On est en 2026, et peu importe que tu bosses dans la vente, les opérations ou un autre secteur, tu as sûrement remarqué que le web, c’est à la fois ton meilleur pote et le plus gros bouffeur de temps. Jamais il n’a été aussi simple de trouver des infos utiles : prospects, prix, avis, mouvements de la concurrence… Mais quand il s’agit de transformer tout ça en un tableau ou un dashboard vraiment exploitable ? Là, ça se complique. J’ai vu des équipes passer des heures à faire du copier-coller, pour finir avec des données en vrac, pas à jour, et une bonne dose de ras-le-bol devant leurs tableurs.

La bonne nouvelle, c’est que l’extraction de contenu depuis d’autres sites web n’est plus réservée aux développeurs ou aux data scientists. Avec la montée des outils no-code boostés à l’IA comme , même si tu n’es pas technique, tu peux collecter les données qu’il te faut—vite, bien, et sans prise de tête. Dans ce guide, je t’explique ce qu’est vraiment l’extraction de contenu web, pourquoi c’est devenu indispensable pour les boîtes modernes, et comment tu peux commencer à extraire des données de sites web facilement (et légalement) en 2026. Que tu sois totalement débutant ou que tu veuilles juste optimiser tes process, tu es au bon endroit.
C’est quoi, « extraire du contenu depuis d’autres sites web » ?
Pour faire simple, extraire du contenu depuis d’autres sites web, c’est utiliser un logiciel pour aller chercher automatiquement des infos sur des pages web et les organiser dans un format carré—tableaux, feuilles de calcul ou bases de données. Au lieu de recopier à la main des fiches produits, des contacts ou des avis, un extracteur web fait tout le boulot pour toi ().
Imagine : tu es à la bibliothèque, et au lieu de prendre des notes à la main, un assistant robot scanne les pages et te file un résumé nickel. C’est exactement ce que fait l’extraction web sur Internet.
Pourquoi extraire du contenu depuis des sites web ?
- Génération de leads : Récupérer noms, emails et numéros de téléphone depuis des annuaires ou des listes d’entreprises.
- Veille concurrentielle : Suivre les prix, les lancements de produits ou les avis sur les sites e-commerce.
- Études de marché : Rassembler des actus, articles de blog ou discussions de forums pour repérer les tendances.
- Agrégation de contenu : Centraliser des articles ou ressources pour des newsletters ou des bases de connaissances internes.
La différence entre le copier-coller manuel et l’extraction automatisée saute aux yeux : l’extraction, c’est bien plus rapide, fiable, et tu peux traiter des milliers de pages en quelques minutes ().
Pourquoi l’extraction de contenu web est devenue incontournable pour les entreprises ?
Si tu fais encore tout à la main, tu passes à côté de la rapidité et de l’intelligence que les équipes modernes utilisent pour prendre de l’avance. Les boîtes pilotées par la donnée , et d’ici 2026, seront totalement data-driven.
Voilà comment l’extraction de contenu web fait vraiment la différence :
| Cas d’usage | Quoi extraire | Bénéfice |
|---|---|---|
| Génération de leads | Annuaires d’entreprises, LinkedIn, Pages Jaunes | Constituer des listes ciblées, accélérer la prospection |
| Veille tarifaire | Fiches produits concurrentes, sites e-commerce | Ajuster sa stratégie de prix en temps réel |
| Analyse client | Avis, posts sur les réseaux sociaux, forums | Analyser les retours, détecter des tendances, améliorer l’offre |
| Agrégation de contenu | Sites d’actualités, blogs, forums sectoriels | Alimenter la veille, enrichir le marketing de contenu |
En automatisant ces tâches, tu ne gagnes pas juste du temps : tu prends de meilleures décisions, plus vite, et tu libères tes équipes pour des missions à plus forte valeur ajoutée ().
Comment choisir le bon outil d’extraction web : le guide pour débuter
Si tu débutes dans l’extraction de contenu web, le premier choix crucial, c’est l’outil. Ce que j’ai appris (parfois à mes dépens) : ton choix dépend de ton aisance technique, de la complexité des sites visés, et de la rapidité attendue.
