Of je nu in sales, operations of een andere zakelijke functie zit, je hebt vast gemerkt dat het internet in 2026 een bron van kansen én tijdverspilling is. Er is meer waardevolle info dan ooit – denk aan leads, prijzen, reviews, concurrenten – maar die data netjes in een spreadsheet of dashboard krijgen? Dat blijft vaak een gedoe. Ik heb teams uren zien zwoegen met kopiëren en plakken, wat meestal eindigt in rommelige, verouderde data en een flinke portie spreadsheet-moeheid.

Gelukkig hoeft data scrapen van andere websites geen klus meer te zijn voor alleen developers of dataspecialisten. Dankzij AI-gedreven no-code tools zoals kan iedereen – ook zonder technische kennis – snel en nauwkeurig de juiste data verzamelen, zonder gedoe. In deze gids leg ik uit wat webscraping precies inhoudt, waarom het onmisbaar is voor moderne bedrijven en hoe je in 2026 efficiënt (en legaal) inhoud van websites kunt scrapen. Of je nu een beginner bent of je workflow wilt verbeteren, je bent hier aan het juiste adres.
Wat is "Inhoud Scrapen van Andere Websites"?
Laten we het simpel houden: inhoud scrapen van andere websites betekent dat je software gebruikt om automatisch info van webpagina’s te halen en die netjes in een gestructureerd formaat zet – bijvoorbeeld tabellen, spreadsheets of databases. In plaats van handmatig productdetails, contactgegevens of reviews te kopiëren, doet een webscraper dit werk voor jou ().
Zie het zo: stel je zit in een bibliotheek en in plaats van zelf aantekeningen te maken, heb je een robot die de boeken voor je scant en een overzichtelijke samenvatting geeft. Dat is wat webscraping doet voor het internet.
Waarom scrapen mensen inhoud van websites?
- Leadgeneratie: Namen, e-mails en telefoonnummers verzamelen uit bedrijvengidsen of zakelijke platforms.
- Concurrentieanalyse: Prijzen, productlanceringen of reviews volgen op webshops.
- Marktonderzoek: Nieuws, blogs of discussies verzamelen om trends te ontdekken.
- Content aggregatie: Artikelen of bronnen verzamelen voor nieuwsbrieven of interne kennisbanken.
Het verschil tussen handmatig kopiëren en automatisch scrapen is enorm: scrapen is sneller, nauwkeuriger en kan duizenden pagina’s in een paar minuten verwerken ().
Waarom Inhoud Scrapen van Andere Websites Belangrijk Is voor Bedrijven
Als je nog steeds vertrouwt op handmatig onderzoek, mis je de snelheid en inzichten waarmee moderne teams het verschil maken. Data-gedreven bedrijven , en in 2026 zal volledig data-gedreven zijn.
Zo levert inhoud scrapen van andere websites direct waarde op voor je bedrijf:
| Toepassing | Wat te scrapen | Voordeel |
|---|---|---|
| Leadgeneratie | Bedrijvengidsen, LinkedIn, Gele Gids | Gericht prospectlijsten opbouwen, sneller je pipeline vullen |
| Prijsmonitoring | Productlijsten van concurrenten, webshops | Je prijsstrategie direct aanpassen |
| Klantinzichten | Reviews, social media posts, forums | Feedback analyseren, trends ontdekken, producten verbeteren |
| Content aggregatie | Nieuwssites, blogs, branchefora | Branche-informatie verzamelen, contentmarketing versterken |
Door deze taken te automatiseren, bespaar je niet alleen tijd, maar neem je ook betere en snellere beslissingen en kan je team zich richten op wat echt belangrijk is ().
