
La semaine dernière, j’ai passé 40 minutes à déboguer un script Python parfaitement fonctionnel sur trois sites de test — avant de comprendre que le quatrième passait par Cloudflare. Le scraper tournait en boucle sur une page « Checking your browser… » et ne renvoyait qu’un HTML de challenge. Ça vous parle ?
Si vous avez déjà buté sur ce mur, vous n’êtes pas seul. utilisent aujourd’hui Cloudflare, soit sur Internet. Autant dire que c’est l’obstacle le plus courant pour toute personne qui veut collecter des données web — que ce soit pour la génération de leads, la veille tarifaire, l’immobilier ou l’analyse concurrentielle.
Le vrai souci, c’est que la plupart des guides listent toutes les méthodes de contournement sans expliquer laquelle essayer en premier dans votre cas précis. Ici, on fait autrement : un arbre de décision classé par priorité, des estimations de fiabilité honnêtes, et une solution sans code que la majorité des articles passent complètement sous silence.
- Difficulté : Débutant à intermédiaire (selon la méthode choisie)
- Temps nécessaire : ~10 à 30 minutes pour la solution sans code ; variable pour les méthodes basées sur du code
- Ce qu’il vous faut : Chrome (pour la solution sans code), éventuellement Python 3.9+ (pour les méthodes avec code) et une URL cible
Qu’est-ce que la protection Cloudflare (et pourquoi bloque-t-elle votre scraper) ?
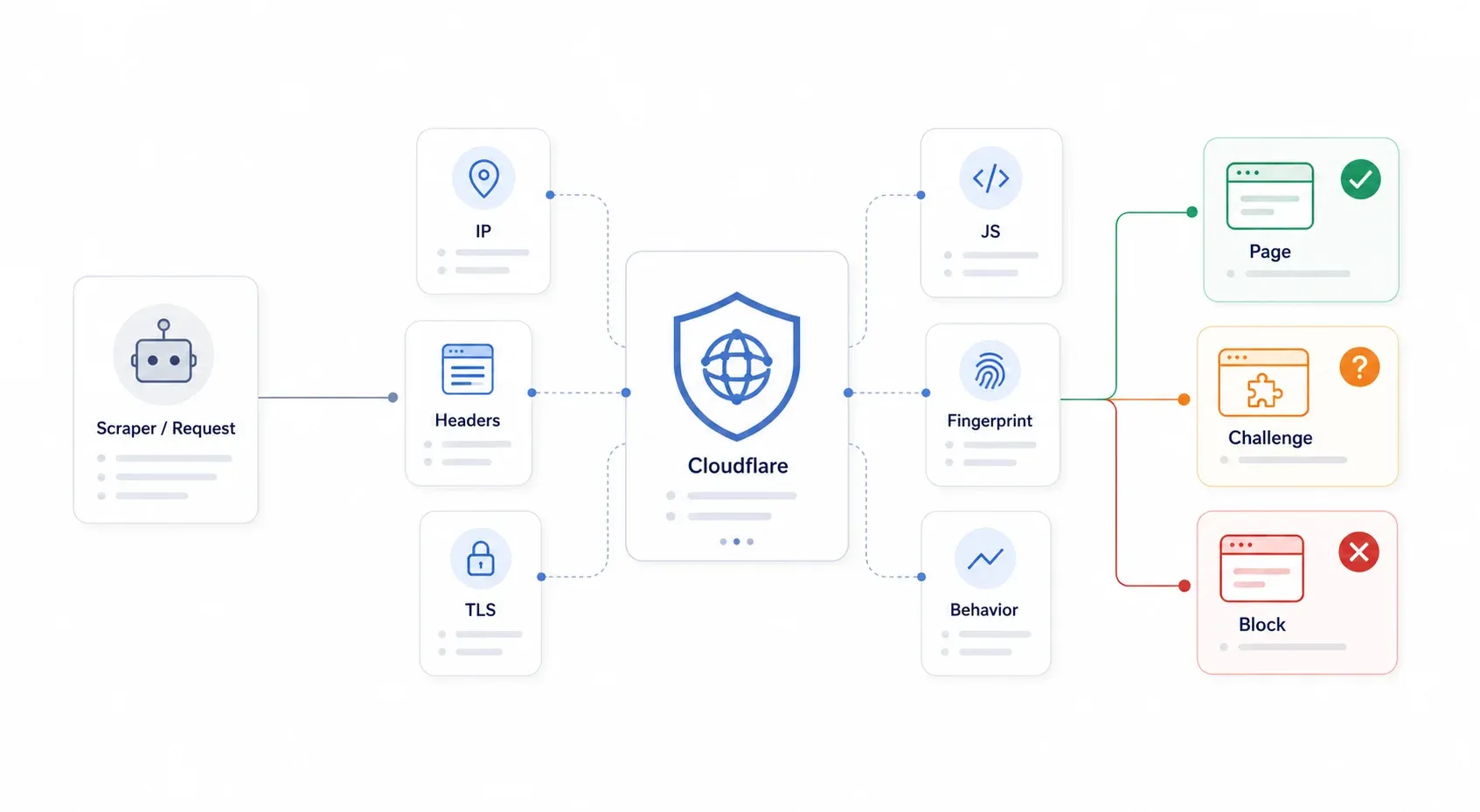
Cloudflare est un reverse proxy qui se place entre les visiteurs et le serveur d’origine du site. Chaque requête passe d’abord par Cloudflare, qui décide ensuite d’afficher la page, de lancer un challenge ou de bloquer la requête purement et simplement. L’important à retenir : Cloudflare n’a pas besoin de savoir que votre scraper est malveillant. Il lui suffit de considérer votre requête comme trop automatisée ou trop suspecte.
Le système de Cloudflare repose sur plusieurs couches — pas une seule barrière, mais un véritable poste de contrôle. Il vérifie la réputation IP, les en-têtes HTTP, les empreintes TLS, l’exécution JavaScript, l’empreinte du navigateur et les comportements observés. Quand votre bibliothèque Python requests envoie un GET vers une page protégée par Cloudflare, elle se heurte à plusieurs couches en même temps : poignée de main TLS atypique, aucune exécution JavaScript, pas de cookies, pas d’empreinte navigateur. C’est pour ça que le simple spoofing d’en-têtes ne marche plus depuis des années.
Les symptômes les plus fréquents : 403 Forbidden, 503 avec « Checking your browser… », 1020 Access Denied, boucles de challenge sans fin, widgets Turnstile qui ne se valident jamais, et pages HTML de challenge là où vous attendiez du JSON.
Détection passive : ce que Cloudflare analyse avant même le chargement de la page
Avant même que la page ne s’affiche, la couche passive de Cloudflare a déjà évalué votre requête :
- Réputation IP : les IP de datacenter, les plages cloud et les sorties de proxy connues sont signalées. Les IP résidentielles et mobiles sont . En 2026, les retours de la communauté décrivent souvent des navigations résidentielles locales qui passent, alors que des environnements Docker ou VPS se font bloquer.
