

Kilka miesięcy temu kolega z naszego zespołu sprzedaży zadał mi pytanie, które słyszałem już dziesiątki razy: „Jeśli zeskrobię ceny konkurencji z publicznej strony, to naprawdę mogę mieć kłopoty?” Znalazł katalog kontaktów do dostawców, ceny ułożone w równych wierszach i chciał po prostu arkusz kalkulacyjny. Wahanie było prawdziwe — i szczerze mówiąc, uzasadnione.
W Wielkiej Brytanii nie ma jednej „ustawy o web scrapingu”. Zamiast tego o legalności konkretnego działania decydują cztery nakładające się ramy prawne. Dlatego odpowiedź zawsze brzmi: „to zależy” — ale nie musi to paraliżować. W tym przewodniku wyjaśnię, co naprawdę mówi prawo, jak stosuje się ono do rzeczywistych scenariuszy, jakie grożą kary i jak zachować zgodność.
Spędziłem dużo czasu, badając to dla naszego zespołu w Thunderbit, i chcę podzielić się tym, co znalazłem, żebyś nie musiał składać tego w całość z pięciu różnych blogów kancelarii i wątku na Reddicie.
Wypróbuj Thunderbit do web scrapingu
Czym jest web scraping (i dlaczego brytyjskie firmy z niego korzystają)
Web scraping polega na użyciu oprogramowania do automatycznego zbierania danych ze stron internetowych — zamiast żmudnego kopiowania i wklejania treści ze stron do arkusza kalkulacyjnego.
Sama technika jest neutralna. Nie jest z natury legalna ani nielegalna. Liczy się to, co zeskrobujesz, w jaki sposób to zrobisz i co zrobisz z danymi później.
Brytyjskie firmy używają scrapingu w wielu legalnych celach:
- Porównywanie cen: na przykład PriceSpy UK aktualizuje ceny produktów trzy do pięciu razy dziennie dzięki automatycznemu web scrapingowi.
- Generowanie leadów: zespoły sprzedaży pobierają nazwy firm, adresy e-mail i numery telefonów z publicznych katalogów.
- Badania rynku: analitycy monitorują ogłoszenia nieruchomości, portale pracy lub asortyment konkurencji.
- Badania naukowe: Office for National Statistics zebrał ponad 2,2 miliona notowań cenowych ze stron supermarketów między 2014 a 2015 rokiem.
- Trenowanie modeli AI: szybko rosnący — i prawnie niejednoznaczny — przypadek użycia.
Trend jest jasny. Badanie Bright Data/Vanson Bourne przeprowadzone wśród 500 decydentów (w tym 200 w Wielkiej Brytanii) wykazało, że 89% uznaje publiczne dane z internetu za kluczowe lub bardzo ważne dla globalnej gospodarki, a 38% pozyskuje je co najmniej codziennie.
Jednocześnie 73% stwierdziło, że brak jasnych regulacji niepokoi ich organizację. To właśnie dlatego powstał ten artykuł.
Czy web scraping jest legalny w Wielkiej Brytanii? Bezpośrednia odpowiedź
Żadne brytyjskie prawo nie zakazuje web scrapingu wprost. Reguluje go jednak kilka ustaw i przepisów, a legalność konkretnego projektu zależy od czterech czynników:
- Jakie dane zeskrobujesz (dane osobowe kontra dane faktograficzne / nieosobowe)
- Jak uzyskujesz dostęp (publiczna strona kontra omijanie logowania lub CAPTCHA)
- Co mówią warunki korzystania ze strony (czy zakazują automatycznego dostępu?)
- Jak wykorzystujesz dane później (analiza wewnętrzna kontra komercyjna odsprzedaż)
Najlepsza analogia, jaką znalazłem: web scraping jest jak fotografowanie w miejscu publicznym. Zrobienie zdjęcia na ulicy nie jest automatycznie nielegalne — ale pewne obiekty, miejsca, metody i sposoby użycia tworzą ryzyko prawne. Z web scrapingiem jest podobnie. Publiczna dostępność ma znaczenie, ale nie wyczerpuje tematu.
Najnowsze konsultacje ICO dotyczące GenAI to jedno z najjaśniejszych oficjalnych stanowisk w Wielkiej Brytanii w sprawie zeskrobanych danych osobowych. ICO stwierdziło, że uzasadniony interes pozostaje jedyną dostępną podstawą prawną do trenowania generatywnych modeli AI z wykorzystaniem zeskrobanych z sieci danych osobowych — ale tylko wtedy, gdy twórca przejdzie rygorystyczny, trzyczęściowy test. To wysoki próg i sygnał, jak poważnie brytyjscy regulatorzy traktują zeskrobane dane.
