

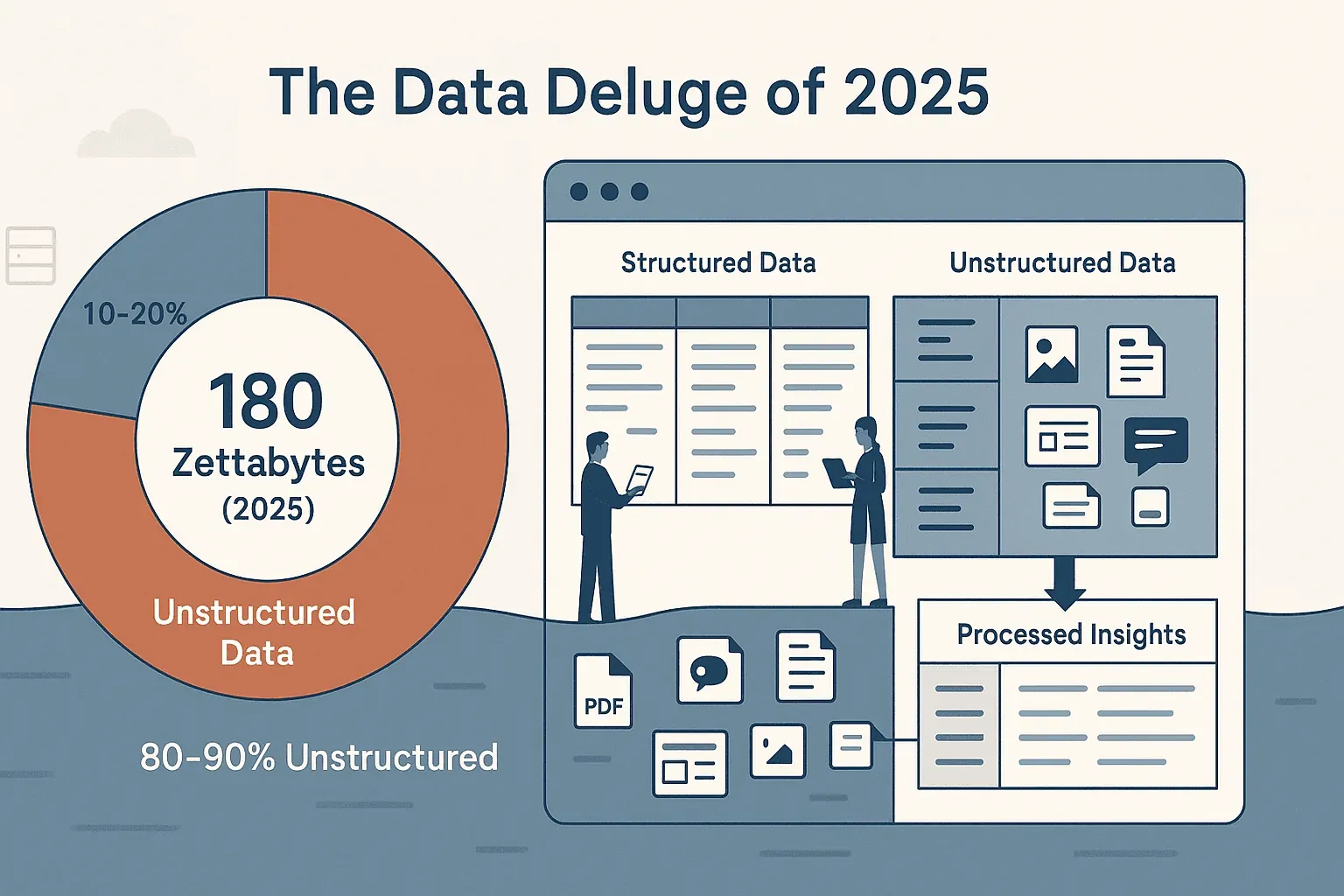
Se você já tentou recolher dados de um site — seja para leads de vendas, preços da concorrência ou simplesmente para organizar um catálogo de produtos desorganizado — sabe que a web não foi feita exatamente para copiar e colar sem esforço. O volume de dados online é absurdo: a IDC e a Statista estimaram a esfera global de dados em cerca de 180 zettabytes em 2025, e já estamos no caminho para algo em torno de 221 zettabytes em 2026. O problema maior não é o volume, e sim o formato: cerca de 80% desses dados são não estruturados, espalhados por páginas da web, PDFs, imagens e feeds dinâmicos. A maioria das equipas de negócios — eu incluído — já perdeu tempo demais a tentar lidar com este caos, só para acabar com folhas de cálculo a meio e uma sensação de déjà vu.
