
Em 2015, fazer scraping significava implorar por um script em Python a um desenvolvedor ou passar o fim de semana aprendendo XPath. Em 2026, você digita “pegue todos os nomes e preços dos produtos” e a IA faz o resto.
Essa mudança aconteceu rápido. Hoje, mais de 2 milhões de empresas dependem de web scraping. O mercado ultrapassou US$ 1 bilhão em 2024 e deve dobrar até 2030.
O grande motor por trás disso? Os rastreadores web com IA. Eles se adaptam a mudanças no layout, entendem o conteúdo da página — não apenas as tags HTML — e funcionam para pessoas que nunca escreveram uma linha de código.
Passei meses testando 15 deles. Eis o que descobri — inclusive por que a Thunderbit (sim, a empresa que cofundei) ficou em primeiro lugar.
Por que a IA está transformando o scraping de páginas web: a nova era das ferramentas de raspador web
Extraia dados de qualquer site usando IA Get Started Free
Vamos ser sinceros: o web scraping tradicional nunca foi feito para o usuário médio de negócios. Tudo girava em torno de código, seletores e da esperança de que o seu script não quebrasse na próxima vez que um site mudasse o layout. Mas a IA e os LLMs mudaram completamente o jogo.
Veja como:
- Instruções em linguagem natural: Em vez de lidar com código, você só diz à IA o que quer. Ferramentas como a Thunderbit interpretam instruções em inglês simples e fazem a extração por você (fonte).
- Aprendizagem adaptativa: Raspadores com IA conseguem adaptar-se a mudanças no layout dos sites, reduzindo dores de cabeça com manutenção.
- Tratamento de conteúdo dinâmico: Sites modernos adoram JavaScript e rolagem infinita. Ferramentas com IA interagem com esses elementos e capturam dados que os raspadores antigos deixariam passar.
- Saída estruturada com parsing por IA: Raspadores baseados em LLMs realmente entendem o conteúdo da página e entregam dados limpos e estruturados.
- Evasão automática de anti-bot: Raspadores com IA podem contornar medidas anti-scraping e usar proxies/navegadores sem interface para evitar bloqueios de IP.
- Fluxos de trabalho de dados integrados: As melhores ferramentas não apenas recolhem dados — elas os entregam onde você precisa, com exportação em um clique para Google Sheets, Airtable, Notion e muito mais (fonte).
O resultado? O web scraping virou uma experiência de apontar e clicar — ou até de conversar — permitindo que equipes de vendas, marketing e operações, e não só desenvolvedores, aproveitem dados da web diretamente.
15 rastreadores web com IA que valem sua atenção em 2026
Vamos analisar os 15 principais rastreadores web com IA, começando pela Thunderbit. Vou explicar os recursos centrais de cada ferramenta, o público-alvo, o preço e o que a faz se destacar. E, sim, vou ser honesto sobre onde cada uma brilha — e onde pode não brilhar.
1. Thunderbit: o raspador web com IA para todos
Obviamente tenho um certo viés aqui, mas a Thunderbit é o raspador web com IA que eu gostaria de ter tido há anos. Eis por que ela está em #1 nesta lista:
- Extração em linguagem natural: Você “conversa” com a Thunderbit. Basta descrever os dados que quer — “raspe todos os nomes e preços dos produtos desta página” — e a IA faz o resto (fonte). Sem código, sem seletores, sem dor de cabeça.
- Rastreamento de subpáginas e em vários níveis: A Thunderbit pode seguir links e raspar subpáginas. Por exemplo, raspe uma lista de produtos e depois clique em cada produto para ver os detalhes, tudo numa única execução.
- Saída estruturada instantânea: A IA formata e limpa os dados em tempo real, sugerindo campos relevantes, padronizando formatos e até resumindo ou categorizando texto.
- Amplo suporte a fontes: A Thunderbit não serve apenas para HTML — ela pode extrair dados de PDFs e imagens usando OCR e IA de visão integrados (fonte).
- Integrações para negócios: Exportação em um clique para Google Sheets, Airtable, Notion ou Excel (fonte). Agende raspagens e envie os dados diretamente para o fluxo de trabalho da sua equipe.
