

Vous cherchez le meilleur outil d’extraction PDF gratuit pour récupérer des tableaux, factures ou données structurées sans copier-coller à la main ? Les PDF sont difficiles à traiter : certains contiennent de vrais tableaux, d’autres sont des scans ou des images. Un bon extracteur PDF avec IA doit détecter ces cas, extraire les données proprement et les exporter vers Excel, CSV, JSON ou vos outils de travail.
Extraire des données de n’importe quel site web grâce à l’IA Get Started Free
Par exemple, si vous voulez extraire des adresses e-mail d’un PDF, certaines peuvent être sous forme d’image, tandis que d’autres sont cachées derrière des encodages de caractères complexes. Prenons cet exemple : {john.doe,jane.doe}@example.com. Cela correspond en réalité à deux e-mails distincts : john.doe@example.com et jane.doe@example.com. Il y a aussi {first.last}@example.com, où vous remplacez « first » et « last » par le prénom et le nom de l’auteur, respectivement. Les outils classiques de reconnaissance de texte ne suffisent tout simplement pas. C’est là qu’un outil pratique, le PDF Scraper, entre en jeu pour sauver la mise.
Qu’est-ce qu’un PDF Scraper
Un PDF Scraper est un outil pratique qui extrait automatiquement les données des fichiers PDF, en convertissant leur contenu, comme les tableaux et le texte, dans les formats dont vous avez besoin, tels que Excel, CSV ou JSON. En d’autres termes, il transforme des tâches fastidieuses de copier-coller en une solution en un clic.
Imaginez une pile de factures, de contrats, d’articles universitaires ou même de PDF scannés qu’il vous faudrait des heures pour retranscrire manuellement. Avec un PDF Scraper, il suffit de téléverser le fichier, et en quelques secondes, les données sont extraites. Vous gagnez du temps et de l’énergie, tout en gardant un bon niveau de précision. Adieu les corvées de saisie manuelle.
Si votre PDF contient différents types de données, comme des tableaux, des liens et des images, laissez un AI PDF Scraper s’en occuper. Les AI PDF Scrapers utilisent de grands modèles de langage (LLM) capables de traiter en même temps le texte, les images et les tableaux, avec des résultats impressionnants.
Les avantages d’un AI PDF Scraper ne se limitent pas à l’efficacité et à la précision ; sa capacité d’adaptation en fait aussi une option sans stress. Qu’il s’agisse de documents scannés, d’images ou de PDF multilingues, l’IA gère tout cela avec aisance. De nombreux excellents outils d’IA sont disponibles, comme Thunderbit, ChatGPT et ChatPDF, chacun avec ses propres fonctionnalités pour répondre à des besoins différents. Que vous ayez besoin d’extraire rapidement des données ou d’analyser des documents complexes, choisir le bon outil peut rendre votre travail plus simple et plus efficace.
Essayez-le : extraire des données de PDF avec l’IA
Essayez ! Vous pouvez cliquer, explorer et lancer le workflow pendant que vous regardez.
