

Interrogez un commercial, un marketeur ou un responsable des opérations sur la récupération de données depuis un site web : tous vous diront que cela ne devrait pas mobiliser plusieurs journées. Dans les faits, c'en est pourtant souvent une. Qui n'a jamais eu sous les yeux une page débordant de noms, de tarifs ou d'adresses e-mail, en cherchant simplement le moyen de tout verser dans un tableur ? Cette frustration est largement partagée, et une même question revient dans presque toutes les discussions avec ces équipes : pourquoi une opération aussi banale reste-t-elle aussi laborieuse ?
Répondre à cette question, c'est déjà cerner ce que désigne l'« easy web extract » : sortir des données utiles du web en quelques minutes, sans réserver l'exercice aux seuls développeurs. Et le besoin ne cesse de croître. Selon l'état de l'IA 2025 de McKinsey, 71 % des organisations utilisent désormais l'IA générative dans au moins une fonction métier, contre 65 % début 2024, l'extraction de données web figurant parmi les usages les plus réclamés. Côté marché, le web scraping devrait représenter 1,17 milliard de dollars en 2026 (environ 1,08 milliard d'euros) et grimper jusqu'à 2,23 milliards d'ici 2031. Les profils non techniques, en particulier, attendent des outils qui rendent l'extraction aussi immédiate qu'un copier-coller. Reste à voir ce que cette promesse signifie concrètement.
Essayez Easy Web Extract avec Thunderbit (gratuit)
L'easy web extract pour les non-techniciens : ni code, ni configuration
Que recouvre au juste l'« easy web extract » ? L'idée se résume à une opération : convertir un web foisonnant et instable en tableaux propres et structurés, sans rédiger une seule ligne de code. Pour une équipe métier dépourvue de compétences techniques, la différence est de taille. Plus de ticket adressé au service informatique, plus de script Python à apprivoiser, plus de découragement lorsqu'un site refond sa mise en page du jour au lendemain.
