
I’ll never forget the first time I tried to gather data from a few dozen product pages for a side project. I had my coffee, a spreadsheet open, and a sense of optimism. Fast forward two hours, and I was still copy-pasting, my eyes glazed over, and my Ctrl+C/Ctrl+V fingers were begging for mercy. If you’ve ever tried to collect info from a long list of web pages, you know the pain: it’s slow, it’s error-prone, and it makes you question your life choices.
That’s exactly why I’m obsessed with bulk scraping—and why, at , we’ve made it our mission to make extracting data from many URLs as easy as possible. In this guide, I’ll break down what bulk scraping is, why it matters for business users, how it’s evolved, and how you can use Thunderbit to go from “I have a list of 200 URLs” to “Here’s my spreadsheet, ready to go” in just a few clicks. No code, no templates, no headaches.
What is Bulk Scrape? The Basics of Bulk Web Scraping
Let’s start with the basics. Bulk scraping (sometimes called list crawling or URL scraping) is the process of extracting data from a whole list of web pages—rather than scraping one page at a time. Instead of opening each link, copying the info you need, and pasting it into a spreadsheet (and repeating until you lose the will to continue), bulk scraping lets you hand a list of URLs to a tool and have it do the heavy lifting for you.
In other words, bulk scraping is like hiring a super-fast, never-tired assistant to visit every link in your list and copy the relevant info into a spreadsheet. It’s web scraping, but at scale. This is different from traditional web scraping, which often focuses on pulling data from a single page or crawling a website one page at a time. With URL scraping, you’re telling the tool, “Here’s my list—go get the data from each of these pages.”
If you want a more technical analogy, think of the difference between copying one row of a spreadsheet and importing the entire spreadsheet in one go. Bulk scraping is that “import” button for the web.
For a deeper dive into the concept, check out .
Why Bulk Scrape Matters for Business Users
Let’s be honest: nobody wakes up excited to copy-paste data from 100 web pages. But for sales, ecommerce, operations, and research teams, getting data from the web is a daily necessity. Bulk scraping isn’t just a buzzword—it’s a productivity multiplier.
Here’s why it matters:
- Speed: What used to take hours (or days) can now be done in minutes or seconds ().
- Accuracy: Automation reduces human error and ensures consistency across your dataset.
- Scale: Need to pull info from 200 product pages? 500 real estate listings? Bulk scraping makes it feasible.
- ROI: Companies that switch to modern, AI-driven scrapers report saving 30–40% of their time on data extraction tasks ().
Let’s look at some real-world business use cases:
| Use Case | Pain Point (Manual) | Benefit of Bulk Scraping |
|---|---|---|
| Lead Generation | Copying contact info one by one is slow | Scrape thousands of leads in one go, filling a sheet with names, emails, phones |
| Competitor Price Tracking | Daily checking of competitor sites | Monitor all product URLs for price changes, enabling dynamic pricing and quick reaction |
| Market/Content Research | Reading many articles/reviews manually | Scrape data from multiple articles or reviews at once for larger, up-to-date datasets |
| Product Data Management | Merging info from various sources is error-prone | Pull specs, stock, etc. from all supplier sites into one file, consistently formatted |
| Real Estate Listings | Manually aggregating listings takes hours | Scrape dozens of listing pages across sites for a unified, up-to-date view |
The bottom line: bulk web scraping boosts productivity and data-driven decision-making across sales, marketing, operations, and more ().
Comparing Bulk Scraping Solutions: From Manual to AI-Powered Tools
Bulk scraping has come a long way. Let’s walk through the main approaches, from the “old school” to the AI-powered present—and see why Thunderbit’s approach is different.
Manual Bulk Scraping: The Old Way
Remember my copy-paste marathon? That’s manual bulk scraping. You open each page, copy the info, paste it into Excel, and repeat. It works for five URLs. For 50? Not so much. It’s slow, boring, and you’ll probably make mistakes or miss updates ().
Template-Based and Code-Driven Bulk Scraping
Next up: code scripts (like Python with BeautifulSoup) and template-based tools. If you can code, you can write a script to loop through your URLs and extract what you need. Powerful, but you need programming skills—and every time the website changes, your script might break. Maintenance is a pain.
Template-based tools let you visually select fields on a page, then apply that “template” to a list of similar pages. This is great for non-coders, but you still have to build a template for each site or page type. If your list of URLs comes from different sites or the pages aren’t structured the same, things get tricky.
Thunderbit’s One-Click Bulk Scrape Advantage
Here’s where Thunderbit shines. Our approach is simple: paste your list of URLs, click once, and get structured data—no templates, no coding, no setup. The AI figures out what to extract based on your column names or suggestions. Even if the pages are a little different, Thunderbit adapts.