Cztery brytyjskie akty prawne mające zastosowanie do web scrapingu
Cztery nakładające się perspektywy — każdy projekt scrapingu może uruchomić jedną, dwie albo wszystkie cztery.
UK GDPR i Data Protection Act 2018
Jeśli zeskrobiesz dane osobowe — imiona i nazwiska, adresy e-mail, numery telefonów, adresy IP, profile w mediach społecznościowych — zastosowanie ma UK GDPR. „Publicznie dostępne” nie znaczy „darmowe do dowolnego użycia”.
Publicznie widoczne dane osobowe nadal są danymi osobowymi.
Najbardziej odpowiednią podstawą prawną dla komercyjnego scrapingu jest uzasadniony interes (artykuł 6) — ale nie wystarczy rzucić tym pojęciem bez dalszego namysłu. Trzeba:
- wskazać konkretny, uzasadniony cel
- wykazać, że przetwarzanie jest niezbędne do tego celu
- wyważyć własny interes wobec praw osób, których dane zbierasz
Odpowiedź ICO na konsultacje dotyczące GenAI jest szczególnie jednoznaczna: twórcy nie powinni zakładać, że szeroka korzyść społeczna wystarczy, powinni wykazać, dlaczego alternatywy dla scrapingu są nieodpowiednie, oraz stosować mechanizmy przejrzystości, które pozwalają osobom zrozumieć ich sytuację i korzystać ze swoich praw. Źródło: odpowiedź ICO dotycząca GenAI.
W przypadku generowania leadów B2B obowiązuje ta sama logika. Zespół sprzedaży może oprzeć się na uzasadnionym interesie przy zbieraniu publicznie dostępnych danych kontaktowych firm, ale nadal musi udokumentować ten interes, ograniczyć zakres zbieranych pól, unikać danych szczególnej kategorii, zapewnić informacje o prywatności tam, gdzie to możliwe, i respektować rezygnacje.
Prawo autorskie, prawa do baz danych i wyjątek TDM
Prawo autorskie chroni oryginalne treści strony internetowej: teksty, obrazy, opisy produktów, artykuły. Fakty — takie jak ceny — zwykle same w sobie są mniej wrażliwe z perspektywy prawa autorskiego, ale skopiowanie i ponowne opublikowanie chronionej ekspresji wchodzi już w obszar naruszenia.
Prawa do baz danych mają przy scrapingu większe znaczenie, niż większość osób przypuszcza. Po Brexicie Wielka Brytania zachowała sui generis prawa do baz danych wzorowane na prawie UE, a wyodrębnienie „istotnej części” chronionej bazy — katalogów kuratorskich, katalogów produktów, ofert na marketplace’ach — może naruszać prawo nawet wtedy, gdy pojedyncze dane są faktograficzne.
Wyjątek Text and Data Mining (TDM) na podstawie Section 29A CDPA pozwala na tworzenie kopii do analizy tekstu i danych tylko wtedy, gdy użytkownik ma legalny dostęp, a cel jest niekomercyjny i badawczy. To bardzo wąski wyjątek. Komercyjny scraping, komercyjne trenowanie AI i komercyjna odsprzedaż zestawów danych nie są nim objęte.
Brytyjski rząd rozważał rozszerzenie tego wyjątku na potrzeby trenowania AI, ale według raportu Copyright and AI z marca 2026 nie zdecydował się na reformy, dopóki nie będzie pewny, że spełniają one cele twórców, twórców systemów AI i brytyjskiej gospodarki. Przy obecnym stanie prawnym zwykle potrzebna jest zgoda na kopiowanie chronionych utworów do trenowania AI, chyba że zastosowanie ma istniejący wyjątek.
Warunki korzystania ze strony i prawo umów
Większość stron ma regulaminy lub warunki korzystania (ToS), które zakazują albo ograniczają automatyczny scraping. Wejście na stronę może oznaczać akceptację tych warunków — szczególnie jeśli przechodzisz przez ekran akceptacji (clickwrap). Umowy browsewrap (warunki ukryte za linkiem w stopce) są bardziej zależne od faktów, ale brytyjskie sądy wykazywały gotowość do egzekwowania ograniczeń dotyczących scrapingu. W sporze Ryanair v Billigfluege sąd uznał widoczne warunki strony za wiążące w kontekście screen scrapingu.
robots.txt nie jest ustawą. To sygnał możliwy do odczytu maszynowo, wysyłany przez właściciela strony. Typowy plik wygląda tak:
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
Ignorowanie robots.txt nie czyni scrapingu automatycznie nielegalnym, ale sądy i ICO traktują to jako dowód intencji właściciela strony. Zignorowanie tego pliku zwiększa ekspozycję prawną, zwłaszcza jeśli łączy się z naruszeniem ToS lub agresywną liczbą zapytań.