Extrair dados de qualquer site com IA Get Started Free
É por isso que sou obcecado por crawling eficiente de sites. Neste guia, vou mostrar um passo a passo prático para rastrear qualquer site — sem código, sem dores de cabeça — usando o Thunderbit, o nosso Raspador Web IA. Não importa se trabalha com vendas, operações ou só está cansado de introduzir dados manualmente: vou mostrar como lidar com layouts complexos, paginação, subpáginas e até extrair dados de PDFs e imagens. Vamos transformar o caos da web na sua próxima vantagem competitiva.
O que significa rastrear um site com eficiência?
Vamos simplificar: rastrear um site significa usar uma ferramenta automatizada — pense num assistente robótico — para visitar páginas da web de forma sistemática e extrair as informações de interesse: nomes, preços, e-mails, especificações de produtos, e por aí fora. O crawling eficiente não tem que ver só com velocidade; tem que ver com precisão, mínimo esforço manual e capacidade de lidar com obstáculos reais da web, como paginação, subpáginas e dados não estruturados (Wikipedia).
O que separa um crawling eficiente de uma maratona de copiar e colar? O que importa é:
- Velocidade: capturar centenas de páginas ou registos em minutos, não em horas.
- Precisão: apanhar exatamente os dados de que precisa, sem perder entradas nem introduzir erros de digitação.
- Automação: deixar a ferramenta tratar das tarefas repetitivas, como clicar em “Próxima” ou seguir links para páginas de detalhe.
- Resiliência: adaptar-se a layouts complexos, conteúdo dinâmico e até mudanças na estrutura do site.
- Configuração mínima: sem programação, sem mexer em seletores, sem manutenção constante.
O mundo real não é feito de tabelas perfeitas. Os sites modernos têm rolagem infinita, navegação em várias etapas, exigência de login e dados escondidos em PDFs ou imagens. Rastrear com eficiência significa ultrapassar tudo isso — para que gaste menos tempo com trabalho braçal e mais com análise e ação (AIMultiple).
