

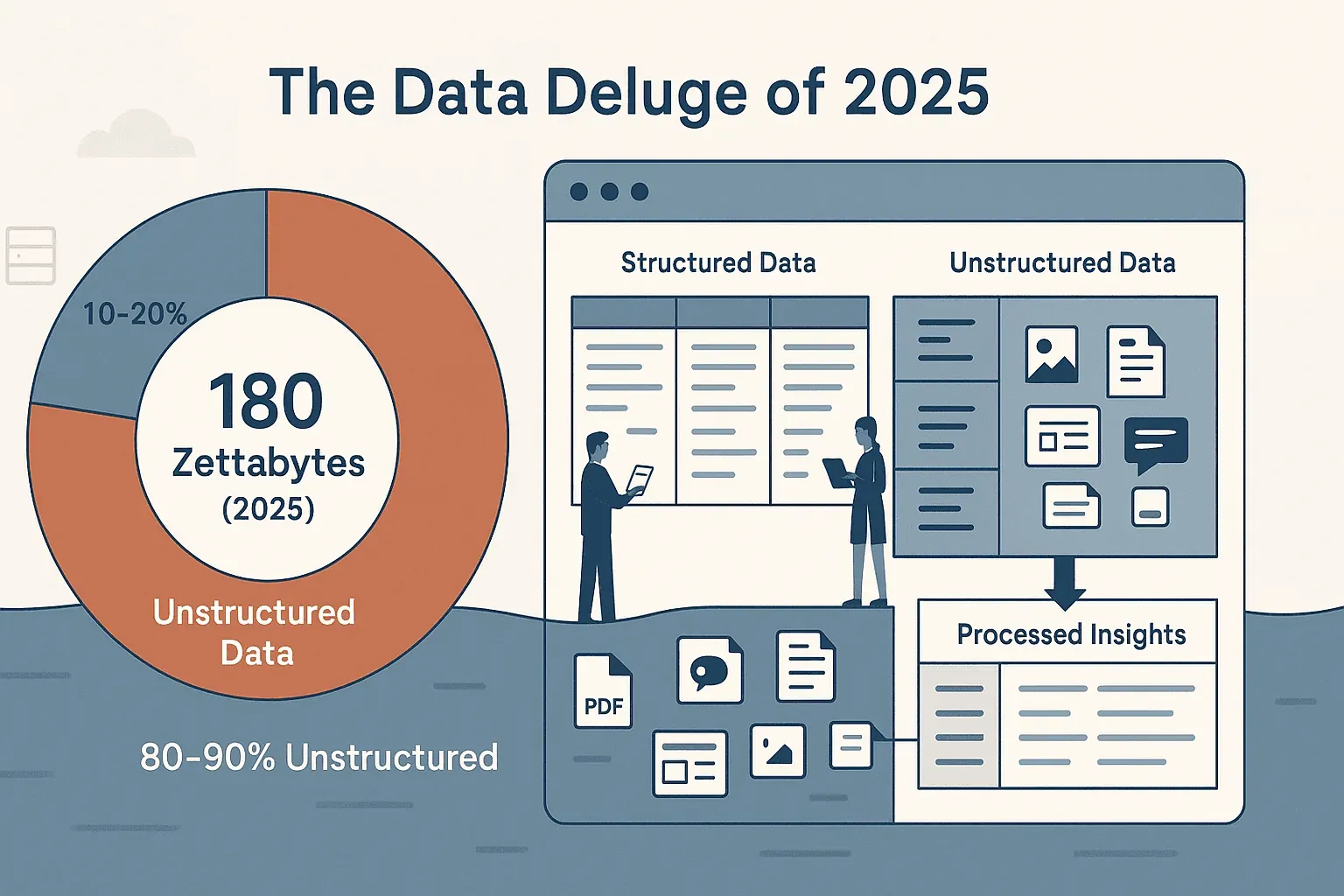
Si vous avez déjà essayé de collecter des données sur un site web — que ce soit pour des leads commerciaux, des prix concurrents ou simplement pour remettre de l’ordre dans un catalogue produits chaotique — vous savez que le web n’est pas vraiment conçu pour le copier-coller à la chaîne. Le volume de données en ligne est vertigineux : IDC et Statista estiment le datasphere mondial à environ 180 zettaoctets en 2025, et nous devrions déjà atteindre environ 221 zettaoctets en 2026. Le vrai problème n’est pas le volume, mais la forme : environ 80 % de ces données sont non structurées, enfouies dans des pages web, des PDF, des images et des flux dynamiques. La plupart des équipes métiers — moi y compris — ont passé beaucoup trop de temps à se battre avec ce chaos, pour finir avec des tableaux bancals et une impression de déjà-vu.
