
Na semana passada, passei 40 minutos depurando um script Python impecável que funcionava bem em três sites de teste — só para descobrir que o quarto site estava protegido pelo Cloudflare. O scraper ficava preso em um loop na página "Checking your browser…" e só devolvia HTML de desafio. Soa familiar?
Se você já bateu nessa parede, não está sozinho. usam Cloudflare hoje, incluindo na internet. Isso faz do Cloudflare a barreira mais comum para quem tenta coletar dados da web — seja para geração de leads, monitoramento de preços, pesquisa imobiliária ou análise da concorrência.
O problema é que a maioria dos guias joga todas as técnicas de bypass numa lista única, sem dizer qual você deve tentar primeiro no seu caso. Este guia segue outra lógica: uma árvore de decisão priorizada, estimativas honestas de confiabilidade e um caminho sem código que a maioria dos artigos ignora por completo.
- Dificuldade: Iniciante a Intermediário (depende do método escolhido)
- Tempo necessário: ~10–30 minutos para o caminho sem código; varia nos métodos com código
- O que você vai precisar: navegador Chrome (para o caminho sem código), opcionalmente Python 3.9+ (para métodos com código) e a URL de destino
O que é a proteção Cloudflare (e por que ela bloqueia seu scraper)?
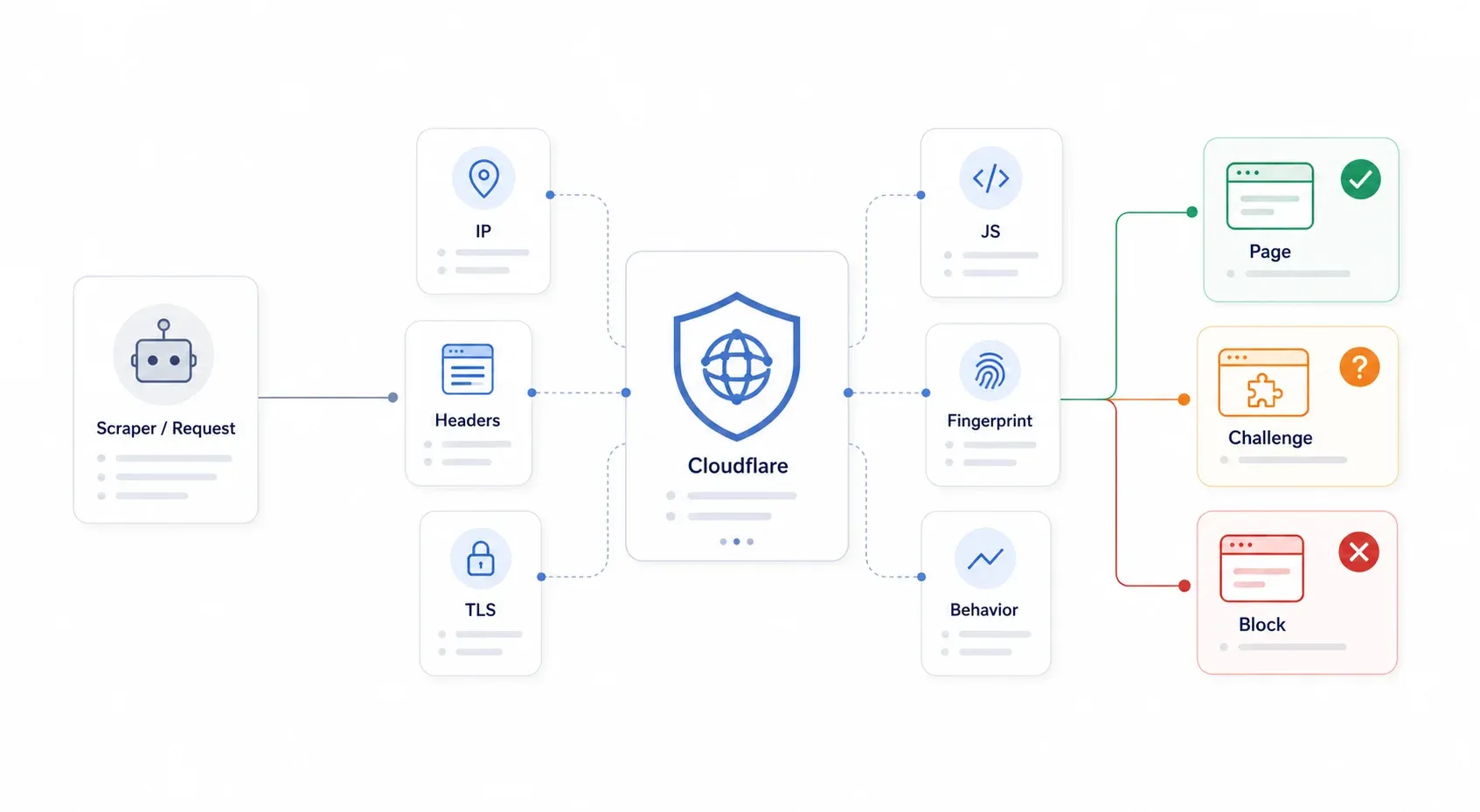
O Cloudflare é um proxy reverso que fica entre o visitante e o servidor de origem do site. Toda requisição passa primeiro pela borda do Cloudflare, e é ele quem decide se entrega a página, se apresenta um desafio ao visitante ou se bloqueia tudo de vez. O ponto principal é entender que o Cloudflare não precisa saber que seu scraper é malicioso. Basta classificar sua requisição como automatizada demais ou suspeita.
O sistema de do Cloudflare usa várias camadas — não é uma única tranca, mas um verdadeiro posto de segurança. Ele avalia reputação de IP, headers HTTP, fingerprints TLS, execução de JavaScript, fingerprint do navegador e padrões comportamentais. Quando sua biblioteca Python requests faz um GET em uma página protegida pelo Cloudflare, ela falha em várias camadas ao mesmo tempo: handshake TLS diferente do esperado, sem execução de JavaScript, sem cookies, sem fingerprint de navegador. É por isso que simplesmente falsificar headers deixou de funcionar há anos.
Os sintomas mais comuns são: 403 Forbidden, 503 com "Checking your browser…", 1020 Access Denied, loops infinitos de desafio, widgets do Turnstile que nunca resolvem e páginas HTML de desafio quando você esperava JSON.
Detecção passiva: o que o Cloudflare verifica antes mesmo da página carregar
Antes mesmo de você ver a página, a camada passiva do Cloudflare já classificou sua requisição:
- Reputação de IP: IPs de datacenter, faixas hospedadas em nuvem e saídas de proxies conhecidas costumam ser sinalizadas. IPs residenciais e de operadoras móveis são . Relatos da comunidade em 2026 mostram consistentemente que o acesso residencial local passa, enquanto ambientes em Docker ou VPS são bloqueados.