Por que o crawling eficiente de sites importa para vendas e operações
Porque é que as equipas de negócio dão tanta importância ao crawling web? Porque os dados certos — entregues rapidamente — podem fazer ou desfazer a sua próxima campanha, lançamento de produto ou trimestre de vendas. Estes são alguns dos casos de uso mais comuns (e com melhor ROI) que vejo todas as semanas:
| Caso de uso | Benefício e ROI | Resultado exemplo |
|---|---|---|
| Geração de leads | Encha o funil de vendas mais depressa, poupe horas na pesquisa de prospects, reduza erros manuais | Extrair 5.000 leads segmentados de um dia para o outro, lançar campanhas 2 semanas antes, aumentar os agendamentos em 30% |
| Monitorização de preços da concorrência | Permita preços dinâmicos, reaja às mudanças do mercado em tempo real, proteja margens | Um retalhista ajusta preços diariamente e vê um aumento de 4% nas vendas |
| Extração de catálogo de produtos/stock | Mantenha os anúncios atualizados, reduza a introdução manual de dados, evite vender em excesso ou definir preços errados | Equipa de e-commerce atualiza 10.000 SKUs por dia, reduz o tempo de atualização em 90% |
| Pesquisa de mercado e análise de avaliações | Obtenha insights em grande escala sobre sentimento do cliente e tendências, identifique oportunidades antes da concorrência | Analisa mais de 10.000 avaliações, identifica novas oportunidades de produto, melhora a comunicação de marketing |
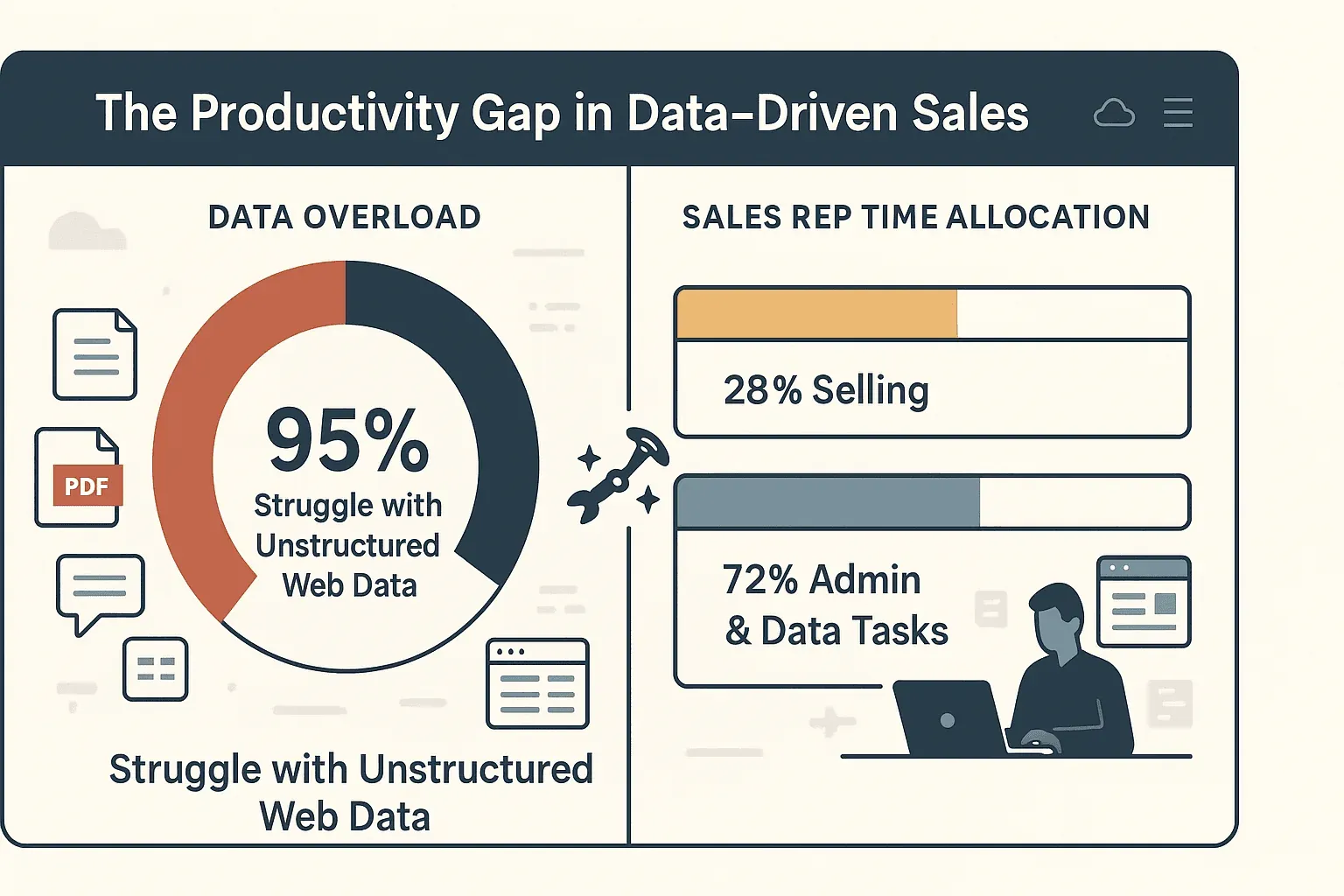
No fim de contas? Crawling eficiente significa decisões mais rápidas e mais inteligentes — e muito menos tempo gasto a copiar e colar. Na verdade, 95% das empresas admitem que têm dificuldade em usar dados web não estruturados, e os representantes de vendas passam apenas 28% do tempo realmente a vender. O resto perde-se na introdução manual de dados e em tarefas administrativas.