Extraire des données de n’importe quel site web grâce à l’IA Get Started Free
C’est pour cela que l’extraction efficace de données sur le web me passionne. Dans ce guide, je vais vous montrer une méthode pratique, étape par étape, pour crawler n’importe quel site web — sans code, sans prise de tête — avec Thunderbit, notre extracteur Web alimenté par l’IA. Que vous travailliez dans la vente, les opérations ou que vous en ayez simplement assez de la saisie manuelle, je vais vous montrer comment gérer des mises en page complexes, la pagination, les sous-pages et même extraire des données depuis des PDF et des images. Transformons le chaos du web en avantage pour votre entreprise.
Que signifie crawler efficacement un site web ?
Décomposons cela : crawler un site web consiste à utiliser un outil automatisé (un peu comme un assistant robot) pour parcourir systématiquement des pages web et extraire les informations qui vous intéressent — noms, prix, e-mails, spécifications produit, tout ce que vous voulez. Un crawl efficace, ce n’est pas seulement une question de vitesse ; c’est aussi une question de précision, d’effort manuel minimal et de capacité à gérer les obstacles bien réels du web, comme la pagination, les sous-pages et les données non structurées (Wikipedia).
Qu’est-ce qui distingue un crawl efficace d’un interminable marathon de copier-coller ? Voici ce qui compte :
- Vitesse : récupérer des centaines de pages ou d’enregistrements en quelques minutes, pas en plusieurs heures.
- Précision : récupérer exactement les données dont vous avez besoin, sans oublier d’entrées ni introduire de fautes de frappe.
- Automatisation : laisser l’outil gérer les tâches répétitives, comme cliquer sur « Suivant » ou suivre les liens vers les pages de détail.
- Résilience : s’adapter aux mises en page complexes, au contenu dynamique et même aux changements de structure du site.
- Configuration minimale : pas de code, pas de réglages fastidieux de sélecteurs, pas de maintenance constante.
