, it’s never been easier to turn the web into business intelligence.
So, next time you need to scrape product data, monitor prices, or build a lead list, ask yourself: do you want to write Python, or do you want results? Give Thunderbit’s free tier a spin and see how much easier web scraping can be.
Curious to learn more? Check out Thunderbit’s official site, download the Chrome extension, or dive deeper into web scraping best practices on the Thunderbit blog.
Further Reading:
- What Is Data Scraping and How to Do It in 2026
- How to Scrape Website Data into Excel using AI
- The Best Web Scraping Tools & Software in 2026
- State of Web Scraping Report
Disclaimer: Always ensure your web scraping activities comply with website terms and local laws. When in doubt, consult legal counsel—no one wants to be the “scraper” who gets a cease-and-desist letter over a spreadsheet.
Written by Shuai Guan, Co-founder & CEO at Thunderbit. I’ve spent years in SaaS, automation, and AI—so you don’t have to.
Try AI Web Scraper Get Started Free