- Análise de headers HTTP: o Cloudflare compara User-Agent, Accept-Language, ordem dos headers e versão do HTTP. Uma inconsistência — por exemplo, dizer que é Chrome 136 enquanto o seu handshake TLS entrega "Python" — é um sinal claro.
- Fingerprint TLS (JA3/JA4): durante o handshake TLS, seu cliente revela um padrão de cifras suportadas, extensões e preferências de protocolo. comprime isso em um identificador. Um Chrome real e um script em Python
requestsdeixam assinaturas bem diferentes. - Fingerprint HTTP/2: navegadores e bibliotecas HTTP diferem nos frames SETTINGS do HTTP/2, na ordem dos pseudo-headers e no comportamento de prioridade. O trabalho de do Cloudflare vai além da identidade de uma única requisição e acompanha padrões entre requisições ao longo do tempo.
- AI Labyrinth: este é o recurso mais novo do Cloudflare. Em vez de bloquear crawlers suspeitos, ele que parecem plausíveis, mas desperdiçam recursos do crawler. Seu scraper talvez nem perceba que caiu na armadilha.
Detecção ativa: desafios executados no navegador
Quando as verificações passivas não são conclusivas, o Cloudflare parte para desafios ativos:
- Desafios JavaScript: o clássico intersticial "Checking your browser…". As do Cloudflare executam scripts invisíveis para identificar requisições automatizadas.
- Turnstile: a substituição do CAPTCHA do Cloudflare. Os incluem Managed, Non-Interactive e Invisible. Ele analisa movimentos do mouse, ambiente do navegador, fingerprint TLS e muito mais — sem necessariamente exibir um quebra-cabeça visível.
- Fingerprint de Canvas e WebGL: essas verificações identificam navegadores headless que renderizam de forma diferente de um navegador real.
- Sinais comportamentais: tempo entre requisições, padrões de rolagem, sequência de cliques. Um scraper que busca 50 páginas em 3 segundos sem nenhum movimento de mouse não parece humano.
A conclusão prática: se o Cloudflare já escalou para um desafio ativo, clientes HTTP puros como requests, httpx ou até curl_cffi não passam. Você precisa de algo que execute um ambiente de navegador real.
Níveis de proteção do Cloudflare: por que o mesmo script funciona em um site e falha em outro
É exatamente isso que a maioria dos guias de bypass ignora. A proteção do Cloudflare não é uniforme. Um site no plano gratuito com "Security Level: Medium" é um desafio completamente diferente de um site Enterprise com Bot Management e Turnstile ativados. O mesmo script que passa tranquilamente em um pode travar completamente no outro.
| Nível do Cloudflare | Defesas típicas | Dificuldade de bypass | O que costuma funcionar |
|---|---|---|---|
| Plano Free (baixa segurança) | Bot Fight Mode, regras básicas de WAF, reputação de IP | ⭐ Baixa | Descoberta de API interna, curl_cffi com headers adequados, sessão real no navegador |
| Plano Pro (médio) | Super Bot Fight Mode, Managed Challenge, detecções de JavaScript | ⭐⭐ Média | Sessão real no navegador, automação de navegador com stealth, proxies residenciais |
| Business | WAF mais forte, Bot Analytics, desafios mais rígidos em caminhos críticos | ⭐⭐⭐ Média–Alta | Extração via sessão do navegador, persistência de sessão, proxies residenciais/móveis, APIs pagas de scraping |
| Enterprise / Bot Management | Bot scores, campos JA3/JA4, regras por endpoint, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Alta | API interna (se houver acesso), ferramentas com sessão de usuário real, APIs de scraping de nível profissional |
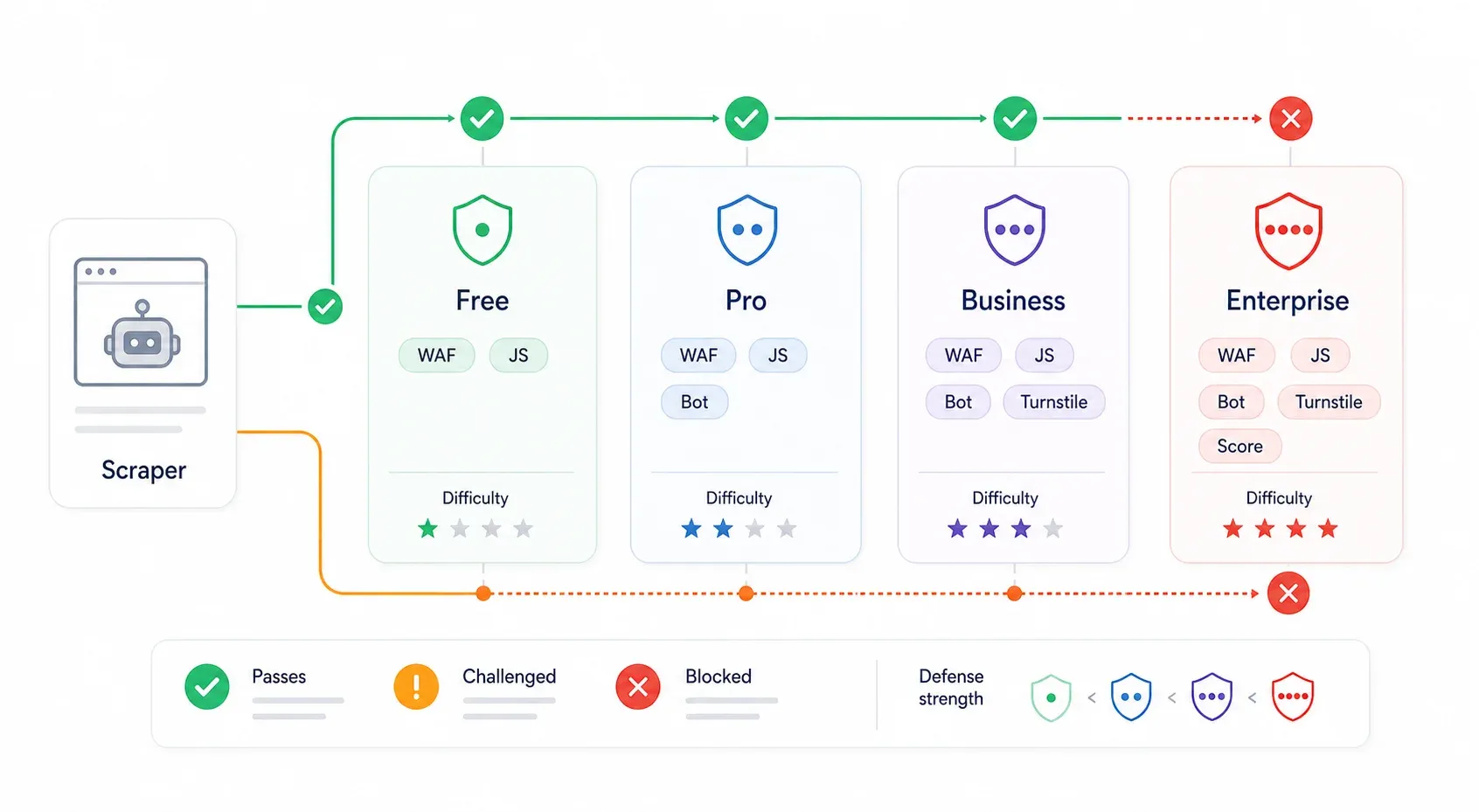
A mostra Free por US$ 0, Pro por US$ 20/mês, Business por US$ 200/mês e Enterprise com preço sob consulta. O é o simples botão de ativação do plano Free; o adiciona mais controles para Pro/Business; e o Bot Management do Enterprise inclui bot scores granulares e regras específicas por endpoint.