Dans la vraie vie, les données ne sont pas rangées dans des tableaux parfaits. Les sites modernes utilisent le défilement infini, une navigation en plusieurs étapes, des connexions obligatoires et des données cachées dans des PDF ou des images. Crawler efficacement, c’est surmonter tout cela — pour passer moins de temps sur les tâches ingrates et davantage sur l’analyse et l’action (AIMultiple).
Pourquoi le crawl efficace de sites web est important pour les ventes et les opérations
Pourquoi les équipes métiers accordent-elles autant d’importance au crawl web ? Parce que la bonne donnée — livrée rapidement — peut faire la réussite ou l’échec de votre prochaine campagne, du lancement d’un produit ou d’un trimestre commercial. Voici quelques-uns des cas d’usage les plus courants — et les plus rentables — que je vois chaque semaine :
| Cas d’usage | Bénéfice et retour sur investissement | Résultat exemple |
|---|---|---|
| Génération de leads | Remplir plus vite le pipeline commercial, gagner des heures de recherche de prospects, réduire les erreurs manuelles | Extraire 5 000 leads ciblés pendant la nuit, lancer les campagnes 2 semaines plus tôt, augmenter les rendez-vous de 30 % |
| Suivi des prix concurrents | Permettre une tarification dynamique, réagir en temps réel aux évolutions du marché, protéger les marges | Un détaillant ajuste ses prix chaque jour et constate une hausse des ventes de 4 % |
| Extraction de catalogues produits / stocks | Garder les fiches à jour, réduire la saisie manuelle, éviter la survente ou les mauvais prix | Une équipe e-commerce met à jour 10 000 références par jour et réduit le temps de mise à jour de 90 % |
| Études de marché et analyse d’avis | Obtenir à grande échelle des insights sur le sentiment client et les tendances, repérer les opportunités avant les concurrents | Analyser plus de 10 000 avis, identifier de nouvelles opportunités produit, améliorer les messages marketing |
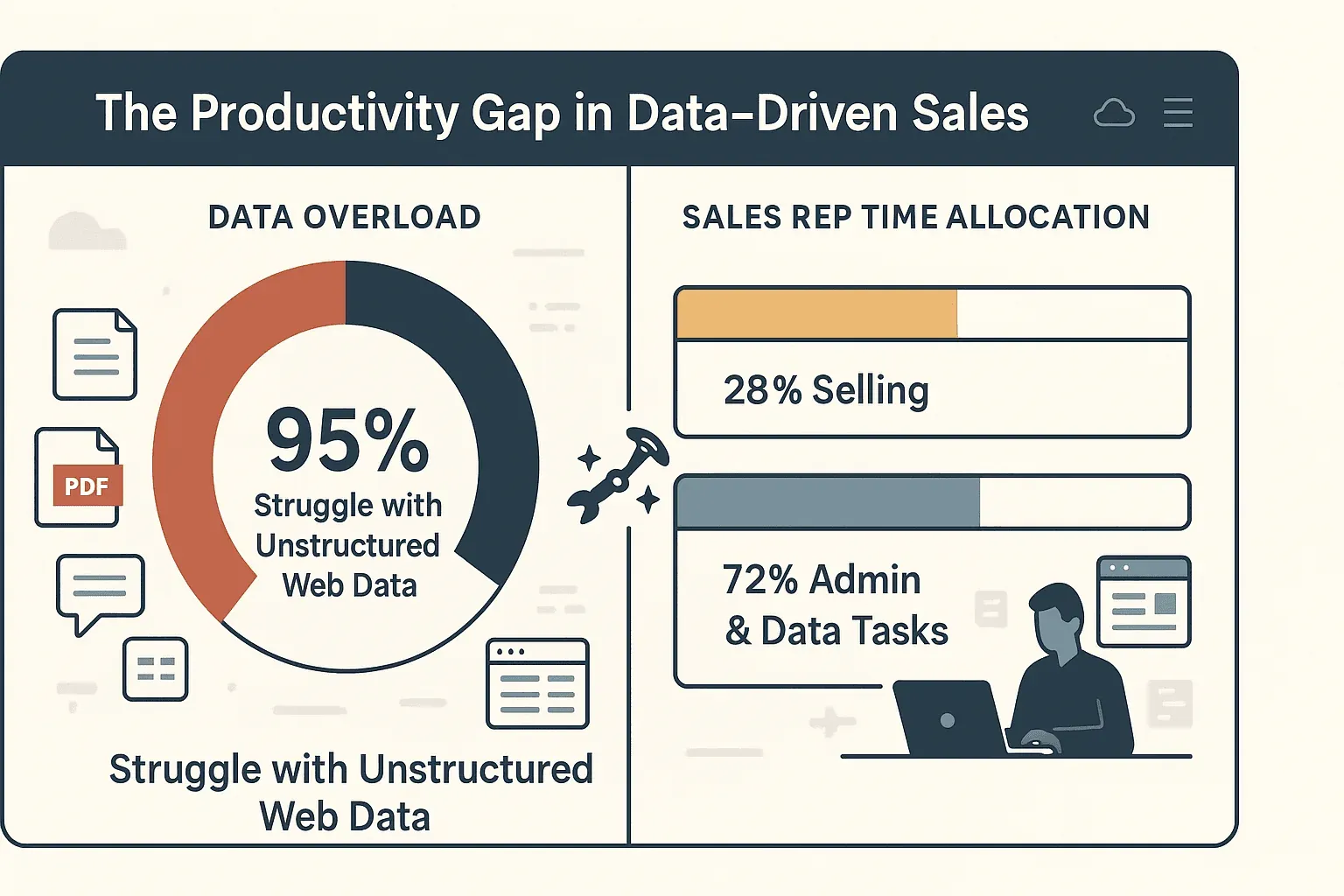
En résumé, un crawl efficace permet de prendre des décisions plus rapides et plus intelligentes — et de passer beaucoup moins de temps à copier-coller. En fait, 95 % des entreprises admettent avoir du mal à exploiter les données web non structurées, et les commerciaux passent seulement 28 % de leur temps à vendre réellement. Le reste se perd dans la saisie manuelle et l’administratif.