- Modelos prontos: Para sites como Amazon, LinkedIn, Zillow etc., a Thunderbit oferece “receitas” de scraping prontas para extração de dados com um clique.
- Fácil de usar e acessível: A interface é de apontar e clicar, com um assistente intuitivo. Os utilizadores relatam que conseguem pôr a ferramenta a funcionar em minutos.

A Thunderbit é confiada por mais de 30.000 utilizadores no mundo todo, incluindo equipas da Accenture, Grammarly e Puma. Equipas de vendas usam-na para montar listas de leads, corretores agregam anúncios de imóveis e profissionais de marketing monitorizam concorrentes — tudo sem escrever uma única linha de código.
Preço: Há uma camada gratuita (raspe até 100 etapas/mês), com planos pagos a partir de US$ 14,99/mês. Até os planos profissionais são acessíveis para indivíduos e pequenas equipas.
A Thunderbit é a coisa mais próxima que já vi de “transformar a web num banco de dados” — e foi feita para toda a gente, não só para engenheiros.
Experimente a Extensão Chrome da Thunderbit
2. Crawl4AI
Para quem é: desenvolvedores e equipas técnicas que constroem pipelines personalizados.
Crawl4AI é uma estrutura open-source baseada em Python, otimizada para velocidade e rastreamento em grande escala, com integração pensada para LLMs. É extremamente rápida, oferece suporte a navegadores sem interface para conteúdo dinâmico e pode estruturar dados raspados para facilitar o uso em fluxos de IA.
- Ideal para: desenvolvedores que precisam de um motor de rastreamento poderoso e personalizável.
- Preço: gratuito (licença MIT). Você precisa de alojar e executar por conta própria.
3. ScrapeGraphAI
Para quem é: desenvolvedores e analistas que constroem agentes de IA ou pipelines complexos de dados.
ScrapeGraphAI é uma biblioteca Python open-source, orientada por prompts, que transforma sites em “grafos” de dados estruturados usando LLMs. Você pode escrever prompts como “extraia todos os nomes, preços e avaliações dos produtos das 5 primeiras páginas” e ela monta o fluxo de scraping para você (fonte).
- Ideal para: utilizadores técnicos que querem scraping flexível baseado em prompts.
- Preço: gratuito para a biblioteca open-source; a API na nuvem começa em US$ 20/mês.
4. Firecrawl
Para quem é: desenvolvedores que constroem agentes de IA ou pipelines de dados em grande escala.
Firecrawl é uma plataforma e API de rastreamento centrada em IA que transforma sites inteiros em dados “prontos para LLM” (fonte). Ela entrega Markdown ou JSON, lida com conteúdo dinâmico e integra com frameworks como LangChain e LlamaIndex.
- Ideal para: desenvolvedores que precisam alimentar modelos de IA com dados web ao vivo.
- Preço: o núcleo open-source é gratuito; os planos na nuvem começam em US$ 19/mês.
5. Browse AI
Para quem é: utilizadores de negócios, growth hackers e analistas.
Browse AI é uma plataforma sem código com uma interface de apontar e clicar. Você “treina” um robô clicando nos dados que quer, e a IA generaliza o padrão para futuras raspagens. Ela lida com logins, rolagem infinita e pode monitorizar sites para detetar mudanças.
- Ideal para: utilizadores não técnicos que querem automatizar a recolha e o monitoramento de dados.
- Preço: plano gratuito (50 créditos/mês); planos pagos a partir de US$ 19/mês.
6. LLM Scraper
Para quem é: desenvolvedores que querem que a IA faça o parsing.
LLM Scraper é uma biblioteca open-source em JavaScript/TypeScript que permite definir um esquema de dados e fazer com que um LLM extraia esses dados de qualquer página web. Ela foi construída sobre o Playwright, oferece suporte a vários fornecedores de LLM e até pode gerar código reutilizável.
- Ideal para: desenvolvedores que querem transformar qualquer página web em dados estruturados usando LLMs.
- Preço: gratuito (licença MIT).
7. Reader (Jina Reader)
Para quem é: desenvolvedores que criam aplicações com LLMs, chatbots ou resumidores.