Thunderbit: a forma mais fácil de rastrear um site
Vamos ser honestos: a maioria das ferramentas de web scraping foi criada para programadores, não para utilizadores de negócio. Foi por isso que criámos o Thunderbit, um Raspador Web IA tão fácil de usar como pedir comida por delivery. Veja o que distingue o Thunderbit:
- Prompts em linguagem natural: basta descrever os dados que quer (“Pegue em todos os nomes e preços de produtos desta página”), e a IA do Thunderbit trata do resto.
- Sugestão de campos por IA: clique em “AI Suggest Fields” e o Thunderbit analisa a página, recomenda as melhores colunas para extrair e configura o rastreador por si.
- Fluxo de trabalho em 2 cliques: quando estiver satisfeito com os campos, clique em “Scrape”. Pronto — sem código, sem modelos, sem andar às voltas com seletores.
- Lida com paginação e subpáginas: o Thunderbit detecta e navega automaticamente listas com várias páginas e pode seguir links para páginas de detalhe (subpáginas) para enriquecer os seus dados.
- Exportação instantânea: envie os seus dados diretamente para Excel, Google Sheets, Airtable ou Notion — ou descarregue em CSV/JSON, tudo de graça.
- OCR para PDFs e imagens: precisa de extrair dados de um PDF, imagem ou documento digitalizado? O OCR integrado do Thunderbit também estrutura esse conteúdo.
O Thunderbit foi pensado para utilizadores não técnicos — se consegue navegar na web e escrever uma frase, consegue rastrear um site como um profissional. E sim, há um plano gratuito para experimentar sem risco.
Teste o Thunderbit gratuitamente – comece a rastrear já
Comparando soluções de crawling de sites: Thunderbit vs. métodos tradicionais
Vamos colocar o Thunderbit lado a lado com os suspeitos do costume:
| Abordagem | Tempo e complexidade de configuração | Habilidades necessárias | Manutenção e fiabilidade |
|---|---|---|---|
| Copiar e colar manualmente | Extremamente alto, não escalável | Nenhuma, mas sujeito a erros | 100% manual, refazer a cada atualização |
| Código personalizado (Python etc.) | Configuração inicial alta, horas/dias por site | Programação necessária | Quebra com mudanças no site, exige correções constantes |
| Ferramenta tradicional sem código | Médio, configuração por clique | Baixa/média | Precisa de atualizações para mudanças de layout, nem sempre lida com sites dinâmicos |
| Thunderbit (com IA) | Muito baixo, configuração em 2 cliques | Nenhuma | A IA adapta-se às mudanças, manutenção mínima |
As ferramentas tradicionais podem levar o utilizador até meio caminho, mas muitas vezes bloqueiam com conteúdo dinâmico, paginação ou obrigam-no a acompanhar cada mudança. A IA do Thunderbit lê o site como uma pessoa, adapta-se a novos layouts e resolve os casos mais complicados — para que não tenha de o fazer (Thunderbit Blog).
Passo 1: configurar o crawl do seu site com Thunderbit
Começar é muito simples:
- Instale a extensão do Thunderbit para Chrome. Crie uma conta gratuita.
- Aceda ao site de destino. Abra a página que quer rastrear — pode ser uma listagem de produtos, um diretório ou até um PDF.
- Abra o Thunderbit. Clique no ícone do Thunderbit na barra de ferramentas do Chrome.
- Descreva o que precisa de extrair. Pode clicar em “AI Suggest Fields” para deixar o Thunderbit recomendar as colunas, ou escrever um prompt em linguagem natural (por exemplo: “Extraia o nome do produto, o preço e o URL da imagem de cada item”).
- Pré-visualize e ajuste. O Thunderbit mostra uma tabela de pré-visualização — edite os nomes dos campos, remova o que for desnecessário ou adicione instruções personalizadas, se precisar.
Dica profissional: seja específico, mas direto nos prompts. Mencione os pontos de dados exatamente como aparecem no site (“preço”, “endereço” etc.) e deixe a IA do Thunderbit fazer o trabalho pesado.
