三週前,我坐下來研究 Etsy 上「客製寵物肖像」賣家。47 個瀏覽器分頁、2 小時的複製貼上,再加上一份亂成一團的試算表之後,我還是沒辦法清楚看出定價、評論,以及哪些賣家在投廣告、哪些又是自然排名。這段經歷,就是我啟動這個專案的原因。
Etsy 現在有、560 萬活躍賣家,以及 8,650 萬活躍買家。這是一個龐大又嘈雜的市場——如果您是賣家、行銷人員,或是想了解自己利基市場表現的電商研究者,您需要的是結構化資料,而不是一堆開著的分頁。問題是?到了 2026 年,Etsy 的反機器人防護已經變得非常複雜。動態頁面結構、TLS 指紋辨識、CAPTCHA,以及行為分析,讓過去那種隨手寫個 Python 腳本就收工的日子幾乎一去不復返。
過去幾週,我實際把六款 Etsy 爬蟲逐一對比測試——從免寫程式的 AI 工具到開發者 API 都有——接下來我會直接告訴您哪些真的有效、哪些不行,以及哪一款適合哪一類使用者。我也會說明您實際能抓到哪些資料(以及哪些抓不到)、Etsy API 與爬蟲之間的爭論、真實使用情境,以及如何驗證結果,避免最後拿錯誤資料做決策。
為什麼抓 Etsy 比您想得更難
如果您曾經想抓 Etsy 卻碰壁,不是只有您這樣。Etsy 不是靜態型目錄,而是一個動態、個人化的市場。搜尋結果、廣告、徽章、運送資訊,甚至頁面上的 CSS class 名稱,都可能在不同工作階段、裝置和國家之間改變。
先用最簡單的方式說明 Etsy 難在哪裡:
- 動態頁面結構: Etsy 前端經常變動。昨天還能用的選擇器,今天可能就抓到空白。就像 Etsy 每隔幾小時就換一次門鎖——對一般購物者來說頁面看起來還是熟悉的,但爬蟲依賴的資料鉤點卻可能毫無預警地改變。
- 機器人管理系統: 像 這類爬蟲供應商公開指出,Etsy 使用「積極的反機器人防護」,而且工作階段可能會被封鎖。有些 Actor 頁面還提到可避開 DataDome 的 URL 模式,以及模擬 Chrome TLS 指紋。更廣泛來看, 指出,2025 年自動化流量占了所有網路流量的 53%,而 則顯示機器人占整體網路流量的 42.1%;電商網站正是主要目標。
- CAPTCHA 與速率限制: 大量抓取可能觸發 CAPTCHA,甚至直接被封鎖。 甚至提到,如果出現 CAPTCHA,使用者可以暫停任務並手動解題。
- 贊助結果與個人化: Etsy 的搜尋結果會混合自然與付費列表,而且 。如果您沒有追蹤哪些結果是廣告,競品分析很可能會失真。
這些都不代表 Etsy 不能抓,而是代表您選的工具比以前重要得多。

您到底能從 Etsy 抓到哪些資料?
這一段是我希望每篇競品文章都會寫、但幾乎沒人寫的內容。在選工具之前,您必須先知道實際能做到什麼。
從 Etsy 搜尋結果可取得的資料
搜尋結果頁能提供廣度。一般來說,您可以從商品格狀列表中擷取以下內容:
- 商品標題
- 價格(目前價格、特價、原價,若有顯示)
- 貨幣