Thunderbit : le moyen le plus simple de crawler un site web
Soyons honnêtes : la plupart des outils de web scraping sont conçus pour les développeurs, pas pour les utilisateurs métiers. C’est pour cela que nous avons créé Thunderbit, un extracteur Web alimenté par l’IA, aussi simple à utiliser que de commander un repas à emporter. Voici ce qui distingue Thunderbit :
- Prompts en langage naturel : décrivez simplement les données que vous voulez (« Récupérez tous les noms et prix des produits de cette page »), et l’IA de Thunderbit s’occupe du reste.
- Suggestions de champs IA : cliquez sur « Suggestion de champs IA » et Thunderbit analyse la page, recommande les meilleures colonnes à extraire et configure le crawler pour vous.
- Flux de travail en 2 clics : une fois les champs validés, cliquez sur « Extraire ». C’est tout — pas de code, pas de modèles, pas de prise de tête avec des sélecteurs.
- Gestion de la pagination et des sous-pages : Thunderbit détecte automatiquement les listes multipages et peut suivre les liens vers les pages de détail (sous-pages) pour enrichir vos données.
- Export immédiat : envoyez vos données directement vers Excel, Google Sheets, Airtable ou Notion — ou téléchargez-les en CSV/JSON, gratuitement.
- OCR pour PDF et images : vous avez besoin de données depuis un PDF, une image ou un document scanné ? L’OCR intégré de Thunderbit extrait et structure aussi ce contenu.
Thunderbit est conçu pour les utilisateurs non techniques — si vous pouvez naviguer sur le web et taper une phrase, vous pouvez crawler un site web comme un pro. Et oui, il existe une version gratuite, pour essayer sans risque.
Essayez Thunderbit gratuitement – commencez à crawler instantanément
Comparer les solutions de crawl de sites web : Thunderbit vs. les méthodes traditionnelles
Comparons Thunderbit aux solutions habituelles :
| Approche | Temps de configuration et complexité | Compétences requises | Maintenance et fiabilité |
|---|---|---|---|
| Copier-coller manuel | Extrêmement élevé, non scalable | Aucune, mais source d’erreurs | 100 % manuel, à recommencer à chaque mise à jour |
| Code personnalisé (Python, etc.) | Configuration initiale lourde, heures/jours par site | Programmation requise | Casse dès que le site change, nécessite des corrections constantes |
| Outil no-code traditionnel | Moyen, configuration par clics | Faibles à intermédiaires | Demande des mises à jour en cas de changement de mise en page, ne gère pas toujours les sites dynamiques |
| Thunderbit (piloté par l’IA) | Très faible, configuration en 2 clics | Aucune | L’IA s’adapte aux changements, maintenance minimale |
Les outils traditionnels peuvent vous mener à mi-chemin, mais ils se bloquent souvent sur le contenu dynamique, la pagination ou exigent que vous surveilliez chaque changement. L’IA de Thunderbit lit le site comme le ferait un humain, s’adapte aux nouvelles mises en page et gère les éléments les plus pénibles — vous n’avez donc pas à le faire (Thunderbit Blog).
Étape 1 : configurer votre crawl de site web avec Thunderbit
Se lancer est très simple :
- Installez l’extension Chrome Thunderbit. Créez un compte gratuit.
- Accédez au site cible. Ouvrez la page que vous souhaitez crawler — cela peut être une liste de produits, un annuaire ou même un PDF.
- Ouvrez Thunderbit. Cliquez sur l’icône Thunderbit dans la barre d’outils Chrome.
- Décrivez vos besoins en données. Cliquez sur « Suggestion de champs IA » pour laisser Thunderbit recommander les colonnes, ou tapez une demande en langage naturel (par exemple : « Extraire le nom du produit, le prix et l’URL de l’image pour chaque élément »).
- Prévisualisez et ajustez. Thunderbit affiche un tableau d’aperçu — modifiez les noms de champs, supprimez les éléments superflus ou ajoutez des consignes personnalisées si nécessaire.
Conseil : soyez précis, mais concis, dans vos prompts. Mentionnez les données telles qu’elles apparaissent sur le site (« prix », « adresse », etc.), et laissez l’IA de Thunderbit faire le gros du travail.
Étape 2 : gérer la pagination et les sous-pages pendant le crawl du site web
C’est là que Thunderbit brille vraiment. La plupart des données du monde réel ne tiennent pas sur une seule page — elles sont réparties sur des listes paginées ou cachées dans des sous-pages.