Como identificar rapidamente o nível que você está enfrentando: um 403 com bloqueio marcado pelo Cloudflare e sem script de desafio costuma indicar WAF ou rejeição por fingerprint. Um cf-turnstile div ou o script challenges.cloudflare.com/turnstile/v0/api.js indica Turnstile. Um intersticial "Checking your browser" indica Managed Challenge. Falhas específicas por rota, depois de carregar a home com sucesso, costumam apontar para regras de WAF ou Bot Management por endpoint.
Identifique o nível de proteção antes de escolher sua abordagem. Isso economiza horas de depuração.
A árvore de decisão "tente isso primeiro" para contornar o Cloudflare
Em vez de testar métodos aleatoriamente, siga uma abordagem priorizada. Comece pelo mais fácil e confiável, e só avance quando precisar:
| Etapa | Tente primeiro | Por quê | Se falhar → |
|---|---|---|---|
| 1 | Verifique se existe uma API interna/não documentada | Ignora o Cloudflare por completo; é o caminho mais rápido e confiável | Etapa 2 |
| 2 | Use uma ferramenta sem código com renderização de navegador integrada (ex.: Thunderbit) | Sem configuração, lida com desafios de JS automaticamente | Etapa 3 |
| 3 | Impersonação de fingerprint TLS (curl_cffi) | Rápido, leve, sem necessidade de navegador | Etapa 4 |
| 4 | Automação de navegador com stealth (SeleniumBase UC / Puppeteer stealth) | Lida com desafios JS + fingerprinting | Etapa 5 |
| 5 | FlareSolverr + Docker | Open-source, amigável para servidores | Etapa 6 |
| 6 | API paga de scraping (ScrapingBee, ZenRows, Scrapfly etc.) | Transfere toda a guerra para o provedor | — |
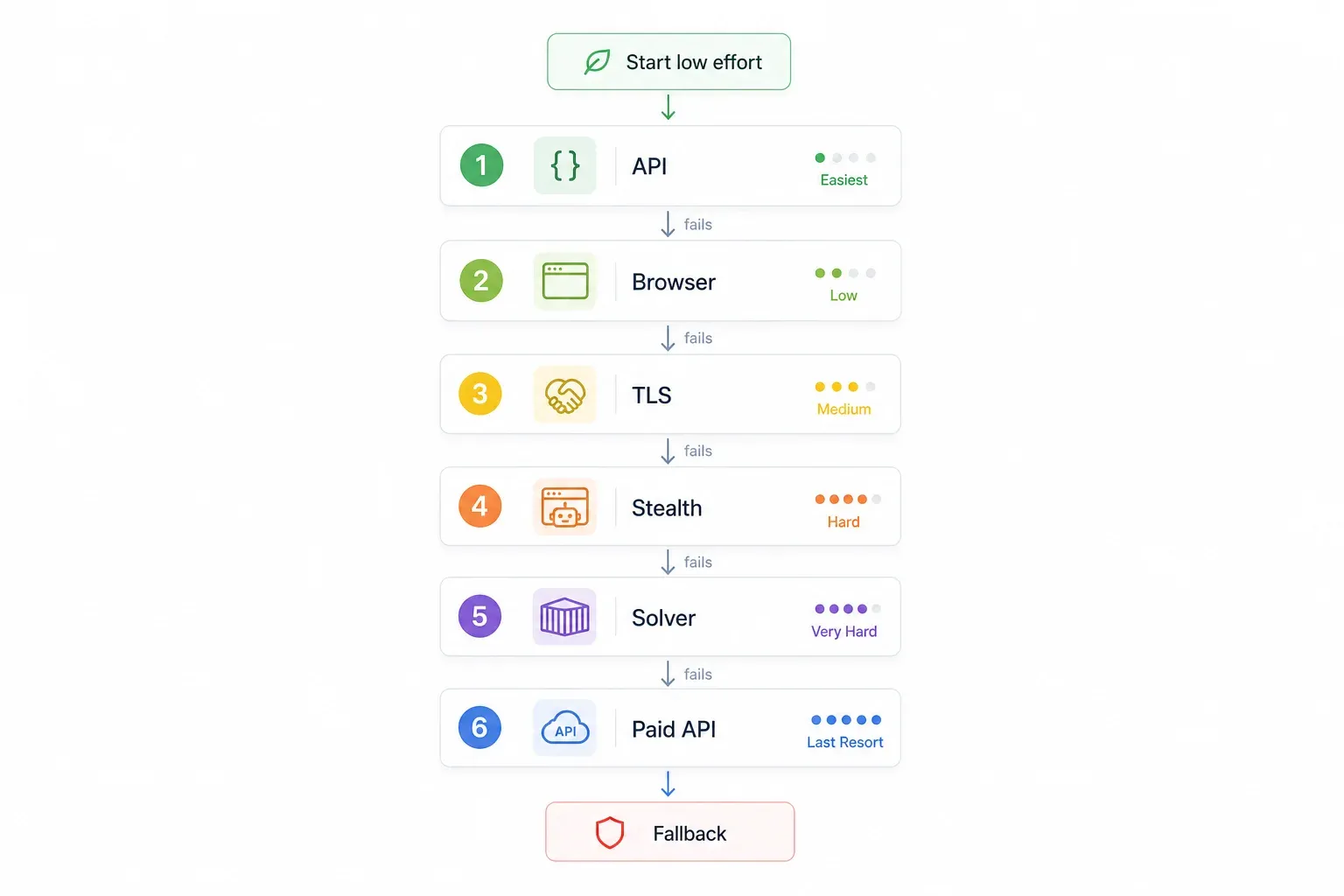
A lógica é simples: primeiro o que exige menos esforço, por último o que custa mais ou depende de código. Vá direto para a etapa que faz sentido para o seu cenário.
