On entend partout parler de décisions guidées par la donnée, mais on oublie souvent à quel point la collecte de données peut être longue et pénible. Si tu as déjà essayé de rassembler des infos à la main, tu sais à quel point ça peut vite devenir décourageant. J’ai vu pas mal d’entreprises galérer à lancer leur stratégie data, tout simplement parce que leurs méthodes de collecte n’étaient pas efficaces. Si tu te reconnais là-dedans, cet article va vraiment t’apporter des solutions concrètes.
💡 Dans cet article, on va plonger dans l’univers du data scraping et voir comment il évolue avec les nouvelles technos. On va parler des limites des méthodes classiques, des avantages du data scraping boosté à l’IA, et je te donnerai des astuces pratiques pour l’utiliser au quotidien.
C’est quoi le Data Scraping ?
Le data scraping, ou , c’est le fait d’extraire automatiquement des infos structurées depuis des pages web grâce à des outils spécialisés (souvent sous forme de tableaux). C’est une méthode ultra-efficace pour récupérer rapidement de gros volumes de données. Par exemple, tu peux choper des infos publiques sur pour générer des leads, extraire des références produits sur pour la revente ou l’analyse de marché, ou encore collecter des avis clients sur pour mieux comprendre ta clientèle.
L’évolution technologique du Data Scraping
Avant, la collecte de données, c’était réservé aux pros de la tech (ou alors il fallait s’armer de patience pour faire du copier-coller à la main). Mais en 2025, l’IA a tout changé. Le data scraping n’est plus réservé aux développeurs ou à l’automatisation basique.
Les méthodes classiques montrent leurs limites
Les sites web d’aujourd’hui posent de nouveaux défis : contenus qui se chargent dynamiquement (React, Vue…), explosion des formats (texte, vidéo, image), structures pas toujours standards (plusieurs modèles sur une même page). Des études récentes pointent trois gros soucis avec les :
-
Un vrai casse-tête en maintenance Les extracteurs web classiques demandent une maintenance manuelle constante (environ 3 à 5 heures par mois et par site). Dès qu’un site change de structure ou de techno, 60% des sélecteurs XPath ne servent plus à rien. Les outils IA, eux, comprennent le langage et le code, donc ils s’adaptent tout seuls à 90% des changements, ce qui fait baisser les coûts de maintenance de 60 à 80%. Pour les sites modernes en React/Vue, les outils IA gardent le cap grâce à leur compréhension sémantique, même si les noms de classes changent.
-
Des données incomplètes Les méthodes classiques ne récupèrent que les données structurées, et laissent de côté plein d’infos précieuses comme :
- Les données cachées dans les images
- Le texte intégré dans les articles
- Les données non structurées sans balises HTML
-
Qualité de données pas au top Les méthodes classiques galèrent avec les contenus dynamiques, ce qui donne des données incomplètes ou fausses :
- Pour les listes paginées (ex : produits e-commerce), les extracteurs classiques ne récupèrent que 30 à 50% du contenu visible.
- Sur les pages à défilement infini (ex : fils d’actualité), plus de 60% des données importantes passent à la trappe.
- Taux d’erreur élevé quand il s’agit d’associer des données non structurées (listes mal alignées).
C’est là que les outils boostés à l’IA comme Thunderbit font toute la différence. Voilà pourquoi ils sont devenus incontournables.
L’essor du Data Scraping par l’IA
En 2025, l’IA – et surtout les grands modèles de langage (LLM) – a fait des bonds de géant. Ces modèles comprennent et génèrent du langage naturel, font des analyses complexes et proposent des solutions bien plus efficaces. Beaucoup d’outils de data scraping intègrent maintenant des LLM pour dépasser les limites des méthodes classiques. Après avoir testé 13 ces derniers mois, je recommande .
Pourquoi Thunderbit sort du lot ?
-
Une interaction vraiment nouvelle : Tu expliques simplement ce que tu veux en langage naturel, et le système crée automatiquement un plan de scraping, ce qui fait gagner 87% de temps de configuration par rapport aux outils classiques.
-
Les gros atouts du scraping localisé : En tant qu’extension navigateur, Thunderbit permet :
- Extraction instantanée des données
- Gestion des pages dynamiques et à défilement infini
- Extraction même sur les pages qui demandent une connexion
-
Traitement multimodal avancé : Thunderbit gère différents types de données, comme :
- Extraction de texte dans les articles
- Extraction de tableaux financiers depuis des PDF
- Reconnaissance de données dans plusieurs images pour créer des tableaux
- Extraction et synthèse de sous-titres vidéo
Avec Thunderbit, tu peux facilement répondre à tous tes besoins de collecte de données. Voyons comment ça marche concrètement.