- 主圖網址
- 商品頁網址 / 商品 ID
- 商店名稱(若有顯示——廣告有時會顯示「Ad by Etsy Seller」)
- 評分
- 評論數
- 免運徽章
- 熱銷 / Etsy's Pick / Star Seller 徽章
- 贊助 / 廣告標示
- 頁碼與位置
- 查詢字詞、篩選、排序,以及國家 / 工作階段中繼資料
例如, 會公開 listingId、name、url、imageUrl、shop、shopId、price、originalPrice、currency、onSale、freeShipping、rating、availability、position、query、page 與 scrapedAt 等欄位,這對驗證哪些資料真的抓得出來很有幫助。
需要逐一進入商品頁才能取得的資料(子頁面抓取)
搜尋卡片刻意做得很精簡。如果您真的在做商品研究,就需要更深一層才看得到的欄位:
- 完整描述
- 完整圖片相簿與影片網址
- 規格與客製化選項
- 商品細節(材質、屬性、尺寸)
- 製作時間
- 運送細節與送達預估
- 賣家 / 商店檔案資訊與政策
- 評論片段或完整評論
- 相關商品
也確認賣家會填入標題、分類、屬性、價格、規格、客製化、描述、運送設定檔、製作 / 運送細節,以及商品尺寸 / 重量——所以這些欄位確實存在,只是您得進頁面才拿得到。
這正是子頁面抓取真正有價值的地方。以 為例,您可以先抓 Etsy 搜尋結果頁的標題、價格和評分,再點一下「抓取子頁面」,讓 AI 逐一拜訪每個商品頁,將標籤、材質、運送細節與賣家資訊補進表格,而完全不需要額外設定。Thunderbit 的欄位 AI 提示詞也能讓您針對每一欄加入自訂指令(例如:「將此商品分類為 Jewelry / Home Decor / Clothing」)。
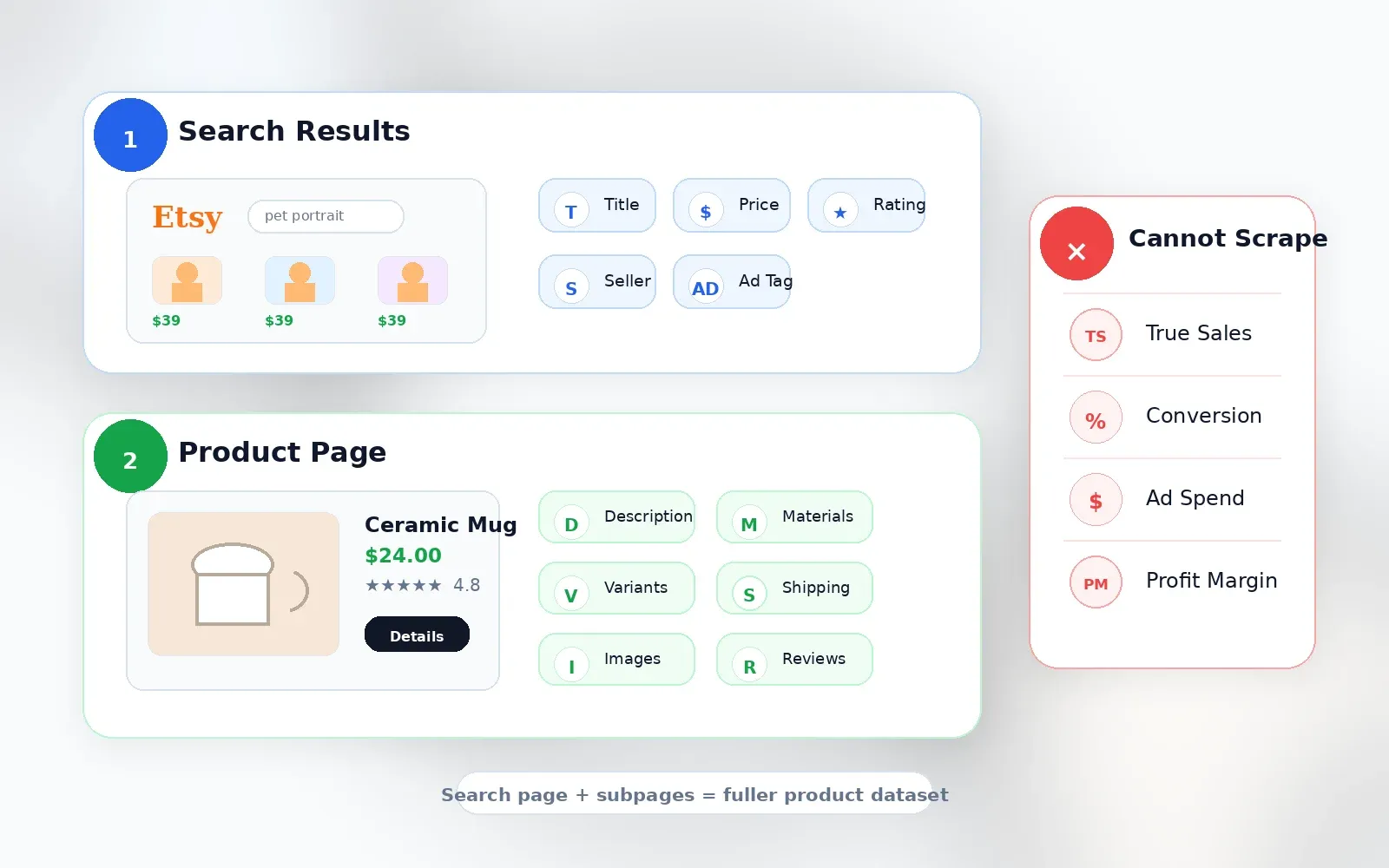
爬蟲無法告訴您的事
我想先把話說清楚,因為很多工具就是在這裡失去可信度:
| 資料點 | 能否透過爬蟲取得? | 說明 |
|---|---|---|
| 每個商品的實際銷售量 | 否 | Etsy 不會公開顯示每個商品的精確銷售數。商店層級的銷售量可能可見,但商品層級不會。 |
| 轉換率 | 否 | 這是賣家分析數據,不是公開資料。 |
| 真正的關鍵字搜尋量 | 否 | Etsy Marketplace Insights 會在賣家工具中顯示 30 天資料,但這不是公開可抓欄位。 |
| 廣告花費 / 出價資料 | 否 | 這不是公開列表資料。 |
| 利潤率 | 否 | 價格與運費看得到;生產成本、手續費與退貨成本看不到。 |
任何宣稱能精確抓到 Etsy 競品銷售數字的工具,其實都是在估算,不是在抓公開事實。 像 、 和 都明確說明它們使用的是估算演算法,而不是直接取得資料。
Etsy API 與爬蟲:您到底需要哪一個?
