

Świat pędzi do przodu — internet też nie zwalnia. Przez lata pracy przy SaaS i automatyzacji zauważyłem jedną uniwersalną prawdę: czasem najszybciej wyprzedzasz innych, kiedy umiesz mądrze uczyć się z tego, co już działa. Niezależnie od tego, czy robisz research konkurencji, budujesz nowy produkt, czy po prostu potrzebujesz kopii zapasowej własnej witryny, możliwość sklonowania dowolnej strony — czyli przechwycenia jej treści, struktury, a czasem nawet elementów działania — potrafi mocno przyspieszyć robotę w zespołach biznesowych. A dzięki rozwojowi narzędzi opartych o AI, takich jak Thunderbit, to, co kiedyś było „sekretną bronią” devów, dziś jest dostępne dla każdego, kto ogarnia przeglądarkę.
Bądźmy jednak szczerzy: klonowanie strony to nie jest jedno kliknięcie „Zapisz jako” i temat zamknięty. Współczesne serwisy są dynamiczne, interaktywne i potrafią wymknąć się prostym metodom jak mydło z rąk. W tym poradniku pokażę, co w praktyce znaczy „sklonuj dowolną stronę”, dlaczego to ważne dla użytkowników biznesowych, na jakie przeszkody trafisz oraz — co najważniejsze — jak zrobić to bezpiecznie, sprawnie i legalnie, korzystając z zaawansowanych rozwiązań takich jak Thunderbit.
Sklonuj dowolną stronę: co to właściwie znaczy?
Zacznijmy od fundamentów. Kiedy ktoś mówi o „klonowaniu strony”, może mieć na myśli kilka różnych rzeczy:
- Klonowanie wyglądu: zrobienie witryny, która wygląda i „czuje się” jak oryginał.
- Klonowanie treści: skopiowanie tekstów, obrazów, informacji o produktach i innych widocznych danych.
- Klonowanie funkcjonalności: odtworzenie elementów typu wyszukiwarka, formularze czy interaktywne komponenty.
Dla większości zespołów biznesowych największą wartość ma skopiowanie widocznej treści i danych — tego, co da się zobaczyć i przeanalizować — a niekoniecznie kodu backendu czy zastrzeżonej logiki. Pomyśl o tym jak o zrobieniu „zrzutu” publicznej warstwy strony i zamianie go w uporządkowany zestaw danych do analizy, prototypowania albo archiwizacji.
I zanim padnie pytanie: nie, klonowanie nie musi oznaczać kradzieży czy plagiatu. Wiele zastosowań jest w pełni uzasadnionych — np. research konkurencji, szybkie prototypowanie czy tworzenie archiwum offline na potrzeby zgodności. Chodzi o to, by oszczędzać czas i wyciągać wnioski z tego, co działa, a nie „podkradać” czyjąś pracę.
Po co klonować dowolną stronę? Najważniejsze zastosowania biznesowe
Może Cię zaskoczyć, jak wiele zespołów korzysta z klonowania witryn w codziennej pracy. Oto kilka najczęstszych scenariuszy:
| Zastosowanie | Opis i korzyść biznesowa |
|---|---|
| Monitorowanie cen konkurencji | Zbieranie danych z kart produktów konkurencji, aby śledzić ceny i stany magazynowe. Umożliwia dynamiczne ustalanie cen — jeden brytyjski detalista odnotował wzrost sprzedaży o 4%. |
| Generowanie leadów i wzbogacanie CRM | Klonowanie katalogów lub stron LinkedIn w celu pozyskania leadów. Automatyzacja może zaoszczędzić nawet 80% czasu. |
| Ponowne wykorzystanie treści | Duplikowanie FAQ, wpisów blogowych lub opinii, aby wyłuskać insighty albo przygotować informacje dla własnej grupy odbiorców. |
| Szybkie prototypowanie i design | Skopiowanie front-endu istniejących stron, by szybciej startować z nowymi projektami — prototyp w dni zamiast tygodni. |
| Kopie zapasowe i archiwizacja | Tworzenie pełnych kopii stron na potrzeby zgodności lub dokumentacji. |
To dopiero czubek góry lodowej. Badacze potrafią klonować strony w social media, żeby analizować trendy, specjaliści SEO kopiują struktury serwisów do analizy offline, a niemal 2 700 porównywarek cen działa w oparciu o dane pozyskane z sieci. Zwrot z inwestycji bierze się z szybkości i wglądu — zamiast ręcznie zbierać dane lub odtwarzać elementy, dostajesz „pakiet” w jednym podejściu.