Comment choisir le bon PDF Scraper
Choisir un PDF Scraper, c’est un peu comme acheter une voiture : le meilleur est celui qui correspond à vos besoins. Voici quelques points à prendre en compte :
| Fonctionnalité | Description |
|---|---|
| Précision et stabilité | Vérifiez si l’outil extrait les données avec précision, surtout pour les informations critiques. |
| Formats de sortie | Assurez-vous que l’outil prend en charge les formats dont vous avez besoin, comme Excel, CSV ou JSON. |
| Intégration avec d’autres outils | Si vous devez le connecter aux systèmes de votre entreprise, vérifiez qu’il prend en charge une intégration fluide. |
| Interface conviviale | Un outil facile à utiliser convient mieux aux utilisateurs généralistes, tandis que des outils plus complexes peuvent convenir aux équipes techniques. |
Chaque outil a ses points forts, et choisir le bon peut améliorer nettement votre productivité. Voici trois PDF Scrapers populaires, chacun avec ses propres fonctionnalités pour des besoins différents :
| Outil | Avantages | Inconvénients |
|---|---|---|
| Thunderbit | Extraction rapide ; facile à utiliser comme extension de navigateur ; excellent pour la collaboration en équipe | Capacité de traitement des données limitée |
| ChatPDF | Facile à utiliser, questions-réponses en mode chat sur un seul PDF | Pas d’export natif en CSV/Excel/JSON — les réponses restent dans le chat |
| ChatGPT | Flexible avec les sémantiques complexes, large champ d’application | Nécessite de saisir manuellement une invite à chaque fois |
Bien démarrer avec un AI PDF Scraper
Thunderbit
Vous voulez extraire rapidement des données de PDF sans y consacrer trop de temps ni d’efforts ? Thunderbit est l’outil qu’il vous faut. Simple à utiliser, il suffit d’un clic pour tout faire. Suivez ces étapes pour convertir facilement des données PDF complexes dans le format dont vous avez besoin, et gagnez nettement en efficacité :
-
Ajoutez Thunderbit à Chrome et inscrivez-vous :
Rendez-vous sur le site officiel de Thunderbit et ajoutez l’extension Thunderbit à votre navigateur Chrome. Inscrivez-vous avec votre compte Google ou une autre adresse e-mail.

-
Ouvrez le PDF dans Chrome :
Ouvrez dans Chrome le fichier PDF dont vous souhaitez extraire les données, puis cliquez sur l’icône Thunderbit en haut à droite.
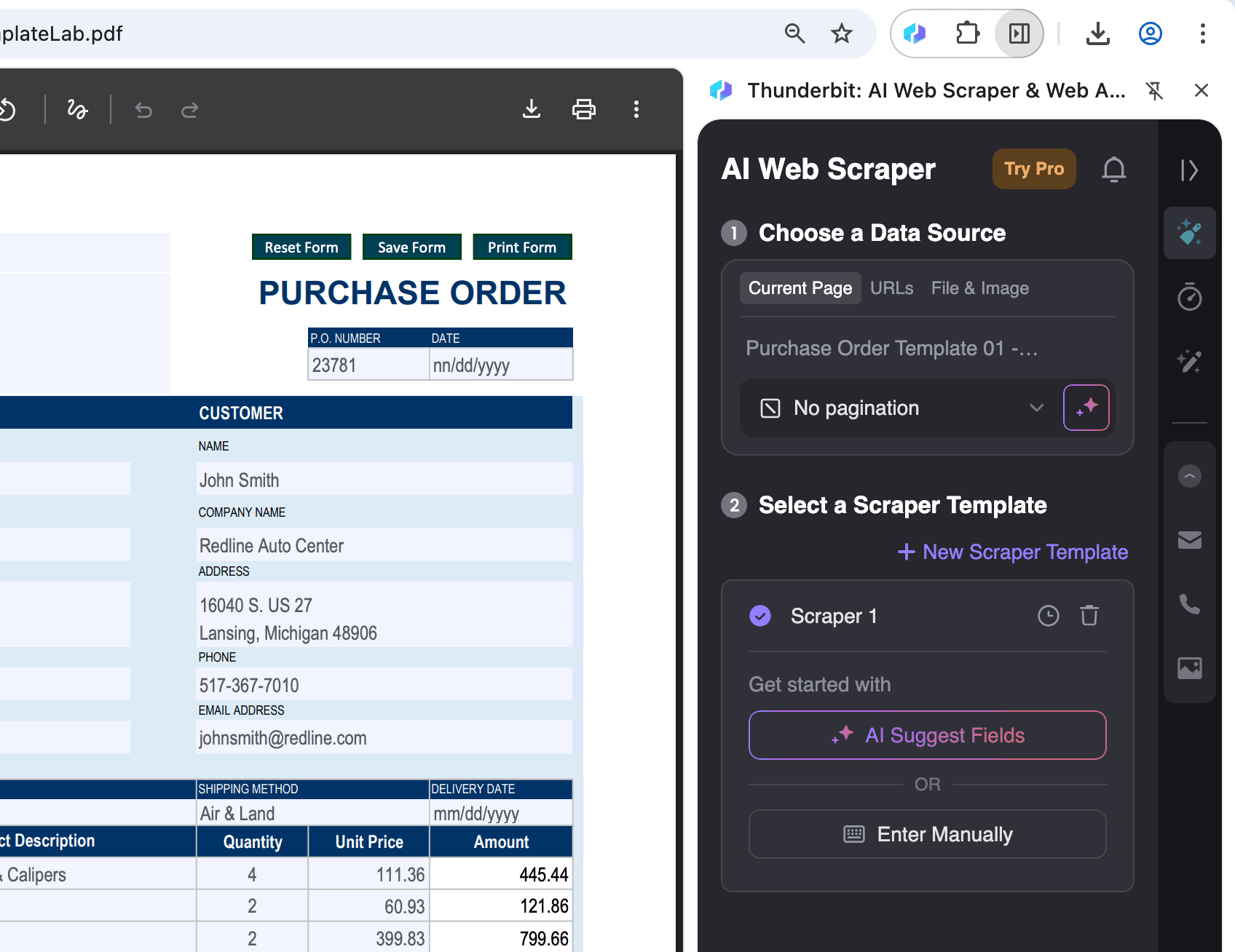
-
Choisissez le format de sortie et exportez :