這是我在論壇最常看到的問題:「既然 Etsy API 不提供關鍵字資料,那應該就是大家都在抓吧?」這種混淆很常見,所以這裡直接整理清楚。
| 面向 | Etsy 官方 API | 網頁爬蟲 |
|---|---|---|
| 最佳用途 | 管理自己的商店、商品、庫存、訂單、付款 | 競品研究、搜尋監控、價格情報、子頁面補全 |
| 商品資料 | 商品搜尋與詳細資料端點 | 任何公開的搜尋 / 商品 / 商店 / 評論頁面 |
| 自家商店銷售 / 訂單 | 可以,需授權 / scope | 不需要;使用 API / Shop Manager 即可 |
| 競品精確銷售數 | 否 | 否(只能估算) |
| 關鍵字搜尋量 | 不作為公開 Open API 端點提供 | 不能直接取得;Marketplace Insights 屬於賣家介面 |
| 速率限制 | 依應用而定的 QPS / QPD;429 處理 | 取決於工具 / 平台 |
| 條款立場 | 在條款範圍內使用屬官方路徑 | Etsy 條款限制未經授權的抓取 |
| 輸出 | JSON API 回應 | CSV / Sheets / JSON / HTML,依工具而定 |
結論很簡單:如果您要管理自己的商店,就用 API;如果您想理解競爭對手、監控價格,或研究利基市場,抓取才是實際可行的路徑。像 eRank 和 Alura 這類工具,很可能是把 API 存取、抓取與估算結合起來——現在您知道原因了。
無程式碼 vs. 程式碼:怎麼挑選最適合的 Etsy 爬蟲
大多數搜尋「最佳 Etsy 爬蟲」的人,並不是在做基礎設施開發的工程師。他們是賣家、行銷人員、虛擬助理,或是想拿到一張可用表格的電商研究者。但許多競品文章卻一直在講 API 工具或 Python 函式庫。這兩者根本對不上。
我的判斷框架如下:
| 如果您是... | 建議選... | 原因 |
|---|---|---|
| 非技術型賣家或行銷人員 | Thunderbit | AI 欄位建議、Chrome 擴充功能、子頁面抓取、直接匯出、排程抓取 |
| 不會寫程式但喜歡視覺化流程 | Octoparse | 桌面視覺化流程建構器、範本、自動偵測、雲端模式 |
| 需要長期承接 Etsy 任務的自由工作者或小型代理商 | Apify | 雲端 Actors、排程器、API、按結果計費選項 |
| 建立內部管線的開發者 | ScrapingBee 或 ZenRows | API 傳輸、JS 渲染、代理 / CAPTCHA 處理;解析與儲存由您掌控 |
| 企業資料團隊 | Bright Data | 代管式爬蟲 API / 資料集、交付選項、正常運行與合規立場 |
這裡的「無程式碼」對這個族群而言,意思是:不需要代理設定、不需要 CSS 選擇器、不需要終端機指令、不需要無頭瀏覽器管理,也不需要自訂重試邏輯或資料庫設定。您可以直接匯出到試算表或工作工具,而子頁面補全也不必自己寫點擊迴圈。
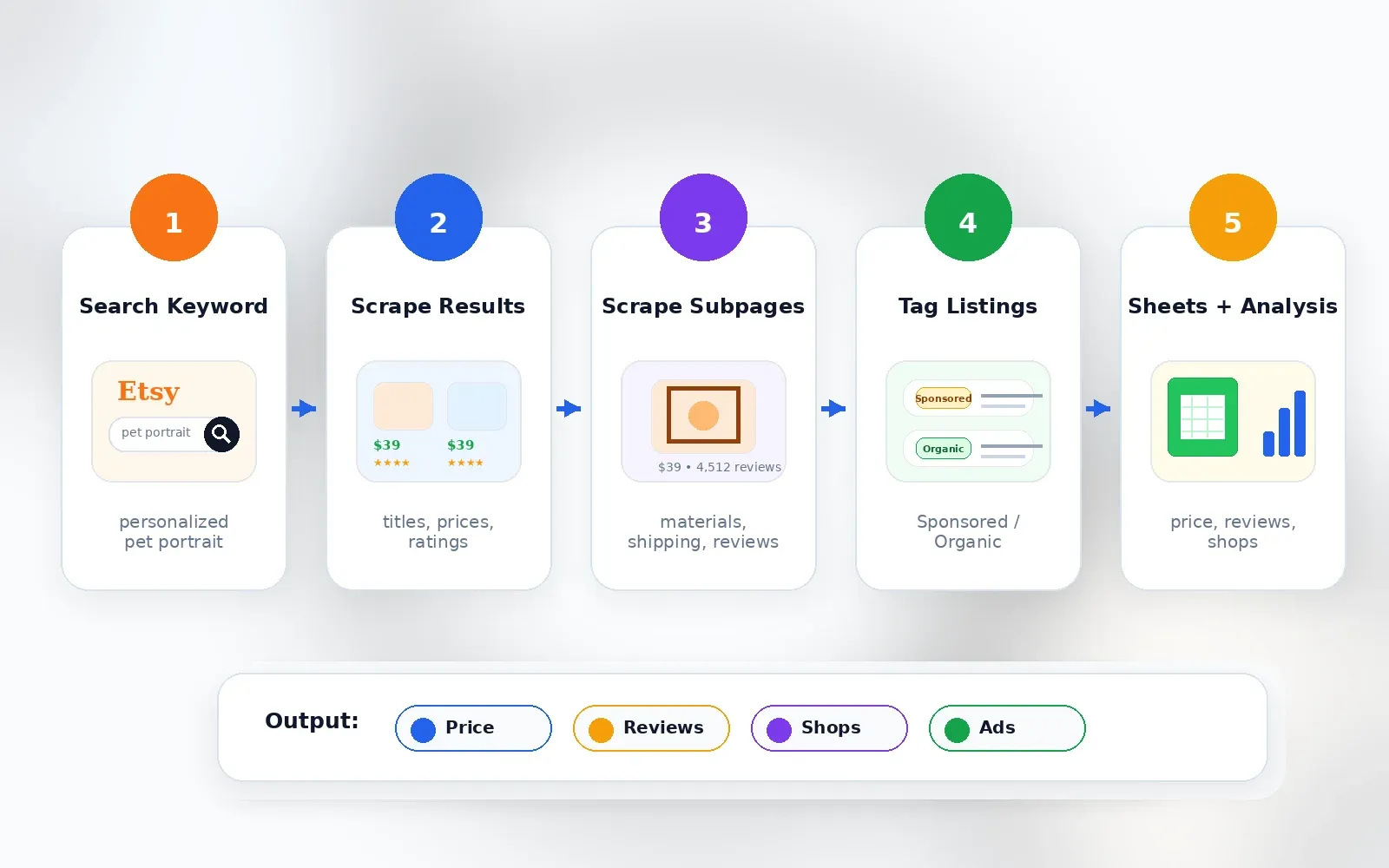
我如何評估這 6 款 Etsy 爬蟲
我讓每個工具都跑同一組任務:一個 Etsy 搜尋字詞(「personalized pet portrait」)、一個擁擠的商品搜尋字詞(「gold huggie earrings」)、一個包含大量商品的商店網址、十個商品詳細頁供子頁面補全、一個每週排程的價格監控任務,以及一次匯出到 Google Sheets 或 CSV。
我的評分項目如下:
| 評估標準 | 為什麼重要 |
|---|---|
| 易用性(無程式碼 vs. 程式碼) | Etsy 賣家不應該先變成爬蟲工程師 |
| 反機器人 / CAPTCHA 處理 | 能抓 10 筆但第 2 頁就失敗的工具沒有用 |
| 可擷取欄位 | 搜尋結果欄位對嚴肅的商品研究來說還不夠 |
| 匯出選項(CSV、JSON、Sheets、Airtable) | 真正的流程通常最後都會進到 Sheets、Airtable、Notion、CSV、JSON 或 BI 工具 |
| 價格透明度(免費方案 + 每 1K 筆成本) | 每一筆可用資料的成本,比月費標價更重要 |
| 子頁面補全 | 標籤、描述、運送、材質、規格與評論都藏在下一層頁面 |
1. Thunderbit
是我們在 Thunderbit 為非技術使用者打造的工具,目標是快速取得結構化網頁資料。它是由 AI 驅動的 :您打開 Etsy 頁面,點擊「AI 建議欄位」,AI 會讀取頁面結構並建議像標題、價格、評論、賣家、網址、圖片、徽章與運送等欄位。接著您按下「抓取」,就會得到一張表格。就這麼簡單。
