En 2026, les logiciels d’extraction de données ne forment plus une catégorie unique et ne visent plus un seul profil d’acheteur. Certaines équipes réclament un outil pensé d’abord pour le navigateur, capable de convertir un site web en feuille de calcul en quelques minutes. D’autres visent des API de crawl, une infrastructure proxy ou un pipeline gouverné alimentant un data warehouse. Tout ranger dans un même classement, sans contexte, c’est le plus sûr moyen de faire perdre du temps aux acheteurs et de les pousser au surdimensionnement.
Cette mise à jour annuelle poursuit un objectif simple : vous aider à dresser vite une liste restreinte. Les 15 outils ci-dessous couvrent encore l’essentiel des vrais parcours d’achat, mais répondent à des besoins très distincts. Si vous cherchez une extraction rapide de sites web avec un minimum de configuration, votre sélection ne ressemblera en rien à celle d’une équipe qui achète une solution d’ELT et de gouvernance.
Note de révision : sélection revue le 7 mai 2026. Prochaine révision : équipe éditoriale de Thunderbit.
Commencez par le bon type d’outil
Avant de comparer les fournisseurs, posez la tâche que vous cherchez vraiment à accomplir :
- Besoin de données de site web dans un tableau rapidement, sans gérer d’infrastructure de scraping : commencez par des outils navigateur IA ou no-code comme Thunderbit, Octoparse, Data Miner ou Browse AI.
- Besoin de pages rendues, d’une livraison par API ou d’une infrastructure anti-bot pour des équipes produit : regardez ScrapingBee, Diffbot, Bright Data ou Captain Data.
- Besoin de centraliser des données SaaS, API et bases de données vers un data warehouse : concentrez-vous sur Airbyte, Hevo, Fivetran, Talend, Matillion ou Integrate.io.
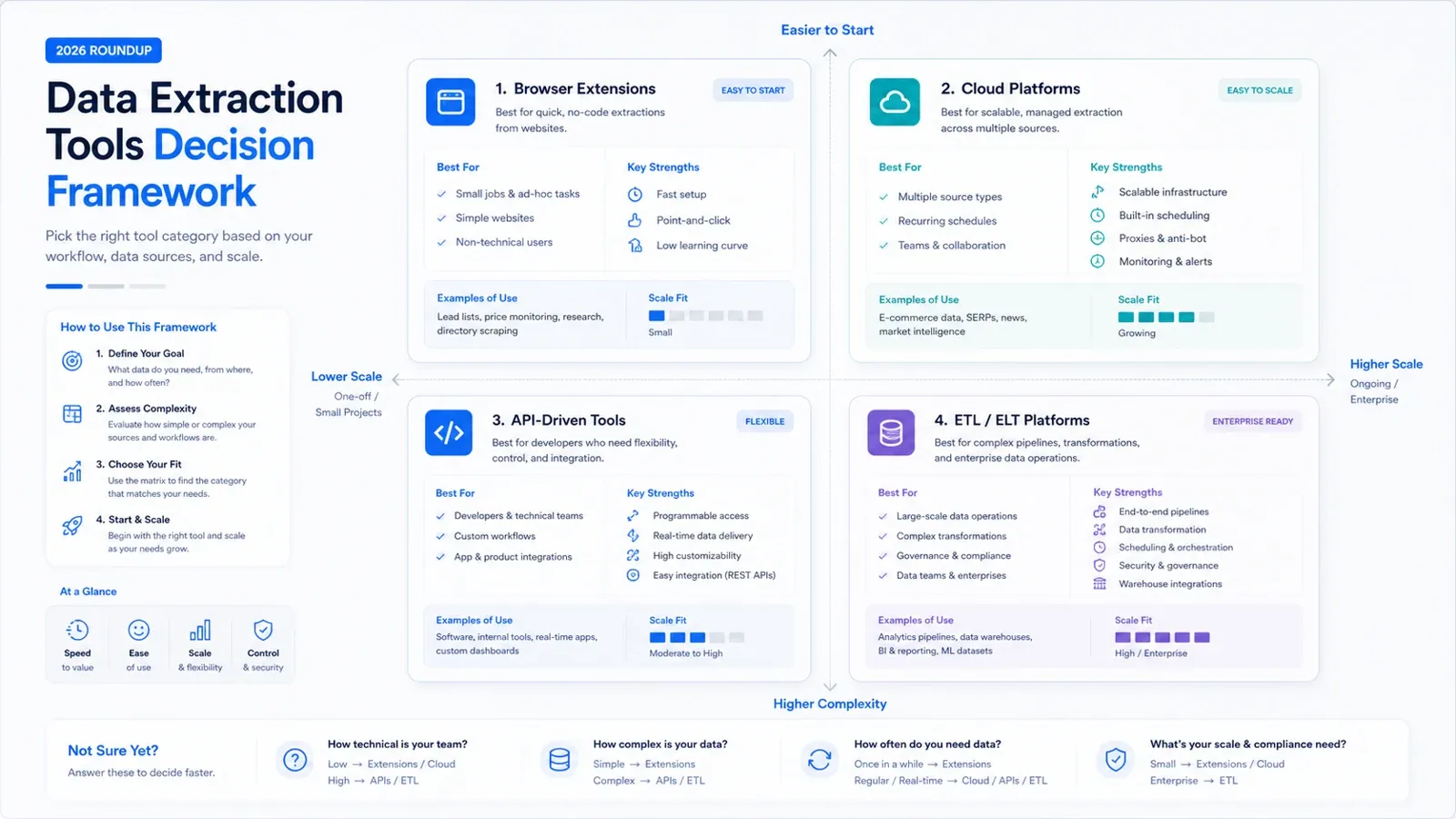
Tableau comparatif rapide : meilleurs outils d’extraction de données en 2026
| Outil | Idéal pour | Ce qui le distingue | Modèle tarifaire |
|---|---|---|---|
| Thunderbit | Utilisateurs métier qui veulent des données de site rapidement | Suggestion de champs par IA, sous-pages, pagination, export vers tableurs | Offre gratuite ; abonnement payant + crédits |
| Diffbot | Équipes qui construisent des produits de données web structurées | API d’extraction, Crawlbot, Knowledge Graph | Essai gratuit ; crédits API payants ; formule entreprise sur mesure |
| Captain Data | Équipes growth et ops qui automatisent les workflows outbound | Workflows no-code en plusieurs étapes sur des sites web et des outils SaaS | Facturation à l’usage / vente directe |
