
Le monde tourne grâce aux données, et en 2026, le besoin de transformer les données du web en insights métiers n’a jamais été aussi fort. J’ai pu constater de première main à quel point les équipes commerciales, opérations et marketing se lancent dans l’automatisation de la recherche, la veille concurrentielle et la création de pipelines plus intelligents — le tout porté par le web scraping. Mais attention : maîtriser le web scraping ne consiste pas seulement à lire quelques tutoriels. Il faut mettre les mains dans le cambouis et s’entraîner sur de vrais sites, parfois franchement retors.
Trouver le bon site test pour le web scraping peut vite ressembler à chercher une aiguille dans une botte de foin. Certains sites sont trop simples, d’autres sont protégés par des défenses anti-bot, et quelques-uns sont tout simplement étranges. C’est pourquoi j’ai rassemblé cette liste des 10 meilleurs sites d’exemple pour s’entraîner au web scraping — sélectionnés pour vous aider à développer de vraies compétences, des bases pour débutants jusqu’à la gestion avancée de données dynamiques. Que vous vouliez extraire des annonces e-commerce, des forums ou des avis de films, ce guide vous aidera à passer au niveau supérieur et à éviter le « 404 » de la frustration du scraping.
Pourquoi s’entraîner au web scraping sur des sites d’exemple ?
Soyons francs : le web scraping est un sport de terrain. Bien sûr, vous pouvez regarder autant de tutoriels YouTube que vous voulez, mais tant que vous ne vous êtes pas frotté à du vrai HTML, à du contenu dynamique et au CAPTCHA occasionnel, vous n’avez pas vraiment appris les bases. S’entraîner sur des sites de test pour le web scraping est la meilleure façon de :
- Comprendre différentes structures de données : des tableaux simples aux listes imbriquées, en passant par le contenu chargé en AJAX, chaque site est une nouvelle énigme.
- Tester vos outils et vos compétences : voyez comment votre scraper — ou votre outil préféré, comme — gère la pagination, les sous-pages et les astuces anti-bot.
- Préparer des cas d’usage métier : le scraping en conditions réelles alimente dans les entreprises du monde entier.
Les chiffres parlent d’eux-mêmes : le marché mondial du web scraping était évalué à , et près de affirment que la prise de décision fondée sur les données est « cruciale » pour leur réussite. Mais le vrai secret ? Les meilleurs scrapeurs ne sont pas seulement des développeurs : ce sont des testeurs acharnés, qui affinent sans cesse leurs compétences sur de nouveaux sites.
Comment nous avons sélectionné les meilleurs sites pour s’entraîner au web scraping
Tous les sites d’exemple pour le web scraping ne se valent pas. Pour cette liste, je me suis concentré sur des sites qui :
- Proposent une variété de types de données : texte, nombres, images, notes, avis et plus encore.
- Offrent différents niveaux de complexité : du HTML statique aux pages dynamiques riches en JavaScript.
- Sont légaux et sûrs à scraper : soit explicitement conçus pour l’entraînement, soit composés de pages publiques sans connexion requise.
- Reproduisent des scénarios métier réels : e-commerce, forums, avis, etc.
- Vous exposent à des mesures anti-scraping : car, sur le terrain, il faudra gérer les CAPTCHA, les limites de requêtes et l’AJAX.
Je me suis aussi assuré que ces sites soient excellents pour tester à la fois les scrapers traditionnels basés sur du code et les outils modernes sans code comme Thunderbit. Prêt à vous lancer ? C’est parti.