Comment faire du Data Scraping avec l’IA
Voici quatre étapes pour profiter à fond du :
-
Installer l’extension navigateur Va sur le site de Thunderbit et télécharge l’extension depuis le Chrome Web Store. Une fois installée, épingle-la dans ta barre d’outils.
-
Créer un compte et profiter des crédits gratuits Inscris-toi via l’extension pour recevoir des crédits d’essai. Ces crédits te permettent de tester les fonctions principales comme le scraping IA, le remplissage automatique de formulaires et la synthèse intelligente. N’hésite pas à explorer l’outil gratuitement dans l’espace de test avant d’utiliser tes crédits pour voir ce qu’il vaut.
-
Lancer un scraping intelligent Ouvre un modèle depuis la barre latérale de Thunderbit. Décris en langage naturel les données et le format que tu veux, ajuste les paramètres si besoin, puis lance l’extraction.
Fonctionnalités avancées (offre Pro)
En passant à l’ (ou en profitant de l’essai gratuit), tu accèdes à des fonctionnalités exclusives :

-
Traitement multimodal avancé Gère des cas complexes comme l’ (rapports financiers, fiches produits), l’extraction de données d’images (étiquettes de prix, fiches techniques) et le scraping de sous-titres vidéo. Le système standardise automatiquement les données non structurées.
-
Scraping profond des sous-pages Accède à tous les sous-liens d’une page (ex : /pages d’avis), reconnaît intelligemment les données associées et les fusionne automatiquement dans le tableau principal. Parfait pour les catalogues e-commerce, annonces immobilières, etc.
-
Bibliothèque de modèles prêts à l’emploi Utilise instantanément des optimisés pour plus de 30 plateformes comme , ou , qui s’adaptent automatiquement aux changements de structure. Les nouveaux utilisateurs économisent en moyenne 83% de temps de configuration.
-
Scraping en masse Lance plusieurs tâches d’extraction en même temps, avec import de listes d’URL pour traiter tout ça en lot.
-
Gestion intelligente de la pagination Détecte et extrait automatiquement les contenus paginés (boutons « charger plus », navigation par page), même sur les pages à défilement infini. Testé pour extraire plus de 200 pages de listes produits e-commerce.
Guide pratique Thunderbit
Cas d’usage 1 : Collecte de données immobilières
Si tu es agent immobilier et que tu veux collecter des données sur Zillow, ou investisseur à la recherche d’opportunités, un extracteur web fiable est ton meilleur allié. L’extracteur web IA de Thunderbit te permet d’extraire facilement les infos clés des biens sur Zillow, pour rester à jour et compétitif. Découvre la vidéo tuto pour extraire des données Zillow avec Thunderbit.
Cas d’usage 2 : Prospection de talents et de clients
Que tu sois RH à la recherche de profils ou commercial en quête de nouveaux leads, un extracteur web fiable peut devenir un vrai atout. Thunderbit permet d’extraire facilement les infos importantes de , pour accélérer la recherche de talents et la gestion des prospects. Après l’avoir testé, tu oublieras vite les recherches manuelles et le copier-coller interminable. Voici une vidéo tuto pour extraire des données LinkedIn avec Thunderbit.