Wyzwania klonowania stron: to coś więcej niż kopiuj-wklej
Gdyby klonowanie strony sprowadzało się do „Kopiuj > Wklej”, wszyscy robiliby to bez przerwy. Rzeczywistość jest jednak bardziej złożona.
Dlaczego proste kopiowanie nie wystarcza
- Treści dynamiczne: wiele stron ładuje dane przez JavaScript, więc zwykłe „Zapisz stronę jako” może zostawić Ci sam szkielet — bez obrazów i danych, z rozbitą strukturą (zobacz ten eksperyment).
- API i skrypty: część treści jest pobierana z API dopiero po załadowaniu strony. Skopiowanie HTML tego nie przechwyci.
- Wymagane logowanie: jeśli potrzebne informacje są za loginem, potrzebujesz narzędzia, które działa w sesji uwierzytelnionej.
- Zabezpieczenia anty-scrapingowe: CAPTCHA, limity zapytań czy wykrywanie botów potrafią blokować automatyczne pobieranie.
- Granice prawne i etyczne: to, że da się coś skopiować, nie znaczy, że należy. Licencje, prawa autorskie i regulaminy mają znaczenie — i to duże.
W skrócie: klonowanie strony to jednocześnie omijanie przeszkód technicznych i trzymanie się zasad odpowiedzialnego pozyskiwania danych. Liczy się nie tylko „mieć dane”, ale mieć je poprawnie — i pozyskać je w porządny sposób.
Porównanie rozwiązań do klonowania stron: od ręcznych metod po narzędzia AI
Przejdźmy do konkretów. Jest kilka głównych podejść do klonowania witryn — każde ma swoje plusy i minusy:
| Metoda | Łatwość użycia | Dokładność | Treści dynamiczne | Opcje eksportu | Zgodność prawna | Utrzymanie |
|---|---|---|---|---|---|---|
| Ręczne kopiowanie/pobieranie | Średnia | Niska | Słaba | HTML/CSS/JS | Zależy od użytkownika | Wysokie (łatwo się psuje) |
| Tradycyjny web scraping | Niska | Wysoka* | Dobra* | CSV/Excel/JSON | Zależy od użytkownika | Wysokie (kruche) |
| Narzędzia oparte o AI (Thunderbit) | Bardzo wysoka | Wysoka | Świetna | Excel/Sheets/Notion | Przyjazna dla użytkownika | Niskie |
*Jeśli wiesz, co robisz i dobrze to skonfigurujesz.
Ręczne kopiowanie/pobieranie
Narzędzia typu HTTrack albo przeglądarkowe „Zapisz stronę jako” potrafią zadziałać dla prostych, statycznych witryn, ale są czasochłonne i polegną na dynamicznych elementach. Często kończy się to brakującymi obrazami, rozjechanymi stylami i folderem plików, który bardziej przeszkadza niż pomaga.
Tradycyjny web scraping
To m.in. pisanie skryptów (Python, BeautifulSoup itd.) albo używanie wizualnych scraperów, gdzie klikasz elementy do wyciągnięcia. Bardzo mocne podejście, ale wymaga kodowania lub sporej konfiguracji. Utrzymanie bywa męczące — gdy strona się zmieni, scraper często przestaje działać.
Narzędzia oparte o AI (Thunderbit)
Tu robi się naprawdę ciekawie. Thunderbit wykorzystuje AI do „zrozumienia” strony, więc nie musisz ręcznie opisywać każdego szczegółu. Wystarczy kliknąć „AI Suggest Fields”, pozwolić narzędziu automatycznie wykryć dane i można działać. Thunderbit ogarnia treści dynamiczne, nawigację po wielu stronach i eksportuje dane bezpośrednio do Excel, Google Sheets, Airtable lub Notion. Co ważne: jest zaprojektowany dla osób nietechnicznych — bez kodowania.
Jeśli chcesz porównać rozszerzenia Chrome do web scrapingu, zajrzyj do tego zestawienia.
Krok po kroku: jak sklonować dowolną stronę za pomocą Thunderbit
Jak zbierać dane z dowolnej strony za pomocą AI Get Started Free
Czas na praktykę. Tak właśnie robię klonowanie strony w Thunderbit — krok po kroku.
Krok 1: Instalacja i konfiguracja Thunderbit
Najpierw wejdź na stronę Thunderbit i załóż darmowe konto. Potem zainstaluj Thunderbit AI Web Scraper Chrome Extension. To jest tak proste jak dodanie dowolnego rozszerzenia — dosłownie parę kliknięć.
