

上周,我们的一位用户给我们发来消息:“我需要在周五之前拿到 14 家竞品 Shopify 店铺的价格、描述和变体数据。” 这差不多就是 4,000 个商品页面。复制粘贴?根本不现实。
如果你曾经尝试从 Shopify 店铺里提取商品数据——价格、图片、描述、变体、评论——你就知道有多痛苦。截至 2026 年,全球有超过 280 万个活跃的 Shopify 店铺,而它们没有一个自带“导出给外部人员”的按钮。与此同时,72% 的企业表示他们会主动监控竞争对手定价,而电商服务商则指出,哪怕只是手动上传一个带变体和图片的商品,也可能要花掉 15 到 30 分钟 。如果把这个时间乘上几百个商品,你整个星期都没了。
这就是为什么 Shopify 爬虫 Chrome 扩展已经成了电商工具箱里的标配——无论是竞品调研、代发货选品、目录迁移,还是其他用途。不过,大多数“最佳爬虫”文章只是罗列功能,却不展示它们在真实 Shopify 店铺上实际会发生什么。这篇不一样。我拿 8 款扩展在真实店铺上做了测试,碰到了真正的反爬墙,最后找出了哪些工具能拿到你真正需要的深层商品数据,哪些只能停留在表面。
为什么电商团队需要 Shopify 爬虫 Chrome 扩展
Shopify 店铺是商业价值极高的商品数据宝库。但作为外部访问者,你拿不到 CSV 下载,只能看到一个店面。要把这个店面变成可操作的情报,你就需要爬虫——而且用途远不只是“我想要一份商品名称列表”。
真正的问题是:你到底需要什么数据,又是为了什么工作流?下面是最常见的电商场景与具体数据字段的对应关系:
竞品定价调研
你需要:商品标题、价格、划线价,以及按变体拆分的定价。这里是动态定价策略的核心——不仅要知道竞品卖多少钱,还要知道他们如何折扣、捆绑,以及按尺寸或颜色如何定价。
代发货商品选品
你需要:标题、所有图片(不只是缩略图)、完整描述,以及发布日期。按最新发布日期排序,可以帮助你在市场饱和前发现趋势商品或新上架商品。
导入到你自己的店铺目录
你需要:标题、正文 HTML、所有图片、变体、SKU 和价格——最好还能导出成 可直接导入 Shopify 的 CSV。并不是每个工具都能把这件事做得很干净。
销售速度估算
你需要:商品标题和库存数量,并持续跟踪。通过按计划抓取库存水平,你可以估算竞品的动销速度——虽然不精确,但在没有直接销量数据时很有用。
线索生成(寻找店主)
你需要:店铺名称、联系邮箱、电话号码,有时还包括店铺使用的应用或技术栈。销售团队会用这些信息按细分行业或技术特征来构建外联名单。
这里有一份快速参考:
| 使用场景 | 所需关键数据字段 | 推荐工作流 |
|---|---|---|
| 竞品定价调研 | 标题、价格、划线价、变体价格 | 抓取列表页 + 通过子页面补全变体信息 |
| 代发货商品选品 | 标题、价格、图片(全部)、描述、发布日期 | 子页面抓取 + 按最新发布日期排序 |
| 导入到自己的店铺目录 | 标题、正文 HTML、图片、变体、SKU、价格 | 完整子页面抓取 → 导出为 Shopify 导入 CSV |
| 销售估算 | 标题、库存数量(随时间变化) | 定时抓取 → Google Sheets 跟踪 |
| 线索生成(店主联系方式) | 店铺名称、邮箱、电话、使用的应用 | 抓取店铺联系页 + 邮箱/电话提取器 |
我是如何评估这 8 款 Shopify 爬虫 Chrome 扩展的
我安装了全部 8 款扩展,并把它们放到同一批真实 Shopify 店铺上测试——包括公开店铺、受 Cloudflare 保护的店铺,以及禁用了 products.json 的店铺。我不只是看功能列表。我想知道,当你在真实的 Shopify 分类页上点击“抓取”时,究竟会发生什么。
下面是我使用的 8 个评估标准,以及它们为什么对 Shopify 尤其重要:
| 标准 | 为什么对 Shopify 抓取很重要 |
|---|---|
| 上手难度 | 非技术型代发货卖家能否在 5 分钟内开始抓取? |
| 提取的数据字段 | 能否拿到标题、价格、图片、描述、变体和评论,还是只有表层数据? |
| 子页面补全 | 能否先抓列表页,再自动访问每个商品页获取完整信息? |
| 分页处理 | 能否抓到第一页以外的商品(点击分页或无限滚动)? |
