

Stel je dit eens voor: je werkt laat door, koffie in de hand, en je hebt nú de nieuwste prijzen van concurrenten, verse leads of trending posts nodig. Maar je ‘data’ is van vorige week, en tegen de tijd dat je eindelijk hebt wat je nodig hebt, is de markt alweer verder. Ik heb dat zelf meegemaakt, en dat is allesbehalve fijn. In de zakenwereld van vandaag is wachten op verouderde, gecachte data alsof je aankomt bij een flash sale nadat alles al is weggegrist. Daarom is live webcrawlen — realtime data ophalen, op het moment dat het gebeurt — niet langer alleen mooi meegenomen. Het is de geheime saus om voorop te blijven.
Als iemand die jarenlang SaaS- en automationtools heeft gebouwd (en onderweg, ja, véél te veel koffie heeft gedronken), heb ik van dichtbij gezien hoe live crawlers de manier waarop teams werken kunnen veranderen. Thunderbit wordt inmiddels gebruikt door meer dan 100.000 mensen wereldwijd — een flink deel daarvan haalt data realtime op, niet in batches. Met Thunderbit wilden mijn team en ik live crawlen zo simpel maken dat iedereen — zelfs complete beginners — met een paar klikken de versste webdata kan ophalen. In deze gids leg ik uit wat live crawlen nu echt betekent, waarom het belangrijk is en hoe je er vandaag nog mee begint, zonder code.
Wat is een live crawler? Jouw snelle route naar realtime data
Laten we bij het begin beginnen: wat is precies een ‘live crawler’? In gewone taal is een live crawler een tool die data rechtstreeks van een website ophaalt, in realtime, telkens wanneer je hem gebruikt. Zie het als live meekijken in plaats van een herhaling zien. Traditionele webscrapers vertrouwen vaak op periodieke downloads of gecachte snapshots — daardoor loop je altijd een stap achter. Live crawlers daarentegen bezoeken de pagina op dat moment, zien wat er staat en pakken de nieuwste info zodra die verschijnt.
Sommige mensen noemen dit soort tools ook ‘live crawler escort’ of ‘live escort crawler’ (wat eerlijk gezegd klinkt als een geheim agent voor je spreadsheets). Het belangrijkste is dat deze crawlers geen genoegen nemen met oude data. Ze gebruiken browserautomatisering of cloud browsing om content op te halen zoals een mens die zou zien — inclusief dynamische elementen zoals JavaScript, infinite scroll en pop-ups. Dus of je nu een prijsdaling, een virale post of een nieuw contact volgt, je werkt altijd met de meest actuele data die er is (dataprocorp.tech Pricing).
Live versus statisch crawlen:
- Statisch crawlen: alsof je elke dag een foto van een website maakt — prima voor archieven, niet voor breaking news.
- Live crawlen: alsof je een livestream kijkt — wat je ziet, gebeurt op dit moment.
Dat verschil is enorm voor iedereen die afhankelijk is van actuele informatie. In snel bewegende markten kan zelfs een paar uur vertraging al gemiste kansen of verouderde beslissingen betekenen (dataprocorp.tech Pricing).
Waarom live crawlen belangrijk is voor bedrijven: use cases en voordelen
Laten we het praktisch maken. Waarom is live crawlen zo belangrijk voor sales, marketing, operations en meer? Het antwoord is simpel: realtime data leidt tot betere beslissingen. De MIT CISR-briefing uit 2024 over real-time business liet zien dat bedrijven in het hoogste kwartiel voor ‘real-time’ 62% hogere omzetgroei en 97% hogere winstmarges behaalden dan bedrijven in het laagste kwartiel — geen verschil om van weg te strepen (MIT CISR).