| ScrapingBee | Développeurs qui extraient des pages très chargées en JavaScript | Rendu headless, rotation des proxies, API simple | Essai gratuit ; offres API payantes |
| Octoparse | Analystes qui veulent du scraping visuel avec exécution cloud | Créateur de tâches en point-and-click, modèles, jobs cloud planifiés | Offre gratuite ; offres payantes |
| Data Miner | Utilisateurs du navigateur qui extraient à la demande des listes et des tableaux | Extraction dans le navigateur basée sur des recettes avec export rapide | Offre gratuite ; offres payantes |
| Browse AI | Équipes qui se soucient du monitoring et des alertes de changement | Robots entraînés, surveillance planifiée, livraison vers Sheets/Zapier | Offre gratuite ; offres payantes |
| Bardeen | Utilisateurs qui combinent scraping et automatisation des workflows navigateur | Playbooks IA, automatisations navigateur, intégrations d’apps | Offre gratuite ; offres payantes |
| Bright Data | Collecte à grande échelle en entreprise | Réseau de proxies, unlocker, jeux de données, plateforme de scraping | Facturation à l’usage / contrat |
| Airbyte | Équipes d’ingénierie qui construisent des pipelines pour data warehouse | Connecteurs open source, option auto-hébergée, focus entrepôt | Auto-hébergé gratuit ; cloud + enterprise |
| Talend / Qlik Talend Cloud | Entreprises qui ont besoin d’une intégration fortement gouvernée | Intégration, qualité, gouvernance, contrôles entreprise | Abonnement sur devis |
| Matillion | Équipes data cloud qui travaillent dans des entrepôts modernes | ELT cloud-native et transformation dans l’entrepôt | Facturation à la consommation |
| Integrate.io | Équipes mid-market qui veulent des pipelines gérés | Intégrations gérées entre SaaS et bases de données | Abonnement vendu en direct |
| Hevo Data | Équipes qui veulent une synchronisation gérée quasi temps réel | Connecteurs gérés, orientation temps réel, configuration légère | Offre gratuite ; offres payantes |
| Fivetran | Équipes qui privilégient la fiabilité à la personnalisation | Connecteurs gérés, gestion des schémas, simplicité opérationnelle | Offre gratuite ; tarification à l’usage basée sur le MAR |
Ce qui a changé en 2026
Trois évolutions pèsent plus lourd que les discours génériques sur « l’automatisation » :
- L’extraction pilotée par l’IA est devenue la norme. Les acheteurs attendent de plus en plus qu’un outil infère les champs, absorbe les variations simples de pages et exporte des tableaux propres sans sélecteurs.
