Firecrawl est devenu l’une des API de web scraping les plus en vue dans l’univers des développeurs IA — , le soutien de Y Combinator et une clientèle qui compte Shopify, Zapier et Apple. Mais après avoir épluché la documentation tarifaire, les plaintes d’utilisateurs, les benchmarks indépendants et les modèles de coûts réels, le récit mis en avant et l’expérience réelle sont assez éloignés.
Cet avis sur Firecrawl n’est pas une simple liste de fonctionnalités. Si vous vous êtes inscrit, avez lancé quelques tests, et vous vous demandez maintenant « combien cela va-t-il vraiment me coûter à grande échelle ? » — ou si vous cherchez à déterminer si Firecrawl est le bon outil pour votre équipe dès le départ — vous êtes au bon endroit. Je vais passer en revue les vrais coûts (y compris le piège de la double facturation que la plupart des avis passent sous silence), les domaines où Firecrawl excelle réellement, ceux où il déçoit (surtout sur les sites protégés contre les bots), et les cas où un outil complètement différent — y compris des options no-code comme — est un choix plus intelligent. Mon objectif : vous éviter la mauvaise surprise sur la carte bancaire.
Qu’est-ce que Firecrawl et pour qui a-t-il été conçu ?
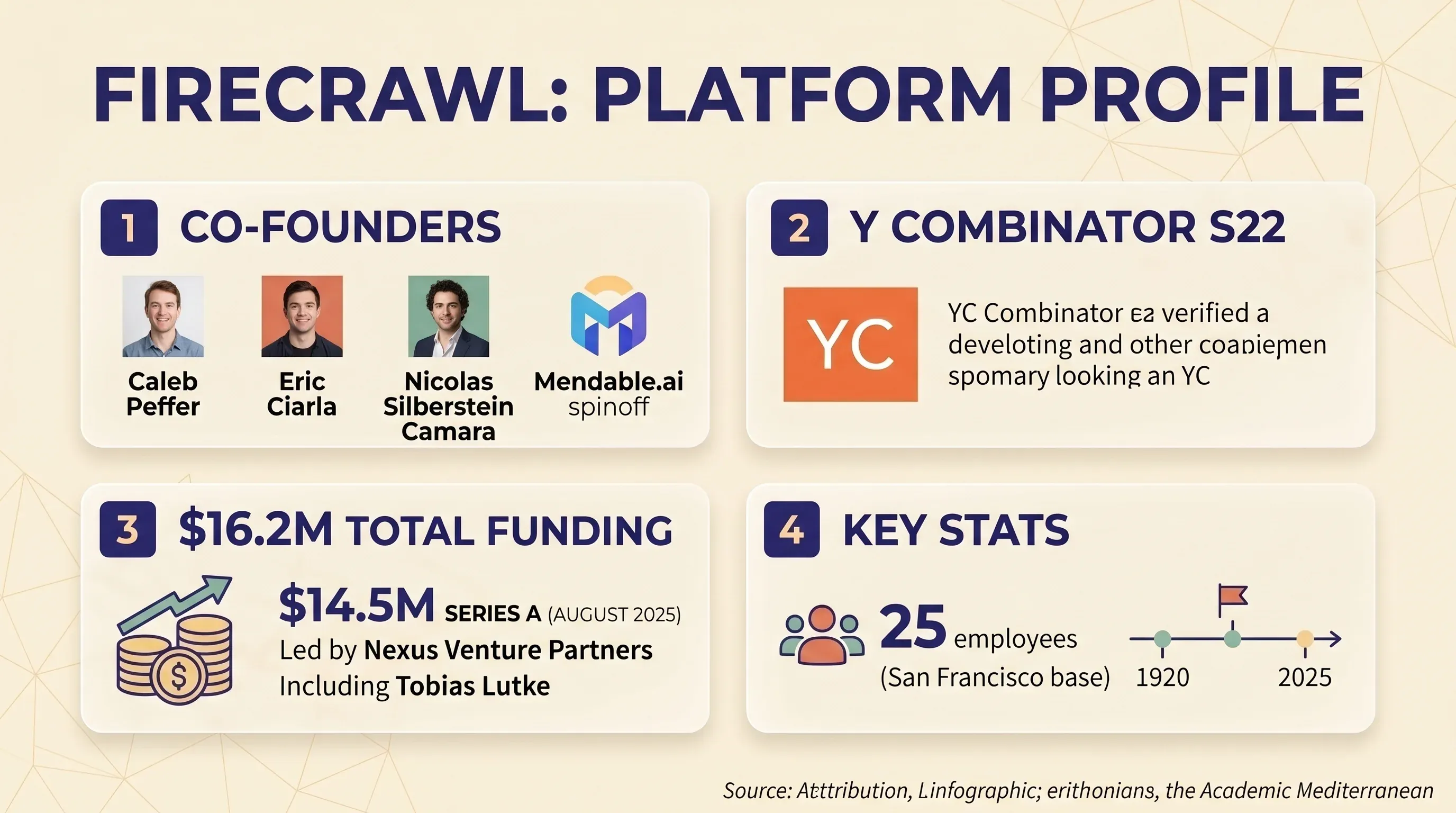
Firecrawl est une plateforme de web scraping et de crawling centrée sur l’API, qui convertit des sites web en Markdown propre ou en JSON structuré. Elle est principalement pensée pour les développeurs qui créent des applications IA et LLM — par exemple des pipelines RAG, des bases de connaissances pour chatbots et des workflows d’agents IA. L’entreprise a été fondée par Caleb Peffer, Eric Ciarla et Nicolas Silberstein Camara comme spin-off de Mendable.ai. Elle est passée par et a levé une en août 2025, menée par Nexus Venture Partners, avec la participation du PDG de Shopify, Tobias Lutke. Financement total : 16,2 M$. L’équipe compte 25 personnes, basée à San Francisco.
Firecrawl propose quatre modes principaux, plus deux ajouts plus récents :
| Mode | Ce qu’il fait |