Après avoir sélectionné AI Suggest Columns, vous pouvez filtrer ou ajuster les données selon vos besoins. Ensuite, choisissez le format d’export souhaité (CSV, Google Sheets, Airtable ou Notion) et cliquez sur Scrape pour exporter les données.
 Les données exportées peuvent être directement connectées à Notion, Airtable ou Google Sheets pour faciliter la collaboration en équipe.
Les données exportées peuvent être directement connectées à Notion, Airtable ou Google Sheets pour faciliter la collaboration en équipe.
Thunderbit est un outil simple d’extraction de données PDF qui vous permet d’extraire rapidement les données dont vous avez besoin depuis des fichiers PDF et de les convertir dans un format exploitable. Que ce soit pour un usage personnel ou pour une collaboration en équipe, Thunderbit peut considérablement améliorer votre productivité et rendre l’extraction de données plus simple et plus pratique.
ChatPDF
Si vous devez traiter des PDF en masse et souhaitez uniquement extraire des informations clés spécifiques plutôt que l’ensemble des données, ChatPDF est un excellent assistant. Il permet d’extraire des données de manière conversationnelle, ce qui le rend accessible aux débutants.
Voici comment extraire des données PDF avec ChatPDF :
- Visitez le site de ChatPDF : Ouvrez le site de ChatPDF ou la page de la plateforme associée.
- Téléversez des fichiers PDF : Cliquez sur le bouton « Upload File » pour glisser-déposer ou sélectionner le document PDF à analyser. L’outil prend en charge divers types de fichiers, comme les contrats, les articles ou les états financiers.
- Analysez le PDF : Une fois téléversé, ChatPDF analysera automatiquement le contenu du fichier et générera un résumé structuré du document. Vous pourrez ensuite consulter les informations clés extraites.
- Interrogez-le de manière interactive : Utilisez la zone de saisie pour poser des questions comme « Quelle est la conclusion de ce rapport ? » ou « Quel est le montant total indiqué sur la facture ? » ChatPDF extraira le contenu pertinent en fonction de votre demande.
- Copiez les réponses : ChatPDF renvoie les réponses dans la fenêtre de chat. Copiez la réponse dans un tableur, un document ou votre propre tableau — pour un rendu très structuré (CSV/JSON propre avec des colonnes cohérentes sur de nombreux fichiers), Thunderbit ou ChatGPT avec une invite fixe est un meilleur choix.
ChatPDF offre une expérience interactive, ce qui le rend particulièrement adapté pour repérer rapidement des informations dans un document, par exemple trouver des détails clés ou résumer le contenu.