Po instalacji zobaczysz ikonę Thunderbit na pasku narzędzi Chrome. Kliknij, zaloguj się i możesz odpalać pierwszy projekt. Pro tip: przypnij ikonę rozszerzenia, żeby zawsze była pod ręką. Jeśli robisz web scraping na stronie wymagającej logowania, zaloguj się na niej przed startem — Thunderbit korzysta z bieżącej sesji przeglądarki.
Wypróbuj Thunderbit AI Web Scraper za darmo
Krok 2: Wykrywanie i porządkowanie danych przez AI
Wejdź na stronę, którą chcesz sklonować (np. kartę produktu konkurencji). Otwórz panel boczny Thunderbit i rozpocznij nowy projekt. I tu dzieje się magia: kliknij „AI Suggest Columns” (czasem „AI Suggest Fields”), a AI Thunderbit przeskanuje stronę i automatycznie zaproponuje pola danych — np. Nazwa produktu, Cena, URL obrazka, Ocena i inne.
Możesz je przejrzeć, poprawić albo dorzucić własne kolumny. Chcesz dodatkowe pole, np. „Dostępność” albo „Numer SKU”? Dodaj je, a AI spróbuje je uzupełnić. Bez grzebania w HTML — AI robi czarną robotę.
Krok 3: Zbieranie i eksport danych ze strony
Gdy kolumny są gotowe, kliknij „Scrape” (lub „Start”). Thunderbit wyciągnie dane dla wybranych pól, wiersz po wierszu. Jeśli na stronie jest wiele elementów (np. lista produktów), pobierze je wszystkie.
A co z paginacją albo infinite scroll? Thunderbit ogarnia większość przypadków automatycznie — jeśli jest przycisk „Next” albo wzorzec ładowania przy przewijaniu, będzie kontynuować. W trudniejszych sytuacjach może być potrzebne ręczne przewinięcie lub ustawienia zaawansowane, ale dla większości stron biznesowych działa to bardzo płynnie.
Po zakończeniu zobaczysz dane w czytelnej tabeli. Eksport jest banalny: bezpośrednio do Excel, Google Sheets, Airtable lub Notion. Koniec z „gimnastyką CSV” — masz uporządkowane dane gotowe do użycia.
Więcej szczegółów znajdziesz w poradniku Thunderbit o scrapowaniu dowolnej strony z użyciem AI.
Pełniejsza kopia: scrapowanie podstron dla kompletnego „klonu”
Scrapowanie podstron w Thunderbit Get Started Free
Tu Thunderbit naprawdę błyszczy: scrapowanie podstron. Wiele serwisów pokazuje na stronie głównej tylko skróty (np. nazwy i ceny), a najcenniejsze informacje — opisy, specyfikacje, opinie — siedzą na podstronach.
Funkcja scrapowania podstron pozwala zejść poziom głębiej. Włącz ją, a AI będzie podążać za linkami z listy do stron szczegółów, pobierze dodatkowe dane i scali je z głównym zestawem. Przykład: klonujesz kategorię „kurtki zimowe” w e-commerce — Thunderbit może wejść w każdą kartę produktu i pobrać materiały, dostępność, opinie klientów i inne szczegóły, tworząc kompletną, uporządkowaną kopię całej oferty.
To ogromna oszczędność czasu. Niezależnie od tego, czy budujesz pełną listę leadów, archiwizujesz bazę wiedzy, czy analizujesz cały katalog produktów — scrapowanie podstron sprawia, że nic Ci nie umknie.
Zobacz przykład w praktyce: scrapowanie podstron w Thunderbit.