1. Thunderbit : le site de test tout-en-un pour le web scraping
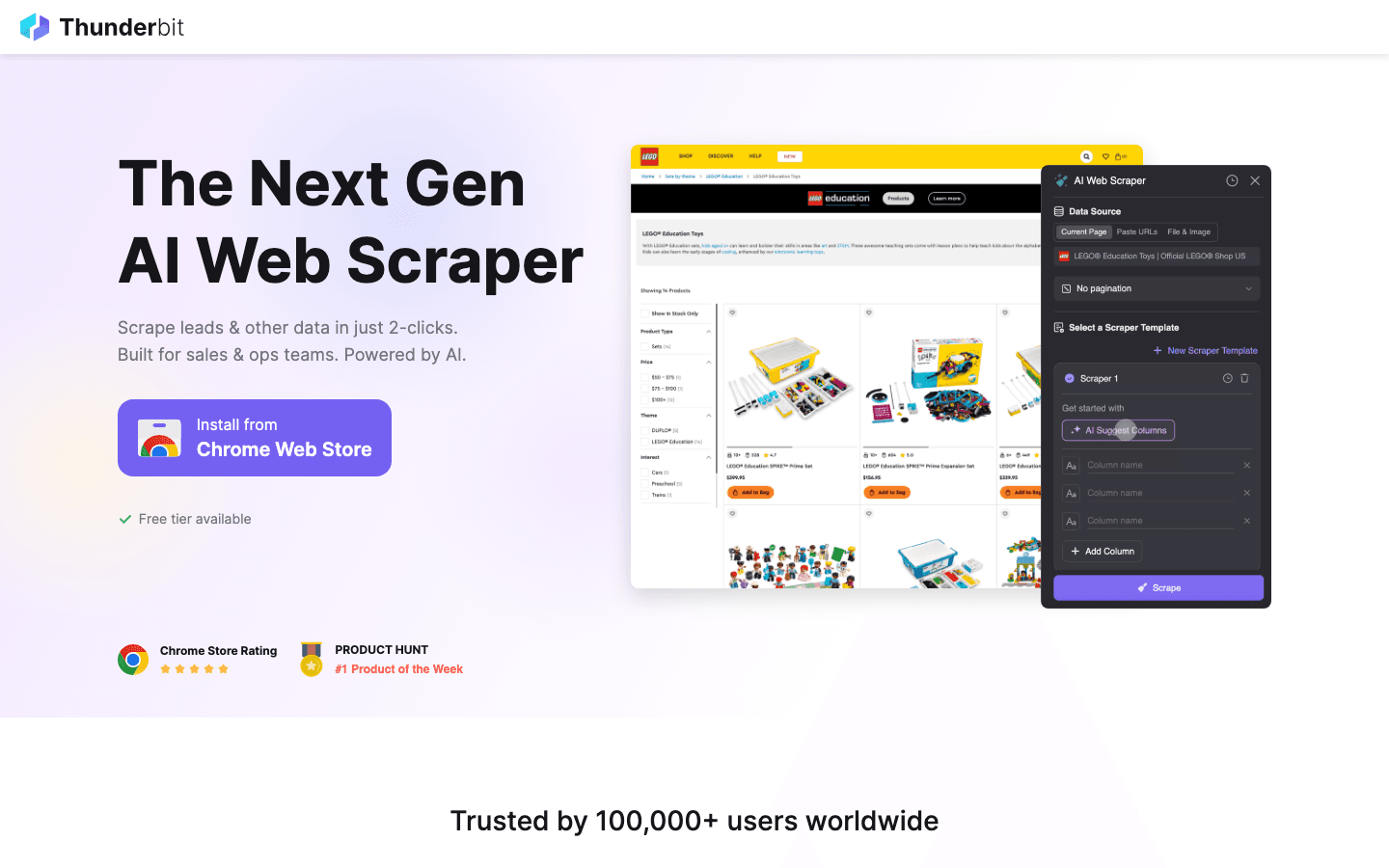
n’est pas seulement un outil — c’est un terrain de jeu pour toute personne qui prend le web scraping au sérieux. Ayant passé des années à construire puis à casser des scrapers, je peux vous le dire : Thunderbit est mon outil de référence pour tester aussi bien des listes simples que des sites e-commerce dynamiques particulièrement coriaces.
