

到 2026 年,互联网比以往任何时候都更庞大、更杂乱,也藏着更多机会——如果你在做销售或市场营销,你一定懂,真正有价值的往往不只是你自己网站上的内容,而是你能从别处挖出来的数据。我亲眼见过,合适的数据在合适的时间出现,常常就是成单和错失之间的分水岭。但说实话,没人愿意花几个小时,从几十个网站里手动复制粘贴潜在客户信息或价格数据。也正因为这样,自动化正在迅速升温,而“Zapier 网页爬虫”也成了希望更聪明而不是更辛苦工作的团队热议的话题。
不过,这里有个反转:虽然 Zapier 已经成了数百万用户首选的无代码自动化工具,但它的网页抓取能力并没有很多人想象中那么强。好消息是,随着像 Thunderbit 这样的 AI 工具出现,你现在可以把两者的优势合起来——既能智能提取数据,又能无缝自动化工作流。在这篇指南里,我会详细拆解 2026 年怎么用 Zapier 做网页抓取、它的局限在哪里,以及如何通过集成 Thunderbit 把自动化能力再往上推一层。不管你是销售、营销人员,还是早就受够了手动录入数据的人,我们都可以直接开始。
什么是 Zapier 网页抓取?为什么它在 2026 年如此重要?
先从最基础的说起。Zapier 网页抓取,就是利用 Zapier——全球领先的无代码自动化平台——来自动收集网页数据,并把它传到你的业务工具里。Zapier 可以连接超过 7,000+ 个应用(比如 Google Sheets、HubSpot、Slack、Salesforce 等),让你创建“Zaps”:当某个事件发生时自动触发(比如表格新增一行),然后执行后续动作(比如发邮件或更新 CRM)。
但问题在这儿:Zapier 本身并不会真正去抓网页数据。它更像一个连接器,把通过第三方工具或 API 抓来的数据,接到你需要的地方。比如,你可以先用 Chrome 扩展或者 AI 驱动的爬虫从目录站点抓取潜在客户,再导出到 Google Sheets,然后让 Zapier 自动把这些数据同步到 CRM。
为什么这件事在 2026 年这么重要?因为自动化数据采集的需求正在爆发式增长。全球网页抓取市场预计将在 2026 年达到 11.7 亿美元,而仅 AI 驱动的抓取市场就已经达到 102 亿美元。销售和营销团队都在被要求用更少的人力做更多的事,而手动录入数据正是效率杀手——它每年可能让企业每位员工损失高达 28,500 美元,并吞掉每周 9 小时以上的重复劳动。