- Analyse des en-têtes HTTP : Cloudflare compare votre User-Agent, votre Accept-Language, l’ordre des en-têtes et la version HTTP. Une incohérence — par exemple se faire passer pour Chrome 136 alors que la poignée de main TLS trahit un client Python — est un signal évident.
- Empreinte TLS (JA3/JA4) : pendant la négociation TLS, votre client révèle un ensemble de suites cryptographiques, d’extensions et de préférences de protocole. condense tout ça en identifiant. Un vrai Chrome et un script Python
requestsn’ont tout simplement pas la même “signature”. - Empreinte HTTP/2 : les navigateurs et les bibliothèques HTTP diffèrent dans les trames SETTINGS HTTP/2, l’ordre des pseudo-en-têtes et la gestion des priorités. Le travail de Cloudflare sur va au-delà de l’identité d’une requête isolée et suit les schémas entre requêtes dans le temps.
- AI Labyrinth : la nouveauté de Cloudflare. Au lieu de bloquer les crawlers suspects, le système qui paraissent crédibles mais gaspillent les ressources du crawler. Votre scraper peut même ne pas se rendre compte qu’il a été piégé.
Détection active : les challenges exécutés dans votre navigateur
Quand les vérifications passives ne suffisent pas, Cloudflare passe à la vitesse supérieure avec des challenges actifs :
- Challenges JavaScript : le classique interstitiel « Checking your browser… ». Les de Cloudflare exécutent des scripts invisibles pour repérer les requêtes automatisées.
- Turnstile : le remplaçant de CAPTCHA signé Cloudflare. Les incluent Managed, Non-Interactive et Invisible. Il analyse les mouvements de souris, l’environnement navigateur, l’empreinte TLS, etc. — sans forcément afficher le moindre puzzle visible.
- Empreinte Canvas et WebGL : ces contrôles repèrent les navigateurs headless qui rendent les pages différemment d’un vrai navigateur.
- Signaux comportementaux : timing des requêtes, défilement, séquences de clics. Un scraper qui récupère 50 pages en 3 secondes sans aucun mouvement de souris n’a rien d’humain.
En pratique : si Cloudflare est passé au challenge actif, les clients HTTP classiques comme requests, httpx ou même curl_cffi ne suffisent plus. Il faut un vrai environnement navigateur.
Les niveaux de protection Cloudflare : pourquoi le même script marche sur un site et pas sur un autre
C’est justement ce que la plupart des guides de contournement oublient. La protection Cloudflare n’est pas uniforme. Un site sur l’offre gratuite avec « Security Level: Medium » n’a rien à voir avec un site Enterprise qui active Bot Management et Turnstile. Le même script peut passer tranquillement sur l’un et se heurter à un mur sur l’autre.
| Niveau Cloudflare | Défenses typiques | Difficulté de contournement | Ce qui fonctionne généralement |
|---|---|---|---|
| Offre gratuite (sécurité faible) | Bot Fight Mode, règles WAF de base, réputation IP | ⭐ Faible | Découverte d’API interne, curl_cffi avec les bons en-têtes, vraie session navigateur |
| Offre Pro (moyenne) | Super Bot Fight Mode, Managed Challenge, détections JavaScript | ⭐⭐ Moyenne | Vraie session navigateur, automatisation de navigateur furtive, proxies résidentiels |
| Business | WAF plus strict, Bot Analytics, challenges plus serrés sur les chemins clés | ⭐⭐⭐ Moyenne à élevée | Extraction via session navigateur, persistance de session, proxies résidentiels/mobiles, API de scraping payantes |
| Enterprise / Bot Management | Scores bot, champs JA3/JA4, règles par endpoint, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Élevée | API interne (si accessible), outils basés sur une vraie session utilisateur, API de scraping de niveau fournisseur |
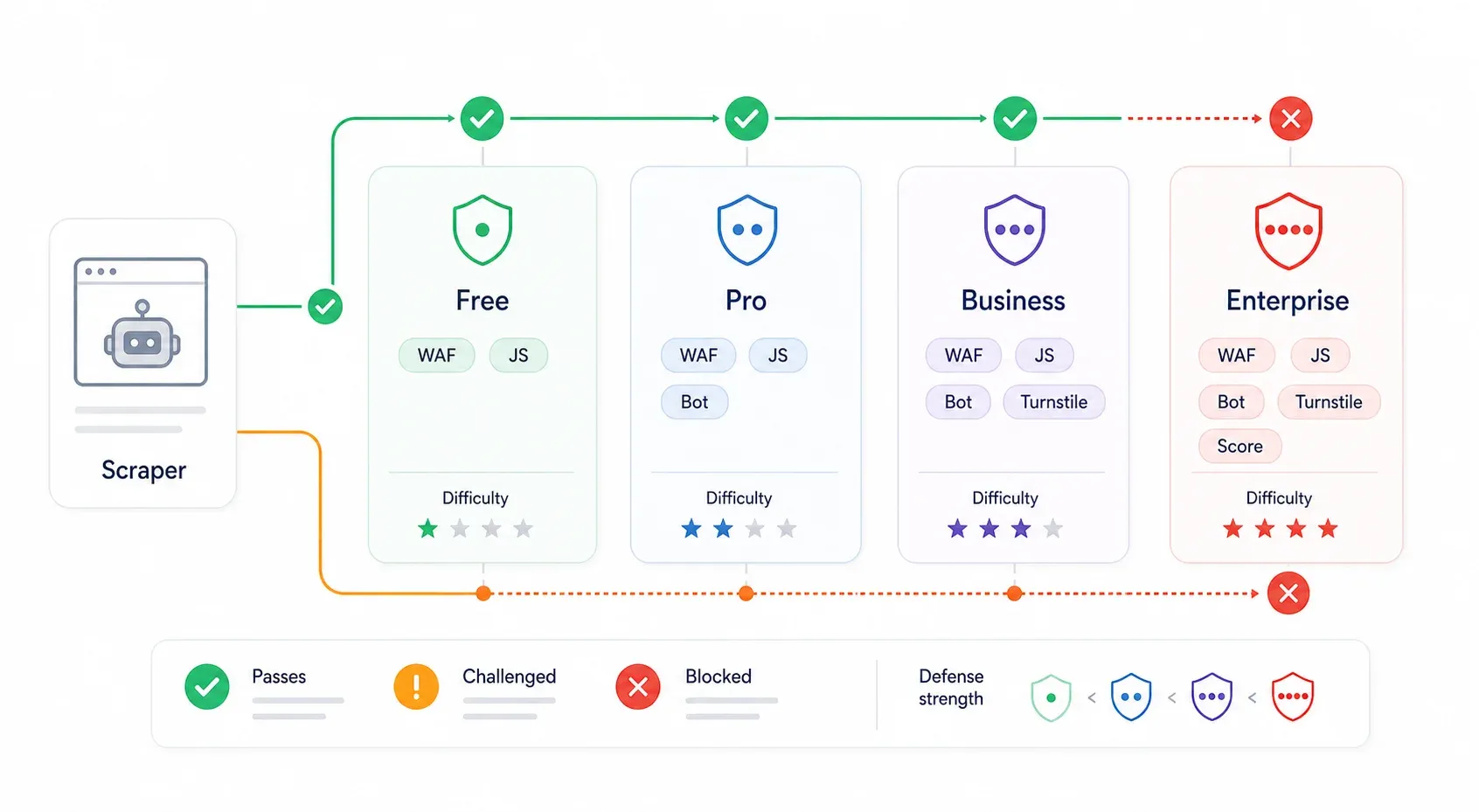
La indique Free à 0 $, Pro à 20 $/mois, Business à 200 $/mois et Enterprise sur devis. est l’option simple de l’offre Free ; ajoute davantage de contrôles pour Pro/Business ; Bot Management Enterprise ajoute des scores bot plus précis et des règles spécifiques à chaque endpoint.
