
你是否也曾陷入这样的循环:在十几个网页上不停点击“下载”,最后才发现自己整个上午都在“伺候”浏览器?你并不孤单。多年来我在 SaaS 和自动化领域工作,见过很多团队把大量时间,甚至精力,都耗在手动下载文件这种重复劳动上。Asana 2023 年《工作解剖指数》——由 ——显示,员工最多有 62% 的时间花在重复性的“围着工作打转”上;而 Smartsheet 对一线员工的调查发现,接近 都被数据录入、文件处理这类手工任务吃掉了。
手动下载不仅烦,还会带来错过更新、版本不一致、文件命名混乱等问题,最后总得有人收拾烂摊子。大多数团队其实没必要忍受这些。在这篇指南里,我们会看看如何自动从网站下载文件,以及像 这样的 AI 工具如何让非开发者也能更快完成整个流程。
为什么手动下载文件会拖慢你的工作流程
说实话,手动下载文件就是效率杀手。问题不只是点来点去浪费时间,更在于它会给业务埋下一串连锁麻烦:
| 手动下载的痛点 | 对工作流程与业务的影响 |
|---|---|
| 步骤繁琐:登录、跳转、逐个点击下载 | 浪费大量时间、报告延迟、决策变慢(例如:每月在发票上花 1–2 天) |
| 格式和命名不统一:文件格式随机,文件名也很难看懂 | 需要额外手动清理,出错风险更高,也更让人抓狂(CSV 导入需要“更多手动设置”) |
| 重复操作容易出错:枯燥的点击很容易漏文件或下错版本 | 数据质量问题、返工,以及每次都得反复核对的烦躁感(手动错误率平均约 1%) |
| 没有自动更新:你得自己记得去检查新文件 | 信息过时、错失机会、响应滞后(漏掉发票或过期的线索名单) |
| 安全隐患:共享账号或以危险方式保存凭据 | 带来安全风险和 IT 负担(脚本里明文密码——太糟了) |
我听过不少团队专门雇人来下载和整理文件,也见过销售运营同事为了整理潜客名单,下午都耗在三个不同门户之间——每个门户还有自己“特别”的格式。这不仅低效,还很打击士气。更别忘了机会成本:每花一小时下载文件,就少一小时创造真正业务价值。
如何自动从网站下载文件:现代做法
想象一下,你只需要对一个智能助手说:“帮我把这个网站上的所有 PDF 抓下来并整理好。”几分钟后,它就替你完成了。这就是现代自动化的价值。
为什么不直接写脚本?
当然,你可以自己写个 Python 脚本,或者做一个 RPA 机器人。问题在于维护成本:昨天还能跑的自定义爬虫,只要供应商门户改了一点 DOM,今天就可能失效,而后面又得有人花时间、有技术能力去追修这些问题。Skyvern 团队。
无代码和 AI 工具登场
现在的自动化工具——尤其是像 这样的 AI 驱动工具——让你不用写一行代码也能自动下载文件。你只要描述目标(“下载所有发票 PDF 以及对应日期”),AI 就会帮你把剩下的事搞定。重点从“写选择器、修选择器”转向“描述结果(下载所有发票 PDF 及其开票日期)”,再让工具去规划提取流程。也正因为如此,它才真正让那些从来不把自己当“爬虫”的人也能上手。
这种变化对业务用户来说意义很大。现在,任何人都能自动下载文件、处理批量任务,甚至搞定复杂的多步骤流程——不需要找 IT 提工单。
文件下载自动化方案对比:哪种最适合你?