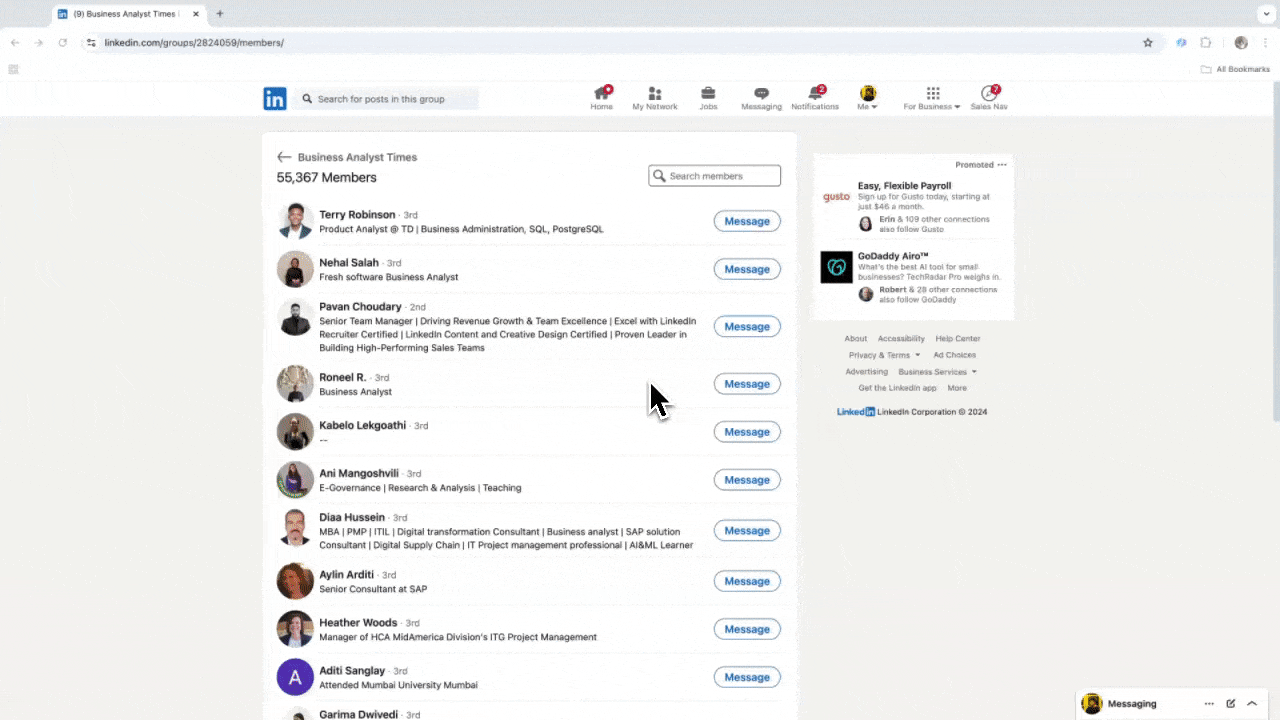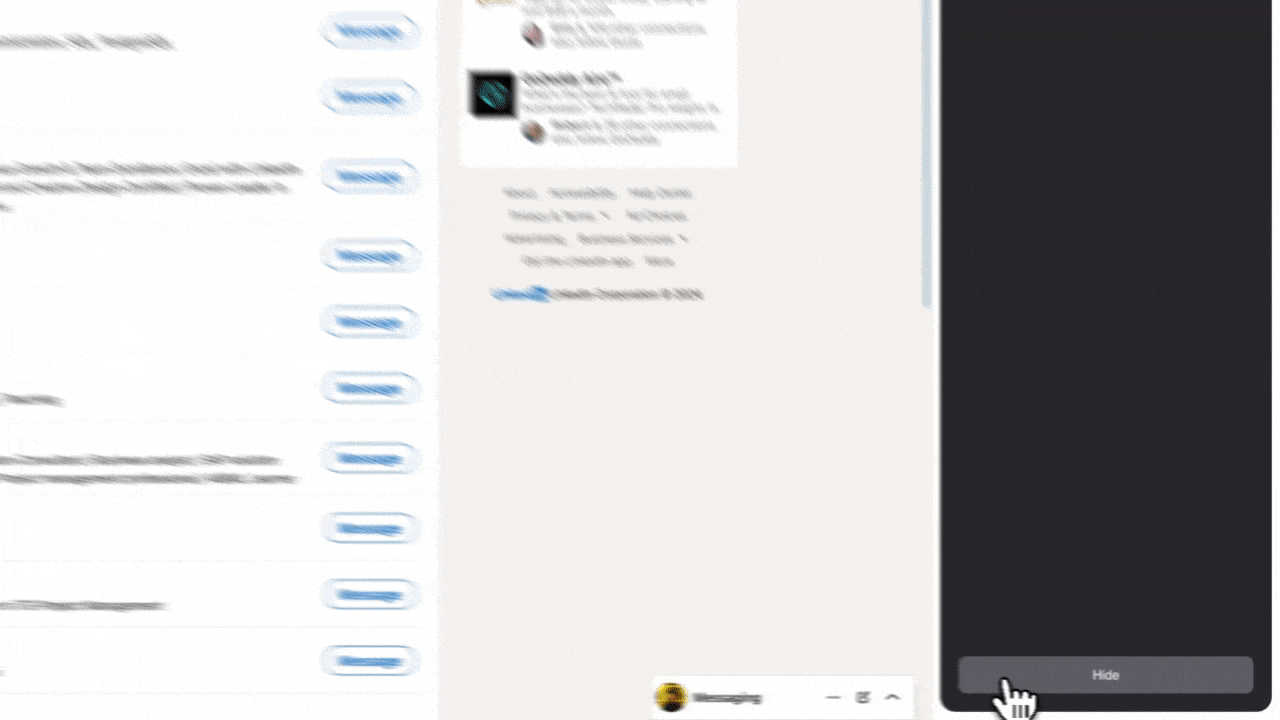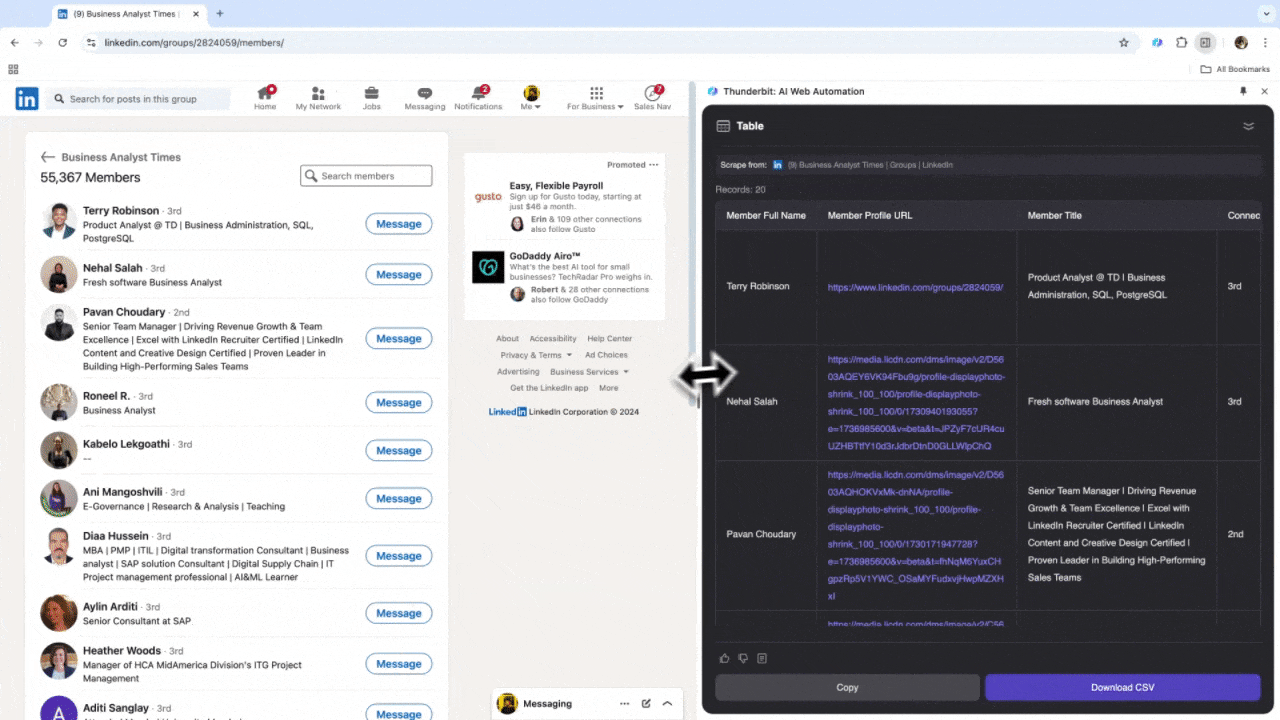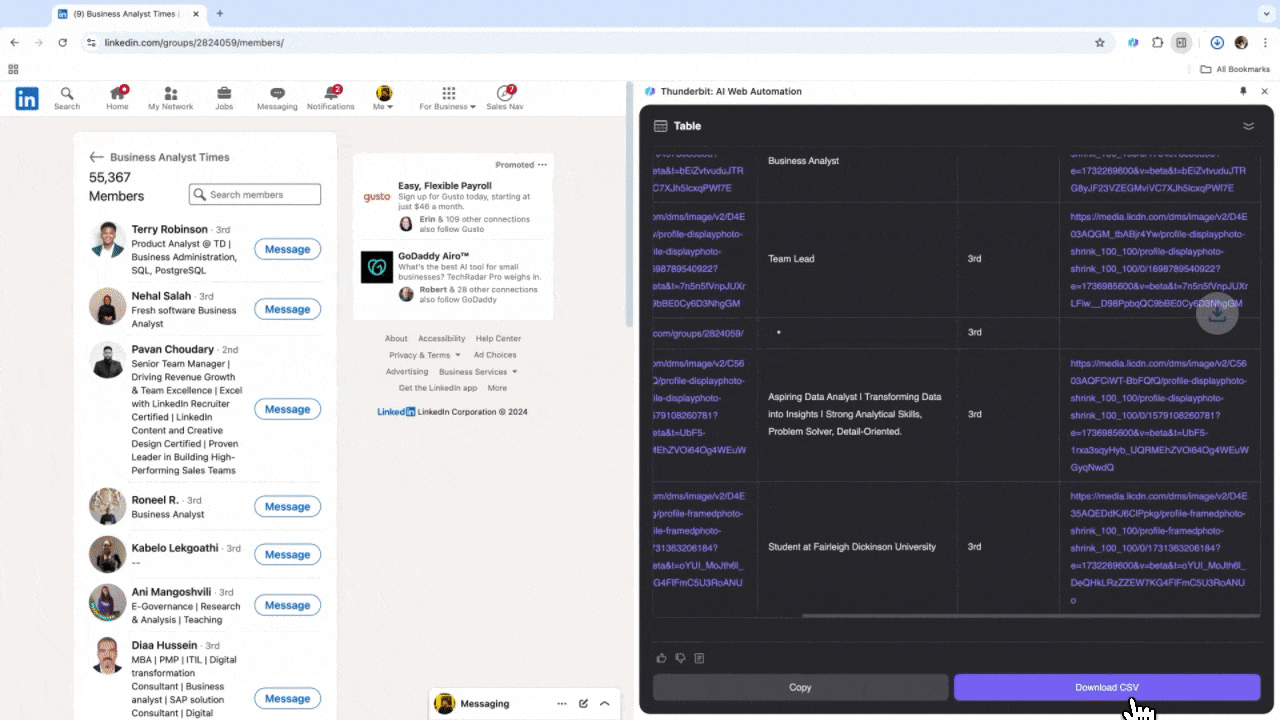
Cas d’usage 3 : Analyse de marché et ciblage client
Si tu es chef d’entreprise et que tu veux collecter des données géolocalisées pour tes analyses de marché, ou commercial à la recherche de prospects locaux, un extracteur web fiable peut tout changer. Thunderbit permet d’extraire facilement les infos clés de , pour prendre de meilleures décisions et booster ta prospection.
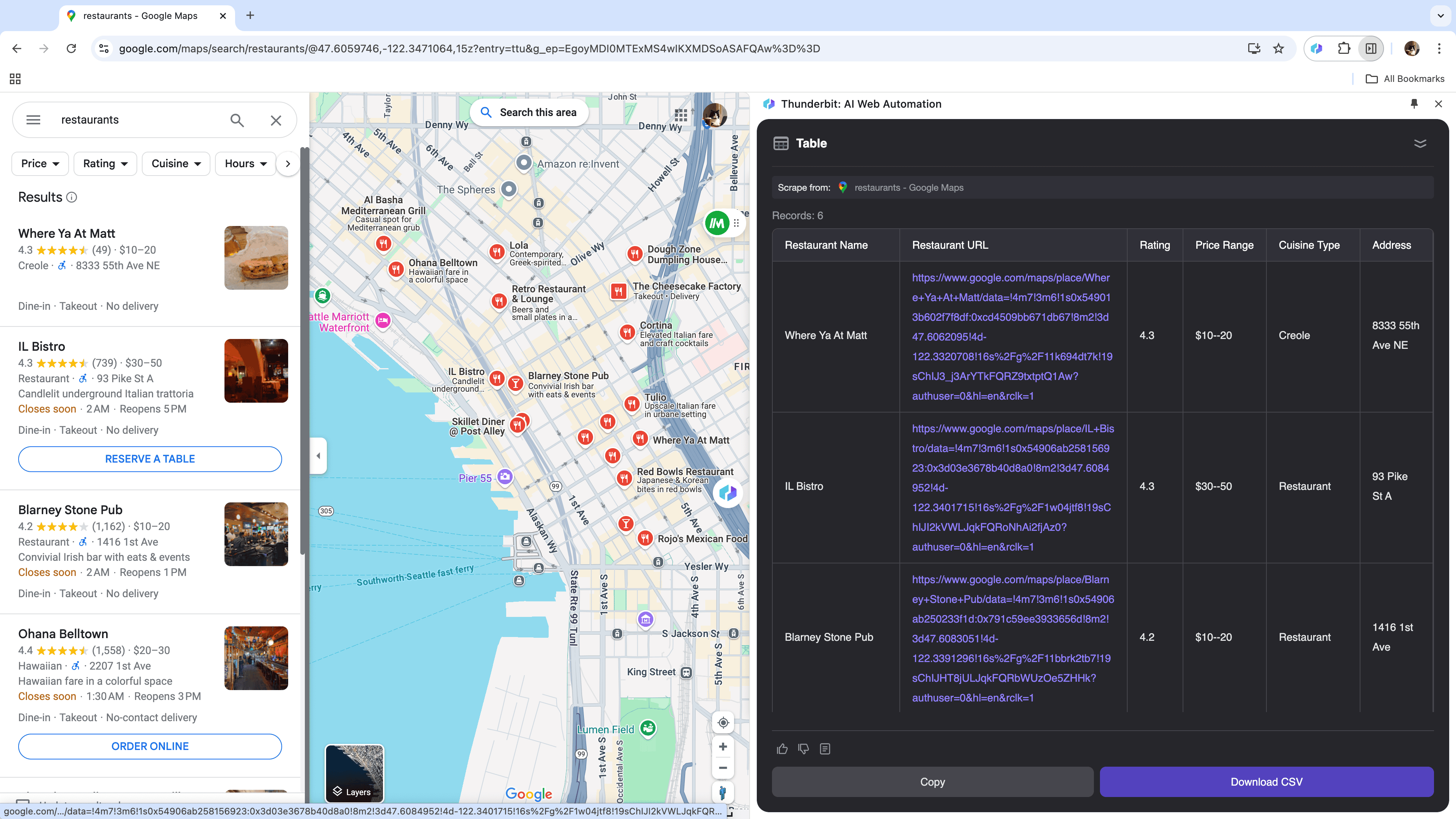
Cas d’usage 4 : Analyse de données e-commerce
Si tu vends en ligne et que tu veux surveiller tes concurrents ou suivre les tendances du marché, Thunderbit est l’outil parfait ! Il collecte facilement toutes les données produits sur , y compris descriptions détaillées, prix et .