Jina Reader é uma API que extrai texto limpo e dados estruturados de páginas web (e até de PDFs/imagens), retornando Markdown ou JSON prontos para LLM. Ela é alimentada por um modelo de IA próprio e até consegue gerar legendas para imagens.
- Ideal para: obter conteúdo limpo e legível para LLMs ou sistemas de perguntas e respostas.
- Preço: API gratuita (sem necessidade de chave para uso básico).
8. Bright Data
Para quem é: empresas e utilizadores profissionais que precisam de escala, conformidade e fiabilidade.
Bright Data é uma gigante no setor de dados web, com uma rede massiva de proxies e ferramentas de scraping orientadas por IA. Ela oferece raspadores prontos, uma API geral de Web Scraper e feeds de dados “prontos para LLM”.
- Ideal para: organizações que precisam de dados web fiáveis em grande escala.
- Preço: baseado no uso, premium. Há testes gratuitos disponíveis.
9. Octoparse
Para quem é: utilizadores sem conhecimentos técnicos ou com conhecimentos técnicos leves.
Octoparse é uma ferramenta consagrada sem código, com um construtor visual de fluxos de trabalho e deteção automática com IA. Ela lida com logins, rolagem infinita e pode exportar dados em vários formatos.
- Ideal para: analistas, donos de pequenas empresas ou investigadores.
- Preço: plano gratuito disponível; planos pagos começam em US$ 119/mês.
10. Apify
Para quem é: desenvolvedores e equipas técnicas que precisam de scraping/automação personalizados.
Apify é uma plataforma na nuvem para executar scripts de scraping (“actors”) e oferece uma loja de actors prontos. É escalável, integra com IA e oferece suporte ao gerenciamento de proxies.
- Ideal para: desenvolvedores que querem executar scripts personalizados na nuvem.
- Preço: plano gratuito; planos pagos com base no uso começam em US$ 49/mês.
11. Zyte (Scrapy Cloud)
Para quem é: desenvolvedores e empresas que precisam de scraping de nível corporativo.
Zyte é a empresa por trás do Scrapy, oferecendo uma plataforma na nuvem e extração automática com IA. Ela lida com agendamento, proxies e projetos em grande escala.
- Ideal para: equipas de desenvolvimento que executam projetos de scraping de longo prazo.
- Preço: de testes gratuitos a planos corporativos personalizados.
12. Webscraper.io
Para quem é: iniciantes, jornalistas e investigadores.
Webscraper.io é uma extensão popular do Chrome para extração de dados por apontar e clicar. É simples, gratuita para uso local e oferece um serviço na nuvem para trabalhos maiores.
- Ideal para: tarefas rápidas e pontuais de scraping.
- Preço: extensão gratuita; planos na nuvem a partir de cerca de US$ 50/mês.
13. ParseHub
Para quem é: utilizadores sem conhecimentos técnicos que precisam de mais poder do que ferramentas básicas.
ParseHub é uma aplicação de desktop com um fluxo de trabalho visual para raspar conteúdo dinâmico, incluindo mapas e formulários. Ela pode executar projetos na nuvem e oferece uma API.
- Ideal para: profissionais de marketing digital, analistas e jornalistas.
- Preço: plano gratuito (200 páginas/execução); planos pagos começam em US$ 189/mês.
14. Diffbot
Para quem é: empresas e companhias de IA que precisam de dados web estruturados em grande escala.
Diffbot usa visão computacional e NLP para extrair dados automaticamente de qualquer página web, oferecendo APIs para artigos, produtos e um enorme grafo de conhecimento.
- Ideal para: inteligência de mercado, finanças e dados para treino de IA.
- Preço: premium, a partir de cerca de US$ 299/mês.
15. DataMiner
Para quem é: utilizadores sem conhecimentos técnicos, especialmente em vendas, marketing e jornalismo.
DataMiner é uma extensão do Chrome para extração rápida de dados web por apontar e clicar. Ela tem uma biblioteca de “receitas” prontas e pode exportar diretamente para o Google Sheets.
- Ideal para: tarefas rápidas como exportar tabelas ou listas para folhas de cálculo.