Thunderbit 對 Etsy 研究特別有用的地方在於子頁面抓取。抓完搜尋結果頁之後,您可以點擊「抓取子頁面」,讓 Thunderbit 的 AI 逐一拜訪每個商品頁,補上完整描述、運送細節、材質、標籤與賣家資訊,而且完全不需要額外設定。我曾用這個流程,在不到十分鐘內從搜尋字詞做出一份完整的競品分析試算表。
主要功能
- AI 建議欄位: AI 讀取 Etsy 頁面並推薦欄位,不需要選擇器,也不用猜。
- 2 次點擊完成抓取: 非常適合臨時性的商品研究。
- 子頁面抓取: 一鍵補全搜尋結果中的完整商品資訊。
- 排程抓取: 只要用自然語言描述間隔,就能設定每週競品價格監控。
- 欄位 AI 提示詞: 可針對每一欄加入自訂指令(例如「分類為 Jewelry / Home Decor / Clothing」或「標記這個商品是否看起來有客製化」)。
- 匯出: Excel、Google Sheets、Airtable、Notion、CSV、JSON——。
- 雲端與瀏覽器模式: 雲端模式適合速度較快的公開任務;瀏覽器模式適合需要您目前工作階段 / 渲染結果的頁面(對 favorites 這類動態欄位更準確)。
- 開放 API: 可接受 URL + JSON Schema,且單次請求最多支援 100 個 URL 批次。
Thunderbit 如何在 2 次點擊內抓 Etsy
- 前往 Etsy 搜尋結果頁(例如搜尋「personalized pet portrait」)。
- 點擊 AI 建議欄位——AI 會建議標題、價格、評論、賣家、網址、圖片、徽章等欄位。
- 點擊 抓取——資料會填入表格中。
- 若需要,可在商品網址欄位上點擊 抓取子頁面,補上完整描述、運送細節、材質或評論。
- 匯出到 Google Sheets、Airtable、Notion、Excel、CSV 或 JSON。
您也可以到我們的 看影片教學。
價格
Thunderbit 採用點數制。它有免費方案 / 試用版,而 Starter 方案約為每月 15 美元,可獲得 500 點數(或每年 108 美元、共 5,000 年度點數)。由於每一列 / 每一頁補全都會分別計算,子頁面抓取可能消耗更多點數。最新價格請見 。
優缺點
| 優點 | 缺點 |
|---|---|
| 無需程式碼,也不用設定選擇器 | 採點數制;超大任務需要付費方案 |
| AI 欄位偵測可降低頁面變動維護成本 | 需要安裝 Chrome 擴充功能 |
| 內建子頁面補全 | 定位不是企業級資料集供應商 |
| 支援排程抓取與自動匯出,適合監控流程 | 準確性仍需抽查(所有工具都一樣) |
| 不只限 Etsy,也可用於一般電商研究 | 某些欄位仍無法取得,因為 Etsy 本身沒有公開 |
最適合: 做商品研究的 Etsy 賣家、建立競品報告的行銷人員、監控價格的營運團隊。
2. Apify Etsy Scraper
是一個雲端自動化平台,內建一個「Actors」市集——您可以直接執行預先建好的爬蟲,而不必自己維護基礎設施。針對 Etsy,目前有多個可用的 Actor,包括 與 。
Automation Lab Actor 支援關鍵字搜尋、分類篩選、分頁(單次執行最多 5,000 件商品),並輸出結構化欄位,例如 listing ID、標題、網址、圖片網址、商店、價格、原價、貨幣、促銷狀態、免運、評分、可用性、位置、查詢字詞、頁碼與抓取時間戳。對搜尋結果層級的資料來說,這組欄位相當完整。
主要功能
- 雲端代管(不需要本地資源)
- 關鍵字搜尋、分類與商店網址抓取
- 分頁處理
- 匯出 JSON、CSV、Excel
- 代理整合(可額外付費使用住宅代理)
- 排程器,適合重複執行的任務
- API 存取,方便接到資料管線
價格
採每次執行加上每件商品計費:依 Apify 方案不同,約為每 1K 件商品 0.80–3.45 美元。平台方案從每月約 9 美元(Starter)起,再加上 actor 使用費。免費方案每月包含 5 美元的平台使用額度。
優缺點
| 優點 | 缺點 |
|---|---|
| 可直接使用的 Etsy Actors | Actor 品質取決於維護者 |
| 雲端執行、排程器、API、webhook | 社群 Actor 可能在 Etsy 版面變動時反應較慢 |
| 部分 Actor 有透明的按結果計價 | 代理成本在大規模時會快速累積 |
| 透過 Apify dataset 匯出 JSON / CSV / Excel | 自訂子頁面補全可能需要額外設定 |
| 適合重複性的資料管線 | 屬於低程式碼,對賣家來說不如瀏覽器擴充功能簡單 |
最適合: 自由工作者、小型代理商,以及想要即裝即用 Etsy 資料管線的半技術使用者。
3. Bright Data