|---|---|
| Scrape | Convertit une URL unique en Markdown, JSON ou capture d’écran |
| Crawl | Parcourt une URL et toutes ses sous-pages |
| Map | Découvre toutes les URL d’un site en quelques secondes (jusqu’à 100 000 URL) |
| Search | Recherche web avec récupération du contenu complet des pages |
| Extract | Extraction structurée alimentée par l’IA via prompts ou schémas |
| Agent (aperçu de recherche) | Recherche web autonome sans spécifier d’URL |
Je veux être transparent : Firecrawl est un outil pour développeurs. Il nécessite des appels API, des connaissances en code et une configuration technique. Si vous êtes un utilisateur métier qui veut récupérer des données d’un site web sans écrire de code, Firecrawl n’a pas été conçu pour vous (j’y reviendrai plus loin avec des alternatives). En revanche, pour des équipes de dev qui construisent des applications IA, la promesse est séduisante : des données web propres, prêtes pour les LLM, avec un minimum de complexité d’infrastructure.
Avis sur Firecrawl : aperçu des niveaux de tarification
En apparence, la tarification de Firecrawl semble simple. Voici ce qui est indiqué sur :
| Formule | Prix mensuel | Crédits/mois | Concurrence | Prix annuel |
|---|---|---|---|---|
| Free | 0 $ | 500 (une seule fois, pas mensuellement) | 2 | — |
| Hobby | 19 $/mois | 3 000 | 10 | 16 $/mois facturés à l’année |
| Standard | 99 $/mois | 100 000 | 50 | 83 $/mois facturés à l’année |
| Growth | 399 $/mois | 500 000 | 100 | 333 $/mois facturés à l’année |
| Scale | 749 $/mois | 1 000 000 | 1 000 | 599 $/mois facturés à l’année |
Deux choses sautent immédiatement aux yeux. Les 500 crédits de l’offre gratuite sont à usage unique, pas mensuels — un détail que beaucoup d’utilisateurs ne remarquent qu’après les avoir épuisés en une seule session de test. Et ces paliers paraissent simples, mais le coût réel dépend fortement des fonctionnalités que vous utilisez. Le prix affiché n’est en réalité qu’un point de départ. La vraie facture ? C’est ce que traite la section suivante.