Comment identifier approximativement le niveau en face : un 403 avec un blocage estampillé Cloudflare et sans script de challenge signale souvent un refus WAF ou une détection d’empreinte. Un cf-turnstile div ou un script challenges.cloudflare.com/turnstile/v0/api.js indique Turnstile. Un interstitiel « Checking your browser » correspond à un Managed Challenge. Des échecs limités à certaines routes après le chargement de la page d’accueil signalent souvent des règles WAF ou Bot Management propres à l’endpoint.
Identifiez le niveau de protection avant de choisir votre méthode. Ça vous évitera des heures de débogage.
L’arbre de décision « essayez ça d’abord » pour contourner Cloudflare
Au lieu de tester des méthodes au hasard, suivez une logique hiérarchisée. Commencez par la plus simple et la plus fiable, puis montez en puissance seulement si nécessaire :
| Étape | Essayez d’abord | Pourquoi | Si ça échoue → |
|---|---|---|---|
| 1 | Vérifier l’existence d’une API interne / non documentée | Évite Cloudflare complètement ; c’est le plus rapide et le plus fiable | Étape 2 |
| 2 | Utiliser un outil no-code avec rendu navigateur intégré (par ex. Thunderbit) | Aucune configuration, gère automatiquement les challenges JavaScript | Étape 3 |
| 3 | Impersonation de l’empreinte TLS (curl_cffi) | Rapide, léger, sans navigateur | Étape 4 |
| 4 | Automatisation furtive du navigateur (SeleniumBase UC / Puppeteer stealth) | Gère les challenges JavaScript + l’empreinte | Étape 5 |
| 5 | FlareSolverr + Docker | Open source, adapté aux serveurs | Étape 6 |
| 6 | API de scraping payante (ScrapingBee, ZenRows, Scrapfly, etc.) | Externalise complètement la course à l’armement | — |
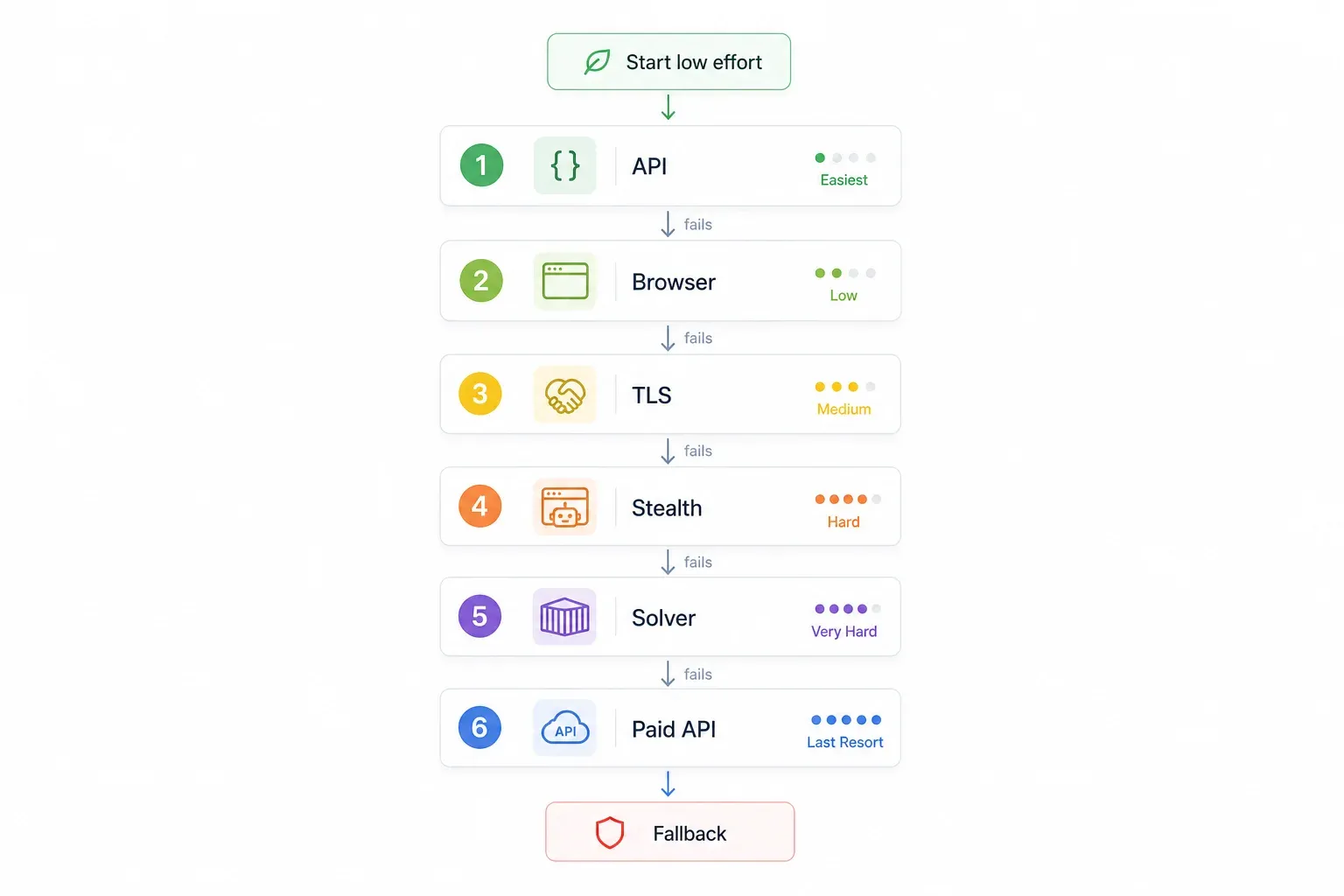
La logique est simple : d’abord le gratuit et le plus simple, puis le code plus lourd et le payant en dernier recours. Allez directement à l’étape qui correspond à votre situation.