 Zapier 网页抓取之所以重要,是因为它让非技术用户也能把这些流程自动化,把时间释放出来,真正用在销售和营销上。事实上,自动化手动任务的销售团队,平均每位销售每周可节省 6 小时,而营销自动化在三年内可带来 544% 的投资回报率。
Zapier 网页抓取之所以重要,是因为它让非技术用户也能把这些流程自动化,把时间释放出来,真正用在销售和营销上。事实上,自动化手动任务的销售团队,平均每位销售每周可节省 6 小时,而营销自动化在三年内可带来 544% 的投资回报率。
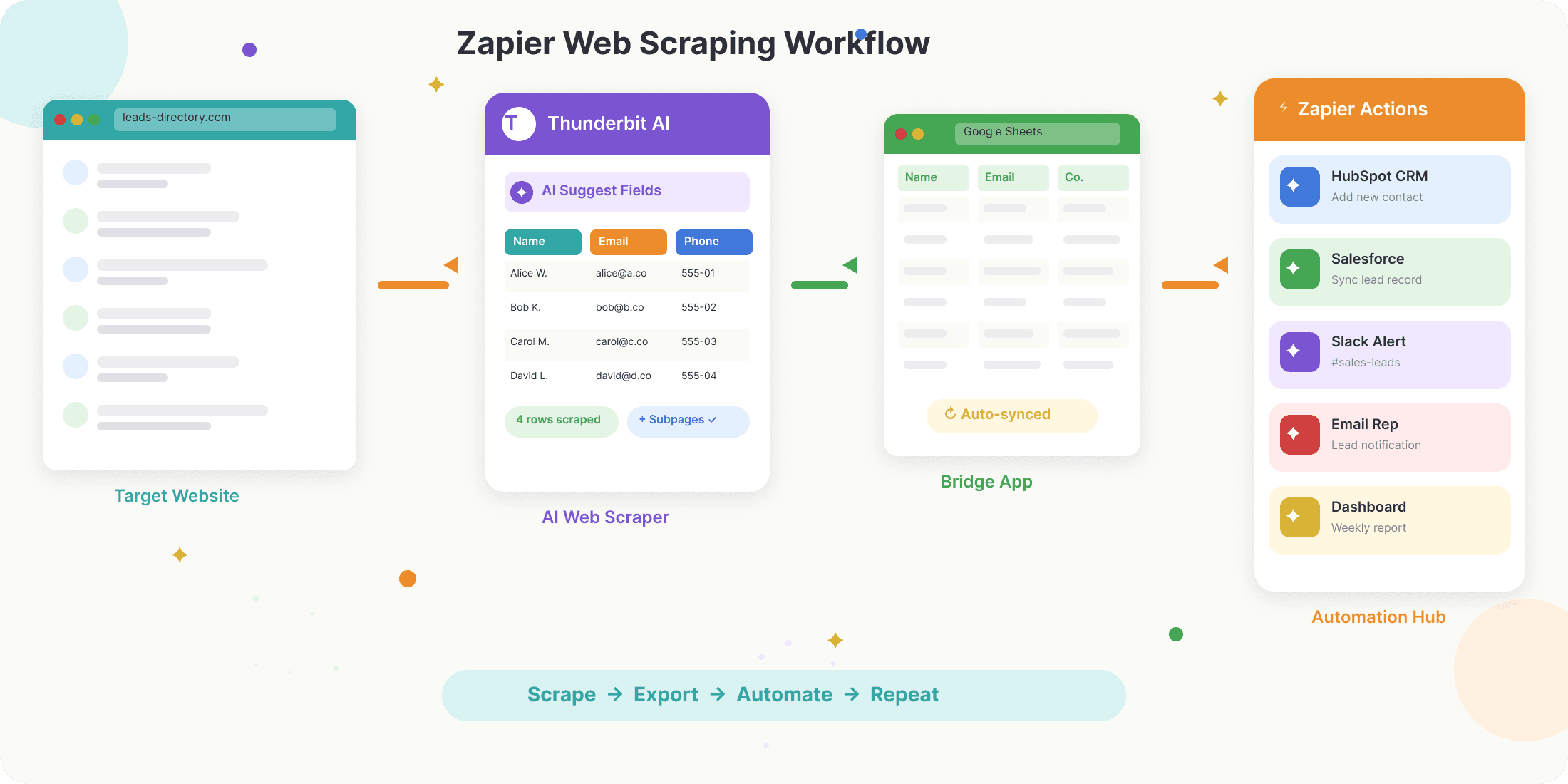
Zapier 网页抓取如何实现自动化:逐步工作流
两步即可用 AI 抓取网页数据 Get Started Free
那么,典型的 Zapier 网页抓取工作流在实际中长什么样?大致流程如下:
- 从网页抓取数据:使用 Chrome 扩展(比如 Thunderbit)、API(比如 Apify 或 Browse AI)或第三方工具,从目标网站提取数据。
- 把数据导出到“中转”应用:最常见的是导出到 Google Sheets、Airtable 或 Notion——这些平台都很容易被 Zapier 监测到变化。
- 设置 Zapier 触发器:在 Zapier 里创建一个新的 Zap,当表格新增一行时触发。
- 自动执行后续动作:在 Zap 里加入步骤,把数据发到 CRM、邮箱、Slack,或者 7,000+ 个其他应用中。
下面是一张适用于销售和营销团队的典型自动化流程表:
| 使用场景 | 抓取工具 | 中转应用 | Zapier 触发器 | 动作 |
|---|---|---|---|---|
| 潜在客户开发 | Thunderbit | Google Sheets | 新增表格行 | 添加到 HubSpot CRM |
| 价格监控 | Apify | Airtable | 新增记录 | 发送 Slack 提醒 |
| 内容聚合 | Browse AI | Notion | 新增数据库条目 | 发送邮件摘要 |