Le vrai coût de Firecrawl : calculateur de crédits selon votre cas d’usage
La tarification est de loin le principal sujet de friction chez les vrais utilisateurs de Firecrawl — « c’est sacrément cher », « je devrais être sur l’offre à 99 $/mois pour mon niveau d’usage », et « outrageusement cher » sont de vraies citations de fils Hacker News et Reddit. La raison ? Il existe un système de double facturation que la plupart des avis sur Firecrawl ignorent complètement.
Voici le piège : les forfaits en crédits de Firecrawl couvrent Scrape, Crawl, Map et Search. Mais Extract — l’extraction structurée alimentée par l’IA, l’un des principaux arguments de Firecrawl — fonctionne sur un abonnement à part, basé sur des tokens.
| Formule Extract | Prix mensuel | Tokens/an | Tokens/mois (env.) |
|---|---|---|---|
| Starter | 89 $/mois | 18 M | ~1,5 M |
| Standard | 189 $/mois | 48 M | ~4 M |
| Growth | 389 $/mois | 108 M | ~9 M |
| Pro | 719 $/mois | 192 M | ~16 M |
Ainsi, une startup sur l’offre Standard en crédits (99 $/mois) qui a aussi besoin d’extraction paie 99 $ + 89 $ = 188 $/mois minimum — avant même d’entrer dans les multiplicateurs de crédits. C’est le piège de la double facturation qui surprend les gens.
Multiplicateurs de crédits cachés que la plupart des utilisateurs ne voient pas
Le slogan « 1 crédit par page » est trompeur. Voici le coût réel des fonctionnalités :
| Fonctionnalité | Coût en crédits | Multiplicateur effectif |
|---|---|---|
| Scrape/Crawl basique | 1 crédit/page | 1x |
| Search | 2 crédits/10 résultats | 2x par lot de résultats |
| Extraction JSON (via Scrape) | +4 crédits/page | 5x au total |
| Enhanced Mode | +4 crédits/page | 5x au total |
| JSON + Enhanced Mode | +8 crédits/page | 9x au total |
| Interactions navigateur | 2 crédits/minute | Variable |
| Mode Agent (spark-1-mini) | Dynamique, ~100–500/requête | 100–500x |
| Mode Agent (spark-1-pro) | Dynamique, ~200–1 500+/requête | 200–1 500x |
Et quelques précisions importantes : les crédits ne sont pas reportés d’un mois sur l’autre. Les requêtes échouées consomment quand même des crédits (les utilisateurs signalent 20 à 30 % de pertes sur des sites instables). Le mode Agent n’a aucun estimateur de coût avant exécution — vous définissez un paramètre maxCredits, mais vous êtes en pratique en train de deviner. Les 500 crédits à vie de l’offre gratuite correspondent à environ 56 pages si vous activez l’extraction. Ce n’est pas un essai complet — c’est juste un aperçu.
Tableau d’estimation mensuelle par profil d’utilisateur
| Profil utilisateur | Pages mensuelles | Fonctionnalités utilisées | Consommation estimée de crédits | Coût mensuel estimé |
|---|---|---|---|---|
| Passionné / projet personnel | 500 | Scrape + crawl basiques | ~500 crédits | 19 $/mois (offre Hobby) |
| Passionné + extraction JSON | 500 | Scrape + Extract | ~2 500 crédits + 89 $ Extract | 108 $/mois |
| Startup / application IA | 5 000 | Scrape + Extract + Search | ~30 000 crédits + 89 $ Extract | 188 $/mois (Standard + Extract) |
| Entreprise / pipeline de données | 50 000 | Stack complète + Agent | ~250 000–450 000 crédits + 389 $ Extract | 788–1 138 $/mois |
Un développeur Hacker News payant 190 $/mois a qualifié l’expérience de « chère et à moitié finie » et a remplacé Firecrawl par 2 700 lignes de code Elixir personnalisé. C’est un signal assez fort.