Um afirmou que curl_cffi passou em 16 de 20 domínios testados (80%), o FlareSolverr cobriu cerca de 55–70%, e agregadores pagos de proxies chegaram a aproximadamente 97% de sucesso médio — mas o mesmo tópico alerta que esses números mudam conforme o Cloudflare é atualizado. Trate todas as taxas de sucesso como orientação, não como garantia.
Etapa 1: pule a briga — encontre a API interna por trás do Cloudflare
Quatro threads diferentes em fóruns que encontrei recomendam descobrir a API interna do site em vez de enfrentar o Cloudflare de frente. E, sinceramente, esse é o melhor primeiro passo. Se o site tem uma API interna, você contorna o Cloudflare por completo — sem truques, sem falsificação de fingerprint, sem plugins stealth.
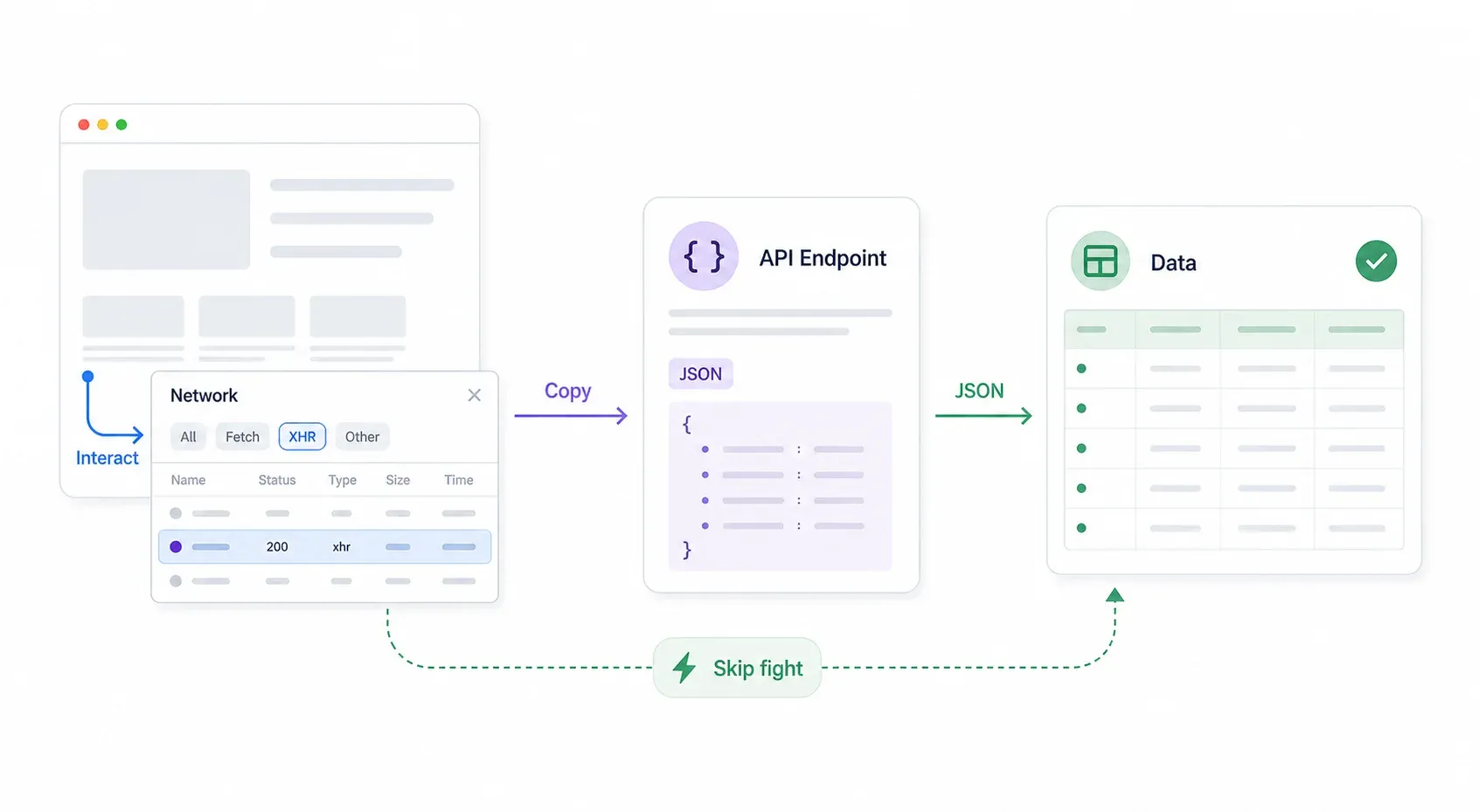
Aqui está a abordagem sistemática:
- Abra o Chrome DevTools → vá até a aba Network → filtre por XHR/Fetch.
- Interaja com a página: pesquise, filtre, navegue por páginas, role. Observe respostas JSON aparecendo na aba Network.
- Inspecione a URL e os headers da requisição. Muitas vezes o endpoint da API não tem a mesma proteção do Cloudflare, ou tem proteção mais fraca do que a página front-end.
- Clique com o botão direito na requisição → Copy → Copy as cURL. Cole no terminal ou no Postman e teste.
- Reproduza a requisição em Python (usando
requestsoucurl_cffi) com os mesmos headers, cookies e parâmetros de consulta.
Se a API devolver JSON estruturado, talvez você nem precise de um scraper tradicional. Uma descreveu exatamente esse cenário: um usuário bloqueado pelo Cloudflare apesar de usar curl_cffi descobriu que o único caminho viável era interceptar diretamente a resposta da API.
Dica prática: depois que o cURL copiado funcionar, comece a remover headers desnecessários. Headers como sec-ch-ua, cookies, tokens CSRF e referer podem ser obrigatórios; controles de cache do navegador normalmente não são. Mantenha o fingerprint TLS consistente com o User-Agent ao sair de um cURL de navegador para código.
Limitações: nem todo site tem uma API acessível. Algumas APIs exigem autenticação, tokens CSRF, parâmetros assinados ou cookies vinculados à sessão. Mas, quando funciona, esse é o método com algo próximo de 99% de sucesso e praticamente sem manutenção.