Computer Misuse Act 1990
To właśnie ta ustawa wielu osobom spędza sen z powiek — i słusznie. Wprowadza przestępstwa kryminalne. Sekcja 1 dotyczy nieuprawnionego dostępu do materiału komputerowego (maksymalnie 2 lata więzienia). Sekcja 3 dotyczy nieuprawnionych działań zakłócających pracę systemu komputerowego (maksymalnie 10 lat więzienia).
Ryzyko na gruncie CMA jest najniższe wtedy, gdy dane są rzeczywiście publiczne, a scraper nie omija barier technicznych. Ryzyko rośnie, gdy:
- omijasz logowanie, CAPTCHA lub blokady IP
- używasz skradzionych danych logowania albo tworzysz fałszywe konta
- wysyłasz tak duży ruch, że zakłóca on działanie usługi docelowej
W Wielkiej Brytanii nie ma prostych, amerykańskich zasad w stylu „publiczne dane są fair game”. Dlatego brytyjskie podejście jest ostrożniejsze: publiczny dostęp istotnie obniża ryzyko w świetle CMA, ale znaczenie mogą mieć nadal warunki strony, zabezpieczenia techniczne i wiedza scrapera o ograniczeniach.
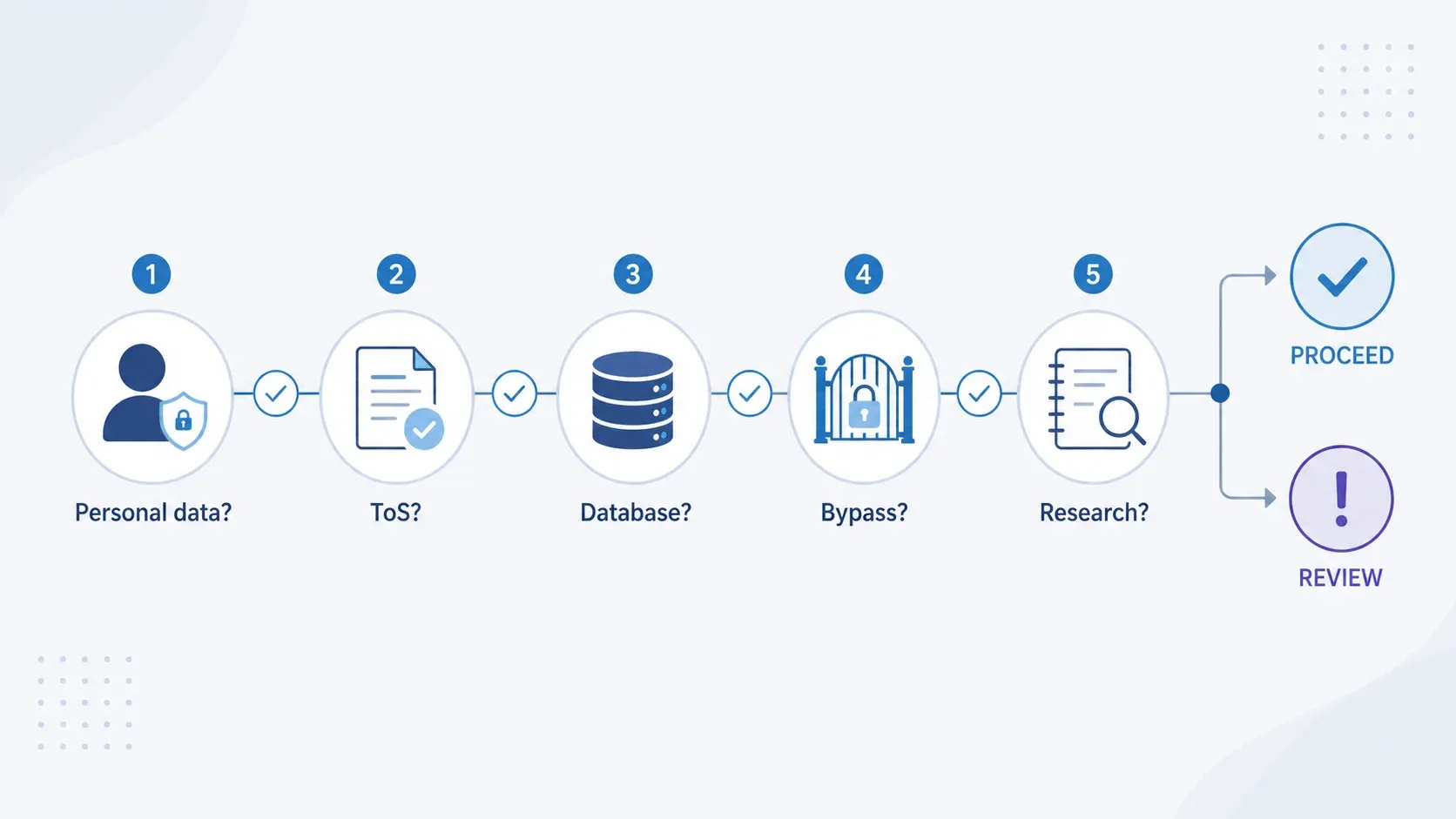
„Czy mogę to legalnie zeskrobać?” — szybki schemat decyzyjny
Zanim zeskrobiesz cokolwiek, przejdź przez te pięć punktów. To nie jest porada prawna — raczej 60-sekundowa ocena ryzyka.