Let’s compare:
| Method | Ease of Use | Flexibility | Technical Skill Needed | Setup Time | Speed | Handles Mixed Page Types? |
|---|---|---|---|---|---|---|
| Manual Copy-Paste | Low | High | None | High | Slow | Yes (but painful) |
| Code Script | Low | Very High | High | High | Fast | Yes (if you code for it) |
| Template-Based Tool | Medium | Medium | Low | Medium | Fast | Only if pages are similar |
| Thunderbit (AI Bulk) | Very High | High | None | Low | Very Fast | Yes |
For a real-world example: scraping 100 product URLs would take hours manually, maybe an hour with a template tool, but just a few minutes with Thunderbit ().
Step-by-Step Guide: How to Bulk Scrape URLs with Thunderbit
Let’s get practical. Here’s how you can bulk scrape a list of URLs using —no technical skills required.
Step 1: Install Thunderbit Chrome Extension
First, grab the . Just search for “Thunderbit AI Web Scraper” in the Chrome Web Store, or head to our . Click “Add to Chrome,” confirm, and you’re set. Over already trust Thunderbit, so you’re in good company.
You might need to sign up or log in—don’t worry, the free tier lets you try bulk scraping right away.
Step 2: Prepare Your List of URLs for Bulk Scraping
Now, gather your URLs. You can:
- Export them from a CRM or spreadsheet
- Copy product page links from a competitor’s site
- Collect LinkedIn profile URLs for lead generation
- Manually copy links you want to scrape
Format them as a simple list—one URL per line in a text file or spreadsheet. For example:
1https://www.example.com/product/123
2https://www.example.com/product/456
3https://www.example.com/product/789Pro tip: Remove duplicates and make sure the URLs are accessible (if a page requires login, Thunderbit needs to be logged in too).
Step 3: Paste URLs and Launch the Bulk Scrape
Here’s where the fun begins:
- Click the Thunderbit icon in your Chrome toolbar.
- Switch the data source to “URLs” or “URLs List.”
- Paste your list of URLs into the input box (or upload a CSV if you prefer).
- Click “AI Suggest Columns”—Thunderbit’s AI will analyze one of the pages and suggest relevant fields (like “Product Name,” “Price,” “Email,” etc.).
- Adjust the suggested columns if needed, or add your own.
- Click “Scrape”. Thunderbit will visit each URL, extract the data, and compile it into a table.
You can keep working in other tabs while Thunderbit does its thing. For big lists, Thunderbit runs multiple threads and respects website speed limits to avoid getting blocked.
Step 4: Review and Export Scraped Data
Once the scrape is done, Thunderbit shows your results in a table. Preview the data—each row is a page, each column is a field you defined.
Export options include:
- Copy to clipboard or download as CSV (great for Excel or Google Sheets)
- Export directly to Google Sheets, Airtable, or Notion (with one click)
- Download as JSON (for developers or advanced workflows)
You can also save your scraper template for next time.
Step 5: Troubleshooting and Tips for Better Bulk Scraping
Even with AI, web scraping can hit snags. Here are some tips:
- Some URLs didn’t scrape? Check if they require login or have unusual structures. Try Thunderbit’s “Browser mode” for tricky pages.
- Missing data in a column? Make your column name more explicit, or use Thunderbit’s “Custom Instruction” feature to guide the AI.
- Large lists slow? Break them into chunks (e.g., 200 URLs at a time) or use Thunderbit’s cloud scraping option.
- Avoid getting blocked: Don’t scrape too quickly. Use reasonable delays and respect websites’
robots.txtand terms of service. - Need more data from subpages? Enable subpage scraping to follow links within each page (like product reviews or author bios).
If you need more help, Thunderbit’s and support are always available.
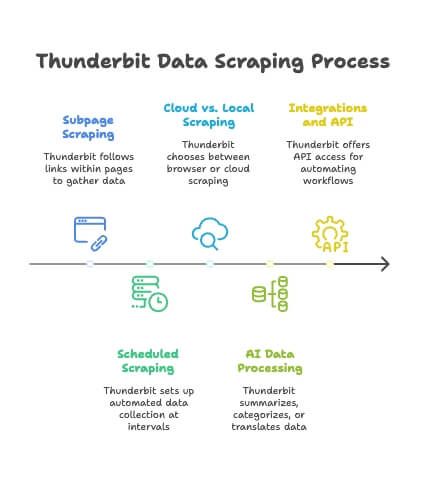
Advanced Bulk Scraping Features: Subpage Scraping, Scheduling, and More
Thunderbit isn’t just about one-off scrapes. Here are some advanced features that make bulk scraping even more powerful:
- Subpage Scraping: Thunderbit can follow links within each page (like “Reviews” tabs or author profiles) and merge that data into your main table. The AI adapts to different subpage layouts—no extra setup required ().
- Scheduled Scraping: Need fresh data every day? Set up a scheduled bulk scrape to run at intervals (hourly, daily, weekly). Your Google Sheet or database will update itself—no manual effort.
- Cloud vs. Local Scraping: By default, Thunderbit runs in your browser, but you can also use cloud scraping for faster, large-scale jobs.
- AI Data Processing: Thunderbit can summarize, categorize, or translate data as it scrapes, so you get enriched datasets without extra steps.