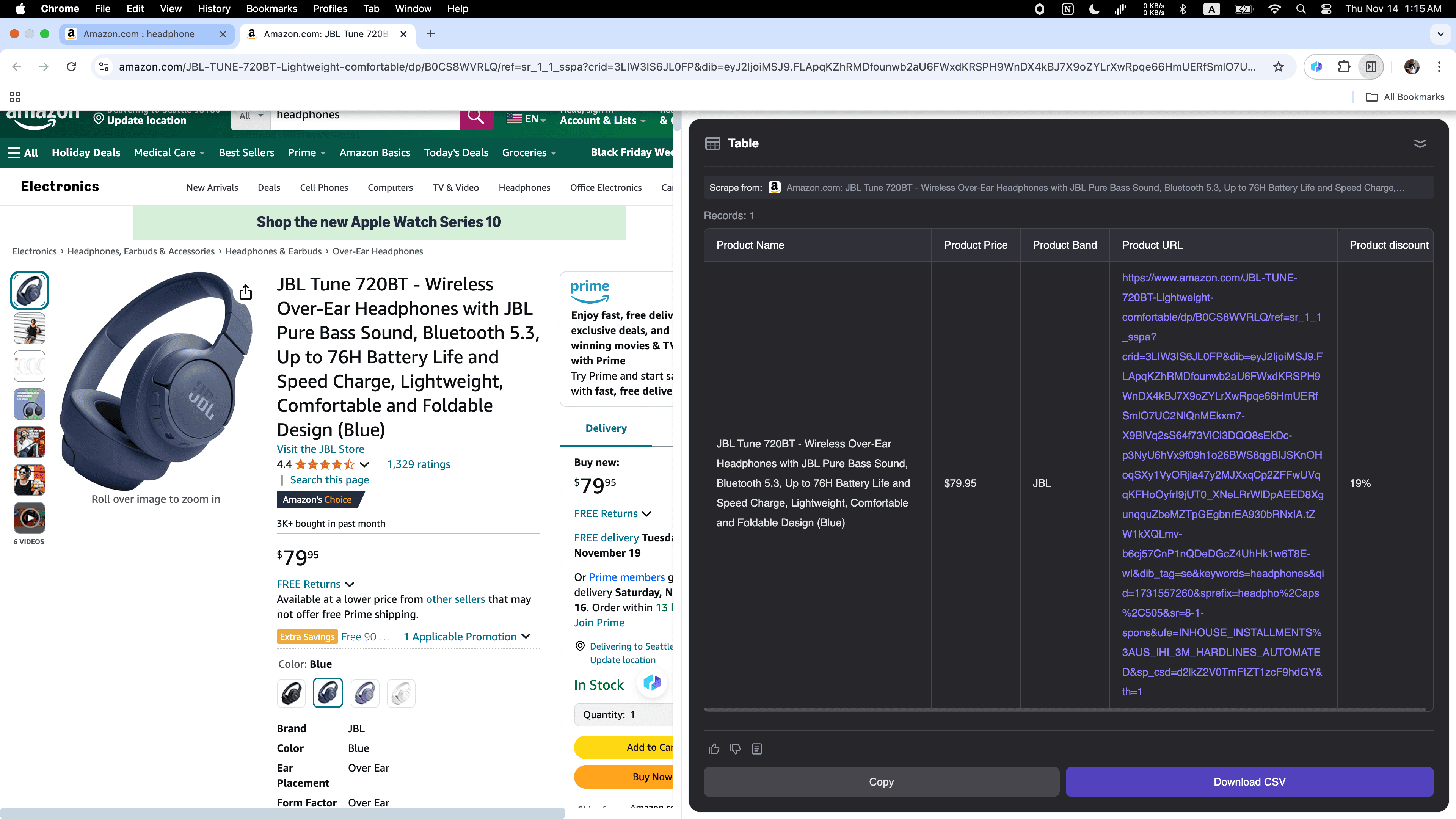
L’extracteur web IA Thunderbit révolutionne la collecte de données pour les pros, en la rendant plus rapide, simple et efficace que jamais. Que tu cherches des biens immobiliers, des prospects ou que tu analyses le marché e-commerce, les extracteurs web IA te font gagner un temps fou. Passe à l’IA pour le web scraping et booste ta productivité. Prêt à te lancer ? Essaie Thunderbit et fais le premier pas vers un scraping intelligent.
Astuces exclusives pour le nettoyage de données
Avec les extracteurs classiques, le vrai boulot commence après l’extraction : le nettoyage des données. L’IA de Thunderbit peut nettoyer les données pendant l’extraction grâce aux LLM, ce qui réduit la charge de nettoyage de 83% grâce à ces innovations :