Les grands types d’outils d’extraction web :
- Outils avec code (genre Python avec BeautifulSoup ou Scrapy) : Ultra flexible, mais il faut savoir coder. Parfait pour les devs ou les équipes IT.
- Outils sans code (genre ParseHub, Octoparse) : Interfaces visuelles, modèles prêts à l’emploi, workflows en mode point & click. Idéal pour les non-codeurs, mais ça peut coincer sur certains sites.
- Extensions navigateur (genre Thunderbit, Extracteur Web) : Directement dans Chrome, installation rapide, top pour des extractions ciblées et rapides.
Pour la plupart des utilisateurs métier—et surtout les débutants—la simplicité, c’est la clé. C’est pour ça que je conseille de commencer avec une extension comme . Elle est pensée pour les non-techniciens et s’appuie sur l’IA pour tout simplifier.
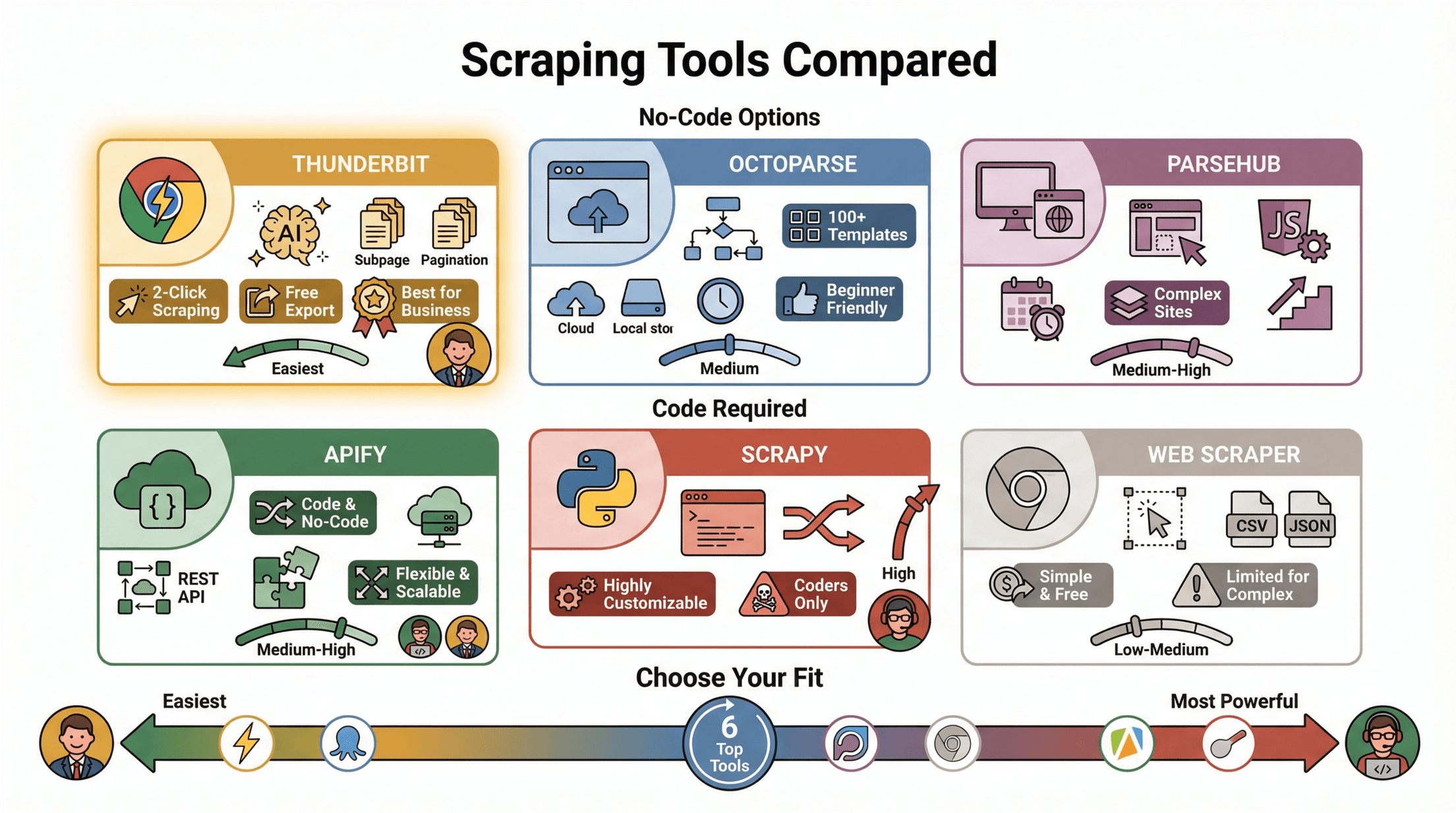
Comparatif des outils d’extraction web les plus populaires
Voyons comment se positionnent les principaux outils pour extraire du contenu depuis d’autres sites :
| Outil | Type | Fonctionnalités clés | Avantages / Inconvénients |
|---|---|---|---|
| Thunderbit | Extension Chrome, IA | Extraction en 2 clics, suggestions IA, sous-pages & pagination, export gratuit | Ultra simple, sans code, idéal pour les pros |
| Octoparse | Application, Sans code | Workflow visuel, 100+ modèles, cloud/local, planification | Facile à prendre en main, mais version gratuite limitée |
| ParseHub | Desktop/Web, Sans code | Builder visuel, gère les pages dynamiques/JS, planification | Puissant pour sites complexes, mais apprentissage plus long |
| Apify | Cloud/Code/Sans code | Code & sans code, serverless, API REST, intégrations | Flexible, évolutif, nécessite quelques bases techniques |
| Scrapy | Librairie Python, Code | Crawl asynchrone, hautement personnalisable | Très puissant, réservé aux codeurs |
| Extracteur Web | Extension Chrome, Sans code | Sélection visuelle, export CSV/JSON | Simple, gratuit, mais limité pour les sites complexes |
Pour la plupart des pros, Thunderbit et Octoparse sont les plus accessibles pour se lancer ().