| Punkt decyzyjny | Jeśli TAK | Jeśli NIE |
|---|---|---|
| Dane są danymi osobowymi (imiona, e-maile itd.)? | Zastosowanie ma UK GDPR. Ustal podstawę prawną, wykonaj LIA, ogranicz pola, zaplanuj przejrzystość. | Warstwa GDPR może nie mieć zastosowania, ale przejdź do kolejnych kontroli. |
| Regulamin strony wyraźnie zakazuje scrapingu? | Ryzyko naruszenia umowy. Rozważ API, licencję albo analizę prawną. | Niższe ryzyko kontraktowe, ale sprawdź robots.txt. |
| Wyodrębniasz istotną część bazy danych? | Prawdopodobne naruszenie prawa sui generis do bazy danych. Rozważ licencję albo węższy zakres ekstrakcji. | Prawo autorskie może nadal dotyczyć pojedynczych skopiowanych treści. |
| Omijasz logowanie, CAPTCHA lub kontrolę dostępu? | Potencjalne przestępstwo na gruncie CMA 1990. Zatrzymaj się i uzyskaj analizę prawną. | Niższe ryzyko CMA, jeśli dostęp jest naprawdę publiczny. |
| Cel jest niekomercyjny i badawczy? | Wyjątek TDM z Section 29A może mieć zastosowanie, jeśli masz legalny dostęp. | Brak szerokiej komercyjnej bezpiecznej przystani w prawie brytyjskim TDM. Potrzebna pełna analiza IP i umów. |
Szczerze, chciałbym, żeby ktoś dał mi to, kiedy zaczynałem badać zgodność scrapingu dla naszego zespołu. Zamiast chaosu dostajesz uporządkowaną samoocenę, którą możesz przeprowadzić w mniej niż minutę.
Rzeczywiste scenariusze: czy Twój konkretny scraping jest legalny w Wielkiej Brytanii?
Prawo w teorii to jedno. Ludzie naprawdę chcą wiedzieć: „Czy mój konkretny projekt wpakuje mnie w kłopoty?”
Rozsądne pytanie. Oto pięć popularnych przypadków użycia scrapingu w Wielkiej Brytanii wraz z krótką oceną ryzyka prawnego dla każdego z nich.
Zbieranie cen produktów do porównań
Jedno z najczęstszych — i często najniższego ryzyka — zastosowań biznesowych. Ceny są danymi faktograficznymi, a automatyczne pobieranie cen to właśnie sposób działania serwisów takich jak PriceSpy.
Ryzyko jednak nie znika całkowicie. Jeśli strona docelowa zakazuje scrapingu w swoich ToS, jeśli kopiujesz opisy produktów lub obrazy albo jeśli wyodrębniasz istotną część kuratorskiej bazy produktów, mogą pojawić się kwestie umowy, prawa autorskiego i praw do baz danych.
Poziom ryzyka: NISKI do ŚREDNIEGO
Kluczowy krok zgodności: zbieraj wyłącznie faktograficzne pola cenowe, nie kopiuj dosłownie opisów produktów, respektuj ToS i robots.txt, stosuj limitowanie zapytań i nie publikuj surowego lustra katalogu konkurenta.
Komercyjne zeskrobywanie i odsprzedaż danych
Najwyższe ryzyko w ujęciu komercyjnym — bez dwóch zdań. Zamieniasz inwestycję innej strony w dane w produkt na sprzedaż, a to może uruchomić jednocześnie wszystkie cztery filary prawne.