Passo 2: lidar com paginação e subpáginas durante o crawling de sites
Aqui é onde o Thunderbit realmente brilha. A maioria dos dados do mundo real não está numa única página — está espalhada em listas paginadas ou escondida em subpáginas.
- Paginação: o Thunderbit detecta automaticamente botões de “Próxima”, números de página ou rolagem infinita. Quando clica em “Scrape”, ele continua a carregar páginas até apanhar tudo — sem precisar de introduzir URLs manualmente ou clicar em cada página.
- Crawling de subpáginas: precisa de mais detalhes? Depois de extrair a lista principal, clique em “Scrape Subpages”. O Thunderbit segue os links (como páginas de detalhe de produtos ou perfis de empresas), extrai informações extra e junta-as na sua tabela.
Exemplo: vai extrair dados de um site de e-commerce? O Thunderbit captura a lista de produtos e depois visita a página de detalhe de cada produto para puxar especificações, avaliações ou imagens — tudo numa única execução.
Boa prática: deixe o Thunderbit terminar o crawl principal e, depois, use a extração de subpáginas para dados mais profundos. Vai ver atualizações de progresso e poderá monitorizar eventuais entradas em falta.
Passo 3: extração inteligente de dados não estruturados com Thunderbit
Nem todos os dados vêm em tabelas organizadas. Descrições de produtos, avaliações ou campos em formato misto podem ser um pesadelo para scrapers tradicionais. A IA do Thunderbit enfrenta isso de frente:
- Limpa e formata os dados: remove símbolos de moeda, interpreta números e separa campos complexos (por exemplo, “USD 299 (50% off!)” passa a “299” e “50% off”).
- Interpreta textos complexos: extrai informações estruturadas de parágrafos (por exemplo, encontra “Localização: Nova Iorque” numa descrição de vaga).
- Classifica e etiqueta: adiciona categorias ou tags com base no conteúdo (por exemplo, “Eletrónica” vs. “Roupas”).
- Lida com inconsistências: adapta-se a campos em falta ou mudanças de layout, mantendo os dados alinhados e precisos.
- Resume ou traduz: precisa de um resumo numa frase ou de uma tradução? Adicione uma instrução personalizada — a IA do Thunderbit também faz isso.
O resultado? Dados limpos e prontos a usar — sem mais horas gastas a limpar tudo no Excel.
Passo 4: escolher entre crawling na nuvem e no navegador
O Thunderbit oferece duas formas de rastrear, dependendo da sua necessidade:
- Crawling no navegador: corre no seu navegador Chrome, usando a sua sessão com login. É perfeito para sites que exigem autenticação ou têm fortes medidas anti-bot. Você vê o crawl a acontecer em tempo real, e ele imita a navegação humana.
- Crawling na nuvem: transfere o trabalho para os servidores cloud do Thunderbit. Lida com até 50 páginas em paralelo — ótimo para tarefas grandes ou agendadas. Pode fechar o portátil e deixar o Thunderbit fazer o trabalho pesado.
Quando usar cada um:
- Use o modo navegador para sites com login ou quando precisar de interagir com a página.
- Use o modo nuvem para sites públicos, tarefas em massa ou quando quiser velocidade e automação.
Alternar entre os modos é fácil — basta escolher a sua preferência antes de começar o crawl.
Passo 5: extrair dados de documentos e imagens usando OCR
Às vezes, os dados de que precisa estão presos em PDFs, imagens ou documentos digitalizados. O OCR integrado do Thunderbit (Reconhecimento Ótico de Caracteres) muda o jogo:
- PDFs: extraia tabelas, e-mails ou texto de relatórios, faturas ou catálogos.
- Imagens: capture texto de capturas de ecrã, rótulos de produtos ou até infográficos.
- Formulários digitalizados: automatize a introdução de dados de recibos, contratos ou cartões de visita.
Basta apontar o Thunderbit para o URL do PDF ou da imagem, e ele extrai e estrutura o conteúdo — sem precisar de software separado. Ainda pode combinar OCR com prompts de IA para extrações avançadas (“Encontre todos os endereços de e-mail neste PDF”).