- L’infrastructure s’est détachée des outils de workflow. Certains produits s’achètent mieux sous forme d’API ou de couche proxy, d’autres conviennent davantage à des workflows complets pour utilisateurs métier.
- Les acheteurs annuels scrutent de plus près les coûts de maintenance. Un outil moins cher sur le papier reste un mauvais pari si votre équipe doit chaque semaine surveiller sélecteurs, synchronisations vers l’entrepôt ou contournements anti-bot.
C’est pourquoi cette page maintient une liste restreinte séparée par modèle opérationnel, au lieu de feindre que tous les outils se concurrencent directement.
Meilleurs outils d’extraction de données IA et no-code
1.
Thunderbit demeure l’option la plus pertinente pour les équipes non techniques qui veulent vite leurs données de site web dans un tableau structuré. Son atout principal ne tient pas qu’au no-code ; il tient surtout au fait que le produit est conçu pour réduire les frictions de configuration. Vous ouvrez une page, vous demandez à l’IA de suggérer des champs, vous ajustez le tableau si besoin, puis vous exportez.
- Idéal pour : sales ops, ecommerce ops, recrutement, recherche, et quiconque passe d’une page web à un tableur.
- Ce qui le distingue : suggestion de champs par IA, extraction de sous-pages, pagination, export vers Sheets / Excel / Airtable / Notion.
- Tarifs : offre gratuite disponible ; les offres payantes évoluent via abonnement et crédits.
2.
Octoparse reste l’un des produits de scraping no-code les plus installés pour les équipes en quête d’un constructeur visuel de tâches plus explicite. Il réclame plus de configuration que Thunderbit, mais la contrepartie est un meilleur contrôle des tâches pour les utilisateurs prêts à modéliser le workflow.
- Idéal pour : analystes, chercheurs et équipes ops qui extraient des jeux de données récurrents à échelle modérée.
- Ce qui le distingue : conception visuelle des tâches, planification cloud, modèles, prise en charge des connexions et des pages dynamiques.
- Tarifs : offre gratuite, plus des offres payantes pour la capacité cloud et les fonctions d’équipe.
3.
Data Miner rend toujours service pour l’extraction tactique dans le navigateur. Il brille quand un utilisateur veut récupérer vite une liste, un annuaire ou un tableau, et qu’il est à l’aise avec l’usage ou l’adaptation de recettes.
- Idéal pour : extraction native dans le navigateur de tableaux, d’annuaires et d’éléments de page répétés.
- Ce qui le distingue : vaste bibliothèque de recettes, workflow rapide, export CSV / tableur familier.
- Tarifs : offre gratuite avec options payantes pour les usages plus intensifs.
4.
Browse AI excelle dès que le besoin déborde l’extraction pour englober le monitoring. Si un acheteur veut un robot qui revisite une page, en guette les changements et transmet les résultats en aval, il conserve toute sa pertinence.
- Idéal pour : surveillance récurrente, alertes de changement et extraction planifiée simple.
- Ce qui le distingue : robots entraînés, exécutions récurrentes, workflows de type alerte, livraison vers Sheets et outils d’automatisation.
- Tarifs : offre gratuite, plus des offres payantes selon la capacité d’exécution.
5.
Bardeen se tient à la frontière entre extraction et automatisation des workflows navigateur. Moins scraper pur que couche de productivité navigateur, il collecte des données et les achemine vers le reste du workflow.
- Idéal pour : équipes qui automatisent des tâches navigateur répétitives autour du scraping, de l’enrichissement et du transfert.
- Ce qui le distingue : playbooks IA, automatisations navigateur, intégrations profondes avec des applications.