Poziom ryzyka: WYSOKI
Kluczowy krok zgodności: niezbędna jest analiza prawna. Rozważ umowy licencyjne z właścicielami danych. Jeśli produkt zawiera dane osobowe, dodaj ocenę skutków dla ochrony danych.
Ekstrakcja danych kontaktowych firm do lead generation
Każdy zespół sprzedaży, z którym rozmawiałem, robi jakąś wersję tego: zeskrobuje e-maile, numery telefonów i nazwy firm z katalogów. Hak? Dane kontaktowe firm często są danymi osobowymi. Adres e-mail przypisany do konkretnego pracownika jest danymi osobowymi, nawet jeśli widnieje publicznie.
Poziom ryzyka: ŚREDNI
Kluczowy krok zgodności: przeprowadź Legitimate Interests Assessment, zbieraj tylko dane kontaktowe biznesowe (nie prywatne), jeśli to możliwe, udokumentuj podstawę prawną i zapewnij możliwość rezygnacji. Narzędzia takie jak Thunderbit mogą tu zmniejszyć ryzyko dostępu, ponieważ rozszerzenie do Chrome działa w przeglądarce użytkownika — uzyskuje dostęp tylko do tego, co użytkownik już widzi, bez obchodzenia kontroli dostępu.
Analiza danych do celów akademickich lub portfolio
Jeśli prowadzisz rzeczywiście niekomercyjne badania, masz najsilniejszą ścieżkę wyjątku w prawie autorskim: Section 29A CDPA, pod warunkiem, że masz legalny dostęp.
Poziom ryzyka: NISKI (jeśli rzeczywiście niekomercyjne)
Kluczowy krok zgodności: udokumentuj niekomercyjny cel, cytuj źródła, anonimizuj lub agreguj dane tam, gdzie to możliwe, i nie rozpowszechniaj ponownie chronionych treści ani danych osobowych.
Zbieranie treści do trenowania modelu AI
To pytanie zadają wszyscy w 2026 roku — a odpowiedź wciąż nie jest satysfakcjonująca. ICO traktuje zeskrobane z sieci dane osobowe użyte do treningu jako wysokiego ryzyka, niewidoczne przetwarzanie. Raport brytyjskiego rządu z 2026 roku nie wprowadził szerokiego komercyjnego wyjątku TDM.
Poziom ryzyka: ŚREDNI do WYSOKIEGO
Kluczowy krok zgodności: licencjonowanie, pochodzenie zbioru danych, analiza praw autorskich, filtrowanie danych osobowych, dokumentacja podstawy prawnej i ścisłe monitorowanie zmian w polityce Wielkiej Brytanii.
Tabela podsumowująca scenariusze
| Scenariusz | Główne przepisy prawne | Poziom ryzyka | Kluczowy krok zgodności |
|---|---|---|---|
| Monitorowanie cen produktów | ToS, prawa do baz danych, prawo autorskie | Niskie–Średnie | Zbieraj pola faktograficzne, respektuj sygnały strony |
| Komercyjna odsprzedaż danych | Wszystkie cztery filary | Wysokie | Niezbędna analiza prawna i licencjonowanie |
| Lead generation B2B | UK GDPR, ToS | Średnie | Przeprowadź LIA, ogranicz dane osobowe |
| Badania akademickie | Prawo autorskie (wyjątek TDM), GDPR jeśli dane osobowe | Niskie | Zachowaj niekomercyjny cel, nie publikuj ponownie |
| Trenowanie modelu AI | UK GDPR, prawo autorskie, prawa do baz danych | Średnie–Wysokie | Licencjonuj dane, dokumentuj podstawę prawną, monitoruj politykę |
Wielka Brytania vs. USA vs. UE: czym różni się prawo web scrapingu
Jeśli działasz tylko w Wielkiej Brytanii, możesz pominąć tę sekcję. Ale większość firm, z którymi rozmawiam, scrapuje międzynarodowo — albo przynajmniej pobiera dane z witryn hostowanych w innych jurysdykcjach. Różnice są ważniejsze, niż się wydaje.