Firecrawl auto-hébergé : ce qui est vraiment gratuit (et ce qui reste réservé au cloud)
« Puis-je simplement auto-héberger Firecrawl gratuitement ? » est l’une des questions les plus fréquentes que je vois. La réponse est : en partie, mais probablement pas dans le sens que vous espérez.
Firecrawl dispose d’un cœur open source (licence AGPL-3.0), mais plusieurs fonctionnalités importantes sont réservées au cloud. Voici le détail définitif :
| Capacité | Auto-hébergé (gratuit) | Cloud (payant) |
|---|---|---|
| Scrape/Crawl basique vers Markdown | ✅ | ✅ |
| Map (découverte d’URL) | ✅ | ✅ |
| Extract alimenté par LLM | ⚠️ (à vous d’apporter vos clés LLM) | ✅ (géré) |
| Mode Agent | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-bot / rotation de proxy (Fire-engine) | ❌ (utilise votre IP statique) | ✅ |
| Traitement par lots | ❌ | ✅ |
| Tableau de bord / analytique | ❌ | ✅ |
| Infrastructure gérée | ❌ (Docker + PostgreSQL + Redis requis) | ✅ |
Fire-engine, le système anti-bot propriétaire de Firecrawl, est . Les utilisateurs en auto-hébergement n’ont aucune capacité anti-bot et doivent fournir leurs propres proxies.
Dans quels cas l’auto-hébergement reste pertinent
L’auto-hébergement fonctionne si vous êtes développeur, que vous voulez un pipeline simple de crawl vers Markdown et que vous êtes à l’aise avec Docker Compose et plus de 5 services. Configuration minimale : 4 Go de RAM, 2 cœurs CPU, plus des clés API LLM pour l’extraction (0,01 à 0,10 $/page) et, si besoin, des services de proxy. Au total, les coûts en auto-hébergement tournent entre 90 et 340 $/mois — ce qui est souvent comparable aux offres cloud à volume modéré.
Pourquoi les utilisateurs sont frustrés par la version auto-hébergée
Les retours réels donnent un tableau assez rude. Plusieurs fils Reddit et GitHub décrivent une version auto-hébergée qui se dégrade avec le temps, à mesure que les fonctionnalités migrent vers le cloud. Un utilisateur a résumé cela sans détour : l’entreprise « essaie de pousser tous les utilisateurs à payer maintenant et à rendre l’auto-hébergement inutile ». La communauté a même créé un fork firecrawl-simple pour répondre à certains points de douleur. Si vous comptez sur l’auto-hébergement comme solution gratuite durable, mieux vaut ajuster vos attentes — c’est une bonne base pour expérimenter, mais pas un substitut au produit cloud payant à grande échelle.
Performance anti-bot de Firecrawl : là où ça marche et là où ça échoue
C’est la partie la plus importante si vous vous demandez : « Firecrawl va-t-il réellement fonctionner sur les sites que je dois scraper ? »
La réponse courte : cela dépend entièrement du niveau de protection de ces sites.
Les chiffres des benchmarks
a testé indépendamment 10 API de web scraping sur 15 sites fortement protégés contre les bots. Résultats de Firecrawl :
| Fournisseur | Taux de réussite (2 req/s) | Taux de réussite (10 req/s) |
|---|---|---|
| Zyte | 93,14 % | 89,2 % |
| ScrapFly | 91,8 % | 88,5 % |
| Bright Data | 88,7 % | 84,9 % |
| Firecrawl | 33,69 % | 26,69 % |
Firecrawl termine des 10 fournisseurs sur les sites protégés. Son temps de réponse rapide (7,92 secondes en moyenne) s’explique en partie par une stratégie de « fail fast » — il renvoie l’échec rapidement plutôt que de réessayer.