- Tarifs : offre gratuite, plus des offres payantes.
Meilleurs outils d’extraction orientés API, workflow et infrastructure
6.
Diffbot s’impose dès que l’acheteur veut une extraction sous forme de produit API plutôt que de workflow navigateur. Conçu pour décoder le web structuré à grande échelle, il reste plus tourné vers les développeurs et les produits de données que les outils no-code ci-dessus.
- Idéal pour : équipes qui construisent des produits de données, des systèmes d’enrichissement ou des pipelines web structurés à grande échelle.
- Ce qui le distingue : API d’extraction, Crawlbot, Knowledge Graph, produits orientés entités.
- Tarifs : essai gratuit et niveaux de crédits API payants, avec options entreprise.
7.

Captain Data garde sa pertinence parce qu’il traite l’extraction comme une étape parmi d’autres dans un workflow go-to-market plus large. Surtout utile quand la vraie tâche n’est pas « scraper une page », mais « récupérer des leads, les enrichir, les acheminer et mettre à jour les systèmes en aval ».
- Idéal pour : équipes growth, outbound et revenue operations.
- Ce qui le distingue : workflows en plusieurs étapes, enrichissement, transfert vers CRM, automatisation des processus outbound.
- Tarifs : facturation à l’usage et vente directe.
8.
ScrapingBee reste une option API commode pour les développeurs qui veulent gérer les pages rendues et abstraire l’infrastructure, sans bâtir une pile de scraping depuis zéro.
- Idéal pour : équipes produit et développeurs qui intègrent le scraping dans des applications ou des outils internes.
- Ce qui le distingue : rendu JavaScript, gestion des proxies, modèle de requête simple, API pensée d’abord pour les développeurs.
- Tarifs : offres API payantes avec accès d’essai.
9.
Bright Data demeure l’option à l’échelle entreprise quand le défi n’est pas un workflow isolé, mais le volume de collecte, la géographie, l’infrastructure de déblocage et des exigences lourdes en matière de conformité.
- Idéal pour : collecte web à l’échelle entreprise, charges lourdes en proxies et programmes d’acquisition avancés.
- Ce qui le distingue : réseau de proxies, outils de déblocage, produits de données et infrastructure de collecte enterprise.
- Tarifs : facturation à l’usage et contrats.
Meilleures plateformes ELT et de pipeline de données avec capacités d’extraction
10.
Airbyte s’invite à juste titre sur la liste dès que le besoin dépasse l’extraction de sites web et que l’équipe veut des connecteurs, des transferts vers le data warehouse et le contrôle de l’architecture du pipeline. Ce n’est pas un substitut au scraper web, mais l’une des meilleures réponses pour centraliser des données SaaS, API et bases de données.
- Idéal pour : équipes pilotées par l’ingénierie qui veulent des connecteurs ouverts et un contrôle centré data warehouse.
- Ce qui le distingue : écosystème ouvert, option auto-hébergée, offre cloud, flexibilité des connecteurs.
- Tarifs : parcours auto-hébergé gratuit, plus des niveaux cloud et entreprise.
11.

Talend reste une option d’intégration entreprise pour les organisations qui placent mouvement gouverné, qualité, traçabilité et contrôle au-dessus d’une configuration légère.
- Idéal pour : entreprises aux besoins de gouvernance, de qualité et d’intégration inter-systèmes.
- Ce qui le distingue : gouvernance enterprise, outils qualité, largeur d’intégration, orientation cloud gérée sous Qlik.
- Tarifs : abonnement sur devis.
12.
Matillion convient toujours aussi bien aux équipes data cloud en quête d’un ELT étroitement aligné avec les entrepôts modernes et la transformation dans l’entrepôt.
- Idéal pour : équipes Snowflake, Databricks, BigQuery et entrepôts modernes.
- Ce qui le distingue : ELT cloud-native, transformation centrée entrepôt, workflows d’équipe pour l’analytics engineering.
- Tarifs : facturation à la consommation.
13.
Integrate.io garde sa pertinence pour les équipes en quête d’une couche d’intégration gérée, sans envie de construire ni de maintenir elles-mêmes une pile de pipeline plus lourde et technique.
- Idéal pour : équipes mid-market qui préfèrent des intégrations gérées entre applications SaaS et bases de données.