Astuce 1 : Alignement intelligent des champs
Quand tu extrais des données hétérogènes (ex : LinkedIn et Zillow en même temps), l’IA de Thunderbit fait automatiquement les correspondances sémantiques :
- Elle repère les correspondances de champs entre différentes sources (ex : « price » ↔ « prix » ↔ « Price »)
- Elle fusionne intelligemment les champs similaires (ex : « surface » et « mètres carrés »)
- Elle standardise les données multi-plateformes (ex : « poste actuel » sur LinkedIn et « statut du bien » sur Zillow regroupés en tags)
Astuce 2 : Remplissage contextuel intelligent
Grâce à la compréhension contextuelle des LLM, Thunderbit atteint un taux de complétion de 99% :
- Complétion d’adresse : Remplit automatiquement la ville/état à partir du code postal (ex : 10001 → New York City, NY)
- Déduction de parcours professionnel : Prédit les expériences à partir de la formation LinkedIn
Astuce 3 : Optimisation des données
- Traduction multilingue (traduction en temps réel dans 12 langues, dont anglais, chinois, japonais)
- Résumé intelligent (condense une description produit de 500 mots en 3 points clés)
- Unification des unités (conversion automatique pieds carrés ↔ mètres carrés, Fahrenheit ↔ Celsius)
- Standardisation des formats (dates au format AAAA-MM-JJ, devises en USD)
Astuce 4 : Vérification qualité
- Correction intelligente des erreurs : Corrige automatiquement les erreurs de format (ex : numéro de téléphone +01 138-1234-5678 → +113812345678)
- Validation logique : Vérifie que « année de construction » est antérieure à « dernière rénovation »
Astuce 5 : Tagging IA
Génère automatiquement des tags intelligents via le traitement du langage naturel :
- Tags d’analyse de sentiment (avis clients étiquetés positif/négatif/neutre)
- Tags de valeur business (ex : « clients à fort potentiel »/« biens à suivre »)
- Tags de secteur d’activité (profils LinkedIn tagués « tech|finance|santé »)
Les limites du Data Scraping
Même si le data scraping apporte une vraie valeur, il faut garder en tête certains obstacles. Les aspects juridiques sont essentiels : des réglementations comme le RGPD ou le CCPA imposent des règles strictes sur la collecte de données, donc il faut être carré sur la conformité. En plus, beaucoup de sites utilisent des protections avancées (Cloudflare, restrictions IP) pour détecter et bloquer le scraping.
