

互联网早就不是“右键另存为”就能轻松搞定的年代了。现在的网站结构越来越复杂,内容经常动态加载,隐藏链接、弹窗、嵌套导航随处可见。如果你试过从电商平台批量提取商品信息,或者想把房产网站的所有房源都抓下来,你一定会发现,普通的网页爬虫早就不够用了。这时候,深度爬虫就成了新宠——它是一种能深入多层结构、挖掘隐藏数据的全新网页爬虫工具。
那么,深度爬虫到底是什么?为什么越来越多的企业——无论是销售还是市场调研——都在关注它?像 Thunderbit 这样的工具,又是怎么让“深度爬取”变得像点两下鼠标一样简单,就算不会编程也能轻松上手?接下来,我们就从原理到实际应用,带你全面了解深度爬虫,看看它为什么会成为现代数据采集的“秘密武器”。
什么是深度爬虫?原理全解析
用 AI 从任意网站抓取数据 Get Started Free
简单来说,深度爬虫就是专门为结构复杂、多层级、动态内容丰富的网站设计的数据采集工具。和传统爬虫只会“浮于表面”、抓首页可见内容不同,深度爬虫能自动跟踪链接,穿梭多级导航,处理分页、标签页、可展开区域等各种隐藏信息。
你可以把传统爬虫想象成在图书馆里只看书架正面书名的人;而深度爬虫就像那个会钻进每个书架、翻开每本书、查脚注,甚至推开“员工专用”门(只要没锁)的人。
在网页数据采集领域,深度爬虫可以:
- 穿越网站多层结构(比如分类、子分类、详情页)
- 提取动态内容,包括 JavaScript 加载或用户操作后才显示的数据
- 处理复杂分页和无限滚动页面
- 跟踪并抓取内部链接,确保所有相关数据都不遗漏
 随着全球网页数据量在 2024 年达到 149 ZB,网站复杂度也在不断提升。对于需要深度挖掘数据的用户来说,深度爬虫已经成了不可或缺的利器。
随着全球网页数据量在 2024 年达到 149 ZB,网站复杂度也在不断提升。对于需要深度挖掘数据的用户来说,深度爬虫已经成了不可或缺的利器。
深度爬虫 vs. 传统爬虫:核心区别在哪?
具体来说,深度爬虫和常见的“普通”爬虫到底有什么不同?
传统爬虫:只抓表面
传统网页爬虫(有时也叫“浅层爬虫”)追求速度和广度,适合快速扫描网站首页,抓取可见内容后就离开。这也是大多数搜索引擎的做法——它们希望尽快索引尽可能多的页面,但不会深入每个角落。
传统爬虫的局限:
- 经常遗漏隐藏在导航、标签页或动态元素后的数据
- 难以应对大量 JavaScript 动态加载的内容
- 无法处理多步导航或复杂页面结构
- 抓取结果常常不完整或数据碎片化
深度爬虫:每一层都不放过