| Use case | Teams/functie | Voorbeeldvoordelen/verzamelde data |
|---|---|---|
| Monitoring van concurrentieprijzen | Sales/e-commerce | Volg prijzen en promoties realtime voor dynamische prijsstelling (promptcloud.com Pricing) |
| Lead-/contactextractie | Sales/marketing | Haal verse contactgegevens op (naam, e-mail, telefoon) uit directories of LinkedIn (Thunderbit Blog) |
| Social media- en trendanalyse | Marketing/product | Monitor hashtags, trending topics en sentiment zodra ze verschijnen (promptcloud.com Pricing) |
| Updates van productcatalogi | E-commerce/operations | Houd aanbiedingen actueel (prijzen, beschrijvingen, voorraad) (datadwip.com Pricing) |
| Data voor sales pipelines | Sales | Bouw automatisch prospectlijsten op door bedrijfsdirectories te scrapen (Thunderbit Blog) |
| Vastgoedaanbod | Vastgoed | Verzamel nieuwe woningaanbiedingen en prijsupdates zodra ze worden geplaatst (promptcloud.com Pricing) |
En laten we de kern niet vergeten: snellere, nauwkeurigere data betekent snellere, betere beslissingen. Teams vermijden giswerk, zien trends zodra ze opduiken en handelen voordat de concurrentie überhaupt weet wat er is gebeurd. Kort gezegd: live crawlen zet ruwe webdata meteen om in bruikbare intelligence (cisr.mit.edu).
Thunderbit: de makkelijkste live crawler voor iedereen
Haal data van elke website met AI Get Started Free
Nu denk je misschien: “Klinkt geweldig, maar ik ben geen programmeur. Hoe doe ik dit eigenlijk?” Precies dát was het probleem dat we met Thunderbit wilden oplossen.
Thunderbit is een AI-aangedreven Chrome-extensie die live crawlen net zo makkelijk maakt als eten bestellen — en eerlijk gezegd soms zelfs sneller. Dit is wat het onderscheidt:
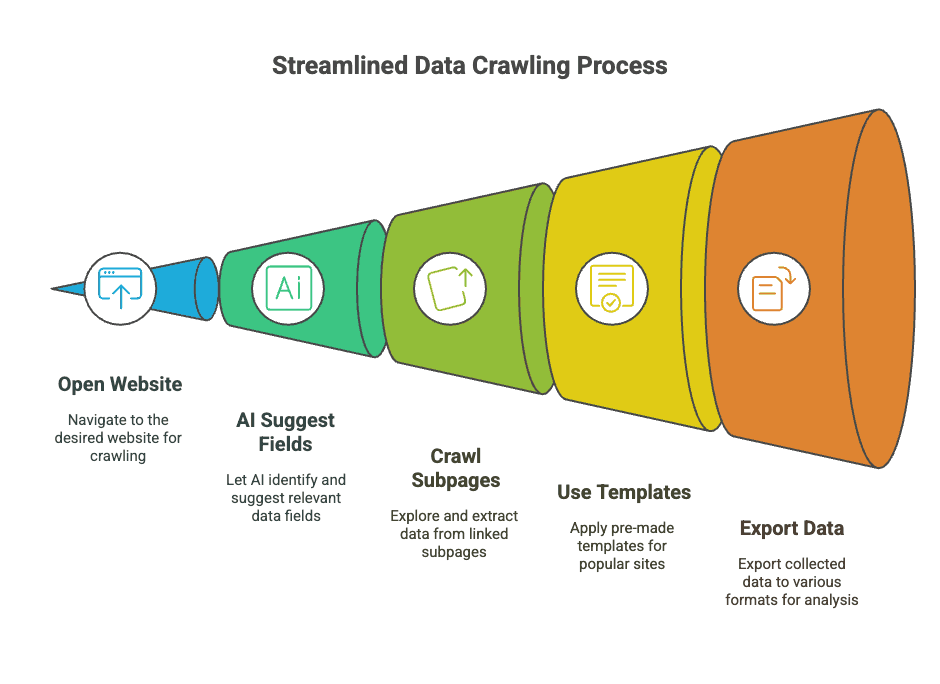
- Geen code nodig: installeer gewoon de extensie, open de site die je wilt en laat de AI van Thunderbit de rest doen.
- AI stelt velden voor: klik op één knop en Thunderbit scant de pagina, waarna automatisch de beste kolommen worden voorgesteld (zoals “Naam”, “Prijs”, “E-mail”) (Thunderbit Blog).
- Subpagina-crawlen: info nodig die achter links verborgen zit? Thunderbit kan elke subpagina bezoeken (zoals productdetails of contactprofielen) en alle data in één tabel samenbrengen.
- Directe templates: voor populaire sites (Amazon, Zillow, LinkedIn, enz.) kun je kant-en-klare sjablonen gebruiken — geen setup, geen stress.
- Meertalige ondersteuning: Thunderbit werkt in 34 talen, dus het is klaar voor internationale teams (Thunderbit Blog).