Pourquoi le sujet prend-il autant d'ampleur maintenant ? Parce que le web n'a jamais été aussi mouvant. Défilement infini, fenêtres surgissantes, JavaScript touffu : chacun de ces éléments met en échec les extracteurs classiques. Dans le même temps, l'exigence de livrer des analyses vite n'a jamais été aussi forte. Du côté du commerce de détail et de l'e-commerce, 98 % des organisations jugent les données web publiques cruciales ou très importantes pour leurs opérations, et plus de la moitié les mobilisent chaque jour.
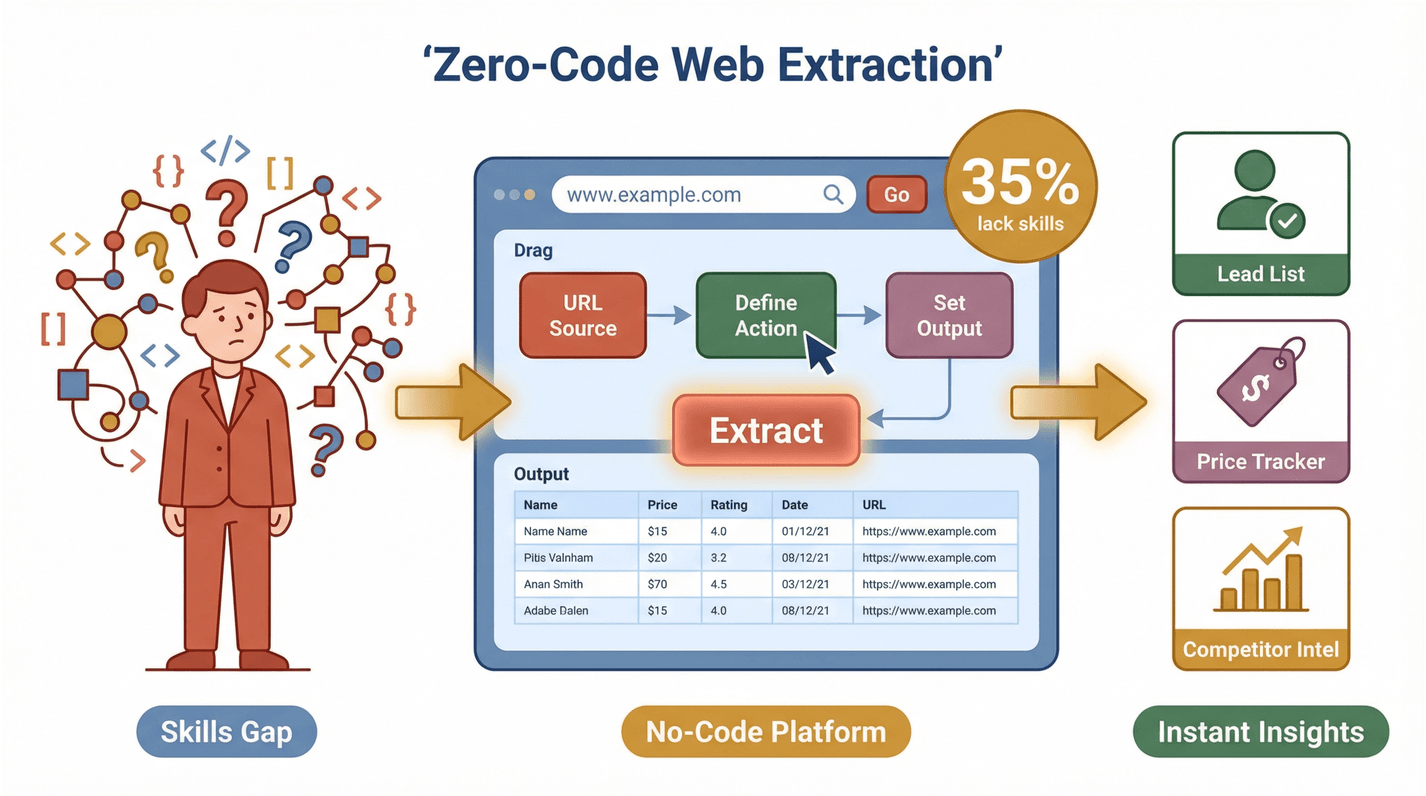
Or ces équipes sont rarement techniques, et c'est là tout l'enjeu. Une enquête récente indique que 35 % des organisations manquent des compétences nécessaires pour l'extraction de données web et que 33 % n'ont pas les bons outils. Le terrain est donc idéal pour les solutions sans code. Dès lors que chacun peut extraire et exploiter des données web, un palier de productivité se franchit — qu'il s'agisse de constituer une liste de prospects, de surveiller la concurrence ou de suivre les prix du marché.
Le mouvement no-code/low-code : de quoi parle-t-on réellement
L'essor des outils no-code et low-code répond à un objectif net : mettre la technologie à la portée de tous. On dépasse largement l'effet de mode : c'est la manière même de travailler qui se transforme. Rapporté au web scraping, cela se concrétise par quatre gains :
- Aucun code requis : l'extraction cesse d'être le domaine réservé des ingénieurs.
- Rapidité : des résultats en quelques minutes plutôt qu'en plusieurs jours.
- Souplesse : une adaptation immédiate à de nouveaux sites comme à de nouveaux besoins.
- Moins d'erreurs : l'automatisation supprime les fautes de recopie.