相比之下,深度爬虫就是为全方位探索网站而生——它会递归跟踪每个相关链接,自动点击分页、进入详情页、处理弹窗和动态内容。深度爬虫更注重数据的完整性和准确性,而不是单纯追求速度。
深度爬虫的核心特性:
- 高级导航能力: 能递归跟踪链接,处理多层级结构,避免死循环和重复抓取(SEO-Wiki)。
- 动态内容提取: 可与 JavaScript 交互,展开隐藏区域,抓取用户操作后才显示的数据(Scientific Reports)。
- 高效聚焦: 只关注有价值的页面,减少重复和无关数据,确保重要信息不遗漏(Medium)。
- 数据完整性: 一次性抓取所有层级信息,包括主列表、详情页、相关文档等。
如果你试过抓取商品评论、房产网站的全部房源(包括经纪人信息在子页面),就会体会到传统爬虫的局限,而深度爬虫正好能解决这些难题。
深度爬虫如何实现数据完整性和高级页面导航
深度爬虫的“魔法”就在于智能跟链、递归导航和动态内容处理。
子页面抓取与多层级导航
深度爬虫不会只停留在首页,而是会:
- 识别内部链接(比如“查看详情”、“下一页”、“查看更多”)
- 自动跟进这些链接,进入子页面、详情页或弹窗
- 逐层提取数据,并整合成结构化的数据表
这种方式也叫“递归爬取”或“多层级抓取”,特别适合信息分散在多个页面的网站,比如商品列表+详情页,或者需要点击后才能看到联系方式的目录网站。
处理分页和动态内容
现在的网站经常用“加载更多”按钮、无限滚动或者 JavaScript 标签页隐藏数据。深度爬虫能做到:
- 自动识别并操作分页控件
- 模拟滚动或点击,触发动态加载
- 等内容加载完再提取数据
这样你拿到的是完整数据集,而不是页面初始加载时的“冰山一角”(Thunderbit Blog)。
深度链接跟踪与多层级抓取
深度爬虫还会用算法确保隐藏或嵌套数据不遗漏,包括:
- 记录已访问链接,避免重复或死循环
- 优先抓取重要页面(比如详情页、可下载文档)
- 处理特殊场景(比如弹窗、可展开区域、AJAX 加载内容)
这对企业用户尤其重要——漏掉一个联系方式或产品参数,可能就错失商机或导致分析不完整(Simplescraper)。
Thunderbit:用 AI 让深度爬取变得又快又简单
说实话,深度爬取以前一直是开发者和数据工程师的“专属技能”——要写脚本、处理各种异常,网站一改版还得重新维护。但有了 Thunderbit,就算你不会编程,也能轻松搞定深度爬取。
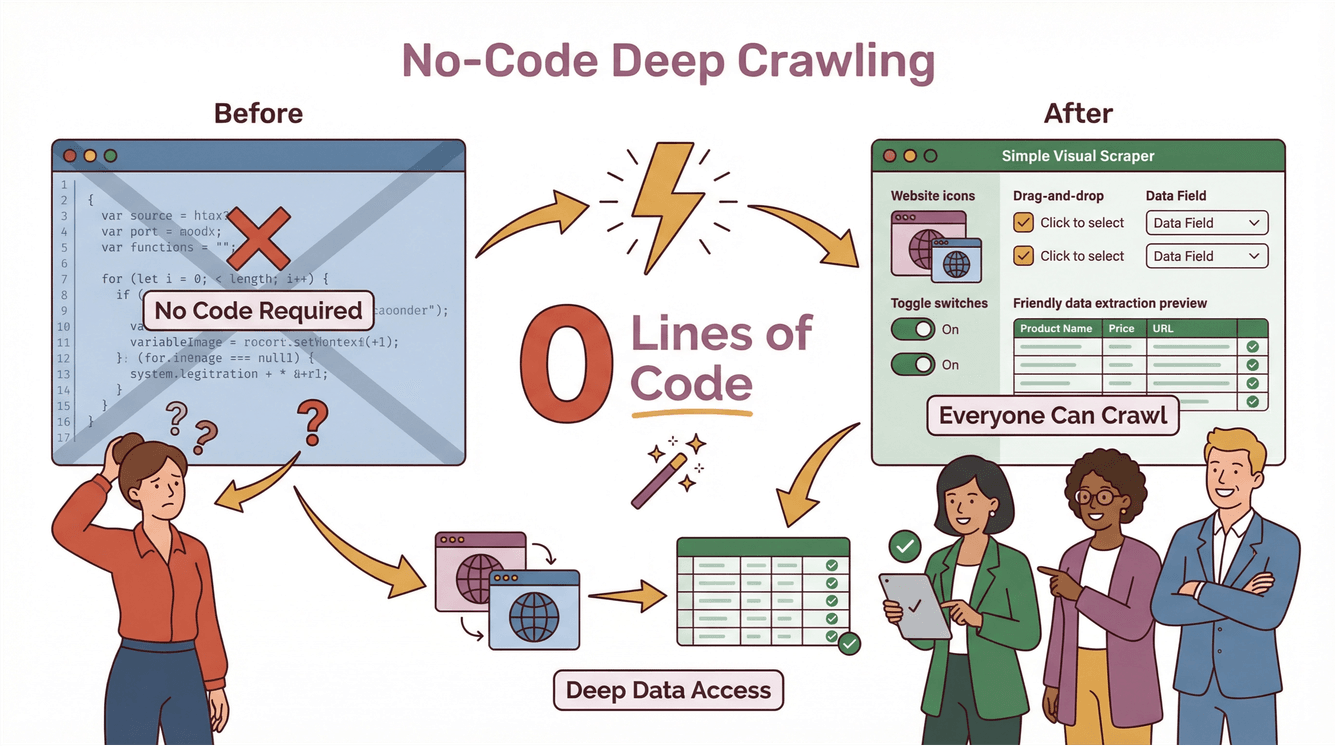
Thunderbit 深度爬虫亮点
Thunderbit 让深度爬取变得前所未有的简单:
- AI 智能字段推荐: 一键“AI 推荐字段”,自动识别页面结构,建议最佳提取列,并为每个字段生成提示词。
- 子页面自动抓取: 需要更多信息?Thunderbit 可自动访问每个子页面(比如商品详情、经纪人资料、评论标签页),让你的数据表更丰富。
- 动态内容处理: 自动应对分页、无限滚动、动态元素,无需手动配置。
- 零代码、两步操作: 只要描述你的需求,点“抓取”,剩下的交给 Thunderbit。数据还能直接导出到 Excel、Google Sheets、Notion、Airtable,无额外费用或限制(Thunderbit Blog)。
实操演示:用 Thunderbit 实现深度爬取
比如你想抓取房产网站的所有房源,包括隐藏在子页面的经纪人联系方式:
- 在 Chrome 打开房源列表页。
- 点击 Thunderbit 扩展。
- 用“AI 推荐字段”,让 Thunderbit 自动识别“房源标题”、“价格”、“地址”、“经纪人链接”等字段。
- 点击“抓取”。 Thunderbit 会采集所有主列表数据。
- 点击“抓取子页面”。 Thunderbit 会自动访问每个经纪人资料页,提取电话、邮箱等信息,并合并到主表。
- 导出数据到 Google Sheets 或 Excel,方便销售或运营团队后续使用。
不用写代码、不用模板、不用反复调试。就算网站结构变了,Thunderbit 的 AI 也能自动适应(Thunderbit Docs)。
商业价值:深度爬虫如何助力销售和市场增长
深度爬虫不仅仅是“炫酷”,它带来的商业价值才是真正让人兴奋的地方。
电商、房产、竞品网站——洞察价值一网打尽
对于销售和市场团队来说,深度爬虫就是数据金矿。它可以:
- 抓取电商网站的所有商品、价格、评论,哪怕数据藏在多层页面或标签下
- 汇总房产网站的全部房源(包括隐藏的经纪人信息、房屋详情)
- 实时监控竞品网站,追踪新品、价格变动、市场动态(GetMonetizely)
- 构建高质量线索库,从目录、活动网站、垂直门户抓取联系方式
深度爬取不仅让你拿到更多数据,更让你拿到更有价值、能直接用的数据,助力业务决策。
深度爬取助力竞品情报
比如你的销售团队想锁定刚发布新品的公司,深度爬虫可以:
- 扫描竞品网站的新产品页面
- 跟踪新闻稿、投资者公告等链接
- 提取关键信息(发布时间、价格、功能等)
- 将数据导入 CRM 或分析工具
结果就是:决策更快更准,领先还在用“表面爬取”的竞争对手一步。
合规与最佳实践:用深度爬虫要注意什么?