ChatGPT
ChatGPT excelle dans le traitement de données sémantiques complexes, comme l’analyse des clauses de documents juridiques. Cet outil est très flexible et vous permet de personnaliser les invites pour extraire des données précises ou analyser du contenu. En revanche, vous devez réutiliser la même invite pour des tâches similaires, et cela demande une bonne maîtrise de la rédaction d’invites.
Voici une invite prête à l’emploi que vous pouvez adapter à vos besoins (n’oubliez pas de remplacer les colonnes par les informations que vous souhaitez extraire) :
Vous êtes maintenant un PDF scraper. Votre mission : lorsqu’un PDF vous est fourni, vous devez extraire son contenu en fonction des colonnes indiquées par l’utilisateur. Votre sortie doit être un fichier CSV.
Voici les colonnes :
1. Nom
2. E-mail
3. Numéro de téléphone
4. ...
- Inscrivez-vous ou connectez-vous : Ouvrez le site ChatGPT et créez un compte. Si vous en avez déjà un, connectez-vous simplement.
- Téléversez le PDF et saisissez votre requête : Tapez directement votre requête dans la zone de saisie ; plus elle est précise, mieux c’est. Par exemple : « Ce document PDF contient trois graphiques, exportez-les sous forme de tableaux. »
- Vérifiez et ajustez les résultats : Vérifiez si la réponse correspond à vos attentes. Si nécessaire, affinez les résultats en posant des questions de suivi ou en ajustant l’invite.
- Exportez les données en Excel ou CSV : Si les données extraites par ChatGPT vous conviennent, tapez dans la zone de saisie : « Exportez ces données en Excel ou CSV. »
- Enregistrez les résultats : Cliquez sur le lien de fichier fourni par ChatGPT pour télécharger le fichier.
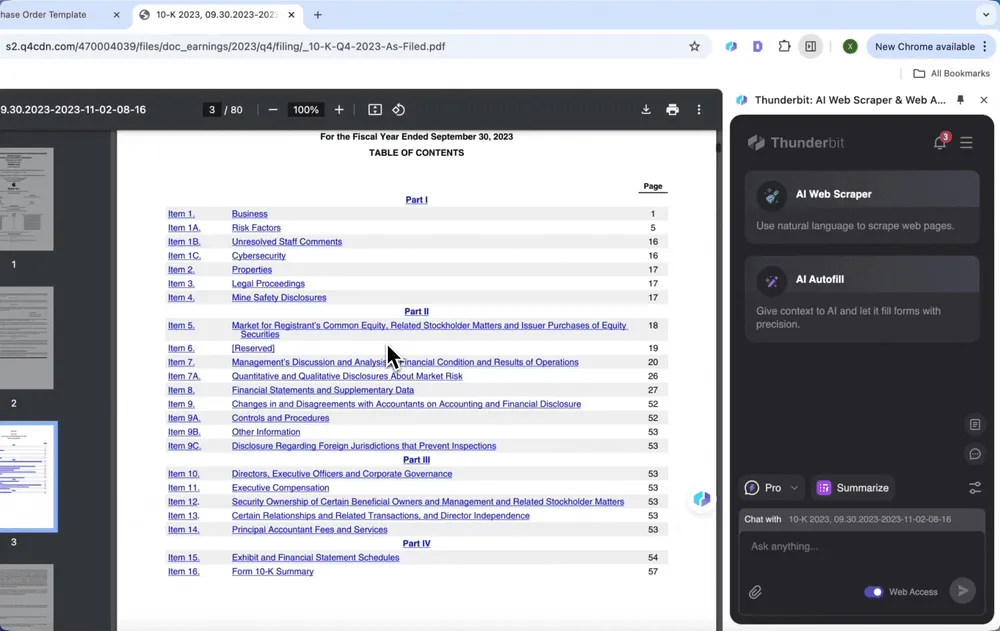
Cas d’usage concrets d’un AI PDF Scraper
L’AI PDF Scraper est comme un assistant polyvalent dans votre travail, que vous traitiez des factures, des contrats, des rapports financiers ou des bons de commande. Voici quelques scénarios pratiques où il excelle :
Traitement des factures et des reçus
Traitez en lot les factures et les reçus de l’entreprise, en extrayant les informations clés comme les montants et les dates pour la classification et l’archivage.