不是所有自动化工具都一样。下面我们来看看主流方案的对比:
| 方案 | 易用性 | 设置时间 | 维护成本 | 最适合 |
|---|---|---|---|---|
| Thunderbit(AI 网页爬虫) | 非常容易(点选式、自然语言) | 几分钟 | 很低(AI 可适应变化) | 业务用户、重复任务、文件类型多样 |
| 传统浏览器扩展 | 中等(可视化,但需手动配置) | 数小时(复杂网站) | 中等(网站变动后需手动更新) | 半技术用户、固定布局 |
| Power Automate / RPA | 中等(拖拽式、逻辑流程) | 数小时到数天 | 中等到较高(界面变化会导致流程失效) | 企业级、多应用工作流 |
| 自定义脚本(Python/JS) | 很难(对非程序员) | 数天到数周 | 高(经常失效,需要开发者) | 开发者、追求极致灵活性 |
| 手动操作 | 上手简单,规模一大就很痛苦 | 无 | 持续投入很高 | 一次性或极少量需求 |
对大多数业务用户来说,像 Thunderbit 这样的 AI 工具最合适:搭建快、上手容易、维护成本低。你能获得自动化的全部能力,却不用承担那些麻烦。
Thunderbit 如何让业务用户轻松实现文件下载自动化
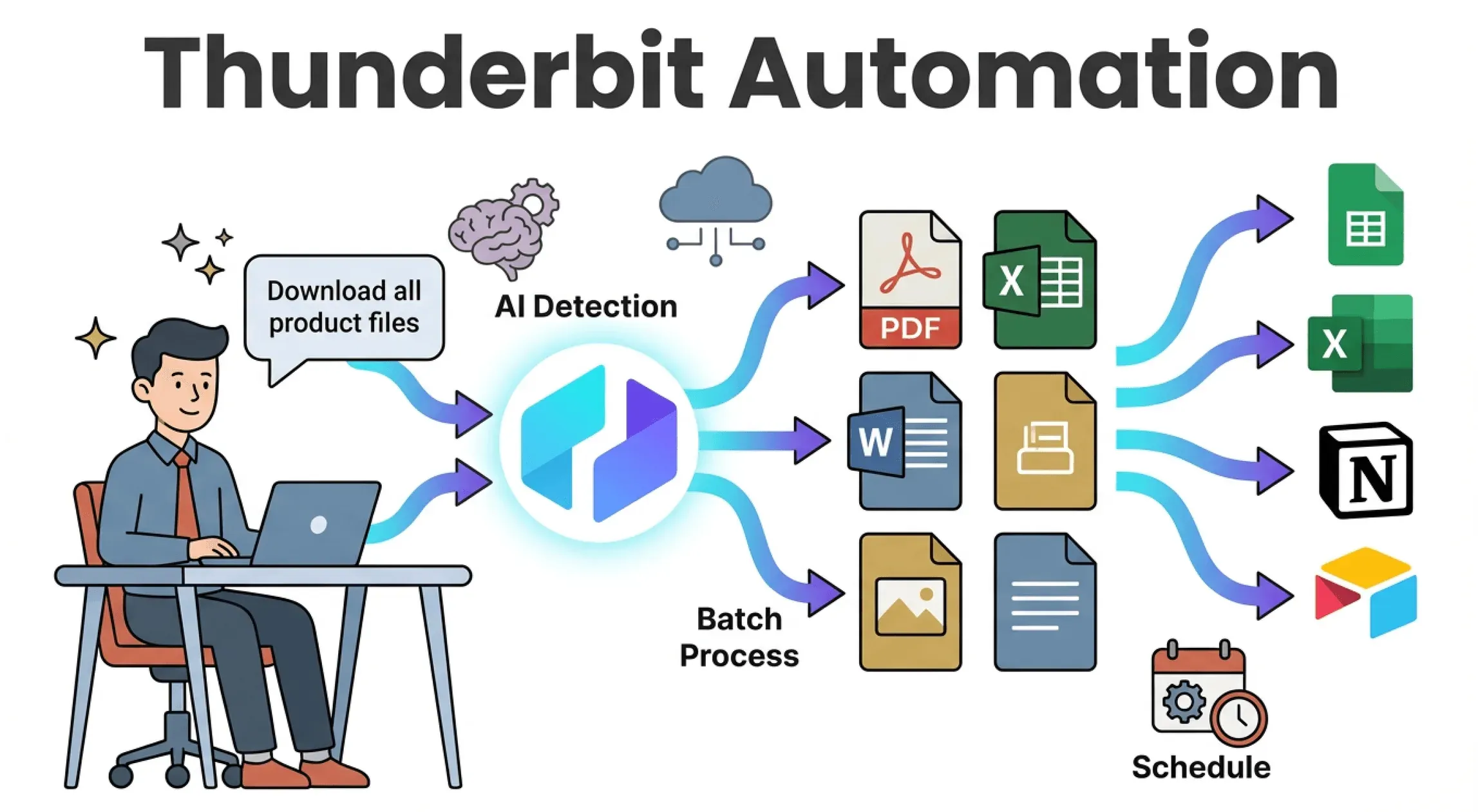 下面来聊聊为什么 是我自动化文件下载的首选——尤其是当你不会写代码时。
下面来聊聊为什么 是我自动化文件下载的首选——尤其是当你不会写代码时。
- “AI 建议字段”作为起点: 点击后,Thunderbit 会扫描页面,自动识别文件链接(PDF、图片、文档)以及旁边的元数据,比如名称或日期。你可以在抓取前确认或修改这些建议。
- 自然语言提示词: 直接用普通语言描述你的目标(“下载所有产品图片和名称”),Thunderbit 的 AI 会自动生成提取方案。
- 支持所有文件类型: PDF、Excel、Word、图片,甚至嵌入式媒体——Thunderbit 都把它们当成普通数据字段来处理。
- 批量与子页面下载: 需要从多个页面抓文件,或者深入子页面获取内容?Thunderbit 原生支持分页和子页面导航。
- 无代码,无需模板: 热门网站可以直接用即用模板;其他网站则交给 AI 处理结构,不用跟选择器较劲。
- 直接导出: 可以把文件下载到本地,或者把结果(连同文件链接或附件)直接导出到 Excel、Google Sheets、Notion 或 Airtable。
- 定时执行: 设置周期性下载(比如“每周一上午 9 点”),就算电脑关机,Thunderbit 的云端也能继续跑。
Thunderbit 面向的是更愿意审核提取结果,而不是长期维护爬虫的业务团队。对于结构清晰的网站,它上手很快;对于复杂或需要登录的页面,你仍然需要花时间检查字段和登录状态,后面我们会讲到。
分步指南:如何用 Thunderbit 自动从网站下载文件
我们来走一遍真实场景——不需要任何技术背景。
第 1 步:安装并设置 Thunderbit
- 安装 。
- 把扩展固定到浏览器工具栏,方便随时使用。