- Pagination : Thunderbit détecte automatiquement les boutons « Suivant », les numéros de page ou le défilement infini. Lorsque vous cliquez sur « Extraire », il charge les pages jusqu’à tout récupérer — sans avoir à saisir des URL manuellement ni à cliquer sur chaque page.
- Crawl de sous-pages : vous avez besoin de plus de détails ? Après l’extraction de la liste principale, cliquez sur « Extraire les sous-pages ». Thunderbit suit les liens (comme les pages de détail produit ou les profils d’entreprise), récupère des informations supplémentaires et les fusionne dans votre tableau.
Exemple : vous extrayez un site e-commerce ? Thunderbit récupère la liste des produits, puis visite la page de détail de chaque produit pour en extraire les spécifications, avis ou images — le tout en une seule fois.
Bonne pratique : laissez Thunderbit terminer le crawl principal, puis utilisez l’extraction des sous-pages pour aller plus loin dans les données. Vous verrez des mises à jour de progression et pourrez surveiller d’éventuelles entrées manquantes.
Étape 3 : extraction intelligente de données non structurées avec Thunderbit
Toutes les données ne se présentent pas sous forme de tableaux bien rangés. Les descriptions produit, avis ou champs au format mixte peuvent être un cauchemar pour les extracteurs traditionnels. L’IA de Thunderbit s’en charge directement :
- Nettoie et met en forme les données : supprime les symboles monétaires, analyse les nombres et découpe les champs complexes (par exemple, « USD 299 (50 % de réduction !) » devient « 299 » et « 50 % de réduction »).
- Analyse les textes complexes : extrait des informations structurées depuis des paragraphes (par exemple, repère « Lieu : New York » dans une description de poste).
- Classe et étiquette : ajoute des catégories ou des tags selon le contenu (par exemple, « Électronique » ou « Vêtements »).
- Gère les incohérences : s’adapte aux champs manquants ou aux changements de mise en page, en gardant vos données alignées et exactes.
- Résume ou traduit : vous avez besoin d’un résumé en une phrase ou d’une traduction ? Ajoutez une consigne personnalisée — l’IA de Thunderbit sait aussi le faire.
Le résultat ? Des données propres et directement exploitables — fini les heures passées à tout nettoyer dans Excel.
Étape 4 : choisir entre crawl dans le cloud et crawl dans le navigateur
Thunderbit vous propose deux façons de crawler, selon vos besoins :
- Crawl dans le navigateur : s’exécute dans votre navigateur Chrome, en utilisant votre session connectée. Parfait pour les sites qui exigent une authentification ou disposent de fortes protections anti-bot. Vous voyez le crawl en temps réel et il reproduit une navigation humaine.
- Crawl dans le cloud : déporte le travail sur les serveurs cloud de Thunderbit. Gère jusqu’à 50 pages en parallèle — idéal pour les gros volumes ou les tâches planifiées. Vous pouvez fermer votre ordinateur portable et laisser Thunderbit faire le travail lourd.
Quand utiliser chaque mode :
- Utilisez le mode navigateur pour les sites nécessitant une connexion ou lorsque vous devez interagir avec la page.
- Utilisez le mode cloud pour les sites publics, les traitements en masse ou lorsque vous voulez vitesse et automatisation.
Le changement de mode est simple : il suffit de choisir votre préférence avant de lancer le crawl.
Étape 5 : extraire des données depuis des documents et des images grâce à l’OCR
Parfois, les données dont vous avez besoin sont piégées dans des PDF, des images ou des documents scannés. L’OCR intégré de Thunderbit (reconnaissance optique de caractères) change la donne :
- PDF : extrayez des tableaux, e-mails ou textes depuis des rapports, factures ou catalogues.
- Images : récupérez du texte depuis des captures d’écran, des étiquettes produit ou même des infographies.
- Formulaires scannés : automatisez la saisie depuis des reçus, contrats ou cartes de visite.
Il vous suffit d’indiquer à Thunderbit l’URL du PDF ou de l’image, et il extraira et structurera le contenu — sans logiciel supplémentaire. Vous pouvez même combiner l’OCR avec des prompts IA pour des extractions avancées (« Trouver toutes les adresses e-mail dans ce PDF »).