| 反爬能力 | 能否处理 Cloudflare Turnstile 或 Shopify 的机器人防护而不崩? |
| 导出格式 | CSV、Excel、Google Sheets、Airtable、Notion、Shopify 导入就绪 CSV? |
| 定时/重复抓取 | 能否自动长期监控价格或库存变化? |
| 价格透明度 | 免费版限制、积分系统、统一收费——以及你真正能得到什么 |
有了这套框架,下面就来看看每个工具的表现。
1. Thunderbit——专为非技术用户打造的 AI Shopify 爬虫
Thunderbit 是我们在 Thunderbit 团队打造的工具,专门面向不写代码、不配置 CSS 选择器、也不想花 20 分钟做初始化的商务用户。它在 Shopify 店铺上的流程真的只要两步:打开分类页,点击“AI 建议字段”,AI 就会读取页面并建议列(标题、价格、图片等)。再点一下“抓取”,列表页就完成了。
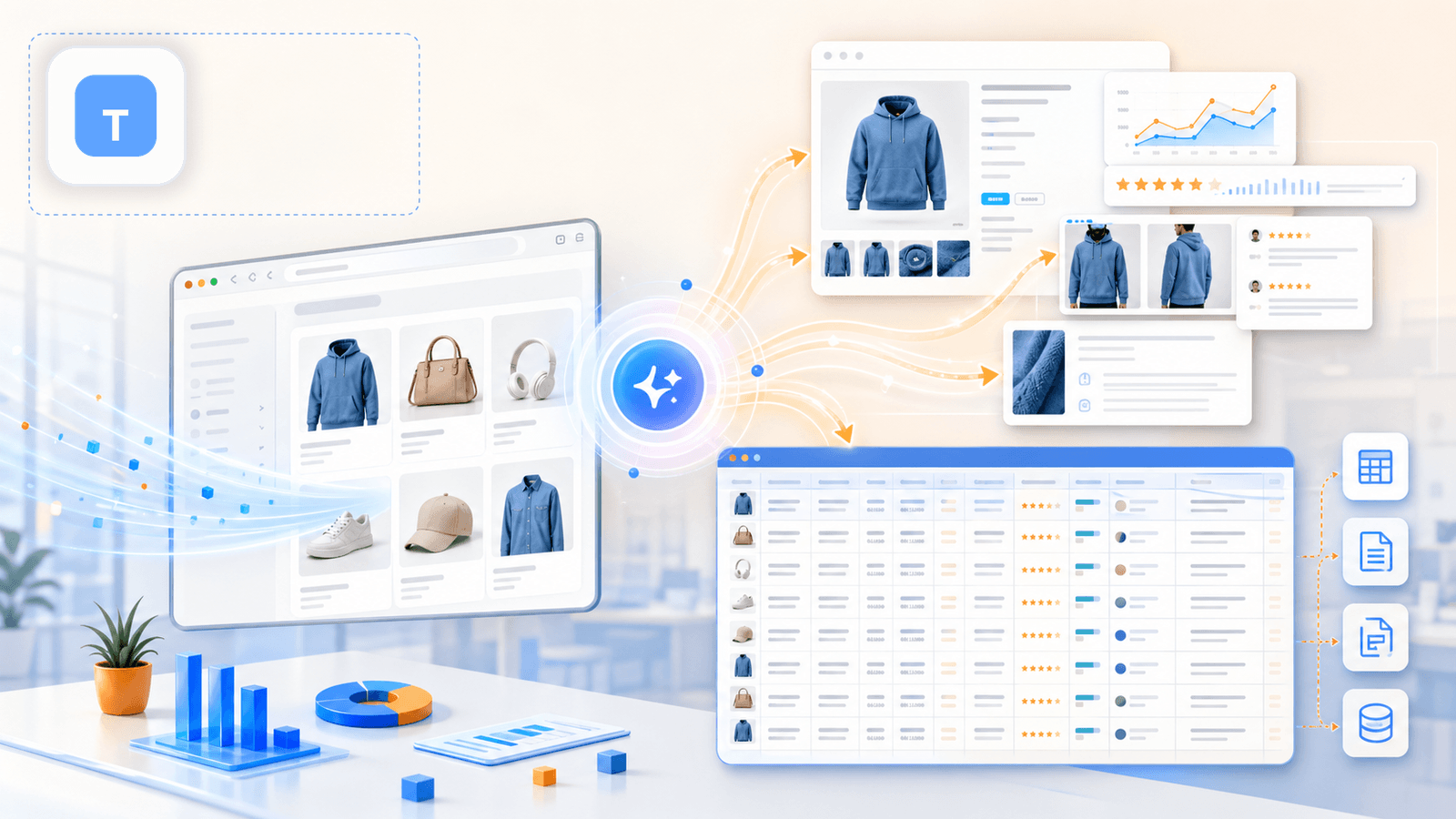
但真正的差异化——也是大多数竞品文章忽略的部分——在于下一步。
子页面补全:改变一切的功能
抓完列表页后,你点击“抓取子页面”。Thunderbit 的 AI 会访问每个单独的商品 URL,并把详情页数据追加到原表格中:完整描述、全部轮播图片、变体选项、SKU、评论数量等等。这一步会把一个浅层表格变成真正可用的竞品研究数据集。
我会在下面的专门章节里更深入解释这为什么重要,并展示前后对比。
Shopify 抓取的核心优势
- AI 建议字段 会读取 Shopify 页面并自动生成正确的列结构——无需 CSS 选择器,也不用手动配置
- 子页面抓取 会补齐列表页缺失的数据(完整描述、变体选项、图片集、评论)
- 云端抓取模式 适合在公开店铺上高速批量提取;浏览器抓取模式 适合 Cloudflare 保护或需要登录的店铺
- 分页处理(点击式和无限滚动)
- 定时抓取 用于持续监控价格/库存——你可以直接用自然语言描述计划(例如“每周一上午 9 点”)
- 免费邮箱和电话提取器,适合线索生成场景
- 导出到 Excel、Google Sheets、Airtable、Notion、CSV、JSON——包括适合 Shopify 导入的格式
- 字段 AI 提示词 可让你为每一列添加自定义指令(例如“将商品分成 3 类”或“把描述翻译成英文”)
不足之处
- 基于积分的定价意味着大规模抓取(数万件商品)需要付费方案
- 与基于模板、且页面非常简单的爬虫相比,AI 处理每行会多花几秒
价格
- 免费版: 6 页(或免费试用最多 10 页),所有导出免费
- 入门版: 15 美元/月,每月 500 积分
- 专业版: 从 38 美元/月(3,000 积分)到 249 美元/月(20,000 积分)
- 积分规则: 1 行输出 = 1 个积分(网页抓取);1 行输出 = 2 个积分(子页面抓取);导出始终免费
最适合: 需要最深层 Shopify 商品数据、又希望零门槛上手的非技术电商团队——以及想持续监控竞品的人。
2. Instant Data Scraper——零配置的自动识别方案
Instant Data Scraper 是一款免费的 Chrome 扩展,它使用启发式算法自动识别网页上的表格数据。完全不需要配置——打开 Shopify 分类页,点击扩展图标,它就会尝试把商品数据识别并展示成表格。
在我的测试里,它在标准的 Shopify Dawn 主题分类页上表现不错,几秒钟内就能抓到标题、价格和缩略图 URL。对于非标准布局的店铺,它偶尔会把导航链接或页脚内容抓进来,而不是商品本身——所以你得自己目测结果。
Shopify 抓取的核心优势
- 完全免费,没有使用限制
- 自动识别意味着零配置时间——很适合快速、一次性的导出
- 支持分页(可自动点击“下一页”)
- 可导出为 CSV 和 XLSX
不足之处
- 在非标准布局的 Shopify 店铺上,自动识别结果不稳定
- 没有子页面补全:你只能拿到列表页上的内容(标题、价格、缩略图),拿不到完整描述、变体或评论
- 没有 AI 来清洗、标注或转换数据
- 没有定时、没有云端抓取
- 不能直接导出到 Google Sheets、Airtable 或 Notion
价格
- 完全免费
最适合: 任何需要从标准 Shopify 店铺中快速、免费、零配置导出可见列表页数据的人。