Le benchmark continu plus large de attribue à Firecrawl un taux de réussite global de 65,4 % (au-dessus de la moyenne du secteur, 59,5 %), avec de bons résultats sur les cibles faciles mais de mauvais résultats sur les sites protégés.
Répartition par difficulté de site : cibles faciles, modérées et difficiles
| Difficulté | Exemples de sites | Taux de réussite de Firecrawl | Recommandation |
|---|---|---|---|
| Facile | Blogs, documentation, pages SaaS publiques | 85–98 % | Utilisez Firecrawl sans crainte |
| Modérée | Catalogues produits, sites d’actualités avec protection anti-bot basique, Etsy, Realtor.com | 53–65 % | Testez avec prudence, attendez-vous à des échecs |
| Difficile | Amazon, LinkedIn, Instagram, pages très chargées en Cloudflare | 0–33 % | Ne vous appuyez pas sur Firecrawl — utilisez des fournisseurs anti-bot dédiés |
Les sites protégés par Cloudflare sont le principal point de rupture signalé. Plusieurs issues GitHub documentent le problème : la détection par empreinte de Cloudflare bloque Firecrawl même lorsque la rotation d’IP est utilisée. Les utilisateurs en auto-hébergement sont les plus touchés, car ils n’ont pas l’infrastructure proxy de Fire-engine.
Que faire quand Firecrawl ne suffit pas
Pour les sites très protégés, les utilisateurs se tournent généralement vers des services de proxy dédiés comme ScrapFly ou Bright Data, ou vers des outils de navigateur headless avec des configurations d’évasion personnalisées. Si vous êtes un utilisateur métier et que vous ne voulez pas gérer la rotation de proxies ni les calculs de taux de réussite, des outils no-code comme s’occupent des problèmes anti-bot en arrière-plan — vous cliquez et vous obtenez vos données.
Avantages et inconvénients de Firecrawl : un résumé honnête
Ce que Firecrawl fait bien
- Sortie Markdown propre, prête pour les LLM — toujours bien formatée, avec une structure de titres correcte. C’est vraiment le point fort de Firecrawl.
- Aucune surcharge d’infrastructure pour les utilisateurs cloud — pas de configuration navigateur, pas de gestion de proxy, pas de paramétrage de navigateur headless.
- Large intégration avec les frameworks — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (plus de 7 intégrations pour les pipelines IA).
- Découverte rapide d’URL via le point de terminaison Map — 2 à 3 secondes pour un sitemap complet.
- Noyau open source avec — transparence et contributions de la communauté.
- Prise en charge d’un serveur MCP avec le modèle FIRE-1 pour les workflows d’agents IA.
- sur les pages riches en JavaScript (SPA React, Vue, Angular).
Là où Firecrawl déçoit
- Tarification double (crédits + abonnement Extract séparé) qui crée des surprises de facturation inattendues.
- Multiplicateurs de crédits qui font grimper les coûts réels de 5 à 9 fois au-dessus du prix affiché.
- Performance anti-bot : dernier du classement dans le benchmark Proxyway ( contre 93,14 % pour le meilleur).
- Le mode Agent consomme des crédits de manière imprévisible, sans estimateur avant exécution.
- Les requêtes échouées consomment quand même des crédits — 20 à 30 % de gaspillage sur les sites instables.
- La version auto-hébergée n’inclut pas Agent, Browser Sandbox, l’anti-bot Fire-engine ni le tableau de bord.
- Aucune résolution native des CAPTCHA — un manque important face à Bright Data et Zyte.
- Inaccessible aux utilisateurs non techniques — nécessite des compétences en code et en API.
- Les 500 crédits de l’offre gratuite sont à vie, pas mensuels — insuffisant pour des tests significatifs.
