O Firecrawl tornou-se uma das APIs de web scraping mais comentadas no universo dos developers de IA — , apoio da Y Combinator e uma lista de clientes que inclui Shopify, Zapier e Apple. Mas, depois de vasculhar a documentação de preços, as queixas dos utilizadores, benchmarks independentes e modelos de custo do mundo real, a narrativa principal e a experiência real ficam bastante longe uma da outra.
Esta análise do Firecrawl já não é apenas mais uma lista de funcionalidades. Se se registou, fez alguns testes de scraping e agora se pergunta “quanto é que isto me vai custar em escala?” — ou se está a tentar perceber, antes de mais, se o Firecrawl é a ferramenta certa para a sua equipa — está no sítio certo. Vou passar pelos custos reais (incluindo a armadilha da dupla cobrança que a maioria das análises ignora), onde o Firecrawl realmente brilha, onde fica aquém do esperado (sobretudo em sites protegidos contra bots) e quando uma ferramenta completamente diferente — incluindo opções no-code como — é a escolha mais inteligente. O meu objetivo: poupá-lo à surpresa na fatura do cartão.
O que é o Firecrawl e para quem foi criado?
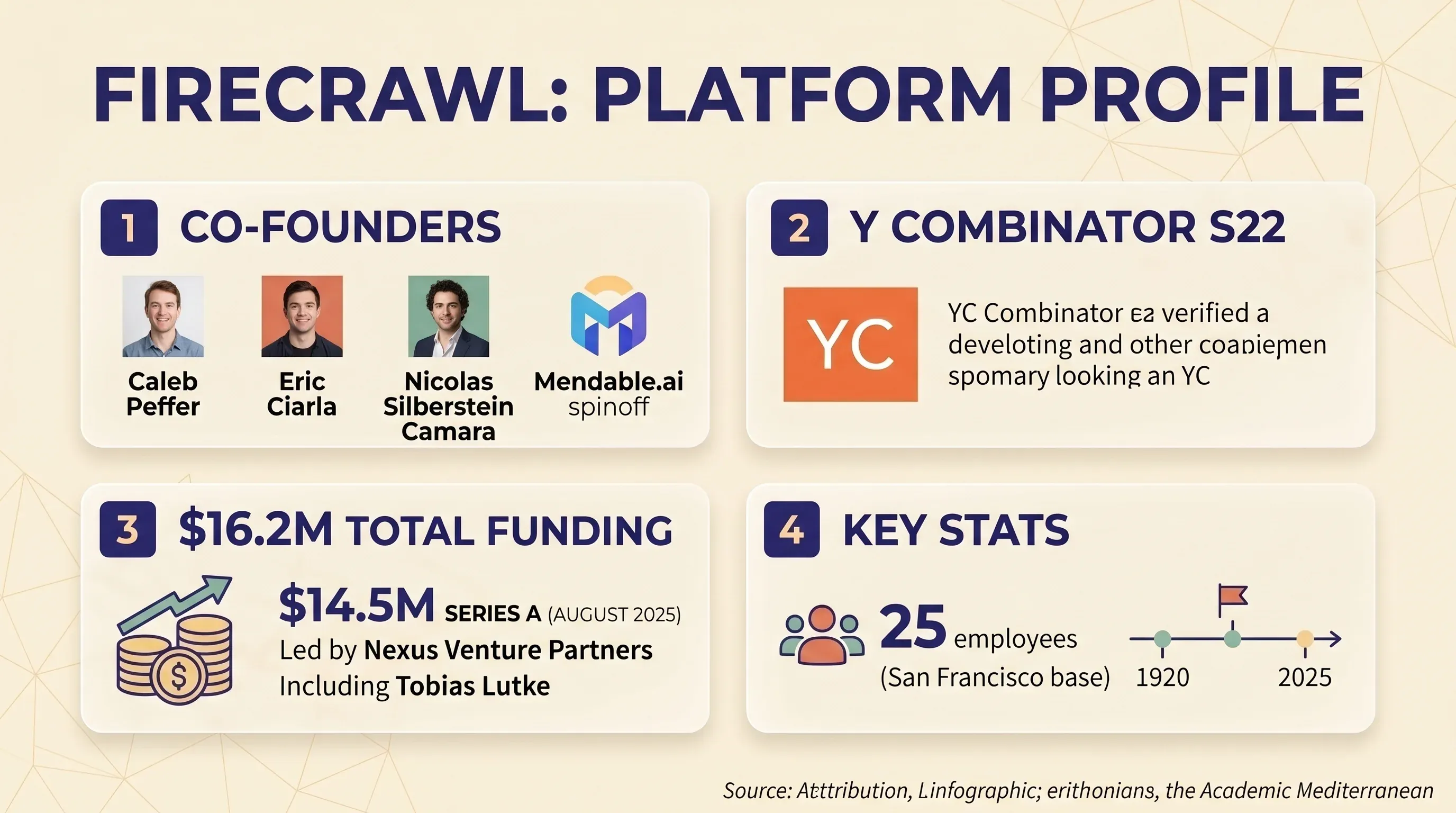
O Firecrawl é uma plataforma de web scraping e crawling centrada em API, que converte sites em markdown limpo ou JSON estruturado. Foi pensado sobretudo para developers que constroem aplicações de IA e LLM — pense em pipelines RAG, bases de conhecimento para chatbots e fluxos de trabalho com agentes de IA. A empresa foi fundada por Caleb Peffer, Eric Ciarla e Nicolas Silberstein Camara como uma spin-off da Mendable.ai. Passaram pela e levantaram uma em agosto de 2025, liderada pela Nexus Venture Partners, com participação do CEO da Shopify, Tobias Lütke. Captação total: US$ 16,2 milhões. A equipa tem 25 pessoas e está sediada em San Francisco.
O Firecrawl oferece quatro modos principais, além de duas adições mais recentes:
| Modo | O que faz |
|---|---|
| Scrape | Converte um único URL em markdown, JSON ou screenshot |
| Crawl | Faz crawl de um URL e de todas as respetivas subpáginas |
| Map | Descobre todos os URLs de um site em segundos (até 100 mil URLs) |