3. Web Scraper——可视化站点地图构建器
Web Scraper(webscraper.io)是经典的点选式 Chrome 扩展,用来构建“站点地图”——也就是你在页面上选择元素并定义抓取流程的规则。在 Shopify 上,你会通过点击商品标题、价格、图片来创建站点地图,并设置分页和跟随链接的规则。
Shopify 抓取的核心优势
- 可视化选择器构建器比自动识别工具更可控
- 可以跟随链接进入子页面(商品详情页)——但你需要在站点地图里手动配置父子选择器
- 设置正确后可处理分页
- 本地浏览器抓取免费;云端抓取有付费方案(从 50 美元/月起)
- 可导出为 CSV;云端方案支持 Google Sheets 和其他格式
不足之处
- 初始化更费时:为一个新的 Shopify 店铺创建带父子选择器的站点地图,我大概花了 15 分钟
- 子页面抓取需要手动配置链接选择器和子站点地图——不是一键补全
- 一旦 Shopify 店铺改了布局或 CSS 类名,站点地图就容易失效
- 学习曲线比 AI 工具更陡
价格
- 浏览器扩展: 免费
- 云端方案: Project 50 美元/月,Professional 100 美元/月,Scale 从 200 美元/月起
最适合: 喜欢对抓取流程有细粒度控制、并且不介意自己搭建规则的技术用户。
4. Data Miner——基于配方的爬虫
Data Miner(dataminer.io)围绕“配方”运作——也就是预设或自定义的抓取模板,你把它应用到某个页面上。它有一个公开配方库,所以你可能会找到其他用户分享的 Shopify 模板,也可以通过选择页面元素自己创建。
Shopify 抓取的核心优势
- 配方库里可能有其他用户分享的现成 Shopify 模板
- 可视化配方构建器,适合自定义抓取配置
- 通过配方配置可处理分页
- 可导出为 CSV、Excel、Google Sheets 和 TSV
- 有爬取工作流,可在列表页之后访问详情页
不足之处
- 免费版限制为每月 500 页
- 配方基于 CSS 选择器,所以店铺布局一变就容易坏
- 没有 AI 辅助字段建议或数据转换
- 没有内置的一键子页面补全流程——需要单独为详情页建立爬取配方
- 虽然支持定时爬取,但整体定时体验并不算最简单
价格
- 免费版: 每月 500 页
- Solo: 19.99 美元/月
- Small Business: 49 美元/月
- Business: 99 美元/月
- Business Plus: 200 美元/月
最适合: 喜欢使用模板、并希望借助配方库加快常见网站上手速度的用户。
5. Simplescraper——轻量级提取器
Simplescraper(simplescraper.io)是一款极简的 Chrome 扩展和云端爬虫,重点就是简单。你在 Shopify 页面上点击数据元素,Simplescraper 会生成 CSS 选择器并提取匹配数据。
Shopify 抓取的核心优势
- 界面干净简洁,上手快
- 支持云端抓取,可用于定时和批量任务
- 提供 API,方便开发者把抓取数据接入工作流
- 可导出为 CSV、JSON、Google Sheets、Airtable,并支持 webhooks
- 有深度抓取概念,可跟随链接访问详情页
- 支持登录态工作流,适合有会话限制的店铺
不足之处
- 主要是手动选择器方式——没有 AI 自动识别字段
- 子页面抓取需要额外配置
- 与 Web Scraper 或 Data Miner 相比,社区更小、现成模板更少
- 免费版:100 积分(1 个 JS 渲染页面 = 2 积分)
- 付费方案在官网上的定价透明度不如多数竞品
价格
- 免费版: 100 积分
- 付费方案: 第三方资料显示 Plus 约 39 美元/月、Pro 约 70 美元/月、Premium 约 150 美元/月(来自 G2 定价数据)
最适合: 想要一个轻量、现代、集成能力不错的云端爬虫、又不需要 AI 字段识别的用户。
6. Octoparse——由桌面端驱动的 Chrome 扩展
Octoparse(octoparse.com)主要是一款桌面应用,配有一个 Chrome 扩展。它同时提供可视化工作流构建器和面向热门网站的预置模板,其中也包含 Shopify 专用抓取教程。