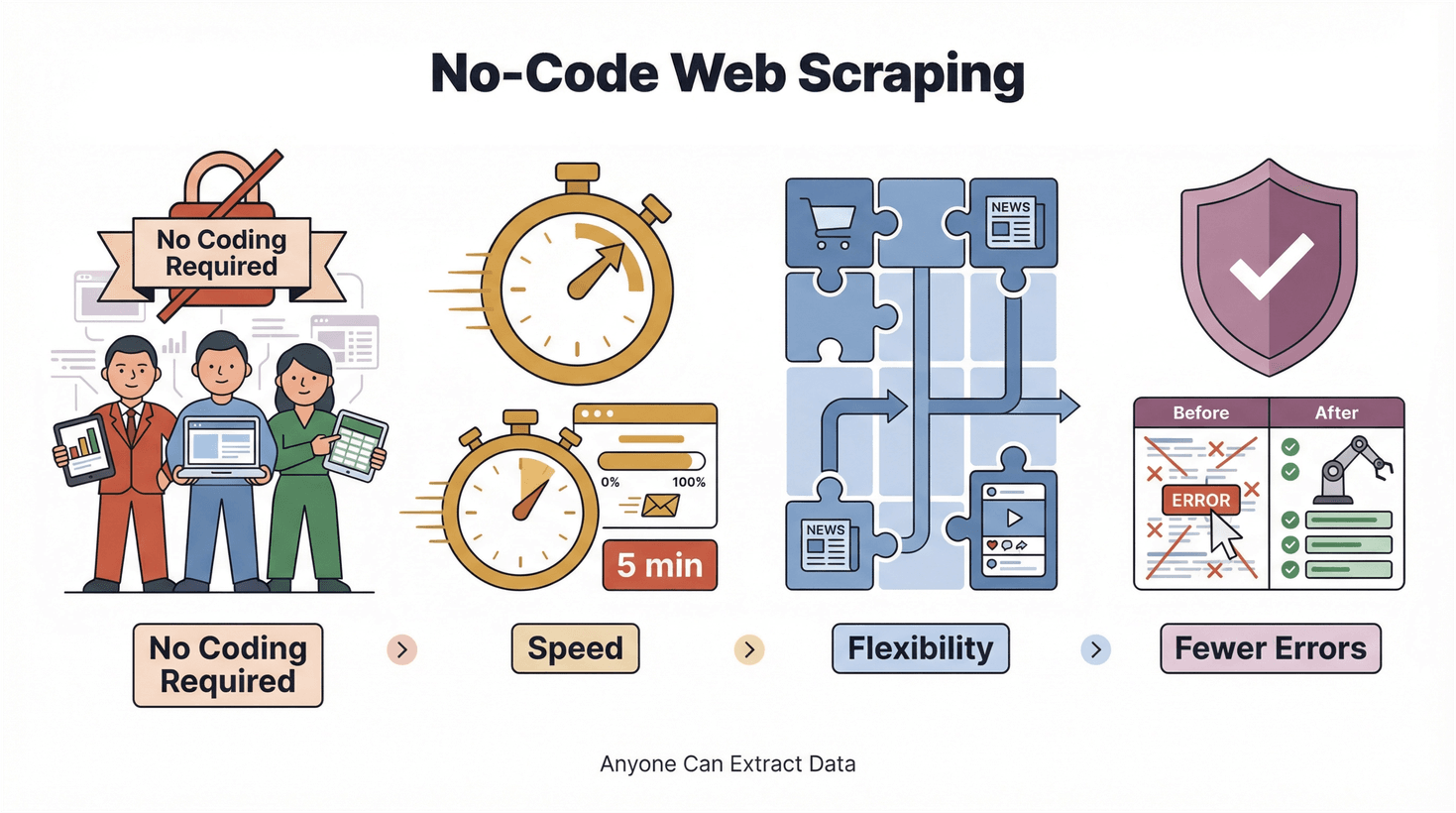
Et l'essentiel tient en peu de mots : nul besoin d'expertise technique pour en tirer parti.
Pourquoi les outils de web scraping classiques rebutent autant
Autant l'admettre : les outils de web scraping traditionnels donnent l'impression d'avoir été conçus par des développeurs pour des développeurs, jamais pour des utilisateurs métier. Le scénario se répète à l'identique : une équipe s'enthousiasme pour un projet, puis bute sur le premier mur venu dès que l'outil réclame des sélecteurs CSS, du XPath ou des expressions régulières. Viennent alors les regards perplexes et les messages du type « on reverra ça au prochain trimestre ».
Les obstacles les plus fréquents sont connus :
- Code obligatoire : la plupart des outils historiques imposent d'écrire des scripts ou de régler des modèles complexes.
- Configuration laborieuse : il faut cartographier chaque champ, gérer les connexions et installer des proxys pour éviter les blocages.
- Logique fragile : un site change de mise en page et l'extracteur cède aussitôt. Vous voilà à déboguer du code au lieu de traiter votre vrai sujet.
- Maintenance sans fin : chaque mise à jour d'un site remet l'ouvrage sur le métier.
Rien d'étonnant, dès lors, à ce que le manque de compétences aille de pair avec le manque d'outils : l'enquête 2024 de Bright Data relève que 35 % des organisations n'ont pas les bonnes compétences et 33 % pas les bons outils pour exploiter les données web publiques. Même les équipes aguerries doivent composer, en prime, avec les bannissements d'IP, le contenu dynamique et les CAPTCHA.