L’avenir du Data Scraping à l’ère de l’IA
L’IA transforme le web scraping en une solution intuitive pour les entreprises. Imagine : tu entres juste un domaine (ex : zillow.com) et une requête (« extraire toutes les annonces à New York »), et l’IA cartographie automatiquement tous les points de données pertinents – des détails des biens aux tendances de prix – sans aucune configuration manuelle. Ces systèmes intelligents intègrent les données extraites dans tes outils métiers, alimentant automatiquement les CRM avec les prospects LinkedIn ou les tableaux de bord avec les métriques e-commerce. La reconnaissance de motifs avancée permettra un scraping prédictif, surveillant proactivement les stocks ou les tendances du marché. Et surtout, l’IA gérera la conformité en temps réel, adaptant les paramètres d’extraction pour respecter les réglementations tout en assurant la traçabilité.
Ce changement de paradigme démocratise l’accès à l’intelligence business et réinvente la façon dont les organisations interagissent avec la donnée web. Ceux qui adoptent des solutions de scraping IA comme Thunderbit prendront une vraie avance dans la prise de décision pilotée par la donnée.
FAQ
-
C’est quoi Thunderbit ? est une extension navigateur intelligente basée sur les grands modèles de langage (LLM), pensée pour la collecte de données moderne. Elle propose non seulement des fonctionnalités d’, mais aussi le traitement multimodal, pour extraire des données de pages dynamiques, PDF, images et vidéos. En tant que solution locale, elle gère directement les pages nécessitant une connexion (ex : LinkedIn) et s’adapte automatiquement aux évolutions des frameworks web.
-
Comment fonctionne l’extracteur web IA de Thunderbit ? L’extracteur web IA de Thunderbit utilise l’IA pour extraire des données structurées des sites web. Tu cliques sur « Suggestion de colonnes IA » pour que l’IA propose une stratégie d’extraction, puis sur « Extraire » pour collecter les données. Tu peux traiter n’importe quel site, PDF ou image en deux clics.
-
Quelle différence entre extraction de liste et extraction de sous-pages ? L’extraction de liste est optimisée pour les scénarios paginés (ex : listes de produits e-commerce), détecte automatiquement la pagination et extrait des milliers d’entrées. L’extraction de sous-pages utilise une structure arborescente (ex : annonces Zillow → fiches détaillées → plans), créant automatiquement des relations principal/sous-tableau via l’association sémantique.
-
Thunderbit est-il accessible aux non-techniciens ? Thunderbit propose une interface en langage naturel : il suffit de décrire tes besoins (« nom, email, téléphone ») et le système génère automatiquement le plan d’extraction. Nos tests montrent que 85% des utilisateurs réalisent leur première collecte en moins de 10 minutes, sans aucune compétence technique.
-
Quels types de données Thunderbit peut-il traiter ? Thunderbit reconnaît intelligemment de nombreux types de données :
- Données structurées : tableaux, listes (ex : spécifications produits Amazon)
- Données non structurées : textes d’avis, PDF (reconnaissance automatique)
- Données multimodales : étiquettes de prix sur images, extraction de sous-titres vidéo
- Données dynamiques : contenus à défilement infini, images chargées à la volée
- Données liées : cartographie inter-pages (ex : contacts LinkedIn → infos entreprise)
-
Comment démarrer avec Thunderbit ? Découvre nos ou explore notre pour commencer tout de suite.
Pour aller plus loin :