
互联网发展速度快得让人都跟不上节奏,数据量更是爆炸式增长。到2025年,全球数据总量预计会达到,比地球上的沙粒还多得多。但这些数据大多分散在各个网站里,杂乱无章,企业想用都没门路。这里说的“爬虫”可不是家里用的那种工具,在数字世界里,爬虫的意义完全不一样。
经常有人问我:“爬虫到底能做什么?”它是机器人吗?黑客工具?还是高级版的复制粘贴?其实,网页爬虫才是互联网背后的无名英雄——它们能把杂乱无章的信息变成整齐的数据表,帮你搞定销售线索、价格监控等各种业务。接下来就聊聊爬虫能做什么、为什么对现代企业这么重要,以及像这样的工具,怎么让数据采集变得又简单又安全。
爬虫的作用是什么?基础原理解析
先说清楚:在数据领域,爬虫不是擦玻璃的工具,而是一种软件(也叫“网页爬虫”),能自动从网站上收集信息,并整理成你能直接用的数据,比如表格或数据库。你可以把它想象成一个超级高效的助手,能在你喝咖啡的时间里,帮你浏览上百个网页,把需要的信息整整齐齐地整理出来。
简单来说:
- 爬虫能帮你“读”网页内容。
- 它会自动查找并提取你需要的数据,比如商品价格、联系方式、评论或房源信息。
- 把这些数据整理成结构化的表格,方便分析或导入到业务系统。
一句话总结:爬虫就是让你从“要是这些信息能直接进 Excel 就好了”变成“表格已经准备好,随时可用”。再也不用手动复制粘贴到天荒地老。
爬虫的核心功能与应用场景
那爬虫到底能帮你做什么?核心功能如下:
| 功能 | 说明 | 常见应用场景 |
|---|---|---|
| 数据提取 | 从网页中抓取特定信息(文本、数字、图片、链接等) | 商品信息、联系方式、用户评论 |
| 数据转换 | 在采集过程中清洗、格式化或分类数据 | 规范化电话号码、SKU 分类 |
| 数据整理 | 将杂乱的网页数据结构化为表格或数据库 | 导出到 Excel、Google Sheets、Notion |
| 自动化 | 定时或批量执行采集任务 | 每日价格监控、大批量线索收集 |
| 子页面导航 | 自动访问链接页面,获取更深入的信息 | 抓取商品详情、作者简介 |
常见应用举例:
- 销售: 从 LinkedIn 或企业名录中提取潜在客户信息
- 电商: 监控竞争对手价格和库存
- 市场营销: 收集用户评论、反馈或社交媒体提及
- 房产: 聚合 Zillow 等平台的房源信息
- 调研: 抓取新闻、学术论文或市场数据
如果你曾经想过“要是这些数据能直接进表格就好了”,那就该用爬虫了。
各行业如何用爬虫实现数据价值
具体来说,不同行业用爬虫能带来哪些提升?
电商:竞争对手监控
如果你开网店,每天都得盯着几十家竞争对手的价格和库存。手动查?根本不现实。有了爬虫,你可以自动抓取竞争对手的价格、商品描述甚至图片,然后在一个仪表盘里对比分析,实时调整自己的定价策略()。
市场营销:用户反馈收集
营销最关心用户反馈。爬虫可以自动收集 Amazon、Yelp 或垂直论坛的评论,分析情感趋势,快速发现用户喜欢或吐槽的点。你不用再手动翻几千条评论,系统就能帮你总结出产品优缺点,为下一步营销决策提供依据()。
房地产:房源信息采集