Passo 6: exportar e usar os dados que rastreou
Quando o crawl termina, é hora de pôr esses dados a trabalhar:
- Opções de exportação: descarregue em CSV ou JSON, ou exporte diretamente para Google Sheets, Excel, Airtable ou Notion. Todos os formatos são gratuitos — até no plano básico.
- Vendas e CRM: importe listas de leads para o seu CRM, lance campanhas de prospeção ou enriqueça contactos existentes.
- Marketing e análise: analise preços da concorrência, acompanhe tendências de mercado ou visualize dados em dashboards.
- Operações e stock: monitorize inventário, atualize catálogos ou dispare alertas para mudanças importantes.
- Automação: use integrações (como Zapier ou Google Apps Script) para automatizar follow-ups, relatórios ou enriquecimento de dados.
A saída estruturada do Thunderbit faz com que passe do crawl à ação em minutos — não em dias.
Comece a rastrear com a IA do Thunderbit
Conclusão e principais conclusões
Rastrear um site de forma eficiente não é só o sonho de um aficionado por tecnologia — é um superpoder para negócios. Com o Thunderbit, qualquer pessoa pode:
- Configurar um crawl em segundos usando linguagem natural ou campos sugeridos por IA.
- Lidar com sites complexos com paginação, subpáginas e conteúdo dinâmico — sem precisar programar.
- Extrair dados limpos e estruturados de páginas web desorganizadas, PDFs e imagens.
- Escolher o melhor modo (navegador ou nuvem) para velocidade, escala e segurança.
- Exportar dados instantaneamente para as suas ferramentas e fluxos de trabalho favoritos.
Acabaram-se os dias de copiar e colar sem fim e de scrapers avariados. Descarregue o Thunderbit, teste um crawl gratuito e veja quanto tempo — e sanidade — pode poupar. A sua próxima grande descoberta — ou vitória em vendas — pode estar a um clique de distância.
Quer mais dicas e análises aprofundadas? Consulte o Thunderbit Blog para tutoriais, casos de uso e as novidades mais recentes em crawling web com IA.
Perguntas frequentes
1. Qual é a diferença entre web crawling e web scraping?
Web crawling refere-se a navegar sistematicamente por sites para descobrir páginas e links, enquanto web scraping consiste em extrair dados específicos dessas páginas. O Thunderbit combina os dois — encontra, navega e extrai as informações de que precisa.
2. O Thunderbit consegue lidar com sites que exigem login?
Sim! Use o modo navegador do Thunderbit para rastrear sites que exigem autenticação. Ele usa a sua sessão do Chrome já com login, para que possa aceder a dados atrás de logins ou paywalls (desde que isso esteja dentro dos termos de serviço do site).
3. Como o Thunderbit lida com paginação e rolagem infinita?
O Thunderbit deteta e navega automaticamente listas paginadas e páginas com rolagem infinita. Clica em “Próxima”, rola a página ou carrega mais conteúdo até capturar todos os dados — sem configuração manual.
4. Que tipos de dados o Thunderbit consegue extrair?
O Thunderbit pode extrair textos, números, datas, URLs, e-mails, telefones, imagens e até dados de PDFs e imagens usando OCR. Pode personalizar os campos e usar prompts de IA para estruturação e limpeza avançadas.
5. O Thunderbit é gratuito?
O Thunderbit oferece um plano gratuito que permite rastrear um número limitado de páginas. Todos os formatos de exportação (CSV, Excel, Google Sheets, Airtable, Notion) estão incluídos gratuitamente. Os planos pagos começam em US$ 15 por mês para maior volume e funcionalidades avançadas.
Pronto para rastrear de forma mais inteligente, não mais difícil? Experimente o Thunderbit hoje e deixe a IA fazer o trabalho pesado no seu próximo projeto de dados da web. Saiba mais
- Como rastrear um site? Um guia para iniciantes
- Como rastrear sites: um guia passo a passo para iniciantes
- Como rastrear todos os links de um site: um guia completo
Experimente o Raspador Web IA gratuitamente Get Started Free