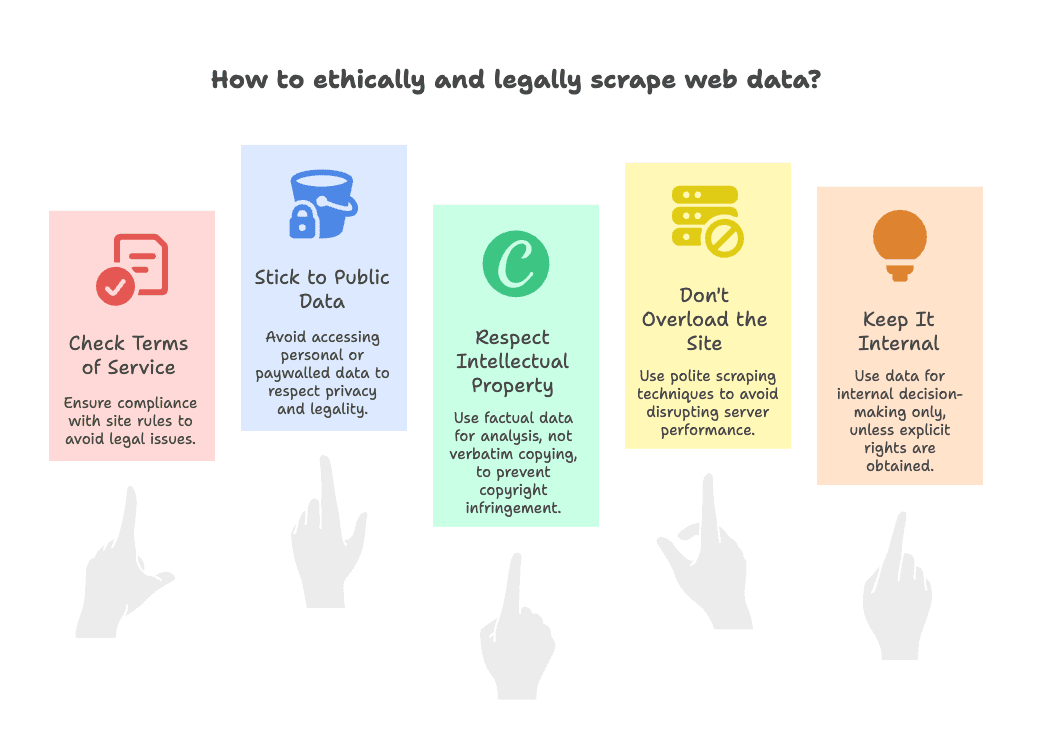
Zgodność i bezpieczeństwo: jak klonować strony legalnie
Porozmawiajmy o najważniejszym pytaniu: czy klonowanie dowolnej strony jest legalne?
W skrócie: zazwyczaj tak — o ile trzymasz się kilku zdroworozsądkowych zasad. Oto moja checklista zgodności:
- Sprawdź regulamin (Terms of Service): część serwisów wprost zabrania scrapowania. Jeśli tak jest, działaj ostrożnie — używaj danych wewnętrznie, nie do publicznej publikacji (więcej o ryzyku prawnym).
- Trzymaj się danych publicznych: pobieraj tylko to, co widać bez logowania. Unikaj danych osobowych, e-maili i treści za paywallem (wytyczne prawne).
- Szanuj własność intelektualną: dane faktograficzne (ceny, nazwy produktów) zwykle są OK. Kopiowanie kreatywnych treści 1:1 (np. artykułów czy zdjęć) może naruszać prawa autorskie — używaj do analizy, nie do budowy „klona” serwisu (więcej o IP).
- Nie przeciążaj serwisu: scrapuj „grzecznie” — nie wysyłaj tysięcy zapytań w kilka sekund. Thunderbit ma wbudowane limity, ale zawsze warto zachować umiar (robots.txt).
- Używaj wewnętrznie: jeśli nie masz wyraźnych praw, wykorzystuj sklonowane dane do decyzji wewnętrznych, a nie do publicznej redystrybucji.
Thunderbit ułatwia zgodność m.in. dzięki temu, że możesz eksportować dane bezpośrednio do bezpiecznych narzędzi, takich jak Google Sheets czy Airtable, i udostępniać je w ramach organizacji. Więcej wskazówek prawnych znajdziesz w tym kompleksowym poradniku.
Zaawansowane wskazówki: jak wycisnąć maksimum z Thunderbit przy klonowaniu stron
Gdy opanujesz podstawy, te triki pomogą Ci wejść poziom wyżej:
- Strony dynamiczne i interaktywne: jeśli treść pojawia się dopiero po kliknięciu (np. „Pokaż wszystkie opinie”), zrób to ręcznie, a dopiero potem uruchom Thunderbit — AI przechwyci to, co jest widoczne. Przy infinite scroll przewijaj partiami lub użyj obsługi paginacji (więcej wskazówek).
- Własne prompty dla AI: prowadź AI precyzyjnymi nazwami kolumn, np. „Autor (tekst po By:)” albo „Podsumowanie zalet”. AI Thunderbit łapie kontekst, więc jasne nazwy działają jak mini-instrukcje (przykłady).
- AI do transformacji danych: użyj funkcji AI Summarize w Thunderbit lub połącz dane z narzędziami typu ChatGPT, aby na bieżąco analizować, kategoryzować lub tłumaczyć informacje (pomysły na integracje).