| 竞争对手跟踪 | ScrapingBee | Google Sheets | 新增行 | 更新 Salesforce |
这种“抓取 → 导出 → 自动化”的模式,就是现代无代码数据工作流的核心。
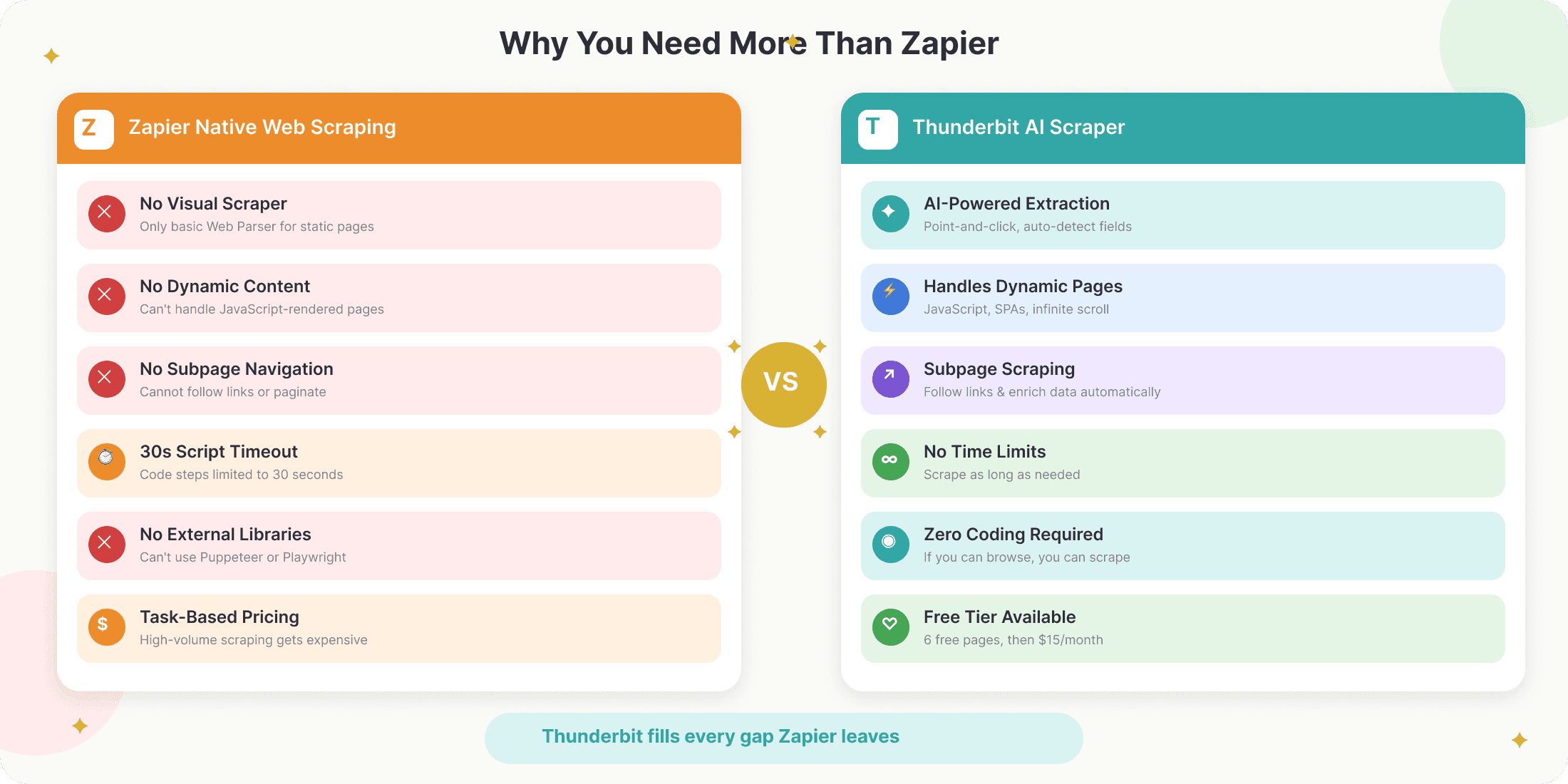
2026 年 Zapier 网页抓取的关键限制
在你太兴奋之前,我们先聊聊现实:Zapier 内置的网页抓取能力是有限的。你需要知道这些问题:
- 没有可视化爬虫:Zapier 原生的“Web Parser”只能提取静态网页(比如博客文章)的主要内容,没法处理结构化数据、表格或商品列表。
- 无法处理动态内容:如果网站是通过 JavaScript 加载数据的(比如无限滚动、弹窗或交互式表格),Zapier 的解析器看不到这些内容。
- 代码步骤有局限:虽然 Zapier 支持运行 Python 或 JavaScript,但你不能导入外部库,而且脚本限制为 30 秒 和 512 MB 内存,这意味着像 Puppeteer 或 Playwright 这样的无头浏览器基本用不了。
- 不支持子页面或分页:Zapier 原生无法自动跟进子页面链接,也不适合多页面抓取。
- 按任务计费:Zap 里的每个动作都会算作一个“task”,所以大规模抓取时成本会很快上涨。
- 线性工作流模型:Zap 只能按直线流程执行,和 Make 或 n8n 相比,复杂分支和条件逻辑支持更弱。
一句话总结:Zapier 很适合在你拿到数据之后做自动化,但它并不是为网页抓取本身的重活设计的。只要不是最基础的文章提取,你就需要一款专门的爬虫工具。
用 Thunderbit 提升 Zapier 网页抓取:集成的力量
这正是 Thunderbit 发挥作用的地方。Thunderbit 是一款面向商务用户的 AI 网页爬虫 Chrome 扩展——不用编程、也不用模板,只要两次点击,就能从任何网站提取结构化数据。
它是这样补上空缺的:
- AI 驱动提取:点击“AI Suggest Fields”,Thunderbit 会自动读取页面,建议字段(比如姓名、邮箱、价格等),并提取数据——不用配置。
- 处理动态和复杂页面:Thunderbit 的 AI 能抓大量 JavaScript 网站,处理分页,甚至还能访问子页面来丰富数据。