Hoe Kies Je de Juiste Webscraper: Een Startersgids
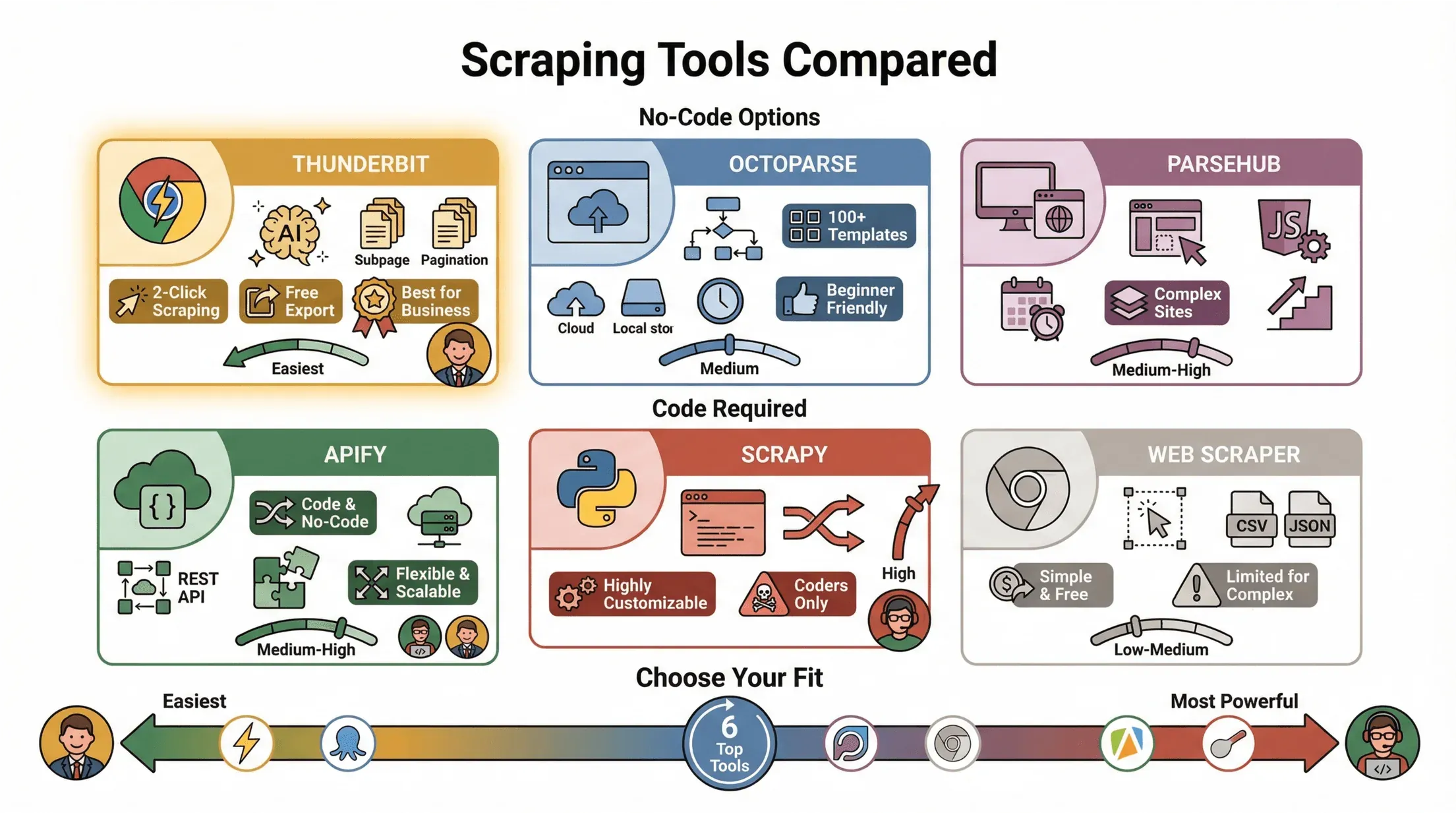
Als je nieuw bent met inhoud scrapen van andere websites, is de eerste stap het kiezen van de juiste tool. Mijn ervaring (soms met vallen en opstaan): je keuze hangt af van je technische kennis, de complexiteit van de websites en hoe snel je resultaat wilt.
Belangrijkste soorten webscraping tools:
- Code-gebaseerde tools (zoals Python met BeautifulSoup of Scrapy): Maximale flexibiliteit, maar je moet kunnen programmeren. Ideaal voor developers of teams met IT-ondersteuning.
- No-code tools (zoals ParseHub, Octoparse): Visuele interfaces, sjablonen en klik-en-sleep workflows. Perfect voor niet-programmeurs, maar kan lastig zijn bij complexe sites.
- Browserextensies (zoals Thunderbit, Webscraper): Direct in Chrome, makkelijk te installeren en ideaal voor snelle, gerichte scrapes.