Au-delà des outils pour développeurs : des alternatives no-code que les avis sur Firecrawl n’évoquent jamais
Chaque avis sur Firecrawl que j’ai lu le compare exclusivement à d’autres outils pour développeurs — Crawl4AI, Scrapy, Playwright, Apify. Cela a du sens si vous êtes développeur. Mais une grande partie des personnes qui cherchent des solutions de web scraping ne sont pas développeuses : équipes commerciales qui construisent des listes de prospects, équipes e-commerce qui surveillent les prix des concurrents, marketeurs qui collectent des données de contenu, agents immobiliers qui suivent les annonces.
C’est un manque qu’il vaut la peine de combler.
Tableau comparatif des alternatives à Firecrawl
| Outil | Idéal pour | Code requis ? | Sortie prête pour les LLM | Prix de départ |
|---|---|---|---|---|
| Firecrawl | Développeurs créant des apps IA | Oui (API) | ✅ Markdown/JSON | 19 $/mois |
| Crawl4AI | Développeurs voulant du gratuit / OSS | Oui (Python) | ✅ Markdown | Gratuit |
| Apify | Développeurs ayant besoin d’échelle + marketplace | Oui (SDK) | ⚠️ Avec configuration | 39 $/mois |
| Thunderbit | Utilisateurs métier (no-code) | Non (extension Chrome) | ✅ Données structurées | Offre gratuite disponible |
| ScrapingBee | Développeurs ayant besoin d’un proxy | Oui (API) | ❌ HTML brut | 49 $/mois |
| Bright Data | Équipes data en entreprise | Oui (API/SDK) | ⚠️ Avec configuration | 500 $+/mois |
Pourquoi Thunderbit est la solution de référence pour les équipes non techniques
Je travaille chez Thunderbit, donc je préfère être transparent à ce sujet. Thunderbit a toute sa place dans cette comparaison parce qu’il résout un problème différent de Firecrawl, pour un public différent, sans exiger la moindre ligne de code.
Le workflow de Thunderbit se fait en deux clics : ouvrez , cliquez sur « Suggestion de champs par l’IA », puis sur « Scraper ». L’IA lit la page, propose les bonnes colonnes et extrait les données structurées dans un tableau. Pas de clés API, pas de sélecteurs, pas de code. Vous pouvez exporter gratuitement vers Excel, Google Sheets, Airtable ou Notion.
Différenciateurs clés pour les utilisateurs métier :
- Enrichissement des sous-pages — cliquez dans les pages de détail et récupérez automatiquement des champs supplémentaires
- IA qui s’adapte aux changements de mise en page — aucune maintenance quand un site change de design
- Étiquetage et traduction des données intégrés — utile pour les jeux de données multilingues
- Modèles instantanés pour les sites populaires (Amazon, Zillow, LinkedIn, etc.)
Pour les développeurs qui veulent une alternative en API, Thunderbit propose aussi des avec une tarification plus simple que le système double crédits/tokens de Firecrawl. Cela ne remplacera pas Firecrawl pour les développeurs de pipelines LLM. Mais pour les équipes commerciales, e-commerce, marketing et opérations qui ont besoin de données structurées sans écrire de code, c’est la voie la plus rapide et la moins chère.
Construire ou acheter : quand Firecrawl est rentable pour vous (et quand il ne l’est pas)
« J’ai pensé écrire mon propre scraper web… plus simple que Firecrawl, mais au moins moins cher. » Plusieurs utilisateurs soulèvent ce point. Plutôt qu’un avis subjectif, voici un cadre de décision structuré.