| Search | Pesquisa na web com recuperação do conteúdo completo das páginas |
| Extract | Extração estruturada com IA via prompts ou schemas |
| Agent (Research Preview) | Pesquisa autónoma na web sem precisar de especificar URLs |
Vou ser direto: o Firecrawl é uma ferramenta para developers. Exige chamadas de API, conhecimento de código e alguma configuração técnica. Se é um utilizador de negócio e quer recolher dados de um site sem escrever código, o Firecrawl não foi feito para si (já falarei de alternativas mais à frente). Mas, para equipas de desenvolvimento que constroem apps de IA, a proposta é muito apelativa — dados web limpos, prontos para LLM, com pouca dor de cabeça de infraestrutura.
Análise do Firecrawl: planos de preços em resumo
À primeira vista, os preços do Firecrawl parecem simples. Veja o que aparece na :
| Plano | Preço mensal | Créditos/mês | Concorrência | Preço anual |
|---|---|---|---|---|
| Free | US$ 0 | 500 (uma única vez, não mensalmente) | 2 | — |
| Hobby | US$ 19/mês | 3.000 | 10 | US$ 16/mês faturado anualmente |
| Standard | US$ 99/mês | 100.000 | 50 | US$ 83/mês faturado anualmente |
| Growth | US$ 399/mês | 500.000 | 100 | US$ 333/mês faturado anualmente |
| Scale | US$ 749/mês | 1.000.000 | 1.000 | US$ 599/mês faturado anualmente |
Duas coisas saltam logo à vista. Os 500 créditos do plano gratuito são de uma única vez, não mensais — um detalhe que muitos utilizadores só percebem depois de os gastarem numa única sessão de testes. E estes planos parecem simples, mas o custo real depende muito das funcionalidades que usar. O preço listado é apenas o ponto de partida. A conta a sério? É a próxima secção.
O custo real do Firecrawl: uma calculadora de créditos para o seu caso de uso
O preço é o maior ponto de dor entre utilizadores reais do Firecrawl — “é caríssimo”, “eu teria de estar no plano de US$ 99/mês para o meu nível de utilização” e “absurdamente caro” são citações reais de discussões no Hacker News e no Reddit. O motivo? Existe um sistema de cobrança dupla que a maioria das análises do Firecrawl ignora por completo.