是企業級選項。如果您是大型電商公司或資料團隊,每天要抓上千筆 Etsy 商品,這就是為您設計的。Bright Data 提供專用的 與 ,內含 1,800 萬筆以上紀錄與 59 個欄位。
他們的基礎設施非常龐大——超過 1 億個住宅 IP、完整的反機器人處理(住宅代理、CAPTCHA 解題、瀏覽器指紋辨識)、結構化 JSON 輸出,以及以合規優先的做法。對不想碰程式碼的人,他們也提供無程式碼的 Data Collector 選項。
主要功能
- 預建 Etsy 資料收集器(無程式碼儀表板選項)
- 完整的反機器人處理
- 59+ 欄位的結構化 JSON 輸出
- 代管交付、webhook 與雲端儲存整合
- 企業級 SLA、合規工具、正常運行保證
- 可直接使用的 Etsy 資料集,方便大量分析
價格
Bright Data 的 Etsy Scraper API 依按量計費方案,起價約 。Etsy 資料集最低消費為 50 美元。沒有免費方案,但 Scraper API 頁面有宣稱提供 1K 次試用請求。Scale 方案每月 499 美元。這是高價位方案——不是那種週六下午抓 50 個商品的人會用的。
優缺點
| 優點 | 缺點 |
|---|---|
| 最穩定、最可靠的平台之一 | 對一次性賣家研究來說太大材小用 |
| 業界領先的反機器人繞過能力 | 價格高,對小型企業門檻高 |
| 無程式碼 Data Collector 選項 | 功能很多,簡單任務反而容易覺得複雜 |
| 嚴格的合規工具 | 沒有免費方案 |
| 大規模擴展能力強 | 子頁面客製化可能需要 API / 設定工作 |
最適合: 需要保證正常運行、法遵與大規模能力的大型電商公司、資料團隊與企業。
4. Octoparse
是一款桌面應用程式,提供可視化的點選介面來建立抓取流程。如果您喜歡清楚看到爬蟲在做什麼——點擊、滾動、分頁——這就是您的工具。
Octoparse 有一個 ,可依關鍵字抓取商品名稱、賣家、評分、評論數、價格、網址與圖片網址。他們的 也會帶您一步步抓 Etsy 商品資訊,包括自動偵測網頁資料,以及建立含分頁與頁面滾動的流程。
主要功能
- 視覺化流程建構器(拖拉式)
- 內建 IP 輪替
- 透過第三方整合處理 CAPTCHA(Etsy 範本有提到可手動解題)
- 支援無限滾動與分頁
- 雲端執行選項
- 匯出:CSV、Excel、JSON、資料庫連線、Google Sheets(付費方案)
價格
有免費方案,可在本機擷取且有列數限制。Standard 方案年繳約為 。付費方案會加入雲端功能、更多匯出選項,以及更高的列數上限。
優缺點
| 優點 | 缺點 |
|---|---|
| 真正無程式碼的視覺介面 | 桌面應用程式較吃資源 |
| 有 Etsy 範本與教學 | 複雜的子頁面抓取需要手動建立流程 |
| 可處理分頁 / 無限滾動 | 在某些情況下 CAPTCHA 可能仍要手動解題 |
| 可匯出 CSV、Excel、JSON、資料庫 | 大規模時速度比 API 型方案慢 |
| 對無程式碼抓取很適合當入門路徑 | 比起 AI 欄位建議工具,設定摩擦較高 |
最適合: 偏好視覺化介面、又想在不寫程式的情況下自訂擷取流程的非技術市場研究者與商業分析師。
5. ScrapingBee
是以開發者為主的 API。您送出一個網址,它回傳渲染後的 HTML(如果您設定了擷取規則,也可回傳已擷取的 JSON)。它沒有那種直接幫您吐出試算表的 Etsy 預建解析器——您得自己用 Python、JavaScript 或任何您喜歡的語言來寫擷取邏輯。
ScrapingBee 的 指出,透過 JSON 格式的擷取規則,可取得商品名稱、分類、價格、庫存狀態、運送資訊與尺寸等欄位。它也提醒,抓 Etsy 時應考慮高階代理、請求速率處理與條款風險。
主要功能
- JavaScript 渲染
- 自動代理輪替
- CAPTCHA 處理
- 簡單的 REST API
- 支援 Python / Node.js / 任意語言
- 回傳原始 HTML 或 JSON;解析與匯出由使用者自行處理
價格
一開始提供 1,000 點免費 API credits。 可得 250K credits 與 10 個並行請求。Startup 方案每月 99 美元,提供 1M credits。Business 方案每月 249 美元,提供 3M credits。
優缺點
| 優點 | 缺點 |
|---|---|
| API 整合簡單 | 需要寫程式(Python / JS) |
| 支援 JavaScript 渲染與代理選項 | 回傳原始 HTML(不是所有欄位都自動解析) |
| 可搭配任何語言 | 沒有視覺化介面 |
| 適合自訂資料管線 | 子頁面補全需要自己寫腳本 |