- Preço: plano gratuito (500 páginas/dia); o Pro começa em cerca de US$ 19/mês.
Comparando as principais ferramentas de raspador web com IA: qual atende às suas necessidades?
Aqui vai uma comparação de alto nível para ajudar você a encontrar a opção ideal:
| Ferramenta | Uso de IA/LLM | Facilidade de uso | Saída/Integração | Ideal para | Preço |
|---|---|---|---|---|---|
| Thunderbit | Interface em linguagem natural; a IA sugere campos | A mais fácil (chat sem código) | Exportação para Sheets, Airtable, Notion | Equipas sem perfil técnico | Plano gratuito; Pro ~US$30/mês |
| Crawl4AI | Rastreamento pronto para IA; integra LLMs | Difícil (código em Python) | Biblioteca/CLI; integração via código | Devs que precisam de pipelines rápidos de dados com IA | Gratuito |
| ScrapeGraphAI | Pipelines de prompt LLM para scraping | Médio (algum código ou API) | API/SDK; saída em JSON | Devs/analistas construindo agentes de IA | OSS gratuito; API a partir de US$20/mês |
| Firecrawl | Rastreia para Markdown/JSON pronto para LLM | Médio (uso de API/SDK) | SDKs (Py, Node etc.); integração com LangChain | Devs que integram dados web ao vivo com IA | Gratuito + nuvem paga |
| Browse AI | IA assistindo no apontar e clicar | Fácil (sem código) | Mais de 7000 integrações com apps (Zapier) | Utilizadores sem perfil técnico automatizando monitoramento web | 50 execuções grátis; Pago a partir de US$19/mês |
| LLM Scraper | Usa LLMs para converter página em esquema | Difícil (código TS/JS) | Biblioteca de código; saída em JSON | Devs que querem que a IA faça o parsing | Gratuito (usando sua própria API de LLM) |
| Reader (Jina) | Modelo de IA extrai texto/JSON | Fácil (chamada simples de API) | API REST retorna Markdown/JSON | Devs que levam busca/conteúdo web para LLMs | API gratuita |
| Bright Data | APIs de scraping aprimoradas por IA; grande rede de proxies | Difícil (API, técnico) | APIs/SDKs; streams ou conjuntos de dados | Escala corporativa | Baseado no uso |
| Octoparse | Deteção automática de listas com IA | Moderado (app sem código) | CSV/Excel, API para resultados | Utilizadores com conhecimentos semi-técnicos | Gratuito com limites; US$59–US$166/mês |
| Apify | Alguns recursos de IA (Actors, tutoriais de IA) | Difícil (scripts em código) | API abrangente; integra com LangChain | Devs que precisam de scraping personalizado na nuvem | Plano gratuito; pay-as-you-go |
| Zyte (Scrapy) | Extração automática baseada em ML; framework Scrapy | Difícil (código Python) | API, interface do Scrapy Cloud; JSON/CSV | Equipas de desenvolvimento, projetos de longo prazo | Preço personalizado |
| Webscraper.io | Sem IA (modelos manuais) | Fácil (extensão do navegador) | Download em CSV, API na nuvem | Iniciantes, raspagens rápidas e pontuais | Extensão gratuita; Nuvem ~US$50/mês |
| ParseHub | Sem LLM explícito; construtor visual | Moderado (app sem código) | JSON/CSV; API para execuções na nuvem | Quem não é dev e raspa sites complexos | 200 páginas grátis; Pago a partir de US$189/mês |
| Diffbot | Visão/NLP com IA para qualquer página; grafo de conhecimento | Fácil (basta chamar APIs) | APIs (Artigo/Produto/...) + consulta ao Grafo de Conhecimento | Dados web estruturados para empresas | A partir de ~US$299/mês |
| DataMiner | Sem LLM; receitas da comunidade | O mais fácil (interface do navegador) | Exportação para Excel/CSV; Google Sheets | Utilizadores sem perfil técnico que raspam para folhas de cálculo | Gratuito com limites; Pro ~US$19/mês |
Categorias de ferramentas: de potências para desenvolvedores a raspadores web amigáveis para negócios
Para dar sentido a esta lista, vamos separar essas ferramentas em algumas categorias:
1. Potências para desenvolvedores e open-source
- Exemplos: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Pontos fortes: alta flexibilidade, escala e personalização. Ótimas para construir pipelines à medida ou integrar com modelos de IA.