- 无需编程:全程点选式操作。只要会用浏览器,就能上手 Thunderbit。
- 可导出到任意平台:抓取结果可以立刻导出到 Google Sheets、Airtable、Notion、Excel 或 CSV,为 Zapier 自动化做好准备。
- 定时抓取:用自然语言就能设置按小时、按天或按周的定期抓取,让数据始终保持最新,不用手动盯着。
真正的威力在于,把 Thunderbit 的抓取能力和 Zapier 的自动化能力结合起来。Thunderbit 负责拿数据,Zapier 负责把数据送到你需要的地方。
分步指南:用 Zapier 和 Thunderbit 自动采集网页数据
下面我们用一个真实工作流来演示——不讲技术术语,只讲能直接照做的步骤。
1. 用 Thunderbit 抓取数据
- 安装 Thunderbit Chrome 扩展(可以免费开始用)。
- 打开你的目标网站(比如潜在客户目录)。
- 点击 Thunderbit 图标,然后选择“AI Suggest Fields”,让 AI 自动识别页面内容。
- 如果需要,调整字段列,再点击“Scrape”。Thunderbit 会提取数据并以表格形式展示。
- 如果你想拿到更多信息,可以用“Scrape Subpages”访问每个链接,丰富你的数据(比如抓取公司主页上的邮箱)。
2. 导出数据到 Google Sheets
- 在 Thunderbit 里点击“Export”,选择 Google Sheets。
- 登录并选择目标表格。
- Thunderbit 会把抓取的数据填进表格,供 Zapier 直接读取。
3. 在 Zapier 中创建 Zap
- 登录 Zapier。
- 创建一个新的 Zap,触发器选择“New Spreadsheet Row in Google Sheets”。
- 连接你的 Google 账号,并选择 Thunderbit 正在更新的那张表。
4. 添加动作,自动化你的工作流
- 添加步骤,把数据发送到 CRM(比如 HubSpot、Salesforce)、邮件、Slack,或者你需要的任何地方。
- 使用 Zapier 的 Formatter 或 Filter 步骤,在数据流到下游之前先做清洗或校验。