Aqui está a armadilha: os planos de créditos do Firecrawl cobrem Scrape, Crawl, Map e Search. Mas o Extract — a extração estruturada com IA, um dos grandes diferenciais do Firecrawl — funciona com uma assinatura separada, baseada em tokens.
| Plano Extract | Preço mensal | Tokens/ano | Tokens/mês (aprox.) |
|---|---|---|---|
| Starter | US$ 89/mês | 18M | ~1,5M |
| Standard | US$ 189/mês | 48M | ~4M |
| Growth | US$ 389/mês | 108M | ~9M |
| Pro | US$ 719/mês | 192M | ~16M |
Assim, uma startup no plano Standard de créditos (US$ 99/mês) que também precise de extração paga US$ 99 + US$ 89 = pelo menos US$ 188/mês — antes de qualquer multiplicador de crédito. Essa é a armadilha da cobrança dupla que apanha muita gente desprevenida.
Multiplicadores de crédito ocultos que a maioria dos utilizadores não nota
A promessa “1 crédito por página” é enganadora. Veja o custo real das funcionalidades:
| Funcionalidade | Custo em créditos | Multiplicador efetivo |
|---|---|---|
| Scrape/Crawl básico | 1 crédito/página | 1x |
| Search | 2 créditos/10 resultados | 2x por conjunto de resultados |
| Extração JSON (via Scrape) | +4 créditos/página | 5x no total |
| Enhanced Mode | +4 créditos/página | 5x no total |
| JSON + Enhanced Mode | +8 créditos/página | 9x no total |
| Interações no navegador | 2 créditos/minuto | Variável |
| Modo Agent (spark-1-mini) | Dinâmico, ~100–500 por consulta | 100–500x |
| Modo Agent (spark-1-pro) | Dinâmico, ~200–1.500+ por consulta | 200–1.500x |
E mais alguns pontos importantes: os créditos não transitam de um mês para o outro. Pedidos falhados continuam a consumir créditos (os utilizadores relatam 20–30% de desperdício em sites instáveis). O modo Agent não tem estimador de custo antes da execução — define-se o parâmetro maxCredits, mas, no fundo, está-se praticamente a adivinhar. Os 500 créditos vitalícios do plano gratuito equivalem a cerca de 56 páginas se ativar extração. Isso não é um teste completo — é apenas uma amostra.
Tabela de custo mensal por perfil de utilizador
| Perfil de utilizador | Páginas/mês | Funcionalidades usadas | Consumo estimado de créditos | Custo mensal estimado |
|---|---|---|---|---|
| Hobbyista / projeto paralelo | 500 | Scrape + crawl básicos | ~500 créditos | US$ 19/mês (plano Hobby) |
| Hobbyista + extração JSON | 500 | Scrape + Extract | ~2.500 créditos + US$ 89 Extract | US$ 108/mês |
| Startup / app de IA | 5.000 | Scrape + Extract + Search | ~30.000 créditos + US$ 89 Extract | US$ 188/mês (Standard + Extract) |
| Empresa / pipeline de dados | 50.000 | Stack completa + Agent | ~250.000–450.000 créditos + US$ 389 Extract | US$ 788–US$ 1.138/mês |
Um developer no Hacker News que pagava US$ 190 por mês descreveu a experiência como “cara e meio inacabada” e substituiu o Firecrawl por 2.700 linhas de código Elixir personalizadas. É um sinal bastante claro.
Firecrawl auto-hospedado: o que realmente é grátis (e o que só existe na nuvem)
“Posso simplesmente auto-hospedar o Firecrawl de graça?” é uma das perguntas mais comuns que vejo. A resposta é: mais ou menos, mas provavelmente não da forma que imagina.
O Firecrawl tem um núcleo open source (licença AGPL-3.0), mas várias funcionalidades importantes só existem na nuvem. Aqui está a divisão definitiva:
| Capacidade | Auto-hospedado (grátis) | Nuvem (pago) |
|---|---|---|
| Scrape/Crawl básico para markdown | ✅ | ✅ |
| Map (descoberta de URLs) | ✅ | ✅ |
| Extract com LLM | ⚠️ (traga as suas próprias chaves de LLM) | ✅ (gerido) |
| Modo Agent | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-bot / rotação de proxy (Fire-engine) | ❌ (usa o seu IP estático) | ✅ |
| Processamento em lote | ❌ | ✅ |
| Dashboard / analytics | ❌ | ✅ |
| Infraestrutura gerida | ❌ (exige Docker + PostgreSQL + Redis) | ✅ |
Fire-engine, o sistema proprietário anti-bot do Firecrawl, é . Utilizadores auto-hospedados não têm qualquer capacidade anti-bot e precisam de fornecer os seus próprios proxies.