- Integrations and API: For power users, Thunderbit offers API access and integration hooks for automating scraping workflows.
For more on these features, check out our .
Bulk Scraping for Different Teams: Sales, Ecommerce, Real Estate, and Beyond
Bulk scraping isn’t just for data geeks (though, hey, we’re a fun crowd). Here’s how different teams use it:
- Sales: Scrape LinkedIn or directory profiles for leads. Build a list of prospects with names, titles, emails, and more—ready to import into your CRM.
- Ecommerce: Monitor competitor prices, stock, and product details across hundreds of pages. Set up scheduled scrapes to keep your pricing strategy sharp.
- Market Research: Aggregate news articles, reviews, or forum posts for trend analysis. Larger, fresher datasets mean better insights.
- Operations: Collect specs, compliance info, or supplier data from multiple sites—automatically and on schedule.
- Real Estate: Aggregate property listings from sites like Zillow or . Get a unified view of the market in one spreadsheet.
Practical tip: For recurring tasks, save your templates and schedule scrapes. For one-off research, just paste your URLs and go.
Bulk Scraping Best Practices: Staying Organized and Compliant
With great scraping power comes great responsibility. Here’s how to stay organized and ethical:
- Organize your data: Use clear file names (like
leads_scraped_Aug2025.csv), add timestamps, and keep track of sources. - Clean and deduplicate: Remove duplicate entries, sanity-check your data, and fix obvious errors before analysis.
- Respect website terms: Only scrape publicly available data, and always check the site’s terms of service and
robots.txt. - Handle personal data carefully: If you’re collecting emails or names, be mindful of privacy laws like GDPR. Don’t misuse sensitive info.
- Be polite: Don’t overload websites—use reasonable scraping speeds and schedule scrapes during off-peak hours.
For more on staying compliant and organized, see .
Conclusion & Key Takeaways
Bulk scraping has gone from a “nice-to-have” to an absolute necessity for anyone who needs web data at scale. With Thunderbit, you don’t need to be a coder, a template wizard, or a spreadsheet ninja. Just paste your URLs, click, and watch the data roll in.
Key benefits of bulk scraping with Thunderbit:
- Ease of use: No technical skills required—just paste and go ().
- Speed and scale: Gather thousands of data points in minutes, not hours ().
- Flexibility: Works on almost any website, with AI adapting to different layouts ().
- Data quality: AI-driven extraction means more accurate, ready-to-use data ().
- Empowering teams: Sales, marketing, ops, and research can all get the data they need—no IT bottleneck ().
Ready to give it a try? , so you can experiment with bulk scraping on a small scale and see the results for yourself. Think of a data problem you have—a list of URLs you wish you could quickly get info from—and test it out. You might solve a task that’s been on your plate for weeks in just a few minutes.
Harnessing web data at scale is a competitive advantage. With bulk scraping and tools like Thunderbit, that advantage is finally within reach for everyone. Happy scraping—and may your Ctrl+C/Ctrl+V days be behind you for good.
Want to learn more about web scraping, list crawling, or advanced scraping techniques? Check out the and our deep dives:
And if you want to see Thunderbit in action, subscribe to our for tutorials and tips.
FAQs
1. What is bulk web scraping and how is it different from traditional scraping?
Bulk web scraping, also called URL scraping or list crawling, is the process of extracting data from a pre-defined list of web pages all at once. Unlike traditional scraping which typically focuses on crawling entire websites or scraping one page at a time, bulk scraping allows users to paste a list of URLs and extract specific data fields directly from each link—ideal for product pages, listings, or directories.
2. Who benefits the most from bulk scraping?
Bulk scraping is useful across many teams and roles. Sales teams use it for lead generation by extracting contact info from LinkedIn or directories. Ecommerce businesses use it to monitor competitor prices and stock levels. Real estate agents aggregate property listings, and market researchers collect reviews or articles in bulk. Essentially, any team needing structured data from multiple URLs will benefit.
3. How is Thunderbit different from other bulk scraping tools?
Thunderbit stands out by offering a no-code, AI-powered experience. Unlike traditional scraping tools that require coding or templates, Thunderbit lets users simply paste a list of URLs and click once to extract structured data. It handles different page types, auto-suggests fields, supports subpage scraping, and integrates directly with tools like Google Sheets, Airtable, and Notion.
4. What kind of data can Thunderbit extract during a bulk scrape?
Thunderbit can extract product names, prices, stock status, contact details (emails, phones), titles, reviews, specifications, and more. The AI automatically detects relevant fields based on your column suggestions or the page structure. You can even scrape subpages, translate content, or summarize information as part of the extraction process.
5. Is bulk scraping legal and safe to use for business?
Bulk scraping is legal when done responsibly and ethically. You should only scrape publicly available data, respect the website's robots.txt file and terms of service, and avoid collecting personal data without proper consent. Thunderbit encourages compliance by throttling scraping speeds, supporting login-based scraping when needed, and offering features to help clean and organize the data responsibly.