Tableau du cadre de décision
| Facteur | Construire sur mesure (Scrapy/Playwright) | Acheter Firecrawl Cloud | Utiliser Thunderbit (no-code) |
|---|---|---|---|
| Temps de mise en place | 10–40+ heures | ~30 minutes | ~5 minutes |
| Maintenance continue | Élevée (les sélecteurs cassent) | Quasi nulle (géré) | Nulle (l’IA s’adapte) |
| Gestion anti-bot | Manuelle (proxy, en-têtes, retries) | Intégrée (partielle — faible sur les sites protégés) | Intégrée (modes navigateur + cloud) |
| Coût à 1 000 pages/mois | 50–150 $ (serveur + proxy) | 19–108 $ (selon les fonctionnalités) | 0–15 $ |
| Coût à 50 000 pages/mois | 500–1 500 $ (infra) | 399–1 138 $ | 39–249 $ |
| Sortie prête pour les LLM | Code personnalisé requis | Intégrée (Markdown/JSON) | Tableaux structurés (exportables) |
| Idéal pour | Contrôle total, sites de niche, équipes DevOps | Développeurs IA/LLM, pipelines RAG | Ventes, e-commerce, marketing, opérations |
Le développement sur mesure revient que les API sur trois ans pour la plupart des organisations. Le point de bascule à partir duquel la solution maison devient moins chère est d’environ 10 millions de pages par mois — une échelle que très peu d’équipes atteignent réellement.
Verdict honnête : quelle voie vous convient ?
Firecrawl devient rentable quand :
- Votre équipe code déjà en Python/JS et a besoin de Markdown propre pour des pipelines LLM/RAG
- Vous ciblez surtout des sites peu ou pas protégés
- Vous voulez une infrastructure gérée sans surcharge DevOps
- Votre volume reste en dessous d’environ 50 000 pages/mois
Firecrawl ne devient pas rentable quand :
- Vous êtes un utilisateur métier qui fait des extractions sans équipe de dev → Thunderbit est plus simple et plus rapide
- Vous ciblez des sites fortement protégés (Amazon, LinkedIn, forte présence Cloudflare) → Bright Data ou Zyte
- Vous avez besoin d’une facturation prévisible à grande échelle → les multiplicateurs de crédits rendent les coûts imprévisibles
- Vous voulez auto-héberger avec toutes les fonctionnalités → Agent, Browser Sandbox, Fire-engine sont réservés au cloud
Construire sur mesure n’a de sens que lorsque :
- Votre équipe dispose d’une capacité DevOps dédiée
- Vous êtes à très grande échelle (10 M+ pages/mois)
- Vous avez besoin d’un contrôle total sur des sites de niche ou atypiques
- Vous êtes à l’aise avec la maintenance continue des sélecteurs
Avis sur Firecrawl : tableau comparatif côte à côte
Voici tout en un coup d’œil :
| Outil | Type | Idéal pour | Code requis | Gestion anti-bot | Sortie prête pour les LLM | Option d’auto-hébergement | Prix de départ |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | Développeurs IA/LLM | Oui | Faible sur les sites protégés | ✅ Markdown/JSON | ✅ (limitée) | 19 $/mois |
| Crawl4AI | Bibliothèque Python | Développeurs OSS-first | Oui | Aucune (fait maison) | ✅ Markdown | ✅ | Gratuit |
| Apify | Plateforme cloud | Échelle + marketplace | Oui | Modérée | ⚠️ Avec configuration | ✅ | 39 $/mois |
| Thunderbit | Extension Chrome + API | Utilisateurs métier, no-code | Non | Intégrée | ✅ Données structurées | ❌ | Offre gratuite |
| ScrapingBee | API | Développeurs orientés proxy | Oui | Solide | ❌ HTML brut | ❌ | 49 $/mois |
| Bright Data | API + réseau de proxies | Équipes data en entreprise | Oui | La meilleure (~99,9 %) | ⚠️ Avec configuration | ❌ | 500 $+/mois |
Verdict final : Firecrawl en vaut-il la peine ?
Firecrawl est un bon outil pour un cas d’usage précis : des équipes de développement qui construisent des applications LLM, des pipelines RAG ou des agents IA et qui ont besoin de données web propres à une échelle modérée, tout en étant à l’aise avec des workflows basés sur l’API. La qualité de la sortie Markdown est réellement parmi les meilleures du marché, et les intégrations avec les frameworks (LangChain, LlamaIndex, CrewAI) sont matures. Si votre équipe vit déjà dans Python ou JavaScript et que les sites ciblés ne sont pas fortement protégés contre les bots, Firecrawl peut vous faire gagner un vrai temps d’ingénierie.