Quando a auto-hospedagem ainda faz sentido
A auto-hospedagem faz sentido se for um developer que quer um pipeline básico de crawl para markdown e está confortável a gerir um Docker Compose com mais de 5 serviços. Requisitos mínimos: 4 GB de RAM, 2 núcleos de CPU, além de chaves de API de LLM para extração (US$ 0,01–US$ 0,10 por página) e serviços de proxy, se forem საჭირო. No total, os custos da versão auto-hospedada ficam entre US$ 90 e US$ 340/mês — muitas vezes próximo dos planos na nuvem em volumes moderados.
Por que razão os utilizadores estão frustrados com a versão auto-hospedada
O feedback real dos utilizadores pinta um cenário complicado. Vários tópicos no Reddit e no GitHub descrevem a versão auto-hospedada a degradar-se com o tempo, à medida que funcionalidades migram para a nuvem. Um utilizador resumiu de forma direta: a empresa “tenta empurrar todos os utilizadores para pagar já e tornar a versão auto-hospedada inútil”. A comunidade até criou um fork firecrawl-simple para resolver estes problemas. Se está a contar com a auto-hospedagem como solução grátis de longo prazo, ajuste as expectativas — é um bom ponto de partida para experimentação, mas não substitui o produto pago na nuvem em escala.
Desempenho anti-bot do Firecrawl: onde funciona e onde falha
Esta é a secção mais importante se estiver a pensar: “o Firecrawl vai mesmo funcionar nos sites que preciso de raspar?”
A resposta curta: depende completamente de quão protegidos esses sites estão.
Os números do benchmark
A testou de forma independente 10 APIs de web scraping em 15 sites fortemente protegidos contra bots. Resultado do Firecrawl:
| Fornecedor | Taxa de sucesso (2 req/s) | Taxa de sucesso (10 req/s) |
|---|---|---|
| Zyte | 93,14% | 89,2% |
| ScrapFly | 91,8% | 88,5% |
| Bright Data | 88,7% | 84,9% |
| Firecrawl | 33,69% | 26,69% |
O Firecrawl ficou entre 10 fornecedores em sites protegidos. O seu tempo de resposta rápido (7,92 segundos em média) explica-se em parte por uma estratégia de “falhar depressa” — devolve erros rapidamente em vez de tentar novamente.
O benchmark contínuo mais amplo da atribui ao Firecrawl uma taxa geral de sucesso de 65,4% (acima da média do setor, de 59,5%), com bons resultados em alvos fáceis, mas desempenho fraco nos protegidos.
Divisão por dificuldade do site: alvos fáceis, médios e difíceis
| Dificuldade | Exemplos de sites | Taxa de sucesso do Firecrawl | Recomendação |
|---|---|---|---|
| Fácil | Blogs, documentação, páginas públicas de SaaS | 85–98% | Use o Firecrawl com confiança |
| Moderada | Catálogos de produtos, sites de notícias com proteção básica contra bots, Etsy, Realtor.com | 53–65% | Teste com cuidado, espere falhas |
| Difícil | Amazon, LinkedIn, Instagram, páginas com muita Cloudflare | 0–33% | Não dependa do Firecrawl — use fornecedores anti-bot dedicados |
Os sites protegidos pela Cloudflare são o ponto de falha mais reportado. Vários issues no GitHub documentam o problema: a deteção baseada em fingerprint da Cloudflare bloqueia o Firecrawl mesmo quando há rotação de IP. Utilizadores auto-hospedados são os mais prejudicados, já que não têm a infraestrutura de proxy do Fire-engine.
O que fazer quando o Firecrawl não chega
Para sites muito protegidos, os utilizadores recorrem normalmente a serviços de proxy dedicados como ScrapFly ou Bright Data, ou a ferramentas de navegador headless com configurações stealth personalizadas. Se é um utilizador de negócio e não quer lidar com rotação de proxy nem fazer contas à taxa de sucesso, ferramentas no-code como tratam das preocupações anti-bot nos bastidores — basta clicar e receber os dados.
Prós e contras do Firecrawl: um resumo honesto
O que o Firecrawl faz bem
- Saída markdown limpa e pronta para LLM — consistentemente bem formatada, com estrutura correta de títulos. Este é, de facto, o maior diferencial do Firecrawl.