| 比視覺化工具更有彈性 | 匯出 / 儲存 / 排程都要自己負責 |
最適合: 建立專有內部工具的 Python / JS 開發者,需要一個可靠的「傳輸層」來取得不被封鎖的 Etsy HTML。
6. ZenRows
也是另一個開發者 API,類似 ScrapingBee,但更強調大規模反機器人繞過。它會自動處理 CAPTCHA、指紋辨識與住宅代理。
ZenRows 的 列出折扣、網址、賣家名稱、描述、評分、商品名稱、價格、可用性、分類、圖片、評論與貨幣等欄位。它宣稱成功率達 99.93%,並具備 anti-CAPTCHA、premium proxies、stealth mode、smart extraction 與 JavaScript rendering 等功能。
主要功能
- 反機器人繞過(高階代理、無頭瀏覽器)
- 自動輪替請求標頭
- JavaScript 渲染
- 簡單 API 呼叫
- 支援高併發
價格
提供 14 天免費試用,包含 1,000 筆基本結果與 40 筆受保護結果。,可取得 250K 基本結果 / 10K 受保護結果。受保護請求(針對有反機器人防護的網站)每次成本較高。
優缺點
| 優點 | 缺點 |
|---|---|
| 大規模反機器人繞過能力強 | 需要寫程式 |
| 對電商場景成功率主張高 | 不做解析——只回傳 HTML / JSON |
| 支援 JS 渲染、高階代理、CAPTCHA 處理 | 沒有視覺化介面 |
| 文件完善,且以 API 為核心 | 子頁面補全完全要手動 |
| 比桌面工具更能擴展 | 不太適合一次性的賣家研究 |
最適合: 需要高併發與強力防偵測的大規模 Etsy 資料管線開發團隊。
最佳 Etsy 爬蟲比較:並排表格
| 工具 | 無程式碼? | 反機器人處理 | 免費方案 / 試用 | 匯出格式 | 子頁面抓取 | 約每 1K 成本 | 最適合 |
|---|---|---|---|---|---|---|---|
| Thunderbit | ✅ 是(Chrome 擴充功能) | 雲端 + 瀏覽器模式;AI 自動調整欄位 | ✅ 免費方案 / 試用 | Excel、Sheets、Airtable、Notion、CSV、JSON | ✅ 內建 | 約 $9.60–$30/1K 列(依方案而定) | 非技術賣家與行銷人員 |
| Apify Etsy Scraper | ⚠️ 低程式碼 | 依 Actor 而定;代理 / 工作階段重試 | ✅ 每月免費 $5 平台額度 | JSON、CSV、Excel、API / webhooks | ⚠️ 需設定 | 約 $0.80–$3.45/1K 商品 | 專用 Etsy 資料管線 |
| Bright Data | ⚠️ 儀表板 + API | ✅ 完整堆疊(住宅代理、CAPTCHA) | ❌ 無(1K 試用請求) | JSON、NDJSON、CSV、雲端交付 | ⚠️ 需設定 | 約 $2.50/1K 筆 PAYG | 企業級擷取 |
| Octoparse | ✅ 是(桌面應用程式) | 內建輪替;可手動 CAPTCHA 選項 | ✅ 免費方案(有限) | CSV、Excel、JSON、資料庫、Sheets(付費) | ⚠️ 以流程為基礎 | 固定 SaaS(月費約從 $69 起) | 視覺化流程建構者 |
| ScrapingBee | ❌ 程式碼(API) | ✅ 代理 + JS 渲染 | ✅ 1K credits | JSON、原始 HTML | ❌ 手動 | 約 $4.90/1K(Freelance 估算) | Python / JS 開發者 |
| ZenRows | ❌ 程式碼(API) | ✅ 反機器人繞過、高階代理 | ✅ 14 天試用 | JSON、HTML | ❌ 手動 | 約 $7/1K 受保護結果 | 需要規模化的開發團隊 |
沒有任何一個工具可以包辦所有情境。最好的 Etsy 爬蟲取決於您的技術能力、預算與規模需求。對賣家來說,500 筆準確的 Google Sheets 資料,裡面有標題、價格、評論、賣家、廣告標記與運送資訊,通常比 5,000 個便宜但原始的 HTML 頁面更有價值。
如何驗證 Etsy 爬蟲的準確度(這步不要省)
我想特別提一件在 Etsy 賣家論壇裡一直會出現的事:資料準確度的懷疑。有位 Reddit 使用者回報,EverBee 顯示某個貼紙銷售量為 0,但那個商品其實在兩個月內賣了大約 40 件。另一位則說,EverBee、Alura 和 eRank 顯示的數字對他們自己連結的商店而言「誤差大到離譜」。這不只發生在這些工具身上——如果沒有驗證,任何爬蟲都可能回傳過時或不準確的資料。
我使用的抽查方法如下:
- 先抓一小樣本——20 到 50 列。
- 手動打開樣本中的 3–5 個商品頁。
- 比對標題、價格、貨幣、評論數、評分、免運、賣家名稱與商品網址 是否與即時 Etsy 頁面一致。
- 檢查贊助 / 廣告列是否有正確標示 或已分開。
- 24 小時後用同樣方式重抓一次,比較價格 / 評論變化。
- 在匯出中加入中繼資料欄位: scraped_at、source_url、query、page、position、country、tool、run_id。
新鮮度很重要。 以即時抓取的工具(例如 Thunderbit 的瀏覽器抓取模式,直接使用您自己的登入瀏覽器開啟頁面)通常會比批次任務、且快取時間不明的工具回傳更即時的結果。Etsy 自己的 要求 API 使用者不得顯示比對應 Etsy 網站資訊晚超過 6 小時的商品內容——這也很適合作為判斷 Etsy 資料是否容易過時的參考基準。
再說一次,請大家聽清楚:任何宣稱能精確提供每個商品銷售數字的工具,其實都是在估算,不是在抓公開事實。 對這類精確度宣稱要保持懷疑。
真實使用情境:為您的工作挑選最好的 Etsy 爬蟲
「我這個利基市場到底賣什麼最好?」——競品商品研究
賣家想看「personalized pet portrait」的熱門商品——價格區間、評論數、熱銷標籤、免運、商店名稱與商品網址。
最適合: Thunderbit(2 次點擊抓搜尋結果,AI 自動建議所有相關欄位,匯出到 Google Sheets 進行分析)或 Apify(把同一個查詢設成每週執行的 Actor)。
小提醒: 一定要包含廣告 / 贊助標記與位置。,所以第 1 頁資料不會全都是自然排序。
「每週監控競品價格」——價格追蹤
店主追蹤 50 個競品商品的價格變化。
最適合: Thunderbit 的排程抓取器(用自然語言描述間隔、輸入網址,完成)或 Bright Data(適合企業級、跨數千個 SKU 的監控)。Apify 也很適合成本較低的重複雲端任務。
小提醒: 請務必追蹤 scraped_at、貨幣、國家,以及該商品是否正在特價。沒有時間戳與地區的價格,證據力很弱。
「幫我的商店建立商品目錄」——大量資料擷取
擷取 500 筆以上商品,包含圖片、標題、價格、描述與材質。
最適合: Thunderbit(子頁面抓取可補全每個商品,圖片提取也可匯出到 Airtable / Notion)或 Octoparse(適合大量擷取的視覺流程)。如果您更重視 JSON 輸出與雲端執行,Apify 也可以。
小提醒: 未經授權,不要重用受著作權保護的描述或圖片。請把抓到的創作內容用在分析,不要直接複製。
「我要打造 Etsy 資料管線」——開發者情境
開發者需要可大規模取得的原始結構化 JSON,還要有反機器人處理、自訂 schema、重試紀錄,以及資料倉儲管線。
最適合: ScrapingBee 或 ZenRows,作為 API 存取 / 渲染層。若您偏好 Actor 生態系與代管資料集,也可以選 Apify。若 JSON Schema 擷取與最多 100 個 URL 的批次符合您的管線,Thunderbit 的 也可考慮。
小提醒: 把抓取、解析、驗證、儲存與報表分開。負責拿到 HTML 的工具,只是整條管線中的一部分。
關於贊助商品的提醒
論壇使用者經常抱怨,Etsy 排名前面的商品有很大一部分其實就是贊助廣告。有位 Reddit 使用者在討論 uBlock 篩選規則時就提到,自己反覆看到「Ad by Etsy Seller」的結果。另一位賣家也說,同一件商品會同時以廣告與自然結果的形式出現。
實務上的抓取建議:
- 在可見時擷取 is_sponsored
- 分開付費與自然位置
- 不只抓第 1 頁
- 依 listing ID / canonical URL 去重,不要只看標題(廣告與自然列可能重疊)
- 如果您的研究問題與個人化有關,請分別執行乾淨的登出搜尋與登入 / 瀏覽器工作階段搜尋
抓 Etsy 的法律與倫理考量
我簡短說明。 規定,未經明確許可,使用者不得對頁面進行 crawl、scrape 或 spider。 也禁止未經明確授權就使用自動化系統存取、分析或抓取 Etsy 的網站 / API / 資料。
美國法律先例其實相當細緻。像 這類案件,對某些公開資料抓取理論是有利的,但並不會消除合約、著作權、隱私或平台執法風險。Bright Data 也曾涉入與這些議題相關的。
我的建議是:凡是 Etsy 官方 API 能涵蓋的用途,就優先用 API;只收集公開且必要的資料;避免個人 / 私密資料;尊重速率限制與存取控制;未經允許,不要重新發布受著作權保護的照片或描述。這不是法律意見——特定情境請諮詢專業人士。
結論:哪一款 Etsy 爬蟲最適合您?