| Obszar prawny | 🇬🇧 Wielka Brytania | 🇺🇸 USA | 🇪🇺 UE |
|---|---|---|---|
| Główne prawo ochrony danych | UK GDPR + DPA 2018 | Brak federalnego odpowiednika (przepisy stanowe różnią się) | EU GDPR |
| Kluczowy precedens dotyczący scrapingu | Clearview AI (kara ICO 7,5 mln £) | hiQ v LinkedIn (scraping publicznych danych OK, Ninth Circuit — ale hiQ został trwale zablokowany i zapłacił 500 tys. $ w ostatecznym wyroku ugodowym) | Ryanair v PR Aviation (TSUE, C-30/14, prawa do baz danych) |
| Prawo dostępu do systemów komputerowych | Computer Misuse Act 1990 | CFAA (zawężony przez Van Buren, 2021) | Różni się w zależności od państwa członkowskiego |
| Prawo autorskie / wyjątek TDM | Wąski: tylko badania niekomercyjne (Section 29A) | Doktryna fair use (szersza, oceniana indywidualnie) | DSM Directive art. 3 i 4 (szersze prawa TDM z zastrzeżeniem praw) |
| Prawa do baz danych | Tak (zachowane z EU Database Directive) | Brak federalnego odpowiednika | Sui generis prawo na mocy Database Directive |
| Egzekwowalność ToS | Obowiązuje prawo umów; browsewrap jest dyskutowany | Mieszana: browsewrap często niewykonalny | Zależna od kraju; Ryanair wzmocnił pozycję ToS |
Praktyczny wniosek: jeśli scrapujesz w wielu jurysdykcjach, przestrzegaj najsurowszego obowiązującego prawa. USA są bardziej liberalne wobec dostępu do danych publicznych na gruncie hiQ, ale hiQ nie jest blankietową zgodą na wszystko (hiQ ostatecznie nie mógł scrapować LinkedIn i zapłacił 500 tys. $). UE ma szerszą architekturę TDM dzięki DSM Directive. Wielka Brytania plasuje się gdzieś pośrodku — bez szerokiego komercyjnego wyjątku TDM, z silnymi prawami do baz danych i aktywnym regulatorem.
Kary i egzekwowanie: co naprawdę się dzieje, jeśli zostaniesz przyłapany
Mgliste ostrzeżenia o „grzywnach” i „kłopotach prawnych” nikomu nie pomagają. Oto konkretne liczby.
Grzywny na gruncie UK GDPR
Maksymalna kara: 17,5 mln £ albo 4% rocznego globalnego obrotu, w zależności od tego, która wartość jest wyższa.
Rzeczywisty przykład: Clearview AI została ukarana przez ICO kwotą 7 552 800 £ w 2022 roku za zeskrobywanie zdjęć twarzy z brytyjskich mediów społecznościowych. First-tier Tribunal uchylił decyzję ze względów jurysdykcyjnych, ale Upper Tribunal w październiku 2025 dopuścił apelację ICO i odesłał sprawę do ponownego rozpoznania. ICO poinformowało, że Clearview miało zgodę na odwołanie do Court of Appeal na grudzień 2025.
Karne sankcje na gruncie Computer Misuse Act
- Sekcja 1 (nieuprawniony dostęp): do 2 lat więzienia
- Sekcja 3 (nieuprawnione zakłócenie): do 10 lat więzienia
Ściganie karne za zwykły scraping publicznych stron jest niezwykle rzadkie.
Profil ryzyka zmienia się gwałtownie, gdy działanie przypomina hakowanie, nadużycie poświadczeń, obejście CAPTCHA albo zakłócenie usługi.
Prawo autorskie i prawa do baz danych
Odszkodowanie cywilne plus nakaz sądowy. Możliwe są także sankcje karne za umyślne naruszenie w celach komercyjnych, ale większość sporów dotyczących scrapingu toczy się jako sprawy cywilne.
Naruszenie umowy (ToS)
Odszkodowanie cywilne, zamknięcie konta, blokada IP. To zwykle najczęstsza praktyczna forma egzekwowania — i często pierwsza rzecz, która się dzieje.
Podsumowanie dotkliwości kar
| Ramy prawne | Maksymalna kara | Prawdopodobieństwo przy typowym biznesowym scrapingu | Przykład z życia |
|---|---|---|---|
| UK GDPR | 17,5 mln £ lub 4% globalnego obrotu | Średnie, jeśli dane osobowe są zbierane na dużą skalę; niskie dla danych nieosobowych | Kara 7,5 mln £ dla Clearview AI |
| CMA sekcja 1 | 2 lata więzienia | Niskie przy stronach publicznych; wyższe przy obchodzeniu zabezpieczeń | Wytyczne CPS dotyczące nieuprawnionego dostępu |
| CMA sekcja 3 | 10 lat więzienia | Niskie, chyba że ruch zakłóca systemy | Przykłady zakłóceń w stylu DDoS |
| Prawo autorskie / prawa do baz danych | Odszkodowanie i nakaz sądowy | Średnie przy kopiowaniu chronionych treści lub kuratorskich baz danych | Linie spraw Ryanair i BHB |
| Naruszenie ToS | Odszkodowanie, zamknięcie konta, blokada | Wysokie jako praktyczna ścieżka egzekwowania | Spory o screen scraping z Ryanair |
Jak odpowiednie narzędzie do scrapingu zmniejsza ryzyko prawne
Wybranie właściwego narzędzia nie czyni nielegalnego scrapingu legalnym. Może jednak wyeliminować ryzyko, którego da się uniknąć.