Pendant ce temps, la demande côté métier reste simple : alimenter tableurs et CRM sans effort et de façon fiable. C'est précisément l'espace qu'occupent l'easy web extract et les méthodes d'extraction sans friction.
Comment Thunderbit concrétise l'easy web extract
Extrayez des données de n'importe quel site avec l'IA Get Started Free
C'est ce problème que nous avons entrepris de résoudre chez Thunderbit, et c'est ce qui nous anime le plus. L'ambition : rendre le web scraping assez simple pour que chacun s'en serve, quel que soit son niveau technique.
Thunderbit est une extension Chrome AI Web Scraper qui ramène l'extraction web à deux clics. Le principe tient en trois étapes :
- Décrivez votre besoin : en langage naturel, précisez à Thunderbit les données visées. Par exemple : « Extraire tous les noms de produits et leurs prix sur cette page. »
- Cliquez sur « AI Suggest Fields » : l'IA de Thunderbit lit la page et propose les colonnes à extraire, du type « Nom », « Prix », « E-mail » ou « Image ».
- Cliquez sur « Scrape » : Thunderbit prend le relais — pagination, sous-pages, et même contenu protégé par connexion si besoin.
C'est tout. Aucun code, aucun modèle, aucune configuration interminable. L'interface vise directement les utilisateurs métier — vente, marketing, e-commerce, immobilier — qui cherchent avant tout des résultats.
Le workflow piloté par l'IA : plus intelligent, pas plus exigeant
Tout repose sur l'IA. Thunderbit ne devine pas simplement votre intention : il lit la page, en saisit le contexte et structure les données de lui-même. Vous pouvez affiner en ajoutant des instructions par champ (par exemple « catégoriser cette colonne » ou « traduire en anglais »), mais la plupart des utilisateurs se contentent d'un clic avant de lancer l'extraction.
Cette logique pilotée par l'IA se traduit par trois bénéfices concrets :
- Moins d'erreurs : l'IA s'ajuste aux mises en page variées, pour des résultats cohérents même quand un site évolue.
- Une mise en place plus rapide : ni modèle à bâtir, ni script à écrire.
- Des données directement exploitables : Thunderbit étiquette, catégorise et enrichit les données au moment même de l'extraction.
Pour aller plus loin, consultez la documentation de Thunderbit ou notre article sur l'extraction automatisée de données. Le blog Thunderbit propose d'autres guides, comme Comment extraire n'importe quel site avec l'IA et Qu'est-ce que le data scraping et comment le faire en 2025.
Les fonctionnalités qui rendent l'extraction sans friction
Ce qui distingue Thunderbit ne se limite pas à l'IA : c'est le workflow entier, calibré pour de vrais besoins métier. Voici les fonctions les plus appréciées de nos utilisateurs :
- Pagination automatique : Thunderbit gère les sites multi-pages et le défilement infini sans configuration.
- Extraction de sous-pages : besoin de détails supplémentaires ? Thunderbit ouvre chaque sous-page (fiches produit, profils LinkedIn) et complète le jeu de données de lui-même.
- Export partout : vers Excel, Google Sheets, Airtable ou Notion, ou en téléchargement CSV/JSON. Fini les longues séances de recopie.
- Compatible avec les pages protégées : l'extraction fonctionne sur les sites qui exigent une authentification, puisque Thunderbit tourne dans votre navigateur et voit ce que vous voyez.
- Étiquetage et catégorisation assistés par l'IA : ajoutez des instructions pour classer, taguer ou traduire les données en cours d'extraction.
- Extraction planifiée : programmez des tâches récurrentes pour maintenir vos données à jour — parfait pour la veille tarifaire ou le suivi de prospects.
Le tout dans un outil adopté par plus de 100 000 utilisateurs à travers le monde.
Pagination automatique et sous-pages
La gestion des listes paginées et des pages de détail imbriquées reste l'un des grands points noirs du web scraping. Avec Thunderbit, la difficulté disparaît. L'IA repère la pagination — bouton « Suivant » ou défilement infini — et suit d'elle-même les liens vers les sous-pages. Vous extrayez ainsi des centaines, voire des milliers d'enregistrements en une passe, sans clic manuel.