在測完這六款之後,我的真實結論是:「最佳」Etsy 爬蟲完全取決於您是誰,以及您需要什麼:
- 非技術型賣家與行銷人員: Thunderbit。兩次點擊、AI 驅動、子頁面補全、直接匯出到 Sheets / Airtable / Notion。先從開始,看看能做到哪一步。
- 專用 Etsy 資料管線: Apify。雲端 Actors、排程器、API、透明的按結果計價。
- 企業級規模: Bright Data。代管基礎設施、合規、SLA、龐大代理池。
- 偏好視覺化流程: Octoparse。可點選的桌面建構器加上範本。
- 開發者: ScrapingBee 或 ZenRows。API 傳輸、JS 渲染、反機器人——其餘由您自己整合。
我最後的建議是:先從免費方案或試用開始,做一次抽查確認準確度,只有在驗證過資料品質之後再擴大規模。不要在確認工具真的能以您需要的格式、需要的新鮮度回傳所需欄位之前,就直接付費。
也祝您的 Etsy 資料永遠乾淨、結構化,且不會意外混進贊助商品。
常見問題
對非技術使用者來說,最好的 Etsy 爬蟲是哪一個?
Thunderbit 是非技術型賣家與行銷人員最強的選擇。它是 Chrome 擴充功能,您只要在任何 Etsy 頁面點擊「AI 建議欄位」,檢視建議欄位,按下「抓取」,就能匯出到 Google Sheets、Airtable、Notion 或 Excel。子頁面抓取與排程抓取也都內建。如果您喜歡視覺化桌面流程建構器,Octoparse 也是不錯的選擇。
抓取 Etsy 商品資料是否合法?
在某些情境下,抓取公開可得的網頁資料在美國法律上有較有利的先例(例如 hiQ v. LinkedIn),但 Etsy 的使用條款與 API 條款限制未經授權的 crawl、scrape 與自動化存取。若用於商業用途,建議諮詢法律專業人士、盡可能使用官方 API,並避免複製受著作權保護的內容,例如商品照片或描述。
使用爬蟲可以從 Etsy 擷取哪些資料?
從搜尋結果可抓到:標題、價格、圖片、商品網址、賣家 / 商店名稱、評分、評論數、徽章(熱銷、免運、Star Seller)以及贊助 / 廣告標示。從個別商品頁(透過子頁面抓取)可取得:完整描述、材質、屬性、運送細節、規格、賣家政策與評論。實際每個商品的銷售數字、轉換率與真正的關鍵字搜尋量,無法直接透過爬蟲取得——凡是顯示這些數字的工具,都是在估算。
我可以在不被封鎖的情況下抓 Etsy 嗎?
可以,只要用對工具。Etsy 會使用包括動態頁面結構、TLS 指紋辨識、CAPTCHA 與速率限制在內的反機器人控制。像 Thunderbit(雲端與瀏覽器抓取模式)、Bright Data(企業級代理基礎設施)、ScrapingBee(JS 渲染與高階代理)與 ZenRows(反機器人 API)都能自動處理這些機制。對小規模研究來說,Thunderbit 的瀏覽器模式——使用您自己的登入工作階段——通常相當穩定,也能拿到最新資料。
Etsy 爬蟲要多少錢?
Thunderbit、Apify、Octoparse、ScrapingBee 與 ZenRows 都有免費方案或試用。Bright Data 提供試用請求,但沒有持續性的免費方案。付費方案通常從每月 49–69 美元起,適用於開發者 / 無程式碼工具。以每筆結果計價的 Etsy 專用 API,大約從 0.80–3.45 美元 / 1K 筆(Apify)到 2.50 美元 / 1K 筆(Bright Data 按量計費)不等。Thunderbit 的點數制方案大約從每月 15 美元起。實際成本取決於您需要多少列、是否使用子頁面補全,以及抓取頻率有多高。
延伸閱讀