房产经纪和投资人都需要最新的房源数据。爬虫可以自动抓取 Zillow、Realtor.com 等平台的房源详情、价格、图片和历史走势,帮你更快做市场分析、比价和投资决策()。
案例:销售线索挖掘
销售团队想联系 SaaS 行业的决策人。与其买一份过时的名单,不如用爬虫实时抓取公司官网和 LinkedIn 上的最新姓名、职位和邮箱。这样获得的线索更精准,回复率更高,避免无效沟通()。
数据采集技术的演进:AI 如何提升爬虫效率
以前做网页采集就像打地鼠——每个网站都要写代码或模板,网站一变动,爬虫就失效,半夜还得紧急修复()。
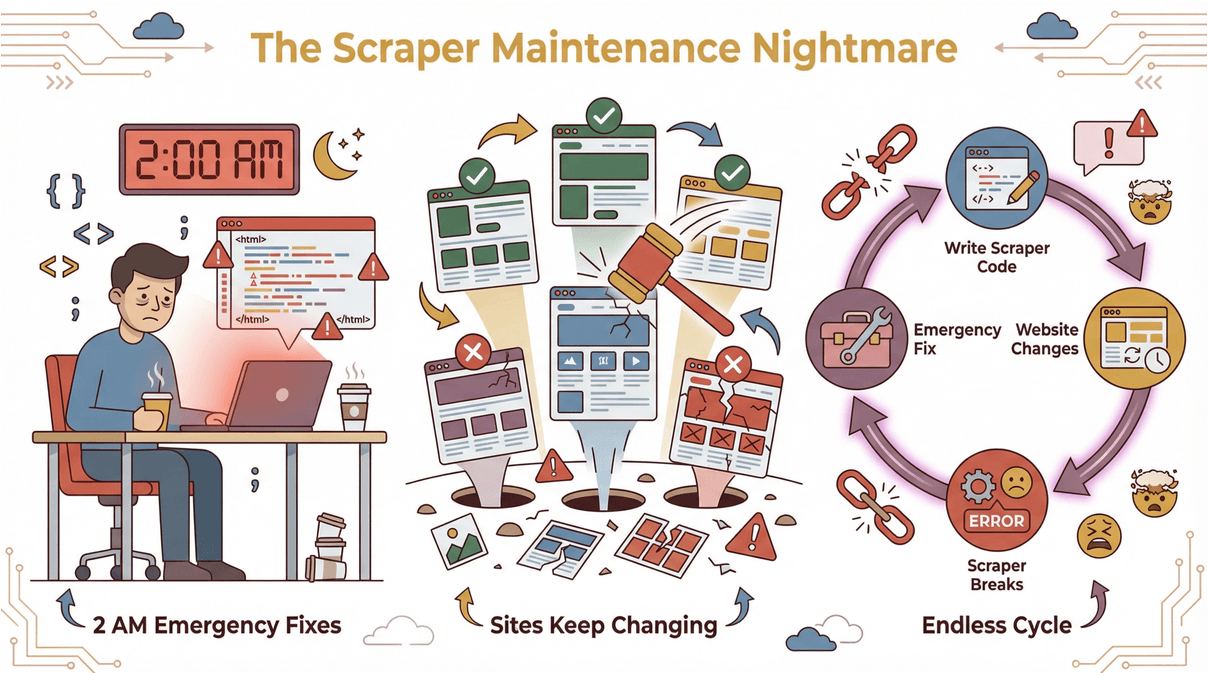 AI 的出现让一切都变了。现在的爬虫(比如 )用上了人工智能,像人一样“读懂”网页。AI 网页爬虫到底有什么优势?
AI 的出现让一切都变了。现在的爬虫(比如 )用上了人工智能,像人一样“读懂”网页。AI 网页爬虫到底有什么优势?
- 无需编程: 只要描述需求(比如“抓取所有商品名称和价格”),AI 自动搞定采集方式。
- 智能字段识别: AI 能自动推荐最适合采集的字段,页面再复杂也不怕。
- 适应页面变化: 网站改版,AI 也能自适应,无需频繁修脚本。
- 适用各种网站: 不管是电商、房产还是多语言页面,AI 网页爬虫都能轻松应对不同结构和数据类型()。
结果就是:上手更快,维护更省心,谁都能用上数据采集,不再是开发者的专属技能。
Thunderbit 如何重塑传统爬虫的使用方式
说实话,我开发 就是因为看不惯企业团队被繁琐、代码密集的爬虫工具折磨。Thunderbit 让数据采集像点外卖一样简单:
- 自然语言提示: 直接用中文或英文告诉 Thunderbit 你要什么数据,无需设置选择器或写代码。
- AI 字段推荐: 一键“AI 推荐字段”,Thunderbit 自动扫描页面,建议如“名称”“价格”“邮箱”等常用列。
- 子页面采集: 需要更详细信息?Thunderbit 可自动访问每个链接页面(如商品详情、作者简介),丰富你的数据表。
- 一键模板: 针对 Amazon、Zillow、Shopify 等热门网站,Thunderbit 提供即用模板,无需配置()。
- 免费数据导出: 结果可直接导出到 Excel、Google Sheets、Notion 或 Airtable,无隐藏费用。
简单操作流程:
- 在目标网站打开 Thunderbit Chrome 插件
- 点击“AI 推荐字段”,让 AI 自动识别数据列
- 一键“采集”,Thunderbit 自动抓取并整理数据
- 导出到你常用的工具,轻松搞定
Thunderbit 已获得,覆盖销售、房产等多个行业。而且有免费版,零成本体验。
爬虫的数据安全与合规性
能力越大,责任越大。用爬虫时,必须遵守网站规定、隐私法规和数据保护要求。你需要注意:
- 遵守 robots.txt: 很多网站会通过
robots.txt文件说明允许采集的内容()。 - 避免采集敏感信息: 未经许可不要抓取个人隐私数据()。
- 合规使用数据: 不要大规模转载或出售采集内容,仅限分析、研究或内部业务用途。