Pourquoi Thunderbit se démarque :
- Scraping assisté par IA : cliquez simplement sur « AI Suggest Fields », et Thunderbit lit la page, identifie les meilleures colonnes et écrit même la logique d’extraction pour vous. Pas de code, pas de prise de tête avec les sélecteurs.
- Gère les sites complexes : Thunderbit excelle sur le HTML difficile, le contenu dynamique et les sites avec sous-pages ou défilement infini. C’est comme avoir un couteau suisse du web scraping.
- Prise en charge des sous-pages et de la pagination : vous devez extraire des listes de produits puis visiter chaque page de détail pour obtenir plus d’informations ? Le scraping de sous-pages de Thunderbit simplifie tout.
- Export de données instantané : exportez vos résultats vers Excel, Google Sheets, Airtable ou Notion — gratuitement et sans limite.
- Extracteurs gratuits : des outils en un clic pour les e-mails, numéros de téléphone et images. Parfait pour s’exercer à la prospection commerciale et à la génération de leads.
- Modèles pour les sites populaires : Amazon, Zillow, Shopify, et bien d’autres — il suffit de choisir un modèle et de lancer.
- Adapté aux débutants : les utilisateurs non techniques apprécient de ne « pas avoir grand-chose à apprendre » pour commencer ().
Scénarios d’entraînement :
- Extraire des annonces e-commerce (comme Amazon ou eBay) avec enrichissement via sous-pages.
- Extraire les coordonnées de répertoires d’entreprises.
- Automatiser des extractions répétitives de données pour l’étude de marché.
Thunderbit est le seul site de test de cette liste qui vous permet de vous entraîner à la fois sur l’extraction et sur l’automatisation des workflows. Et oui, c’est gratuit à essayer — vous pouvez donc constater par vous-même pourquoi c’est mon premier choix pour tous les niveaux.
2. Codeforces : s’entraîner au scraping de données de programmation structurées
 est une véritable mine d’or pour toute personne qui souhaite s’exercer à extraire des données structurées sous forme de tableaux. Cette plateforme de programmation compétitive propose :
est une véritable mine d’or pour toute personne qui souhaite s’exercer à extraire des données structurées sous forme de tableaux. Cette plateforme de programmation compétitive propose :
- Listes de concours : avec des tableaux de noms, dates et liens.
- Jeux de problèmes : tableaux imbriqués avec noms de problèmes, tags et niveaux de difficulté.
- Classements utilisateurs : tableaux de classement et profils utilisateurs avec points et statistiques.
Pourquoi c’est idéal pour s’entraîner :
- Vous apprend à analyser des tableaux HTML, des listes imbriquées et des résultats multipages.
- La plupart des données sont en HTML statique — pas de connexion ni de JavaScript à gérer.
- Reproduit des scénarios réels comme le scraping d’offres d’emploi ou de résultats académiques.
Astuce : essayez d’extraire tous les problèmes d’un concours, ou de construire un classement des meilleurs utilisateurs. Vous obtiendrez un cours accéléré sur la gestion des données structurées et de la pagination.