- 测试你的 Zap,确认流程一切正常。

5. 设置定时并监控
- 如果你希望定期拿到最新数据,可以在 Thunderbit 里设置定时抓取(比如“每天上午 9 点”)。
- Zapier 会自动处理新出现的表格行——不用人工盯着。
实用建议:
- 批量抓取,避免碰到 Zapier 的任务限制。
- 在 Zapier 里加上错误通知(Slack 或邮件),及时发现问题。
- 如果工作量很大,可以考虑升级 Zapier 套餐,或者采用批量更新方式。
真实案例:用 Zapier 网页抓取优化销售线索跟踪
我们把它放到一个真实业务场景里。假设你是一家 SaaS 公司的销售经理,想要跟踪一个细分行业目录里的新线索,而这个目录并不提供 API。
旧方法: 你或团队每周花大量时间把姓名、邮箱和公司信息复制到表格里,然后再手动更新 CRM。
Thunderbit + Zapier 的新方法:
- Thunderbit 抓取目录网站——包括子页面里的直接邮箱和 LinkedIn 资料。
- 数据导出到 Google Sheets——结构清楚、内容干净、随时更新。
- Zapier 监测新行——每个新线索都会触发一条自动流程。
- 线索自动添加到 HubSpot CRM,分配给对应销售,同时向团队发送 Slack 提醒。
- 每周摘要邮件 会发给管理层,高价值线索也会被自动标记待跟进。
效果如何? 团队通常能节省 每位销售每周 6 小时以上,捕获 多 40% 的高质量线索,并把转化率提升 15–25%。某家金融服务公司在自动化线索管道后,实现了 70% 的投资回报率,线索转化率提升了 40% (browsercat.com)。
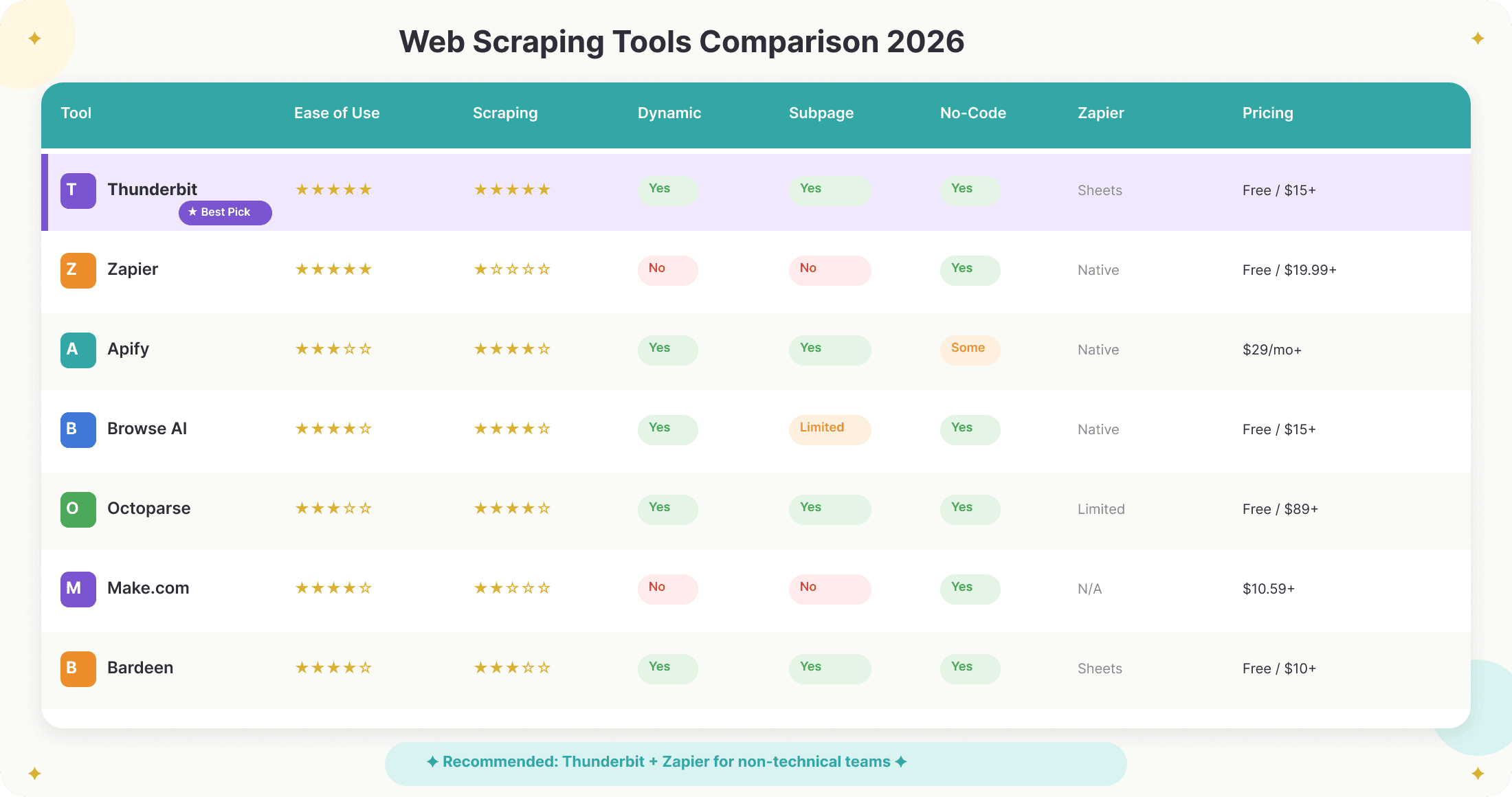
对比 Zapier、Thunderbit 和其他网页抓取解决方案
 下面看看 2026 年适合企业自动化的主流工具表现如何:
下面看看 2026 年适合企业自动化的主流工具表现如何:
| 工具 | 易用性 | 抓取能力 | 支持动态页面 | 子页面抓取 | 无代码 | Zapier 集成 | 价格 |
|---|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 支持 | 支持 | 支持 | 通过 Sheets/Airtable | 免费(6 页),$15/月起 |