Un a indiqué que curl_cffi passait 16 domaines testés sur 20 (80 %), que FlareSolverr couvrait environ 55 à 70 %, et que les agrégateurs de proxies payants atteignaient en moyenne près de 97 % de réussite — mais le même fil précise que ces chiffres changent dès que Cloudflare se met à jour. Prenez tous les taux comme indicatifs, jamais garantis.
Étape 1 : évitez le combat — trouvez l’API interne derrière Cloudflare
Quatre discussions de forum distinctes que j’ai lues conseillent de trouver l’API interne du site au lieu d’affronter Cloudflare de face. Et franchement, c’est le meilleur premier réflexe. Si le site expose une API interne, vous contournez Cloudflare entièrement — sans bidouille, sans spoofing d’empreinte, sans plugin furtif.
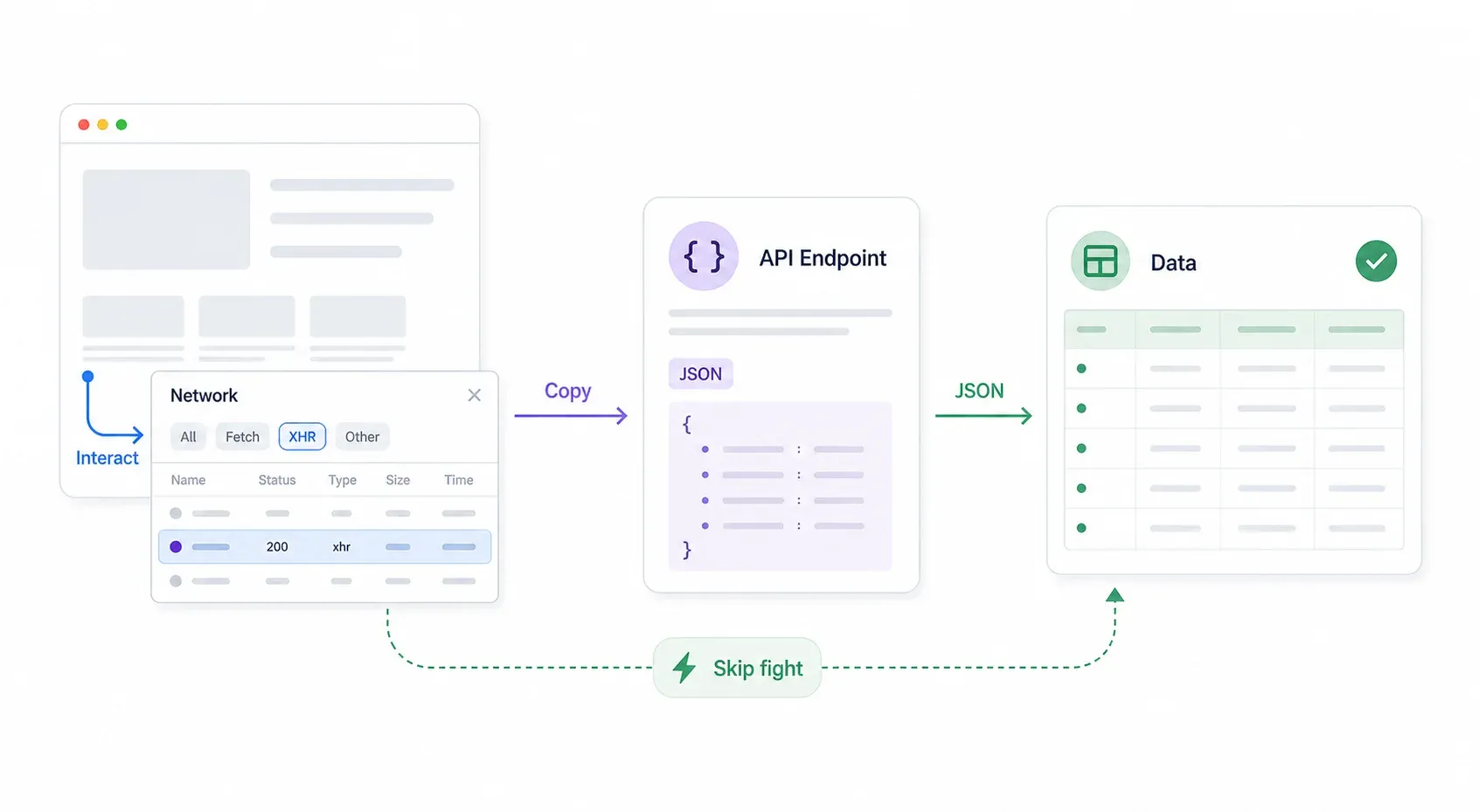
Voici la méthode systématique :
- Ouvrez Chrome DevTools → allez dans l’onglet Network → filtrez par XHR/Fetch.
- Interagissez avec la page : recherche, filtres, pagination, scroll. Repérez les réponses JSON qui apparaissent dans l’onglet Network.
- Inspectez l’URL et les en-têtes de la requête. Souvent, l’endpoint API n’a pas la protection Cloudflare ou en a une plus légère que la page front-end.
- Clic droit sur la requête → Copy → Copy as cURL. Collez-la dans votre terminal ou Postman et testez-la.
- Reproduisez la requête en Python (avec
requestsoucurl_cffi) en conservant les mêmes en-têtes, cookies et paramètres de requête.
Si l’API renvoie du JSON structuré, vous n’aurez peut-être même pas besoin d’un scraper classique. Un décrivait exactement ce cas : un utilisateur bloqué par Cloudflare malgré curl_cffi a découvert que la seule voie viable consistait à intercepter directement la réponse API.
Conseil pratique : une fois que la copie cURL fonctionne, commencez à retirer les en-têtes superflus. Des en-têtes comme sec-ch-ua, les cookies, les tokens CSRF et referer peuvent être nécessaires ; les contrôles de cache du navigateur, en revanche, le sont généralement moins. Gardez une empreinte TLS cohérente avec le User-Agent lorsque vous passez du cURL navigateur au code.
Limites : tous les sites n’exposent pas d’API accessible. Certaines API exigent une authentification, des tokens CSRF, des paramètres signés ou des cookies liés à la session. Mais quand ça marche, c’est la méthode qui se rapproche le plus d’un taux de réussite à 99 %, sans maintenance.
Étape 2 : la voie sans code — contourner Cloudflare avec une extension de navigateur (Thunderbit)
Tous les guides concurrents partent du principe que le lecteur code en Python ou en JavaScript. Pourtant, ce mot-clé attire aussi des équipes commerciales qui montent des listes de prospects, des équipes e-commerce qui surveillent les prix des concurrents et des analystes immobiliers qui récupèrent des données de biens. Ces profils n’ont pas forcément envie de lancer des conteneurs Docker.