3. Books to Scrape : le grand classique des sites d’entraînement au web scraping
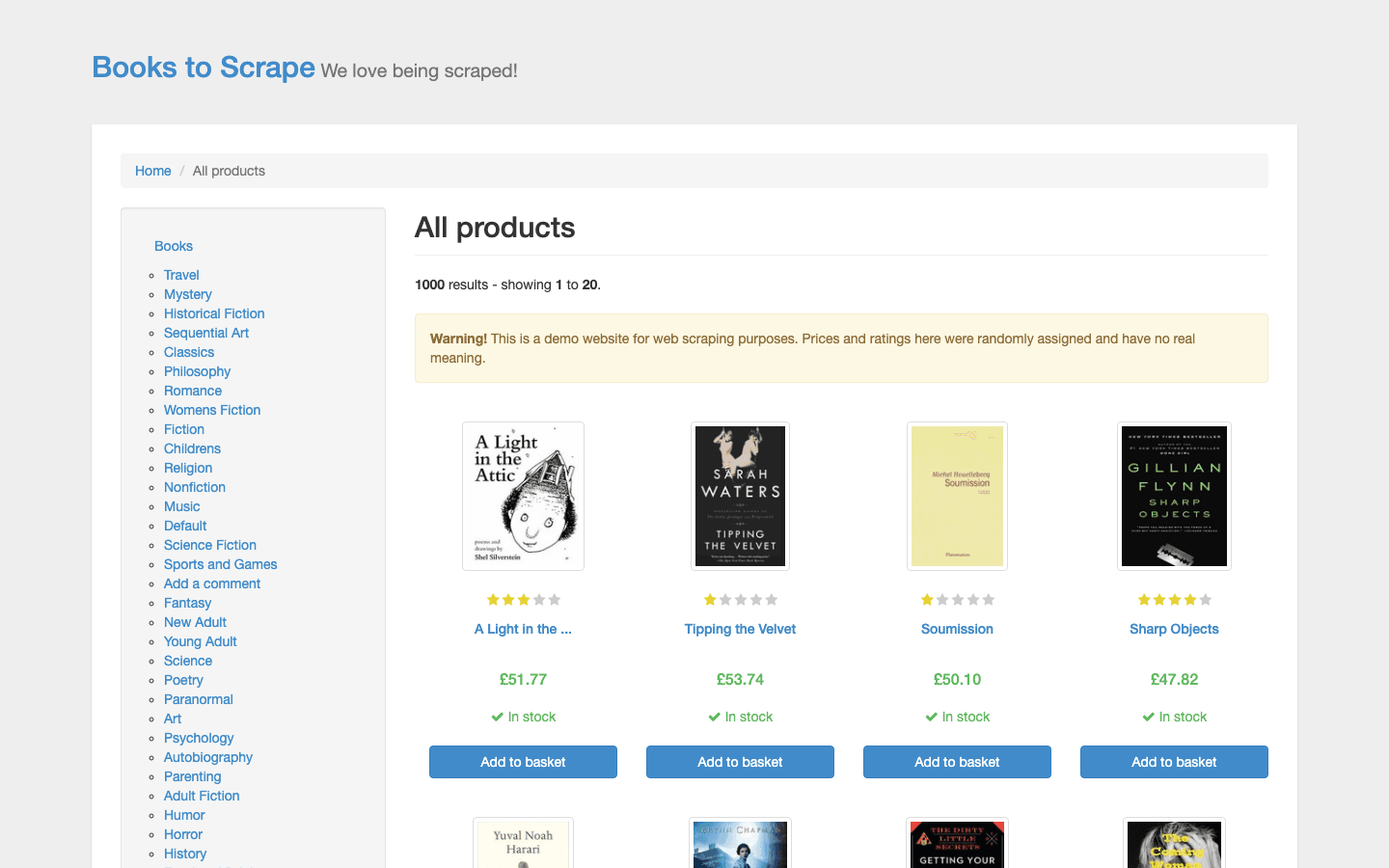 est le « hello world » du web scraping. Cette librairie en ligne fictive est conçue pour les débutants, mais ne vous y trompez pas : c’est un excellent endroit pour maîtriser les bases.
est le « hello world » du web scraping. Cette librairie en ligne fictive est conçue pour les débutants, mais ne vous y trompez pas : c’est un excellent endroit pour maîtriser les bases.
Ce que vous y trouverez :
- Listes de produits en HTML statique : titres, prix, notes et catégories.
- Pagination : entraînez-vous à scraper plusieurs pages.
- Structure cohérente : idéale pour apprendre les sélecteurs et les boucles.