- 关注法律变化: 比如欧洲 GDPR、加州 CCPA 等法规对数据采集有严格要求。
Thunderbit 支持 34 种语言采集,自动遵守网站规则,并倡导合规使用,帮你合法合规地获取数据()。
常见爬虫类型及如何选择
并不是所有爬虫都一样,主要有以下几类:
| 类型 | 优点 | 缺点 | 适用人群 |
|---|---|---|---|
| 浏览器插件 | 易用、免安装、上手快 | 仅能采集浏览器可见内容 | 非技术用户 |
| 云端工具 | 可扩展、后台运行、支持定时任务 | 可能需订阅、前期配置 | 团队、定期任务 |
| 自定义脚本 | 灵活可定制、功能强大 | 需编程、维护成本高 | 开发者、特殊需求 |
如何选择:
- 想要快速、零代码体验,推荐用 Thunderbit 这类浏览器插件
- 需要大规模或定时采集,云端工具更合适
- 追求极致定制且有开发能力,可选自定义脚本
想了解更多,欢迎阅读 。
爬虫未来趋势:AI 与自动化深度融合
未来的爬虫会全面拥抱 AI 和自动化,主要趋势包括:
- 定时采集: 一次设置,自动定期更新数据()。
- 与业务系统集成: 采集数据可直接流入 CRM、仪表盘、分析工具。
- 多语言支持: 能采集全球各类语言网站,拓展数据来源。
- 预测性采集: AI 不仅能抓数据,还能预测下一个有价值的信息()。
- 零维护工具: 网站变动时,AI 自动适应,无需手动修复脚本。
Thunderbit 已经实现了定时采集、子页面导航、AI 字段推荐等功能,未来还会持续创新。
总结:爬虫如何赋能现代企业
所以,爬虫到底能做什么?在数据爆炸的时代,爬虫就像救生艇,帮企业高效收集、整理并利用关键数据。不管你是做销售、电商、市场还是房产,爬虫都能节省时间、提升准确率,挖掘出更多业务洞察。
像 这样的现代工具,让数据采集变得人人可用——无需编程,无需折腾,轻松见效。如果你也想让网页数据高效融入工作流,现在就可以试试。
想知道爬虫能为你的团队带来哪些改变?立即体验。更多实用技巧,欢迎访问 。
常见问题解答
1. 网页爬虫到底是做什么的?
网页爬虫是一种自动化软件,可以从网站上批量采集特定信息,并整理成结构化的表格或数据库。它能帮你省去手动复制粘贴的繁琐,大幅提升数据分析效率。
2. 使用爬虫合法吗?安全吗?
只要遵守网站规定、隐私法规,不采集敏感个人信息,网页采集是合法且安全的。务必查看目标网站的 robots.txt 文件,并合理合规使用数据。
3. AI 网页爬虫和传统爬虫有何不同?
像 Thunderbit 这样的 AI 网页爬虫,能智能理解网页内容、自动推荐字段,并适应页面变化。相比传统模板式爬虫,无需编程、维护更省心、上手更快。
4. 企业使用爬虫的主要好处有哪些?
爬虫能自动化数据采集,节省时间、减少错误,助力线索挖掘、价格监控、市场调研等多种业务,让团队决策更高效、更有数据支撑。
5. 如何选择适合自己的爬虫工具?
如果你不懂技术,建议用 Thunderbit 这类浏览器插件,简单易用。大规模或定期采集可选云端工具,开发者可用自定义脚本。选择时要考虑技术能力、数据量和集成需求。