- Gratis data-export: exporteer je resultaten naar Excel, Google Sheets, Airtable, Notion, CSV of JSON — helemaal gratis (Thunderbit Blog).
En het mooiste? Zelfs als je een complete beginner bent, kun je binnen enkele minuten aan de slag. Zoals een gebruiker het zei: “Ik hoef maar twee knoppen aan te klikken en de data is meteen klaar. De nauwkeurigheid is indrukwekkend” (trustpilot.com).
Live crawler-oplossingen vergelijken: Thunderbit versus traditionele tools
Laten we eerlijk zijn: er zijn ook andere manieren om live webdata te scrapen. Als je engineer bent, kun je een custom crawler bouwen met Selenium (nog steeds actief onderhouden — versie 4.4x verscheen in 2026) of Beautiful Soup, of kiezen voor nieuwere AI-achtige opties zoals Browser Use voor browserflows in natuurlijke taal en Firecrawl voor LLM-vriendelijke URL-naar-markdown-extractie. Ze werken allemaal — maar ze gaan er ook allemaal van uit dat je zelf comfortabel code, anti-botmaatregelen en proxies inricht. Is dat niet jouw weekendproject, lees dan vooral verder.
| Aspect | Traditionele tools (Python/Selenium) | Thunderbit AI Crawler |
|---|---|---|
| Setup & vaardigheid | Coderen vereist, omgeving instellen | Geen code — gewoon installeren en gaan (Thunderbit Blog) |
| Insteltijd | Uren tot dagen | Minuten |
| Actualiteit van data | Snapshots, kunnen verouderd zijn | Live, tot op de seconde (dataprocorp.tech Pricing) |
| Dynamische content | Lastig (extra code nodig) | Ingebouwd, verwerkt JS en scrollen (Thunderbit Blog) |
| Aanpasbaarheid | Breekt als de site verandert | AI past zich automatisch aan (dataprocorp.tech Pricing) |
| Onderhoud | Hoog (regelmatig repareren) | Laag (AI verwerkt de meeste wijzigingen) (dataprocorp.tech Pricing) |
| Uitvoerformaat | Ruwe HTML, handmatig opschonen | Gestructureerde tabellen, direct exporteerbaar (Thunderbit Blog) |
| Integraties | Aangepaste code nodig | Direct exporteren naar Sheets, Airtable, Notion, CSV, JSON (Thunderbit Blog) |
Dus tenzij je op zoek bent naar een nieuwe hobby in het schrijven van webscraping-scripts, is Thunderbit de logische keuze voor zakelijke gebruikers die snel en betrouwbaar resultaat nodig hebben.
Stap voor stap: Thunderbit gebruiken als jouw live crawler
Klaar om live crawlen in actie te zien? Zo kun je Thunderbit gebruiken om realtime data van elke website te halen — zonder technisch jargon, zonder hoofdpijn.
Stap 1: Installeer Thunderbit en open je doelsite
Begin bij het begin: voeg de Thunderbit Chrome-extensie toe aan je browser. Het duurt ongeveer een minuut (tenzij je wifi op hamsters draait).
Open daarna gewoon de website die je wilt crawlen. Thunderbit werkt op elke site die je browser kan zien — dus als jij kunt inloggen en de pagina kunt bekijken, kan Thunderbit dat ook.
Probeer Thunderbit Live Crawler gratis
Stap 2: Gebruik AI om velden voor te stellen voor directe datamapping
Hier gebeurt de magie — oké, de AI. Klik op de knop AI stelt velden voor in Thunderbit. De AI scant de pagina en stelt de beste kolommen voor om te extraheren — zoals “Naam”, “Prijs”, “Voorraad”, “E-mail” of alles wat relevant is (Thunderbit Blog).
Je kunt deze velden aanpassen, hernoemen of zelf extra velden toevoegen. Wil je het wat geavanceerder aanpakken? Voeg dan per veld eigen instructies toe — bijvoorbeeld “formatteer telefoonnummers als E.164” of “categoriseer producten op type”.
Stap 3: Scrape live data met één klik
Zodra je velden staan, klik je op Scrape. Thunderbit begint de pagina realtime te crawlen en volgt paginering of infinite scroll als dat nodig is. Als je subpagina-crawlen hebt ingeschakeld, klikt het door naar elk gelinkt item (zoals productdetails of profielen) en haalt die info in je tabel (Thunderbit Blog).