| Zapier(原生) | ⭐⭐⭐⭐⭐ | ⭐ | 不支持 | 不支持 | 支持 | — | 免费(100 tasks),$19.99/月起 |
| Apify | ⭐⭐⭐ | ⭐⭐⭐⭐ | 支持 | 支持 | 部分支持 | 原生支持 | $29/月起 |
| Browse AI | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 支持 | 有限 | 支持 | 原生支持 | 免费(50 credits),$15/月起 |
| Octoparse | ⭐⭐⭐ | ⭐⭐⭐⭐ | 支持 | 支持 | 支持 | 有限 | 免费,$89/月起 |
| Make.com | ⭐⭐⭐⭐ | ⭐⭐ | 不支持 | 不支持 | 支持 | 原生支持 | $10.59/月起 |
| Bardeen | ⭐⭐⭐⭐ | ⭐⭐⭐ | 支持 | 支持 | 支持 | 通过 Sheets | 免费,$10/月起 |
推荐结论:
- 对于想快速、稳定、灵活地抓取数据,同时又能轻松自动化的非技术用户,Thunderbit + Zapier 是最理想的组合。
- 如果你是开发驱动型团队,或者需要处理高复杂度、高体量的抓取任务,Apify 或 Octoparse 可能更合适,但配置会更重。
- 如果你偏向基于浏览器的抓取和自动化,Bardeen 也是不错的替代方案,不过下游流程很多时候还是会依赖 Zapier。
Zapier 网页抓取的未来:2026 年的无代码、AI 与自动化趋势
下一波自动化浪潮的核心,是 AI 代理和无代码编排。到 2026 年底,企业应用中会有 40% 集成任务专用 AI 代理,而 2025 年这个比例还不到 5%。Zapier 也在加速推出 AI Actions、Copilot 和自主 Agents,让用户用自然语言描述工作流,平台自动帮你搭起来。
与此同时,像 Thunderbit 这样的 AI 爬虫正在让数据提取变得更稳定、更容易上手。再也不用依赖脆弱的 CSS 选择器——你只要告诉 AI 你想要什么,剩下的它自己处理。自我修复爬虫、基于视觉的提取和定时自动化,正在变成常态。
这对企业用户意味着什么?