Prenons une liste de produits sur Amazon : Thunderbit récupère l'ensemble des articles répartis sur plusieurs pages, puis ouvre chaque fiche pour en tirer avis, notes ou données vendeur. Un assistant qui ne se fatigue jamais.
Export multiformat et intégration CRM
Une donnée ne vaut que par son exploitation possible. Thunderbit exporte vos résultats dans le format attendu par votre équipe — Excel, Google Sheets, Airtable, Notion ou CSV/JSON. Vous pouvez aussi les acheminer directement vers votre CRM ou vos outils de workflow, pour que les équipes commerciales et opérationnelles disposent toujours de données à jour.
Cette intégration directe fait gagner un temps réel. Plus besoin de nettoyer des exports brouillons ni de reformater des colonnes : l'IA de Thunderbit s'en charge.
L'easy web extract sur le terrain
Où l'easy web extract change-t-il le plus la donne ? Voici quelques situations bien concrètes, relevées chez les utilisateurs de Thunderbit :
Constituer des listes de prospects
Les équipes commerciales dépendent étroitement de leurs listes de prospects. Thunderbit permet d'extraire en quelques minutes des coordonnées depuis LinkedIn, Google Maps ou des annuaires professionnels. Ouvrez la page, cliquez sur « AI Suggest Fields », et laissez Thunderbit réunir noms, e-mails, numéros et informations d'entreprise dans un tableur immédiatement exploitable.
Un responsable commercial témoignait : ses équipes passaient auparavant des heures chaque semaine à recopier des coordonnées pour bâtir leurs listes. Aujourd'hui, elles montent des listes ciblées en une fraction de ce temps et se recentrent sur la prospection plutôt que sur la saisie.
E-commerce et veille marché
Les équipes e-commerce s'appuient sur Thunderbit pour suivre références, prix et avis des concurrents sur Amazon, Shopify et d'autres plateformes. Besoin de surveiller les variations de prix ou les lancements ? Mettez en place une extraction planifiée et recevez chaque matin des données fraîches dans votre Google Sheet.
L'extraction de sous-pages se montre ici particulièrement précieuse : détails produit, images et avis clients arrivent sans intervention manuelle.
Collecter des données immobilières
Les professionnels de l'immobilier recourent à Thunderbit pour rassembler annonces, prix et coordonnées d'agents depuis des sites comme Zillow ou Realtor.com. L'IA prend en charge pagination et sous-pages, offrant une vue complète et actualisée du marché — idéale pour l'analyse comme pour les rapports clients.
Un analyste immobilier expliquait qu'une tâche qui lui prenait tout un après-midi se règle désormais en quelques clics. C'est là que réside l'intérêt d'une extraction sans friction.
Méthodes classiques ou extraction sans friction : le face-à-face
Plaçons les deux approches côte à côte :
| Fonctionnalité | Extracteurs traditionnels | Easy Web Extract (Thunderbit) |
|---|---|---|
| Codage requis | Oui (scripts, sélecteurs) | Non (IA + langage naturel) |
| Temps de configuration | Élevé (modèles, config) | Faible (2 clics) |
| Maintenance | Fréquente (cassures lors des changements de site) | Minimale (l'IA s'adapte) |
| Gestion de la pagination | Configuration manuelle | Automatique |
| Extraction des sous-pages | Logique complexe | 1 clic |
| Formats d'export | Souvent limités | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Fonctionne sur les pages avec connexion | Parfois (avec configuration) | Oui (basé sur le navigateur) |
| Étiquetage/catégorisation des données | Post-traitement manuel | Intégré, piloté par l'IA |
| Planification/suivi | Parfois (avancé) | Oui (configuration simple) |
L'écart est manifeste. Avec Thunderbit, extraire, organiser et exploiter des données web devient accessible sans la moindre compétence technique.
Ce qui attend l'easy web extract et l'extraction sans friction
Les perspectives sont encourageantes. L'IA gagne en finesse et la demande d'outils sans code progresse rapidement. Selon l'état de l'IA 2025 de McKinsey, 88 % des organisations utilisent désormais régulièrement l'IA dans au moins une fonction, contre 78 % un an plus tôt, tandis que les systèmes agentiques — des IA capables de conduire des workflows web en plusieurs étapes — se développent fortement.