- Lancez Thunderbit, cliquez sur AI Web Scraper, puis sur Bulk Pages
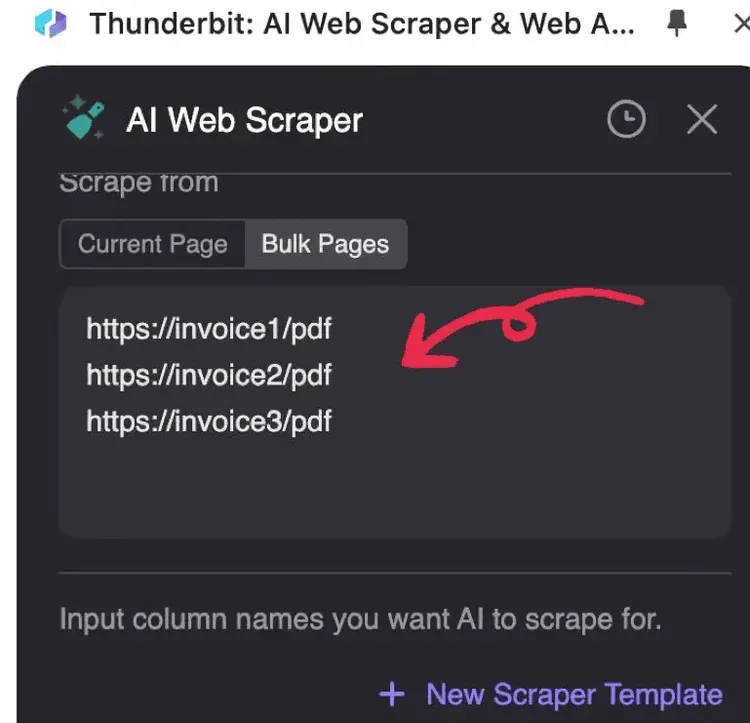
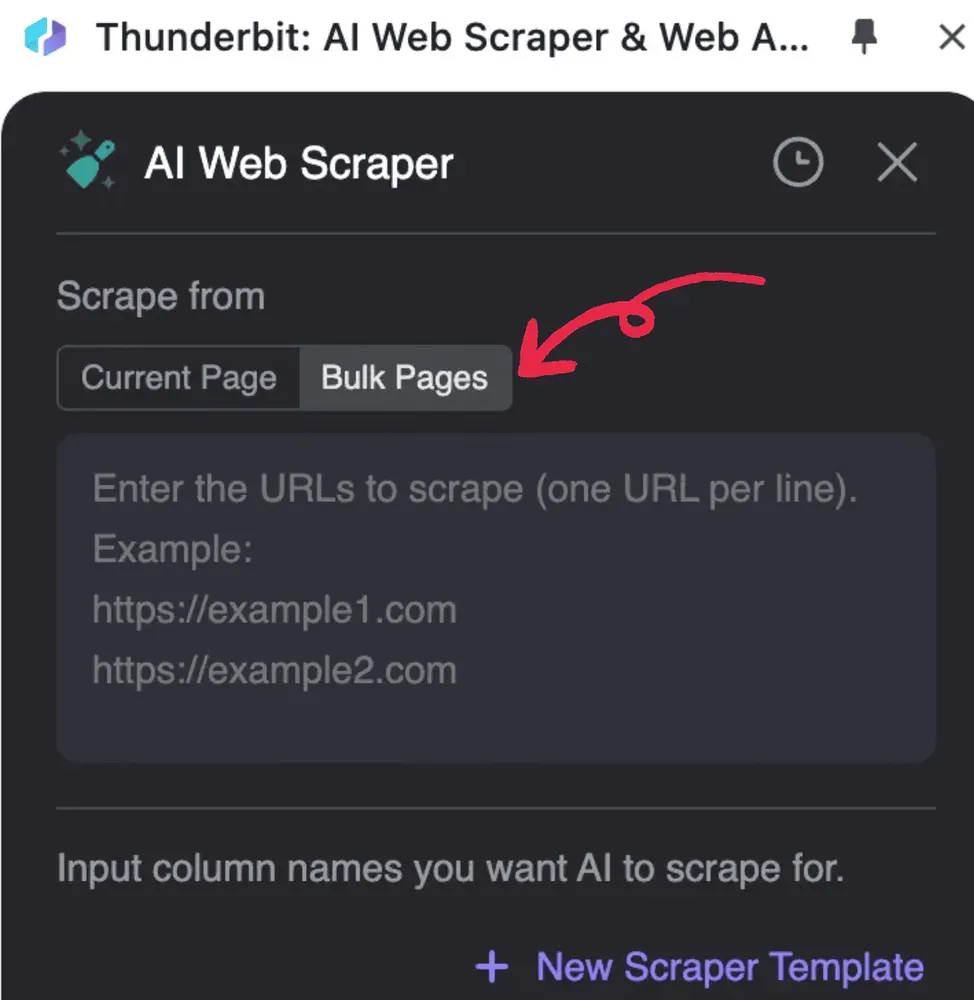 2. Saisissez les URL des PDF à traiter, une URL par ligne
2. Saisissez les URL des PDF à traiter, une URL par ligne
 3. Cliquez sur AI Suggest Columns (l’IA lira le PDF et suggérera la structure des données)
4. Cliquez sur Scrape et exportez les données