Étape 6 : exporter et exploiter les données extraites
Une fois votre crawl terminé, il est temps de mettre ces données au travail :
- Options d’export : téléchargez au format CSV ou JSON, ou exportez directement vers Google Sheets, Excel, Airtable ou Notion. Tous les formats sont gratuits, même dans l’offre de base.
- Ventes et CRM : importez les listes de leads dans votre CRM, lancez des campagnes de prospection ou enrichissez les contacts existants.
- Marketing et analyse : analysez les prix des concurrents, suivez les tendances du marché ou visualisez les données dans des tableaux de bord.
- Opérations et inventaire : surveillez les stocks, mettez à jour les catalogues ou déclenchez des alertes sur les changements importants.
- Automatisation : utilisez des intégrations (comme Zapier ou Google Apps Script) pour automatiser les relances, les reportings ou l’enrichissement des données.
Le format structuré de Thunderbit vous permet de passer du crawl à l’action en quelques minutes — pas en plusieurs jours.
Commencez à crawler avec Thunderbit IA
Conclusion et points clés à retenir
Crawler efficacement un site web n’est pas seulement le rêve d’un passionné de tech — c’est un superpouvoir pour l’entreprise. Avec Thunderbit, tout le monde peut :
- Configurer un crawl en quelques secondes grâce au langage naturel ou aux champs suggérés par l’IA.
- Gérer des sites complexes avec pagination, sous-pages et contenu dynamique — sans code.
- Extraire des données propres et structurées depuis des pages web, des PDF et des images désordonnés.
- Choisir le meilleur mode (navigateur ou cloud) selon la vitesse, l’échelle et la sécurité.
- Exporter les données instantanément vers vos outils et workflows préférés.
L’époque du copier-coller sans fin et des extracteurs cassés est révolue. Téléchargez Thunderbit, essayez un crawl gratuit et voyez combien de temps — et de sérénité — vous pouvez gagner. Votre prochain grand insight, ou votre prochaine victoire commerciale, n’est peut-être qu’à un clic.
Vous voulez davantage de conseils et d’analyses approfondies ? Consultez le Thunderbit Blog pour des tutoriels, des cas d’usage et les dernières nouveautés du crawl web piloté par l’IA.
FAQ
1. Quelle est la différence entre le web crawling et le web scraping ?
Le web crawling consiste à parcourir systématiquement des sites web pour découvrir des pages et des liens, tandis que le web scraping consiste à extraire des données précises depuis ces pages. Thunderbit combine les deux : il trouve, navigue et extrait les informations dont vous avez besoin.
2. Thunderbit peut-il gérer des sites web nécessitant une connexion ?
Oui ! Utilisez le mode navigateur de Thunderbit pour crawler des sites qui exigent une authentification. Il utilise votre session Chrome connectée, ce qui vous permet d’accéder à des données derrière une connexion ou un paywall (dans le respect des conditions d’utilisation du site).
3. Comment Thunderbit gère-t-il la pagination et le défilement infini ?
Thunderbit détecte et navigue automatiquement dans les listes paginées et les pages à défilement infini. Il clique sur « Suivant », fait défiler la page ou charge davantage de contenu jusqu’à ce que toutes les données soient capturées — sans configuration manuelle.
4. Quels types de données Thunderbit peut-il extraire ?
Thunderbit peut extraire du texte, des nombres, des dates, des URL, des e-mails, des numéros de téléphone, des images, et même des données depuis des PDF et des images grâce à l’OCR. Vous pouvez personnaliser les champs et utiliser des prompts IA pour des structurations et nettoyages avancés.
5. Thunderbit est-il gratuit ?
Thunderbit propose une offre gratuite qui vous permet de crawler un nombre limité de pages. Tous les formats d’export (CSV, Excel, Google Sheets, Airtable, Notion) sont inclus gratuitement. Les offres payantes commencent à 15 $/mois pour des volumes plus élevés et des fonctionnalités avancées.
Prêt à crawler plus intelligemment, pas plus difficilement ? Essayez Thunderbit dès aujourd’hui et laissez l’IA faire le gros du travail pour votre prochain projet de données web. En savoir plus
- Comment crawler un site web ? Guide pour débutants
- Comment crawler des sites web : guide étape par étape pour débutants
- Comment crawler tous les liens d’un site web : guide complet
Essayez gratuitement l’extracteur Web IA Get Started Free