- Ce qui le distingue : posture de mise en œuvre gérée, connectivité aux systèmes métier, modèle opérationnel peu contraignant.
- Tarifs : abonnement vendu en direct.
14.
Hevo Data continue de séduire les équipes en quête d’un pipeline géré, à la configuration légère, à la synchronisation quasi temps réel et à la surcharge opérationnelle faible.
- Idéal pour : équipes analytiques qui veulent faire passer vite les données opérationnelles vers un data warehouse.
- Ce qui le distingue : connecteurs gérés, synchronisation quasi temps réel, configuration accessible.
- Tarifs : offre gratuite et offres payantes.
15.
Fivetran figure parmi les listes les plus sûres dès que l’acheteur privilégie fiabilité, maintenance des connecteurs et simplicité opérationnelle plutôt que l’optimisation des coûts ou la liberté de personnalisation.
- Idéal pour : équipes data qui veulent un standard de connecteurs gérés et acceptent d’en payer le prix.
- Ce qui le distingue : connecteurs gérés, gestion des schémas, grande maturité, faible maintenance.
- Tarifs : offre gratuite, puis tarification à l’usage basée sur le MAR.
Comment choisir sans suracheter
Le plus rapide pour bien choisir consiste à éviter de résoudre le mauvais problème.

- Si vous avez surtout besoin de données web dans une feuille de calcul, ne commencez pas par une plateforme ELT.
- Si vous avez besoin d’un pipeline gouverné vers un data warehouse, ne transformez pas un scraper navigateur en plateforme data.
- Si la partie la plus ardue touche au rendu JavaScript, au blocage ou à la livraison par API, comparez d’abord les outils d’infrastructure.
- Si le plus difficile reste l’adoption par l’équipe et la rapidité de mise en place, comparez d’abord les outils IA et no-code.
Une règle d’achat utile en 2026 : achetez au niveau de complexité le plus bas que votre vrai workflow autorise. Le coût de maintenance s’accumule plus vite que les économies sur le prix affiché.
Liste restreinte finale par type d’équipe
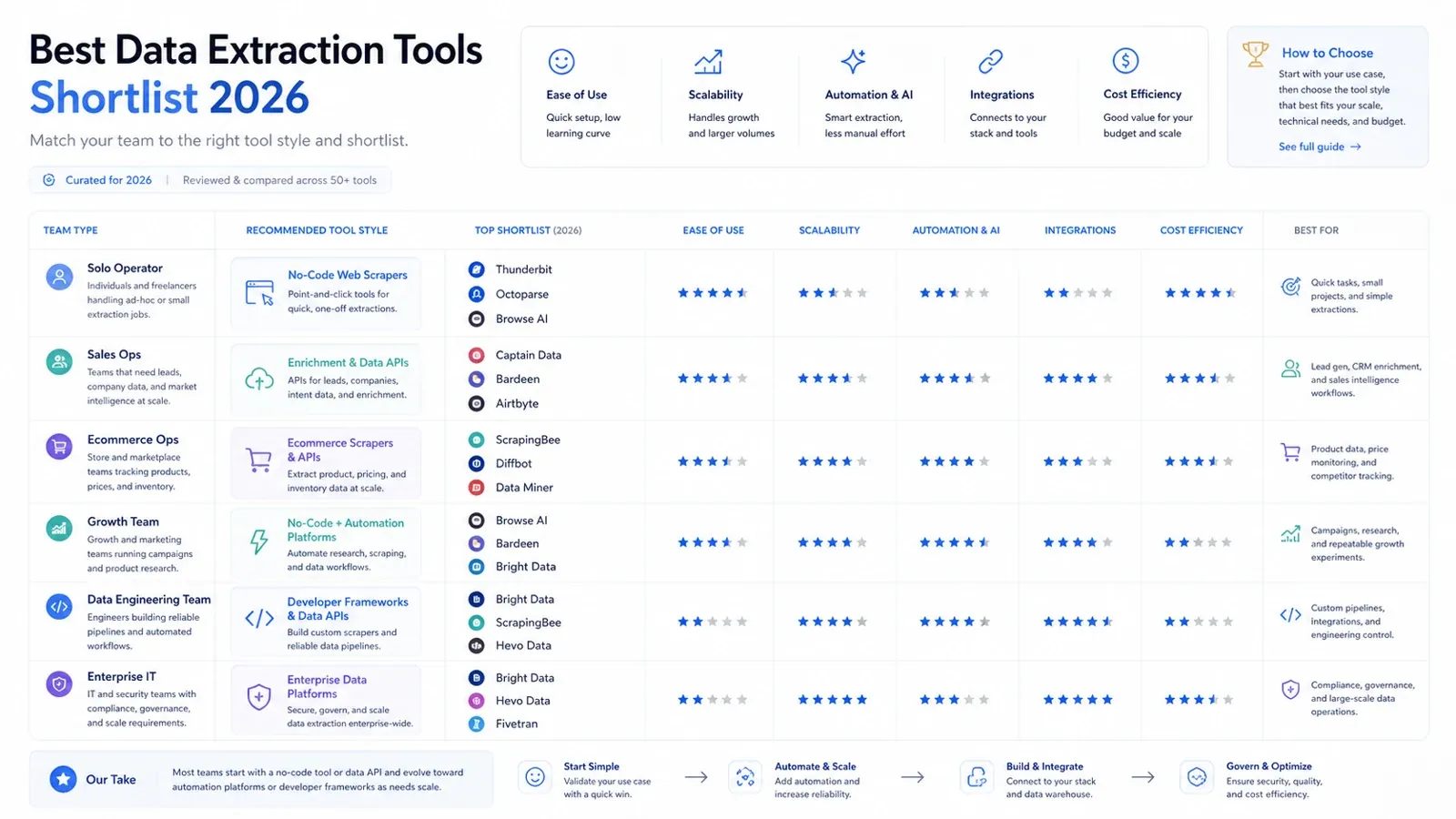
Voici la version concrète de la liste restreinte :
- Opérateur solo ou utilisateur métier : Thunderbit, Data Miner, Browse AI.
- Équipe sales ops ou growth : Thunderbit, Captain Data, Bardeen.