3. Cliquez sur AI Suggest Columns (l’IA lira le PDF et suggérera la structure des données)
4. Cliquez sur Scrape et exportez les données
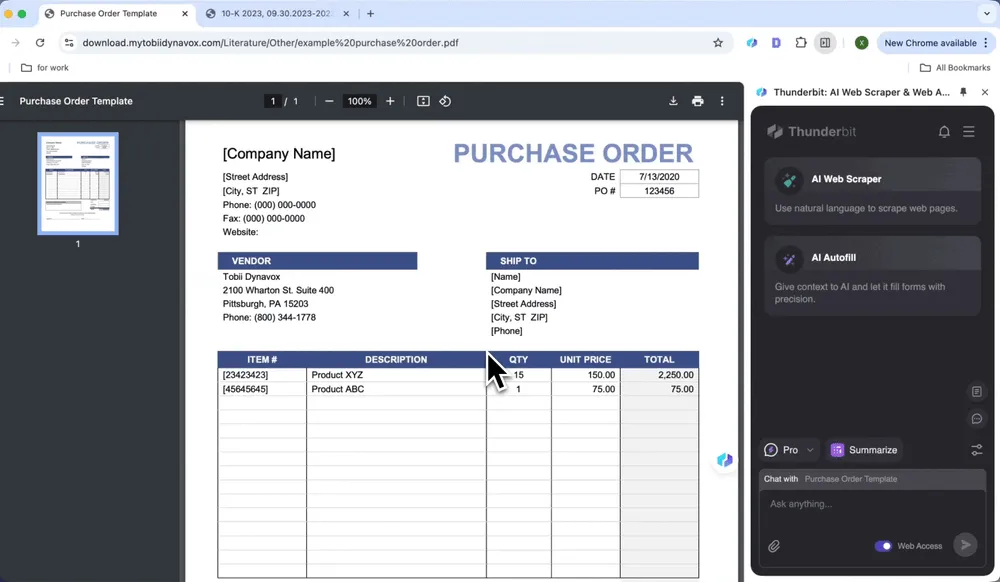
Traitement des bons de commande
Identifiez automatiquement les articles, quantités et prix unitaires dans les bons de commande, générez des enregistrements de données standardisés et extrayez les données des PDF, ce qui permet de gagner du temps sur le traitement manuel.