Shopify 抓取的核心优势
- 针对常见抓取任务提供预置 Shopify 模板
- 功能强大的桌面应用,具备高级能力:IP 轮换、定时抓取、云端提取
- 对分页、无限滚动和 AJAX 加载内容处理得很好
- 这份名单里文档化最完整的反爬能力,包括自动处理 CAPTCHA
- 可导出为 CSV、Excel、JSON、HTML、XML、数据库和 Google Sheets
不足之处
- 单靠 Chrome 扩展功能有限——大多数强大功能都需要桌面应用
- 桌面应用的可视化工作流构建器学习曲线更陡
- 免费版限制较多;真正有意义的使用需要付费方案
- 相比纯 Chrome 扩展工具,初始化更重——不适合想快速 5 分钟内完成抓取的人
- 桌面应用仅支持 Windows/Mac(不是纯浏览器方案)
价格
- 免费方案 可用
- Basic: 39 美元/月
- Standard: 约 83 美元/月(按月),约 75 美元/月(按年)
- Professional: 约 299 美元/月(按月),约 208 美元/月(按年)
- Enterprise: 定制
最适合: 需要企业级抓取、IP 轮换、反爬处理和循环云任务的团队——并且不介意装桌面应用。
7. Bardeen——优先自动化的爬虫
Bardeen(bardeen.ai)是一个浏览器自动化平台,把网页抓取和工作流自动化结合在一起。用户可以创建“playbook”,既能抓数据,也能把数据发送到其他应用——你可以把它理解成“如果我抓到这个,就把它推送到我的 CRM”。

Shopify 抓取的核心优势
- 除了抓取,还能做工作流自动化:抓取 Shopify 数据 → 补全 → 一次 playbook 推送到 CRM 或表格
- 可与 100 多个应用集成(Google Sheets、Airtable、Notion、HubSpot、Slack 等)
- 具备 AI 驱动的数据提取和分类能力
- 在浏览器中运行——不需要桌面应用
- 支持基于时间/日期的自动化调度
不足之处
- 它主要是自动化工具,不是专门爬虫——抓取能力没有专业工具那么深
- 对于只想提取商品列表的用户来说,playbook 的创建过程可能比较绕
- 免费版仅限 100 积分
- 子页面补全和分页处理没有专用抓取工具那么直观
- 如果你只是要抓数据,而不做后续自动化,它可能显得有点过度
价格
- 免费版: 100 积分
- Basic: 10 美元/月,100 积分/月
- Premium: 50 美元/月,1,000 积分/月(按年约 40 美元/月)
- Enterprise: 定制
- 积分模型:每行爬取 1 个积分,每行补全 3 个积分
最适合: 想把 Shopify 数据抓取后,立刻推送到下游应用(CRM、表格、Slack)的一体化自动化团队。
8. Listly——把列表转换成表格的工具
Listly(listly.io)专门用于把网页列表和表格转换成适合电子表格的数据。你在 Shopify 分类页上点击扩展,Listly 会尝试识别商品列表并把它导出为表格。

Shopify 抓取的核心优势
- 界面极其简单——专为一键式列表提取设计
- 很擅长识别重复列表结构(比如商品网格)
- 可直接导出到 Excel 和 Google Sheets
- 支持分组抓取,可一次处理多个 URL
- Business 方案支持定时
不足之处
- 只能抓页面上自动识别到的内容——不能自定义字段
- 没有子页面补全——只能导出列表页级别的数据
- 在非标准 Shopify 主题或大量 JavaScript 渲染的店铺上表现吃力
- 免费版非常有限(每月 10 个 URL)
- 与竞品相比,导出选项较少(主要是 Excel 和 Sheets)
价格
- 免费版: 每月 10 个 URL,基础单页提取,Excel 下载,Google Sheet 导出
- Light: 30 美元/月(按年 187.20 美元)
- Business: 90 美元/月(按年 993.60 美元)——增加高级提取、分组提取、定时、自动滚动/点击、API 测试版
最适合: 想从 Shopify 分类页到表格之间走最简单路径、并不需要深层商品数据的用户。
8 款 Shopify 爬虫 Chrome 扩展横向对比