Une extension Chrome comme gère naturellement beaucoup de contrôles Cloudflare, puisqu’elle fonctionne dans votre vraie session navigateur. Elle hérite de l’empreinte TLS authentique de Chrome, de vos cookies, de votre état de connexion et de vos signaux comportementaux — exactement ce que Cloudflare considère comme fiable. Pas de plugin furtif, pas de xvfb-run, pas de ligne de commande.
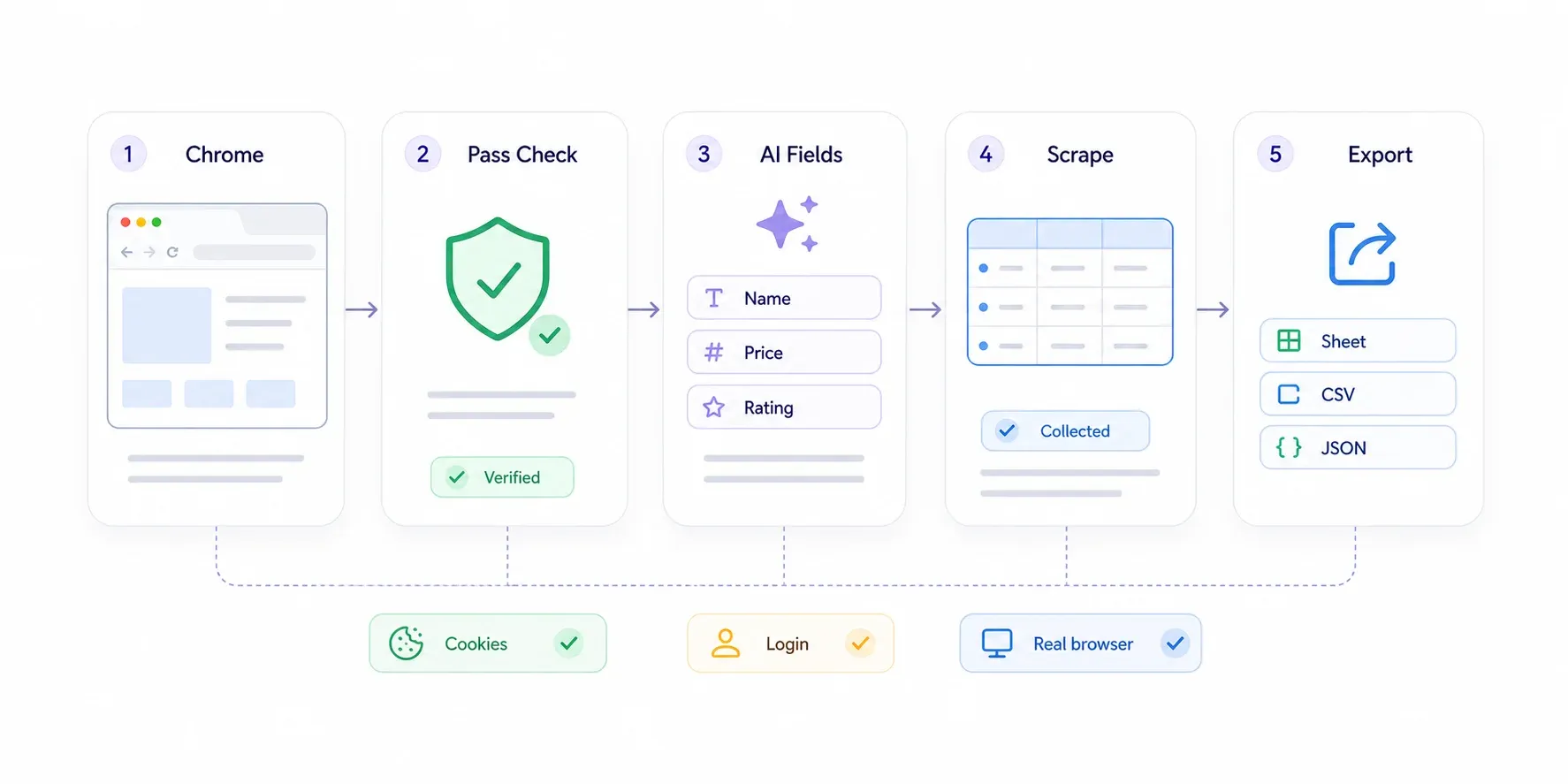
Tutoriel pas à pas
- Installez l’ depuis le Chrome Web Store.
- Ouvrez la page protégée par Cloudflare dans Chrome. Si Cloudflare lance un challenge, résolvez-le comme un utilisateur normal — cochez Turnstile si nécessaire, attendez que la page « Checking your browser » disparaisse. Vous êtes une vraie personne dans un vrai navigateur ; Cloudflare vous laisse passer.
- Cliquez sur « AI Suggest Fields » dans la barre latérale Thunderbit. L’IA analyse la page et propose des colonnes comme « Nom du produit », « Prix », « Note » ou toute autre donnée utile.
- Passez en revue les champs suggérés. Supprimez ce qui ne vous sert pas, ajoutez des champs personnalisés en décrivant simplement ce que vous voulez.
- Cliquez sur « Scrape ». Thunderbit extrait les données de la page visible.
- Exportez vers Google Sheets, Excel, Airtable, Notion, CSV ou JSON.
Pour les sites paginés, Thunderbit gère aussi bien la pagination par clic que le scroll infini. Pour les pages détaillées (par exemple, si vous avez une liste de liens produits et que vous voulez récupérer les caractéristiques de chaque page individuelle), utilisez le — Thunderbit visite chaque page de détail liée et enrichit votre tableau.
D’après mon expérience, ce flux prend environ 5 à 10 minutes entre l’installation et l’export du tableau pour un jeu de données classique de 50 à 100 lignes.
Quand le scraping via navigateur fonctionne le mieux — et quand il atteint ses limites
Je préfère être transparent sur les limites. Le scraping via navigateur dépend de la vitesse de votre session. Il est idéal pour les tâches de taille moyenne — de quelques centaines à quelques milliers de pages. Si vous devez explorer des millions de pages selon un planning, vous aurez plutôt besoin d’une méthode par code ou d’une API.
L’option Cloud Scraping de Thunderbit peut accélérer les choses en récupérant jusqu’à 50 pages à la fois pour les sites accessibles publiquement. Et pour les workflows de développeurs ou les volumes plus importants, l’ gère le rendu JavaScript, la protection anti-bot et la rotation des proxies avec un traitement par lots pouvant aller jusqu’à .
Mais pour un utilisateur métier qui scrape des leads, des prix ou des annonces immobilières à une échelle raisonnable ? C’est souvent la seule méthode dont vous avez besoin. Pas de code, pas de proxies, pas de maintenance.