- Équipe ecommerce ops : Thunderbit, Octoparse, Bright Data.
- Équipe data engineering : Airbyte, Fivetran, Matillion, Hevo.
- Acheteur entreprise IT / intégration gouvernée : Talend, Fivetran, Integrate.io, Bright Data.
- Développeur de produits de données : Diffbot, ScrapingBee, Bright Data.
Et si je devais réduire ce marché à la liste de départ la plus courte et utile pour la majorité des acheteurs en 2026, ce serait :
- Thunderbit pour une extraction web rapide assistée par IA, pour équipes non techniques.
- ScrapingBee pour les développeurs en quête d’une infrastructure API pour pages rendues.
- Bright Data pour la collecte à l’échelle entreprise et l’infrastructure de déblocage.
- Airbyte pour des pipelines data warehouse pilotés par l’ingénierie, avec flexibilité.
- Fivetran pour la fiabilité de connecteurs gérés.
FAQ
Q1 : Les outils d’extraction de données et les outils ETL sont-ils la même chose ?
Non. Un outil d’extraction peut se concentrer sur les sites web, les PDF ou la capture structurée au niveau d’une page, tandis qu’une plateforme ETL ou ELT se consacre au déplacement et à la transformation des données entre systèmes vers un data warehouse. Certains acheteurs ont besoin des deux, mais on ne doit pas les évaluer comme s’ils résolvaient le même premier problème.
Q2 : Quel est le meilleur choix pour une équipe non technique en 2026 ?
Pour une extraction rapide de sites web avec un minimum de configuration, les outils IA et no-code restent le meilleur point de départ. Thunderbit, Octoparse, Browse AI et Data Miner sont les options les plus pertinentes, selon le niveau de contrôle et de vitesse recherché.
Q3 : Quels outils conviennent le mieux aux cas d’usage développeurs ou entreprise ?
Pour les développeurs, ScrapingBee et Diffbot sont de très bons points de départ, selon que vous visiez une infrastructure de rendu ou des API de données web structurées. Pour la collecte à l’échelle entreprise ou une infrastructure lourde en conformité, Bright Data reste un candidat majeur. Pour des pipelines internes gouvernés, Airbyte, Fivetran, Talend, Matillion, Hevo et Integrate.io forment des choix plus solides.