Etapa 2: o caminho sem código — contorne o Cloudflare com uma extensão de navegador (Thunderbit)
Todos os guias concorrentes assumem que o leitor escreve Python ou JavaScript. Mas essa palavra-chave também atrai equipes comerciais montando listas de leads, operações de ecommerce monitorando preços da concorrência e analistas imobiliários extraindo dados de imóveis. Essas pessoas não querem subir containers Docker.
Uma extensão do Chrome como o lida naturalmente com muitos controles do Cloudflare porque opera dentro da sua sessão real de navegador. Ela herda o fingerprint TLS legítimo do Chrome, seus cookies, seu estado de login e seus sinais comportamentais — exatamente o que o Cloudflare considera confiável. Sem plugins stealth, sem xvfb-run, sem comandos de terminal.
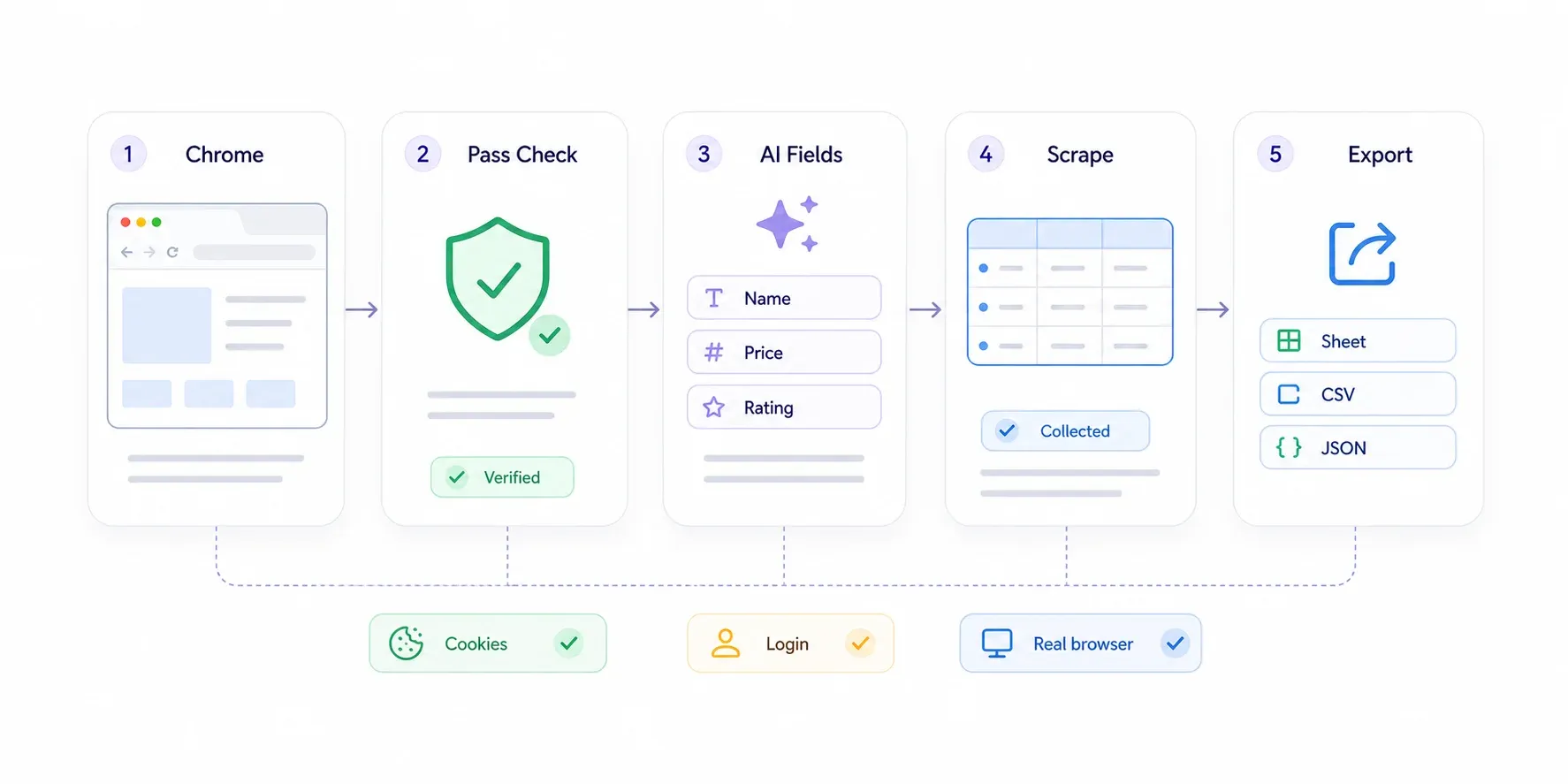
Passo a passo
- Instale a na Chrome Web Store.
- Acesse a página protegida pelo Cloudflare no Chrome. Se o Cloudflare desafiar você, passe como um usuário normal — clique na caixa do Turnstile, aguarde a página "Checking your browser" desaparecer. Você está em um navegador real, como uma pessoa real; o Cloudflare libera.
- Clique em "AI Suggest Fields" na barra lateral do Thunderbit. A IA analisa a página e sugere colunas de dados como "Product Name", "Price", "Rating" ou qualquer outra que faça sentido.
- Revise os campos sugeridos. Remova o que não precisa e adicione campos personalizados descrevendo em linguagem natural o que deseja.
- Clique em "Scrape." O Thunderbit extrai os dados da página visível.
- Exporte para Google Sheets, Excel, Airtable, Notion, CSV ou JSON.
Para sites com paginação, o Thunderbit lida tanto com paginação por clique quanto com rolagem infinita. Para páginas de detalhe (por exemplo, se você tiver uma lista de links de produtos e quiser puxar especificações de cada página individual), use — o Thunderbit visita cada página vinculada e enriquece sua tabela.
Na minha experiência, esse fluxo leva cerca de 5–10 minutos da instalação até a planilha exportada para um conjunto típico de 50–100 linhas.
Quando o scraping baseado no navegador funciona melhor — e quando não funciona
Quero ser transparente sobre as limitações. O scraping baseado no navegador depende da velocidade da sua sessão. Ele é ideal para tarefas de escala moderada — de centenas a poucos milhares de páginas. Se você precisa rastrear milhões de páginas em uma agenda recorrente, vai querer métodos baseados em código ou API.
A opção de Cloud Scraping do Thunderbit pode acelerar o processo, fazendo scraping de até 50 páginas por vez em sites publicamente acessíveis. E, para fluxos de trabalho de desenvolvedor ou maior escala, a do Thunderbit lida com renderização JavaScript, proteção anti-bot e rotação de proxies com processamento em lote de até .