下面是完整对照表。我尽量在每个单元格里写具体一点,而不是只打勾——因为“支持分页”在不同工具上的含义差别很大。
| 工具 | 上手难度 | 数据字段 | 子页面补全 | 分页 | 反爬处理 | 导出格式 | 定时 | 免费版 / 价格 |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | 非常简单(AI 引导,2 步) | 对非技术用户最强(AI 建议所有相关字段) | 有——一键补全 | 有(点击 + 无限滚动) | 公开站点用云端,受保护站点用浏览器 | Sheets、Airtable、Notion、CSV、JSON、Excel | 有(自然语言定时) | 免费 6 页;付费从 15 美元/月起 |
| Instant Data Scraper | 极其简单(零配置) | 只适合列表级数据 | 无 | 有(自动识别下一页) | 仅浏览器端,没有专门反爬方案 | CSV、XLSX | 无 | 免费 |
| Web Scraper | 中等偏难(手动站点地图) | 如果站点地图搭得好,灵活性很高 | 有,但需要通过链接选择器手动配置 | 有(通过站点地图配置) | 本地浏览器;云端方案支持代理轮换 | 本地可导出 CSV;云端支持更多格式 | 云端方案支持 | 免费扩展;云端从 50 美元/月起 |
| Data Miner | 中等(基于配方) | 如果有现成配方,表现不错 | 有,但需要多步骤爬取设置 | 有(配方配置) | 主要在浏览器端 | CSV、Excel、Sheets、TSV | 有自动爬取 | 免费 500 页/月;付费从 19.99 美元/月起 |
| Simplescraper | 简单到中等(基于选择器) | 适合轻量提取 | 有深度抓取概念,但不是一键式 | 有(支持无限滚动) | 支持代理轮换,适合登录态 | CSV、JSON、Sheets、Airtable、webhooks | 有 | 免费 100 积分;有付费档位 |
| Octoparse | 较难(桌面应用) | 配置好后非常强 | 有,可通过工作流或模板 | 有(AJAX、无限滚动) | 反爬能力最强(IP 轮换、CAPTCHA) | CSV、Excel、JSON、HTML、XML、数据库、Sheets | Standard 及以上支持 | 免费;Basic 39 美元/月;云端从约 83 美元/月起 |
| Bardeen | 中等(playbook 构建器) | 绑定自动化后表现不错 | 在工作流逻辑里可实现,但不是 Shopify 优先 | 可实现 | 在浏览器中运行,反爬不是核心重点 | CSV、Sheets、Airtable、Notion | 可通过自动化实现 | 免费 100 积分;Basic 10 美元/月;Premium 50 美元/月 |
| Listly | 非常简单(一键识别列表) | 最适合可见列表行 | 无 | 仅限自动识别到的列表结构 | 很少 | Excel、Sheets、Business 版支持 CSV/JSON API | Business 版支持 | 免费 10 个 URL/月;Light 30 美元/月;Business 90 美元/月 |
按优先级给出快速结论
如果你需要最深层的 Shopify 商品数据,而且初始化尽量少,Thunderbit 的 AI + 子页面补全是最强组合。如果你需要完全免费、快速粗暴的导出,Instant Data Scraper 适合简单页面。如果你想要完全控制并且不介意自己搭配方,Web Scraper 或 Octoparse 能给你这种能力。如果你的真实目标是抓取 → 自动化 → 推送到 CRM,那就该看看 Bardeen 这种工作流平台。
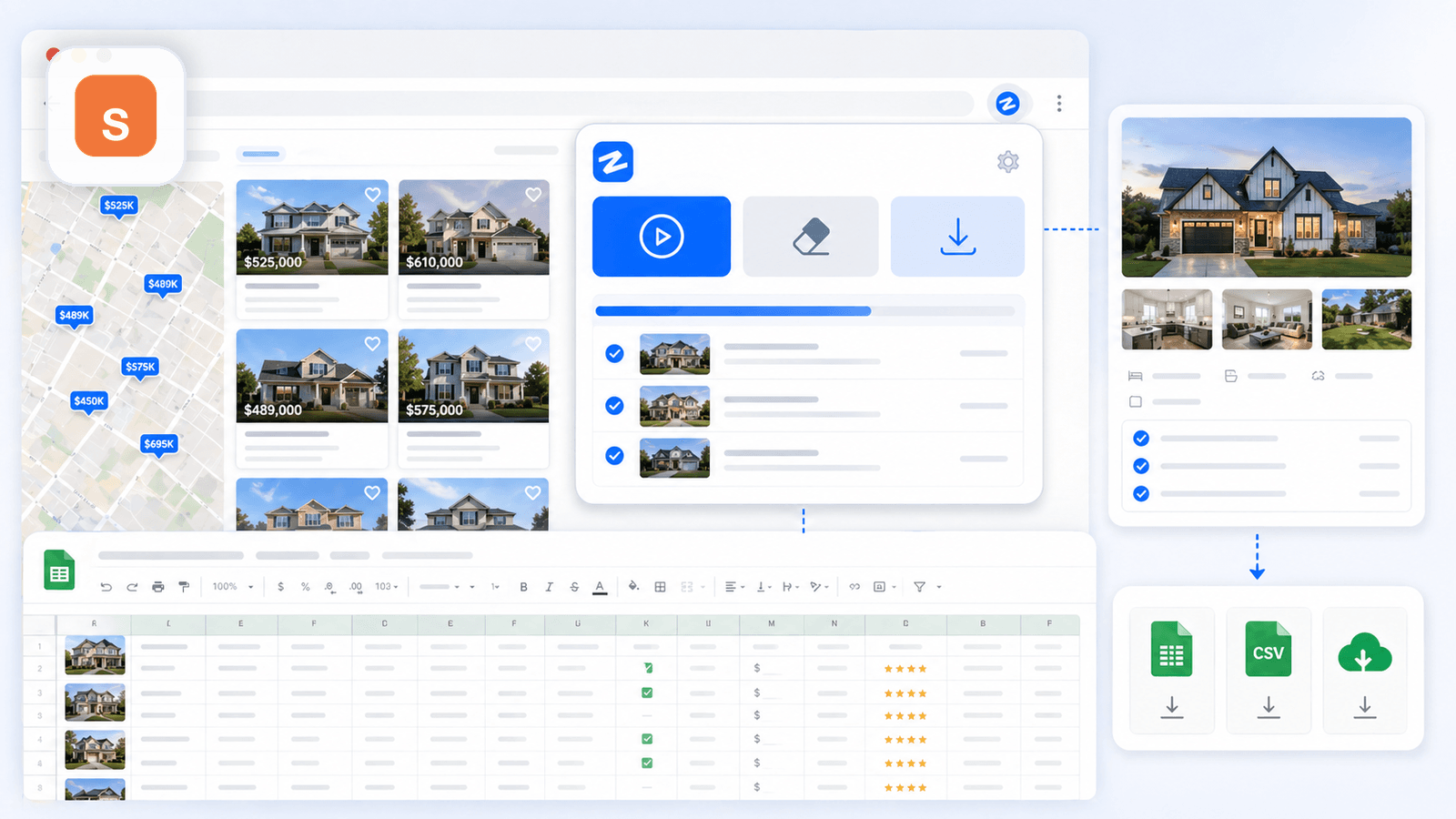
只抓列表页只是做了一半:子页面补全工作流
这一节是我希望所有其他 Shopify 爬虫文章都该写到的,因为它是竞品内容里最大的缺口,也是我从电商用户那里听到的第一大痛点。
当你抓取 Shopify 分类页(列表页)时,你拿到的是表层数据:标题、价格、缩略图,可能还有一段被截断的描述。但你做竞品分析、目录导入或代发货研究真正需要的字段,往往都在单独的商品详情页里。
列表页能拿到什么 vs. 子页面补全后能拿到什么
| 数据字段 | 仅来自列表页 | 子页面补全后 |