Les points forts de Thunderbit pour l’extraction de contenu web
Petit aparté sur Thunderbit (promis, c’est pas de la pub cachée) : ce qui fait la différence avec , c’est sa prise en main ultra simple, pensée pour les débutants et les utilisateurs métier.
Ce qui change la donne avec Thunderbit :
- Interface en langage naturel : Tu décris ce que tu veux (« Récupérer tous les avis et notes produits de cette page »), l’IA de Thunderbit s’occupe du reste.
- Suggestions et amélioration IA des champs : Thunderbit analyse la page et te propose direct les colonnes à extraire—noms, prix, emails, etc. Plus besoin de bidouiller des sélecteurs ou du code.
- Workflow en 2 clics : Clique sur « Suggestions IA », puis sur « Extraire ». C’est tout. Même ma mère pourrait le faire (et elle croit encore que « le cloud » c’est la météo).
- Gestion des sous-pages et de la pagination : Thunderbit suit les liens vers les pages de détail (genre avis produits) et gère les listes multi-pages sans que tu aies à t’en occuper.
- Export instantané : Tu envoies tes données direct vers Excel, Google Sheets, Airtable ou Notion—pas d’étape en plus, pas de surcoût.
Exemple : Tu veux extraire les avis d’un site e-commerce. Ouvre la page des avis, clique sur l’icône Thunderbit, lance « Suggestions IA » : Thunderbit te propose des colonnes comme « Nom du client », « Note », « Commentaire ». Clique sur « Extraire » et c’est plié. Besoin de plus de détails ? Utilise l’extraction de sous-pages pour tout récupérer.
Les utilisateurs disent souvent que Thunderbit « gère mieux les longues pages que prévu » et « simplifie l’extraction sur les sites dynamiques » ().
Extraire du contenu sur des sites complexes : pagination et sous-pages
Soyons clairs : tous les sites ne rendent pas la vie facile pour récupérer les données. Les plateformes e-commerce, annuaires ou sites d’avis utilisent souvent la pagination (plusieurs pages de résultats) ou des sous-pages imbriquées (faut cliquer sur chaque produit ou entreprise pour plus de détails).