Mas para o usuário de negócios coletando leads, dados de preços ou anúncios imobiliários em escala razoável? Muitas vezes esse é o único método de que você precisa. Sem código, sem proxies, sem manutenção.
Etapa 3: spoofing de fingerprint TLS com curl_cffi (abordagem leve com código)
Se você se sente confortável com Python e o caminho sem código não se encaixa no seu fluxo, é a opção de código mais leve. É um binding Python em torno do libcurl que consegue imitar fingerprints TLS de navegadores reais. Ao contrário de requests ou httpx, seu handshake TLS parece ter vindo do Chrome ou do Safari.
Em 2026, os incluem chrome136, safari184 e muitos perfis históricos. A biblioteca teve um , então continua ativamente mantida.
Quando usar: sites com proteção Cloudflare de nível Free ou Pro que dependem principalmente de fingerprinting passivo — sem desafio JavaScript ativo, sem Turnstile.
Exemplo básico:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Um erro comum: mantenha seu User-Agent coerente com o alvo de impersonação. Se você está imitando o Chrome 136, não envie uma string de User-Agent do Chrome 120. A inconsistência é um sinal.
Limitações: curl_cffi não executa JavaScript. Se o site exibir um desafio "Checking your browser" ou um widget Turnstile, esse método falha. Ele também não ajuda em sites que exigem estado de sessão baseado em cookies vindo de um desafio do navegador. Pense nele como uma primeira tentativa rápida e barata para proteção apenas passiva.
Alternativas da mesma família: tls-client e curl-impersonate oferecem capacidades semelhantes de impersonação TLS.
Etapa 4: automação de navegador com stealth (Puppeteer Stealth e SeleniumBase UC)
Spoofing TLS não basta quando o site exige execução de JavaScript, desafios ativos ou Turnstile. Nesse ponto você precisa de um navegador completo. Duas opções principais:
- SeleniumBase UC Mode (Python): a como uma forma de a automação parecer mais humana e evitar serviços anti-bot. Inclui exemplos de tratamento do Cloudflare Turnstile.
- Puppeteer com
puppeteer-extra-plugin-stealth(Node.js): ainda é muito usado, mas . Relatos da comunidade descrevem falhas por detecção de CDP (Chrome DevTools Protocol) e perfis de navegador incompatíveis.
Ambas as ferramentas abrem um navegador Chromium real, mas mascaram sinais detectáveis de automação: navigator.webdriver, metadados de WebGL, lista de plugins e muito mais.
Dicas de configuração que realmente importam:
- Use modo com interface (não headless). A documentação do SeleniumBase alerta que o UC Mode é detectável em modo headless. Em servidores Linux, use uma tela virtual.
- Randomize o tamanho da viewport e o User-Agent, mas mantenha tudo coerente entre si e com a geolocalização do proxy.
- Adicione atrasos realistas entre ações. Um intervalo de 200 ms entre carregamentos de página denuncia um bot.
- Persista cookies e perfis do navegador depois de passar no desafio inicial. Não resolva o desafio a cada requisição.
- Combine com proxies residenciais para melhorar a reputação do IP.
O risco dessa abordagem é a manutenção. Pilhas de automação de navegador quebram quando o Chrome atualiza, quando o Cloudflare adiciona um novo sinal, quando um plugin stealth fica desatualizado ou quando o alvo adiciona Turnstile específico por rota. Um mostrou que muitas configurações stealth falham nos testes de fingerprint por causa de combinações "franken-fingerprint" — timezone, idioma e geografia do proxy incompatíveis.
Esse método é poderoso, mas caro operacionalmente. Reserve tempo para ajustes contínuos.
Rotação de proxy: por que o IP importa tanto quanto o fingerprint
Mesmo com stealth perfeito no navegador, enviar requisições demais a partir de um único IP aciona limites de taxa. O Cloudflare confia muito mais em IPs residenciais e móveis do que em IPs de datacenter.
- Proxies residenciais: em volumes iniciais em 2026. São mais confiáveis, mas mais caros.
- Proxies de datacenter: mais baratos, mas .
- Estratégia de rotação: faça rotação por sessão, não por requisição. Rotação por requisição quebra cookies vinculados à sessão e
cf_clearance. Mantenha IP, cookies e fingerprint consistentes dentro de uma sessão.
Não existe uma "quantidade mínima mágica" de proxies. Um scraping de leads de baixo volume pode funcionar com algumas sessões residenciais persistentes; um monitor de preços de alto volume pode exigir centenas de saídas e lógica de retry.
Etapa 5: FlareSolverr — o servidor open-source para contornar Cloudflare
é um servidor proxy open-source que usa Chromium com undetected-chromedriver em um container Docker para resolver desafios do Cloudflare e devolver cookies/headers para reutilização. Ele teve um , então segue sendo mantido ativamente.
Quando usar: pipelines de scraping no lado do servidor em que você precisa de um serviço persistente para resolver desafios — por exemplo, um job automatizado executado todas as noites que precisa de cookies cf_clearance novos.
Como funciona: seu scraper envia uma URL para a API do FlareSolverr. O FlareSolverr abre a página em um navegador, tenta resolver o desafio e retorna o HTML junto com os cookies. Depois disso, você pode reutilizar esses cookies no seu cliente HTTP normal para as requisições seguintes.
Visão geral da configuração: Docker Compose, subir o container, enviar requisições POST para o endpoint local da API. .
Limitações que vale deixar claras:
- Não consegue resolver de forma confiável desafios interativos do Turnstile nem o Enterprise Bot Management.
- e mostram comportamento inconsistente: detecção de desafio falha, timeouts no Turnstile, crashes da página.
- Exige infraestrutura Docker e manutenção contínua.
- Consome muitos recursos — cada resolução de desafio abre um contexto de navegador.
Confiabilidade estimada: 60–80% em alvos com proteção média. Menor em Enterprise, maior em páginas de desafio mais simples. Se o FlareSolverr não der conta, é hora de considerar APIs pagas.
Etapa 6: APIs pagas de scraping que lidam com Cloudflare por você
Às vezes a conta fecha assim: manter sua própria infraestrutura stealth custa mais em horas de engenharia do que uma assinatura. APIs pagas de scraping tiram toda a guerra de braços do seu time e entregam para um provedor especializado — você envia a URL, e eles cuidam de fingerprinting, proxies, resolução de desafio e retries.