Je kunt de rijen zien vullen terwijl Thunderbit bezig is — een beetje alsof je popcorn ziet poppen, maar dan veel nuttiger.
Stap 4: Exporteer verse data naar Excel, Google Sheets of Notion
Als de crawl klaar is, is het tijd om met je data aan de slag te gaan. Thunderbit laat je alles gratis exporteren naar Excel, Google Sheets, Airtable, Notion, CSV of JSON (Thunderbit Blog). Kies gewoon je formaat, en je live data is klaar voor analyse, rapportage of delen.
Pro-tips: haal meer uit je live crawler
Wil je nog meer uit Thunderbit halen? Hier zijn een paar tips die ik onderweg heb opgepikt — soms op de harde manier:
- Plan crawls in: gebruik de planner van Thunderbit om scrapes automatisch uit te voeren (bijvoorbeeld “elke maandag om 9:00”). Perfect voor doorlopende prijsmonitoring of lead-updates (Thunderbit Blog).
- Gebruik subpagina’s: als details achter links verborgen zitten (zoals contactgegevens op profielen), schakel subpagina-crawlen in. Thunderbit bezoekt dan elke link en voegt de extra data samen.
- Pas veldprompts aan: voor complexe data kun je aangepaste AI-instructies toevoegen — bijvoorbeeld voor het categoriseren van producten of het formatteren van tekst tijdens het scrapen.
- Gebruik directe templates: kijk bij populaire sites eerst of er een one-click template is voordat je velden handmatig instelt.
- Overbelast sites niet: scrape niet sneller dan nodig. Gebruik planning en redelijke vertragingen om de servers van websites te respecteren (scrapingapi.ai Pricing).
- Slimme cloud vs. browser: voor publieke sites is Cloud-modus super snel (tot 50 pagina’s tegelijk). Voor sites waarvoor je moet inloggen, gebruik je Browser-modus zodat Thunderbit binnen jouw sessie draait.
Veilig en compliant blijven bij live crawlen
Een korte maar belangrijke opmerking: respecteer altijd de voorwaarden en privacy van websites. Controleer vóór het crawlen het robots.txt-bestand en de servicevoorwaarden van de site (scrapingapi.ai Pricing). Sommige sites beperken geautomatiseerde toegang of crawlsnelheid. Thunderbit geeft je tools om verzoeken te vertragen en runs in te plannen, maar het is aan jou om die verantwoord te gebruiken.
- Respecteer privacy en wetgeving: scrape alleen publieke data en vermijd het verzamelen van persoonsgegevens zonder toestemming. Als je e-mails of telefoonnummers verzamelt, zorg dan dat je voldoet aan de AVG of CCPA (scrapingapi.ai Pricing).
- Wees een goede webburger: gebruik de data voor legitieme zakelijke doeleinden en overbelast servers niet. Transparantie en naleving verkleinen juridische risico’s en houden iedereen tevreden.
Veelvoorkomende uitdagingen bij live crawlers oplossen
Bekijk de Thunderbit-blog voor meer tips Get Started Free
Live crawlen verloopt niet altijd vlekkeloos. Dit zijn een paar veelvoorkomende obstakels — en hoe Thunderbit je helpt ze te omzeilen:
- Anti-botmaatregelen: sommige sites gebruiken CAPTCHA’s of IP-blokkades. Thunderbit bootst menselijk browsen na (vooral in Browser-modus) en handelt retries af. Voor hardnekkige CAPTCHA’s moet je ze mogelijk handmatig oplossen.
- JavaScript en dynamische pagina’s: traditionele scrapers hebben hier moeite mee, maar Thunderbit draait in een echte browser en verwerkt scripts, AJAX en infinite scroll dus native.
- Wijzigingen in de lay-out van de site: als een site zijn lay-out aanpast, breken traditionele scrapers vaak. Thunderbit’s AI past zich automatisch aan de meeste wijzigingen aan — klik gewoon op “AI velden verbeteren” als dat nodig is (dataprocorp.tech Pricing).
- Datakwaliteit: Thunderbit maakt data schoon en structureert ze tijdens het scrapen, maar controleer de resultaten altijd steekproefsgewijs vóór export.