Qu'est-ce que cela change côté métier ? Plus de capacité, moins de friction. À mesure que l'IA mûrit, quatre évolutions se dessinent :
- Une détection des champs plus fine : l'IA appréhendera des données et des relations plus complexes.
- De meilleures intégrations : des connexions directes vers davantage d'outils et de plateformes métier.
- Une fiabilité renforcée : moins de pannes, des résultats plus stables, y compris sur des sites dynamiques ou protégés.
- Une accessibilité élargie : l'extraction web deviendra une compétence courante, et non l'apanage des techniciens.
Thunderbit entend rester en tête de ce mouvement.
Conclusion et points clés
Voir les formules et les crédits Thunderbit Get Started Free
Le web demeure la plus vaste base de données au monde — mais, jusqu'à récemment, seuls les développeurs savaient vraiment l'exploiter. Cette période s'achève. Grâce à l'easy web extract et aux méthodes d'extraction sans friction, chacun peut transformer un site en données exploitables en quelques minutes.
Voici ce que je retiens, et ce que vous retiendrez probablement aussi :
- L'extraction web sans code s'installe durablement : des outils comme Thunderbit ouvrent la collecte et l'exploitation des données web à tous, sans compétence technique.
- L'IA est l'ingrédient décisif : en automatisant la sélection des champs, la pagination, les sous-pages et l'étiquetage, les extracteurs alimentés par l'IA font gagner du temps et réduisent les erreurs.
- L'impact métier est mesurable : les équipes commerciales, e-commerce et immobilières constatent déjà des gains de productivité, des données plus fraîches et de meilleures décisions.
- La suite s'annonce plus prometteuse encore : avec la maturité de l'IA et du no-code, l'extraction de données web deviendra aussi ordinaire que l'envoi d'un e-mail.
Si la recopie manuelle vous épuise, si les extracteurs cassés vous exaspèrent ou si vous voulez simplement mesurer le champ des possibles, essayez Thunderbit. Vous pouvez télécharger l'extension Chrome et commencer à extraire gratuitement — sans configuration, sans code, sans complication.
Et pour prolonger, rendez-vous sur le blog Thunderbit, riche en guides, en conseils et en exemples concrets.
FAQ
1. Qu'est-ce que l'« easy web extract » et à qui cela s'adresse-t-il ?
L'easy web extract regroupe des méthodes d'extraction web sans code, alimentées par l'IA, qui permettent à quiconque — et d'abord aux utilisateurs métier non techniques — d'extraire vite et sans peine des données structurées depuis des sites web. C'est tout indiqué pour les équipes commerciales, marketing, e-commerce et opérations qui ont besoin de données exploitables sans barrière technique.
2. En quoi Thunderbit se distingue-t-il des outils de web scraping traditionnels ?
Thunderbit s'appuie sur l'IA pour automatiser la sélection des champs, la pagination et l'extraction des sous-pages. Là où les extracteurs classiques réclament du code ou des modèles compliqués, Thunderbit vous laisse décrire votre besoin en langage clair et extraire vos données en deux clics.
3. Thunderbit gère-t-il les sites dynamiques ou multi-pages ?
Oui. Thunderbit détecte et gère automatiquement la pagination, défilement infini compris, et suit les liens vers les sous-pages pour une extraction plus complète — avec une configuration minimale.
4. Quelles options d'export Thunderbit propose-t-il ?
Thunderbit exporte vos données directement vers Excel, Google Sheets, Airtable, Notion, CSV ou JSON. Vous pouvez également l'intégrer à des CRM et à d'autres outils de workflow pour fluidifier vos processus métier.
5. Est-il sûr et éthique d'utiliser des outils comme Thunderbit pour l'easy web extract ?
Thunderbit encourage une pratique responsable et éthique du web scraping. Respectez toujours les conditions d'utilisation des sites, évitez d'extraire des données personnelles sans consentement et modérez votre cadence de requêtes pour ne pas perturber le service. Pour approfondir les bonnes pratiques, consultez le guide de Thunderbit sur le web scraping.
Prêt à exploiter la puissance des données web ? Essayez Thunderbit dès aujourd'hui et mesurez à quel point l'easy web extract peut changer votre quotidien.
Essayez Thunderbit pour Easy Web Extract
Essayez Thunderbit AI Web Scraper Get Started Free
En savoir plus