- Trade-offs: exigem competências de programação e mais configuração.
- Casos de uso: construir um pipeline de dados personalizado, raspar sites complexos ou integrar com sistemas internos.
2. Agentes de scraping integrados à IA
- Exemplos: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Pontos fortes: reduzem a distância entre raspar e entender os dados. As interfaces em linguagem natural tornam-nos acessíveis.
- Trade-offs: alguns ainda estão a evoluir; talvez não ofereçam controlo granular.
- Casos de uso: respostas rápidas ou conjuntos de dados, criação de agentes autónomos ou envio de dados ao vivo para LLMs.
3. Raspadores sem código/baixo código, amigáveis para negócios
- Exemplos: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Pontos fortes: fáceis de usar, exigem pouco ou nenhum código, e são bons para tarefas recorrentes de negócios.
- Trade-offs: podem ter dificuldade com sites muito complexos ou com escala massiva.
- Casos de uso: geração de leads, monitoramento de concorrentes, projetos de pesquisa e extrações pontuais de dados.
4. Plataformas e serviços de dados corporativos
- Exemplos: Bright Data, Diffbot, Zyte
- Pontos fortes: soluções completas, serviços geridos, conformidade e fiabilidade em escala.
- Trade-offs: custo mais alto, exigem mais integração inicial.
- Casos de uso: pipelines de dados contínuos e em grande escala, inteligência de mercado e dados para treino de IA.
Como escolher o rastreador web com IA certo para suas necessidades de scraping de páginas web
O que é Data Scraping e como fazer Get Started Free
Escolher a ferramenta certa pode parecer demais, então aqui vai o meu guia passo a passo:
- Defina os seus objetivos e requisitos de dados: quais sites e quais dados você precisa? Com que frequência? Em que volume? O que vai fazer com eles?
- Avalie a sua capacidade técnica: sem código? Experimente Thunderbit, Browse AI ou Octoparse. Sabe programar um pouco? LLM Scraper ou DataMiner. Tem forte capacidade de desenvolvimento? Crawl4AI, Apify ou Zyte.
- Considere frequência e escala: uso pontual? Use ferramentas gratuitas. Recorrente? Procure recursos de agendamento. Em grande escala? Ferramentas corporativas ou open-source em escala.
- Orçamento e modelo de preço: planos gratuitos são ótimos para testes. Assinatura vs. cobrança por uso depende das suas necessidades.
- Teste e prova de conceito: experimente algumas ferramentas com os seus dados reais. A maioria tem versões gratuitas.
- Manutenção e suporte: quem vai corrigir as coisas se o site mudar? Ferramentas sem código com IA podem corrigir pequenas alterações automaticamente; open-source depende de você ou da comunidade.
- Associe as ferramentas aos cenários: equipa de vendas a raspar leads? Thunderbit ou Browse AI. Investigador a recolher tweets? DataMiner ou Webscraper.io. Modelo de IA a precisar de artigos de notícias? Jina Reader ou Zyte. A construir um site comparativo? Apify ou Zyte.
- Tenha um plano B: às vezes, uma ferramenta não funciona num determinado site. Tenha uma alternativa.
A ferramenta “certa” é aquela que entrega os dados de que você precisa com o menor atrito possível e dentro do seu orçamento. Às vezes, é uma combinação de ferramentas.
Thunderbit vs. ferramentas tradicionais de raspador web: o que a torna diferente?
Vamos ser específicos sobre por que a Thunderbit é diferente:
- Interface em linguagem natural: sem código, sem malabarismos de apontar e clicar. Basta descrever o que quer (fonte).
- Zero configuração e sugestões de modelos: a Thunderbit detecta automaticamente paginação, subpáginas e até sugere modelos para sites comuns (fonte).
- Limpeza e enriquecimento de dados com IA: resuma, categorize, traduza e enriqueça dados enquanto faz o scraping (fonte).
- Menos dores de cabeça com manutenção: a IA da Thunderbit é resiliente a pequenas mudanças no site, reduzindo falhas.