- Ouvrez le bon de commande dans Chrome et lancez Thunderbit
- Cliquez sur AI Web Scraper, puis sur AI Suggest Columns
- Vérifiez les noms générés dans la liste et cliquez sur Scrape
- Cliquez sur Download CSV
Extraction de données financières
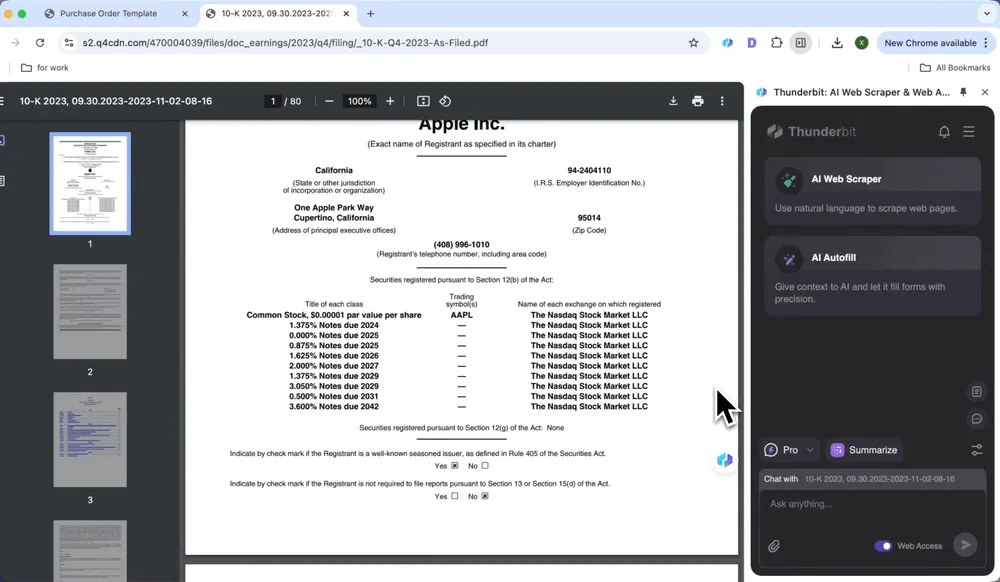
Extrayez d’un simple clic les données de rapports financiers, comme les marges bénéficiaires et les chiffres de vente, en évitant les longues vérifications manuelles.
- Ouvrez le rapport financier dans Chrome et lancez Thunderbit
- Cliquez sur Summarize
- Générez automatiquement un résumé des informations clés, y compris le texte et le contenu des tableaux
Le résumé généré automatiquement ne vous convient pas ? Vous pouvez saisir manuellement les informations du projet que vous souhaitez.
- Ouvrez le rapport financier dans Chrome et lancez Thunderbit
- Cliquez sur AI Web Scraper, saisissez les noms de projets souhaités, comme le revenu net, le chiffre d’affaires, etc.
- Cliquez sur Scrape, sortie en tableau
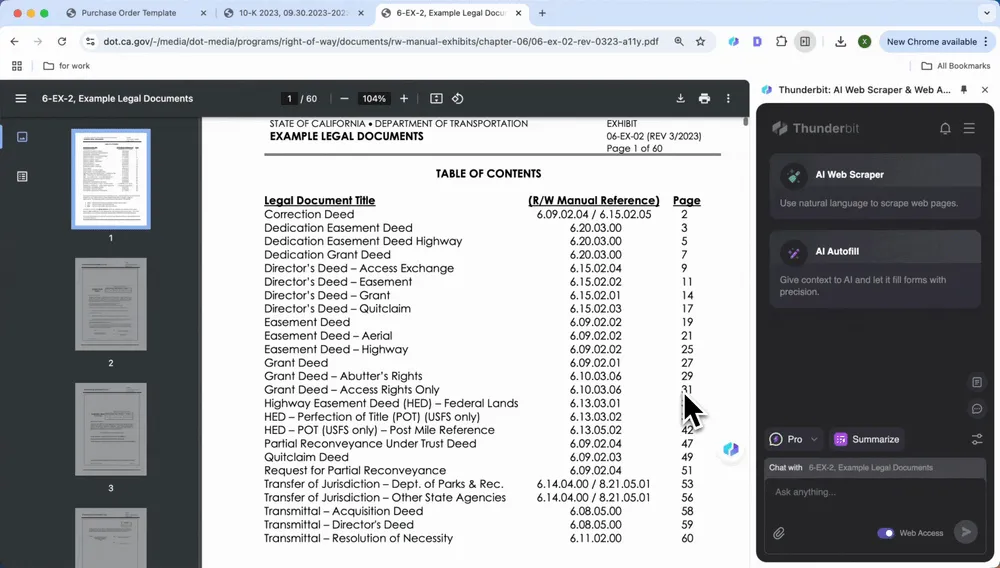
Analyse de documents juridiques
Vous avez du mal avec les clauses de contrats et d’accords ? Les outils d’IA peuvent rapidement repérer les conditions de paiement, les clauses de violation, la durée des contrats et d’autres points clés. Extrayez-les d’un clic pour générer un résumé concis ou une liste de clauses, ce qui vous fait gagner du temps et évite d’oublier des détails.