Z mojego doświadczenia wynika, że różnica między narzędziem, które szanuje sygnały strony, a takim, które agresywnie wszystko omija, często decyduje o tym, czy mamy zwykły projekt danych, czy prawny ból głowy.
Respektowanie robots.txt i sygnałów strony
Odpowiedzialne narzędzie powinno ułatwiać sprawdzenie i respektowanie robots.txt przed scrapowaniem. Choć nie jest to prawnie wiążące, zgodność z robots.txt sądy i ICO traktują jako dowód dobrej wiary. Dokumentacja Thunderbit zaleca użytkownikom zeskrobywanie publicznie dostępnych danych oraz przestrzeganie robots.txt i warunków korzystania.
Scrapowanie w przeglądarce vs. w chmurze
To rozróżnienie ma znaczenie prawne. Scraping w przeglądarce pobiera tylko to, co użytkownik widzi w swojej uwierzytelnionej sesji — w praktyce automatyzuje to, co zrobiłbyś ręcznie. Scraping w chmurze wysyła żądania z serwerów, co jest szybsze dla publicznych stron, ale z perspektywy strony może wyglądać bardziej jak „automatyczny dostęp”.
Thunderbit oferuje oba tryby. Scraping w przeglądarce sprawdza się przy stronach wymagających logowania (zmniejszając ryzyko „nieuprawnionego dostępu” na gruncie CMA), a scraping w chmurze dobrze działa przy publicznie dostępnych stronach e-commerce, gdzie liczy się szybkość. To podejście dualne pozwala dopasować metodę scrapingu do profilu ryzyka prawnego konkretnej strony.
Brak omijania kontroli dostępu
Narzędzie, które działa wewnątrz przeglądarki i nie łamie CAPTCHA ani nie omija ekranów logowania, jest z natury mniej ryzykowne na gruncie Computer Misuse Act. Rozszerzenie Thunderbit do Chrome działa w sesji przeglądarki użytkownika — uzyskuje dostęp tylko do tego, co użytkownik już widzi.
Przejrzysty eksport danych (wsparcie zgodności z GDPR)
Thunderbit eksportuje dane bezpośrednio do Excel, Google Sheets, Airtable lub Notion. Użytkownik kontroluje, dokąd trafiają dane. Wspiera to przejrzystość wymaganą przez GDPR i dokumentowanie podstawy prawnej: dokładnie wiesz, jakie dane zebrałeś i gdzie trafiły. Brak ukrytego przetwarzania czy zatrzymywania danych przez narzędzie.
Limitowanie tempa i odpowiedzialny dostęp
Zbyt duży ruch może uruchomić sekcję 3 CMA (nieuprawnione zakłócenie). Limitowanie tempa to nie tylko dobra praktyka techniczna — to także zabezpieczenie prawne. Odpowiedzialne narzędzia nie przeciążają serwerów, co zmniejsza zarówno ryzyko prawne, jak i szansę na zablokowanie IP.

Praktyczna lista zgodności dla web scrapingu w Wielkiej Brytanii
Przejdź przez nią, zanim zeskrobiesz cokolwiek:
- Przeczytaj regulamin i politykę akceptowalnego użycia docelowej strony.
- Sprawdź plik robots.txt i udokumentuj, czy istotne ścieżki są zabronione.
- Ustal, czy dane, które chcesz zebrać, są danymi osobowymi. Jeśli tak, wskaż podstawę prawną na gruncie UK GDPR.
- Oceń, czy wyodrębniasz „istotną część” bazy danych.
- Upewnij się, że nie omijasz żadnych technicznych kontroli dostępu (CAPTCHA, logowanie, limity zapytań).
- Jeśli Twój cel jest niekomercyjny i badawczy, udokumentuj to, aby korzystać z wyjątku TDM.
- Stosuj limitowanie tempa. Nie przeciążaj serwera docelowego.
- Dokumentuj wszystko: podstawę prawną, przegląd ToS, zebrane pola danych, miejsca eksportu, okres retencji.
- Jeśli masz wątpliwości, skonsultuj się z prawnikiem specjalizującym się w ochronie danych i IP.