Les inconvénients sont bien réels, cependant. Le système de tarification double (crédits + abonnement Extract séparé) crée de vraies surprises de facturation. Le sur les sites protégés signifie que vous ne pouvez pas compter sur Firecrawl pour Amazon, LinkedIn ou des cibles très chargées en Cloudflare. La version auto-hébergée manque de trop de fonctionnalités pour constituer une véritable alternative gratuite. Et si vous êtes un utilisateur non technique — quelqu’un en vente, e-commerce ou marketing — Firecrawl n’a tout simplement pas été conçu pour vous.
Testez les 500 crédits gratuits de Firecrawl pour voir si la qualité de sortie convient à votre pipeline. Mais modélisez vos vrais coûts mensuels avec le calculateur ci-dessus avant de vous engager sur une offre payante. Si vous êtes un utilisateur métier et que vous avez juste besoin de données structurées à partir de sites web sans écrire de code, commencez plutôt par — vous extrairez des données en quelques minutes, pas en plusieurs heures. Vous pouvez essayer dès maintenant, ou consulter pour voir ce qui convient à votre équipe à grande échelle. Pour des démonstrations vidéo, propose des tutoriels pas à pas.
FAQ
Combien coûte Firecrawl par page scrapée ?
Un scrape ou un crawl basique coûte 1 crédit par page. L’extraction JSON ajoute 4 crédits/page (5 au total). Le Enhanced Mode ajoute encore 4 crédits (jusqu’à 9 au total). Search coûte 2 crédits pour 10 résultats, et le mode Agent peut consommer de 100 à 1 500+ crédits par requête. En plus, la fonctionnalité Extract nécessite un abonnement séparé à partir de 89 $/mois. Consultez la section sur le calcul des coûts ci-dessus pour des estimations réalistes selon le profil d’utilisateur.
Peut-on auto-héberger Firecrawl gratuitement ?
Oui, le cœur open source (AGPL-3.0) est gratuit à auto-héberger. Mais vous perdez le mode Agent, le Browser Sandbox, l’anti-bot/la rotation de proxy (Fire-engine est fermé), le traitement par lots et le tableau de bord de gestion. Vous devez apporter vos propres clés LLM pour l’extraction et gérer vous-même Docker, PostgreSQL et Redis. L’auto-hébergement convient pour des pipelines simples de crawl vers Markdown, mais ce n’est pas un substitut au produit cloud à l’échelle de production.
Firecrawl est-il adapté au scraping d’Amazon, LinkedIn ou d’autres sites protégés ?
Le montre que Firecrawl atteint un taux de réussite de 33,69 % sur les sites fortement protégés contre les bots — dernier des 10 fournisseurs testés. Il fonctionne bien sur les pages non protégées (blogs, docs, sites SaaS — 85 à 98 % de réussite), mais n’est pas fiable pour les grandes plateformes e-commerce ou sociales. Pour ces cibles, privilégiez des fournisseurs anti-bot dédiés comme Bright Data ou Zyte, ou des outils no-code comme Thunderbit qui gèrent l’anti-bot en arrière-plan.
Quelle est la meilleure alternative à Firecrawl pour les utilisateurs non techniques ?
est la meilleure alternative no-code. C’est une extension Chrome où vous cliquez sur « Suggestion de champs par l’IA » puis sur « Scraper » — pas d’appels API, pas de code, pas de sélecteurs. Les données s’exportent gratuitement vers Excel, Google Sheets, Airtable ou Notion. Elle est conçue pour les équipes commerciales, e-commerce, marketing et opérations qui ont besoin de données web structurées sans développeur.
Firecrawl propose-t-il un essai gratuit ?
Firecrawl offre sans carte bancaire. Cela suffit pour tester les fonctions de base Scrape/Crawl sur quelques pages, mais pas pour une utilisation en production — surtout si vous activez l’extraction (qui consomme 5 crédits par page). Les crédits ne sont pas renouvelés chaque mois sur l’offre gratuite.
En savoir plus