|---|---|---|
| 商品标题 | ✅ | ✅ |
| 价格 | ✅ | ✅ |
| 缩略图 | ✅ | ✅ + 全部图库图片 |
| 简短描述 | ⚠️ 已截断 | ✅ 完整 HTML 描述 |
| 变体(尺寸、颜色) | ❌ | ✅ |
| SKU / 库存 | ❌ | ✅ |
| 评论 / 评分 | ❌ | ✅ |
差别非常大。
只导出列表页,你得到的是一张浅层表格;做了子页面补全,你才得到真正可用的竞品研究数据集。
Thunderbit 的子页面抓取怎么做(分步)
- 打开 Shopify 店铺的分类页/列表页
- 点击 “AI 建议字段”——Thunderbit 会读取页面并建议列(标题、价格、图片、链接等)
- 点击 “抓取” 提取列表页数据
- 点击 “抓取子页面”——AI 会访问每个商品 URL,并把详情页数据(完整描述、所有图片、变体、评论)追加到原表格中
- 将补全后的表格导出到 Excel、Google Sheets、Airtable、Notion 或 CSV
整个过程对于普通分类页来说只要几分钟,但你最终拿到的数据集,手工整理可能要花几个小时。
还有哪些工具支持子页面补全?
- Web Scraper: 支持,但需要通过链接选择器和子站点地图手动配置——每个店铺预计要 15–20 分钟
- Octoparse: 支持,可通过工作流构建器或模板实现——功能强,但设置更重
- Data Miner: 支持,但要通过多步骤爬取工作流实现——不是一键操作
- Simplescraper: 有深度抓取概念,但不够即插即用
- Instant Data Scraper、Listly、Bardeen: 没有文档化的一键 Shopify 子页面补全
“技术上可以跟随链接,但要手动配 20 分钟” 和 “一键补全” 之间的差别,就是爬虫工程师工具和电商运营工具之间的差别。
当 Shopify 的 products.json 失效时——为什么 Chrome 扩展是你的备份方案
如果你看过其他 Shopify 抓取指南,大概率见过 /products.json 这个技巧:只要在 Shopify 店铺 URL 后面加上 /products.json,就能拿到 JSON 格式的结构化商品数据。这个端点确实存在,能用时也很方便。
products.json 的工作方式
Shopify 店铺会在 /products.json 暴露一个 JSON API 端点,返回结构化商品数据。你可以通过 ?page=2&limit=250 做分页(每页最多 250 个商品)。
通常返回的字段包括:title、body_html、vendor、product_type、tags、published_at、variants(含 price、compare_at_price、sku、available)以及 images。
products.json 漏掉了什么
- 没有评论数据或评分数量
- 与渲染后的页面相比,描述格式更受限
- 自定义 metafields 往往不会包含在内
- 变体级图片可能不一致
- 没有渲染后的营销内容、徽章或社交证明
products.json 什么时候会失效
我在 2026 年 4 月 27 日对 8 家真实 Shopify 店铺做了直接 HTTP 检查。结果很能说明问题:
| 店铺 | 结果 |
|---|---|
| kith.com | ✅ 可用——干净的 JSON |
| colourpop.com | ✅ 可用 |
| allbirds.com | ✅ 可用 |
| brooklinen.com | ✅ 可用 |
| negativeunderwear.com | ✅ 可用 |
| gymshark.com | ❌ 被拦截——返回 403 HTML 而不是 JSON |
| mvmt.com | ⚠️ 部分禁用——返回 200 HTML 页面,不是 JSON |
| fashionnova.com | ❌ 已禁用——404 |
8 家里有 5 家返回了干净的 JSON,另外 3 家没有。
论坛用户也有同样反馈:“不知为什么,有些 Shopify 店铺就是不会公开 products.json。” 需要密码保护的店铺、自定义 API 配置的店铺,以及受 Cloudflare 保护的域名,都可能打破这个模式。
Chrome 扩展的备选方案