- Harmonogram dla cyklicznych „klonów”: ustaw zaplanowane scrapowanie, by monitorować zmiany w czasie — idealne do śledzenia cen konkurencji lub nowych ofert pracy (scraping w chmurze).
- Scrapowanie listy URL-i: wklej listę adresów, a Thunderbit pobierze dane z każdego automatycznie — świetne, gdy linki masz już zebrane gdzie indziej.
- Szablony dla popularnych serwisów: skorzystaj z gotowych szablonów Thunderbit dla stron takich jak Amazon czy Zillow, a potem dopasuj je do potrzeb (szczegóły szablonów).
- Trudne przypadki: jeśli trafisz na CAPTCHA lub nietypowy układ, spróbuj zebrać dane w dwóch przebiegach albo dopracuj kolumny. AI Thunderbit jest odporne, ale szybka kontrola jakości zawsze się opłaca.
Jeśli interesują Cię bardziej zaawansowane scenariusze, zobacz API i opcje integracji Thunderbit.
Sklonuj dowolną stronę z Thunderbit AI
Podsumowanie: klonuj dowolną stronę z pewnością
Klonowanie stron nie jest już zarezerwowane dla programistów — to praktyczna i dostępna technika, która wspiera zespoły sprzedaży, marketingu i operacji. Najważniejsze wnioski:
- Wartość biznesowa: klonowanie witryn daje realny zwrot — pomaga wyprzedzać konkurencję, oszczędzać czas i podejmować lepsze decyzje (statystyki branżowe).
- Wyzwania i rozwiązania: nowoczesne strony są złożone, ale narzędzia takie jak Thunderbit sprawiają, że klonowanie jest dokładne, szybkie i proste — nawet bez zaplecza technicznego.
- Przewaga Thunderbit: funkcje „AI Suggest Columns” i scrapowanie podstron zamieniają godziny ręcznej pracy w proces na dwa kliknięcia.
- Zgodność ma znaczenie: klonuj odpowiedzialnie — trzymaj się danych publicznych, szanuj IP i wykorzystuj dane do analizy lub decyzji wewnętrznych.
- Idź dalej: dzięki wskazówkom i integracjom Thunderbit poradzi sobie nawet z trudnymi stronami i procesami.
Następnym razem, gdy będziesz patrzeć na kartę produktu konkurencji, katalog leadów albo bazę wiedzy, którą chcesz przeanalizować — pamiętaj, że masz narzędzia, by sklonować dane ze strony z pełnym spokojem. Korzystaj z nich mądrze, a Twoje projekty oparte na danych będą rosnąć.
Wypróbuj Thunderbit AI Web Scraper teraz Get Started Free
FAQ
1. Czy klonowanie dowolnej strony do celów biznesowych jest legalne?
Zazwyczaj tak — jeśli ograniczasz się do danych publicznych, szanujesz własność intelektualną i używasz danych wewnętrznie. Zawsze sprawdzaj regulamin serwisu i unikaj pobierania danych osobowych lub treści chronionych prawem autorskim bez zgody. Więcej: ten poradnik prawny.
2. Jaka jest różnica między klonowaniem strony a scrapowaniem?
Klonowanie strony zwykle oznacza wykonanie kopii treści, struktury lub wyglądu, a web scraping to proces wyciągania konkretnych danych ze strony. Przy narzędziach takich jak Thunderbit granica się zaciera — możesz pobrać i uporządkować dane tak, by w praktyce „sklonować” potrzebne elementy.
3. Czy Thunderbit obsługuje treści dynamiczne i podstrony?
Tak. AI Thunderbit jest przygotowane do pracy z treściami dynamicznymi (np. danymi ładowanymi przez JavaScript) i potrafi podążać za linkami, by scrapować podstrony, a następnie scalać wszystko w jeden zestaw danych. To jeden z najprostszych sposobów na uzyskanie kompletnej kopii danych ze strony.
4. Jak wyeksportować sklonowane dane do Excel lub Google Sheets?
Po zebraniu danych w Thunderbit możesz wyeksportować je bezpośrednio do Excel, Google Sheets, Airtable lub Notion — w kilka kliknięć. Bez ręcznego formatowania: dane są gotowe do analizy i udostępniania.
5. Jakie są zaawansowane wskazówki dla trudnych stron?
Stosuj własne prompty AI, aby precyzyjnie wyciągać pola, ustaw harmonogramy do stałego monitoringu oraz korzystaj z funkcji masowego scrapowania URL-i i szablonów dla większej wydajności. W serwisach interaktywnych wykonaj akcje ręcznie przed scrapowaniem i zawsze sprawdzaj dane pod kątem poprawności.