Exercices d’entraînement :
- Extraire tous les titres et prix des livres.
- Scraper les notes et la disponibilité.
- Gérer la pagination pour obtenir le catalogue complet.
Ce site est si populaire dans les tutoriels parce qu’il est sûr, prévisible et parfait pour gagner en confiance avant d’affronter le web sauvage ().
4. HackerRank : s’entraîner au scraping de texte et de données algorithmiques
 devient plus corsé. Cette plateforme de défis de programmation regorge de :
devient plus corsé. Cette plateforme de défis de programmation regorge de :
- Contenu dynamique : descriptions de défis, cas de test et classements.
- Profils utilisateurs : statistiques, badges et rangs.
- Connexion/authentification : de nombreuses pages nécessitent une session utilisateur.
Pourquoi c’est un excellent site de test :
- Vous apprend à gérer les flux de connexion et les cookies de session.
- Vous expose à du contenu rendu en JavaScript et à l’AJAX.
- Parfait pour s’entraîner à scraper des défis de programmation, des statistiques utilisateur ou des résultats de concours.
Si vous voulez apprendre à scraper des sites qui ne se laissent pas faire avec de simples requêtes HTTP, HackerRank est votre terrain d’entraînement.
5. Web Scraper Test : un site de test dédié au web scraping
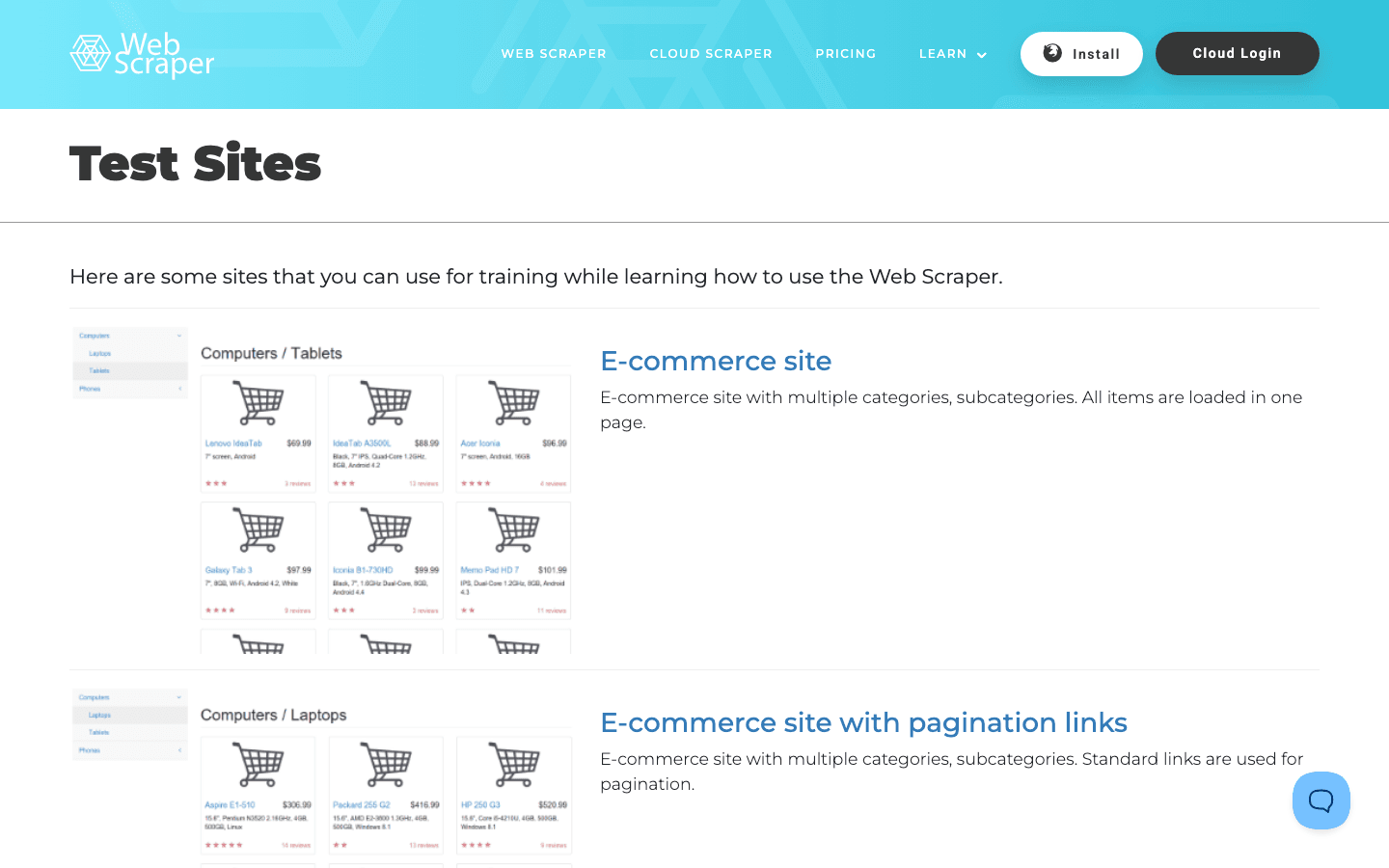 a été conçu spécialement pour des personnes comme nous — des passionnés du scraping qui veulent s’exercer sur des scénarios pensés à cet effet.
a été conçu spécialement pour des personnes comme nous — des passionnés du scraping qui veulent s’exercer sur des scénarios pensés à cet effet.
Ce qu’il contient :
- Pages e-commerce : à la fois statiques et alimentées par AJAX.
- Tableaux et catégories imbriquées : des listes simples aux menus à plusieurs niveaux.
- Contenu dynamique : testez la capacité de votre scraper à gérer JavaScript.
Pourquoi c’est génial :
- Aucune mesure anti-bot — vous pouvez scraper sans crainte.