- Integração com ferramentas de negócios: exportação direta para Google Sheets, Airtable e Notion — chega de lidar com CSV (fonte).
- Rapidez para gerar valor: vá da ideia aos dados em minutos, não em dias.
- Curva de aprendizagem: se você consegue navegar na web e descrever o que precisa, consegue usar a Thunderbit.
- Adaptabilidade: raspe sites, PDFs, imagens e muito mais — tudo com a mesma ferramenta.
A Thunderbit não é apenas um raspador — é um assistente de dados que se encaixa no seu fluxo de trabalho, seja você de vendas, marketing, ecommerce ou imóveis.
Experimente o Raspador Web IA da Thunderbit
Melhores práticas de scraping de páginas web com ferramentas de raspador web com IA
Para aproveitar ao máximo os raspadores web com IA, aqui estão as minhas principais dicas:
- Defina claramente as suas necessidades de dados: saiba quais campos quer, quantas páginas e qual formato precisa.
- Aproveite as sugestões da IA: use a deteção de campos e as sugestões da ferramenta para captar dados importantes que poderia perder (fonte).
- Comece pequeno e valide: teste numa amostra pequena, confira a saída e ajuste conforme necessário.
- Lide com conteúdo dinâmico: confirme se a sua ferramenta suporta conteúdo e interações dinâmicas (paginação, rolagem infinita etc.).
- Respeite as políticas do site: verifique o robots.txt, evite raspar dados sensíveis e respeite os limites de taxa.
- Integre para automatizar: use recursos de exportação e webhooks para ligar os dados raspados diretamente ao seu fluxo de trabalho.
- Mantenha a qualidade dos dados: faça uma verificação de sanidade, use pós-processamento e monitorize erros.
- Seja conciso com prompts: ao usar ferramentas orientadas por IA, instruções claras e específicas trazem melhores resultados.
- Aprenda com a comunidade: participe em fóruns e comunidades para dicas e resolução de problemas.
- Fique atualizado: ferramentas de IA evoluem rápido — acompanhe novos recursos e melhorias.
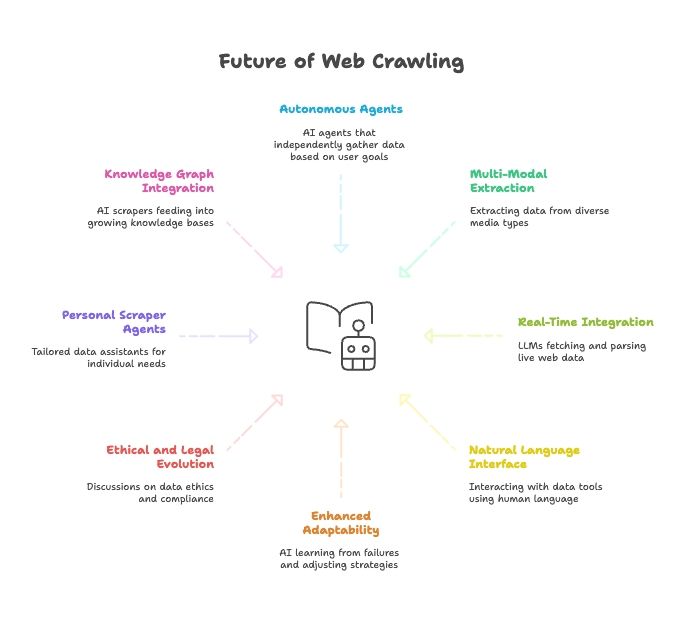
O futuro do web scraping: IA, LLMs e a ascensão dos agentes de raspador web em linguagem natural
Olhando para a frente, a convergência entre IA e web scraping só acelera:
- Agentes de scraping totalmente autónomos: em breve, você só vai dizer a um agente de IA qual é o objetivo final, e ele vai descobrir como obter os dados.
- Extração de dados multimodal: os raspadores vão puxar dados de texto, imagens, PDFs e até vídeos.
- Integração em tempo real com modelos de IA: os LLMs terão módulos nativos para buscar e analisar dados web ao vivo.