- 点击 Thunderbit 图标并登录(Google 或邮箱都可以,只要几秒)。
- 确保你已经登录了需要访问的网站(Thunderbit 会使用你的浏览器会话)。
就这么简单。通常不到一分钟就能完成设置。
第 2 步:用 AI 定义你的下载任务
- 打开包含目标文件的网页(例如供应商的“报告”页面)。
- 点击 Thunderbit 扩展图标。
- 点击 “AI 建议字段”。Thunderbit 的 AI 会扫描页面,并建议像“文件名”“下载链接”“日期”这样的字段。
- 你也可以输入自然语言提示词,例如:“提取所有 PDF 下载链接及其名称。”
Thunderbit 会自动生成一个待提取内容的表格——不用写代码,也不用模板。
第 3 步:检查并调整下载字段
- 查看 AI 建议: 是否已经包含你需要的所有字段?(文件名、URL、日期等)
- 编辑或新增字段: 重命名列、补充缺失信息,或者删除多余字段。
- 设置数据类型: 确保文件链接被标记为 URL。
- 启用分页或子页面: 如果文件分布在多个页面,打开分页;如果需要点进每个条目才能下载,启用子页面抓取。
Thunderbit 的 AI 通常能做对,但你也可以按需微调。
第 4 步:运行自动化并导出文件
- 点击 “抓取”。Thunderbit 会把所有文件信息收集到表格中。
- 预览结果,确认所有文件和信息都已采集。
- 点击 “导出”。选择你想要的格式:
- 下载文件到电脑(Thunderbit 可以保存成有意义的文件名,而不是“document(17).pdf”)。
- 导出到 Excel、Google Sheets、Notion 或 Airtable(文件可以直接附加到行中)。
- 如果是周期性需求,设置一个计划(比如“每周一上午 9 点”),让 Thunderbit 的云端帮你自动运行。
再也不用一个个点开几十个链接了——Thunderbit 一次就能搞定。
超越自动化:让下载后的文件真正产生业务价值
下载文件只是开始。Thunderbit 的 AI 还能帮你:
- 自动命名和整理文件: 用抓取到的数据给文件命名(如 “Invoice_2025-10.pdf”),并把它们分类到不同文件夹。
- 打标签和分类: 添加供应商、日期或类别等字段,让文件更容易搜索,也更容易转化为行动。
- 丰富数据: 在工作流中直接提取文件里的关键信息(例如发票编号或 PDF 里的到期日)。
- 与工作流集成: 直接把文件和数据导出到团队工具中,无需手动上传。
你可以把它理解成:把一堆原始下载文件,变成结构化、可搜索的业务资产。
实时下载 vs. 批量下载:如何满足你的业务需求
 并不是所有下载场景都一样。有时你需要文件一上线就立刻拿到(实时),有时每周批量处理一次也完全够用。
并不是所有下载场景都一样。有时你需要文件一上线就立刻拿到(实时),有时每周批量处理一次也完全够用。
- 实时 / 定时: 使用 Thunderbit 的调度器按固定间隔运行下载(例如“每天早上 7 点”)。非常适合需要最新潜客名单的销售团队,或追踪每日发票的运营团队。
- 批量 / 按需: 在你需要的时候再运行自动化,特别适合月报或一次性项目。