- Permet d’évaluer les performances de votre outil sur des pages statiques versus dynamiques.
- Excellent pour comparer la façon dont Thunderbit et d’autres scrapers gèrent différents types de sites ().
Si vous voulez un bac à sable sûr pour pousser votre scraper à ses limites, c’est l’endroit idéal.
6. eBay : s’entraîner au web scraping e-commerce en conditions réelles
 est l’endroit où le web scraping rencontre le monde réel. Avec des millions d’annonces produits, c’est une référence pour s’exercer à :
est l’endroit où le web scraping rencontre le monde réel. Avec des millions d’annonces produits, c’est une référence pour s’exercer à :
- L’extraction de données produits : titres, prix, images, informations sur le vendeur.
- La pagination et le filtrage : scraper à travers les catégories ou les résultats de recherche.
- Le contenu dynamique : annonces et avis chargés via AJAX.
Défis :
- eBay utilise des CAPTCHA, des limites de requêtes et du HTML dynamique pour bloquer les bots ().
- Vous devrez apprendre à utiliser des proxies, des user agents et des techniques de scraping respectueuses.
Cas d’usage métier :
- Suivi des prix, analyse concurrentielle et étude de marché.
Si vous savez scraper eBay, vous êtes prêt pour presque n’importe quel défi e-commerce.
7. Amazon : le site de test ultime pour le web scraping e-commerce
 est le boss final du web scraping. Avec plus de 12 millions de produits et certaines des défenses anti-bot les plus redoutables au monde, c’est le test ultime pour n’importe quel scraper.
est le boss final du web scraping. Avec plus de 12 millions de produits et certaines des défenses anti-bot les plus redoutables au monde, c’est le test ultime pour n’importe quel scraper.
Exercices d’entraînement :
- Extraire les détails produits, les prix, les notes et les avis.
- Gérer le défilement infini, les éléments dynamiques et les données imbriquées.