- Zero sobrecarga de infraestrutura para utilizadores da nuvem — sem configuração de navegador, gestão de proxy ou afinação de browser headless.
- Integrações amplas com frameworks — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (mais de 7 integrações para pipelines de IA).
- Descoberta rápida de URLs através do endpoint Map — 2 a 3 segundos para um sitemap completo.
- Núcleo open source com — transparência e contribuição da comunidade.
- Suporte a servidor MCP com o modelo FIRE-1 para fluxos de agentes de IA.
- em páginas pesadas em JavaScript (SPAs em React, Vue, Angular).
Onde o Firecrawl fica aquém
- Preço duplo (créditos + plano separado de tokens do Extract) cria surpresas na faturação que ninguém espera.
- Multiplicadores de crédito aumentam o custo real em 5 a 9 vezes acima do preço anunciado.
- Desempenho anti-bot: último lugar no benchmark da Proxyway ( contra 93,14% do melhor classificado).
- Modo Agent consome créditos de forma imprevisível e sem estimador antes da execução.
- Pedidos falhados continuam a consumir créditos — 20–30% de desperdício em sites instáveis.
- A versão auto-hospedada não tem Agent, Browser Sandbox, anti-bot Fire-engine nem dashboard.
- Sem solução nativa para CAPTCHA — uma lacuna importante face à Bright Data e à Zyte.
- Não é acessível para utilizadores sem perfil técnico — exige conhecimento de código e de API.
- Os 500 créditos do plano gratuito são vitalícios, não mensais — insuficientes para testes relevantes.
Para lá das ferramentas para developers: alternativas no-code que as análises do Firecrawl nunca mencionam
Todas as análises do Firecrawl que li comparam a ferramenta apenas com outras voltadas para developers — Crawl4AI, Scrapy, Playwright, Apify. Faz sentido se for developer. Mas uma grande parte de quem procura soluções de web scraping não é técnica: equipas de vendas a montar listas de prospeção, operações de ecommerce a monitorizar preços da concorrência, profissionais de marketing a reunir dados de conteúdo, mediadores a acompanhar anúncios imobiliários.
É uma lacuna que vale a pena preencher.
Tabela comparativa de alternativas ao Firecrawl
| Ferramenta | Ideal para | Exige código? | Saída pronta para LLM | Preço inicial |
|---|---|---|---|---|
| Firecrawl | Developers a criar apps de IA | Sim (API) | ✅ Markdown/JSON | US$ 19/mês |
| Crawl4AI | Developers que querem grátis/OSS | Sim (Python) | ✅ Markdown | Grátis |
| Apify | Developers que precisam de escala + marketplace | Sim (SDK) | ⚠️ Com configuração | US$ 39/mês |
| Thunderbit | Utilizadores de negócio (no-code) | Não (extensão do Chrome) | ✅ Dados estruturados | Plano grátis disponível |
| ScrapingBee | Developers que precisam de proxy | Sim (API) | ❌ HTML bruto | US$ 49/mês |
| Bright Data | Equipas corporativas de dados | Sim (API/SDK) | ⚠️ Com configuração | US$ 500+/mês |
Por que razão o Thunderbit é a escolha natural para equipas não técnicas
Trabalho na equipa do Thunderbit, por isso vou ser transparente em relação a isso. O Thunderbit entra nesta comparação porque resolve um problema diferente do Firecrawl, para um público diferente, sem exigir código.
O fluxo do Thunderbit faz-se em dois cliques: abra a , clique em “AI Suggest Fields” e depois clique em “Scrape”. A IA lê a página, sugere as colunas certas e extrai os dados estruturados para uma tabela. Sem chaves de API, sem seletores, sem programação. Pode exportar gratuitamente para Excel, Google Sheets, Airtable ou Notion.
Diferenciais importantes para utilizadores de negócio:
- Enriquecimento de subpáginas — entra em páginas de detalhe e extrai campos adicionais automaticamente
- IA que se adapta a alterações no layout — sem manutenção quando um site é redesenhado
- Rotulagem e tradução de dados integradas — útil para conjuntos de dados multilingues
- Modelos instantâneos para sites populares (Amazon, Zillow, LinkedIn etc.)