当 products.json 不可用时,Chrome 扩展爬虫会直接从渲染后的页面(DOM)提取数据。这就是基于浏览器的爬虫的核心价值:它们看到并提取的是你在浏览器里看到的内容,不管 API 是否存在。这让 Chrome 扩展成为可靠的 B 计划——而且在你需要评论、营销内容或完整图库这类渲染后页面数据时,它们往往还是 A 计划。
反爬防护:当你抓 Shopify 店铺时,真实会发生什么
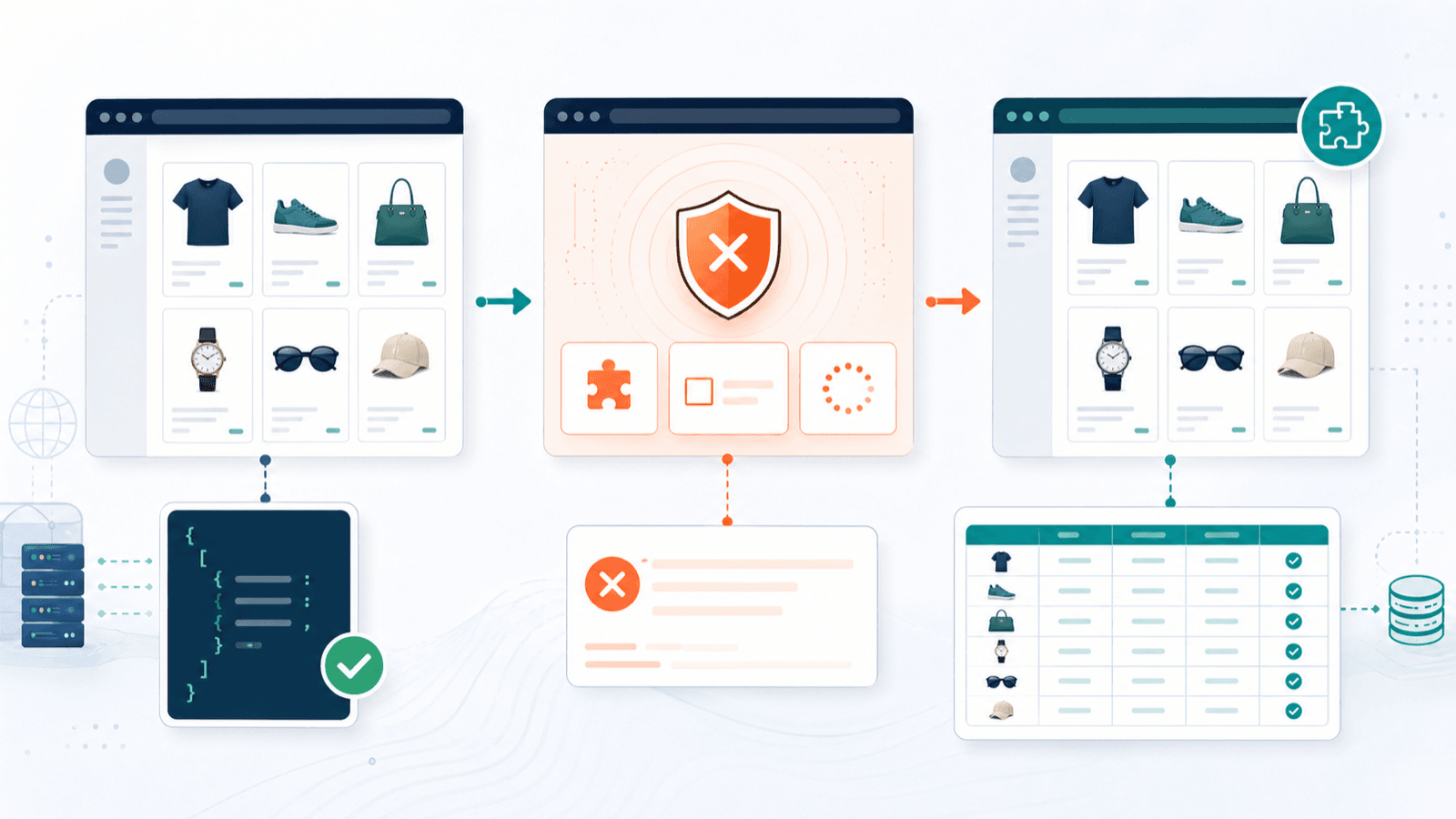
大多数 Shopify 爬虫文章都假设每个店铺都是完全开放的。事实并非如此。Store Leads 报告显示,99.2% 的 Shopify 店铺使用了 Cloudflare 基础设施。这不代表每个店铺都会强力拦截爬虫,但说明用于拦阻的基础设施无处不在。
实际情况大致分成这样:
容易抓取
- 没有强力 Cloudflare 防护的公开店铺
- 启用了 products.json 的店铺
- 使用标准 Shopify 主题的店铺(DOM 结构一致)
更难抓取
- 受 Cloudflare 保护的店铺(CAPTCHA 挑战、Turnstile)
- 需要登录或密码门禁的店铺
- 使用 Shopify Plus 并叠加自定义安全层的店铺
- 限速非常激进的店铺
每个工具如何应对反爬场景
| 场景 | 最佳方式 | 能处理的工具 |
|---|---|---|
| 公开店铺,无反爬 | 云端抓取(更快) | Thunderbit(云端模式)、Instant Data Scraper、大多数其他工具 |
| 受 Cloudflare 保护的店铺 | 基于浏览器的抓取(使用你的会话) | Thunderbit(浏览器模式)、Web Scraper、Octoparse |
| 需要登录 / 私有店铺 | 使用你已登录会话的浏览器抓取 | Thunderbit(浏览器模式)、Web Scraper、Simplescraper |
| products.json 被禁用 | 从渲染页面的 DOM 提取 | 所有 Chrome 扩展(这是它们的强项) |
Thunderbit 的云端/浏览器双模式在这里确实很关键。云端模式适合公开店铺的大批量高速抓取;当反爬防护需要时,浏览器模式会使用你真实的 Chrome 会话。这个灵活性在 gymshark.com 上帮了我一把——云端请求被拦住了,但浏览器模式运行正常。
定时 Shopify 抓取:长期监控价格和库存
一次性抓取当然有用。但电商运营团队通常需要的是持续的竞品情报,而不是一张静态截图。价格变化、库存波动、新品上架,这些都是持续发生的。有位论坛用户说得很直白:“更有帮助的是看到他们当前库存水平,以及库存逐渐减少的快照。”
然而,几乎没有竞品文章会提到定时或循环抓取。这是一个明显的盲区。
Shopify 定时监控是怎么运作的
- 为竞品的分类页或商品页设置循环抓取
- 每次运行后,数据都会导出到 Google Sheets(或 Airtable),形成价格和库存的时间序列
- 利用这些数据跟踪:降价/涨价、缺货、新品增加、季节性模式
使用 Thunderbit 设置定时抓取
Thunderbit 把这件事做得非常简单。
你只需要用自然语言描述计划(例如“每周一上午 9 点”),输入 Shopify 店铺 URL,然后点击“定时”。Thunderbit 会自动运行抓取并导出到你选择的目标位置。没有 cron,没有代码,也不需要第三方定时器。
8 款工具的定时支持情况
| 工具 | 支持定时吗? |
|---|---|
| Thunderbit | 支持——自然语言定时 |
| Instant Data Scraper | 不支持 |
| Web Scraper | 支持——云端方案支持 |
| Data Miner | 有自动爬取,但不是最简单的定时方案 |
| Simplescraper | 支持 |
| Octoparse | 支持——Standard 及以上 |
| Bardeen | 支持——通过时间/日期自动化 |
| Listly | 支持——Business 方案 |
如果你的工作流里包含持续竞品监控,这就是一个关键差异点。大多数免费版 Chrome 扩展根本没有这个能力。
哪个 Shopify 爬虫 Chrome 扩展适合你的场景?