- Respecter les mesures anti-bot : bannissements d’IP, fingerprinting des requêtes, et plus encore ().
Pourquoi s’y frotter ?
- Scraper Amazon vous apprend des techniques avancées comme la rotation de proxies et l’automatisation du navigateur.
- C’est la meilleure façon de vous entraîner pour de vrais projets e-commerce — en gardant toujours à l’esprit qu’il faut scraper de manière responsable et respecter les conditions d’Amazon.
8. Yelp : s’entraîner à extraire des fiches d’entreprises et des avis
 est une mine d’or pour toute personne intéressée par les données d’entreprises locales, les avis et les notes.
est une mine d’or pour toute personne intéressée par les données d’entreprises locales, les avis et les notes.
Ce que vous pouvez extraire :
- Noms d’entreprises, catégories, notes et adresses.
- Avis des utilisateurs (texte, date, note).
- Images et niveaux de prix.
Défis :
- Yelp a renforcé ses défenses anti-scraping, notamment les CAPTCHA et les limites de requêtes API ().
- Idéal pour pratiquer la configuration d’outils et un scraping respectueux.
Intérêt métier :
- Étude de marché locale, génération de leads et analyse de sentiment.
9. Stack Overflow : scraper les questions-réponses et les insights développeurs
 est le plus grand site Q&R du monde pour les développeurs — et un excellent site de test pour le web scraping.
est le plus grand site Q&R du monde pour les développeurs — et un excellent site de test pour le web scraping.
Possibilités d’entraînement :
- Scraper les questions, réponses, tags et profils utilisateurs.
- Gérer la pagination et les commentaires imbriqués.
- Utiliser l’API publique pour un accès responsable aux données.
Pourquoi c’est utile :
- Vous apprend à scraper des forums et des sites communautaires.
- Excellent pour construire des jeux de données destinés à l’analyse des tendances ou à l’extraction de connaissances.
Stack Overflow est en grande partie en HTML statique, ce qui le rend accessible aux débutants, mais son ampleur et sa structure offrent aussi de nombreux défis avancés.
10. Rotten Tomatoes : scraper les avis et notes de films
 est le site de référence pour les notes de films, les critiques et les scores du public.
est le site de référence pour les notes de films, les critiques et les scores du public.
Ce que vous y trouverez :
- Titres de films, scores des critiques et du public, et extraits d’avis.
- Contenu dynamique chargé via AJAX et API cachées.
- Certaines fonctionnalités nécessitent une connexion ou des techniques de scraping avancées ().
Exercices d’entraînement :
- Extraire les notes de films et des extraits d’avis.
- Faire de la rétro-ingénierie sur les appels API pour obtenir des données JSON.
- Gérer le contenu dynamique et les mesures anti-bot.
Rotten Tomatoes est un défi de fin de parcours — si vous parvenez à le scraper, vous êtes prêt pour presque n’importe quel projet d’extraction de données.