Como compará-las:
| Provedor | Suporte ao Cloudflare | Renderização de JS | Proxies residenciais | Saída estruturada | Modelo de preço |
|---|---|---|---|---|---|
| ScrapingBee | Sim | Sim | Sim | Apenas HTML | Créditos por requisição |
| ZenRows | Sim (afirma >99% de sucesso) | Sim | Sim (premium) | HTML, alguma análise | CPM com multiplicadores |
| Scrapfly | Sim (lista CF, Akamai, DataDome) | Sim | Sim | HTML, alguma análise | Baseado em créditos |
| Browserless | Sim | Sim (Chrome headless) | Sim (incluído) | HTML, screenshots | Baseado em unidades |
| Thunderbit API | Sim | Sim | Sim | JSON/CSV estruturado com esquema de IA | Plano gratuito + planos pagos |
Quando isso faz sentido: scraping em alto volume, requisitos de confiabilidade de nível enterprise ou quando seu time não quer manter infraestrutura de scraping. Faixa de custo: aproximadamente US$ 30–US$ 500+/mês para uso pequeno a médio, podendo subir bastante em volumes enterprise.
A Thunderbit API merece destaque porque gera dados estruturados (não apenas HTML bruto). O endpoint pode processar até 50 URLs por requisição e retornar JSON/CSV com base em um esquema orientado por IA — útil se você precisa de dados limpos e prontos para análise, em vez de HTML para depois parsear manualmente.
Placar honesto de confiabilidade: o que realmente funciona e o que quebra
Tenho acompanhado relatos da comunidade, issues no GitHub e promessas de fornecedores ao longo de 2025–2026. O que segue é uma comparação franca. São estimativas orientativas, não benchmarks de laboratório:
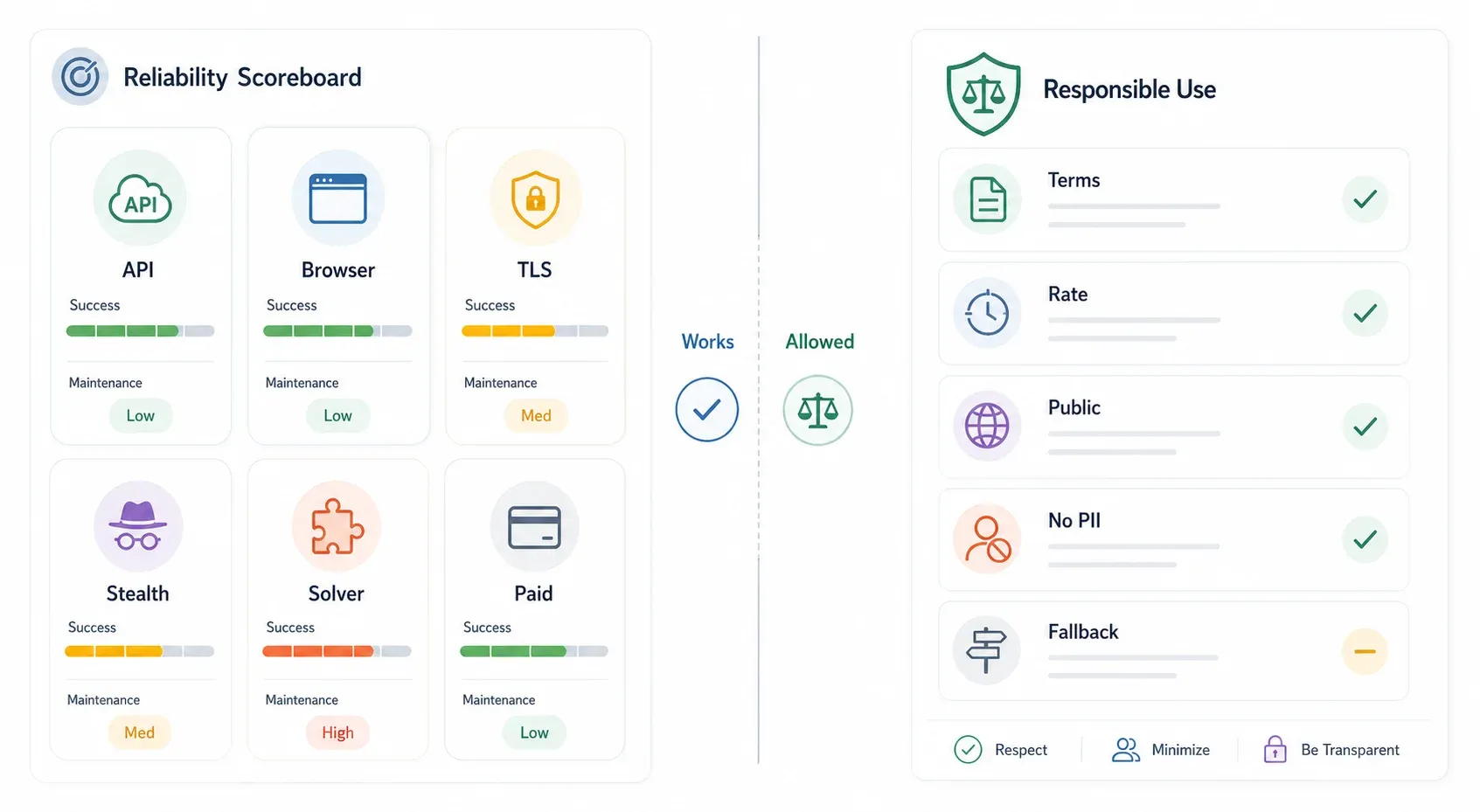
| Método | Taxa de sucesso estimada | Esforço de manutenção | Quebra quando… | Faixa de custo |
|---|---|---|---|---|
| API interna (se existir) | ~90–99% | Baixo | A API muda, adicionam autenticação, tokens passam a ser assinados | Gratuito |
| Extensão de navegador (Thunderbit) | ~85–95% (sessão real) | Baixo (IA se adapta a mudanças de layout) | O site exige fluxo de autenticação especial, Turnstile agressivo por ação | Plano gratuito disponível |
curl_cffi / spoofing TLS | ~70–85% | Médio (atualizações de fingerprint) | O Cloudflare muda as verificações JA3, exige desafio JS ativo | Gratuito |
| Puppeteer + plugin stealth | ~70–90% | Alto (atualizações do plugin atrasam) | Detecção de CDP, novos sinais de fingerprint, detecção de headless | Gratuito + custo de proxy |
| FlareSolverr | ~60–80% | Alto (Docker, dependências divergindo) | Proteção nível Enterprise, interação com Turnstile | Gratuito + custo de infraestrutura |
| API paga de scraping | ~85–95% | Baixo (o provedor mantém) | O provedor não atualizou; orçamento excedido | ~US$ 30–500+/mês |
A coluna mais importante não é a taxa de sucesso — é "Quebra quando…". Todo método tem um modo de falha. A melhor estratégia é escolher o método de menor esforço que funcione para o seu alvo e ter um plano B.