- Tudo em linguagem natural: vamos conversar com as nossas ferramentas de dados como conversamos com pessoas, tornando a recolha e a transformação de dados acessíveis para todos.
- Adaptabilidade aprimorada: os raspadores com IA vão aprender com falhas e adaptar estratégias automaticamente.
- Evolução ética e legal: espere mais discussões sobre ética de dados, conformidade e uso justo.
- Agentes pessoais de scraping: imagine um assistente pessoal de dados que reúne notícias, vagas de emprego e muito mais, adaptado às suas necessidades.
- Integração com grafos de conhecimento: raspadores com IA vão alimentar continuamente bases de conhecimento cada vez maiores, impulsionando uma IA mais inteligente.
Em resumo? O futuro do web scraping está entrelaçado com o futuro da IA. As ferramentas estão a ficar mais inteligentes, mais autónomas e mais acessíveis a cada dia.
Conclusão: destravar valor de negócio com o rastreador web com IA certo
O web scraping saiu de uma habilidade técnica de nicho para se tornar uma capacidade central de negócio — graças à IA. As 15 ferramentas que abordei aqui representam o melhor do que é possível em 2026, de potências para desenvolvedores a assistentes amigáveis para negócios.
O verdadeiro segredo? Escolher a ferramenta certa pode aumentar dramaticamente o valor que você obtém dos dados da web. Para equipas sem perfil técnico, a Thunderbit é a forma mais fácil de transformar a web num banco de dados estruturado e pronto para análise — sem código, sem complicação, só resultados.
Então, seja para reunir leads, monitorizar concorrentes ou alimentar o seu próximo modelo de IA, vale a pena dedicar algum tempo a avaliar as suas necessidades, testar algumas ferramentas e ver o que funciona para você. E, se quiser experimentar hoje o futuro do web scraping, experimente a Thunderbit. As informações de que você precisa estão a apenas um prompt de distância.
Curioso para saber mais? Confira o Blog da Thunderbit para análises aprofundadas, tutoriais e as novidades mais recentes em extração de dados com IA.
Leituras adicionais:
- O que é Data Scraping e como fazer em 2026
- Como raspar dados de sites para o Excel usando IA
- As melhores ferramentas e softwares de web scraping em 2026
Experimente o Raspador Web IA Get Started Free
FAQs
1. O que é um rastreador web com IA e em que ele difere dos raspadores web tradicionais?
Um rastreador web com IA usa processamento de linguagem natural e aprendizagem de máquina para entender, extrair e estruturar dados da web. Ao contrário dos raspadores tradicionais, que exigem programação manual e seletores XPath, as ferramentas de IA conseguem lidar com conteúdo dinâmico, adaptar-se a mudanças de layout e interpretar instruções do utilizador em inglês simples.
2. Quem deve usar ferramentas de web scraping com IA como a Thunderbit?
A Thunderbit foi criada para utilizadores técnicos e não técnicos. É ideal para profissionais de vendas, marketing, operações, pesquisa e ecommerce que querem extrair dados estruturados de sites, PDFs ou imagens — sem escrever código.
3. Quais recursos fazem a Thunderbit se destacar de outros rastreadores web com IA?
A Thunderbit oferece uma interface em linguagem natural, rastreamento em vários níveis, estruturação automática de dados, suporte a OCR e exportações diretas para plataformas como Google Sheets e Airtable. Ela também inclui sugestões de campos com IA e modelos prontos para sites populares.
4. Existem opções gratuitas para web scraping com IA em 2026?
Sim. Muitas ferramentas como Thunderbit, Browse AI e DataMiner oferecem planos gratuitos com uso limitado. Para desenvolvedores, opções open-source como Crawl4AI e ScrapeGraphAI oferecem funcionalidade completa sem custo, embora exijam configuração técnica.
5. Como escolher o rastreador web com IA certo para as minhas necessidades?
Comece identificando os seus objetivos de dados, capacidade técnica, orçamento e requisitos de escala. Se você quer uma solução sem código e fácil de usar, Thunderbit ou Browse AI são ótimas opções. Para necessidades maiores ou personalizadas, ferramentas como Apify ou Bright Data são mais indicadas.