Voor de meeste zakelijke gebruikers – zeker beginners – is gebruiksgemak het belangrijkst. Daarom raad ik aan te starten met een browserextensie zoals . Deze is speciaal ontwikkeld voor niet-technische gebruikers en maakt dankzij AI het instellen super eenvoudig.
Vergelijking van Populaire Webscraping Tools
Zo scoren de bekendste tools voor het scrapen van inhoud van andere websites:
| Tool | Type | Belangrijkste functies | Voordelen / Nadelen |
|---|---|---|---|
| Thunderbit | Chrome-extensie, AI | 2-kliks scraping, AI veldsuggesties, subpagina’s & paginering, gratis export | Super eenvoudig, geen code, ideaal voor zakelijke gebruikers |
| Octoparse | Desktop-app, no-code | Visuele workflow, 100+ sjablonen, cloud/lokaal, plannen | Gebruiksvriendelijk, gratis versie is beperkt |
| ParseHub | Desktop/Web, no-code | Visuele builder, werkt met dynamische/JS-pagina’s, plannen | Goed voor complexe sites, iets steilere leercurve |
| Apify | Cloud/Code/No-code | Code & no-code, serverless, REST API, integraties | Flexibel, schaalbaar, enige technische kennis vereist |
| Scrapy | Python-bibliotheek, code | Asynchrone crawling, zeer aanpasbaar | Krachtig, maar alleen voor programmeurs |
| Webscraper | Chrome-extensie, no-code | Visuele selectie, export naar CSV/JSON | Simpel, gratis, beperkt bij complexe sites |
Voor de meeste zakelijke gebruikers zijn Thunderbit en Octoparse het makkelijkst om mee te starten ().
De Unieke Voordelen van Thunderbit voor Inhoud Scrapen
Even een kleine Thunderbit-pet op (of eigenlijk een digitale hoodie): wat onderscheidt, is hoe toegankelijk het is voor beginners en zakelijke gebruikers.
Dit maakt Thunderbit uniek:
- Natuurlijke taalinterface: Beschrijf simpelweg wat je wilt (“Haal alle productreviews en beoordelingen van deze pagina”) en de AI van Thunderbit regelt de rest.
- AI Veldsuggesties & Verbeteringen: Thunderbit scant de pagina en stelt automatisch de beste kolommen voor – namen, prijzen, e-mails, noem maar op. Geen gedoe met selectors of code.
- 2-kliks workflow: Klik op “AI Suggest Fields” en daarna op “Scrape”. Zo simpel is het. Zelfs mijn moeder kan het (en die denkt nog steeds dat ‘de cloud’ gewoon slecht weer is).
- Subpagina’s en paginering: Thunderbit volgt automatisch links naar detailpagina’s (zoals individuele productreviews) en verwerkt meerdere pagina’s zonder extra werk.
- Direct exporteren: Stuur je data direct naar Excel, Google Sheets, Airtable of Notion – zonder extra stappen of kosten.
Voorbeeld: Stel je wilt productreviews van een webshop halen. Open de reviewpagina, klik op het Thunderbit-icoon, kies “AI Suggest Fields” en Thunderbit stelt kolommen voor als “Naam beoordelaar”, “Beoordeling” en “Reviewtekst”. Klik op “Scrape” en je bent klaar. Meer details nodig? Gebruik subpagina-scraping om alles binnen te halen.
Gebruikers geven vaak aan dat Thunderbit “lange pagina’s verrassend goed aankan” en “scrapen van dynamische sites super eenvoudig maakt” ().
Inhoud Scrapen van Complexe Websites: Paginering en Subpagina’s
Laten we eerlijk zijn: niet elke website maakt het makkelijk om data te verzamelen. Webshops, bedrijvengidsen en reviewplatforms gebruiken vaak paginering (meerdere pagina’s met lijsten) of geneste subpagina’s (zoals doorklikken naar elk product of bedrijf voor meer details).
Het probleem: Traditionele scrapers missen vaak data die verstopt zit achter “Volgende”-knoppen of op subpagina’s. Handmatig scrapen? Dan ben je dagen bezig.
De oplossing van Thunderbit: De AI herkent pagineringslinks of oneindig scrollen en blijft scrapen tot alles binnen is. Voor subpagina’s kan Thunderbit elke link in je tabel volgen (zoals elk product of bedrijf), extra velden ophalen en deze samenvoegen met je hoofddata.