- 到 2026 年,80% 的技术产品将由非开发者构建(Gartner)。
- 数据驱动团队获得客户的可能性高 23 倍,盈利能力也高 19 倍。
- AI 抓取和无代码自动化的组合,正在释放新的商业机会——从动态定价、实时线索获取,到大规模市场研究。
归根结底:如果你还没有把网页数据工作流自动化,就等于把钱和时间留在桌子上了。
结论与核心要点
Zapier 网页抓取正在改变 2026 年销售和营销团队的工作方式——但前提是要配上合适的工具。Zapier 擅长在你拿到数据后做自动化,但它本身扛不起网页抓取这部分重活。这正是 Thunderbit 的价值所在:它提供人人都能用的 AI 驱动、无代码抓取能力。
核心要点:
- Zapier 是自动化中枢,服务于 340 万+ 企业,但它的网页抓取能力只适合基础解析或第三方集成。
- Thunderbit 补上了短板:两次点击即可完成 AI 抓取,可处理动态页面、子页面和定时任务,完全不用编程。
- 最佳工作流:用 Thunderbit 抓取 → 导出到 Google Sheets/Airtable → 用 Zapier 自动化。
- 实际效果:团队可以节省大量时间、提升线索质量,并带来可衡量的 ROI——某些行业甚至可达到 70%。
- 未来属于 AI + 无代码:到 2026 年,大多数企业自动化都将由非开发者构建,由智能代理和更稳健的 AI 爬虫驱动。
准备好告别手动录入,释放自动化网页数据工作流的力量了吗?下载 Thunderbit,创建你的第一个 Zap,看看自动化到底能有多简单。想了解更多技巧,也可以看看 Thunderbit 博客。
试用 AI 网页爬虫 Get Started Free
常见问题
1. Zapier 能直接抓取任何网站吗?
不能。Zapier 没有内置可视化网页爬虫。它只能通过 Web Parser 解析基础静态内容,或者连接第三方抓取工具。对于结构化或动态数据,建议用 Thunderbit 这类专用爬虫,然后导出到 Google Sheets,再交给 Zapier 自动化。
2. Zapier 网页抓取的主要限制是什么?
Zapier 无法处理 JavaScript 渲染页面、子页面导航或复杂数据提取。它的代码步骤限制为 30 秒和 512 MB 内存,也不能使用外部库。由于按任务计费,高频抓取的成本也可能很快上升。
3. Thunderbit 如何与 Zapier 集成?
Thunderbit 可以从任何网站抓取数据,并直接导出到 Google Sheets、Airtable 或 Notion。之后,Zapier 会在这些平台有新行时触发自动流程,自动执行把线索添加到 CRM、发送提醒或更新仪表盘等操作。
4. 用 Zapier 和网页抓取自动化销售线索跟踪,最好的方式是什么?
用 Thunderbit 从目标网站抓取线索,导出到 Google Sheets,然后设置一个 Zap,把新线索加入 CRM 并通知团队。还可以在 Thunderbit 里设置定时抓取,让数据始终保持最新。
5. 2026 年网页抓取自动化要关注哪些趋势?
重点关注 AI 驱动、自我修复爬虫、无代码工作流构建器,以及能够编排复杂多步骤自动化的 agentic AI。未来的重点是更强的稳定性、更易用的体验,以及把抓取能力和业务流程无缝整合。
了解更多
- 2026 年最值得关注的 10 款网页爬虫软件工具
- 使用 Thunderbit 开始网页数据提取的教程
- 2026 年提升效率的 10 款 AI 网页抓取工具
- 适合自动化方案的 9 款无代码网页爬虫
- 如何使用 Thunderbit 精通自动化数据抓取
准备好自动化你的网页数据工作流了吗?免费试用 Thunderbit,看看在 2026 年把抓取和自动化连接起来有多简单。