Étape 3 : spoofing de l’empreinte TLS avec curl_cffi (approche légère en code)
Si vous êtes à l’aise avec Python et que la voie sans code ne colle pas à votre façon de travailler, est l’option code la plus légère. C’est un binding Python autour de libcurl capable d’imiter l’empreinte TLS de vrais navigateurs. Contrairement à requests ou httpx, votre poignée de main TLS ressemble à celle de Chrome ou Safari.
En 2026, les incluent chrome136, safari184 et de nombreux profils historiques. La bibliothèque a eu une , ce qui montre qu’elle est activement maintenue.
Quand l’utiliser : sites avec protection Cloudflare de niveau Free ou Pro qui reposent surtout sur l’empreinte passive — sans challenge JavaScript actif ni Turnstile.
Exemple basique :
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Point qui piège souvent les gens : gardez un User-Agent cohérent avec la cible d’impersonation. Si vous imitez Chrome 136, n’envoyez pas une chaîne User-Agent de Chrome 120. L’incohérence est un signal.
Limites : curl_cffi n’exécute pas JavaScript. Si le site affiche un challenge « Checking your browser » ou un widget Turnstile, cette méthode échoue. Elle n’est pas non plus utile pour les sites qui exigent un état de session basé sur des cookies issus d’un challenge navigateur. Voyez-la comme un premier essai rapide et peu coûteux pour une protection purement passive.
Alternatives de la même famille : tls-client et curl-impersonate offrent des capacités similaires d’imitation TLS.
Étape 4 : automatisation furtive du navigateur (Puppeteer Stealth et SeleniumBase UC)
Le spoofing TLS ne suffira pas si le site exige l’exécution JavaScript, des challenges actifs ou Turnstile. À ce stade, il vous faut un navigateur complet. Deux options principales :
- SeleniumBase UC Mode (Python) : la comme un moyen pour que l’automatisation paraisse plus humaine et évite les services anti-bot. Des exemples de gestion de Cloudflare Turnstile y sont inclus.
- Puppeteer avec
puppeteer-extra-plugin-stealth(Node.js) : encore très utilisé, mais . Les retours de la communauté évoquent des échecs dus à des flags de détection CDP (Chrome DevTools Protocol) et à des profils navigateur incohérents.
Ces deux outils lancent un vrai navigateur Chromium mais corrigent certains signaux d’automatisation détectables : navigator.webdriver, métadonnées WebGL, liste des plugins, etc.
Conseils de configuration qui comptent vraiment :
- Utilisez le mode avec interface (pas headless). La documentation de SeleniumBase indique que UC Mode est détectable en headless. Sur les serveurs Linux, utilisez un affichage virtuel.
- Randomisez la taille de la fenêtre et le User-Agent, mais gardez-les cohérents entre eux et avec la géolocalisation de votre proxy.
- Ajoutez des délais réalistes entre les actions. Un écart de 200 ms entre deux chargements de page crie « bot ».
- Conservez les cookies et les profils navigateur après avoir passé le challenge initial. Ne résolvez pas le challenge à chaque requête.
- Associez des proxies résidentiels pour une meilleure réputation IP.
Le risque de cette approche, c’est la maintenance. Les stacks d’automatisation de navigateur cassent quand Chrome se met à jour, quand Cloudflare ajoute un nouveau signal, quand un plugin furtif prend du retard, ou quand une cible ajoute un Turnstile spécifique à une route. Un a montré que beaucoup de montages de navigateurs furtifs échouent aux tests d’empreinte à cause de combinaisons « franken-fingerprint » — fuseau horaire, langue et géographie du proxy qui ne concordent pas.
Cette méthode est puissante, mais coûteuse à maintenir. Prévoyez du temps pour des corrections continues.
Rotation de proxies : pourquoi l’IP compte autant que l’empreinte
Même avec un navigateur parfaitement furtif, envoyer trop de requêtes depuis une seule IP déclenche les limitations de débit. Cloudflare fait nettement plus confiance aux IP résidentielles et mobiles qu’aux IP de datacenter.
- Proxies résidentiels : à faible volume en 2026. Plus fiables, mais plus chers.
- Proxies de datacenter : moins chers, mais .
- Stratégie de rotation : faites tourner par session, pas par requête. Une rotation à chaque requête casse les cookies liés à la session et
cf_clearance. Gardez IP, cookies et empreinte cohérents au sein d’une session.
Il n’existe pas de taille minimale magique pour un pool de proxies. Un scraping de leads à faible volume peut fonctionner avec quelques sessions résidentielles persistantes ; un suivi tarifaire à gros volume peut nécessiter des centaines de sorties et une logique de retry.
Étape 5 : FlareSolverr — le serveur open source de contournement Cloudflare
est un serveur proxy open source qui utilise Chromium avec undetected-chromedriver dans un conteneur Docker pour résoudre les challenges Cloudflare et renvoyer cookies et en-têtes pour réutilisation. Il a publié une , preuve qu’il est toujours maintenu.
Quand l’utiliser : pipelines de scraping côté serveur où vous avez besoin d’un service persistant de résolution de challenges — par exemple une tâche automatisée lancée chaque nuit et nécessitant de nouveaux cookies cf_clearance.
Principe de fonctionnement : votre scraper envoie une URL à l’API FlareSolverr. FlareSolverr ouvre la page dans un navigateur, tente de résoudre le challenge et renvoie le HTML ainsi que les cookies. Vous pouvez ensuite réutiliser ces cookies dans votre client HTTP habituel pour les requêtes suivantes.
Aperçu de la configuration : Docker Compose, lancement du conteneur, envoi de requêtes POST vers l’endpoint API local. .
Limites à connaître clairement :
- Ne résout pas de manière fiable les challenges Turnstile interactifs ni Bot Management Enterprise.
- Les et montrent un comportement inconstant : détection des challenges ratée, timeouts Turnstile, crashs de page.
- Nécessite une infrastructure Docker et une maintenance continue.
- Consomme beaucoup de ressources — chaque résolution lance un contexte navigateur.
Fiabilité estimée : 60 à 80 % sur des cibles à protection moyenne. Plus bas pour Enterprise, plus haut pour des pages de challenge plus simples. Si FlareSolverr ne suffit pas, il est temps d’envisager des API payantes.
Étape 6 : les API de scraping payantes qui gèrent Cloudflare à votre place
Parfois, le calcul est simple : maintenir sa propre infrastructure furtive coûte plus cher en heures d’ingénierie qu’un abonnement. Les API de scraping payantes externalisent toute la course à l’armement à un fournisseur dédié — vous envoyez une URL, ils gèrent l’empreinte, les proxies, la résolution de challenges et les retries.