Tableau comparatif : les sites d’entraînement au web scraping en un coup d’œil
| Site web | Types de données | Complexité | Anti-scraping | Meilleur cas d’usage |
|---|---|---|---|---|
| Thunderbit | Tout (texte, images, e-mails, téléphones, etc.) | Tous niveaux | N/A (outil, pas un site) | S’entraîner sur n’importe quel site, tester des workflows |
| Codeforces | Tableaux, classements, statistiques utilisateur | Moyen | Faible | Analyse de données structurées, concours |
| Books to Scrape | Titres, prix, notes, catégories | Faible | Aucun | Web scraping e-commerce pour débutants |
| HackerRank | Défis, profils utilisateur, classements | Élevée | Connexion, lourd en JS | Contenu dynamique, authentification |
| Web Scraper Test | Produits, tableaux, pages imbriquées | Variable | Aucun | Comparaison d’outils, statique/dynamique |
| eBay | Annonces, prix, images, infos vendeur | Élevée | CAPTCHA, limites de requêtes | E-commerce réel, suivi des prix |
| Amazon | Produits, avis, images, prix | Très élevée | Bannissements IP, fingerprinting | Web scraping e-commerce avancé |
| Yelp | Entreprises, avis, notes, images | Élevée | CAPTCHA, limites API | Données d’entreprises locales, avis |
| Stack Overflow | Q&R, tags, statistiques utilisateur | Moyenne | Faible, API disponible | Scraping de forums, insights développeurs |
| Rotten Tomatoes | Films, notes, avis, critiques | Élevée | AJAX, API cachée | Analyse d’avis, contenu dynamique |
Conclusion : passez au niveau supérieur avec les bons sites d’entraînement au web scraping
Si vous voulez devenir bon en web scraping, rien ne remplace la pratique concrète. Les sites ci-dessus offrent une progression allant de bacs à sable adaptés aux débutants jusqu’à de véritables champs de bataille anti-bot. Commencez par quelque chose de simple comme Books to Scrape, puis progressez vers des géants dynamiques comme Amazon ou Rotten Tomatoes.
N’oubliez pas : l’outil que vous utilisez compte autant que le site sur lequel vous vous entraînez. est mon premier choix pour les utilisateurs métiers et pour toute personne qui veut aller vite, automatiser ses workflows et gérer même les sites les plus chaotiques. Mais quel que soit votre choix, continuez à expérimenter, continuez à apprendre, et scrapez toujours de manière responsable — respectez robots.txt, les limites de requêtes et la vie privée.
Vous voulez aller plus loin ? Consultez le pour d’autres guides, ou rejoignez une communauté de web scraping pour échanger astuces et défis. Le web est votre terrain de jeu — allez y extraire quelque chose d’incroyable.
FAQ
1. Pourquoi devrais-je m’entraîner au web scraping sur des sites d’exemple plutôt que sur de vrais sites métiers ?
Les sites d’exemple sont conçus pour une pratique sûre et légale. Ils vous permettent de développer vos compétences, de tester des outils et d’expérimenter sans risquer de bannissements ou de problèmes juridiques. Une fois en confiance, vous pourrez vous attaquer à des projets réels de manière plus responsable.
2. Qu’est-ce qui fait de Thunderbit un bon site de test pour le web scraping ?
Thunderbit n’est pas seulement un site de test — c’est un outil alimenté par l’IA qui vous permet de pratiquer le scraping sur n’importe quel site, du plus simple au plus complexe. Ses fonctions comme les suggestions de champs par IA, le scraping de sous-pages et les exports instantanés le rendent idéal pour les débutants comme pour les utilisateurs avancés.
3. Comment gérer les mesures anti-scraping sur des sites comme eBay ou Amazon ?
Commencez par respecter les limites de requêtes et robots.txt. Pour les sites plus difficiles, vous devrez peut-être utiliser des proxies, faire tourner les user agents ou simuler le comportement d’un navigateur. S’entraîner sur ces sites vous aide à apprendre à adapter votre approche.
4. Y a-t-il des risques juridiques liés au web scraping ?
Vérifiez toujours les conditions d’utilisation d’un site et son fichier robots.txt. Pour vous entraîner, limitez-vous aux pages publiques sans connexion et évitez d’extraire des données personnelles ou sensibles. En cas de doute, utilisez des sites d’exemple ou les API officielles.
5. Quelle est la meilleure façon de progresser en web scraping ?
Commencez par des sites pour débutants comme Books to Scrape, puis passez aux données structurées (Codeforces), au contenu dynamique (HackerRank) et aux défis du monde réel (Amazon, Yelp). Utilisez des outils comme Thunderbit pour automatiser et fluidifier votre workflow, et continuez à apprendre auprès de la communauté.
Bon scraping — et que vos données soient toujours propres, structurées et prêtes à l’action.
En savoir plus