- 批量抓取: 粘贴一组 URL,让 Thunderbit 一次性处理所有链接()。
让自动化节奏贴合你的业务周期——Thunderbit 给你两种方式都能做的灵活性。
文件下载自动化中的常见问题排查
再好的工具也会遇到小插曲。以下是使用 Thunderbit 时处理常见问题的方法:
- 文件缺失或链接错误: 再检查一遍字段选择。如果 AI 误判了链接,可以手动选择。
- 登录问题: 对于需要身份验证的网站,请使用浏览器模式(Thunderbit 会使用你的会话)。如果是云端抓取,必要时提供登录步骤或令牌。
- 验证码 / 反爬: 降低抓取频率,或者使用支持轮换 IP 的云端模式。
- 网站改版: 如果网页重设计导致自动化失效,重新运行“AI 建议字段”即可适配。
- 额度限制: 监控你的 Thunderbit 点数(1 点 = 1 行)。如果量不够,可以升级套餐。
- 文件没有下载: 有些文件需要保持活跃会话。请使用浏览器模式,或者手动测试链接。
需要更多帮助,可以查看 或联系支持团队。
结论与关键收获:用自动化文件下载释放效率
自动化下载文件不只是省时间,更是在释放更高层次的效率、准确性和业务价值。借助 ,你可以:
- 每周找回数小时,不再被重复且容易出错的任务拖住——Smartsheet 发现,接近 。
- 减少错误,确保你不会错过任何关键文件。
- 更快拿到更新鲜的数据,从而做出更好的决策。
- 让团队无需被 IT 流程卡住,也能推进自动化。
- 把下载直接接入工作流——从 Excel 到 Notion,再到 Airtable。
如果文件下载正持续占用某个人每周一大块时间——每周都要花好几个小时,在同样的供应商门户里反复操作——那就是自动化最值得投入、并且很快能回本的场景。对于轻量或一次性的需求,手动下载依然没问题;目标不是把一切都自动化,而是不再把时间浪费在那些可预测的部分上。
想了解更多网页自动化技巧,可以查看 或订阅我们的 。
常见问题
1. Thunderbit 能自动下载需要登录才能访问的文件吗?
可以——Thunderbit 的浏览器模式会使用你已登录的会话来访问受身份验证保护的文件。对于云端抓取,你可能需要提供登录步骤或令牌。
2. Thunderbit 支持哪些文件类型?
Thunderbit 支持 PDF、图片、Excel、Word 文档以及大多数常见文件类型。它还可以使用 OCR 从 PDF 和图片中提取文本。
3. Thunderbit 如何处理分页或跨多个页面分布的文件?
Thunderbit 的 AI 可以自动识别并处理分页(包括无限滚动)和子页面导航,确保所有文件都被抓取到。
4. 我可以用 Thunderbit 设置周期性下载吗?
当然可以。你可以用调度器设置任意间隔的下载任务(例如“每周一上午 9 点”“每天午夜”之类)。即使电脑关闭,Thunderbit 的云端也会继续执行。
5. 如果网站改了布局怎么办?
Thunderbit 的 AI 能自动适应很多变化。如果发生大改版,只需重新运行“AI 建议字段”来更新自动化即可。
准备好自动化下一次文件下载了吗?,看看它能有多简单。
了解更多