Para developers que querem uma alternativa via API, o Thunderbit também oferece endpoints com preços mais simples do que o sistema duplo de créditos/tokens do Firecrawl. Não substitui o Firecrawl para developers de pipeline LLM. Mas, para equipas de vendas, ecommerce, marketing e operações que precisam de dados estruturados sem escrever código, é o caminho mais rápido e mais barato.
Fazer ou comprar: quando o Firecrawl compensa e quando não compensa
“Pensei em escrever o meu próprio web scraper… mais simples do que o Firecrawl, mas pelo menos mais barato.” Vários utilizadores levantam esta questão. Em vez de uma opinião subjetiva, aqui fica um framework de decisão estruturado.
Tabela de framework de decisão
| Fator | Construir à medida (Scrapy/Playwright) | Comprar Firecrawl Cloud | Usar Thunderbit (No-Code) |
|---|---|---|---|
| Tempo de configuração | 10–40+ horas | ~30 minutos | ~5 minutos |
| Manutenção contínua | Alta (seletores partem) | Quase zero (gerido) | Zero (IA adapta-se) |
| Tratamento anti-bot | Manual (proxy, headers, retries) | Integrado (parcial — fraco em sites protegidos) | Integrado (modos navegador + nuvem) |
| Custo em 1 mil páginas/mês | US$ 50–150 (servidor + proxy) | US$ 19–US$ 108 (depende das funcionalidades) | US$ 0–US$ 15 |
| Custo em 50 mil páginas/mês | US$ 500–US$ 1.500 (infra) | US$ 399–US$ 1.138 | US$ 39–US$ 249 |
| Saída pronta para LLM | Exige código personalizado | Integrada (markdown/JSON) | Tabelas estruturadas (exportáveis) |
| Melhor para | Controlo total, sites de nicho, equipas de DevOps | Developers de IA/LLM, pipelines RAG | Vendas, ecommerce, marketing, operações |
Construir algo à medida sai do que usar APIs ao longo de três anos para a maioria das organizações. O ponto de viragem em que o sistema próprio fica mais barato é aproximadamente em 10 milhões ou mais de páginas por mês — uma escala que muito poucas equipas realmente alcançam.
O veredito honesto: qual caminho faz sentido para si?
O Firecrawl compensa quando:
- A sua equipa já programa em Python/JS e precisa de markdown limpo para pipelines de LLM/RAG
- O foco está sobretudo em sites sem proteção ou com proteção leve
- Quer infraestrutura gerida sem sobrecarga de DevOps
- O volume fica abaixo de ~50 mil páginas/mês
O Firecrawl não compensa quando:
- É um utilizador de negócio a fazer extrações sem uma equipa de dev → Thunderbit é mais simples e rápido
- O alvo são sites muito protegidos (Amazon, LinkedIn, muita Cloudflare) → Bright Data ou Zyte
- Precisa de faturação previsível em escala → os multiplicadores de crédito tornam os custos imprevisíveis
- Quer auto-hospedar com todas as funcionalidades → Agent, Browser Sandbox e Fire-engine são exclusivos da nuvem
Construir à medida só faz sentido quando:
- A sua equipa tem capacidade dedicada de DevOps
- Está em escala massiva (10 milhões+ de páginas/mês)
- Precisa de controlo total sobre sites de nicho ou com comportamentos estranhos
- Está confortável com manutenção contínua de seletores
Análise do Firecrawl: tabela comparativa lado a lado
Aqui está tudo lado a lado:
| Ferramenta | Tipo | Ideal para | Exige código | Tratamento anti-bot | Saída pronta para LLM | Opção de auto-hospedagem | Preço inicial |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | Developers de IA/LLM | Sim | Fraco em sites protegidos | ✅ Markdown/JSON | ✅ (limitada) | US$ 19/mês |
| Crawl4AI | Biblioteca Python | Developers que priorizam OSS | Sim | Nenhum (faça você mesmo) | ✅ Markdown | ✅ | Grátis |
| Apify | Plataforma em nuvem | Escala + marketplace | Sim | Moderado | ⚠️ Com configuração | ✅ | US$ 39/mês |
| Thunderbit | Extensão Chrome + API | Utilizadores de negócio, no-code | Não | Integrado | ✅ Dados estruturados | ❌ | Plano grátis |
| ScrapingBee | API | Developers focados em proxy | Sim | Forte | ❌ HTML bruto | ❌ | US$ 49/mês |
| Bright Data | API + rede de proxies | Equipas corporativas de dados | Sim | Melhor (~99,9%) | ⚠️ Com configuração | ❌ | US$ 500+/mês |
Veredito final: vale a pena usar o Firecrawl?