Ta lista nie zastępuje opinii prawnika — ale daje solidny punkt wyjścia i pokazuje dobrą wiarę, jeśli kiedykolwiek pojawią się pytania.
Najważniejsze wnioski
- Web scraping nie jest w Wielkiej Brytanii nielegalny — ale podlega czterem nakładającym się ramom prawnym: UK GDPR, prawu autorskiemu / prawom do baz danych, prawu umów i Computer Misuse Act.
- Legalność każdego scrapingu zależy od tego, co zeskrobujesz, jak uzyskujesz dostęp, co mówi regulamin strony i co robisz z danymi.
- Scraping danych osobowych wiąże się z najwyższym obciążeniem zgodności. Uzasadniony interes jest zwykle jedyną realną podstawą prawną i wymaga udokumentowanego testu wyważenia interesów.
- Wielka Brytania nie ma szerokiego komercyjnego wyjątku TDM. Komercyjne trenowanie AI i odsprzedaż zbiorów danych wiążą się z wysokim ryzykiem bez licencji.
- Przed rozpoczęciem użyj powyższego schematu decyzyjnego i tabeli scenariuszy, aby ocenić swoją sytuację.
- Wybieraj narzędzia zgodne z dobrymi praktykami compliance: dostęp z przeglądarki, brak omijania CAPTCHA, przejrzysty eksport danych i limitowanie tempa. Thunderbit został zaprojektowany z myślą o tych zasadach — ale odpowiedzialność za zgodność zawsze spoczywa na użytkowniku.
- Jeśli masz wątpliwości, udokumentuj swoje rozumowanie i porozmawiaj z prawnikiem. Koszt opinii prawnej jest prawie zawsze niższy niż koszt postępowania ICO.
Wypróbuj AI Web Scraper z Thunderbit Get Started Free
FAQ
Czy legalne jest zeskrobywanie publicznie dostępnych danych w Wielkiej Brytanii?
Zasadniczo tak — zeskrobywanie danych publicznych wiąże się z mniejszym ryzykiem niż scrapowanie danych chronionych logowaniem lub prywatnych. Ale „publicznie dostępne” nie znaczy „możesz używać tego, jak chcesz”. UK GDPR może nadal mieć zastosowanie do publicznych danych osobowych, prawo autorskie może dotyczyć skopiowanej ekspresji, prawa do baz danych mogą chronić kuratorskie zbiory, a ToS mogą ograniczać automatyczny dostęp.
Czy mogę zeskrobywać e-maile i numery telefonów z brytyjskich stron?
Jeśli dane są danymi osobowymi (a e-maile i numery telefonów zazwyczaj są), potrzebujesz podstawy prawnej na gruncie UK GDPR. Uzasadniony interes jest najczęstszą podstawą przy lead generation B2B, ale musisz przeprowadzić test wyważenia interesów, ograniczyć zbierane dane i zapewnić możliwość rezygnacji. Zeskrobywanie prywatnych danych kontaktowych (numery komórkowe, prywatne e-maile) jest znacznie bardziej ryzykowne niż dane z katalogów firm.
Jaka jest różnica między web scrapingiem a web crawlingiem w prawie brytyjskim?
Prawnie nie ma istotnej różnicy — prawo interesuje się działaniem, a nie etykietą. Crawling zwykle oznacza odkrywanie lub indeksowanie stron, a scraping — wyodrębnianie ustrukturyzowanych danych. Oba polegają na automatycznym dostępie do witryn i podlegają tym samym ramom prawnym.
Czy robots.txt sprawia, że scraping jest nielegalny?
Nie. robots.txt nie jest prawnie wiążący. Ignorowanie go zwiększa jednak ryzyko prawne, ponieważ sądy i ICO traktują go jako dowód intencji właściciela strony. Jeśli zignorujesz robots.txt, a regulamin strony również zakazuje scrapingu, dokładasz sobie kolejne czynniki ryzyka — a to znacznie trudniejsza pozycja do obrony.
Czy za web scraping mogę zostać ukarany karnie w Wielkiej Brytanii?
Tylko jeśli ominiesz kontrolę dostępu (CAPTCHA, logowanie, blokady IP) albo spowodujesz szkody w systemie komputerowym na gruncie Computer Misuse Act 1990. Zwykły scraping rzeczywiście publicznych danych, w rozsądnej skali, bez technicznego obchodzenia zabezpieczeń, niezwykle rzadko kończy się zarzutami karnymi. Profil ryzyka radykalnie się zmienia, gdy działanie przypomina hakowanie albo celowe zakłócanie usługi.
Dowiedz się więcej