“能力越大,责任越大”。深度爬虫能获取大量数据,但不代表可以随心所欲。一定要注意:
数据隐私与版权
- 遵守网站服务条款: 很多网站在 TOS 里明确了数据使用范围,违规可能有法律风险(Apify Blog)。
- 避免抓取个人或敏感信息,除非获得明确授权。
- 尊重版权: 不要随意转载或售卖抓取内容,务必核查相关权利。
负责任地爬取
- 控制请求频率: 不要对网站发起过多请求,避免影响其正常运行。
- 查看 robots.txt: 虽然不是法律强制,但遵守网站爬取指引是基本礼仪。
- 关注法律法规: 比如 GDPR、CCPA 等数据保护法规,可能影响你能采集和使用哪些数据(Octoparse)。
想深入了解,推荐阅读 2025 年网页爬取是否合法?。
如何为企业选择合适的深度爬虫方案?
查看 Thunderbit 价格 团队级深度爬取,价格亲民,适合各类企业。 Get Started Free
选深度爬虫工具时,建议关注:
- 易用性: 非技术用户能否快速上手?(Thunderbit:完全可以)
- 可扩展性: 能否应对大型网站、大量页面和动态内容?
- 合规工具: 是否有助于你合法合规地采集数据?
- 集成能力: 能否导出到团队常用工具(Excel、Sheets、Notion、Airtable)?
- 维护成本: 网站变动时能否自动适应,还是要频繁修脚本?
Thunderbit 针对这些需求量身打造,全球 30,000+ 用户信赖,无论是个人创业者还是大型企业都能以低至 $15/月的价格轻松入门。
总结:深度爬虫将成为企业数据战略的核心
回顾一下:
- 深度爬虫是采集复杂网站完整数据的必备工具。
- 它远超传统爬虫,能处理多层级导航、动态内容和隐藏数据。
- 企业团队用深度爬虫洞察市场、驱动销售、监控竞品、加速决策。
- 合规同样重要:始终负责任地爬取,尊重隐私和规则。
- Thunderbit 让深度爬取人人可用,AI 驱动、零代码、数据无缝导出。
如果你准备好告别“表面爬取”,深入挖掘数据价值,下载 Thunderbit Chrome 扩展,亲自体验深度爬取的高效与便捷。更多实用技巧,欢迎访问 Thunderbit Blog,获取最新 AI 网页爬取指南与最佳实践。
常见问题
1. 什么是深度爬虫?它和普通网页爬虫有啥区别?
深度爬虫是一种能穿越网站多层结构、抓取子页面、动态内容和隐藏信息的网页爬虫工具。和只抓表面数据的传统爬虫不同,深度爬虫通过跟踪链接、处理复杂结构,实现全面、完整的数据采集。
2. 为什么 2025 年企业更需要深度爬虫?
现代网站结构越来越复杂,数据经常藏在导航、标签页或动态元素后。深度爬虫帮助企业获取完整数据集,支持销售、市场、调研和竞品分析,而这些是基础爬虫做不到的。
3. Thunderbit 怎么让非技术用户也能轻松深度爬取?
Thunderbit 利用 AI 推荐字段、自动抓取子页面、智能处理动态内容,全部通过简单的零代码界面实现。用户只要描述需求,点“抓取”,就能把结果导出到常用工具。
4. 用深度爬虫时要注意哪些合规问题?
一定要遵守网站服务条款,未经授权不要抓取个人或敏感数据,并关注 GDPR、CCPA 等隐私法规。负责任地爬取和使用数据,是规避法律风险的关键。
5. 深度爬虫能帮销售和市场团队提升业绩吗?
当然。深度爬虫能从电商、房产、竞品等网站挖掘更丰富、更有价值的数据,助力线索挖掘、市场分析和决策提速。借助 Thunderbit 等工具,非技术团队也能轻松获取所需洞察,推动业务增长。
用 Thunderbit 体验 AI 深度爬虫 Get Started Free
了解更多