O Firecrawl é uma ferramenta sólida para um caso de uso específico: equipas de desenvolvimento que constroem apps de LLM, pipelines RAG ou agentes de IA e que precisam de dados web limpos em escala moderada, com conforto em fluxos baseados em API. A qualidade da saída em markdown é realmente de topo, e as integrações com frameworks (LangChain, LlamaIndex, CrewAI) são maduras. Se a sua equipa já trabalha em Python ou JavaScript e os sites-alvo não são muito protegidos contra bots, o Firecrawl pode poupar tempo real de engenharia.
Mas os pontos fracos são reais. O sistema de preço duplo (créditos + assinatura separada do Extract) cria surpresas de faturação muito concretas. A taxa de sucesso de em sites protegidos significa que não pode depender dele para alvos como Amazon, LinkedIn ou páginas com muita Cloudflare. A versão auto-hospedada deixa de fora demasiadas funcionalidades para servir como uma alternativa gratuita de verdade. E, se é um utilizador sem perfil técnico — alguém de vendas, ecommerce ou marketing — o Firecrawl simplesmente não foi feito para si.
Teste os 500 créditos grátis do Firecrawl para perceber se a qualidade da saída combina com o seu pipeline. Mas estime os seus custos mensais reais usando a calculadora acima antes de subscrever um plano pago. Se é um utilizador de negócio que só precisa de dados estruturados de sites sem escrever código, comece pelo — vai extrair dados em minutos, não em horas. Pode experimentar agora mesmo a ou ver para perceber o que escala para a sua equipa. Para tutoriais em vídeo, o tem demonstrações passo a passo.
Perguntas frequentes
Quanto custa o Firecrawl por página raspada?
Um scrape ou crawl básico custa 1 crédito por página. A extração JSON acrescenta 4 créditos por página (5 no total). O Enhanced Mode acrescenta mais 4 (até 9 no total). O Search custa 2 créditos a cada 10 resultados, e o modo Agent pode consumir de 100 a mais de 1.500 créditos por consulta. Além disso, a funcionalidade Extract exige uma assinatura separada de tokens, a partir de US$ 89/mês. Veja a secção da calculadora de custo acima para estimativas realistas por perfil de utilizador.
É possível auto-hospedar o Firecrawl de graça?
Sim, o núcleo open source (AGPL-3.0) pode ser auto-hospedado gratuitamente. Mas perde o modo Agent, o Browser Sandbox, o anti-bot/rotação de proxy (o Fire-engine é de código fechado), o processamento em lote e o painel de gestão. Terá de trazer as suas próprias chaves de LLM para extração e gerir Docker, PostgreSQL e Redis por conta própria. A auto-hospedagem funciona para pipelines básicos de crawl para markdown, mas não substitui o produto em nuvem em escala de produção.
O Firecrawl é bom para raspar Amazon, LinkedIn ou outros sites protegidos?
O mostra o Firecrawl com uma taxa de sucesso de 33,69% em sites fortemente protegidos contra bots — último lugar entre 10 fornecedores testados. Funciona bem em páginas sem proteção (blogs, docs, sites de SaaS — 85–98% de sucesso), mas não é fiável para grandes plataformas de ecommerce ou sociais. Para esses alvos, considere fornecedores anti-bot dedicados como Bright Data ou Zyte, ou ferramentas no-code como o Thunderbit, que tratam do anti-bot nos bastidores.
Qual é a melhor alternativa ao Firecrawl para utilizadores sem perfil técnico?
é a melhor alternativa no-code. É uma extensão do Chrome em que clica em “AI Suggest Fields” e depois em “Scrape” — sem chamadas de API, sem programação, sem seletores. Os dados exportam gratuitamente para Excel, Google Sheets, Airtable ou Notion. Foi feito para equipas de vendas, ecommerce, marketing e operações que precisam de dados web estruturados sem depender de um developer.
O Firecrawl oferece teste grátis?
O Firecrawl oferece sem exigir cartão de crédito. Isso chega para testar a funcionalidade básica de scrape/crawl em algumas páginas, mas não é suficiente para uso em produção — especialmente se ativar a extração (que consome 5 créditos por página). Os créditos não se renovam mensalmente no plano gratuito.
Saiba mais