与其用一句泛泛的“选你喜欢的”,不如直接给你一张按具体场景映射的决策表:
| 使用场景 | 最佳推荐 | 原因 |
|---|---|---|
| 竞品定价调研 | Thunderbit | 列表页 + 子页面补全 + 定时 = 完整定价工作流 |
| 快速一次性导出 | Instant Data Scraper | 当你只需要可见列表数据时,它是最快的免费路径 |
| 导入到你的 Shopify 店铺目录 | Thunderbit | 完整子页面数据 + 适合 Shopify 导入的 CSV/Excel 导出 |
| 持续价格/库存监控 | Thunderbit 或 Octoparse | 最简单的无代码定时 vs. 最强的企业级定时能力 |
| 线索生成(店主联系方式) | Thunderbit | 内置邮箱/电话提取器 + 结构化导出 |
| 复杂多步骤自动化 | Bardeen | 在一个工作流里完成抓取、补全和推送到下游应用 |
| 想要完全控制的技术用户 | Web Scraper 或 Octoparse | 对选择器、流程和提取逻辑有最佳手动控制 |
| 仅需可见列表快速转表格 | Listly | 一键识别列表最省事 |
总结
2026 年的 Shopify 抓取,不在于你能不能拿到商品数据,而在于你的工作流有多深、多快、以及多可重复。这个领域的大多数文章只停留在列表页。真正的价值在于子页面补全、定时监控,以及处理真实 Shopify 店铺抛给你的各种反爬难题。
如果你想看看实际效果——从分类页到几次点击后得到完整补全的数据集——不妨试试 Thunderbit。如果 Thunderbit 不是你的完美选择,Instant Data Scraper 是简单任务的不错免费起点;而 Web Scraper 和 Octoparse 则是给想要更多控制权的技术用户的强力选项。
祝你抓取顺利,愿你的商品数据永远完整、结构化,而且变体信息丰富。
试用 Thunderbit 进行 Shopify 抓取 Get Started Free
常见问题
1. 抓取 Shopify 店铺数据合法吗?
Shopify 店铺中公开可访问的商品数据,通常任何访问网站的人都能看到。不过,是否合法取决于你的司法辖区、店铺的服务条款,以及你如何使用这些数据。抓取公开价格用于竞品分析很常见;但如果原样复制内容并重新发布,风险会更高。这不是法律建议——你的具体情况请咨询专业人士。
2. 我可以抓取需要登录或密码的 Shopify 店铺吗?
可以,但你需要一个基于浏览器的爬虫,并且它要使用你已登录的 Chrome 会话。云端爬虫通常无法访问有登录门槛的页面。Thunderbit 的浏览器模式、本地版 Web Scraper,以及 Simplescraper 的登录工作流都支持这种场景。
3. 我一次能从 Shopify 店铺抓取多少商品?
这取决于工具和方案。Shopify 的 products.json 端点按 每页 250 个商品分页。Thunderbit 的云端模式一次最多处理 50 页。大多数工具的免费层都会限制页面数、行数或积分,所以在开始大任务前先确认你的方案额度。
4. Shopify 的云端抓取和浏览器抓取有什么区别?
云端抓取运行在远程服务器上——速度更快,也更适合没有反爬保护的公开店铺。浏览器抓取使用你本地的 Chrome 会话,因此可以处理受 Cloudflare 保护、需要登录或对地区敏感的店铺。Thunderbit 两种模式都支持,通常取决于店铺是否会拦截远程请求。
5. 我可以把抓取到的 Shopify 数据直接导出到 Google Sheets 或 Airtable 吗?
可以,但不是所有工具都支持。Thunderbit 可以免费导出到 Google Sheets、Airtable、Notion、Excel、CSV 和 JSON。Data Miner 和 Listly 支持 Google Sheets。Simplescraper 支持 Sheets 和 Airtable。Octoparse 在高级方案中支持 Google Sheets。Bardeen 可与 Sheets、Airtable 和 Notion 集成。Instant Data Scraper 只支持导出 CSV 和 XLSX,不能直接对接 Sheets。
了解更多