Comment les comparer :
| Fournisseur | Prise en charge de Cloudflare | Rendu JavaScript | Proxies résidentiels | Sortie structurée | Modèle tarifaire |
|---|---|---|---|---|---|
| ScrapingBee | Oui | Oui | Oui | HTML uniquement | Crédits par requête |
| ZenRows | Oui (annoncé >99 % de réussite) | Oui | Oui (premium) | HTML, parsing partiel | CPM avec multiplicateurs |
| Scrapfly | Oui (Cloudflare, Akamai, DataDome listés) | Oui | Oui | HTML, parsing partiel | Modèle à crédits |
| Browserless | Oui | Oui (Chrome headless) | Oui (intégré) | HTML, captures d’écran | Facturation par unités |
| Thunderbit API | Oui | Oui | Oui | JSON/CSV structuré avec schéma IA | Offre gratuite + abonnements payants |
Quand ça a du sens : scraping à fort volume, besoins de fiabilité niveau entreprise, ou situations où votre équipe ne veut pas entretenir d’infrastructure de scraping. Fourchette de coût : environ 30 à 500 $+/mois pour des usages petits à moyens, puis davantage pour les volumes enterprise.
L’API Thunderbit mérite une mention à part, car elle renvoie des données structurées et pas seulement du HTML brut. Son peut traiter jusqu’à 50 URL par requête et renvoyer du JSON/CSV basé sur un schéma alimenté par l’IA — utile si vous avez besoin de données propres et directement exploitables, plutôt que d’HTML à parser vous-même.
Tableau de bord honnête de fiabilité : ce qui marche vraiment — et ce qui casse
Je suis les retours de la communauté, les issues GitHub et les promesses des fournisseurs tout au long de 2025–2026. Voici une comparaison sans détour. Ce sont des estimations indicatives, pas des benchmarks de labo :
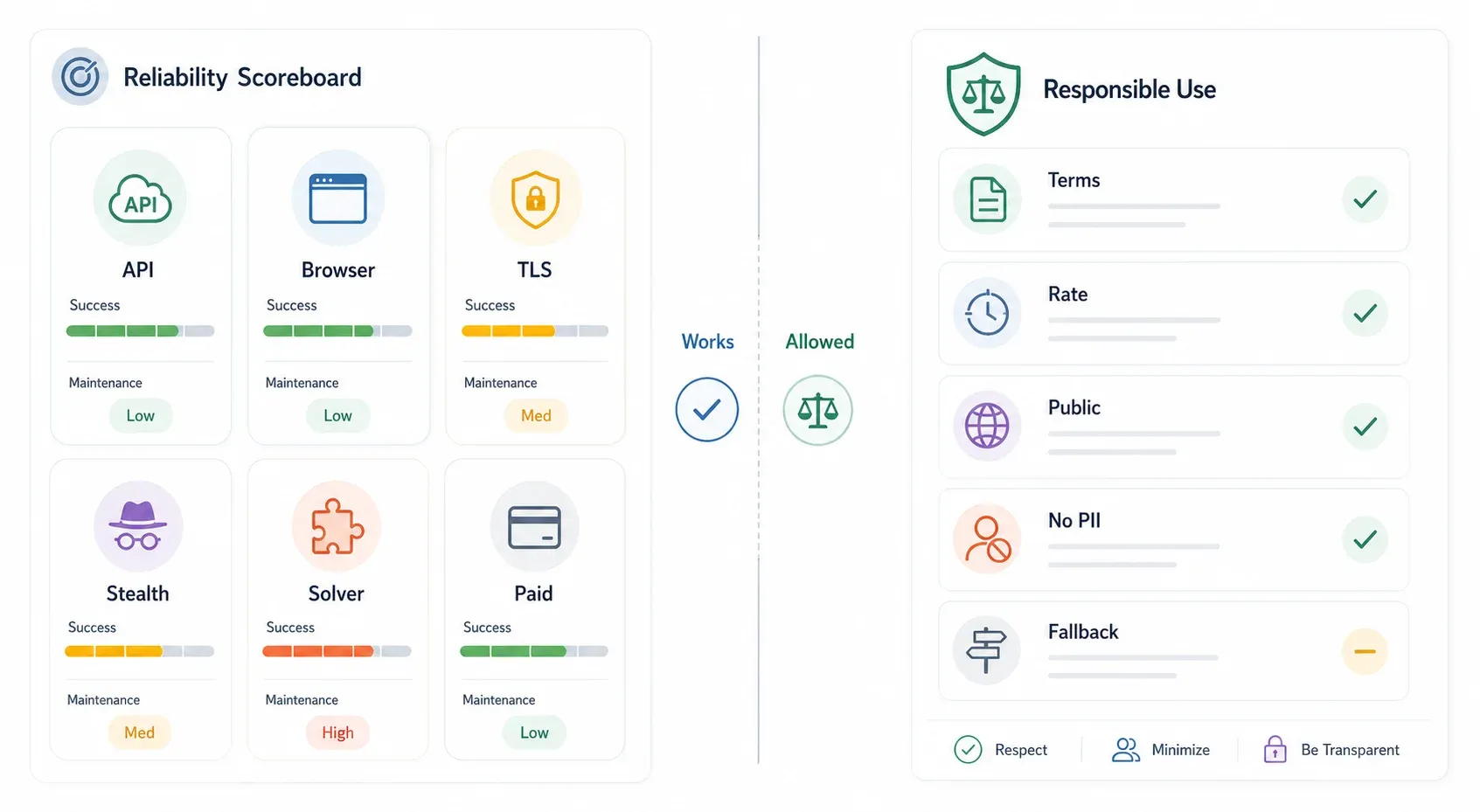
| Méthode | Taux de réussite estimé | Charge de maintenance | Casse quand… | Fourchette de coût |
|---|---|---|---|---|
| API interne (si elle existe) | ~90–99 % | Faible | L’API change, l’authentification s’ajoute, les tokens deviennent signés | Gratuit |
| Extension navigateur (Thunderbit) | ~85–95 % (vraie session) | Faible (l’IA s’adapte aux changements de mise en page) | Le site impose un flux d’authentification spécial, ou Turnstile devient trop agressif à chaque action | Offre gratuite disponible |
curl_cffi / spoofing TLS | ~70–85 % | Moyenne (mises à jour des empreintes) | Cloudflare change les vérifications JA3, un challenge JS actif devient nécessaire | Gratuit |
| Puppeteer + plugin stealth | ~70–90 % | Élevée (les mises à jour du plugin prennent du retard) | Détection CDP, nouveaux signaux d’empreinte, détection headless | Gratuit + coût proxy |
| FlareSolverr | ~60–80 % | Élevée (Docker, dérive des dépendances) | Protection de niveau Enterprise, interaction Turnstile | Gratuit + coût d’infrastructure |
| API de scraping payante | ~85–95 % | Faible (gérée par le fournisseur) | Le fournisseur n’a pas mis à jour ; budget dépassé | ~30 à 500 $+/mois |
La colonne la plus importante n’est pas le taux de réussite — c’est « Casse quand ». Chaque méthode a son mode d’échec. La meilleure stratégie, c’est de choisir la méthode la moins coûteuse en effort qui fonctionne pour votre cible, puis de prévoir un plan de secours.