Le souci : Les extracteurs classiques loupent souvent les infos cachées derrière les boutons « Suivant » ou dans les sous-pages. À la main ? Tu y passes des jours.
La solution Thunderbit : L’IA repère les liens de pagination ou le scroll infini et continue d’extraire jusqu’à tout avoir. Pour les sous-pages, Thunderbit visite chaque lien de ton tableau (genre chaque fiche produit ou entreprise), extrait les champs en plus et les fusionne dans ton jeu de données principal.
Pas à pas : extraire du contenu multi-pages et sous-pages
Voici comment t’y prendre sur un site complexe avec Thunderbit :
- Ouvre la page principale de la liste (ex : catégorie e-commerce ou annuaire).
- Clique sur l’icône Thunderbit et sélectionne « Suggestions IA ». Thunderbit te propose des colonnes comme « Nom du produit », « Prix », « Lien ».
- Clique sur « Extraire ». Thunderbit récupère tous les éléments de la page courante—et suit la pagination pour le reste.
- Besoin de détails ? Clique sur « Extraire les sous-pages ». Thunderbit visite chaque page de détail et collecte les infos complémentaires (avis, caractéristiques, contacts…).
- Vérifie et exporte ton jeu de données enrichi.
Astuce : Utilise l’extraction de sous-pages dès que tu vois des liens « détails », « avis » ou « contact »—c’est parfait pour l’e-commerce, les Pages Jaunes ou les annonces immobilières.
Organiser et analyser les données extraites : tags, catégories et export
Extraire les données, c’est juste la première étape. Pour en tirer vraiment profit, il faut les organiser, les analyser et les partager.
Thunderbit te facilite la vie :
- Tags et catégories : Ajoute des tags ou catégories à tes champs (ex : « Type de produit », « Région », « Statut du lead ») pour filtrer et analyser facilement.
- Prompts IA sur les champs : Besoin de classer des références ou de traduire des avis ? Ajoute une instruction personnalisée, l’IA de Thunderbit s’en charge à l’extraction.
- Options d’export : Envoie instantanément tes données vers Excel, Google Sheets, Airtable ou Notion. Téléchargement CSV ou JSON possible pour aller plus loin.
Bonnes pratiques pour organiser tes données :
- Utilise des noms de colonnes clairs et cohérents.
- Ajoute des tags ou catégories pour faciliter le tri.
- Archive les extractions brutes avec les jeux de données nettoyés.
- Programme des exports réguliers ou des extractions planifiées pour les projets récurrents.
Les équipes commerciales peuvent taguer les leads par source ou statut, pendant que les ops classent les produits par fournisseur ou région. Le but : rendre tes données exploitables et faciles à partager.
Respecter la législation : ce qu’il faut savoir avant d’extraire du contenu web
Avant de te lancer à fond dans l’extraction, parlons un peu conformité. Bonne nouvelle : extraire des données publiques est en général légal si tu respectes quelques règles simples (, ).
Conseils pour rester dans les clous :
- N’extrais que du contenu public. Ne contourne pas les connexions, paywalls ou protections.
- Respecte le robots.txt et les CGU. Même si ce n’est pas toujours contraignant, ça montre la volonté du site.
- Évite les données perso ou protégées par le droit d’auteur. Reste sur les infos factuelles (noms, prix, caractéristiques) et ne republie pas de gros blocs de texte ou d’images protégés.
- Cite tes sources si tu utilises les données extraites dans des rapports ou publications.
- Modère la fréquence de tes requêtes pour ne pas saturer les sites.
Checklist pour une extraction sans souci :
- ✅ Pages publiques uniquement (pas de connexion)
- ✅ Vérifier robots.txt et CGU
- ✅ Pas de données perso ou protégées
- ✅ Citer les sources
- ✅ Ne pas extraire trop vite
Thunderbit encourage une extraction responsable en te permettant de cibler précisément les données utiles et de les exporter pour un usage interne.
Guide pas à pas : extraire du contenu web avec Thunderbit
Prêt à te lancer ? Voici comment extraire du contenu depuis d’autres sites avec :
- Installe l’extension Chrome Thunderbit : et crée-toi un compte gratuit.