Stappenplan: Multi-Page en Subpagina Inhoud Scrapen
Zo pak je een complexe site aan met Thunderbit:
- Open de hoofdpagina met de lijst (bijvoorbeeld een categoriepagina of bedrijvengids).
- Klik op het Thunderbit-icoon en kies “AI Suggest Fields”. Thunderbit stelt kolommen voor als “Productnaam”, “Prijs”, “Link”.
- Klik op “Scrape”. Thunderbit haalt alle items van de huidige pagina op – en volgt automatisch de paginering voor de rest.
- Meer details nodig? Klik op “Scrape Subpages”. Thunderbit bezoekt elke detailpagina en haalt extra info op (zoals reviews, specificaties of contactgegevens).
- Controleer en exporteer je complete, verrijkte dataset.
Tip: Gebruik subpagina-scraping als je links ziet naar “details”, “reviews” of “contact” – ideaal voor webshops, Gele Gids of vastgoedlijsten.
Gegevens Organiseren en Analyseren: Tags, Categorieën en Exportopties
Scrapen is pas de eerste stap. Om echt waarde te halen uit je data, moet je deze organiseren, analyseren en delen.
Thunderbit maakt dit eenvoudig:
- Tags en categorieën: Voeg tags of categorieën toe aan je velden (zoals “Producttype”, “Regio”, “Leadstatus”) zodat je later makkelijk kunt filteren en analyseren.
- AI Prompts per veld: Wil je SKU’s categoriseren of reviews vertalen? Voeg een aangepaste instructie toe aan het veld en Thunderbit’s AI regelt het tijdens het scrapen.
- Exportopties: Stuur je data direct naar Excel, Google Sheets, Airtable of Notion. Of download als CSV of JSON voor verdere analyse.
Best practices voor het organiseren van je data:
- Gebruik duidelijke, consistente kolomnamen.
- Voeg tags of categorieën toe voor eenvoudig filteren.
- Archiveer ruwe scrapes samen met opgeschoonde datasets.
- Stel regelmatige exports of geplande scrapes in voor doorlopende projecten.
Sales-teams kunnen leads labelen op bron of status, terwijl operations producten kunnen categoriseren op leverancier of regio. Het doel: maak je gescrapete data bruikbaar en makkelijk deelbaar.
Blijf Binnen de Regels: Juridische Overwegingen bij Inhoud Scrapen
Voordat je enthousiast aan de slag gaat, even over de regels. Goed nieuws: het scrapen van openbare data is meestal toegestaan als je je aan een paar simpele richtlijnen houdt (, ).
Belangrijkste tips voor compliance:
- Scrape alleen publiek toegankelijke inhoud. Omzeil geen logins, betaalmuren of beveiliging.
- Respecteer robots.txt en de gebruiksvoorwaarden. Niet altijd juridisch bindend, maar het geeft de voorkeuren van de site-eigenaar aan.
- Vermijd het scrapen van auteursrechtelijk beschermde of persoonlijke data. Beperk je tot feitelijke info (namen, prijzen, specificaties) en publiceer geen grote stukken tekst of afbeeldingen opnieuw.
- Vermeld je bronnen als je gescrapete data gebruikt in rapporten of publicaties.
- Beperk het aantal verzoeken om websites niet te overbelasten.
Checklist voor veilig scrapen:
- ✅ Alleen openbare pagina’s (geen logins)
- ✅ Check robots.txt en TOS
- ✅ Geen auteursrechtelijk beschermde of persoonlijke data
- ✅ Bronnen vermelden
- ✅ Niet te snel scrapen
Thunderbit stimuleert verantwoord scrapen door het makkelijk te maken alleen de data te selecteren die je nodig hebt en deze voor intern gebruik te exporteren.
Stappenplan: Inhoud Scrapen van Andere Websites met Thunderbit
Zelf aan de slag? Zo scrape je inhoud van andere websites met :
- Installeer de Thunderbit Chrome-extensie: en maak gratis een account aan.
- Open de gewenste website: Ga naar de pagina die je wilt scrapen (bijvoorbeeld productlijsten, bedrijvengids, reviewpagina).
- Klik op het Thunderbit-icoon: Open de extensie via je Chrome-werkbalk.