- Zware JavaScript: probeer bij extreem complexe sites te wisselen tussen Cloud- en Browser-modus, of gebruik indien mogelijk een andere URL.
- Hardnekkige CAPTCHA’s: als een site bots agressief blokkeert, overweeg dan een officiële API of pas je crawltempo aan.
De meeste van deze problemen zijn met Thunderbit veel minder vervelend dan met handgeschreven scripts. En als je ooit vastloopt, is er altijd de Thunderbit Blog voor meer tips en troubleshooting.
Conclusie en belangrijkste inzichten: til je data naar een hoger niveau met live crawlen
Laten we samenvatten: live webcrawlen is de snelste manier om up-to-the-second data voor je bedrijf te krijgen. Of je nu in sales, marketing, operations zit of gewoon een data-nerd bent zoals ik, de meest actuele info betekent betere beslissingen, minder giswerk en een echte voorsprong op de concurrentie.
Met Thunderbit hoef je geen codeur of data scientist te zijn. Iedereen kan binnen enkele minuten een live crawl opzetten, automatiseren en de resultaten exporteren naar favoriete tools. En met functies zoals AI-veldherkenning, subpagina-crawlen en directe templates besteed je minder tijd aan het worstelen met data en meer tijd aan handelen op basis ervan.
Kortom: de markt voor realtime analytics groeit inmiddels van ongeveer 1,1 miljard dollar in 2025 naar een verwachte 5,3 miljard dollar in 2032 — een CAGR van 25,1%. Live crawlen is niet langer een trend voor de toekomst; het is de basisvoorwaarde. Thunderbit maakt het voor iedereen toegankelijk, zodat je kunt stoppen met wachten en kunt beginnen met winnen.
Klaar om het te proberen? Download Thunderbit, kies een website en ontdek hoe makkelijk live crawlen kan zijn. En als je verder wilt duiken, bekijk dan onze beginnersgids of ontdek meer use cases op de Thunderbit-blog.
Lees de beginnersgids voor Thunderbit
Veel succes met crawlen — en moge je data altijd verser zijn dan je ochtendkoffie.
Probeer AI Live Web Crawler nu Get Started Free
Veelgestelde vragen
1. Wat is een live crawler en hoe verschilt die van traditionele webscrapers?
Een live crawler is een tool die realtime data van websites ophaalt op het moment dat je daarom vraagt. In tegenstelling tot traditionele scrapers die volgens een schema werken of gecachte data gebruiken, leveren live crawlers informatie tot op de seconde. Ze bevatten vaak AI om relevante velden te herkennen en pagina’s automatisch te navigeren, waardoor ze sneller en makkelijker te gebruiken zijn.
2. Waarom is realtime data belangrijk voor sales- en operationsteams?
Realtime data helpt teams om direct beslissingen te nemen in snel veranderende omgevingen. Of het nu gaat om het aanpassen van prijzen op basis van concurrentiewijzigingen, reageren op trends op social media of voorraadupdates volgen: met de nieuwste data blijven bedrijven concurrerend, vermijden ze vertragingen en verhogen ze hun omzet.
3. Hoe verbetert AI het live-crawlproces?
AI vereenvoudigt live crawlen door automatisch relevante datavelden te detecteren, zich aan lay-outwijzigingen aan te passen, paginering en subpagina’s af te handelen en zelfs data te transformeren (zoals tekst vertalen of valuta omrekenen). Daardoor is het toegankelijk voor niet-technische gebruikers en is er minder handmatige setup nodig.
4. Wat zijn praktische use cases voor live crawlen?
Live crawlers worden gebruikt voor het monitoren van prijzen op e-commerceplatforms, het scrapen van TikTok of Twitter voor reacties, het genereren van salesleads uit LinkedIn, het verzamelen van klantreviews en het volgen van content van concurrenten. Deze use cases komen voor in sectoren zoals retail, vastgoed, marketing en logistiek.
5. Hoe kan iemand beginnen met een live crawler-tool zoals Thunderbit?
Om te beginnen kunnen gebruikers de Thunderbit Chrome-extensie installeren, naar een webpagina gaan en de functie “AI stelt velden voor” gebruiken om data te selecteren. Na het klikken op “Scrape” verzamelt de tool de data en levert die in een gestructureerde output, die kan worden geëxporteerd naar spreadsheets of geïntegreerd met tools zoals Google Sheets of Airtable — zonder code.