- Ouvre le site cible : Va sur la page à extraire (ex : liste de produits, annuaire, page d’avis).
- Clique sur l’icône Thunderbit : Dans la barre Chrome, ouvre l’extension.
- Utilise « Suggestions IA » : Thunderbit analyse la page et propose les colonnes à extraire (« Nom », « Prix », « Email »…).
- Ajuste les colonnes si besoin : Renomme, ajoute ou supprime des champs. Tu peux aussi ajouter des prompts IA personnalisés pour trier ou catégoriser.
- Clique sur « Extraire » : Thunderbit récupère les données de la page—et suit la pagination si elle existe.
- Extraction des sous-pages (optionnel) : Pour plus de détails, clique sur « Extraire les sous-pages » pour collecter les infos des pages liées.
- Vérifie et exporte : Prévisualise tes données, puis exporte-les vers Excel, Google Sheets, Airtable, Notion, ou télécharge-les en CSV/JSON.
Dépannage des galères courantes :
- Pages nécessitant une connexion : Utilise le mode « Browser Scraping » de Thunderbit en étant connecté.
- Sites lents ou bloqués : Essaie d’extraire en dehors des heures de pointe, ou fractionne ton extraction.
- Contenu dynamique non chargé : Fais défiler la page avant d’extraire, ou utilise le mode navigateur de Thunderbit.
- Changements de mise en page : Relance « Suggestions IA » pour que l’IA s’adapte à la nouvelle structure.
En cas de pépin, la et l’équipe support Thunderbit sont là pour toi.
Conclusion & points clés à retenir
L’extraction de contenu web, ce n’est plus un truc de dev, c’est devenu un réflexe business. En 2025, avec la masse de données en ligne et les outils no-code boostés à l’IA, tout le monde peut extraire les infos qu’il lui faut—vite, bien, et sans prise de tête.
À retenir :
- Extraire du contenu web, c’est devenu indispensable pour la prospection, la veille et rester dans la course.
- Des outils modernes comme rendent l’extraction accessible à tous, avec prompts en langage naturel, suggestions IA et export instantané.
- La gestion de la pagination, des sous-pages et l’organisation des données par Thunderbit permet de gérer même les sites les plus tordus.
- Reste conforme : n’extrais que des données publiques, respecte les règles des sites, évite les contenus protégés ou perso.
- Démarrer, c’est aussi simple qu’installer une extension Chrome et cliquer sur quelques boutons.
Prêt à dire adieu au copier-coller ? et découvre combien de temps (et d’énergie) tu peux économiser sur tes prochains projets de collecte de données. Pour plus d’astuces et de tutos, va faire un tour sur le .
FAQ
1. Est-ce légal d’extraire du contenu depuis d’autres sites web ?
En général, oui—si tu restes sur des données publiques, respectes le robots.txt et les CGU, et évites les infos protégées ou perso. Vérifie toujours les règles de chaque site et utilise les données extraites de façon responsable ().
2. Faut-il savoir coder pour extraire du contenu web ?
Non ! Des outils comme sont faits pour les non-techniciens. Tu peux extraire des données en quelques clics, grâce aux prompts en langage naturel et aux suggestions IA.
3. Quels types de sites puis-je extraire avec Thunderbit ?
Thunderbit marche sur plein de sites—e-commerce, annuaires, plateformes d’avis, annonces immobilières, etc. Il gère la pagination, les sous-pages et même le contenu dynamique dans la plupart des cas.
4. Comment organiser et analyser les données extraites ?
Thunderbit te permet de taguer, catégoriser et étiqueter tes données dès l’extraction. Tu peux exporter direct vers Excel, Google Sheets, Airtable ou Notion pour analyse et partage.
5. Que faire si un site bloque mon extracteur ou change de mise en page ?
Essaie d’extraire plus lentement, utilise le mode « Browser Scraping » de Thunderbit, ou relance « Suggestions IA » pour t’adapter à la nouvelle structure. Si ça coince toujours, check la ou contacte le support Thunderbit.
Bonne extraction—et que tes tableurs soient toujours propres, bien rangés et prêts à l’action.
Pour aller plus loin