Não existe solução permanente. O Cloudflare é atualizado o tempo todo. A guerra de braços é real.
Dicas para ficar fora do radar do Cloudflare (não importa o método que você use)
Independentemente do método escolhido, alguns hábitos ajudam você a passar mais tempo fora do radar do Cloudflare:
- Respeite limites de taxa. Adicione atrasos realistas entre requisições — no mínimo 2–5 segundos para navegação com aparência humana. Bater no site em velocidade de máquina é a forma mais rápida de ser bloqueado.
- Mantenha o fingerprint consistente. User-Agent, fingerprint TLS, versão do navegador, timezone, localidade e geografia do IP devem contar a mesma história. Um User-Agent do Chrome 136 vindo de um IP alemão, com locale
en-USe handshake TLS de Python, é uma contradição. - Reutilize cookies e sessões depois de passar pelo desafio. Não resolva o desafio a cada requisição.
- Não troque de IP no meio da sessão. O Cloudflare acompanha a continuidade da sessão.
- Use IPs residenciais ou móveis quando o caso de uso e o orçamento justificarem.
- Monitore bloqueios suaves: HTML de desafio quando você esperava JSON, tabelas vazias, redirecionamentos para login ou páginas que parecem suspeitamente honeypots.
- Evite horários de pico quando os operadores do site podem apertar as regras do WAF.
- Crie caminhos de fallback: API primeiro → sessão no navegador em segundo → provedor pago em terceiro.
Para usuários do Thunderbit, especificamente, a IA se adapta automaticamente a mudanças no layout da página, então você gasta menos tempo mantendo seletores CSS e mais tempo usando os dados de verdade.
Um aviso rápido sobre questões legais e éticas
Não é o foco deste artigo, mas é importante demais para ser ignorado.
A coleta de dados publicamente disponíveis tem — o raciocínio do caso hiQ v. LinkedIn sob a CFAA sobreviveu ao retorno da Suprema Corte, embora as partes tenham feito acordo em 2022 e o quadro completo seja complexo. Mais recentemente, o em 2025 por suposta coleta de comentários de usuários, e o ainda naquele ano.
Na UE, o GDPR se aplica sempre que há dados pessoais envolvidos, e o acrescenta obrigações específicas sobre .
Regras práticas:
- Sempre verifique os Termos de Serviço do site.
- A proteção do Cloudflare é um sinal de que o dono do site quer controlar o acesso automatizado — respeite essa intenção.
- Evite coletar dados pessoais sem uma base legítima.
- Para fluxos comerciais ou de alto volume, prefira APIs oficiais, dados licenciados ou permissão por escrito quando disponíveis.
- Em caso de dúvida, consulte um advogado para o seu caso de uso e jurisdição.
O Thunderbit foi projetado para casos legítimos de uso empresarial — geração de leads, monitoramento de preços, pesquisa de mercado — usando dados publicamente acessíveis.
Conclusão: o que tentar primeiro e o que testar depois
A maior economia de tempo neste artigo não é uma ferramenta nem um trecho de código — é identificar o nível de proteção antes de começar. Só isso já evita horas depurando um método que nunca teria funcionado.
Comece por aqui:
- Verifique se existe uma API interna (é grátis, rápido e frequentemente ignorado).
- Se você é um usuário de negócios e não escreve código, teste a — sua sessão real no navegador é seu melhor trunfo contra o Cloudflare.
- Se você é desenvolvedor e o alvo usa apenas fingerprinting passivo, tente
curl_cffi. - Suba para navegadores stealth, FlareSolverr ou APIs pagas só quando os métodos mais simples falharem.
Nenhum método é permanente. Combine a ferramenta certa para a sua escala com um plano de contingência, e você vai passar muito menos tempo encarando páginas 403.
Se quiser se aprofundar, escrevemos sobre , e no blog da Thunderbit. E, se quiser ver a extensão em ação, confira o com vídeos passo a passo.
Perguntas frequentes
1. É possível contornar completamente a proteção do Cloudflare?
Nenhum método garante 100% de sucesso, especialmente contra Bot Management de nível Enterprise com Turnstile, fingerprinting JA4 e AI Labyrinth. As abordagens mais confiáveis combinam fingerprints reais de navegador com boa reputação de IP. Encontrar uma API interna é o mais próximo de um bypass "completo", já que evita o Cloudflare por inteiro — mas nem todo site tem uma.
2. É legal contornar o Cloudflare ao fazer scraping?
Depende da sua jurisdição, dos Termos de Serviço do site e dos dados que você está coletando. A coleta de dados publicamente disponíveis tem jurisprudência favorável em alguns contextos nos EUA (hiQ v. LinkedIn), mas burlar controles técnicos de acesso, violar os Termos de Serviço ou coletar dados pessoais sem base legítima pode gerar risco jurídico. Para fluxos comerciais, prefira APIs oficiais ou dados licenciados quando disponíveis e consulte um advogado se tiver dúvidas.
3. Qual é a forma mais fácil de contornar o Cloudflare sem programar?
Extensões de navegador como que funcionam dentro da sua sessão real do Chrome lidam automaticamente com os desafios do Cloudflare — você interage com o site como um usuário normal e depois deixa a extensão extrair e exportar os dados. Sem Python, sem Docker, sem configurar proxy.
4. Por que meu scraper funciona em alguns sites com Cloudflare, mas não em outros?
O nível de proteção do Cloudflare varia muito conforme o plano (Free, Pro, Business, Enterprise) e a configuração. Um método que funciona contra desafios JavaScript básicos em um site Free pode falhar contra Turnstile ou Bot Management completo em um site Enterprise. Sempre identifique primeiro o nível de proteção — veja se você está diante de uma simples checagem JS, de um Managed Challenge ou de um widget Turnstile — antes de escolher sua abordagem de bypass.
5. Com que frequência os métodos de bypass do Cloudflare quebram?
Métodos baseados em código, como plugins stealth e spoofing TLS, podem perder eficácia a cada poucas semanas ou meses em alvos difíceis, conforme o Cloudflare atualiza suas detecções. APIs pagas e ferramentas que usam sessão real de navegador tendem a ser mais resilientes porque se adaptam na camada de infraestrutura ou de sessão do usuário. APIs internas raramente quebram, a menos que o site redesenhe o backend ou mude o modelo de autenticação. A estratégia mais segura no longo prazo é ter vários métodos de fallback, em vez de depender de uma única abordagem.
Saiba mais