Il n’existe pas de solution permanente. Cloudflare évolue en continu. La course à l’armement est bien réelle.
Conseils pour rester sous le radar de Cloudflare, quelle que soit la méthode utilisée
Quelle que soit la méthode choisie, quelques habitudes vous aideront à rester plus longtemps sous le radar de Cloudflare :
- Respectez les limites de débit. Ajoutez des délais réalistes entre les requêtes — 2 à 5 secondes minimum pour une navigation de type humain. Marteler un site à vitesse machine, c’est le moyen le plus rapide d’être bloqué.
- Gardez une empreinte cohérente. User-Agent, empreinte TLS, version du navigateur, fuseau horaire, langue et géographie IP doivent raconter la même histoire. Un User-Agent Chrome 136 depuis une IP allemande avec une locale
en-USet une poignée de main TLS Python se contredit. - Réutilisez cookies et sessions après avoir franchi un challenge. Ne résolvez pas le challenge à chaque requête.
- Ne changez pas d’IP en plein milieu de session. Cloudflare suit la continuité de session.
- Utilisez des IP résidentielles ou mobiles lorsque le cas d’usage et le budget le justifient.
- Surveillez les blocages silencieux : HTML de challenge là où vous attendiez du JSON, tableaux vides, redirections vers la connexion, ou pages qui ressemblent étrangement à des leurres d’.
- Évitez les heures de pointe, quand les opérateurs du site peuvent durcir les règles WAF.
- Prévoyez des chemins de repli : API d’abord → session navigateur ensuite → fournisseur payant en dernier recours.
Pour les utilisateurs de Thunderbit, l’IA s’adapte automatiquement aux changements de mise en page, ce qui vous fait gagner du temps sur la maintenance des sélecteurs CSS et vous permet de vous concentrer sur l’exploitation des données.
Note rapide sur les aspects juridiques et éthiques
Ce n’est pas le sujet principal de l’article, mais c’est trop important pour être mis de côté.
Le scraping de données publiques bénéficie — le raisonnement CFAA de hiQ v. LinkedIn a survécu au renvoi de la Cour suprême, même si un accord a finalement été conclu en 2022 et que la situation reste nuancée. Plus récemment, en 2025 pour le prétendu scraping de commentaires d’utilisateurs, et plus tard la même année.
Dans l’UE, le RGPD s’applique dès lors que des données personnelles sont en jeu, et l’ ajoute des obligations spécifiques concernant .
Quelques règles pratiques :
- Vérifiez toujours les Conditions d’utilisation du site.
- La protection Cloudflare indique que le propriétaire du site veut contrôler l’accès automatisé — respectez cette intention.
- Évitez de collecter des données personnelles sans base légitime.
- Pour les usages commerciaux ou à fort volume, privilégiez les API officielles, les données sous licence ou une autorisation écrite lorsqu’elles existent.
- En cas de doute, consultez un avocat pour votre cas d’usage et votre juridiction.
Thunderbit est conçu pour des usages métier légitimes — génération de leads, suivi des prix, étude de marché — à partir de données librement accessibles.
Conclusion : quoi essayer d’abord et quoi essayer ensuite
Le plus gros gain de temps dans tout cet article n’est pas un outil ni un extrait de code — c’est d’identifier le niveau de protection avant de commencer. À lui seul, ce réflexe évite des heures de débogage sur une méthode qui n’avait aucune chance de fonctionner.
Commencez ici :
- Vérifiez s’il existe une API interne (c’est gratuit, rapide et souvent oublié).
- Si vous êtes un utilisateur métier qui ne code pas, essayez l’ — votre vraie session navigateur est votre meilleur atout face à Cloudflare.
- Si vous êtes développeur et que la cible utilise seulement une empreinte passive, testez
curl_cffi. - Passez aux navigateurs furtifs, à FlareSolverr ou aux API payantes seulement si les méthodes plus simples échouent.
Aucune méthode n’est permanente. Combinez l’outil adapté à votre volume avec un plan de secours, et vous passerez beaucoup moins de temps à corriger des pages 403.
Si vous voulez aller plus loin, nous avons aussi écrit sur , et sur le blog Thunderbit. Et si vous voulez voir l’extension en action, consultez la pour des tutoriels pas à pas.
FAQ
1. Peut-on contourner complètement la protection Cloudflare ?
Aucune méthode ne garantit 100 % de réussite, surtout face à Bot Management Enterprise avec Turnstile, l’empreinte JA4 et AI Labyrinth. Les approches les plus fiables combinent une vraie empreinte navigateur et une bonne réputation IP. Trouver une API interne est ce qui se rapproche le plus d’un contournement « total », puisqu’on évite Cloudflare entièrement — mais tous les sites n’en ont pas.
2. Est-ce légal de contourner Cloudflare lors d’un scraping ?
Cela dépend de votre juridiction, des Conditions d’utilisation du site et des données collectées. Le scraping de données publiques a parfois une jurisprudence favorable aux États-Unis (hiQ v. LinkedIn), mais contourner des contrôles techniques d’accès, violer les CGU ou collecter des données personnelles sans base légitime peut entraîner des risques juridiques. Pour les usages commerciaux, privilégiez les API officielles ou les données sous licence quand elles existent, et demandez conseil à un juriste en cas de doute.
3. Quelle est la manière la plus simple de contourner Cloudflare sans coder ?
Les extensions de navigateur comme , qui s’exécutent dans votre vraie session Chrome, gèrent automatiquement les challenges Cloudflare — vous interagissez avec le site comme un utilisateur normal, puis l’extension extrait et exporte les données. Pas de Python, pas de Docker, pas de configuration de proxy.
4. Pourquoi mon scraper fonctionne-t-il sur certains sites Cloudflare et pas sur d’autres ?
Le niveau de protection Cloudflare varie énormément selon l’offre (Free, Pro, Business, Enterprise) et la configuration. Une méthode qui marche sur un site Free avec un simple challenge JavaScript peut échouer face à Turnstile ou à Bot Management complet sur un site Enterprise. Identifiez toujours d’abord le niveau de protection — vérifiez s’il s’agit d’un simple check JavaScript, d’un Managed Challenge ou d’un widget Turnstile — avant de choisir votre méthode de contournement.
5. À quelle fréquence les méthodes de contournement Cloudflare cassent-elles ?
Les méthodes basées sur du code, comme les plugins stealth et le spoofing TLS, peuvent se dégrader toutes les quelques semaines à quelques mois sur les cibles difficiles, au rythme des mises à jour de détection de Cloudflare. Les API payantes et les outils basés sur de vraies sessions navigateur sont généralement plus robustes, car ils s’adaptent au niveau de l’infrastructure ou de la session utilisateur. Les API internes cassent rarement, sauf si le site refond son backend ou modifie son modèle d’authentification. La stratégie la plus sûre sur le long terme consiste à disposer de plusieurs méthodes de repli plutôt que de dépendre d’une seule.
En savoir plus