- Gebruik “AI Suggest Fields”: Thunderbit scant de pagina en stelt kolommen voor (zoals “Naam”, “Prijs”, “E-mail”).
- Pas kolommen aan indien nodig: Hernoem, voeg toe of verwijder velden naar wens. Je kunt ook AI-prompts toevoegen voor labeling of categorisatie.
- Klik op “Scrape”: Thunderbit haalt de data van de huidige pagina op – en volgt automatisch paginering als die er is.
- Subpagina’s scrapen (optioneel): Voor meer details klik je op “Scrape Subpages” om info van gelinkte pagina’s te halen.
- Controleer en exporteer: Bekijk je data en exporteer direct naar Excel, Google Sheets, Airtable, Notion of download als CSV/JSON.
Veelvoorkomende problemen oplossen:
- Pagina’s met login: Gebruik Thunderbit’s Browser Scraping-modus terwijl je bent ingelogd.
- Geblokkeerde of trage sites: Probeer te scrapen op rustige tijden of splits je scrape op in kleinere delen.
- Dynamische content laadt niet: Scroll de pagina volledig door voor het scrapen, of gebruik de browsermodus van Thunderbit.
- Layout verandert: Voer opnieuw “AI Suggest Fields” uit zodat de AI zich aanpast aan de nieuwe structuur.
Kom je er niet uit? De en het supportteam van Thunderbit staan altijd klaar om te helpen.
Samenvatting & Belangrijkste Leerpunten
Inhoud scrapen van andere websites is uitgegroeid van een geheime tool voor developers tot een onmisbare vaardigheid voor elk bedrijf. In 2025, met de enorme groei van webdata en de opkomst van no-code AI-tools, kan iedereen snel en nauwkeurig de informatie verzamelen die hij nodig heeft – zonder gedoe.
Belangrijk om te onthouden:
- Inhoud scrapen van andere websites is essentieel voor leadgeneratie, marktonderzoek en concurrentievoordeel.
- Moderne tools zoals maken webscraping toegankelijk voor iedereen, met natuurlijke taal, AI-veldsuggesties en directe export.
- Dankzij ondersteuning voor paginering, subpagina’s en data-organisatie kun je zelfs de meest complexe sites aan.
- Blijf binnen de regels: scrape alleen openbare data, respecteer sitevoorwaarden en vermijd auteursrechtelijk of persoonlijke inhoud.
- Beginnen is zo simpel als een Chrome-extensie installeren en een paar keer klikken.
Klaar om afscheid te nemen van kopiëren en plakken? en ontdek hoeveel tijd (en frustratie) je bespaart bij je volgende webdataproject. Meer tips en handleidingen vind je op de .
Veelgestelde Vragen
1. Is het legaal om inhoud van andere websites te scrapen?
Over het algemeen wel – zolang je je beperkt tot openbare data, robots.txt en de gebruiksvoorwaarden respecteert en geen auteursrechtelijk beschermde of persoonlijke informatie verzamelt. Controleer altijd de regels per site en gebruik gescrapete data verantwoord ().
2. Moet ik kunnen programmeren om inhoud van websites te scrapen?
Nee! Tools zoals zijn speciaal ontwikkeld voor niet-technische gebruikers. Je kunt data verzamelen met slechts een paar klikken, dankzij natuurlijke taal en AI-veldsuggesties.
3. Welke soorten websites kan ik scrapen met Thunderbit?
Thunderbit werkt op veel verschillende sites – webshops, bedrijvengidsen, reviewplatforms, vastgoedlijsten en meer. Het kan meestal omgaan met paginering, subpagina’s en zelfs dynamische content.
4. Hoe organiseer en analyseer ik de data die ik scrape?
Met Thunderbit kun je data taggen, categoriseren en labelen tijdens het scrapen. Je exporteert direct naar Excel, Google Sheets, Airtable of Notion voor verdere analyse en delen.
5. Wat als een website mijn scraper blokkeert of de layout verandert?
Probeer langzamer te scrapen, gebruik Thunderbit’s Browser Scraping-modus of voer opnieuw “AI Suggest Fields” uit om je aan te passen aan de nieuwe layout. Bij aanhoudende problemen kun je de of het supportteam van Thunderbit raadplegen.
Veel succes met scrapen – en moge je spreadsheets altijd overzichtelijk, gestructureerd en klaar voor gebruik zijn.
Meer weten?