Comme pour l’extraction des informations clés à partir de rapports financiers, vous pouvez ouvrir le PDF et cliquer sur Summarize pour consulter d’un seul clic les conditions de paiement, les clauses de violation, la durée du contrat et d’autres informations importantes.
FAQ
-
Puis-je extraire des données de plusieurs PDF en même temps ?
Oui, les outils avancés d’extraction de PDF permettent d’extraire simultanément des données de plusieurs fichiers. Cette capacité de traitement par lots accélère considérablement le flux de travail par rapport aux méthodes d’extraction manuelles.
-
PDF Scraper est-il gratuit ?
Oui, plusieurs outils gratuits de PDF scraper sont disponibles. De nombreux outils en ligne, comme Thunderbit et ChatPDF, proposent des fonctions gratuites d’extraction de pages et de données. Certaines fonctionnalités avancées peuvent être payantes, mais les capacités de base d’extraction de données sont généralement gratuites.
-
Faut-il savoir programmer pour utiliser un PDF scraper ?
Non, de nombreux AI PDF scrapers, comme Thunderbit, sont conçus pour les utilisateurs sans compétences en programmation. Ils offrent des interfaces conviviales qui permettent de téléverser des fichiers et d’extraire des données en quelques clics.
-
Quels types de documents peuvent être traités avec un PDF scraper ?
Les PDF scrapers peuvent traiter divers types de documents, notamment les factures, contrats, rapports financiers, articles universitaires et tout autre contenu structuré ou semi-structuré présent dans les fichiers PDF.
-
Mes données sont-elles sécurisées lorsque j’utilise un PDF scraper ?
Les outils d’extraction de PDF réputés accordent la priorité à la sécurité des utilisateurs et respectent souvent des réglementations comme le RGPD. Ils stockent généralement vos données sur des serveurs chiffrés et n’y accèdent pas sans votre permission.
-
Existe-t-il d’autres moyens d’extraire des données d’un PDF ?
Il existe plusieurs méthodes pour extraire des données de fichiers PDF au-delà de la saisie manuelle et des scripts Python. Parmi elles : l’utilisation de convertisseurs PDF pour transformer les fichiers en formats comme Excel ou CSV, des outils spécialisés d’extraction de données PDF comme Tabula et Excalibur pour les documents structurés, des solutions pilotées par l’IA avec reconnaissance optique de caractères (OCR) pour les PDF natifs comme scannés, ainsi que des outils open source comme Extractous et PymuPDF4llm conçus pour une extraction de données efficace. Chaque méthode a ses avantages et ses limites ; le choix dépend donc des besoins spécifiques et du niveau d’expertise technique de l’utilisateur.
En savoir plus
- Comment extraire n’importe quel site web avec l’IA
- Top 5 des outils d’IA pour extraire des données de PDF
- Comment utiliser ChatGPT pour extraire des données de PDF
- Résumé de PDF gratuit en ligne
Essayez l’AI Web Scraper Get Started Free




